
A Safe and Efficient Lane Change Decision-Making Strategy of Autonomous Driving Based on Deep Reinforcement Learning


Abstract
:1. Introduction
- (1)
- For AD tasks such as lane-changing in highway scenarios, the DRL model is integrated to optimize the continuous actions into the low-level vehicle control module, and a dual-computer co-simulation platform is built for verification.
- (2)
- The Safety Rules module and the Safety Prediction module are both deployed explicitly and implicitly to impose some constraints on the output actions of the AV to enhance driving safety. During the agent training process, the trauma memory method is adopted to learn safer driving behavior when encountering emergencies in highway scenarios. Moreover, dynamic potential-based reward shaping is also implemented to improve the learning efficiency of the agent.
2. Related Work
3. Background
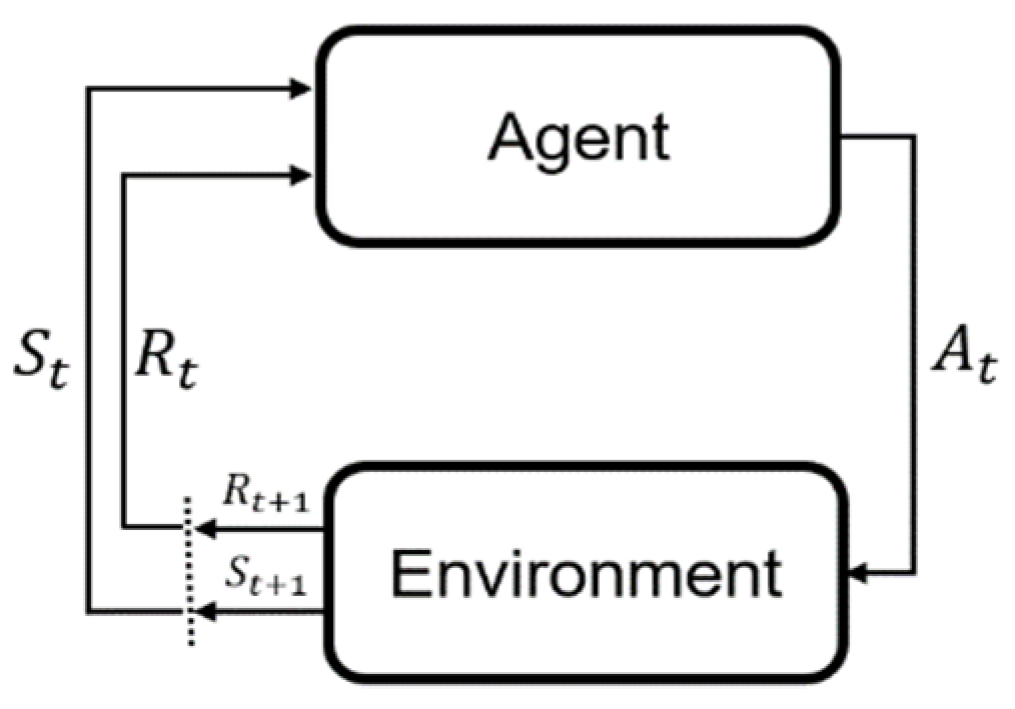
3.1. Deep Reinforcement Learning
3.2. DDPG Algorithm
4. Problem Formulation
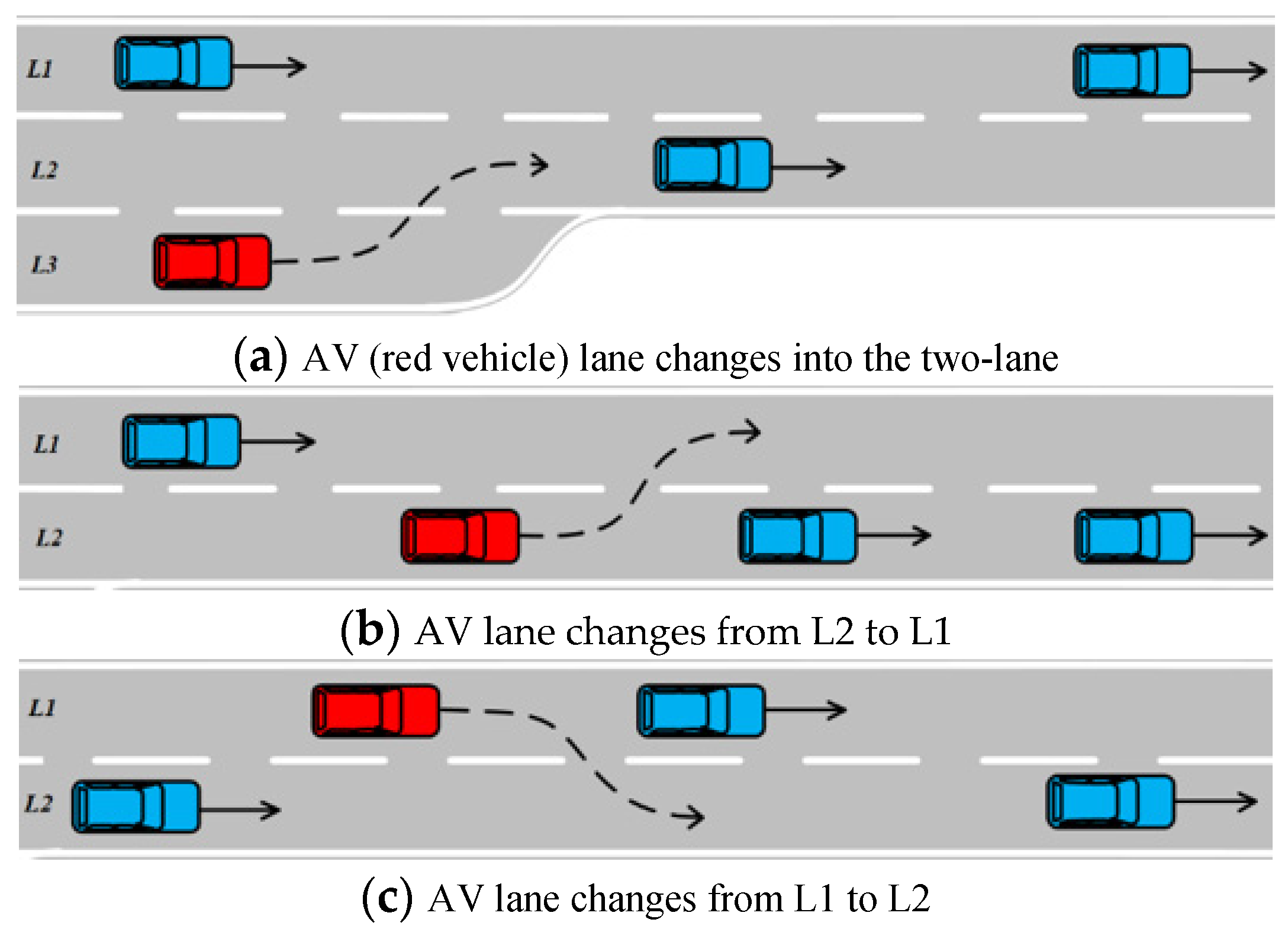
4.1. Lane-Changing Task
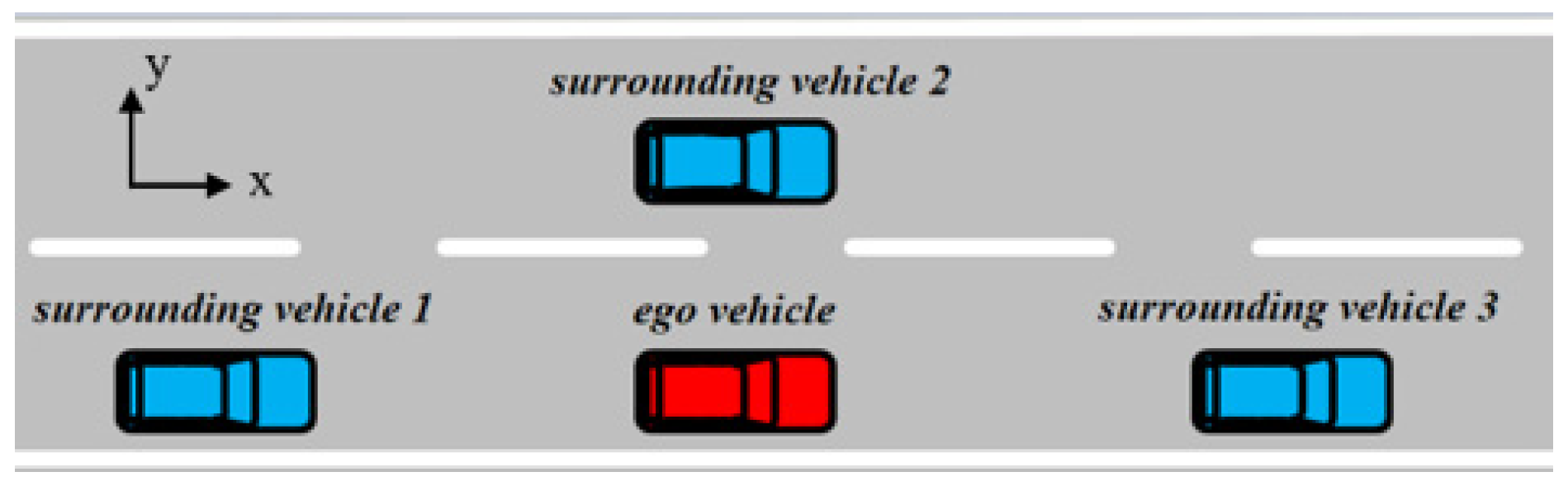
4.2. State and Action Space
4.3. Reward Function
- (1)
- Efficiency-related reward : This contributor aims to allow the AV to drive as fast as possible if permitted until the desired velocity is maintained. Simultaneously, if the vehicle’s departure from the lane centerline becomes larger, more penalties should be granted. For these reasons, the efficiency-related reward can be formulated bywhere are the weighting parameters and v and represent the real velocity and the desired velocity of the AV, respectively.
- (2)
- Comfort-related reward : This dedicator intends to enable the learning of smoother and more comfortable driving behavior by reducing the comfort deterioration due to excessive sudden changes in the vehicle state:where is the acceleration; is the maximum comfortable acceleration; is the derivative of acceleration (also called Jerk [45]), = /; and is the maximum Jerk. Here, we let = 5 m/s2 and = 2 m/s3. The third term in limits the rate of change of the compass heading angle change to control the yaw motion caused by large angle changes in the driving direction.
