
Optimal Reinforcement Learning-Based Control Algorithm for a Class of Nonlinear Macroeconomic Systems



Abstract
:1. Introduction
2. Literature Review
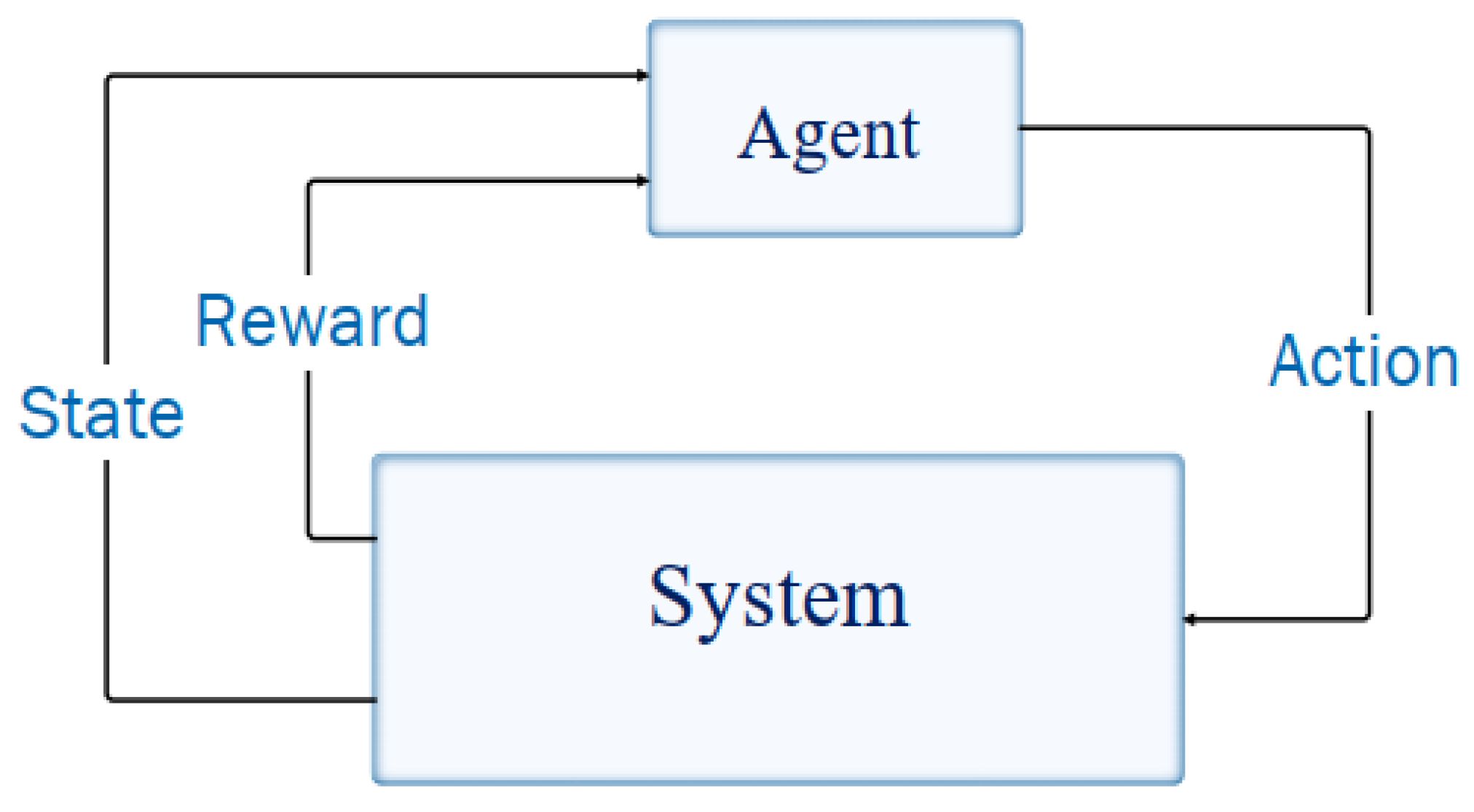
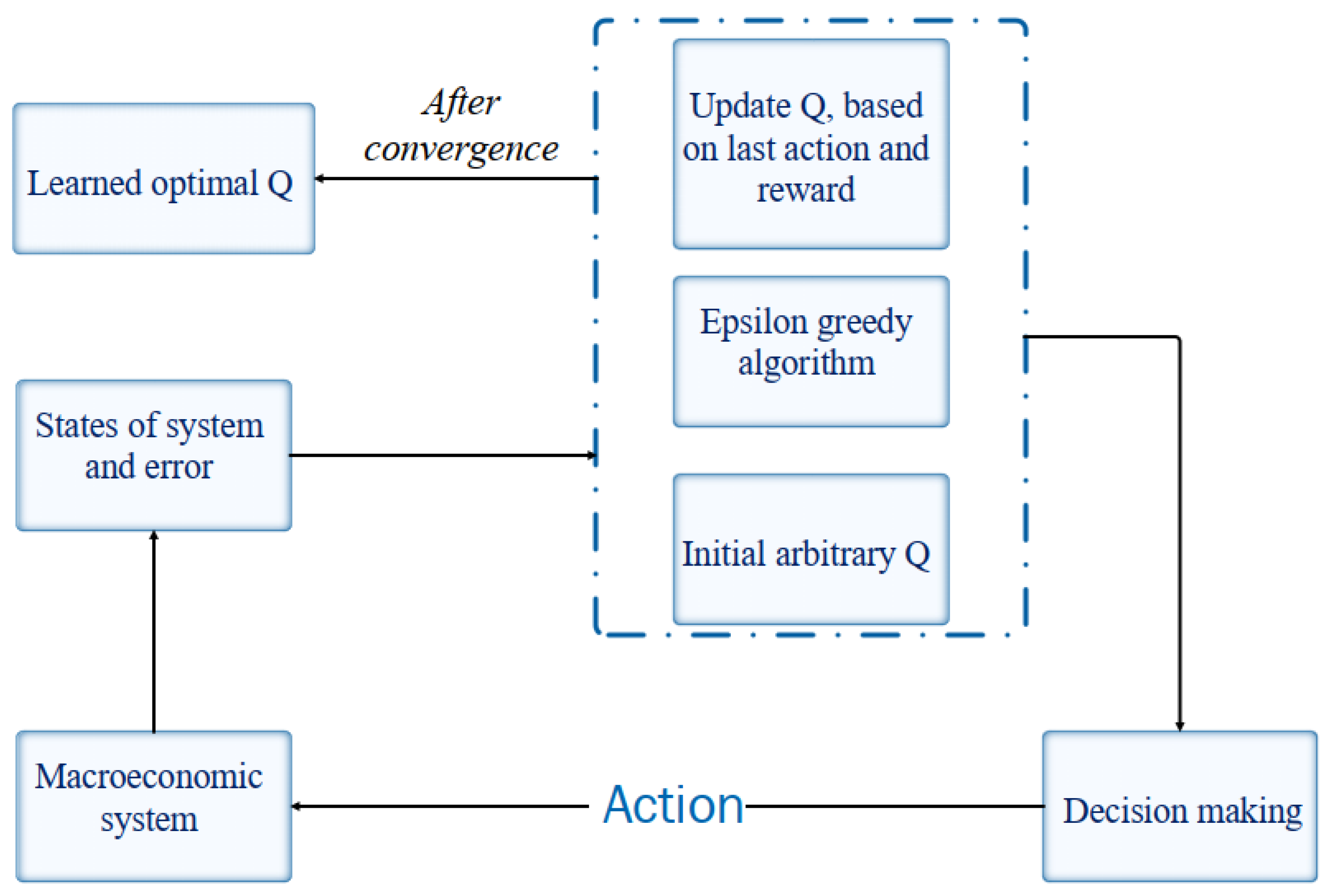
3. Methodology
| Algorithm 1. Q-learning algorithm. |
| 1: Initialize Q-table. 2: Loop {for all of episodes}. 3: Initialize state s. 4: Repeat {for each step-in episode}. 5: Calculate firing strength of 6: Choose action 7: Take action . 8: Calculate state value of state . 9: Update Q-table. 10: Until is terminal state. 11: End loop. |
4. Macroeconomic System
5. Results
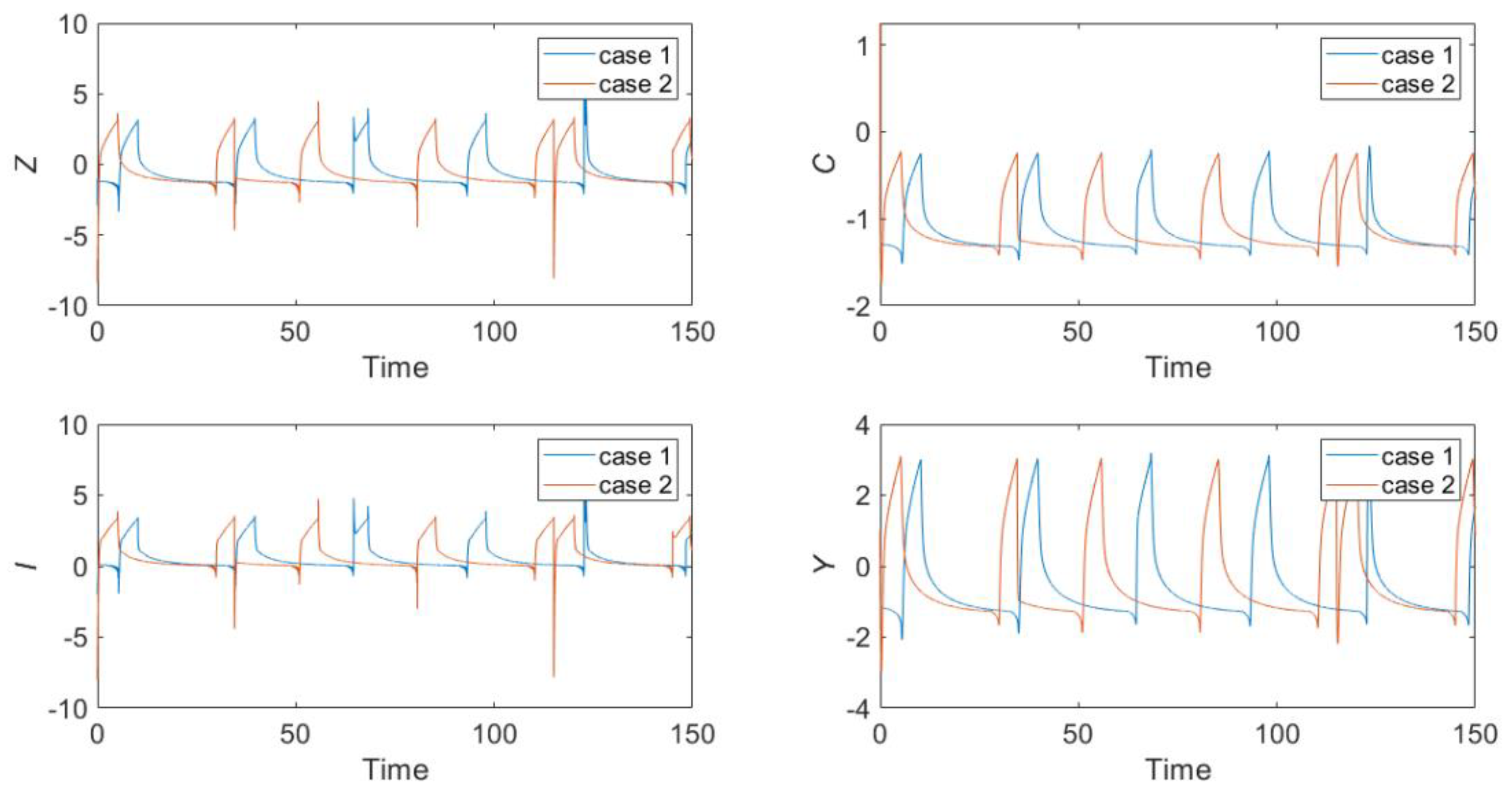
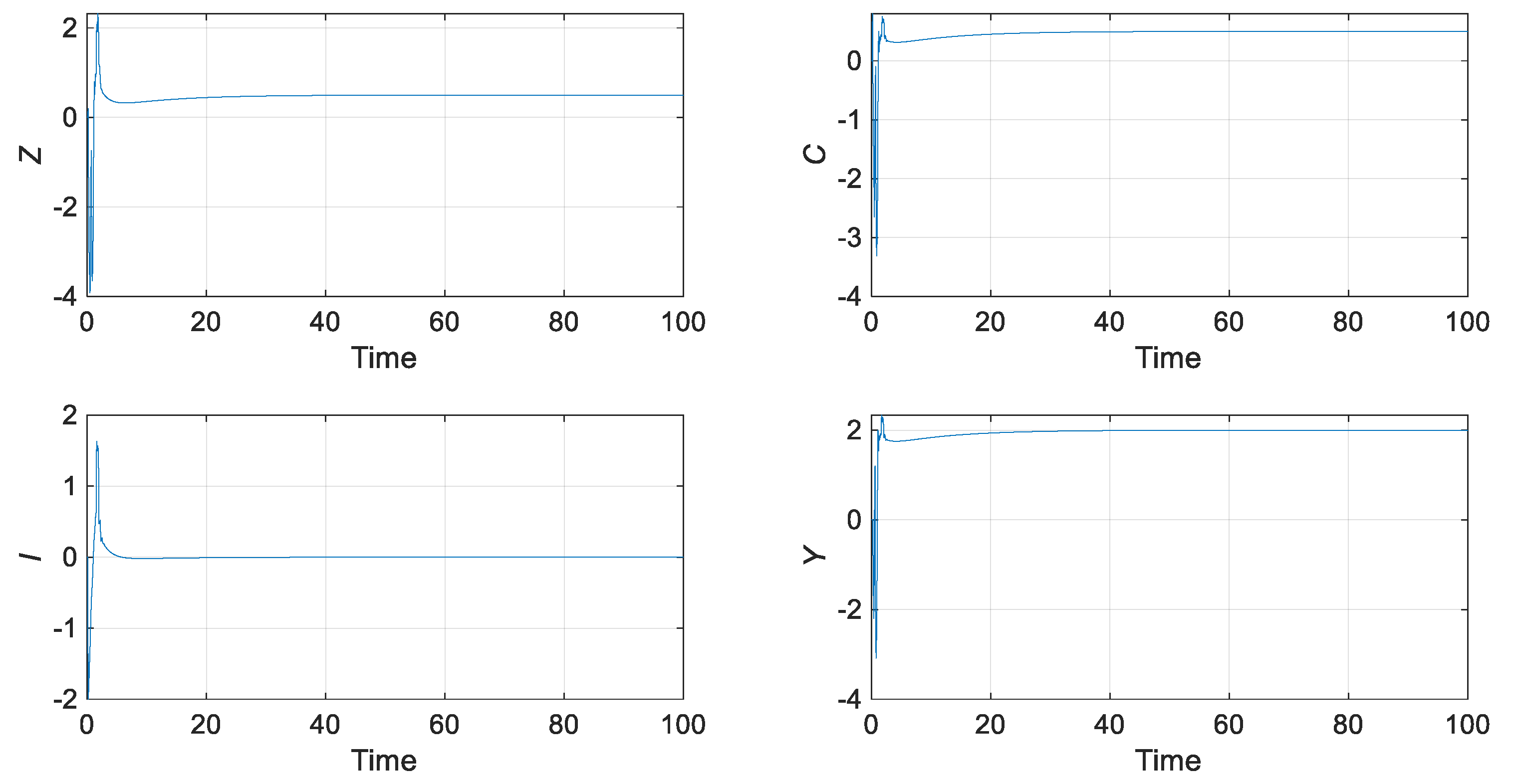
5.1. Dynamical investigation
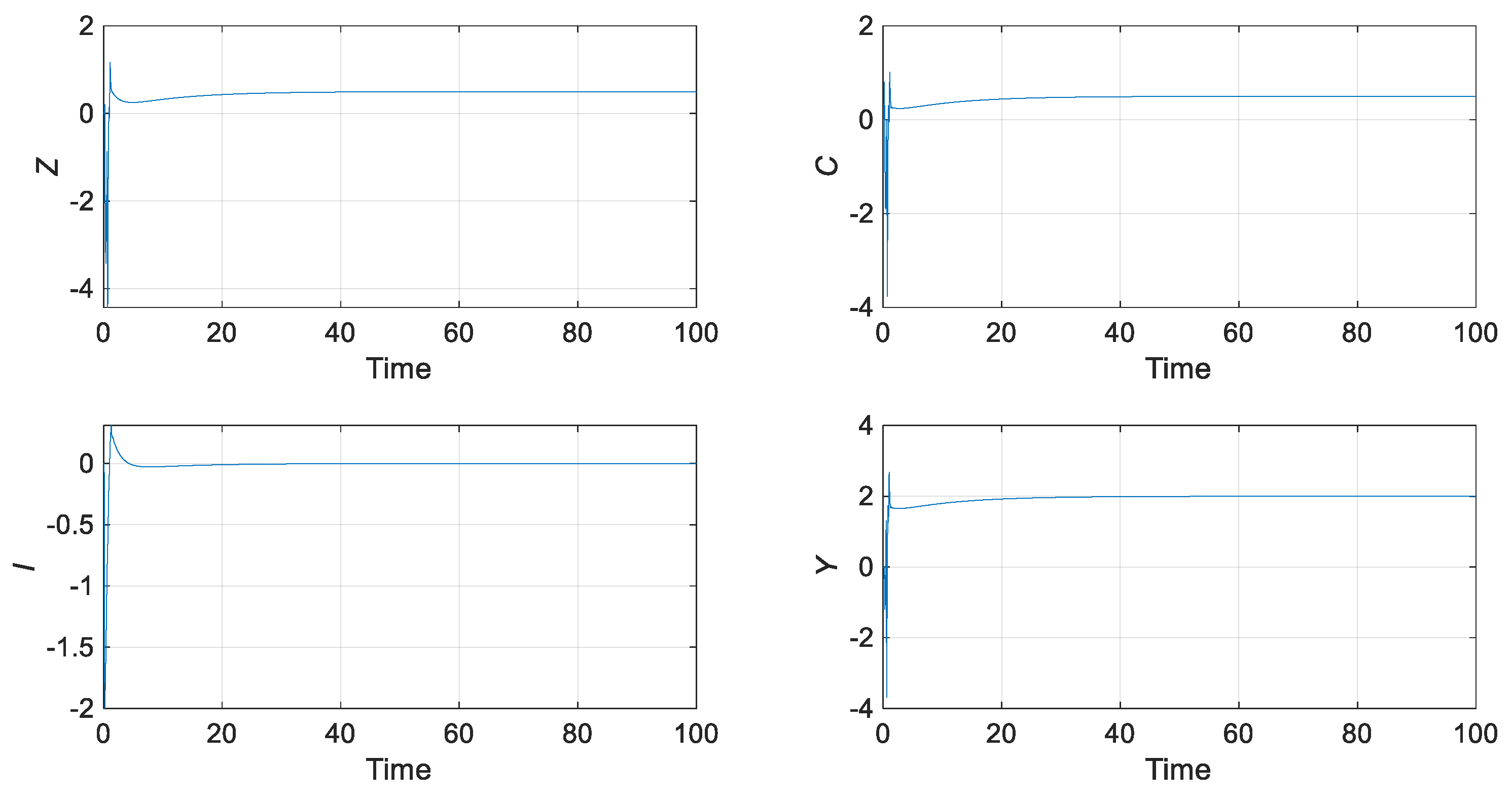
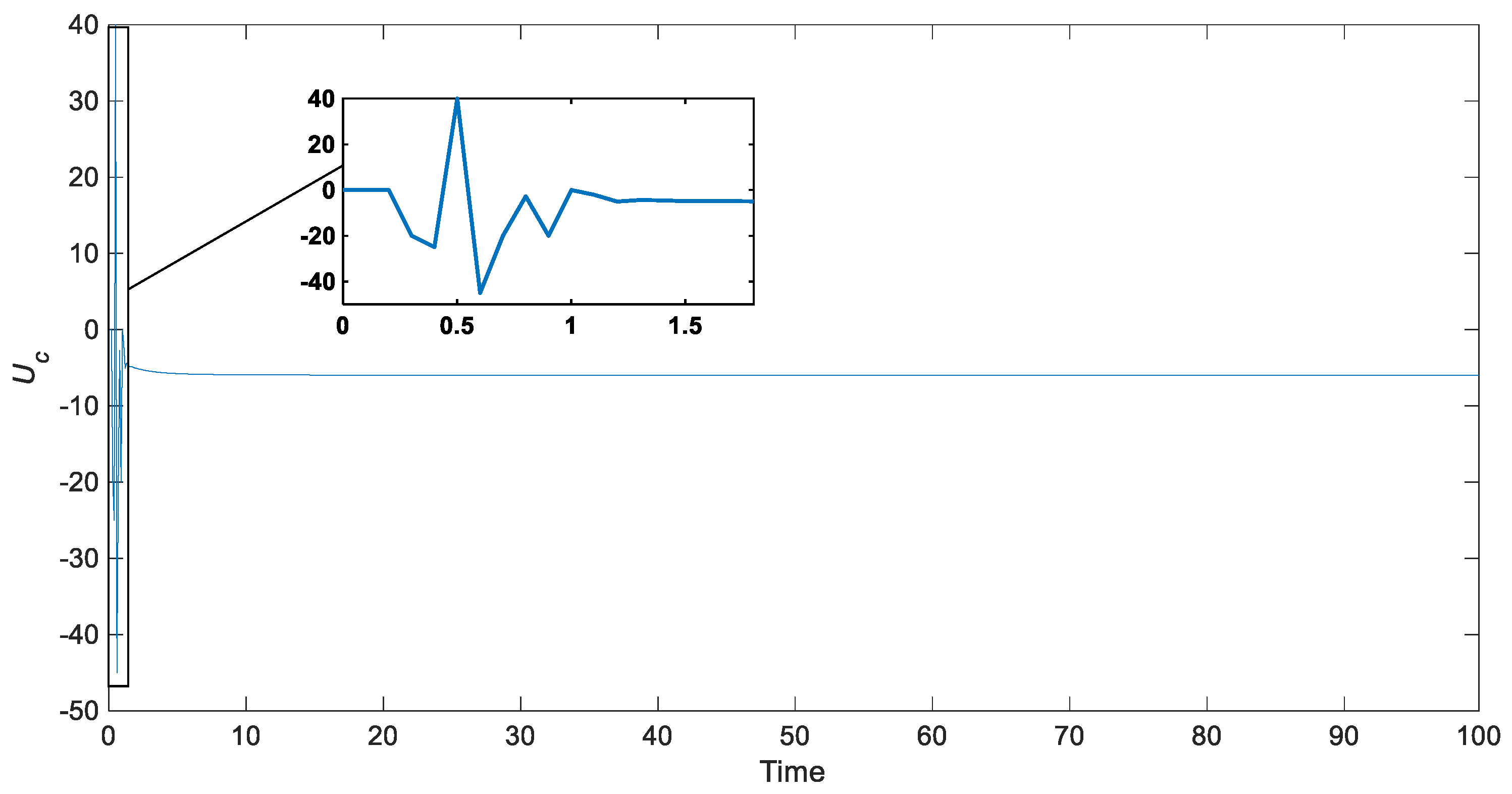
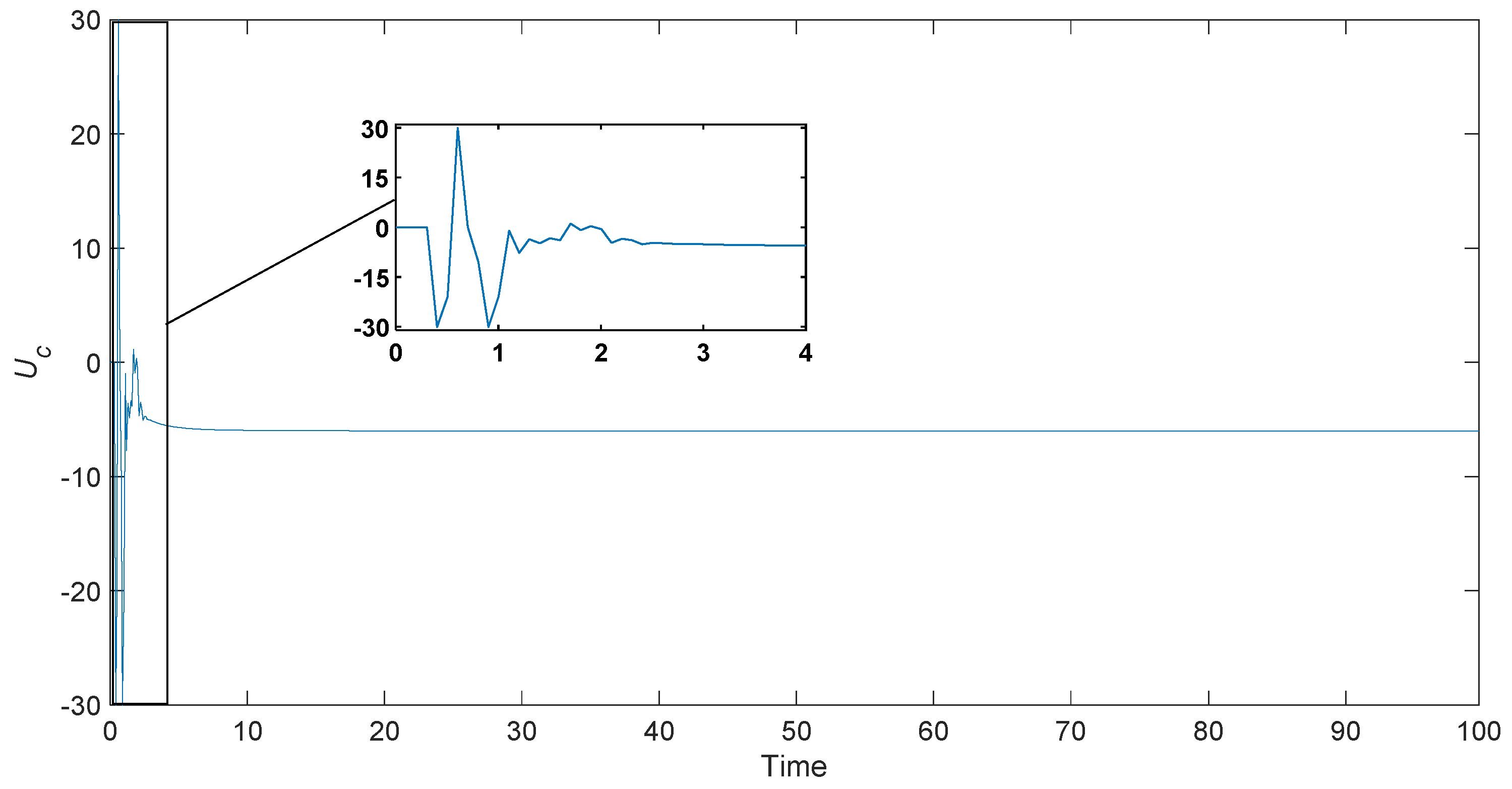
5.2. Control Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lai, Q.; Wan, Z.; Kuate, P.D.K.; Fotsin, H. Coexisting attractors, circuit implementation and synchronization control of a new chaotic system evolved from the simplest memristor chaotic circuit. Commun. Nonlinear Sci. Numer. Simul. 2020, 89, 105341. [Google Scholar] [CrossRef]
- Zhu, Z.-Y.; Zhao, Z.-S.; Zhang, J.; Wang, R.-K.; Li, Z. Adaptive fuzzy control design for synchronization of chaotic time-delay system. Inf. Sci. 2020, 535, 225–241. [Google Scholar] [CrossRef]
- Jahanshahi, H.; Yousefpour, A.; Munoz-Pacheco, J.M.; Kacar, S.; Pham, V.-T.; Alsaadi, F.E. A new fractional-order hyperchaotic memristor oscillator: Dynamic analysis, robust adaptive synchronization, and its application to voice encryption. Appl. Math. Comput. 2020, 383, 125310. [Google Scholar] [CrossRef]
- Han, Z.; Li, S.; Liu, H. Composite learning sliding mode synchronization of chaotic fractional-order neural networks. J. Adv. Res. 2020, 25, 87–96. [Google Scholar] [CrossRef] [PubMed]
- Kosari, A.; Jahanshahi, H.; Razavi, S. An optimal fuzzy PID control approach for docking maneuver of two spacecraft: Orientational motion. Eng. Sci. Technol. Int. J. 2017, 20, 293–309. [Google Scholar] [CrossRef] [Green Version]
