
Scrambling Reports: New Estimators for Estimating the Population Mean of Sensitive Variables

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
Proposed RR Scrambling Procedure Using SRSWR
- (i)
- , which is an estimator of the population mean of Y.
- (ii)
- , which is the variance of the estimator.
- (iii)
- .
- (iv)
- is an estimator of the variance, where , and .
3. Results
3.1. Simulation with Data of Illicit Crops in Guerrero, Mexico
3.2. Simulation with Data about First Sexual Intercourse
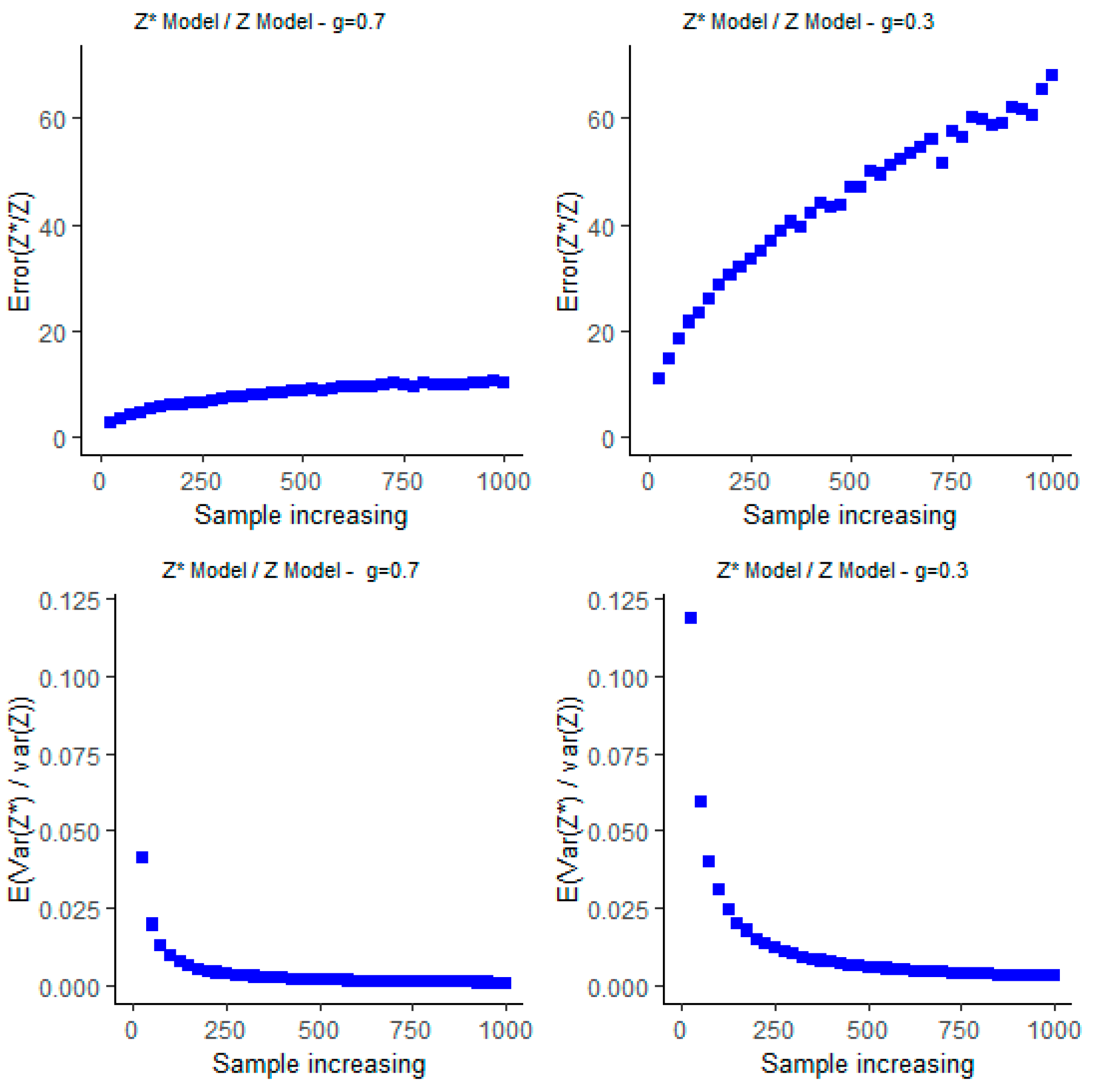
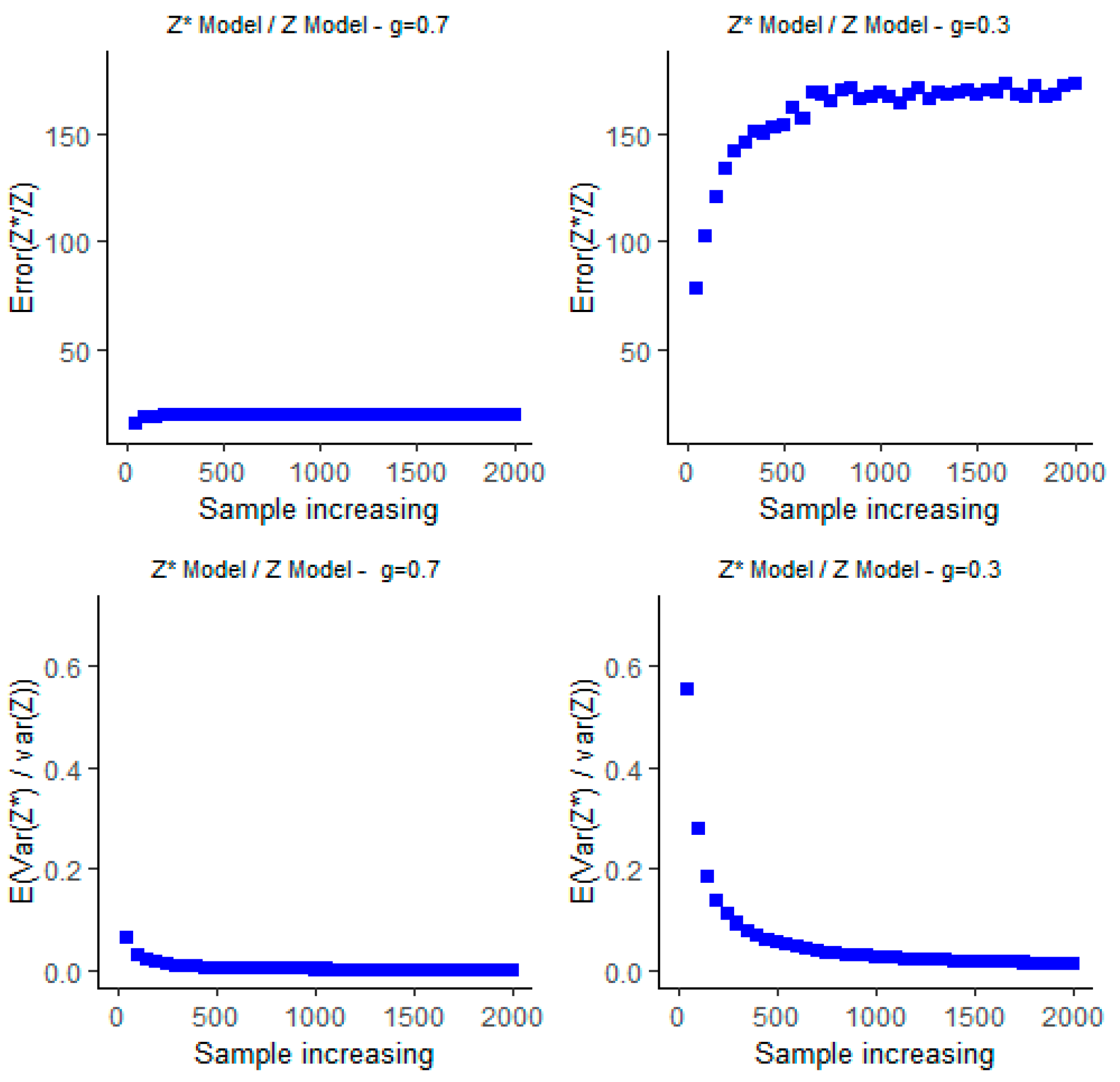
3.3. Graphical Simulation
4. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jones, E.E.; Sigall, H. The bogus pipeline: A new paradigm for measuring affect and attitude. Psychol. Bull. 1971, 76, 349–364. [Google Scholar] [CrossRef] [Green Version]
- Raghavarao, D.; Federer, W.T. Block Total Response as an Alternative to the Randomized Response Method in Surveys. J. R. Stat Soc. Ser. B 1979, 41, 40–45. [Google Scholar] [CrossRef] [Green Version]
- Gupta, S.; Thornton, B. Circumventing Social Desirability Response Bias in Personal Interview Surveys. Am. J. Math. Manag. Sci. 2002, 22, 369–383. [Google Scholar] [CrossRef]
- Warner, S.L. Randomized response: A survey technique for eliminating evasive answer bias. J. Am. Stat. Assoc. 1965, 60, 63–69. [Google Scholar] [CrossRef] [PubMed]
- Bahadivand, S.; Doosti-Irani, A.; Karami, M. Prevalence of high-risk behaviors in reproductive age women in Alborz province in 2019 using unmatched count technique. BMC Women’s Health 2020, 20, 186. [Google Scholar] [CrossRef] [PubMed]