- (3)
- Safety-related reward : To ensure driving safety, the AV should learn to keep a safe distance from the leading vehicle in the same lane in the longitudinal direction (x-direction) to reduce collision. Thus, the safety-related reward can be adopted by
- (4)
- Terminal-related reward : When the AV meets the required conditions during the simulation, the whole process will be terminated. We divid the termination requirements into two parts: positive reward value and negative reward value (for penalty use), which can be represented bywhere , is set to have large positive values. If the AV collides or leaves the lane, a larger negative penalty will be utilized. Instead, whenever it successfully completes the expected LC task and drives to the desired target position, a larger positive reward is deployed.
5. Methodology
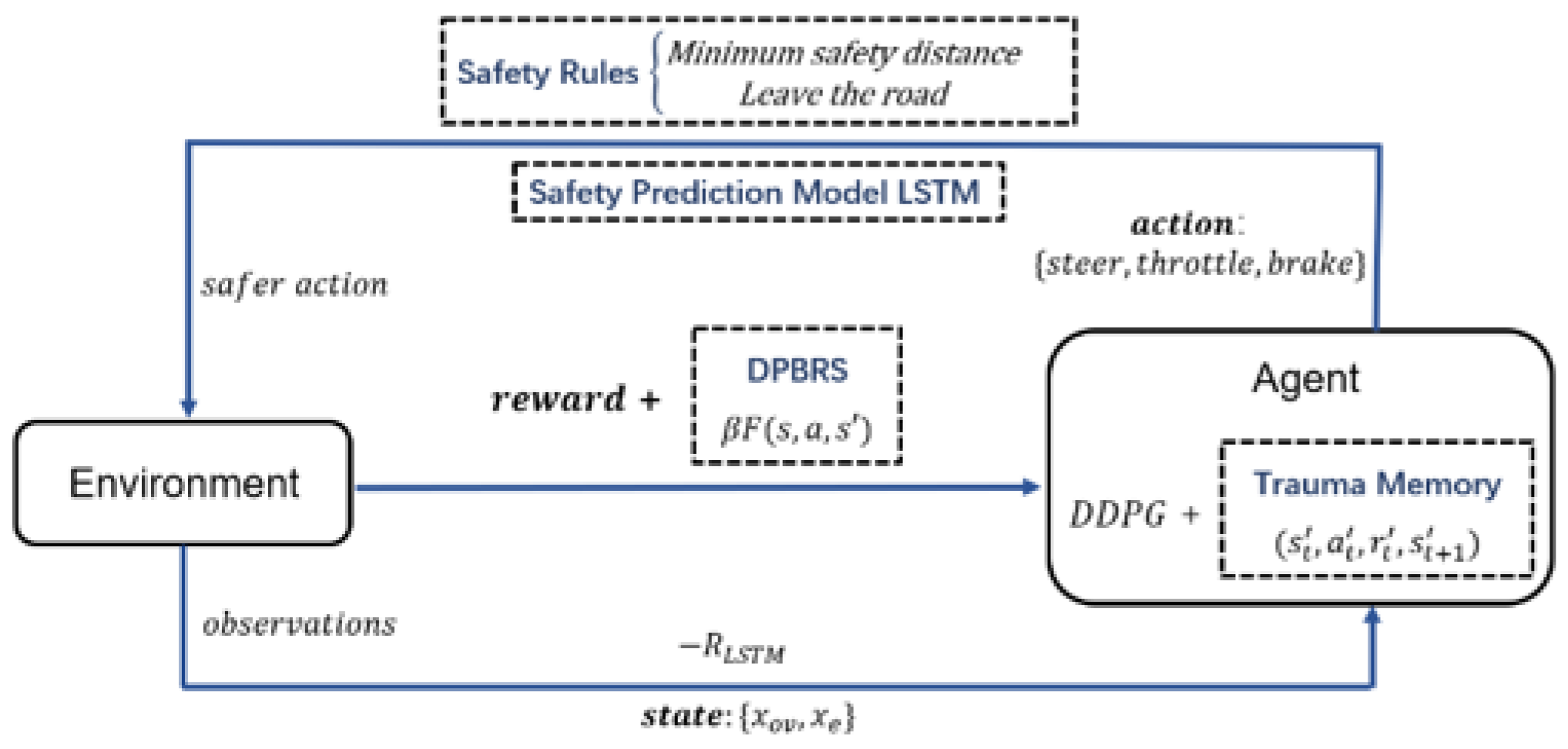
5.1. Decision-Making Strategy Algorithm Architecture
5.2. Safety Enhancement
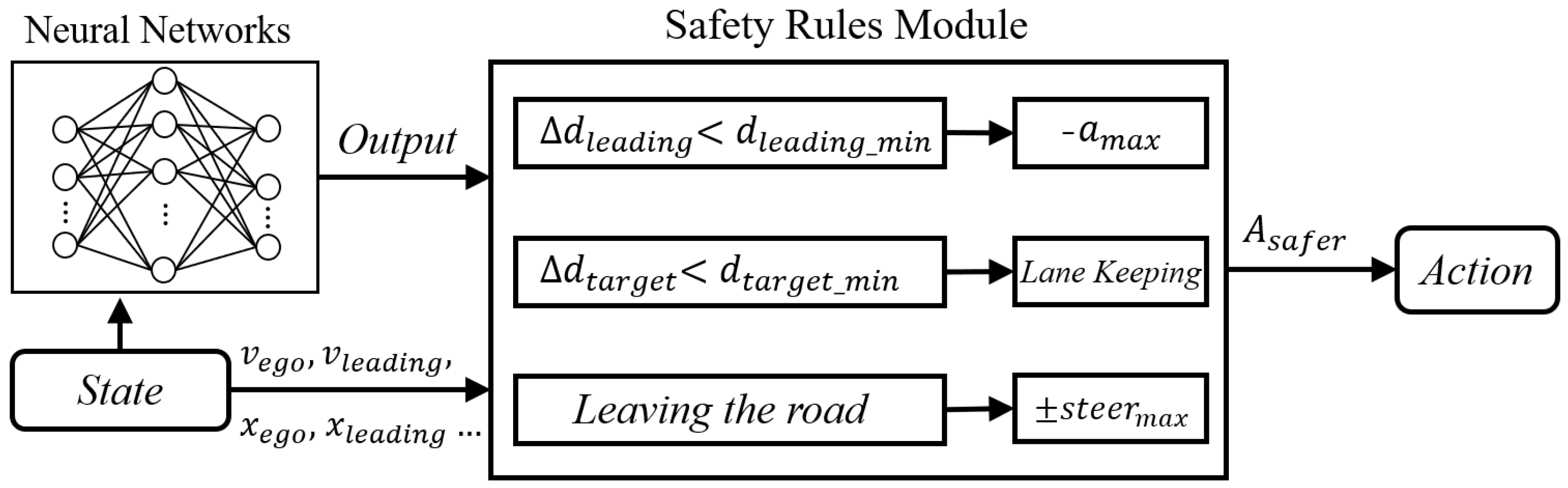
5.2.1. Safety Rules (SR) + Safety Prediction (SP) Module
- (1)
- The minimum safe distance from the leading vehicle : When the speed of the AV exceeds that of the leading vehicle driving in the same lane and the minimum safety distance between the two vehicles is breached, it is highly probable that a collision will occur if a certain deceleration maneuver is not performed. To avoid this, the minimum safe time interval can be introduced to satisfy:where v and represent the speeds of the AV and the leading vehicle in the same lane, respectively, and implies the maximum deceleration of the AV. Correspondingly, the minimum safety distance should also satisfy:where , represent the horizontal coordinates of the leading vehicle in the same lane and the AV, respectively. When the relative distance between the two vehicles is less than the minimum safe distance , the AV will attain the maximum deceleration . Otherwise, the AV will directly execute the throttle and brake pressure output by the neural network to accelerate and decelerate.