- Wang, B.; Jahanshahi, H.; Volos, C.; Bekiros, S.; Khan, M.; Agarwal, P.; Aly, A. A New RBF Neural Network-Based Fault-Tolerant Active Control for Fractional Time-Delayed Systems. Electron. 2021, 10, 1501. [Google Scholar] [CrossRef]
- Wang, H.; Jahanshahi, H.; Wang, M.-K.; Bekiros, S.; Liu, J.; Aly, A. A Caputo–Fabrizio Fractional-Order Model of HIV/AIDS with a Treatment Compartment: Sensitivity Analysis and Optimal Control Strategies. Entropy 2021, 23, 610. [Google Scholar] [CrossRef]
- Jahanshahi, H.; Yousefpour, A.; Munoz-Pacheco, J.M.; Moroz, I.; Wei, Z.; Castillo, O. A new multi-stable fractional-order four-dimensional system with self-excited and hidden chaotic attractors: Dynamic analysis and adaptive synchronization using a novel fuzzy adaptive sliding mode control method. Appl. Soft Comput. 2020, 87, 105943. [Google Scholar] [CrossRef]
- Chen, Y.-J.; Chou, H.-G.; Wang, W.-J.; Tsai, S.-H.; Tanaka, K.; Wang, H.O.; Wang, K.-C. A polynomial-fuzzy-model-based synchronization methodology for the multi-scroll Chen chaotic secure communication system. Eng. Appl. Artif. Intell. 2020, 87, 103251. [Google Scholar] [CrossRef]
- Wang, B.; Liu, J.; Alassafi, M.O.; Alsaadi, F.E.; Jahanshahi, H.; Bekiros, S. Intelligent parameter identification and prediction of variable time fractional derivative and application in a symmetric chaotic financial system. Chaos Solitons Fractals 2021, 154, 111590. [Google Scholar] [CrossRef]
- Wang, R.; Zhang, Y.; Chen, Y.; Chen, X.; Xi, L. Fuzzy neural network-based chaos synchronization for a class of fractional-order chaotic systems: An adaptive sliding mode control approach. Nonlinear Dyn. 2020, 100, 1275–1287. [Google Scholar] [CrossRef]
