
Robust Graph Neural Networks via Ensemble Learning



Abstract
:1. Introduction
- We propose a novel framework of graph ensemble learning based on knowledge passing (i.e., GEL) to address the robustness challenge of GNNs and improve the performance on semi-supervised learning tasks.
- We design a multilayer DropNode propagation strategy to reduce each node’s dependence on particular neighbors, which can strengthen the robustness of GEL. Moreover, this propagation rule enables each node to extract knowledge from diverse subsets of neighbors, alleviating the oversmoothing issues.
- Experimental results on three public datasets show that our framework performs better than baseline methods in terms of classification accuracy and robustness.
2. Task Definition and Related Work
2.1. Semi-Supervised Node Classification
2.2. Graph Neural Networks
2.3. Ensemble Learning
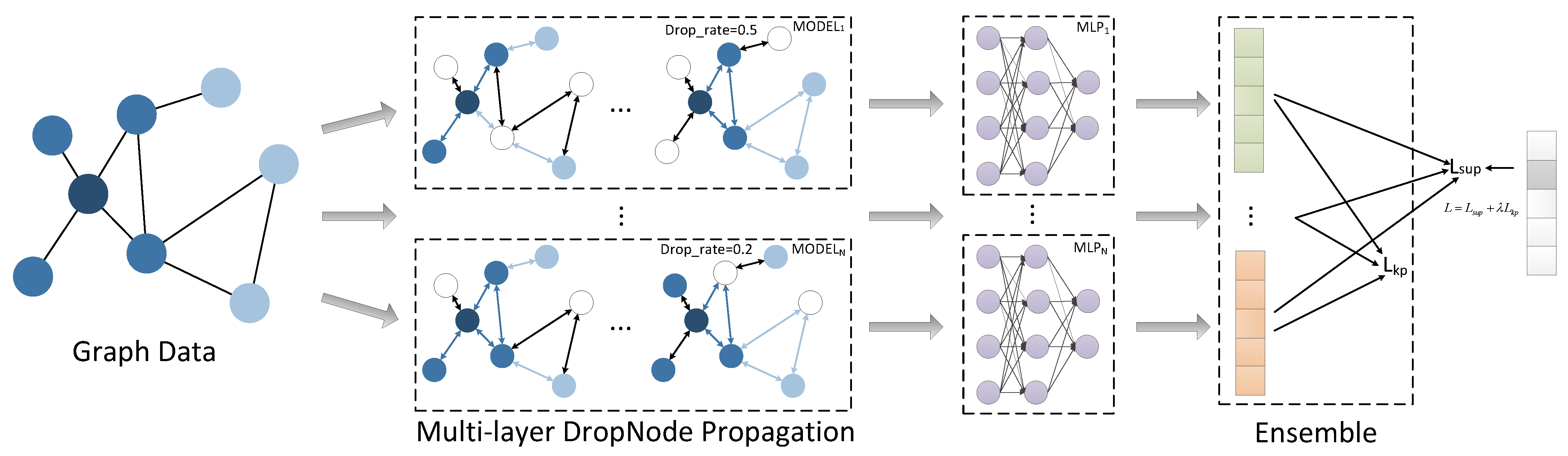
3. The Design of GEL
3.1. MultiLayer DropNode Propagation
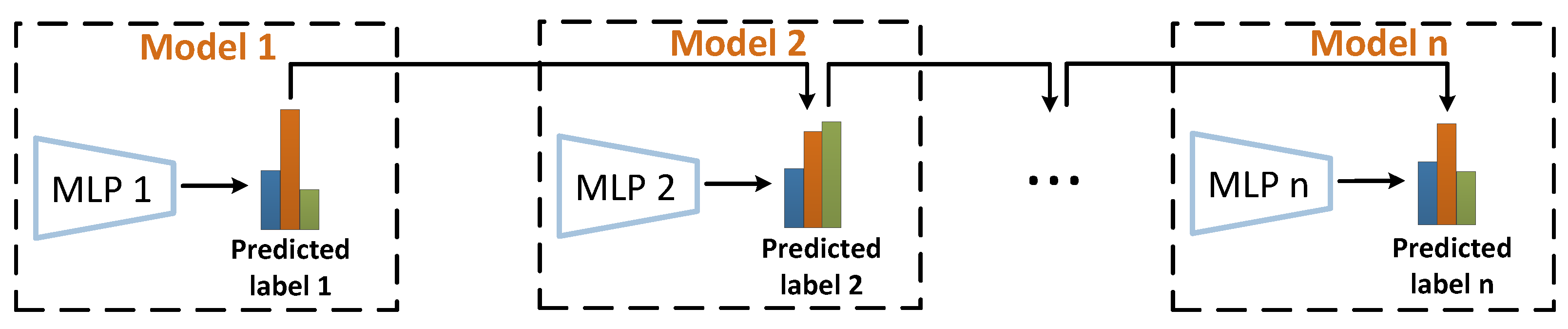
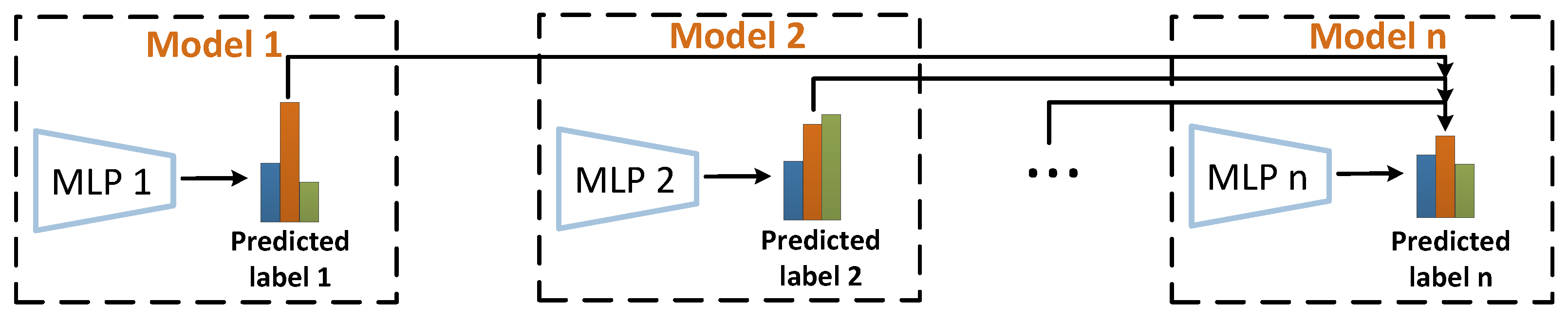
3.2. Graph Ensemble Learning Based on Knowledge Passing
| Algorithm 1 GEL. |
| Require: Graph G, adjacent matrix , feature matrix , the number of models N, DropNode probability p, learning rate , an MLP model: . Ensure: Prediction results .
|
3.3. Computational Complexity
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
- Cora [39] is a benchmark dataset related to citations between machine learning papers. It is widely used in the field of graph learning. Each node represents a paper and the edges represent citations between papers. The label of a node indicates the research field of a paper.
- Similar to Cora, Citeseer [39] is another benchmark dataset which represents the citations between computer science papers, keeping a similar configuration to Cora.
- Pubmed [40] is also a citation dataset which is relevant to articles about diabetes. The node features are weighted frequency–inverse document frequencies (TF-IDF). The label of a node denotes the type of diabetes.
4.1.2. Baselines and Variants
- GCN [7] is a semi-supervised learning approach which employs novel convolution operators on graph-structured data to learn node representations.
- GAT [27] performs better than GCN by combining an attention mechanism which specifies different weight to a neighbor node.
- DGI [41] is an unsupervised learning approach to study node representations. Maximizing mutual information between patch representations and corresponding high-level summaries were proposed in DGI.
- APPNP [42] improved GCN by connecting GCN with PageRank. A new propagation procedure based on personalized PageRank was proposed to make full use of neighbor information.
- MixHop [30] was proposed to study neighborhood mixing relationships, such as difference operators. Sparsity regularization lets us visualize which neighborhood information will be chosen in priority by the network.
- GraphSAGE [26] was proposed to study node embeddings by sampling and aggregating information which comes from a node’s local neighborhood.