- (2)
- The minimum safe distance from the vehicle in the target lane : When the AV attempts to change lanes, it is essential to determine whether the relative distance between itself and the front vehicle or the behind vehicle in the target lane meets the minimum safe distance requirement. Similarly, the minimum safe time interval between the AV and the front and behind vehicles in the target lane are and , respectively:where , represent the speed of the front and behind vehicles in the target lane, respectively. Correspondingly, the minimum safe distance between the vehicle in the target lane and the AV can be described as:where , represent the horizontal coordinates of the front and behind vehicles in the target lane, respectively. If the distance between the vehicle in the target lane and the AV is less than the minimum safety distance , the steering wheel angle is maintained for lane keeping. Otherwise, the AV will perform lane changing actions according to the steering wheel angle output by the neural network.
- (3)
- Avoid leaving the road: Besides collision, leaving the road is also a dangerous driving behavior in real traffic scenarios. When the AV is about to leave the road, the maximum reverse angle is exploited to keep it driving in the same lane at the same speed. Inherently, similar operations will be implemented when the AV is in the opposite lane. The corresponding formula is described as follows:where , represent the minimum and maximum steering wheel angles taken by the AV when it is about to leave the left and right road lanes, respectively. According to the description of the MDP model action space, and are equal to −20 degrees and 20 degrees.
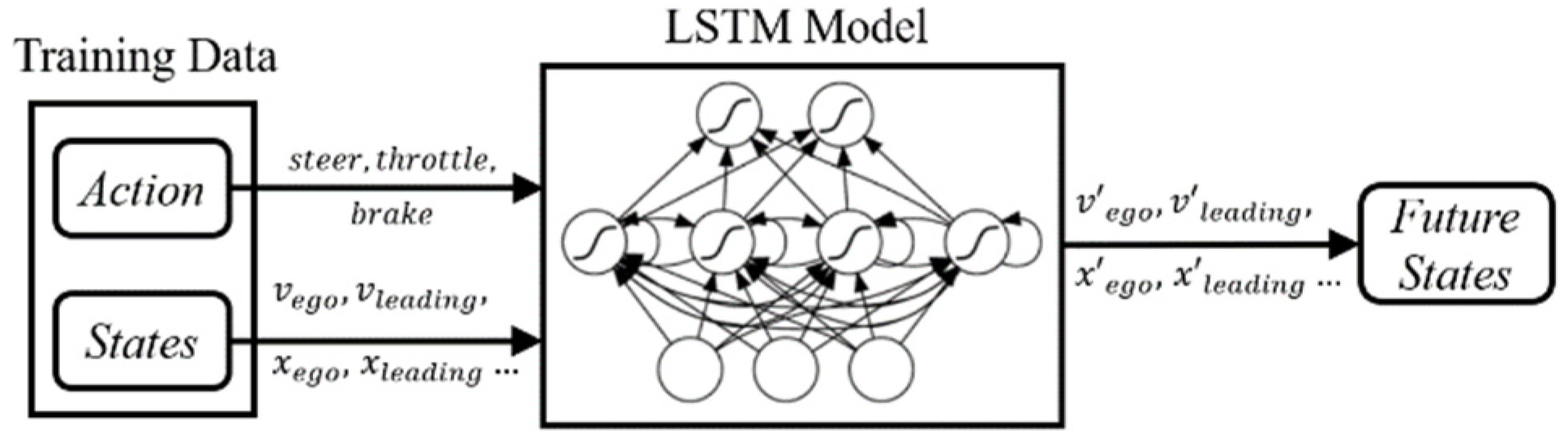
- (1)
- LSTM training: We utilize the state–action data of the RL model in 3000 rounds with the SR module in the test set as the training data of the LSTM prediction model in Figure 7. The state–action pairs in the last five simulation steps are employed as the input of the LSTM prediction model, and its output predicts the state vectors of the next five steps.