- Jahanshahi, H.; Shahriari-Kahkeshi, M.; Alcaraz, R.; Wang, X.; Singh, V.P.; Pham, V.-T. Entropy Analysis and Neural Network-Based Adaptive Control of a Non-Equilibrium Four-Dimensional Chaotic System with Hidden Attractors. Entropy 2019, 21, 156. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rostam, M.; Nagamune, R.; Grebenyuk, V. A hybrid Gaussian process approach to robust economic model predictive control. J. Process Control 2020, 92, 149–160. [Google Scholar] [CrossRef]
- Rajaei, A.; Vahidi-Moghaddam, A.; Ayati, M.; Baghani, M. Integral sliding mode control for nonlinear damped model of arch microbeams. Microsyst. Technol. 2018, 25, 57–68. [Google Scholar] [CrossRef]
- Yousefpour, A.; Vahidi-Moghaddam, A.; Rajaei, A.; Ayati, M. Stabilization of nonlinear vibrations of carbon nanotubes using observer-based terminal sliding mode control. Trans. Inst. Meas. Control 2019, 42, 1047–1058. [Google Scholar] [CrossRef]
- Rao, M. Filtering and Control of Macroeconomic Systems: A Control System Incorporating the Kalman Filter for the Indian Economy; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Barnett, W.A.; He, S. Unsolved Econometric Problems in Nonlinearity, Chaos, and Bifurcation; University of Kansas, Department of Economics: Lawrence, KS, USA, 2012. [Google Scholar]
- Jahanshahi, H.; Yousefpour, A.; Wei, Z.; Alcaraz, R.; Bekiros, S. A financial hyperchaotic system with coexisting attractors: Dynamic investigation, entropy analysis, control and synchronization. Chaos Solitons Fractals 2019, 126, 66–77. [Google Scholar] [CrossRef]
- Wang, S.; He, S.; Yousefpour, A.; Jahanshahi, H.; Repnik, R.; Perc, M. Chaos and complexity in a fractional-order financial system with time delays. Chaos Solitons Fractals 2020, 131, 109521. [Google Scholar] [CrossRef]
- Keller, A. Fuzzy control of macroeconomic models. Int. J. Appl. Math. Comput. Sci. 2009, 5, 115. [Google Scholar]
- Wang, S.; Bekiros, S.; Yousefpour, A.; He, S.; Castillo, O.; Jahanshahi, H. Synchronization of fractional time-delayed financial system using a novel type-2 fuzzy active control method. Chaos Solitons Fractals 2020, 136, 109768. [Google Scholar] [CrossRef]
