1. Introduction
In recent years, with the rapid development of financial market and artificial intelligence technology, quantitative investment has attracted more and more attention from investors and securities investment practitioners. Quantitative investment is an investment technology that combines mathematics, statistics, computer, finance and other knowledge to establish transaction models and strategies, find effective investment opportunities in the market, and finally achieve the goal of rational investment and income maximization [
1]. Compared with traditional securities investment, quantitative investment uses mathematical models to provide investors and practitioners with scientific trading decisions, so as to realize rational investment and improve the efficiency and stability of securities trading with the help of computer technology. In the financial field, the operation of the market is affected by many factors. There is a high-dimensional and complex nonlinear relationship between the rise and fall of stocks and various factors. Deep learning has unique advantages in dealing with the high-dimensional characteristics of big data and solving complex problems [
2,
3,
4]. In recent years, deep learning has achieved remarkable results in many fields, such as trend prediction, unstructured text processing, improving transaction strategies, and so on [
5,
6,
7]. Therefore, how to use deep learning to build a multi-factor stock selection model that can be effectively applied to the actual market, and to study stock selection strategies, has important research significance.
The representative quantitative stock selection research can be traced back to the Markowitz model proposed by American economist Markowitz in 1952. This method uses the mean-variance model to quantify the return and risk in securities investment [
8]. After that, Sharpe et al. proposed the Capital Asset Pricing Model (CAPM) based on the Markowitz model, which described the relationship between asset returns and risks with linear expression, and further improved the financial theory research [
9]. At present, the mainstream multi-factor stock selection model mainly draws lessons from the “Fama–French three-factor model” proposed by Fama and French in 1993 [
10], and continues to innovate and explore on this basis. Carhart [
11] found that the momentum factor can explain the excess return of individual stocks based on the “Fama–French three-factor model”. In 2015, Fama and French found that the company’s profitability and investment preference can further explain the excess return, so they put forward a more perfect “five-factor model” [
12]. Wang et al. [
13] proposed an eight-factor stock selection model index system, which predicted the rise and fall of 200 stocks in April 2013 and achieved good results. Shang [
14] comprehensively considered the heterogeneity of property rights and investor sentiment factors to explore their impact on managers’ investment behavior. However, in the existing quantitative stock selection studies, the construction of a factor pool still has some limitations. In the selection of stock factor data, many scholars are mostly limited to fundamental indicators or technical indicators, and few people combine the two. In addition, the research on investor sentiment is not sufficient, and there is still a research gap.
In terms of the stock selection model, the arrival of the era of big data and artificial intelligence has provided new opportunities for quantitative investment [
15,
16]. More and more scholars have begun to use machine learning algorithms for modeling, so as to effectively overcome the limitations of traditional statistical models that are difficult to describe the complex nonlinear relationship between stock returns and factors and are not suitable for high-dimensional problems [
17,
18,
19,
20]. Rasekhschaffe et al. [
21] respectively applied four machine learning algorithms such as gradient boosting classification regression tree and support vector machine to the stock markets in the United States, Japan, Europe and Asia (except Japan) for empirical research. The experimental results show that a machine learning algorithm can be used by investors to predict stock returns and limit the risk of over fitting. Deng [
22] used the gradient boosting tree model in machine learning to perform technical analysis on the deviation of stock factor data and established a multi-factor stock selection model based on factor deviation and gradient boosting tree. The simulated trading results show that the Alpha excess return of the stock selection model reaches about 25%. Luo [
23] combined random forest, extreme gradient boosting and other machine learning algorithms based on the Stacking method, and established an integrated multi-factor stock selection model with strong learning capabilities. The back test performance of this model on the CSI 300 is significantly better than other comparisons models. Although machine learning models such as random forest and gradient lifting tree have achieved good prediction performance in the modeling application of stock factor data, traditional shallow learning algorithms such as random forest also have defects such as insufficient deep-level learning and over fitting [
24,
25]. Deep learning has stronger learning ability and adaptability. Many scholars have also made many attempts in the application of deep learning in recent years [
26]. Liu et al. [
27] proposed a stock selection algorithm that combines gray wolf optimization and support vector regression and conducted empirical research on the performance of the hybrid algorithm through transaction and financial data from the US and Chinese stock markets. Experimental results show that the proposed algorithm can stably achieve excess returns. Zhang et al. [
28] combined traditional multi-factor analysis and established a multi-factor stock selection model based on long short-term memory (LSTM) algorithm. In the empirical analysis, LSTM is used to predict stock returns and portfolio classification. The results show that the multi-factor stock selection model based on LSTM has good profit prediction ability and profitability. Sun and Bi [
29] combined deep learning with high-frequency trading, and selected Convolutional Neural Networks (CNN) and LSTM neural networks to construct the ups and downs classification models of the main asphalt futures contracts. Fischer and Krauss [
30] used the LSTM neural network model to predict the movement direction of the S&P500 component stocks from 1992 to 2015. Research shows that the deep learning model has better stock selection capabilities than random forest, support vector machine (SVM) and logistic regression classification device. Zhao et al. [
31] used three different recurrent neural network frameworks, namely Recurrent Neural Network (RNN), LSTM, and GRU, to predict stock fluctuations based on the memory of stock data, and it is concluded that the prediction performance of LSTM and GRU is obviously better than RNN.
However, the selection of parameters in deep learning has a great impact on the calculation results, and there are many difficulties, such as a large number of parameters and high calculation cost [
32,
33]. The intelligent optimization algorithm can solve this problem well. In particular, the Cuckoo Search optimization algorithm has significant advantages in optimization problems and has achieved remarkable results in parameter optimization [
34], image signal processing [
35], scheduling optimization [
36], combinatorial optimization [
37].