- GRAND [38] first designed random propagation to achieve data augmentation and then proposed consistency loss to optimize the prediction loss of unlabeled nodes through data augmentation.
- RDD [34] was proposed to define node reliability and edge reliability to ensure the quality of a model. Moreover, a new ensemble learning method was proposed to combine the above optimization.
- M-GEL: The variant without the multilayer DropNode propagation mechanism.
- K-GEL: The variant without graph ensemble learning based on knowledge passing mechanism.
- P-GEL: The variant with the multilayer DropNode propagation and graph ensemble learning based on parallel knowledge passing.
4.1.3. Settings
4.2. Node Classification Results
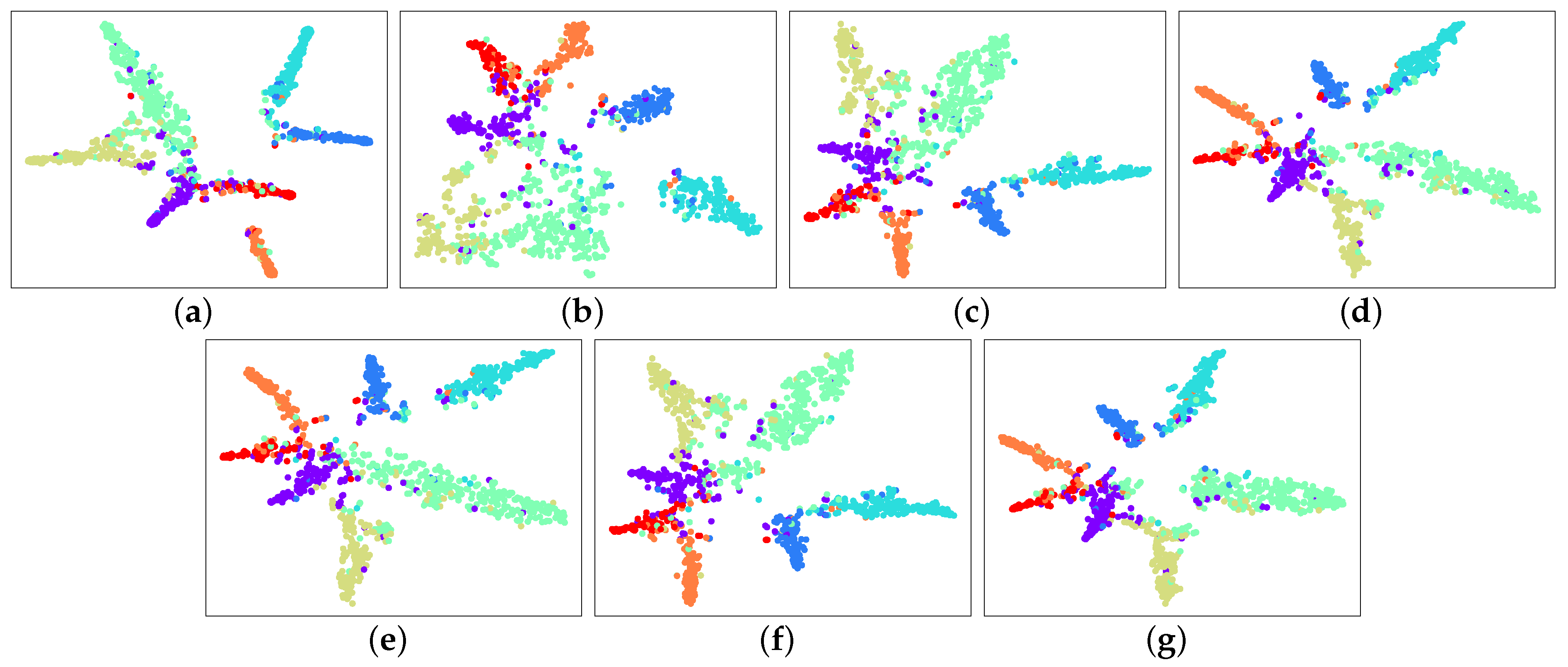
4.3. Network Visualization
- GCN tightly confuses red, purple, and green, as well as blue and lake blue. GAT poorly separates the boundary of green and peak green, and strongly confuses red, orange, and purple. GRAND fails to separate purple and red and cannot develop the boundary of green and peak green.