- Jahanshahi, H.; Sajjadi, S.S.; Bekiros, S.; Aly, A.A. On the development of variable-order fractional hyperchaotic economic system with a nonlinear model predictive controller. Chaos Solitons Fractals 2021, 144, 110698. [Google Scholar] [CrossRef]
- Allgöwer, F.; Zheng, A. Nonlinear Model Predictive Control; Birkhäuser: Basel, Switzerland, 2012; Volume 26. [Google Scholar]
- Camacho, E.; Alba, C. Model Predictive Control; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Jahanshahi, H.; Sari, N.N.; Pham, V.-T.; E Alsaadi, F.; Hayat, T. Optimal adaptive higher order controllers subject to sliding modes for a carrier system. Int. J. Adv. Robot. Syst. 2018, 15, 1729881418782097. [Google Scholar] [CrossRef]
- Jahanshahi, H. Smooth control of HIV/AIDS infection using a robust adaptive scheme with decoupled sliding mode supervision. Eur. Phys. J. Spéc. Top. 2018, 227, 707–718. [Google Scholar] [CrossRef]
- Yousefpour, A.; Jahanshahi, H. Fast disturbance-observer-based robust integral terminal sliding mode control of a hyperchaotic memristor oscillator. Eur. Phys. J. Spéc. Top. 2019, 228, 2247–2268. [Google Scholar] [CrossRef]
- Xiong, P.-Y.; Jahanshahi, H.; Alcaraz, R.; Chu, Y.-M.; Gómez-Aguilar, J.; Alsaadi, F.E. Spectral Entropy Analysis and Synchronization of a Multi-Stable Fractional-Order Chaotic System using a Novel Neural Network-Based Chattering-Free Sliding Mode Technique. Chaos Solitons Fractals 2021, 144, 110576. [Google Scholar] [CrossRef]
- Wang, Y.-L.; Jahanshahi, H.; Bekiros, S.; Bezzina, F.; Chu, Y.-M.; Aly, A.A. Deep recurrent neural networks with finite-time terminal sliding mode control for a chaotic fractional-order financial system with market confidence. Chaos Solitons Fractals 2021, 146, 110881. [Google Scholar] [CrossRef]
- Wang, B.; Jahanshahi, H.; Volos, C.; Bekiros, S.; Yusuf, A.; Agarwal, P.; Aly, A. Control of a Symmetric Chaotic Supply Chain System Using a New Fixed-Time Super-Twisting Sliding Mode Technique Subject to Control Input Limitations. Symmetry 2021, 13, 1257. [Google Scholar] [CrossRef]
