


Convolution Based Graph Representation Learning from the Perspective of High Order Node Similarities

Abstract
:1. Introduction
2. Related Work
2.1. Graph Neural Networks
2.2. Node Similarities
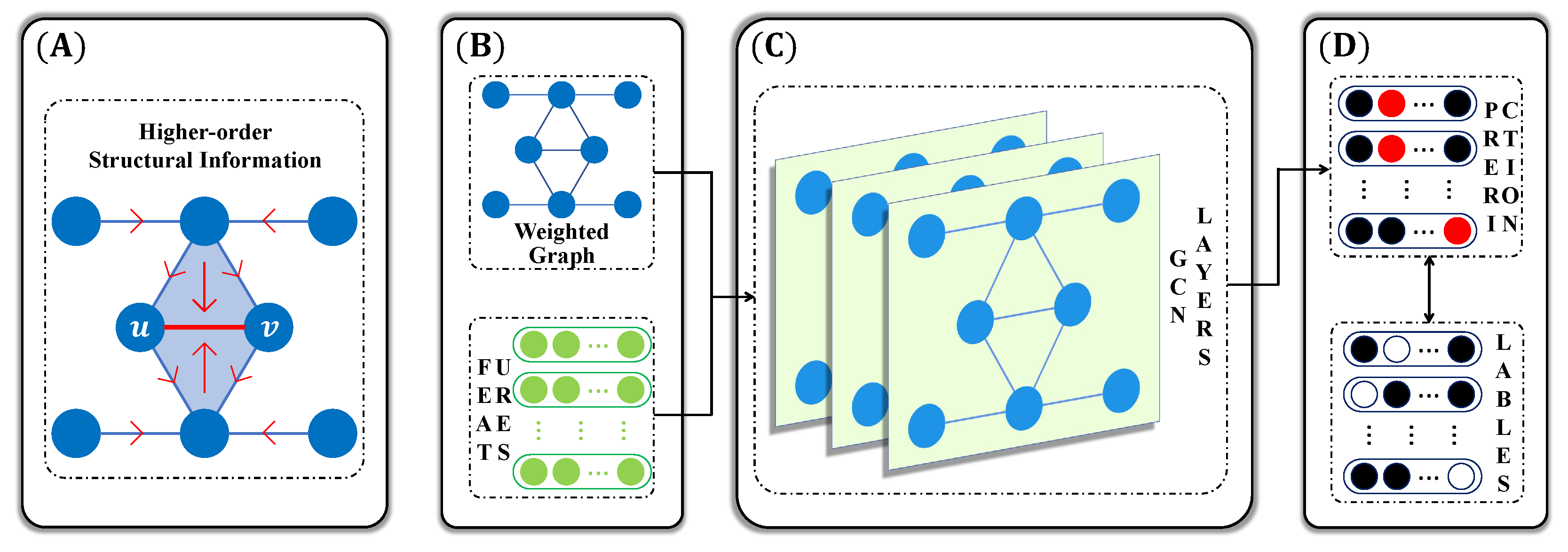
3. Method
3.1. Algorithm
| Algorithm 1: HS-GCN embedding algorithm. |
|
3.2. Theoretical Analysis
4. Experiments
4.1. Datasets
4.2. Experimental Setup and Baselines
- DeepWalk [46] is the well-known random walk based method proposed by Perozzi et al. in 2014. DeepWalk obtains contextual information about nodes by modeling graph structure data as sequences of nodes using random walk.
- Node2vec [47] generalizes DeepWalk, which controls the exploration of node neighborhoods by random walk using two hyperparameters (return parameter and in-out parameter).
- GCN [5] is a semi-supervised GNN model and also the base model of our method.
- GraphSAGE [13] determines node neighborhoods by sampling and can generate embeddings for unseen data. In addition, GraphSAGE allows the use of aggregation functions of a more general form.