- GEL shows a remarkable ability to visualize the Cora network. It can separate points of different colors and cluster points of the same color, though tightly confuse red and purple. We can also observe that the variants of GEL also show a significant performance in the network visualization compared to GCN, GAT, and GRAND. These results indicate that the multilayer DropNode propagation and ensemble learning on graphs are useful in network visualization.
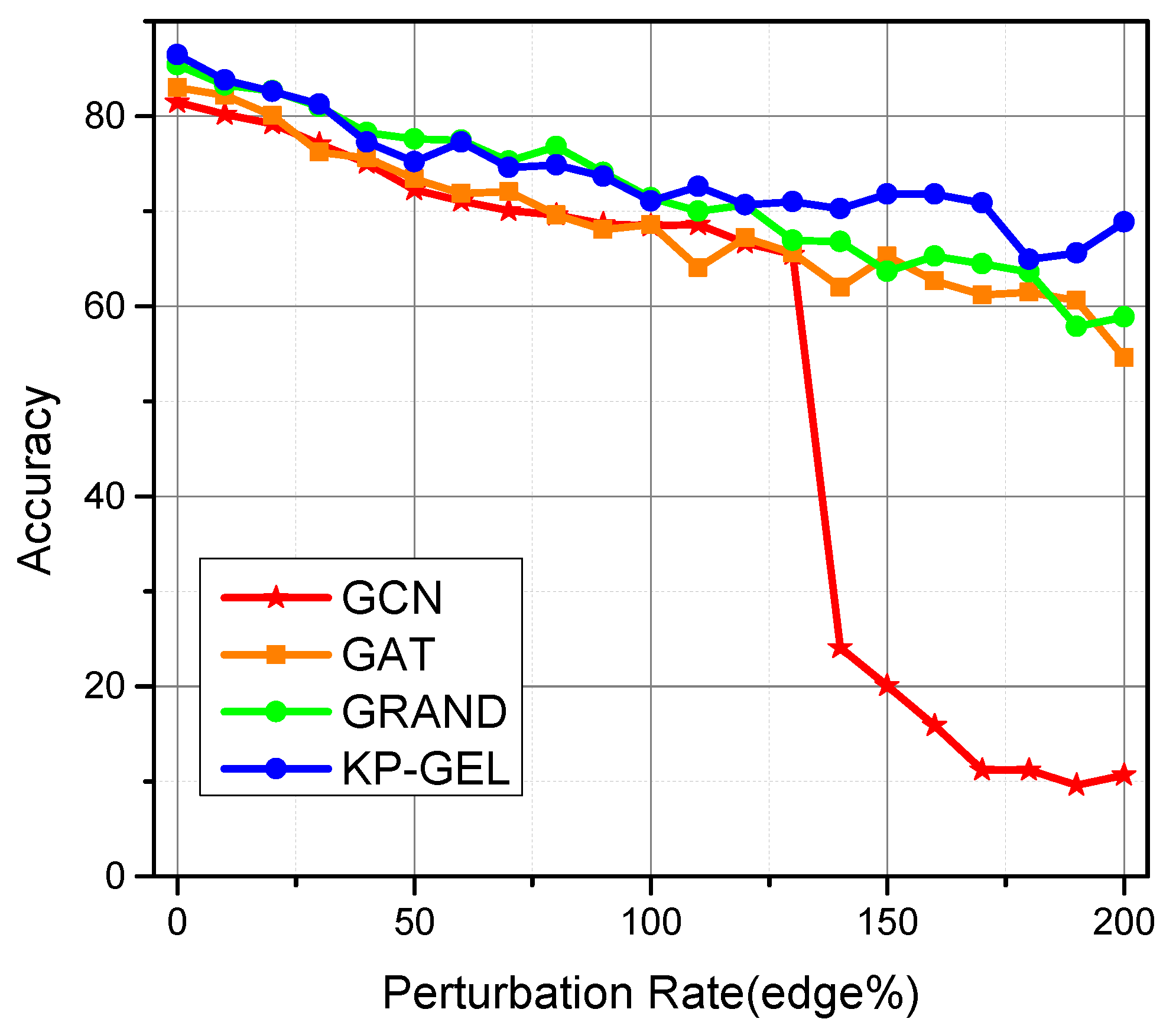
4.4. Robustness Analysis
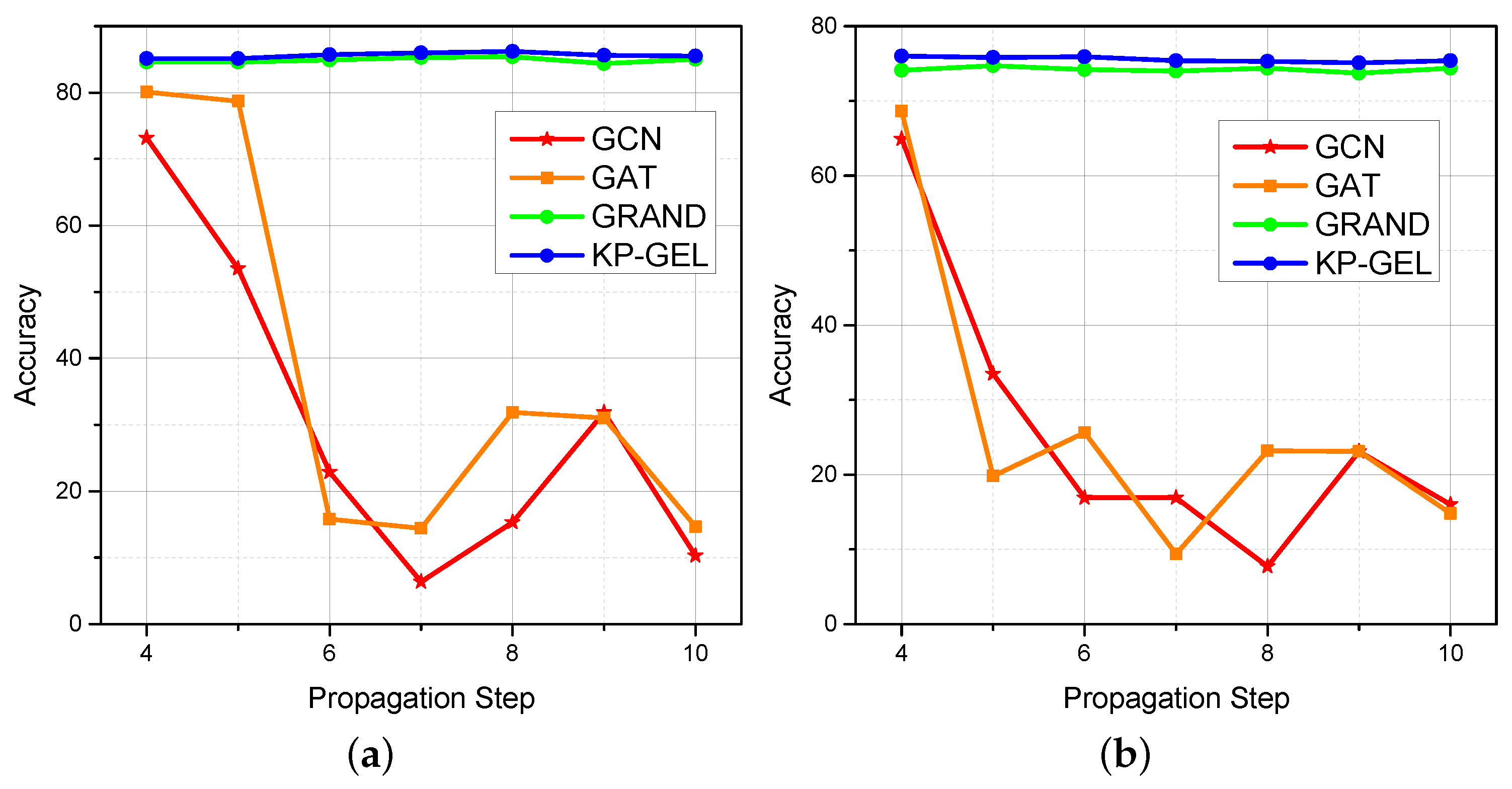
4.5. Oversmoothing Analysis
4.6. Parameter Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Stadtfeld, C.; Vörös, A.; Elmer, T.; Boda, Z.; Raabe, I.J. Integration in emerging social networks explains academic failure and success. Proc. Natl. Acad. Sci. USA 2019, 116, 792–797. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, J.; Yu, S.; Sun, K.; Ren, J.; Lee, I.; Pan, S.; Xia, F. Multivariate relations aggregation learning in social networks. In Proceedings of the ACM/IEEE Joint Conference on Digital Libraries, Virtual Event, China, 1–5 August 2020; pp. 77–86. [Google Scholar]
- Xia, F.; Wang, W.; Bekele, T.M.; Liu, H. Big scholarly data: A survey. IEEE Trans. Big Data 2017, 3, 18–35. [Google Scholar] [CrossRef]
- Ebesu, T.; Fang, Y. Neural citation network for context-aware citation recommendation. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 1093–1096. [Google Scholar]
- Xia, F.; Wang, L.; Tang, T.; Chen, X.; Kong, X.; Oatley, G.; King, I. CenGCN: Centralized Convolutional Networks with Vertex Imbalance for Scale-Free Graphs. IEEE Trans. Knowl. Data Eng. 2022. [Google Scholar] [CrossRef]
- Lee, K.; Eo, M.; Jung, E.; Yoon, Y.; Rhee, W. Short-term traffic prediction with deep neural networks: A survey. IEEE Access 2021, 9, 54739–54756. [Google Scholar] [CrossRef]
- Kipf, T.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Xiao, Y.; Li, C.; Liu, V. DFM-GCN: A Multi-Task Learning Recommendation Based on a Deep Graph Neural Network. Mathematics 2022, 10, 721. [Google Scholar] [CrossRef]
- Xia, F.; Sun, K.; Yu, S.; Aziz, A.; Wan, L.; Pan, S.; Liu, H. Graph Learning: A Survey. IEEE Trans. Artif. Intell. 2021, 2, 109–127. [Google Scholar] [CrossRef]