- Wang, B.; Jahanshahi, H.; Dutta, H.; Zambrano-Serrano, E.; Grebenyuk, V.; Bekiros, S.; Aly, A.A. Incorporating fast and intelligent control technique into ecology: A Chebyshev neural network-based terminal sliding mode approach for fractional chaotic ecological systems. Ecol. Complex. 2021, 47, 100943. [Google Scholar] [CrossRef]
- Wang, B.; Derbeli, M.; Barambones, O.; Yousefpour, A.; Jahanshahi, H.; Bekiros, S.; Aly, A.A.; Alharthi, M.M. Experimental validation of disturbance observer-based adaptive terminal sliding mode control subject to control input limitations for SISO and MIMO systems. Eur. J. Control 2021. [Google Scholar] [CrossRef]
- Jahanshahi, H.; Rajagopal, K.; Akgul, A.; Sari, N.N.; Namazi, H.; Jafari, S. Complete analysis and engineering applications of a megastable nonlinear oscillator. Int. J. Non-linear Mech. 2018, 107, 126–136. [Google Scholar] [CrossRef]
- Li, J.-F.; Jahanshahi, H.; Kacar, S.; Chu, Y.-M.; Gómez-Aguilar, J.; Alotaibi, N.D.; Alharbi, K.H. On the variable-order fractional memristor oscillator: Data security applications and synchronization using a type-2 fuzzy disturbance observer-based robust control. Chaos Solitons Fractals 2021, 145, 110681. [Google Scholar] [CrossRef]
- Bekiros, S.; Jahanshahi, H.; Bezzina, F.; Aly, A. A novel fuzzy mixed H2/H∞ optimal controller for hyperchaotic financial systems. Chaos Solitons Fractals 2021, 146, 110878. [Google Scholar] [CrossRef]
- Tutueva, A.V.; Moysis, L.; Rybin, V.G.; Kopets, E.E.; Volos, C.; Butusov, D.N. Fast synchronization of symmetric Hénon maps using adaptive symmetry control. Chaos Solitons Fractals 2021, 155, 111732. [Google Scholar] [CrossRef]
- Liu, Z.; Jahanshahi, H.; Volos, C.; Bekiros, S.; He, S.; Alassafi, M.O.; Ahmad, A.M. Distributed Consensus Tracking Control of Chaotic Multi-Agent Supply Chain Network: A New Fault-Tolerant, Finite-Time, and Chatter-Free Approach. Entropy 2021, 24, 33. [Google Scholar] [CrossRef] [PubMed]
- Al-Hussein, A.-B.; Tahir, F.; Ouannas, A.; Sun, T.-C.; Jahanshahi, H.; Aly, A. Chaos Suppressing in a Three-Buses Power System Using an Adaptive Synergetic Control Method. Electron. 2021, 10, 1532. [Google Scholar] [CrossRef]