- (2)
- Judgment of the future states: If there are any dangerous states (collision or offroad) in the next five steps predicted by the LSTM prediction model, we store the state information of the next step in the TM and offer the reward function a larger penalty value of
5.2.2. Trauma Memory (TM)
5.3. Efficiency Improvement
| Algorithm 1. DSSTD Algorithm. |
| 1: Initialize the weights and 2: Initialize the weights and 3: Initialize buffers:, 4: For episode = 1, E do 5: Initialize noise value N 6: Obtain state–action information 7: Receive initial state s1 8: For t = 1, T do 9: Select the output action 10: If the conditions are met 11: Execute action and obtain reward and next state 12: Store transitions and in and 13: Use LSTM to predict , , …, 14: If conditions are met ← 15: Store transition in 16: Sample minibatchs and from and 17: Calculate loss function and Q value 18: Update critic network 19: Update output strategy 20: Update AC networks 21: end for 22: end for 23: end while |
6. Experimental Evaluation
6.1. Simulation Setup
6.2. Initial Scenario and Surrounding Vehicles Driving Model
6.3. Training Results
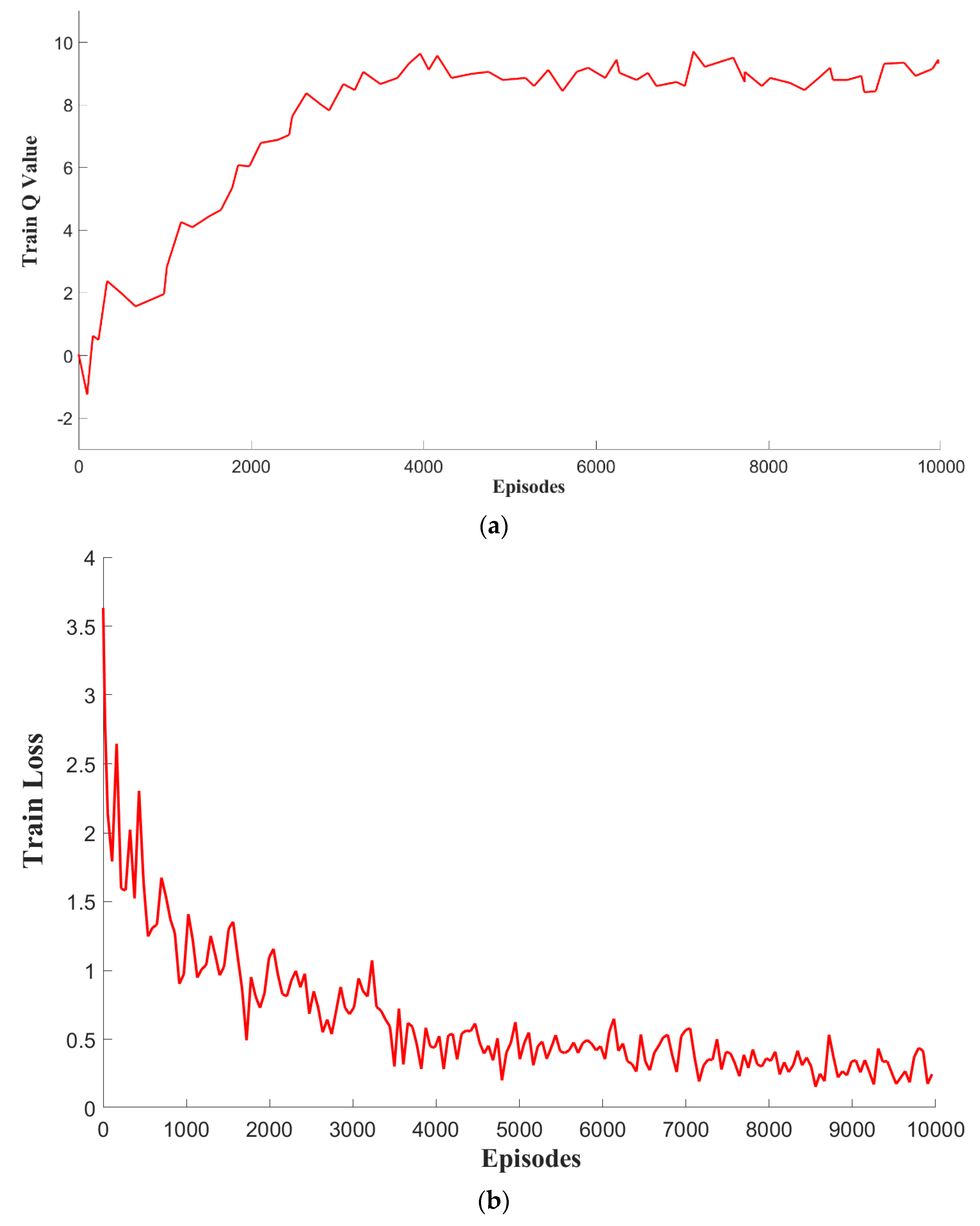
- (1)
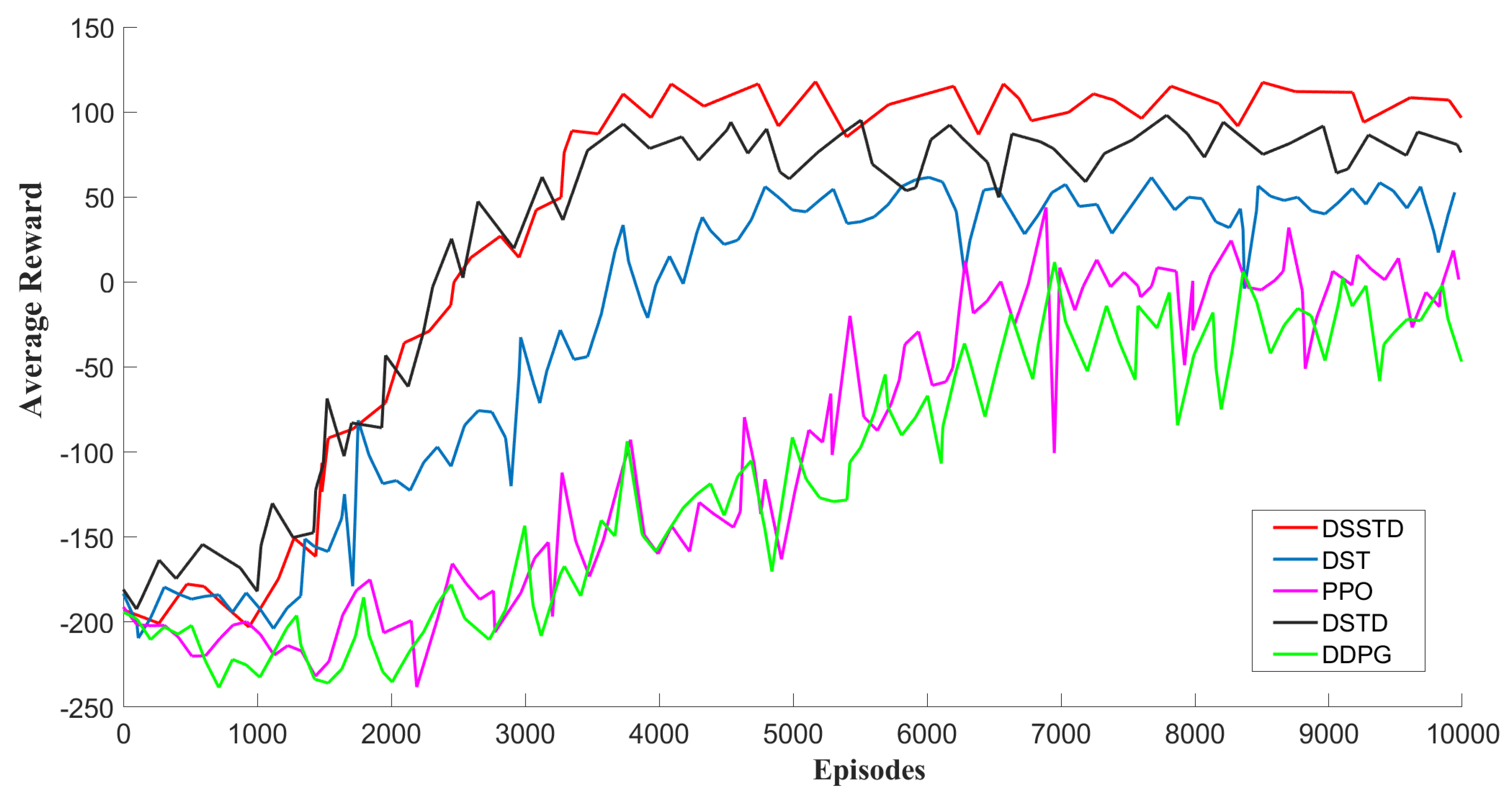
- Evaluation of the proposed DRL model: To evaluate the stability of the proposed DRL model, we investigated the average Q value of the Actor network and the loss value of the Critic network in the DSSTD model during training. As shown in Figure 10a, the average Q value finally converged to the maximum value (9.86) around 4000 episodes. It could also be observed from Figure 10b that the loss values converged to the minimum value (0.33) around 4000 episodes. The result of the above converging phenomenon was well consistent with the stability performance of the DSSTD model, as shown in Figure 11. This demonstrated that our DSSTD model had good stability, and furthermore, the trained Actor network could output the action with the largest expected Q value and attain considerable cumulative returns. It is necessary to explain that the curve often experiences fluctuation in a smaller range after it converges, which could also be found on other studies [22].