- GAT [10] introduces attention mechanism into graph convolution network, which can flexibly aggregate node feature information.
- APPNP [39] is a diffusion based model which introduces PageRank algorithm to GNN, and it reduces computational complexity by iteratively computing the matrix product.
4.3. Results and Analysis
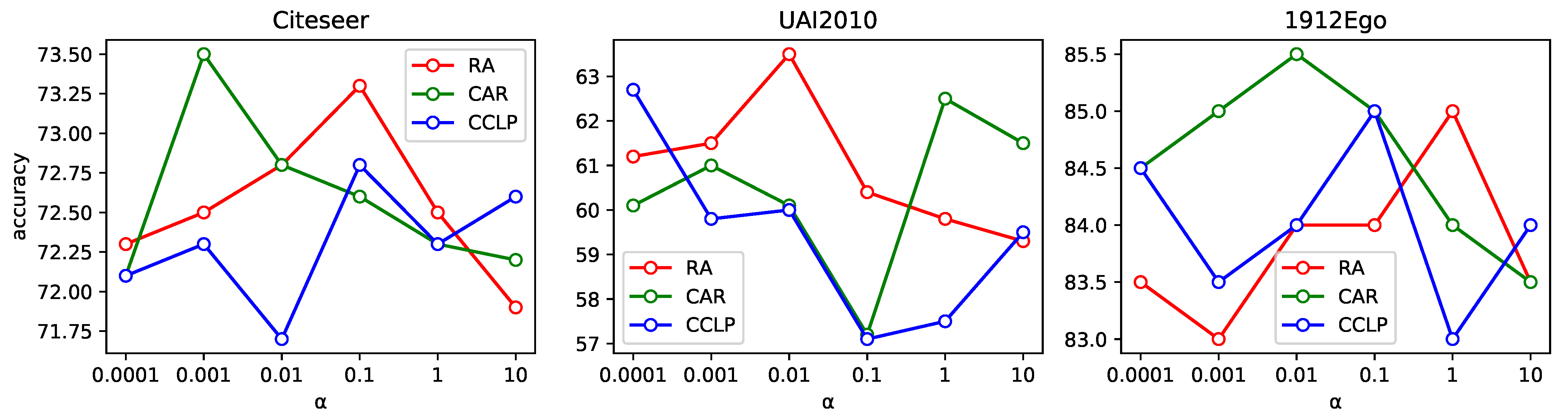
4.4. Hyperparameters
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zeng, X.; Zhang, X.; Liao, Y.; Pan, L. Prediction and validation of association between microRNAs and diseases by multipath methods. Biochim. Biophys. Acta (BBA)-Gen. Subj. 2016, 1860, 2735–2739. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Zeng, X. Integrative approaches for predicting microRNA function and prioritizing disease-related microRNA using biological interaction networks. Bio-Inspired Comput. Model. Algorithms 2019, 75–105. [Google Scholar]
- Kandhway, K.; Kuri, J. Using node centrality and optimal control to maximize information diffusion in social networks. IEEE Trans. Syst. Man Cybern. Syst. 2016, 47, 1099–1110. [Google Scholar] [CrossRef] [Green Version]
- Herzallah, R. Scalable Harmonization of Complex Networks with Local Adaptive Controllers. IEEE Trans. Syst. Man Cybern.-Syst. 2017, 47, 3. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 2017 International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Choong, J.J.; Liu, X.; Murata, T. Learning community structure with variational autoencoder. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Sentosa, Singapore, 17–20 November 2018; IEEE: New York, NY, USA, 2018; pp. 69–78. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [Green Version]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral networks and locally connected networks on graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural Inf. Process. Syst. 2016, 29, 3844–3852. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. Stat 2017, 1050, 20. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Brauwers, G.; Frasincar, F. A General Survey on Attention Mechanisms in Deep Learning. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar] [CrossRef]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Li, G.; Muller, M.; Thabet, A.; Ghanem, B. Deepgcns: Can gcns go as deep as cnns? In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9267–9276. [Google Scholar]
- Li, G.; Xiong, C.; Thabet, A.; Ghanem, B. Deepergcn: All you need to train deeper gcns. arXiv 2020, arXiv:2006.07739. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How powerful are graph neural networks? arXiv 2018, arXiv:1810.00826. [Google Scholar]
