


Constructing Traceability Links between Software Requirements and Source Code Based on Neural Networks

(This article belongs to the Section Network Science)
Abstract
:1. Introduction
- 1.
- We propose a generic and automated technique for mapping software requirements to source code.
- 2.
- We use a combination of neural network techniques to extract semantic information from software artifacts.
- 3.
- We develop DCT, a tool for constructing traceability links between software requirements and source code.
- 4.
- We demonstrate that self-attention is better at constructing traceability networks than other neural network models.
- 5.
- We demonstrate that neural network technology can surpass or even substitute information retrieval techniques in traceability tasks.
2. Related Works
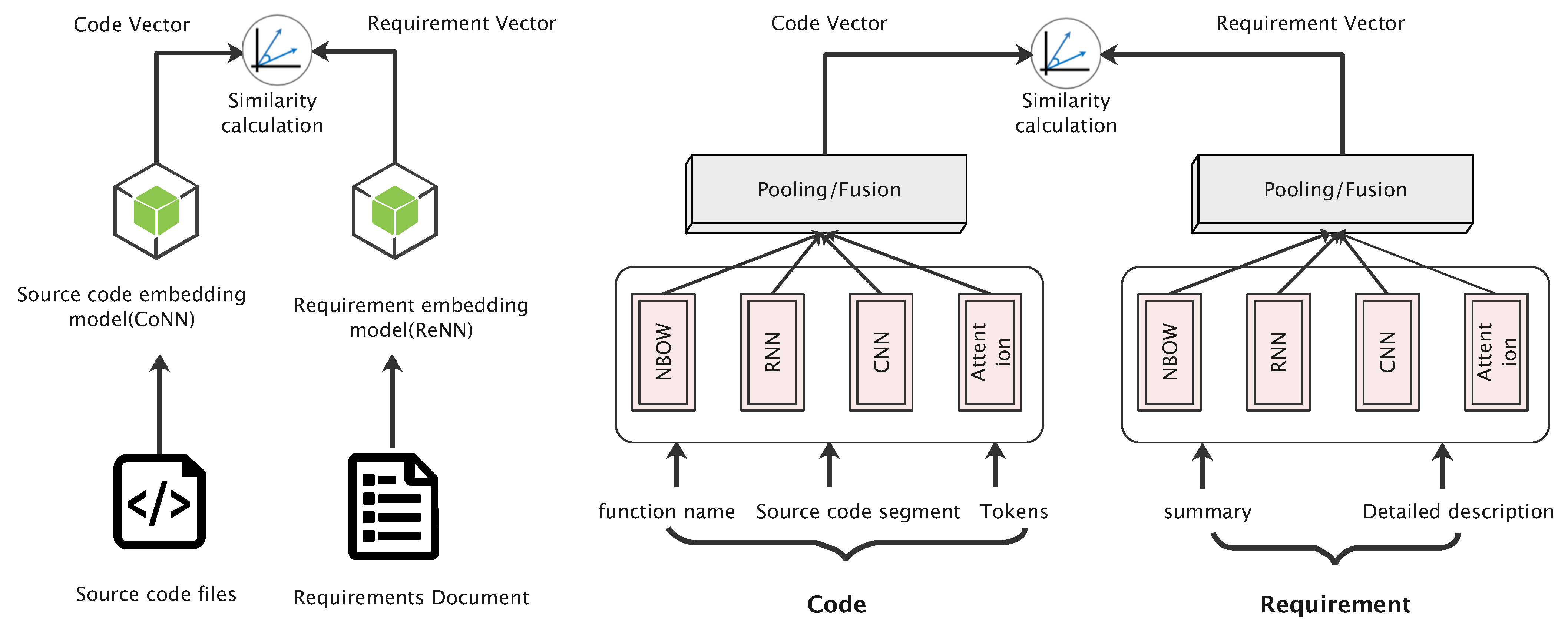
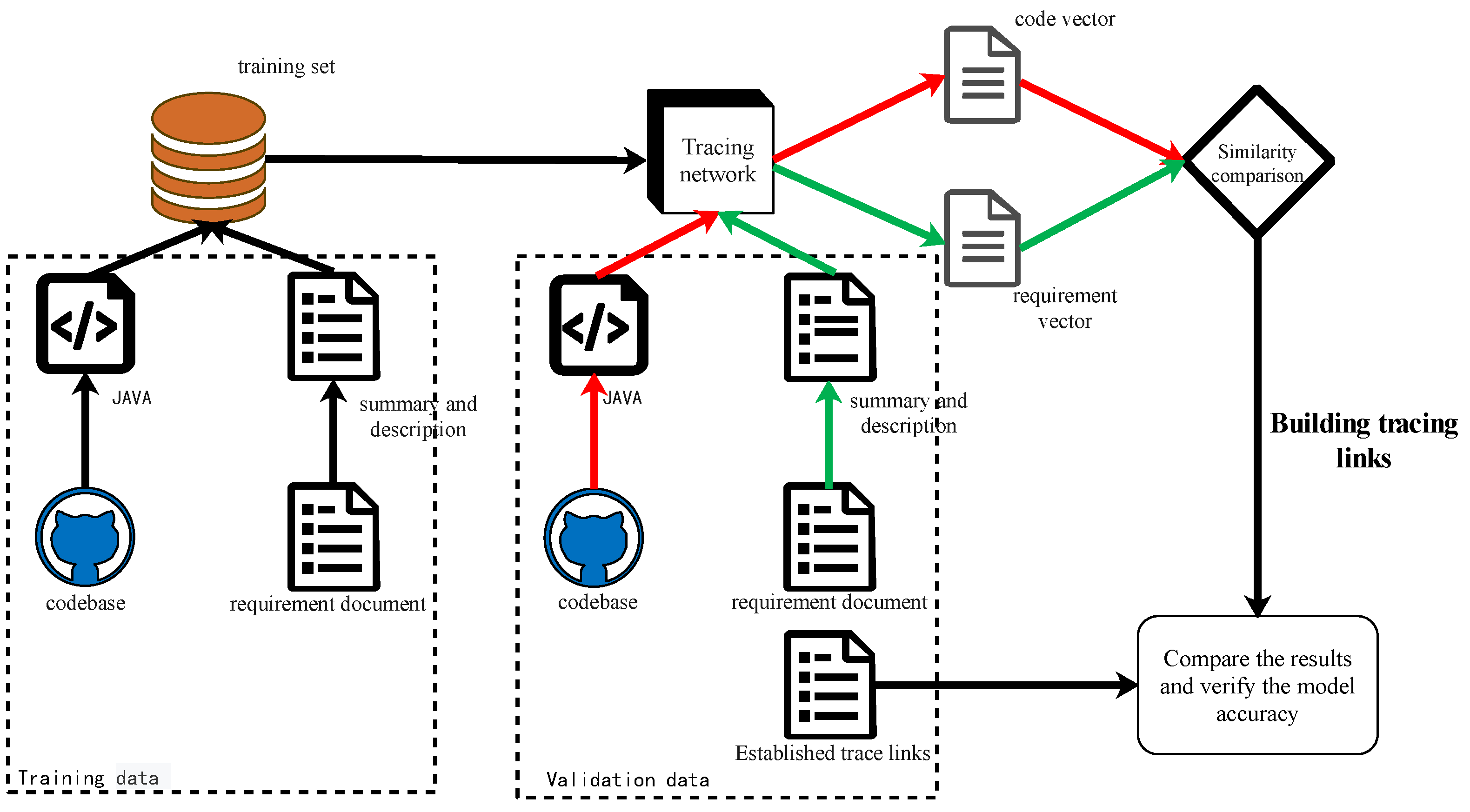
3. Overview of Approach
3.1. Neural Network Structures
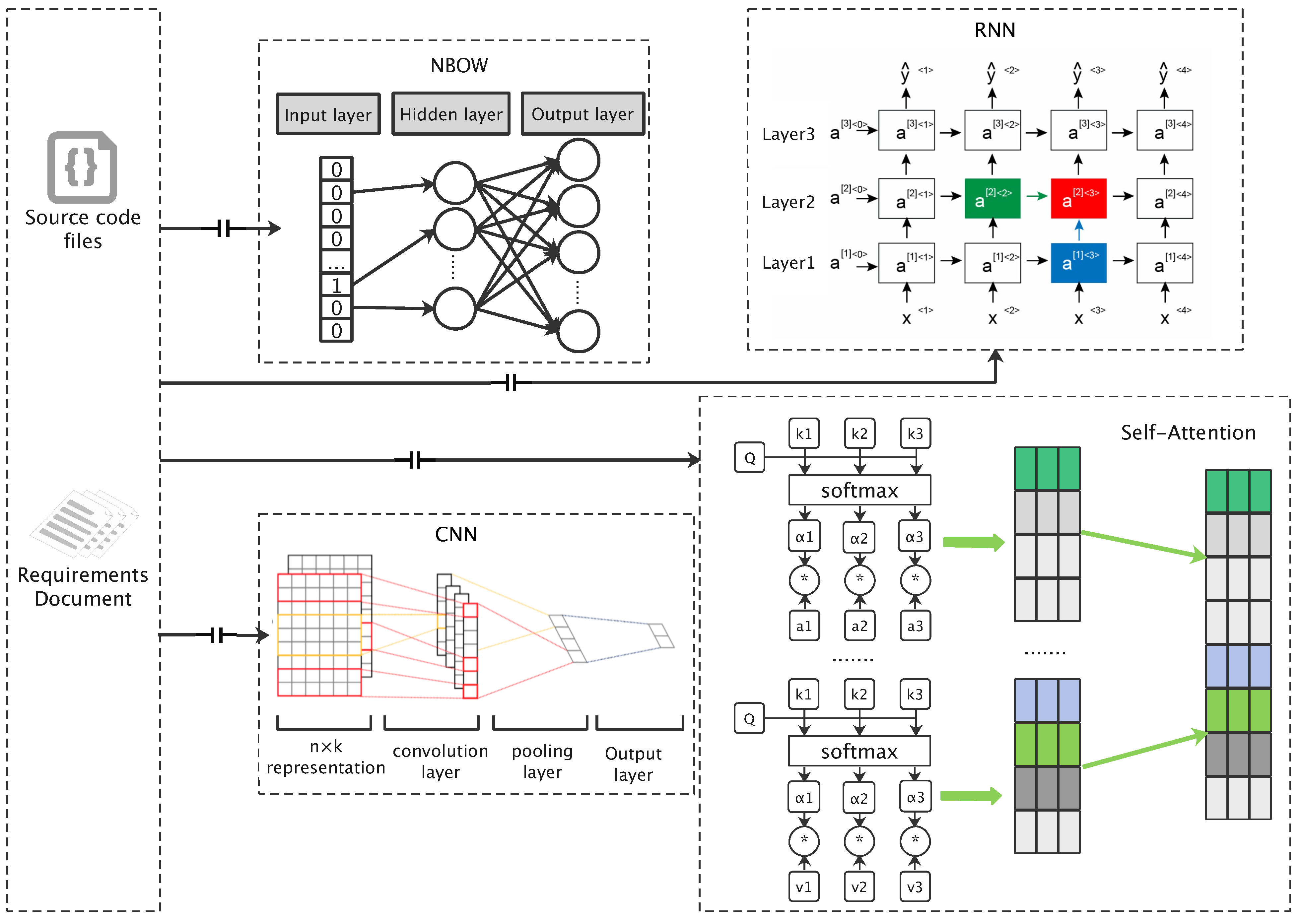
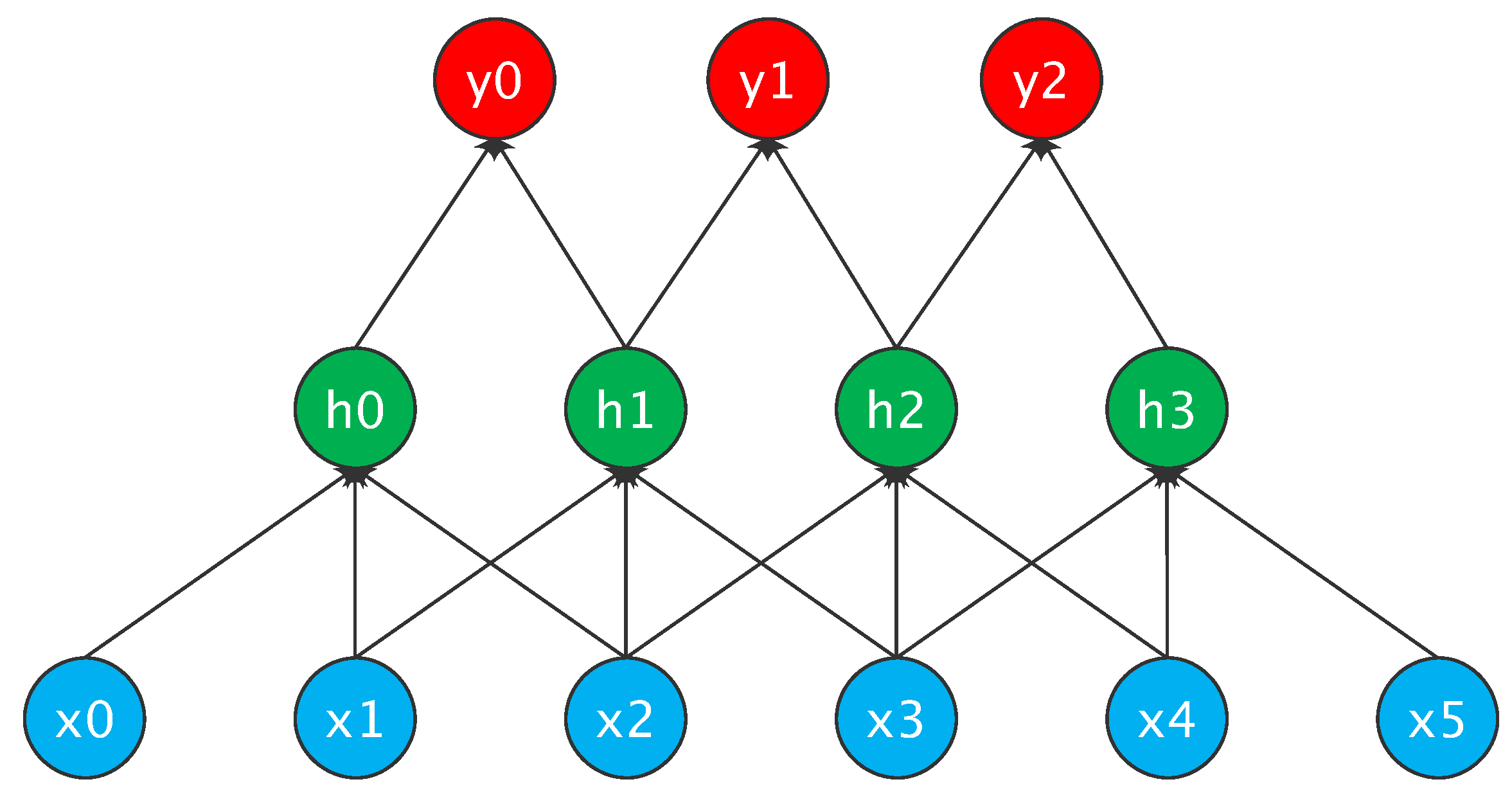
3.1.1. Embedding Model Based on NBOW
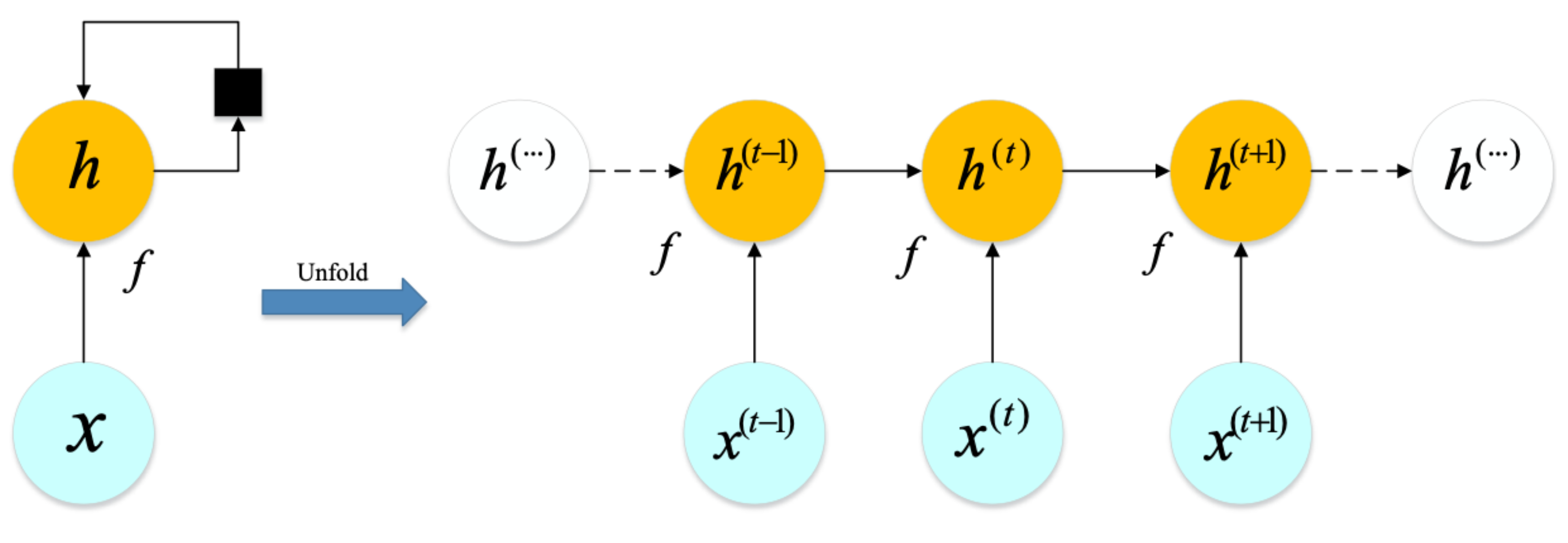