- (2)
- Discussion on reward function: From Figure 11, it can be seen that as the training simulation progressed, the cumulative average rewards of the traditional DDPG or PPO algorithms gradually increased and eventually converged to be stable around 8000 episodes. If more training episodes are available, the traditional RL rewards tend to have fewer fluctuations after convergence, but may experience the divergence problem. Prior to being stabilized, they are prone to relatively large fluctuations around 7000 episodes and their convergence speeds were almost the same. The fact that a higher reward of PPO is granted indicates that its driving strategy outperformed traditional DDPG in safety and speed.
6.4. Test Result
- (1)
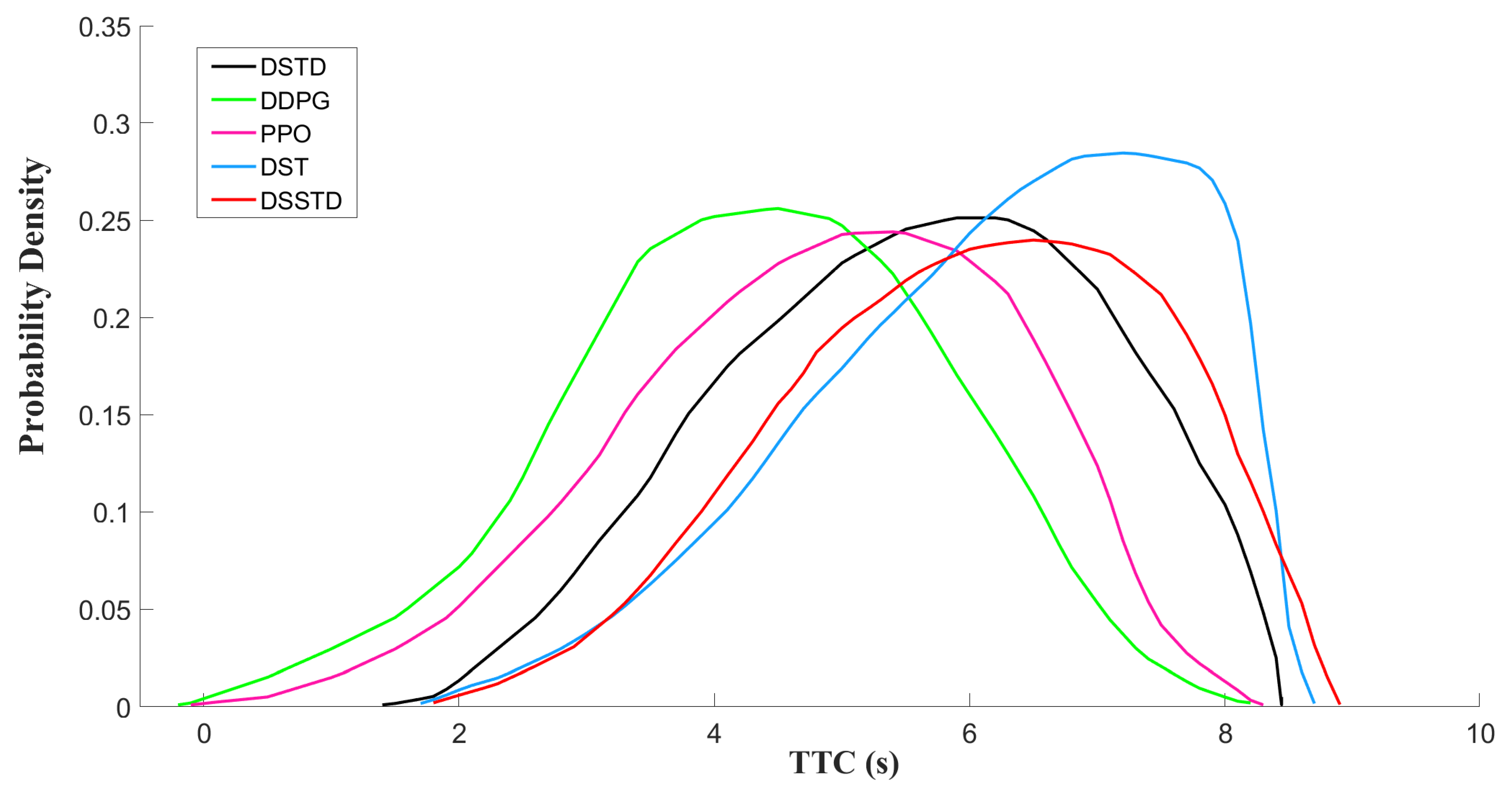
- Safety: Here, four indicators including LC success rate, collision or off-road counts, the minimum distance to the leading vehicle, and the TTC, were utilized to evaluate the safety of AV during LC in the test round.