- Yu, S.; Xia, F.; Sun, Y.; Tang, T.; Yan, X.; Lee, I. Detecting outlier patterns with query-based artificially generated searching conditions. IEEE Trans. Comput. Soc. Syst. 2020, 8, 134–147. [Google Scholar] [CrossRef]
- Zügner, D.; Akbarnejad, A.; Günnemann, S. Adversarial attacks on neural networks for graph data. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2847–2856. [Google Scholar]
- Zhu, D.; Zhang, Z.; Cui, P.; Zhu, W. Robust graph convolutional networks against adversarial attacks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1399–1407. [Google Scholar]
- Nagurney, A. Networks in economics and finance in Networks and beyond: A half century retrospective. Networks 2021, 77, 50–65. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.; Bengio, S.; Dong, Y.; Liao, F.; Liang, M.; Pang, T.; Zhu, J.; Hu, X.; Xie, C.; et al. Adversarial attacks and defences competition. In The NIPS’17 Competition: Building Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2018; pp. 195–231. [Google Scholar]
- Kannan, H.; Kurakin, A.; Goodfellow, I. Adversarial logit pairing. arXiv 2018, arXiv:1803.06373. [Google Scholar]
- Croce, F.; Hein, M. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 2206–2216. [Google Scholar]
- Bui, A.; Le, T.; Zhao, H.; Montague, P.; deVel, O.; Abraham, T.; Phung, D. Improving Ensemble Robustness by Collaboratively Promoting and Demoting Adversarial Robustness. In Proceedings of the National Conference on Artificial Intelligence, New York, NY, USA, 7 February 2020. [Google Scholar]
- Liu, L.; Wei, W.; Chow, K.H.; Loper, M.; Gursoy, E.; Truex, S.; Wu, Y. Deep Neural Network Ensembles Against Deception: Ensemble Diversity, Accuracy and Robustness. In Proceedings of the Mobile Adhoc and Sensor Systems, Monterey, CA, USA, 4–7 November 2019. [Google Scholar]
- Li, Y.; Yosinski, J.; Clune, J.; Lipson, H.; Hopcroft, J.E. Convergent Learning: Do different neural networks learn the same representations? In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Weston, J.; Ratle, F.; Mobahi, H.; Collobert, R. Deep learning via semi-supervised embedding. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 639–655. [Google Scholar]