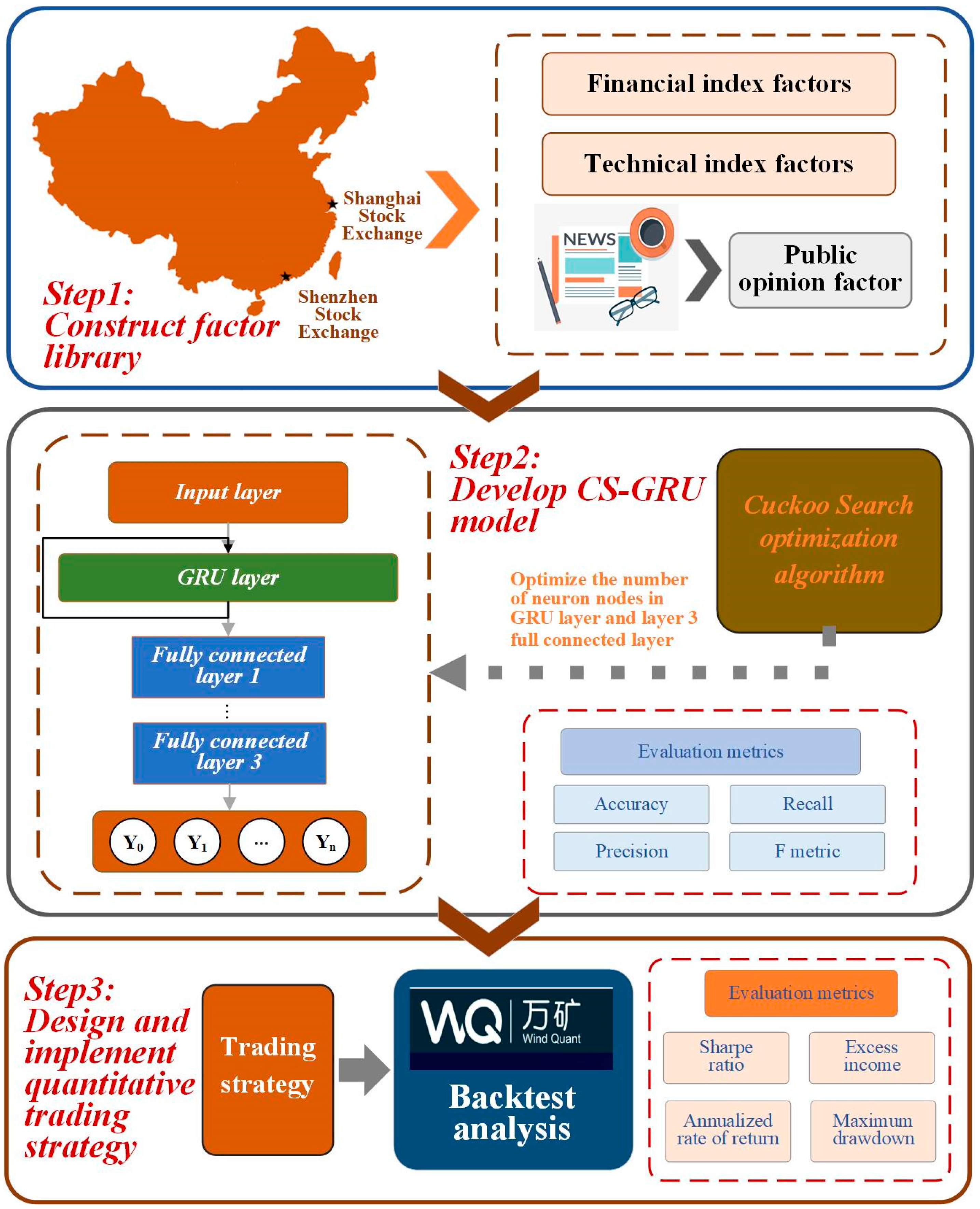
In order to describe the complex relationship between stock factors and individual stock excess returns, according to the previous research and the characteristics of quantitative investment, this paper designs 16 financial index factor data such as circulation market value, 9 technical index factor data such as 20 day annualized return variance, and sentiment index factor based on public opinion, innovatively proposed a multi-factor deep learning stock selection model based on intelligent optimization algorithms, and finally proposed a quantitative trading strategy, using the test set data and the established CS-GRU stock selection model.