- Yousefpour, A.; Jahanshahi, H.; Bekiros, S.; Muñoz-Pacheco, J.M. Robust adaptive control of fractional-order memristive neural networks. In Mem-Elements for Neuromorphic Circuits with Artificial Intelligence Applications; Elsevier BV: Amsterdam, The Netherlands, 2021; pp. 501–515. [Google Scholar]
- Bhuvaneswari, N.; Uma, G.; Rangaswamy, T. Adaptive and optimal control of a non-linear process using intelligent controllers. Appl. Soft Comput. 2009, 9, 182–190. [Google Scholar] [CrossRef]
- Zak, M. Expectation-based intelligent control. Chaos Solitons Fractals 2006, 28, 616–626. [Google Scholar] [CrossRef]
- Chen, X. Research on application of artificial intelligence model in automobile machinery control system. Int. J. Heavy Veh. Syst. 2020, 27, 83. [Google Scholar] [CrossRef]
- Das, P.; Chanda, S.; De, A. Artificial Intelligence-Based Economic Control of Micro-grids: A Review of Application of IoT. In Lecture Notes in Electrical Engineering; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2019; pp. 145–155. [Google Scholar]
- Yousefpour, A.; Jahanshahi, H.; Munoz-Pacheco, J.M.; Bekiros, S.; Wei, Z. A fractional-order hyper-chaotic economic system with transient chaos. Chaos Solitons Fractals 2020, 130, 109400. [Google Scholar] [CrossRef]
- Ho, Y.-C. Neuro-fuzzy And Soft Computing - A Computational Approach To Learning And Machine Intelligence [Book Reviews]. Proc. IEEE 1998, 86, 600–603. [Google Scholar]
- Woelfel, J. Convergences in cognitive science, social network analysis, pattern recognition and machine intelligence as dynamic processes in non-Euclidean space. Qual. Quant. 2020, 54, 263–278. [Google Scholar] [CrossRef]
- Sutton, R.; Barto, A. Introduction to Reinforcement Learning; MIT press Cambridge: Cambridge, MA, USA, 1998; Volume 135. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement Learning: A Survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef] [Green Version]