- Lv, X.; Wang, Z.L.; Ren, Y.; Yang, D.Z.; Feng, Q.; Sun, B.; Liu, D. Traffic network resilience analysis based on the GCN-RNN prediction model. In Proceedings of the 2019 International Conference on Quality, Reliability, Risk, Maintenance, and Safety Engineering (QR2MSE), Zhangjiajie, China, 6–9 August 2019; IEEE: New York, NY, USA, 2019; pp. 96–103. [Google Scholar]
- Sun, M.; Zhao, S.; Gilvary, C.; Elemento, O.; Zhou, J.; Wang, F. Graph convolutional networks for computational drug development and discovery. Briefings Bioinform. 2020, 21, 919–935. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. Kgat: Knowledge graph attention network for recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 950–958. [Google Scholar]
- Kosaraju, V.; Sadeghian, A.; Martín-Martín, R.; Reid, I.; Rezatofighi, H.; Savarese, S. Social-bigat: Multimodal trajectory forecasting using bicycle-gan and graph attention networks. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Representation learning on graphs: Methods and applications. arXiv 2017, arXiv:1709.05584. [Google Scholar]
- Xia, F.; Sun, K.; Yu, S.; Aziz, A.; Wan, L.; Pan, S.; Liu, H. Graph learning: A survey. IEEE Trans. Artif. Intell. 2021, 2, 109–127. [Google Scholar] [CrossRef]
- Wang, S.; Hu, L.; Wang, Y.; He, X.; Sheng, Q.Z.; Orgun, M.A.; Cao, L.; Ricci, F.; Yu, P.S. Graph learning based recommender systems: A review. arXiv 2021, arXiv:2105.06339. [Google Scholar]
- Jepsen, T.S.; Jensen, C.S.; Nielsen, T.D. Relational Fusion Networks: Graph Convolutional Networks for Road Networks. IEEE Trans. Intell. Transp. Syst. 2022, 23, 418–429. [Google Scholar] [CrossRef]
- Dong, Y.; Liu, Q.; Du, B.; Zhang, L. Weighted feature fusion of convolutional neural network and graph attention network for hyperspectral image classification. IEEE Trans. Image Process. 2022, 31, 1559–1572. [Google Scholar] [CrossRef]
- Kumar, A.; Singh, S.S.; Singh, K.; Biswas, B. Link prediction techniques, applications, and performance: A survey. Phys. A Stat. Mech. Its Appl. 2020, 553, 124289. [Google Scholar] [CrossRef]
- Adamic, L.A.; Adar, E. Friends and neighbors on the web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef] [Green Version]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ravasz, E.; Somera, A.L.; Mongru, D.A.; Oltvai, Z.N.; Barabási, A.L. Hierarchical Organization of Modularity in Metabolic Networks. Science 2002, 297, 1551–1555. [Google Scholar] [CrossRef] [Green Version]
- Dong, Y.; Ke, Q.; Wang, B.; Wu, B. Link Prediction Based on Local Information. In Proceedings of the 2011 International Conference on Advances in Social Networks Analysis and Mining, Kaohsiung, Taiwan, 25–27 July 2011; pp. 382–386. [Google Scholar]