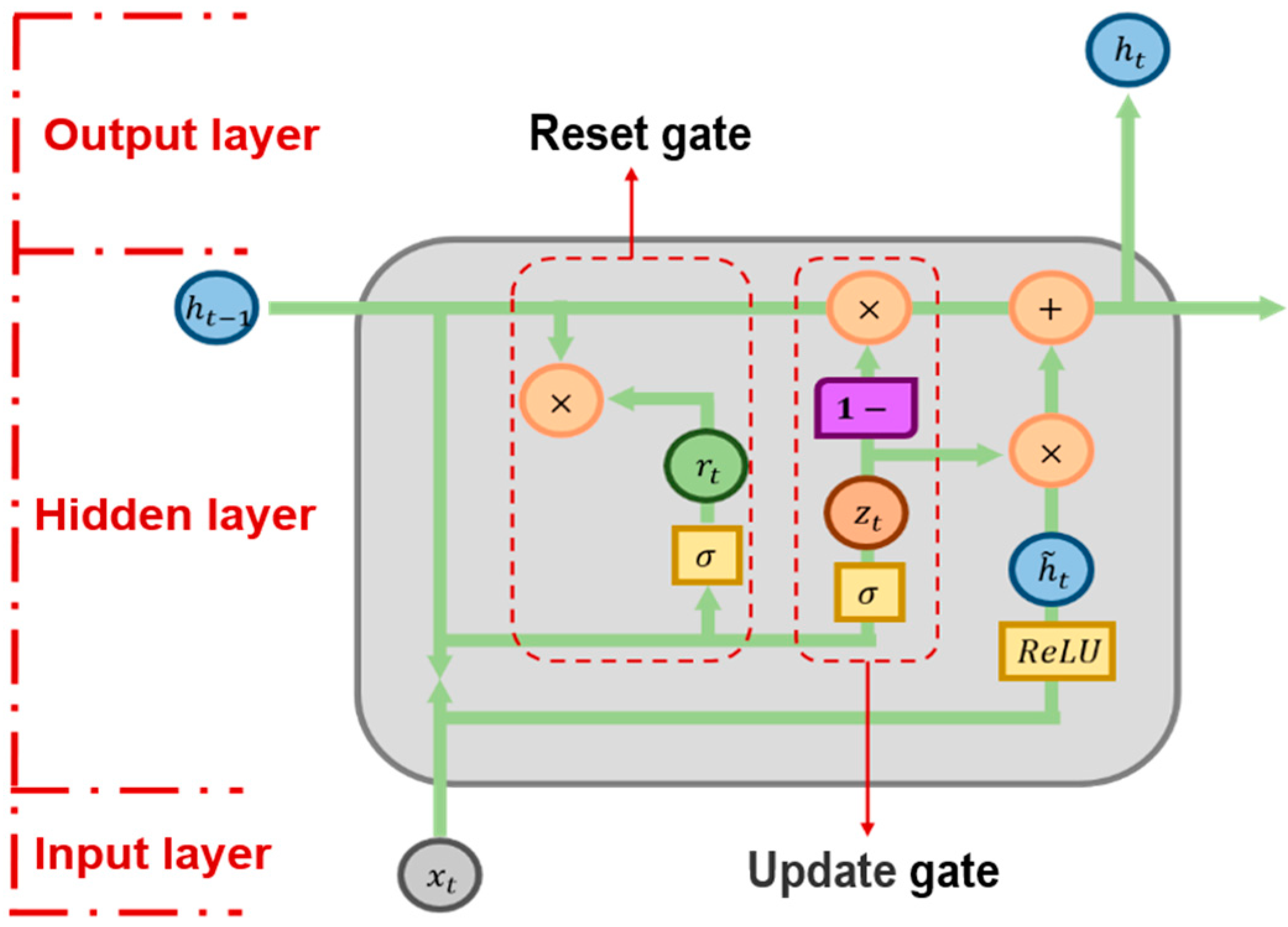
The contributions of this paper are mainly reflected in the following aspects. Firstly, in the construction of the factor database, this paper considers the impact of public opinion on investors and practitioners and constructs an innovative sentiment index factor based on the sentimental analysis of news broadcast text data. Secondly, in the construction of a multi-factor stock selection model, in order to solve the problem of nonlinear and high-dimensional stock price series prediction, this paper designs a GRU neural network architecture with multiple hidden layers as the core classification model of the multi-factor stock selection model. Thirdly, because the selection of parameters has a great impact on the prediction effect of the deep learning model, this paper creatively puts forward the CS-GRU stock selection model. Among them, the Cuckoo Search algorithm is used to optimize the number of neuron nodes in multiple hidden layers in GRU neural network architecture, so as to further improve the classification and prediction effect.
The rest of this paper is organized as follows.
Section 2 introduces the methodological principles of this research.
Section 3 presents and analyzes the empirical results. Comparisons and discussions are given in
Section 4 and
Section 5 provides some summaries and outlooks based on the results of the empirical study.
5. Conclusions
This paper makes an in-depth study on the multi-factor quantitative stock selection based on China’s stock market from three aspects: the construction of the factor library, the construction of the deep learning stock selection model, the design and implementation of quantitative trading strategy, and provides a research route from data to model and then to practice. The research results are summarized as follows.