- (2)
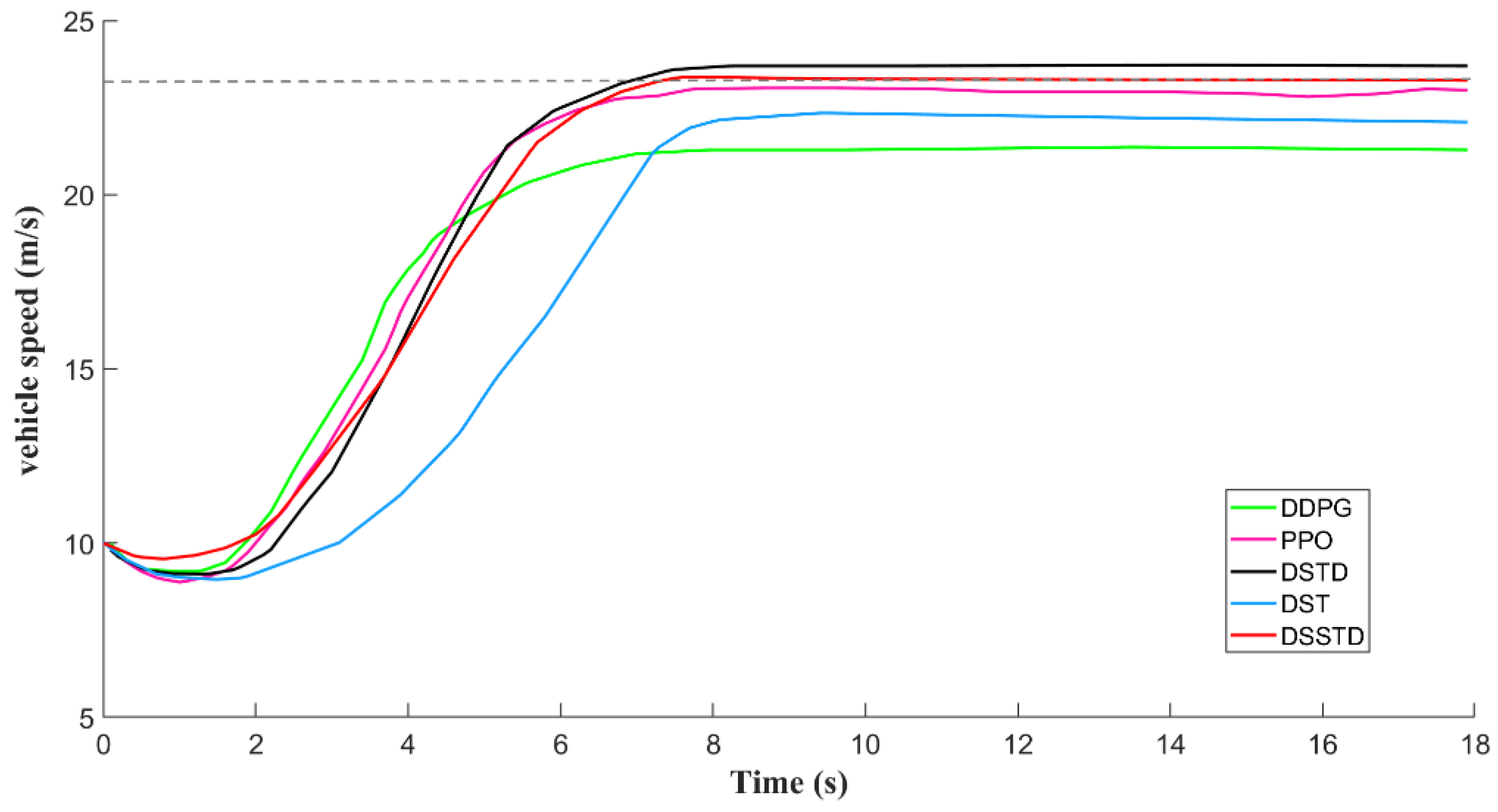
- Driving efficiency: The test rounds with an initial speed of 10 m/s were used and the results of changes in their vehicle speeds during testing are shown in Figure 13. We regarded the average speed of the ego vehicle as an indicator to evaluate driving efficiency. The gray dotted line in Figure 13 represents the standard line for the desired speed (also the optimal speed). We hope that the average speed of the ego vehicle can reach the set desired speed value of = 23.0 m/s as quickly as possible, and maintain this stable speed. Among the five strategies, it can be seen that the speed of the traditional DDPG behaved more fluctuant, and finally stabilized at about 22 m/s with the lowest driving efficiency. Compared to PPO, the driving efficiency of PPO was slightly higher, and the speed fluctuation was smaller. This shows that the speed reward item of the traditional algorithm did not finally converge to the optimal value during the training process, resulting in a difference between the average speed and the desired speed.
- (3)
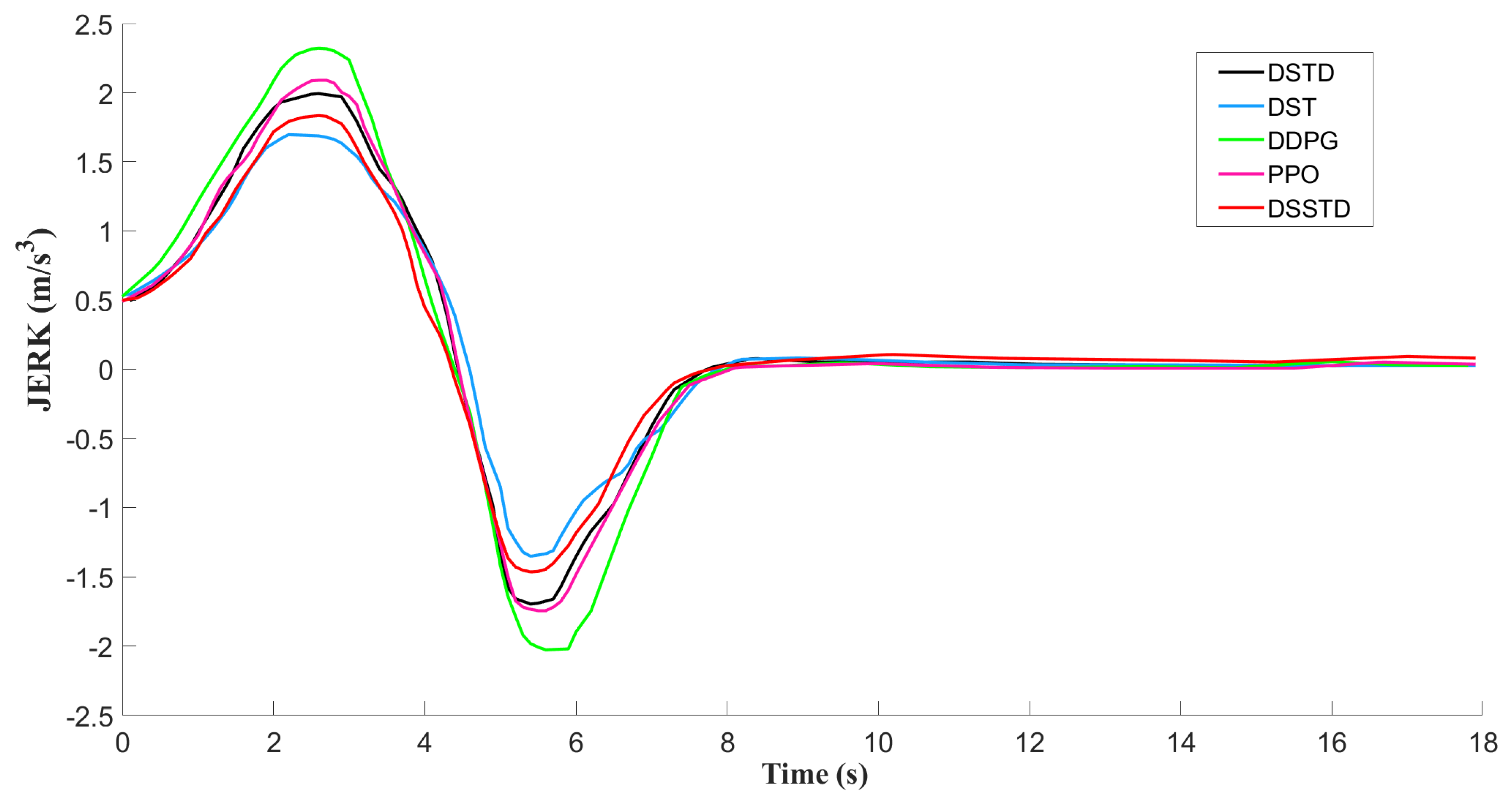
- Comfort: For evaluating the comfort of the AV, we will mainly consider the Jerk value, which is defined as the time rate of a change of acceleration. It is clear that a large Jerk value implies a great decrease in driving comfort. According to the reward function described in Section 4, the maximum Jerk was set as = 2 m/s3. The result of changes in the Jerk values of the five algorithms is shown in Figure 14. The maximum Jerk value of the traditional DDPG was about 2.3 m/s3 slightly higher than the maximum limit. This indicates that the agent cannot fully learn under the specification of the comfort-related reward. The results of PPO and DSTD were both around 2 m/s3. In contrast, that of the DSSTD was 1.81 m/s3, and for DST, it was about 1.65 m/s3, which was much smaller than the other four. Although DST and DSSTD can both have steady and smooth acceleration for comfort evaluation, when considering the testing result of driving efficiency together, the DSSTD was proven to have superior driving performance in agent training.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Health Organization. Global Status Report on Road Safety 2018: Summary; World Health Organization: Geneva, Switzerland, 2018. [Google Scholar]
- National Highway Traffic Safety Administration (NHTSA). 2016 Fatal Motor Vehicle Crashes. 2017. Available online: https://www.nhtsa.gov/press-releases/usdot-releases-2016-fatal-traffic-crash-data (accessed on 27 March 2021).