3.1.2. Embedding Model Based on RNN
3.1.3. Embedding Model Based on Self-Attention
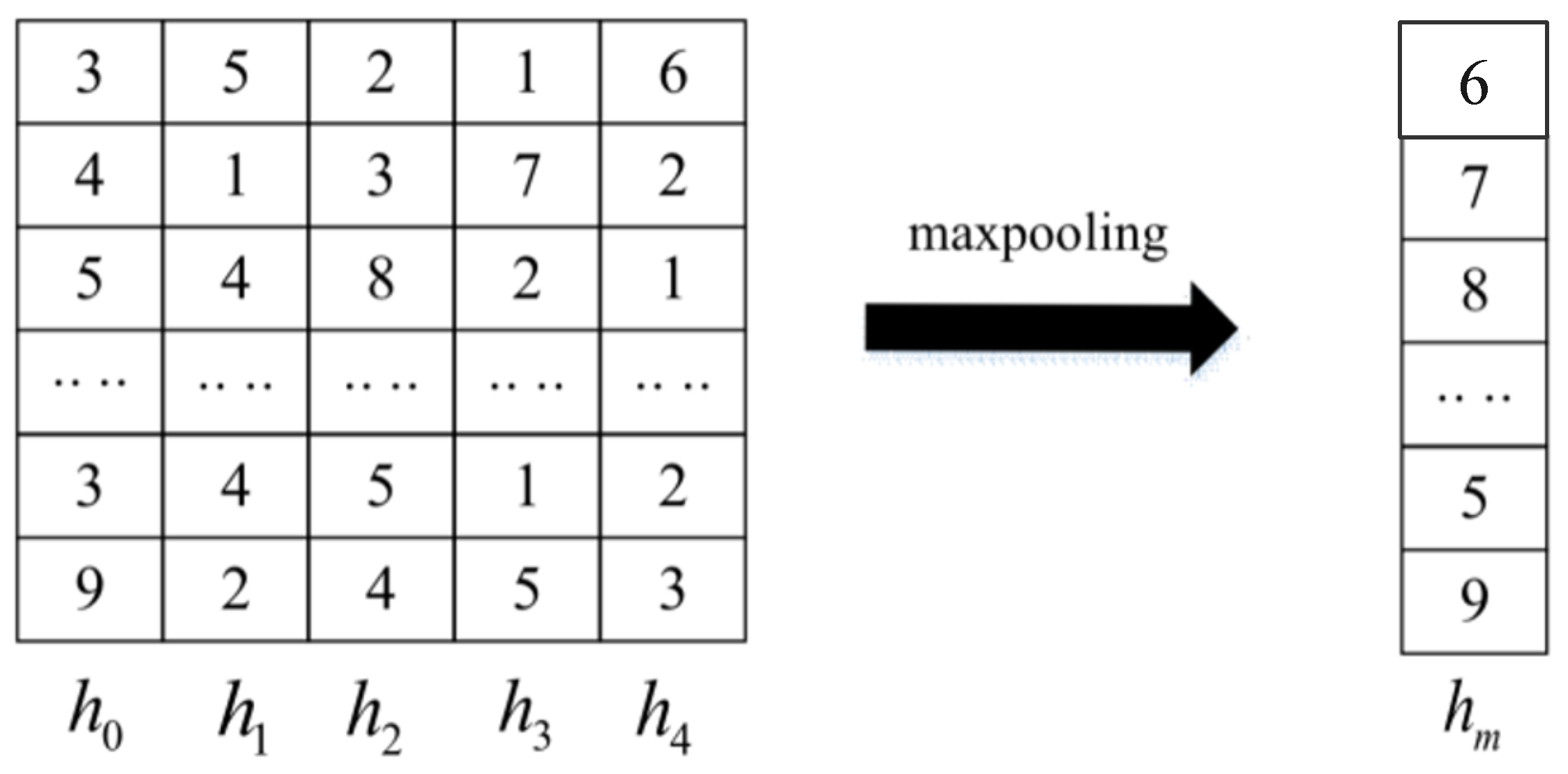
3.2. Embedding Model Based on CNN
- 1.
- Sparse connection: This enables each neuron in the neural network to focus on acquiring local features.
- 2.
- Weight sharing: It increases efficiency by reducing the number of parameters to be learned and allows the model to be generalized.
3.3. Requirement and Source Code Feature Vector Generation
3.4. Similarity Calculation and Model Training
4. Experiment Setup
4.1. Subject Programs and Metrics
- The metric measures the percentage of correct relevant results among the first k results returned by each query or prediction [44], which is calculated as shown in Equation (21), where is the correct relevant results among the first k results and is the correct results that were not detected in the first k results.Because a requirement may be related to multiple code files in the software, a higher value of indicates a better performance in constructing traceability links between the software requirements and the source code.