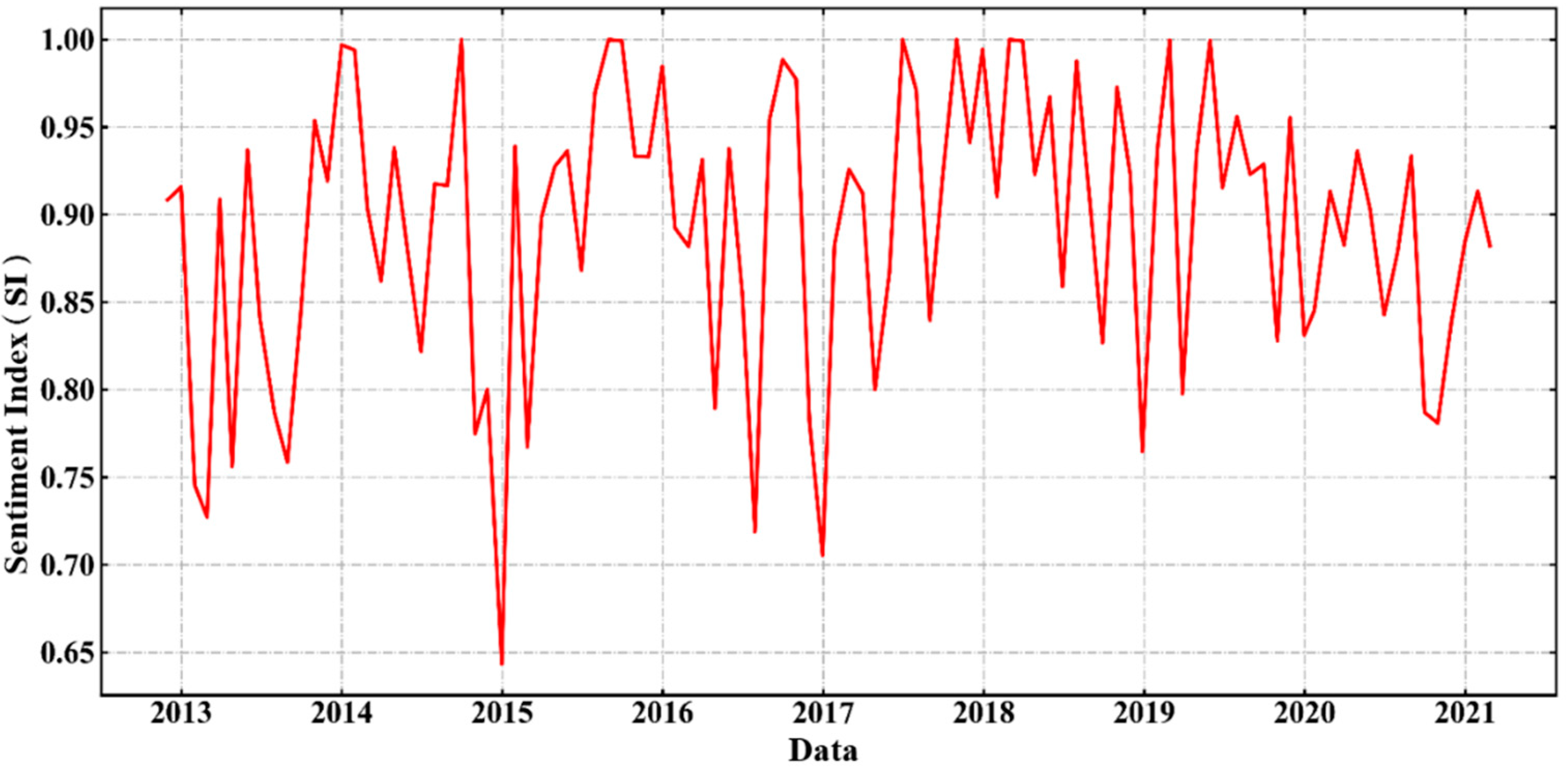
Firstly, this paper constructs a comprehensive library of quantitative factors. This paper selects 16 financial indicators such as circulation market value from the basic indicators to describe the valuation level, profitability, growth ability and financial level of individual stocks. From the technical indicators, nine technical indicators such as the 10 day average turnover rate are selected to describe the volatility, trading volume, momentum and so on. In addition, from the perspective of the impact of public opinion on the investment behavior of investors and employees, this paper makes a sentimental analysis on the text data of news broadcast and constructs an innovative public opinion factor, sentiment index.