- Zhu, X.; Ghahramani, Z.; Lafferty, J.D. Semi-supervised learning using gaussian fields and harmonic functions. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 912–919. [Google Scholar]
- Sun, K.; Liu, J.; Yu, S.; Xu, B.; Xia, F. Graph force learning. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 2987–2994. [Google Scholar]
- Sun, K.; Wang, L.; Xu, B.; Zhao, W.; Teng, S.W.; Xia, F. Network representation learning: From traditional feature learning to deep learning. IEEE Access 2020, 8, 205600–205617. [Google Scholar] [CrossRef]
- Yu, S.; Feng, Y.; Zhang, D.; Bedru, H.D.; Xu, B.; Xia, F. Motif discovery in networks: A survey. Comput. Sci. Rev. 2020, 37, 100267. [Google Scholar] [CrossRef]
- Berrone, S.; Della Santa, F.; Mastropietro, A.; Pieraccini, S.; Vaccarino, F. Graph-Informed Neural Networks for Regressions on Graph-Structured Data. Mathematics 2022, 10, 786. [Google Scholar] [CrossRef]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1025–1035. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Xu, K.; Li, C.; Tian, Y.; Sonobe, T.; Kawarabayashi, K.i.; Jegelka, S. Representation learning on graphs with jumping knowledge networks. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5453–5462. [Google Scholar]
- Wu, F.; Souza, A.; Zhang, T.; Fifty, C.; Yu, T.; Weinberger, K. Simplifying graph convolutional networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6861–6871. [Google Scholar]
- Abu-El-Haija, S.; Perozzi, B.; Kapoor, A.; Alipourfard, N.; Lerman, K.; Harutyunyan, H.; Ver Steeg, G.; Galstyan, A. Mixhop: Higher-order graph convolutional architectures via sparsified neighborhood mixing. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 21–29. [Google Scholar]
- Tu, K.; Ma, J.; Cui, P.; Pei, J.; Zhu, W. Autone: Hyperparameter optimization for massive network embedding. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 216–225. [Google Scholar]
- Dietterich, T.G. Ensemble learning. In The Handbook of Brain Theory and Neural Networks; MIT Press: Cambridge, MA, USA, 2002; Volume 2, pp. 110–125. [Google Scholar]