4.2. Experiment Process
5. Results
- 1.
- RQ1: Which neural network model in RCT can obtain better results for constructing traceability links between software requirements and source code?
- 2.
- RQ2: Is RCT better than other methods of constructing traceability links between software requirements and source code?
5.1. RQ1 Comparative Experimental Analysis
5.2. RQ2 Comparative Experimental Analysis
6. Discussion
6.1. Why Does RCT Work?
6.2. Limitation of RCT
6.3. Threats to Validity
- External validity: Firstly, the dataset used for this experiment is the natural language description-code base provided by Microsoft and some projects on GitHub, so the results of this paper may not apply to all open-source projects. At the same time, the code in these datasets is well written, which helps build links between software requirements and source code. However, due to the varying levels of programmers, there are many irregularities in writing, such as poor naming. Therefore, more actual projects can be considered in the future. In addition, we use Java projects as the subject of the experiment. However, the coding specifications and syntax vary between programming languages, so the performance of building links may also be different. The performance of RCT will be further evaluated.
- Internal validity: RCT uses neural networks to extract textual semantic information from software requirements and code and uses the similarity between their feature vectors to construct traceability links. However, the functionality of the code implementation sometimes cannot be summarized from the vocabulary used in the code text alone but needs to be analyzed in terms of the code’s abstract syntax tree, control flow graphs, etc., to understand the code functionality better. Therefore, the following work will further improve the neural network models: combine multiple neural network models to better extract semantic information from the source code, or use other neural networks (tree-LSTM [58], GNN [59]) to extract a source code’s control flow graph and deeper structural semantic information in the abstract syntax tree. This will further improve the accuracy of constructing traceability.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hall, T.; Beecham, S.; Rainer, A. Requirements problems in twelve software companies: An empirical analysis. Iee Proc. Softw. 2002, 149, 153–160. [Google Scholar] [CrossRef]
- Gotel, O.; Cleland-Huang, J.; Hayes, J.H.; Zisman, A.; Egyed, A.; Grünbacher, P.; Dekhtyar, A.; Antoniol, G.; Maletic, J.; Mäder, P. Traceability fundamentals. In Software and Systems Traceability; Springer: Berlin/Heidelberg, Germany, 2012; pp. 3–22. [Google Scholar]
- Knight, J.C. Safety critical systems: Challenges and directions. In Proceedings of the 24th International Conference on Software Engineering, Orlando FL, USA, 19–25 May 2002; pp. 547–550. [Google Scholar]
- Cleland-Huang, J.; Rahimi, M.; Mäder, P. Achieving lightweight trustworthy traceability. In Proceedings of the 22nd ACM Sigsoft International Symposium on Foundations of Software Engineering, Hong Kong, China, 16–21 November 2014; pp. 849–852. [Google Scholar]
- Rempel, P.; Mäder, P.; Kuschke, T.; Cleland-Huang, J. Traceability Gap Analysis for Assessing the Conformance of Software Traceability to Relevant Guidelines. In Proceedings of the Software Engineering & Management, Dresden, Germany, 17–20 March 2015; pp. 120–121. [Google Scholar]
- Shao, J.; Wu, W.; Geng, P. An improved approach to the recovery of traceability links between requirement documents and source codes based on latent semantic indexing. In Proceedings of the International Conference on Computational Science and Its Applications, Ho Chi Minh City, Vietnam, 24–27 July 2013; pp. 547–557. [Google Scholar]
- Chen, X.; Grundy, J. Improving automated documentation to code traceability by combining retrieval techniques. In Proceedings of the 2011 26th IEEE/ACM International Conference on Automated Software Engineering (ASE 2011), Lawrence, KS, USA, 6–10 November 2011; pp. 223–232. [Google Scholar]
- Cleland-Huang, J.; Czauderna, A.; Gibiec, M.; Emenecker, J. A machine learning approach for tracing regulatory codes to product specific requirements. In Proceedings of the 32nd ACM/IEEE International Conference on Software Engineering-Volume 1, Cape Town, South Africa, 1–8 May 2010; pp. 155–164. [Google Scholar]
- Eaddy, M.; Aho, A.V.; Antoniol, G.; Guéhéneuc, Y.G. Cerberus: Tracing requirements to source code using information retrieval, dynamic analysis, and program analysis. In Proceedings of the 2008 16th IEEE International Conference on Program Comprehension, Amsterdam, The Netherlands, 10–13 June 2008; pp. 53–62. [Google Scholar]
- Vale, T.; de Almeida, E.S. Experimenting with information retrieval methods in the recovery of feature-code SPL traces. Empir. Softw. Eng. 2019, 24, 1328–1368. [Google Scholar] [CrossRef]
- Cleland-Huang, J.; Guo, J. Towards more intelligent trace retrieval algorithms. In Proceedings of the 3rd International Workshop on Realizing Artificial Intelligence Synergies in Software Engineering, Hyderabad, India, 3 June 2014; pp. 1–6. [Google Scholar]
- Socher, R.; Lin, C.C.; Manning, C.; Ng, A.Y. Parsing natural scenes and natural language with recursive neural networks. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 129–136. [Google Scholar]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved semantic representations from tree-structured long short-term memory networks. arXiv 2015, arXiv:1503.00075. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Hindle, A.; Barr, E.T.; Gabel, M.; Su, Z.; Devanbu, P. On the naturalness of software. Commun. ACM 2016, 59, 122–131. [Google Scholar] [CrossRef]
- Nurmuliani, N.; Zowghi, D.; Powell, S. Analysis of requirements volatility during software development life cycle. In Proceedings of the 2004 Australian Software Engineering Conference. Proceedings, Melbourne, Australia, 13–16 April 2004; pp. 28–37. [Google Scholar]
- Clancy, T. The Chaos Report; The Standish Group: Yarmouth, MA, USA, 1995. [Google Scholar]
- Cleland-Huang, J.; Chang, C.K.; Christensen, M. Event-based traceability for managing evolutionary change. IEEE Trans. Softw. Eng. 2003, 29, 796–810. [Google Scholar] [CrossRef]
- Nuseibeh, B.; Easterbrook, S. Requirements engineering: A roadmap. In Proceedings of the Conference on the Future of Software Engineering, Limerick, Ireland, 4–11 June 2000; pp. 35–46. [Google Scholar]
- Curtis, B.; Krasner, H.; Iscoe, N. A field study of the software design process for large systems. Commun. ACM 1988, 31, 1268–1287. [Google Scholar] [CrossRef]
- Boehm, B.W.; Papaccio, P.N. Understanding and controlling software costs. IEEE Trans. Softw. Eng. 1988, 14, 1462–1477. [Google Scholar] [CrossRef] [Green Version]
- Lock, S.; Kotonya, G. Requirement Level Change Management and Impact Analysis. 1998. Available online: https://eprints.lancs.ac.uk/id/eprint/11646/ (accessed on 7 July 2011).