- Szepesvári, C. Algorithms for reinforcement learning. Synth. Lect. Artif. Intell. Mach. Learn. 2010, 4, 1–103. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Padmanabhan, R.; Meskin, N.; Haddad, W.M. Reinforcement learning-based control of drug dosing for cancer chemotherapy treatment. Math. Biosci. 2017, 293, 11–20. [Google Scholar] [CrossRef] [PubMed]
- Bucci, M.A.; Semeraro, O.; Allauzen, A.; Wisniewski, G.; Cordier, L.; Mathelin, L. Control of chaotic systems by deep reinforcement learning. In Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences; The Royal Society: London, UK, 2019; Volume 475, p. 20190351. [Google Scholar]
- Mao, Y.; Wang, J.; Jia, P.; Li, S.; Qiu, Z.; Zhang, L.; Han, Z. A Reinforcement Learning Based Dynamic Walking Control. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 3609–3614. [Google Scholar]
- Qiao, J.; Hou, Z.; Ruan, X. Application of reinforcement learning based on neural network to dynamic obstacle avoidance. In Proceedings of the 2008 International Conference on Information and Automation, Changsha, China, 20–23 June 2008; pp. 784–788. [Google Scholar]
- Wei, C.; Zhang, Z.; Qiao, W.; Qu, L. Reinforcement-Learning-Based Intelligent Maximum Power Point Tracking Control for Wind Energy Conversion Systems. IEEE Trans. Ind. Electron. 2015, 62, 6360–6370. [Google Scholar] [CrossRef]
- Balashevich, N.; Gabasov, R.; Kalinin, A.; Kirillova, F. Optimal control of nonlinear systems. Comput. Math. Math. Phys. 2002, 42, 931–956. [Google Scholar]
- Aliyu, M.D.S. An improved iterative computational approach to the solution of the Hamilton–Jacobi equation in optimal control problems of affine nonlinear systems with application. Int. J. Syst. Sci. 2020, 51, 2625–2634. [Google Scholar] [CrossRef]
- Watkins, C.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Sutton, R.S.; Barto, A.G.; Williams, R.J. Reinforcement learning is direct adaptive optimal control. IEEE Control Syst. 1992, 12, 19–22. [Google Scholar] [CrossRef]