- Hou, X.; Qi, P.; Wang, G.; Ying, R.; Huang, J.; He, X.; Zhou, B. Graph Ensemble Learning over Multiple Dependency Trees for Aspect-level Sentiment Classification. arXiv 2021, arXiv:2103.11794. [Google Scholar]
- Zhang, W.; Miao, X.; Shao, Y.; Jiang, J.; Chen, L.; Ruas, O.; Cui, B. Reliable data distillation on graph convolutional network. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 1399–1414. [Google Scholar]
- Zou, J.; Fu, L.; Zheng, J.; Yang, S.; Yu, G.; Hu, Y. A many-objective evolutionary algorithm based on rotated grid. Appl. Soft Comput. 2018, 67, 596–609. [Google Scholar] [CrossRef]
- Zou, J.; Fu, L.; Yang, S.; Zheng, J.; Ruan, G.; Pei, T.; Wang, L. An adaptation reference-point-based multiobjective evolutionary algorithm. Inf. Sci. 2019, 488, 41–57. [Google Scholar] [CrossRef] [Green Version]
- Mun, Y.J.; Kang, J.W. Ensemble of random binary output encoding for adversarial robustness. IEEE Access 2019, 7, 124632–124640. [Google Scholar] [CrossRef]
- Feng, W.; Zhang, J.; Dong, Y.; Han, Y.; Luan, H.; Xu, Q.; Yang, Q.; Kharlamov, E.; Tang, J. Graph Random Neural Networks for Semi-Supervised Learning on Graphs. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Sen, P.; Namata, G.; Bilgic, M.; Getoor, L.; Galligher, B.; Eliassi-Rad, T. Collective classification in network data. AI Mag. 2008, 29, 93. [Google Scholar] [CrossRef] [Green Version]
- Namata, G.; London, B.; Getoor, L.; Huang, B.; EDU, U. Query-driven active surveying for collective classification. In Proceedings of the 10th International Workshop on Mining and Learning with Graphs, Washington, DC, USA, 24–25 July 2012; Volume 8. [Google Scholar]
- Veličković, P.; Fedus, W.; Hamilton, W.L.; Liò, P.; Bengio, Y.; Hjelm, R.D. Deep Graph Infomax. ICLR (Poster) 2019, 2, 4. [Google Scholar]
- Klicpera, J.; Bojchevski, A.; Günnemann, S. Predict then Propagate: Graph Neural Networks meet Personalized PageRank. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Yang, Z.; Cohen, W.; Salakhudinov, R. Revisiting semi-supervised learning with graph embeddings. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 40–48. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Definitions |
|---|---|
| N | Number of base models |
| n | Number of nodes |