- Ziftci, C.; Krueger, I. Tracing requirements to tests with high precision and recall. In Proceedings of the 2011 26th IEEE/ACM International Conference on Automated Software Engineering (ASE 2011), Lawrence, KS, USA, 6–10 November 2011; pp. 472–475. [Google Scholar]
- Yu, D.; Geng, P.; Wu, W. Constructing traceability between features and requirements for software product line engineering. In Proceedings of the 2012 19th Asia-Pacific Software Engineering Conference, Hong Kong, China, 4–7 December 2012; Volume 2, pp. 27–34. [Google Scholar]
- Eder, S.; Femmer, H.; Hauptmann, B.; Junker, M. Configuring latent semantic indexing for requirements tracing. In Proceedings of the 2015 IEEE/ACM 2nd International Workshop on Requirements Engineering and Testing, Florence, Italy, 18 May 2015; pp. 27–33. [Google Scholar]
- Zhou, J.; Lu, Y.; Lundqvist, K. A context-based information retrieval technique for recovering use-case-to-source-code trace links in embedded software systems. In Proceedings of the 2013 39th Euromicro Conference on Software Engineering and Advanced Applications, Santander, Spain, 4–6 September 2013; pp. 252–259. [Google Scholar]
- Mahmoud, A.; Niu, N.; Xu, S. A semantic relatedness approach for traceability link recovery. In Proceedings of the 2012 20th IEEE International Conference on Program Comprehension (ICPC), Passau, Germany, 11–13 June 2012; pp. 183–192. [Google Scholar]
- Mahmood, K.; Takahashi, H.; Alobaidi, M. A semantic approach for traceability link recovery in aerospace requirements management system. In Proceedings of the 2015 IEEE Twelfth International Symposium on Autonomous Decentralized Systems, Taichung, Taiwan, 25–27 March 2015; pp. 217–222. [Google Scholar]
- Ali, N.; Jaafar, F.; Hassan, A.E. Leveraging historical co-change information for requirements traceability. In Proceedings of the 2013 20th Working Conference on Reverse Engineering (WCRE), Koblenz, Germany, 14–17 October 2013; pp. 361–370. [Google Scholar]
- Mahmoud, A. An information theoretic approach for extracting and tracing non-functional requirements. In Proceedings of the 2015 IEEE 23rd International Requirements Engineering Conference (RE), Ottawa, ON, Canada, 24–28 August 2015; pp. 36–45. [Google Scholar]
- Zhang, Y.; Wan, C.; Jin, B. An empirical study on recovering requirement-to-code links. In Proceedings of the 2016 17th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Shanghai, China, 30 May–1 June 2016; pp. 121–126. [Google Scholar]
- Gervasi, V.; Zowghi, D. Supporting traceability through affinity mining. In Proceedings of the 2014 IEEE 22nd International Requirements Engineering Conference (RE), Karlskrona, Sweden, 25–29 August 2014; pp. 143–152. [Google Scholar]
- Guo, J.; Gibiec, M.; Cleland-Huang, J. Tackling the term-mismatch problem in automated trace retrieval. Empir. Softw. Eng. 2017, 22, 1103–1142. [Google Scholar] [CrossRef]
- Mahmoud, A.; Niu, N. Supporting requirements to code traceability through refactoring. Requir. Eng. 2014, 19, 309–329. [Google Scholar] [CrossRef]
- Li, Z.; Chen, M.; Huang, L.; Ng, V. Recovering traceability links in requirements documents. In Proceedings of the Nineteenth Conference on Computational Natural Language Learning, Beijing, China, 30–31 July 2015; pp. 237–246. [Google Scholar]
- Mills, C. Towards the automatic classification of traceability links. In Proceedings of the 2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE), Urbana, IL, USA, 30 October–3 November 2017; pp. 1018–1021. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv 2014, arXiv:1404.2188. [Google Scholar]
- Iyyer, M.; Manjunatha, V.; Boyd-Graber, J.; Daumé, H., III. Deep unordered composition rivals syntactic methods for text classification. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 1681–1691. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Rocktäschel, T.; Grefenstette, E.; Hermann, K.M.; Kočiskỳ, T.; Blunsom, P. Reasoning about entailment with neural attention. arXiv 2015, arXiv:1509.06664. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Britz, D.; Goldie, A.; Luong, M.T.; Le, Q. Massive exploration of neural machine translation architectures. arXiv 2017, arXiv:1703.03906. [Google Scholar]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar]