- Greenberg, B.G.; Kuebler, R.R.J.; Abernathy, J.R.; Horvitz, D.G. Application of the Randomized Response Technique in Obtaining Quantitative Data. J. Am. Stat. Assoc. 1971, 66, 243–250. [Google Scholar] [CrossRef]
- Eriksson, S.A. A new model for randomized response. Int. Stat. Rev. 1973, 41, 40–43. [Google Scholar] [CrossRef]
- Huang, K.C. Estimation of sensitive characteristics using optional randomized technique. Qual. Quant. 2008, 42, 679–686. [Google Scholar] [CrossRef]
- Bouza, C.N. Ranked set sampling and randomized response procedures for estimating the mean of a sensitive quantitative character. Metrika 2009, 70, 267–277. [Google Scholar] [CrossRef]
- Arnab, R. Optional randomized response techniques for quantitative characteristics. Commun. Stat. Theory Methods 2018, 48, 4154–4170. [Google Scholar] [CrossRef]
- Singh, H.P.; Gorey, S. On Two Stage Optional Randomized Response Model. Elixir Stat. 2018, 123C, 51963–51987. [Google Scholar]
- Hussain, Z.; Shahid, M.I. Improved Randomized Response in Optional Scrambling Models. J. Stat. Theory Pract. 2019, 18, 351–360. [Google Scholar] [CrossRef] [Green Version]
- Narjis, G.; Shabbir, J.; Onyango, R. Partial Randomized Response Model for Simultaneous Estimation of Means of Two Sensitive Variables. Math. Probl. Eng. 2022, 2022, 1–13. [Google Scholar] [CrossRef]
- Bouza-Herrera, C.N.; Juárez-Moreno, P.O.; Santiago-Moreno, A.; Sautto-Vallejo, J.M. A Two-Stage Scrambling Procedure: Simple and Stratified Random Sampling. An Evaluation of COVID 19’s data in Mexico. Investig. Oper. 2022, 43, 421–430. [Google Scholar]
- Hussain, Z.; Shakeel, S.; Cheema, S.A. Estimation of stigmatized population total: A new additive quantitative randomized response model. Commun. Stat. Theory Methods 2022, 51, 8741–8753. [Google Scholar] [CrossRef]