- Eno Center for Transportation. Preparing a Nation for Autonomous Vehicles: Opportunities, Barriers and Policy Recommendations. 2013. Available online: http://www.enotrans.org/wp-content/uploads/wpsc/downloadables/AV-paper.pdf (accessed on 15 January 2022).
- Thorpe, C.; Herbert, M.; Kanade, T.; Shafter, S. Toward autonomous driving: The cmu navlab. ii. architecture and systems. IEEE Expert 1991, 6, 44–52. [Google Scholar] [CrossRef]
- Buehler, M.; Iagnemma, K.; Singh, S. (Eds.) The Darpa Urban Challenge: Autonomous Vehicles in City Traffic; Springer: Berlin, Germany, 2009. [Google Scholar]
- Zhang, M.; Li, N.; Girard, A.; Kolmanovsky, I. A finite state machine based automated driving controller and its stochastic optimization. In Proceedings of the ASME 2017 Dynamic Systems and Control Conference, Tysons, VA, USA, 11–13 October 2017. [Google Scholar]
- Li, N.; Chen, H.; Kolmanovsky, I.; Girard, A. An explicit decision tree approach for automated driving. In Proceedings of the ASME 2017 Dynamic Systems and Control Conference, Tysons, VA, USA, 11–13 October 2017. [Google Scholar]
- González, D.; Pérez, J.; Milanés, V. A Review of Motion Planning Techniques for Automated Vehicles. IEEE Trans. Int. Transp. Syst. 2015, 17, 1135–1145. [Google Scholar] [CrossRef]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Bojarski, M.; del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J. End to end learning for self-driving cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Perez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2021, 1–18. [Google Scholar] [CrossRef]
- Ronecker, M.P.; Zhu, Y. Deep q-network based decision making for autonomous driving. In Proceedings of the IEEE International Conference on Robotics and Automation Sciences, Montreal, QC, Canada, 20–24 May 2019; pp. 154–160. [Google Scholar]
- Min, K.; Kim, H.; Huh, K. Deep distributional reinforcement learning based high-level driving policy determination. IEEE Trans. Intell. Veh. 2019, 4, 416–424. [Google Scholar] [CrossRef]
- Fu, Y.; Li, C.; Yu, F.R.; Luan, T.H.; Zhang, Y. A decision making strategy for vehicle autonomous braking in emergency via deep reinforcement learning. IEEE Trans. Veh. Technol. 2020, 69, 5876–5888. [Google Scholar] [CrossRef]
- He, X.; Fei, C.; Liu, Y.; Yang, K.; Ji, X. Multi-objective Longitudinal Decision-making for Autonomous Electric Vehicle: A Entropy-constrained Reinforcement Learning Approach. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar]
- Chae, H.; Kang, C.M.; Kim, B.D.; Kim, J.; Chung, C.C.; Choi, J.W. Autonomous braking system via deep reinforcement learning. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Baheri, A.; Baheri, A.; Nageshrao, S.; Tseng, H.E.; Kolmanovsky, I.; Girard, A.; Filev, D. Deep Reinforcement Learning with Enhanced Safety for Autonomous Highway Driving. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 20–23 October 2020; pp. 1550–1555. [Google Scholar]
- Li, G.; Gomez, R.; Nakamura, K.; He, B. Human-centered reinforcement learning: A survey. IEEE Trans. Hum. Mach. Syst. 2019, 49, 337–349. [Google Scholar] [CrossRef]
- Wang, Z.; Taylor, M. Effective transfer via demonstrations in reinforcement learning: A preliminary study. In Proceedings of the 2016 AAAI Spring Symposia, Stanford University, Palo Alto, CA, USA, 21–23 March 2016. [Google Scholar]
- Trott, A.; Zheng, S.; Xiong, C.; Socher, R. Keeping your distance: Solving sparse reward tasks using self-balancing shaped rewards. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 10376–10386. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous Control with Deep Reinforcement Learning. 2015. Available online: http://arxiv.org/abs/1509.02971 (accessed on 15 January 2022).
- Ye, Y.; Zhang, X.; Sun, J. Automated vehicle’s behavior decision making using deep reinforcement learning and high-fidelity simulation environment. Transp. Res. C Emerg. Technol. 2019, 107, 155–170. [Google Scholar] [CrossRef] [Green Version]
- Liang, X.; Wang, T.; Yang, L.; Xing, E. Cirl: Controllable imitative reinforcement learning for vision-based self-driving. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 584–599. [Google Scholar]
- Wang, Q.; Zhuang, W.; Wang, L.; Ju, F. Lane Keeping Assist for an Autonomous Vehicle Based on Deep Reinforcement Learning. In Proceedings of the WCX SAE World Congress Experience, Detroit, MI, USA, 21–24 April 2020. [Google Scholar]
- Tang, Y. Towards Learning Multi-Agent Negotiations via Self-Play. 2019. Available online: https://arxiv.org/abs/2001.10208 (accessed on 15 January 2022).
- Karaduman, O.; Eren, H.; Kurum, H.; Celenk, M. Interactive risky behavior model for 3-car overtaking scenario using joint Bayesian network. In Proceedings of the 2013 IEEE Intelligent Vehicles Symposium (IV), Gold Coast, Australia, 23–26 June 2013; pp. 1279–1284. [Google Scholar]
- Bouton, M.; Nakhaei, A.; Fujimura, K.; Kochenderfer, M.J. Safe Reinforcement Learning with Scene Decomposition for Navigating Complex Urban Environments. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1469–1476. [Google Scholar]
- Wen, L.; Duan, J.; Li, S.E.; Xu, S.; Peng, H. Safe Reinforcement Learning for Autonomous Vehicles through Parallel Constrained Policy Optimization. 2020. Available online: https://arxiv.org/abs/2003.01303 (accessed on 15 January 2022).