- Chen, Y. Convolutional Neural Network for Sentence Classification. Master’s Thesis, University of Waterloo, Waterloo, ON, Canada, 2015. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Yoon, K. Convolutional Neural Networks for Sentence Classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Frome, A.; Corrado, G.S.; Shlens, J.; Bengio, S.; Dean, J.; Ranzato, M.; Mikolov, T. Devise: A deep visual-semantic embedding model. Adv. Neural Inf. Process. Syst. 2013, 26, 2121–2129. [Google Scholar]
- Husain, H.; Wu, H.H.; Gazit, T.; Allamanis, M.; Brockschmidt, M. Codesearchnet challenge: Evaluating the state of semantic code search. arXiv 2019, arXiv:1909.09436. [Google Scholar]
- Rath, M.; Mäder, P. The SEOSS 33 dataset—Requirements, bug reports, code history, and trace links for entire projects. Data Brief 2019, 25, 104005. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Yu, T.; Lane, I.; Mengshoel, O.J. Customized nonlinear bandits for online response selection in neural conversation models. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Lv, F.; Zhang, H.; Lou, J.g.; Wang, S.; Zhang, D.; Zhao, J. Codehow: Effective code search based on api understanding and extended boolean model (e). In Proceedings of the 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), Lincoln, NE, USA, 9–13 November 2015; pp. 260–270. [Google Scholar]
- Ye, X.; Bunescu, R.; Liu, C. Learning to rank relevant files for bug reports using domain knowledge. In Proceedings of the 22nd ACM Sigsoft International Symposium on Foundations of Software Engineering, Hong Kong, China, 16–21 November 2014; pp. 689–699. [Google Scholar]
- Guo, J.; Cheng, J.; Cleland-Huang, J. Semantically enhanced software traceability using deep learning techniques. In Proceedings of the 2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE), Buenos Aires, Argentina, 20–28 May 2017; pp. 3–14. [Google Scholar]
- Zhao, G.; Huang, J. Deepsim: Deep learning code functional similarity. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Lake Buena Vista, FL, USA, 4–9 November 2018; pp. 141–151. [Google Scholar]
- Ahmed, M.; Samee, M.R.; Mercer, R.E. Improving tree-LSTM with tree attention. In Proceedings of the 2019 IEEE 13th International Conference on Semantic Computing (ICSC), Newport Beach, CA, USA, 30 January–1 February 2019; pp. 247–254. [Google Scholar]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R. Gated graph sequence neural networks. arXiv 2015, arXiv:1511.05493. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reasons for Failure | Proportions (%) | |
|---|---|---|
| 1 | Incomplete requirements | 13.1 |
| 2 | Lack of user engagement | 12.4 |
| 3 | Lack of resources | 10.6 |
| 4 | Unrealistic expectations | 9.9 |
| 5 | Lack of administrative support | 9.3 |
| 6 | Changes in the requirements specification | 8.7 |
| 7 | Lack of project plan | 8.1 |
| 8 | The user no longer needs | 7.5 |
| 9 | Lack of IT management | 6.2 |
| 10 | Technical error | 4.3 |
| 11 | other | 9.9 |
| Project Name | Requirement Number | Number of Source Files | Number of Traceability Links |
|---|---|---|---|
| archiva 1 | 174 | 750 | 3028 |
| cassandra 2 | 1992 | 2203 | 22,399 |
| derby 3 | 980 | 2849 | 14,736 |
| drools 4 | 654 | 4342 | 29,399 |
| errai 5 | 152 | 3815 | 2630 |
| flink 6 | 1177 | 5366 | 22,082 |
| groovy 7 | 736 | 1376 | 2693 |
| hbase 8 | 2169 | 3429 | 24,986 |
| hibernate 9 | 819 | 9178 | 23,542 |
| hive 10 | 1738 | 5544 | 15,468 |
| kafka 11 | 257 | 1564 | 3156 |
| keycloak 12 | 505 | 4343 | 21,820 |
| maven 13 | 357 | 966 | 2782 |
| railo 14 | 167 | 2788 | 1147 |
| spark 15 | 513 | 857 | 2338 |
| switchyard 16 | 334 | 2954 | 12,719 |
| teiid 17 | 768 | 2 269 | 23,941 |
| zookepper 18 | 229 | 603 | 2457 |
| total | 13,721 | 55,196 | 231,323 |
| Network Type | NBOW, RNN, CNN, Self-Attention |
|---|---|
| Batch Size | 1000 |
| Learning Rate | 0.01 |
| Learning Rate Decay | 0.98 |
| Code Max Num Tokens | 200 |
| Query Max Num Tokens | 30 |
| Dropout Keep Rate | 0.9 |
| Max Epoch | 500 |
| Optimizer | Adam |
| Project Name | NBOW | CNN | RNN | Self-Attention |
|---|---|---|---|---|
| archiva | 0.281 | 0.443 | 0.449 | 0.298 |
| cassandra | 0.419 | 0.384 | 0.411 | 0.416 |