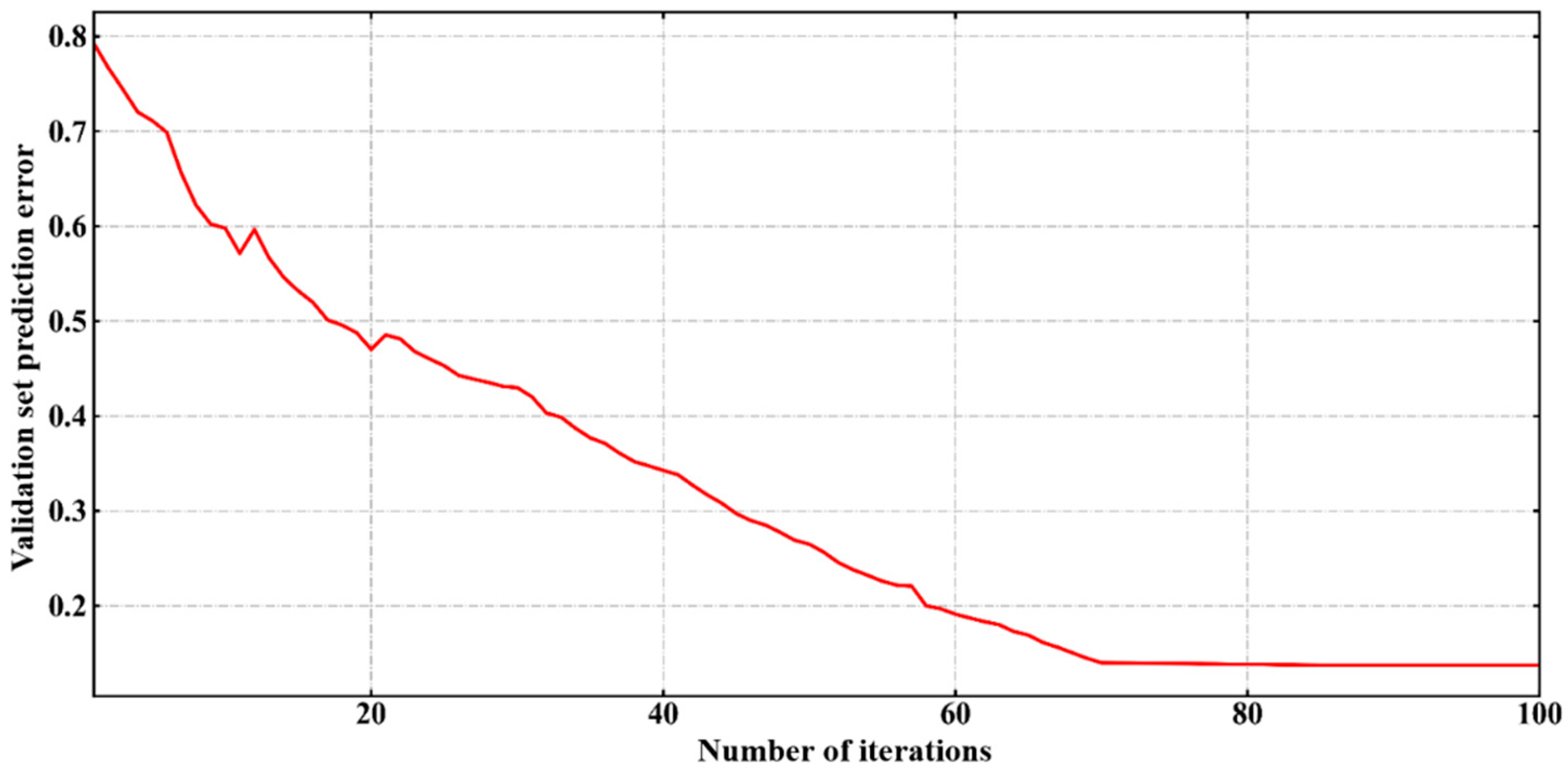
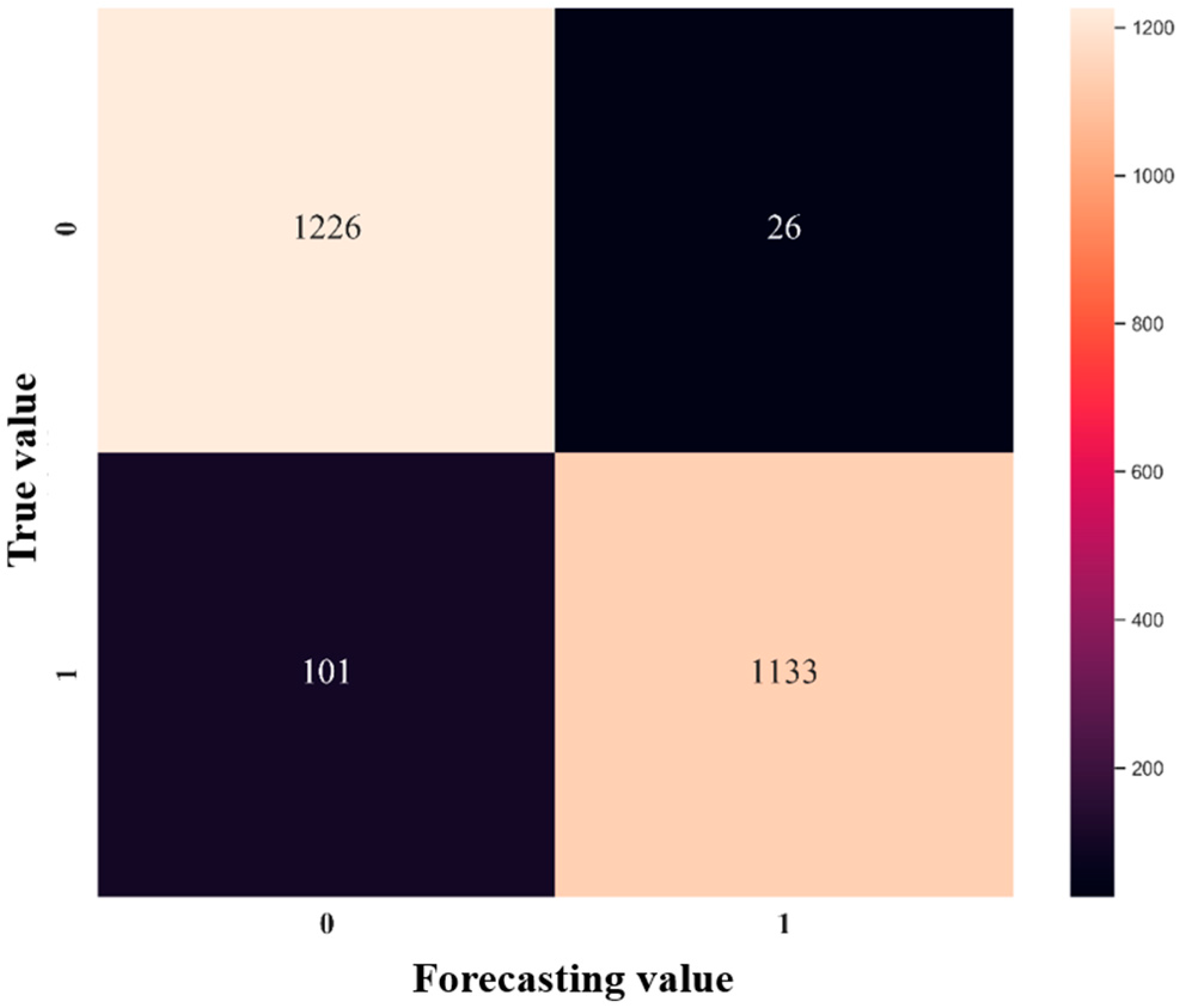
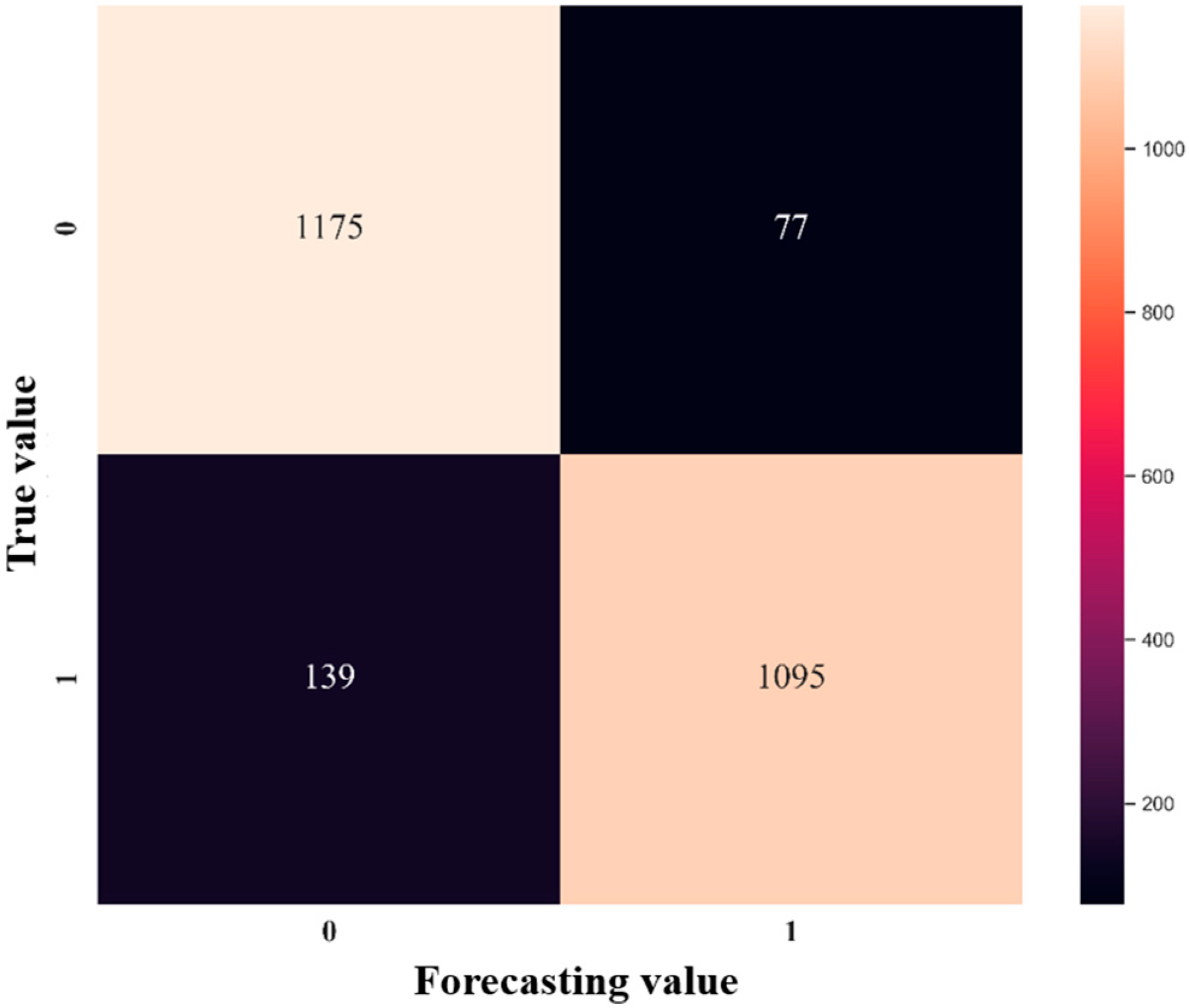
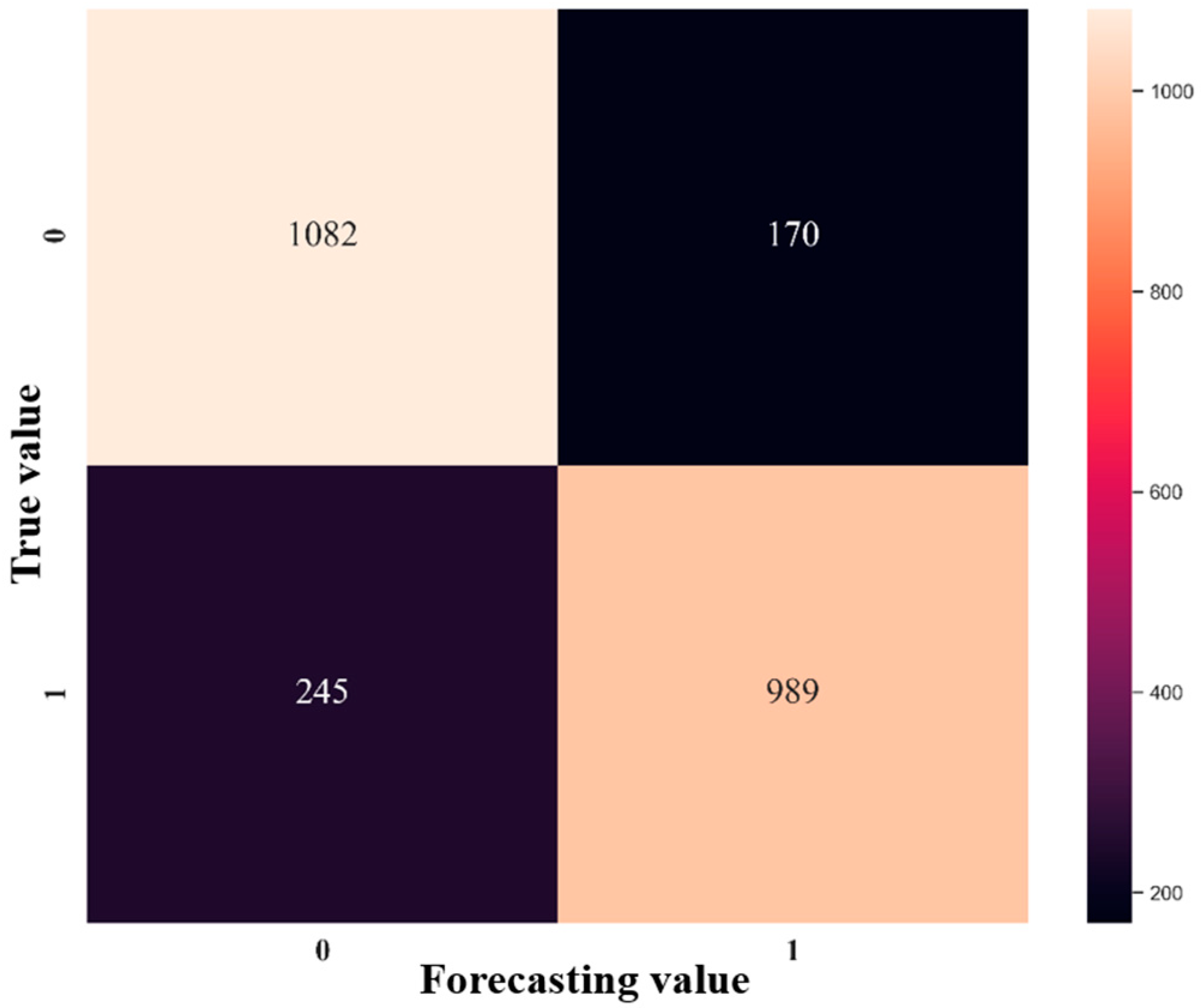
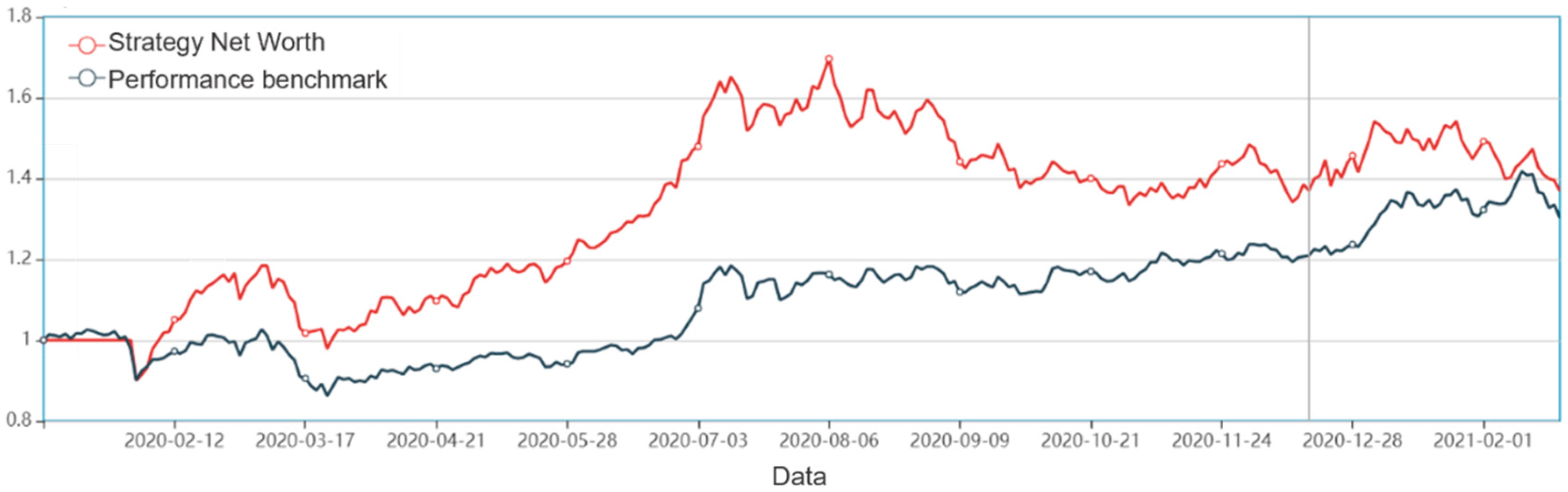
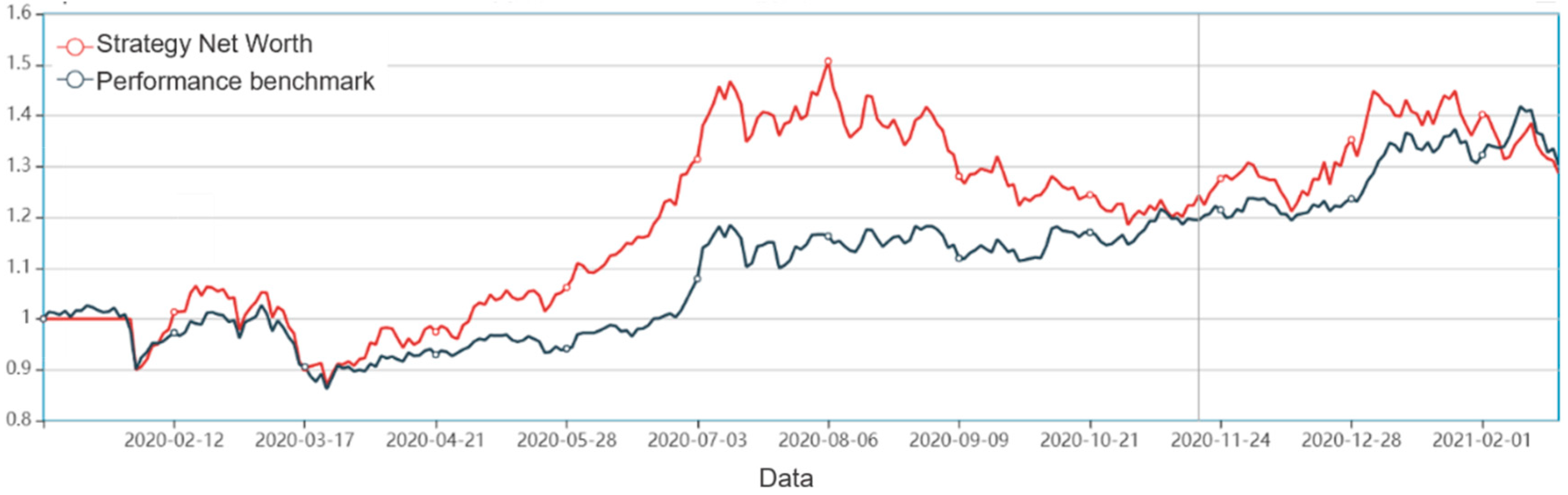
Secondly, this research builds a deep learning stock selection model based on intelligent optimization. Aiming at the complex nonlinear relationship between each factor and individual stock excess return, this paper proposes an innovative multi-factor deep learning stock selection model based on intelligent optimization to solve the multi-factor