- Katz, L. A new status index derived from sociometric analysis. Psychometrika 1953, 18, 39–43. [Google Scholar] [CrossRef]
- Lorrain, F.; White, H.C. Structural equivalence of individuals in social networks. J. Math. Sociol. 1971, 1, 49–80. [Google Scholar] [CrossRef]
- Salton, G.; McGill, M.J. Introduction to Modern Information Retrieval; Mcgraw-Hill: New York, NY, USA, 1983; p. 448. [Google Scholar]
- Sorensen, T. A method of establishing groups of equal amplitude in plant sociology based on similarity of species content, and its application to analyses of the vegetation on Danish commons. K. Dan. Vidensk. Selsk. Skr. 1948, 5, 1–34. [Google Scholar]
- Leicht, E.A.; Holme, P.; Newman, M.E.J. Vertex similarity in networks. Phys. Rev. E 2006, 73, 026120. [Google Scholar] [CrossRef] [Green Version]
- Zhou, T.; Lü, L.; Zhang, Y.C. Predicting missing links via local information. Eur. Phys. J. B 2009, 71, 623–630. [Google Scholar] [CrossRef] [Green Version]
- Cannistraci, C.V.; Alanis-Lobato, G.; Ravasi, T. From link-prediction in brain connectomes and protein interactomes to the local-community-paradigm in complex networks. Sci. Rep. 2013, 3, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, Z.; Lin, Y.; Wang, J.; Gregory, S. Link prediction with node clustering coefficient. Phys. A Stat. Mech. Its Appl. 2016, 452, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Klicpera, J.; Bojchevski, A.; Günnemann, S. Predict then propagate: Graph neural networks meet personalized pagerank. arXiv 2018, arXiv:1810.05997. [Google Scholar]
- Milo, R.; Shen-Orr, S.; Itzkovitz, S.; Kashtan, N.; Chktovskii, D.; Alan, U. Network Motifs: Simple Building Blocks of Complex Networks. Science 2011, 298, 824–827. [Google Scholar] [CrossRef]
- Aktas, M.E.; Nguyen, T.; Jawaid, S.; Riza, R.; Akbas, E. Identifying critical higher-order interactions in complex networks. Sci. Rep. 2021, 11, 21288. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Ji, H.; Shi, C.; Wang, B.; Ye, Y.; Cui, P.; Yu, P.S. Heterogeneous Graph Attention Network. In Proceedings of the 2019 The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2022–2032. [Google Scholar]
- Wang, W.; Liu, X.; Jiao, P.; Chen, X.; Jin, D. A Unified Weakly Supervised Framework for Community Detection and Semantic Matching. In Proceedings of the 2018 Advances in Knowledge Discovery and Data Mining, Melbourne, VIC, Australia, 3–6 June 2018; pp. 218–230. [Google Scholar]
- Wang, X.; Zhu, M.; Bo, D.; Cui, P.; Shi, C.; Pei, J. Am-gcn: Adaptive multi-channel graph convolutional networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 1243–1253. [Google Scholar]