- Azeem, M.; Ali, S. A neutral comparative analysis of additive, multiplicative, and mixed quantitative randomized response models. PLoS ONE 2023, 18, 4. [Google Scholar] [CrossRef]
- Murtaza, M.; Singh, S.; Hussain, Z. Use of correlated scrambling variables in quantitative randomized response technique. Biom. J. 2020, 63, 134–147. [Google Scholar] [CrossRef]
- Chong, A.; Chu, A.; So, M.; Chung, R. Asking Sensitive Questions Using the Randomized Response Approach in Public Health Research: An Empirical Study on the Factors of Illegal Waste Disposal. Int. J. Environ. Res. Public Health 2019, 16, 970. [Google Scholar] [CrossRef] [Green Version]
- Perri, P.F.; Cobo-Rodríguez, B.; Rueda-García, M. A mixed-mode sensitive research on cannabis use and sexual addiction: Improving self-reporting by means of indirect questioning techniques. Qual. Quant. 2018, 52, 1593–1611. [Google Scholar] [CrossRef]
- Kirtadze, I.; Otiashvili, D.; Tabatadze, M.; Vardanashvili, I.; Sturua, L.; Zabransky, T.; Anthony, J.C. Republic of Georgia estimates for prevalence of drug use: Randomized response technique suggest under-estimation. Drug Alcohol. Depend. 2018, 187, 300–304. [Google Scholar] [CrossRef]
- Saleem, I.; Sanaullah, A.; Koyuncu, N. Estimation of Mean of a Sensitive Quantitative Variable in Complex Survey: Improved Estimator and Scrambled Randomized Response Model. J. Sci. 2019, 32, 1021–1043. [Google Scholar]
- México Unido Contra La Delincuencia. Datos Abiertos Sobre Acciones Antidrogas. Available online: https://www.mucd.org.mx (accessed on 19 January 2023).