- Kamran, D.; Lopez, C.F.; Lauer, M.; Stiller, C. Risk-Aware High-level Decisions for Automated Driving at Occluded Intersections with Reinforcement Learning. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 23 June 2020; pp. 1205–1212. [Google Scholar]
- Peng, H.; Du, B.; Liu, M.; Liu, M.; He, L. Dynamic graph convolutional network for long-term traffic flow prediction with reinforcement learning. Inf. Sci. 2021, 578, 401–416. [Google Scholar] [CrossRef]
- Buhet, T.; Wirbel, E.; Perrotton, X. Conditional vehicle trajectories prediction in carla urban environment. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Vasquez, R.; Farooq, B. Multi-Objective Autonomous Braking System using Naturalistic Dataset. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 4348–4353. [Google Scholar]
- Kohler, S.; Schreiner, B.; Ronalter, S.; Doll, K.; Zindler, K. Autonomous evasive maneuvers triggered by infrastructure-based detection of pedestrian intentions. In Proceedings of the 2013 IEEE Intelligent Vehicles Symposium (IV), Gold Coast, Australia, 23–26 June 2013; pp. 519–526. [Google Scholar]
- Brannstrom, M.; Coelingh, E.; Sjoberg, J. Model-based threat assessment for avoiding arbitrary vehicle collisions. IEEE Trans. Intell. Transp. Syst. 2010, 11, 658–669. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529. [Google Scholar] [CrossRef] [PubMed]
- Okudo, T.; Yamada, S. Subgoal-based Reward Shaping to Improve Efficiency in Reinforcement Learning. IEEE Access 2021, 9, 97557–97568. [Google Scholar] [CrossRef]
- Marom, O.; Rosman, B.S. Belief reward shaping in reinforcement learning. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; AAAI Press: Palo Alto, CA, USA; pp. 3762–3769. [Google Scholar]
- Demir, A.; Cilden, E.; Polat, F. Landmark based reward shaping in reinforcement learning with hidden states. In Proceedings of the 18th International Conference on Autonomous Agents and Multi Agent Systems, Montreal, QC, Canada, 13–17 May 2019; pp. 1922–1924. [Google Scholar]
- Paul, S.; Baar, J.V.; Roy-Chowdhury, A.K. Learning from trajectories via subgoal discovery. Adv. Neural Inf. Processing Syst. 2019, 32, 8411–8421. [Google Scholar]
- Hoel, C.J.; Driggs-Campbell, K.; Wolff, K.; Laine, L.; Kochenderfer, M.J. Combining Planning and Deep Reinforcement Learning in Tactical Decision Making for Autonomous Driving. IEEE Trans. Int. Veh. 2020, 5, 294–305. [Google Scholar] [CrossRef] [Green Version]
- Hugle, M.; Kalweit, G.; Mirchevska, B.; Werling, M.; Boedecker, J. Dynamic Input for Deep Reinforcement Learning in Autonomous Driving. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 7566–7573. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Treiber, M.; Hennecke, A.; Helbing, D. Congested traffic states in empirical observations and microscopic simulations. Phys. Rev. E 2000, 62, 1805. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kesting, A. General lane-changing model MOBIL for car-following models. Transp. Res. Rec. 2007, 1999, 86–94. [Google Scholar] [CrossRef] [Green Version]
- Liu, T.; Huang, B.; Mu, X.; Zhao, F.; Cao, D. A Comparative Analysis of Deep Reinforcement Learning-Enabled Freeway Decision-Making for Automated Vehicles. 2020. Available online: http://arxiv.org/abs/2008.01302 (accessed on 15 January 2022).
- Treiber, M.; Kesting, A.; Thiemann, C. Traffic Flow Dynamics: Data, Models and Simulation; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Van Der Horst, A.R.A. A Time-Based Analysis of Road User Behaviour in Normal and Critical Encounters; TNO Institute for Perception: Soesterberg, The Netherlands, 1990. [Google Scholar]
- Xu, J.; Pei, X.; Lv, K. Decision-Making for Complex Scenario using Safe Reinforcement Learning. In Proceedings of the 2020 4th CAA International Conference on Vehicular Control and Intelligence (CVCI), Hangzhou, China, 18–20 December 2020; pp. 1–6. [Google Scholar]
- Ng, A.Y. Policy invariance under reward transformations: Theory and application to reward shaping. In Proceedings of the Sixteenth International Conference on Machine Learning, Bled, Slovenia, 27–30 June 1999; pp. 278–287. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Explanation |
|---|---|
| ML | Machine Learning |
| RL | Reinforcement Learning |
| DL | Deep Learning |
| AD | Autonomous Driving |
| AV | Autonomous Vehicle |
| AC | Actor–Critic |
| LC | Lane Change |
| DRL | Deep Reinforcement Learning |
| DDPG | Deep Deterministic Policy Gradient |
| DPBRS | Dynamic Potential-Based Reward Shaping |
| ETA | Estimated Time of Arrival |
| SORL | Survival-Oriented Reinforcement Learning |
| SR | Safety Rules |
| SP | Safety Prediction |
| LSTM | Long Short-Term Memory |
| TM | Trauma Memory |
| MDP | Markov Decision Process |
| DQN | Deep Q-network |
| IDM | Intelligent Driver Model |
| MOBIL | Minimizing Overall Braking Induced by Lane changes |
| TTC | Time-To-Collision |
| PPO | Proximal Policy Optimization |
| DST | DDPG + SR + TM |
| DSTD | DDPG + SR + TM + DPBRS |
| DSSTD | DDPG + SR + SP + TM + DPBRS |
| Parameters | Values |
|---|---|
| Discount factor | 0.99 |
| Actor network learning rate | 0.001 |
| Critic network learning rate | 0.002 |
| Size of hidden layers | (64, 64, 32) |
| Optimization algorithm type | Adam |
| Size of replay memory | 1e5 |
| Size of trauma memory | 1e3 |
| Batch size of replay memory | 64 |
| Batch size of trauma memory | 20 |
| Soft updating rate | 0.001 |
| Exploration | 0.1 |
| Symbol | Parameters | Values |
|---|---|---|
| Length of three-lane | 80 m | |
| Length of two-lane | 100 m | |
| Length of converging-lane | 20 m | |
| Width of road | 3.5 m | |
| Length of vehicle | 4 m | |
| Width of vehicle | 1.96 m | |
| Initial velocity of the AV | 10.0 m/s | |
| Desired velocity of the AV | 23.0 m/s | |
| Initial velocity of surrounding vehicles | [8~12] m/s | |
| Limit velocity of surrounding vehicles | 20.0 m/s | |
| Actual acceleration of the AV | / | |
| Actual velocity of the AV | / | |
| Desired velocity of surrounding vehicles | 15.0 m/s | |
| Actual relative velocity | / | |
| Desired time gap | 1.0 s | |
| Minimum relative distance | g0 | 10.0 m |
| Actual relative distance | / | |
| Maximum acceleration | 2.0 m/s2 | |
| Desired deceleration | b | (−)1.0 m/s2 |
| Acceleration in transition state | / | |
| Safe deceleration limit | 1.0 m/s2 | |
| Acceleration argument | λ | 4 |
| the vehicle that will execute the LC | c | / |
| the following vehicles after the LC | n | / |
| the following vehicles before the LC | o | / |
| Politeness factor | 0.001 | |
| Acceleration threshold | 0.2 m/s2 |
| Algorithm | DDPG | PPO | DST | DSTD | DSSTD |
|---|---|---|---|---|---|
| Lane change success rate (%) | 87.6 | 90 | 98.8 | 98.4 | 100 |
| Collision or off-road counts | 59 | 48 | 6 | 8 | 0 |
| Average speed (m/s) | 22.3 | 22.62 | 22.48 | 23.12 | 23.03 |
| Relative Distance (m) | DDPG | PPO | DST | DSTD | DSSTD |
|---|---|---|---|---|---|
| Surrounding vehicle 1 | 9.5 | 8.6 | 14.5 | 14.7 | 15.0 |
| Surrounding vehicle 2 | 9.2 | 10.1 | 12.1 | 12.6 | 14.8 |
| Surrounding vehicle 3 | 7.8 | 9.9 | 12.8 | 12.0 | 12.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, K.; Pei, X.; Chen, C.; Xu, J. A Safe and Efficient Lane Change Decision-Making Strategy of Autonomous Driving Based on Deep Reinforcement Learning. Mathematics 2022, 10, 1551. https://doi.org/10.3390/math10091551
Lv K, Pei X, Chen C, Xu J. A Safe and Efficient Lane Change Decision-Making Strategy of Autonomous Driving Based on Deep Reinforcement Learning. Mathematics. 2022; 10(9):1551. https://doi.org/10.3390/math10091551
Chicago/Turabian StyleLv, Kexuan, Xiaofei Pei, Ci Chen, and Jie Xu. 2022. "A Safe and Efficient Lane Change Decision-Making Strategy of Autonomous Driving Based on Deep Reinforcement Learning" Mathematics 10, no. 9: 1551. https://doi.org/10.3390/math10091551