| derby | 0.520 | 0.213 | 0.622 | 0.521 |
| drools | 0.325 | 0.255 | 0.312 | 0.334 |
| errai | 0.358 | 0.334 | 0.365 | 0.337 |
| flink | 0.349 | 0.333 | 0.343 | 0.340 |
| groovy | 0.736 | 0.727 | 0.709 | 0.743 |
| hbase | 0.398 | 0.381 | 0.380 | 0.382 |
| hibernate | 0.443 | 0.434 | 0.460 | 0.461 |
| hive | 0.419 | 0.401 | 0.392 | 0.410 |
| kafka | 0.367 | 0.333 | 0.396 | 0.343 |
| keycloak | 0.357 | 0.316 | 0.340 | 0.326 |
| maven | 0.485 | 0.434 | 0.509 | 0.481 |
| railo | 0.434 | 0.397 | 0.409 | 0.397 |
| spark | 0.598 | 0.476 | 0.538 | 0.554 |
| switchyard | 0.484 | 0.492 | 0.288 | 0.502 |
| teiid | 0.290 | 0.301 | 0.293 | 0.309 |
| zookepper | 0.480 | 0.481 | 0.459 | 0.479 |
| Project Name | NBOW | CNN | RNN | Self-Attention |
|---|---|---|---|---|
| archiva | 0.483 | 0.532 | 0.579 | 0.553 |
| cassandra | 0.543 | 0.540 | 0.531 | 0.546 |
| derby | 0.639 | 0.458 | 0.675 | 0.605 |
| drools | 0.480 | 0.419 | 0.427 | 0.452 |
| errai | 0.511 | 0.516 | 0.476 | 0.519 |
| flink | 0.487 | 0.461 | 0.487 | 0.502 |
| groovy | 0.793 | 0.768 | 0.788 | 0.768 |
| hbase | 0.516 | 0.511 | 0.518 | 0.523 |
| hibernate | 0.581 | 0.562 | 0.614 | 0.590 |
| hive | 0.562 | 0.552 | 0.544 | 0.536 |
| kafka | 0.503 | 0.514 | 0.504 | 0.527 |
| keycloak | 0.484 | 0.494 | 0.497 | 0.511 |
| maven | 0.595 | 0.570 | 0.611 | 0.604 |
| railo | 0.569 | 0.510 | 0.590 | 0.527 |
| spark | 0.700 | 0.614 | 0.633 | 0.682 |
| switchyard | 0.714 | 0.702 | 0.572 | 0.741 |
| teiid | 0.439 | 0.418 | 0.437 | 0.448 |
| zookepper | 0.621 | 0.609 | 0.586 | 0.640 |
| Project Name | NBOW | CNN | RNN | Self-Attention |
|---|---|---|---|---|
| archiva | 0.574 | 0.651 | 0.629 | 0.621 |
| cassandra | 0.620 | 0.630 | 0.617 | 0.636 |
| derby | 0.713 | 0.767 | 0.683 | 0.676 |
| drools | 0.544 | 0.548 | 0.526 | 0.550 |
| errai | 0.561 | 0.596 | 0.557 | 0.587 |
| flink | 0.578 | 0.572 | 0.579 | 0.599 |
| groovy | 0.812 | 0.800 | 0.821 | 0.799 |
| hbase | 0.604 | 0.595 | 0.594 | 0.610 |
| hibernate | 0.665 | 0.639 | 0.690 | 0.647 |
| hive | 0.638 | 0.625 | 0.620 | 0.625 |
| kafka | 0.610 | 0.625 | 0.593 | 0.670 |
| keycloak | 0.564 | 0.580 | 0.612 | 0.586 |
| maven | 0.677 | 0.647 | 0.688 | 0.662 |
| railo | 0.661 | 0.558 | 0.622 | 0.601 |
| spark | 0.735 | 0.701 | 0.700 | 0.720 |
| switchyard | 0.822 | 0.740 | 0.701 | 0.838 |
| teiid | 0.517 | 0.499 | 0.533 | 0.599 |
| zookepper | 0.683 | 0.692 | 0.677 | 0.723 |
| Projects Name | RCT [Self-Attention] | LSA | BM25 | VSM | TraceNN | Poirot (PN) |
|---|---|---|---|---|---|---|
| archiva | 0.621 | 0.154 | 0.102 | - | 0.374 | 0.201 |
| cassandra | 0.636 | 0.234 | 0.070 | - | 0.432 | 0.181 |
| derby | 0.676 | 0.247 | - | - | 0.411 | 0.112 |
| drools | 0.550 | 0.188 | - | - | 0.387 | 0.231 |
| errai | 0.587 | 0.191 | 0.128 | - | 0.365 | 0.215 |
| flink | 0.599 | 0.188 | 0.166 | - | 0.401 | 0.224 |
| groovy | 0.799 | 0.312 | 0.074 | - | 0.525 | 0.281 |
| hbase | 0.610 | 0.171 | - | - | 0.372 | 0.264 |
| hibernate | 0.647 | 0.203 | - | - | 0.390 | 0.275 |
| hive | 0.625 | 0.295 | - | - | 0.501 | 0.223 |
| kafka | 0.670 | 0.193 | - | 0.149 | 0.421 | 0.301 |
| keycloak | 0.586 | 0.231 | 0.115 | - | 0.347 | 0.211 |
| maven | 0.662 | 0.345 | 0.155 | - | 0.476 | 0.292 |
| railo | 0.601 | 0.205 | 0.101 | - | 0.365 | 0.177 |
| spark | 0.720 | 0.379 | 0.196 | - | 0.545 | 0.286 |
| switchyard | 0.838 | 0.394 | - | - | 0.582 | 0.216 |
| teiid | 0.599 | 0.210 | 0.165 | - | 0.388 | 0.257 |
| zookepper | 0.723 | 0.401 | 0.089 | - | 0.491 | 0.208 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, P.; Yang, L.; Wang, Y.; Jin, D.; Gong, Y. Constructing Traceability Links between Software Requirements and Source Code Based on Neural Networks. Mathematics 2023, 11, 315. https://doi.org/10.3390/math11020315
Dai P, Yang L, Wang Y, Jin D, Gong Y. Constructing Traceability Links between Software Requirements and Source Code Based on Neural Networks. Mathematics. 2023; 11(2):315. https://doi.org/10.3390/math11020315
Chicago/Turabian StyleDai, Peng, Li Yang, Yawen Wang, Dahai Jin, and Yunzhan Gong. 2023. "Constructing Traceability Links between Software Requirements and Source Code Based on Neural Networks" Mathematics 11, no. 2: 315. https://doi.org/10.3390/math11020315