- Kearns, M.; Singh, S. Near-Optimal Reinforcement Learning in Polynomial Time. Mach. Learn. 2002, 49, 209–232. [Google Scholar] [CrossRef] [Green Version]
- Rummery, G.; Niranjan, M. On-Line Q-Learning Using Connectionist Systems; University of Cambridge, Department of Engineering: Cambridge, UK, 1994; Volume 37. [Google Scholar]
- Wei, Q.; Lewis, F.L.; Sun, Q.; Yan, P.; Song, R. Discrete-Time Deterministic Q- -Learning: A Novel Convergence Analysis. IEEE Trans. Cybern. 2016, 47, 1224–1237. [Google Scholar] [CrossRef]
- Melo, F.S.; Ribeiro, M.I. Convergence of Q-learning with linear function approximation. In Proceedings of the 2007 European Control Conference (ECC), Kos, Greece, 2–5 July 2007; pp. 2671–2678. [Google Scholar]
- Puu, T. Multiplier-Accelerator Models Revisited. In Economics of Space and Time; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 1997; pp. 145–159. [Google Scholar]
- White, M.V.; Rosser, J.B. From Catastrophe to Chaos: A General Theory of Economic Discontinuities. South. Econ. J. 1992, 59, 350. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1 | 13 | ||
| 2 | 14 | ||
| 3 | 15 | ||
| 4 | 16 | ||
| 5 | 17 | ||
| 6 | 18 | ||
| 7 | 19 | ||
| 8 | 20 | ||
| 9 | 21 | ||
| 10 | 22 | ||
| 11 | 23 | ||
| 12 | 24 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, Q.; Jahanshahi, H.; Wang, Y.; Bekiros, S.; Alassafi, M.O. Optimal Reinforcement Learning-Based Control Algorithm for a Class of Nonlinear Macroeconomic Systems. Mathematics 2022, 10, 499. https://doi.org/10.3390/math10030499
Ding Q, Jahanshahi H, Wang Y, Bekiros S, Alassafi MO. Optimal Reinforcement Learning-Based Control Algorithm for a Class of Nonlinear Macroeconomic Systems. Mathematics. 2022; 10(3):499. https://doi.org/10.3390/math10030499
Chicago/Turabian StyleDing, Qing, Hadi Jahanshahi, Ye Wang, Stelios Bekiros, and Madini O. Alassafi. 2022. "Optimal Reinforcement Learning-Based Control Algorithm for a Class of Nonlinear Macroeconomic Systems" Mathematics 10, no. 3: 499. https://doi.org/10.3390/math10030499