- De Salud, S. Encuesta Nacional de Salud y Nutrición. Available online: https://www.ensanut.insp.mx (accessed on 19 January 2023).
- Epstein, M.; Bailey, J.; Manhart, L.; Hill, K.; Hawkins, D.; Haggerty, K.; Catalano, R. Understanding the Link Between Early Sexual Initiation and Sexually Transmitted Infection: Test and Replication in Two Longitudinal Studies. J. Adolesc. Health. 2014, 54, 435–441. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brener, N.D.; Eaton, D.K.; Kann, L. The Association of Survey Setting and Mode with Self-Reported Health Risk Behaviors Among High School Students. Public. Opin. Q. 2014, 70, 354–374. [Google Scholar] [CrossRef] [Green Version]
- Singh, S. Advanced Sampling Theory with Application, 1st ed.; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2003. [Google Scholar]
- México, Monitoreo de Plantíos de Amapola 2019–2020. Available online: https://www.unodc.org (accessed on 23 January 2023).
- Candia, R.; Caiozzi, G. Intervalos de confianza. Rev. Méd. Chile 2005, 133, 1111–1115. [Google Scholar] [CrossRef] [PubMed] [Green Version]



{kind=link}
{kind=link}
| Z* | Z | |||
|---|---|---|---|---|
| g = 0.7 | g = 0.3 | g = 0.7 | g = 0.3 | |
| 57.53 | 157.9 | 33.23 | 32.85 | |
| = | 6.73% | 3.35% | 185.5% | 129% |
| ACP = | 1% | 0% | 100% | 100% |
| AL = | 15.33 | 20.77 | 241.8 | 181.54 |
| 15.64 | 28.55 | 3881 | 2216.5 | |
| 0.639 | 3.489 | 0.097 | 0.109 | |
| g = 0.7 | g = 0.3 | |
|---|---|---|
| 6.587 | 32.009 | |
| 0.004 | 0.01 |
| Z* | Z | |||
|---|---|---|---|---|
| g = 0.7 | g = 0.3 | g = 0.7 | g = 0.3 | |
| 29.03 | 77.34 | 17.56 | 17.77 | |
| = | 0.88% | 1.09% | 26.89% | 29.85% |
| ACP = | 0% | 0% | 100% | 100% |
| AL = | 1.005 | 3.331 | 18.51 | 20.79 |
| 0.065 | 0.722 | 22.32 | 28.15 | |
| 0.601 | 3.268 | 0.0311 | 0.0195 | |
| g = 0.7 | g = 0.3 | |
|---|---|---|
| 19.324 | 167.589 | |
| 0.0029 | 0.0025 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Juárez-Moreno, P.O.; Santiago-Moreno, A.; Sautto-Vallejo, J.M.; Bouza-Herrera, C.N. Scrambling Reports: New Estimators for Estimating the Population Mean of Sensitive Variables. Mathematics 2023, 11, 2572. https://doi.org/10.3390/math11112572
Juárez-Moreno PO, Santiago-Moreno A, Sautto-Vallejo JM, Bouza-Herrera CN. Scrambling Reports: New Estimators for Estimating the Population Mean of Sensitive Variables. Mathematics. 2023; 11(11):2572. https://doi.org/10.3390/math11112572
Chicago/Turabian StyleJuárez-Moreno, Pablo O., Agustín Santiago-Moreno, José M. Sautto-Vallejo, and Carlos N. Bouza-Herrera. 2023. "Scrambling Reports: New Estimators for Estimating the Population Mean of Sensitive Variables" Mathematics 11, no. 11: 2572. https://doi.org/10.3390/math11112572