stock selection problem with high dimension and nonlinear characteristics. Compared with the traditional linear regression model and shallow machine learning model, the GRU neural network architecture in this model can more effectively describe the nonlinear relationship between factors and excess return, so as to achieve better prediction performance; Compared with RNN and other deep learning models, the GRU neural network can further improve the computational efficiency on the basis of improving the prediction performance. In the CS-GRU stock selection model, the Cuckoo Search optimization algorithm is also used to optimize the number of neuron nodes in the multi-layer hidden layer of the GRU neural network, so as to build a CS-GRU stock selection model with the best prediction performance. Finally, the CS-GRU stock selection model proposed in this paper achieved an accuracy of 94.89%, a recall rate of 97.92%, an precision rate of 92.38% and an F metric of 95.07%, and achieved excellent stock classification prediction results.
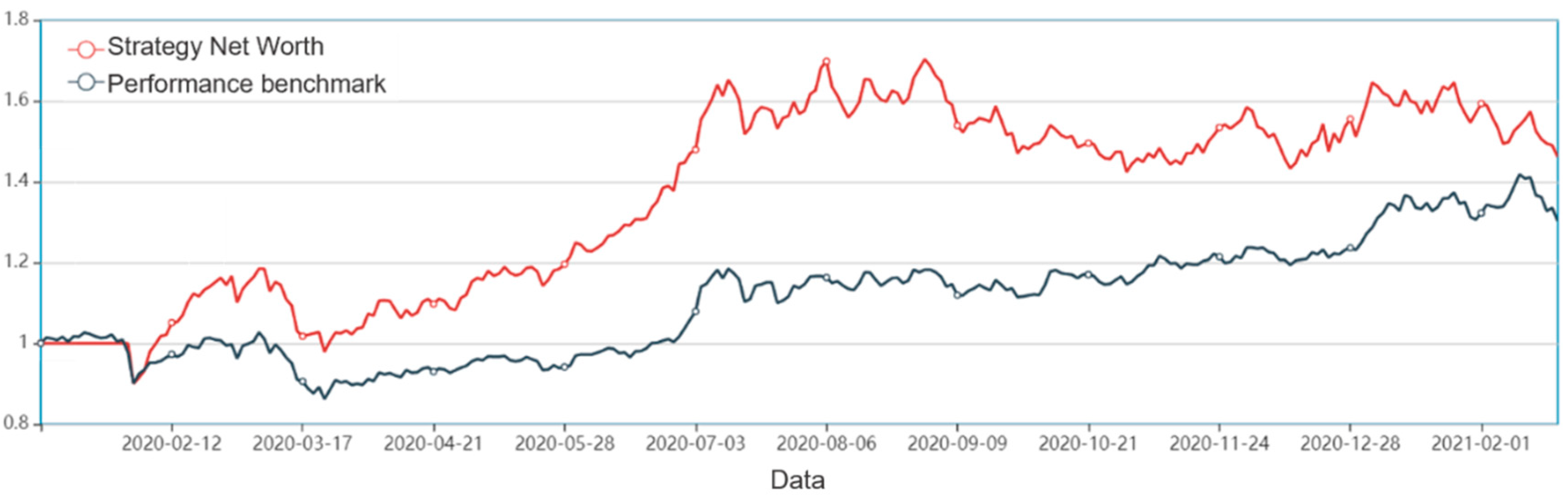
Thirdly, this paper designs and implements a quantitative trading strategy. Based on the CS-GRU stock selection model, this paper designs and implements a quantitative trading strategy. The sharp ratio of 127.08%, the annualized rate of return 40.66%, the Alpha excess return of 13.13%, and the maximum drawdown rate of −17.38% of the back test results show that the CS-GRU-based multi-factor stock selection model proposed in this article is effective for the Chinese stock market. Trading strategy research is very meaningful.
In the future, we can expand the work from the following aspects to enhance the performance of the proposed model: (1) Some social media text data can be deeply mined to further improve the ability of the model to select stocks. (2) The number of hidden layers, activation function type, learning rate and other parameters of the GRU neural network can be further optimized.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}