| m | Number of labeled nodes |
| p | Multilayer DropNode probability |
| K | Propagation Step |
| KP loss coefficient | |
| Set of model parameters | |
| Learning rate | |
| Feature matrix | |
| Adjacency matrix | |
| All possible labels | |
| Hidden node representations in the lth layer | |
| Weight matrix in the lth layer | |
| Perturbed matrix | |
| Matrix after propagation | |
| Predicted possibilities of matrix |
| Dataset | Nodes | Edges | Classes | Features |
|---|---|---|---|---|
| Cora | 2708 | 5429 | 7 | 1433 |
| Citeseer | 3327 | 4732 | 6 | 3703 |
| Pubmed | 19,717 | 44,338 | 3 | 500 |
| Method | Cora | Citeseer | Pubmed |
|---|---|---|---|
| GCN | 81.5 | 70.3 | 79.0 |
| GAT | 83.7 | 73.2 | 79.3 |
| DGI | 82.9 | 72.5 | 77.4 |
| APPNP | 84.1 | 72.1 | 80.0 |
| MixHop | 82.3 | 72.2 | 81.4 |
| GraphSAGE | 79.7 | 68.1 | 78.4 |
| GRAND | 85.8 | 75.8 | 83.3 |
| RDD | 86.1 | 74.2 | 81.5 |
| GEL | 86.5 | 76.0 | 84.2 |
| M-GEL | 84.6 | 74.7 | 81.1 |
| K-GEL | 85.4 | 74.8 | 82.9 |
| P-GEL | 85.7 | 75.5 | 84.2 |
| Hyperparameter | Cora | Citeseer | Pubmed |
|---|---|---|---|
| Model number N | 6 | 6 | 2 |
| Propagation step K | 8 | 2 | 5 |
| DropNode probability p | [0.7, 0.6, 0.5, 0.3, 0.2, 0.15] | [0.7, 0.6, 0.5, 0.4, 0.3, 0.2] | [0.7, 0.6] |
| KP loss coefficient | 1.0 | 0.7 | 1.0 |
| Learning rate | 0.01 | 0.01 | 0.2 |
| Early stopping patience | 200 | 200 | 200 |
| Hidden layer size | 32 | 32 | 32 |
| L2 weight decay rate | |||
| Dropout rate in input layer | 0.5 | 0.0 | 0.6 |
| Dropout rate in hidden layer | 0.5 | 0.2 | 0.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Q.; Yu, S.; Sun, K.; Zhao, W.; Alfarraj, O.; Tolba, A.; Xia, F. Robust Graph Neural Networks via Ensemble Learning. Mathematics 2022, 10, 1300. https://doi.org/10.3390/math10081300
Lin Q, Yu S, Sun K, Zhao W, Alfarraj O, Tolba A, Xia F. Robust Graph Neural Networks via Ensemble Learning. Mathematics. 2022; 10(8):1300. https://doi.org/10.3390/math10081300
Chicago/Turabian StyleLin, Qi, Shuo Yu, Ke Sun, Wenhong Zhao, Osama Alfarraj, Amr Tolba, and Feng Xia. 2022. "Robust Graph Neural Networks via Ensemble Learning" Mathematics 10, no. 8: 1300. https://doi.org/10.3390/math10081300