- McAuley, J.; Leskovec, J. Learning to Discover Social Circles in Ego Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems (NIPS’12), Lake Tahoe, NV, USA, 3–6 December 2012; Volume 1, pp. 539–547. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Weisfeiler, B.Y.; Leman, A.A. A reduction of a Graph to a Canonical Form and an Algebra Arising during this Reduction. Nauchno-Tech. Inf. 1968, 2, 12–16. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Datasets | Nodes | Edges | Features | Classes | |
|---|---|---|---|---|---|
| Cora | 2708 | 5429 | 1433 | 7 | 4.0 |
| Citeseer | 3327 | 4732 | 3703 | 6 | 2.8 |
| Pubmed | 19,717 | 44,338 | 500 | 3 | 4.5 |
| ACM | 3025 | 13,128 | 1870 | 3 | 8.7 |
| UAI2010 | 3067 | 28,311 | 4973 | 19 | 18.5 |
| 414Ego | 159 | 3386 | 105 | 7 | 42.6 |
| 1912Ego | 755 | 60,050 | 480 | 46 | 159.1 |
| 2106Ego | 2457 | 174,309 | 2094 | 2 | 141.9 |
| Method | Cora | Citeseer | Pubmed | ACM |
|---|---|---|---|---|
| DeepWalk | 67.2 | 43.2 | 65.3 | 62.8 |
| Node2vec | 67.9 | 51.5 | 69.1 | 64.2 |
| GCN | 81.6 | 71.0 | 79.5 | 87.8 |
| GraphSAGE | 82.6 | 71.2 | 78.5 | 86.4 |
| GIN | 82.8 | 71.4 | 79.6 | 78.1 |
| GAT | 83.4 | 71.7 | 79.0 | 87.4 |
| APPNP | 83.6 | 72.1 | 80.0 | 85.4 |
| HS-GCN | 83.0 | 73.5 | 80.3 | 87.9 |
| Method | UAI2010 | 414Ego | 1912Ego | 2106Ego |
| DeepWalk | 42.4 | 79.2 | 66.5 | 75.8 |
| Node2vec | 44.0 | 91.7 | 75.0 | 82.4 |
| GCN | 51.6 | 93.8 | 77.0 | 95.6 |
| GraphSAGE | 54.5 | 91.7 | 82.0 | 94.3 |
| GIN | 52.9 | 95.8 | 82.5 | 93.4 |
| GAT | 57.2 | 93.8 | 77.0 | 87.4 |
| APPNP | 62.9 | 97.9 | 82.5 | 96.3 |
| HS-GCN | 63.1 | 97.9 | 85.5 | 97.8 |
| Method | Cora | Citeseer | Pubmed | ACM |
|---|---|---|---|---|
| HS-GCN(RA)- | 82.0 | 72.5 | 79.8 | 87.0 |
| HS-GCN(RA) | 83.0 | 73.3 | 80.0 | 87.4 |
| HS-GCN(CAR)- | 82.0 | 72.7 | 79.9 | 87.2 |
| HS-GCN(CAR) | 82.7 | 73.5 | 80.2 | 87.9 |
| HS-GCN(CCLP)- | 81.8 | 72.6 | 79.7 | 86.8 |
| HS-GCN(CCLP) | 82.5 | 72.8 | 80.3 | 87.3 |
| Method | UAI2010 | 414Ego | 1912Ego | 2106Ego |
| HS-GCN(RA)- | 61.7 | 95.8 | 84.5 | 95.6 |
| HS-GCN(RA) | 63.5 | 97.9 | 85.0 | 96.7 |
| HS-GCN(CAR)- | 61.9 | 97.9 | 84.0 | 96.2 |
| HS-GCN(CAR) | 63.1 | 97.9 | 85.5 | 97.8 |
| HS-GCN(CCLP)- | 61.7 | 97.9 | 84.0 | 95.6 |
| HS-GCN(CCLP) | 62.7 | 97.9 | 85.0 | 96.7 |
| Method | Cora | Citeseer | Pubmed | ACM |
|---|---|---|---|---|
| HS-GCN(CN) | 82.1 | 72.8 | 80.0 | 87.2 |
| HS-GCN(SA) | 82.5 | 72.9 | 80.0 | 87.2 |
| HS-GCN(SO) | 82.3 | 72.6 | 80.0 | 87.1 |
| HS-GCN(HPI) | 82.2 | 73.2 | 80.1 | 87.2 |
| HS-GCN(HDI) | 82.2 | 73.3 | 79.8 | 87.3 |
| HS-GCN(LLHN) | 82.1 | 73.1 | 80.3 | 87.3 |
| HS-GCN(PA) | 82.4 | 72.9 | 80.1 | 87.3 |
| HS-GCN | 83.0 | 73.5 | 80.3 | 87.9 |
| Method | UAI2010 | 414Ego | 1912Ego | 2106Ego |
| HS-GCN(CN) | 62.7 | 97.9 | 85.0 | 95.6 |
| HS-GCN(SA) | 62.5 | 97.9 | 85.0 | 95.6 |
| HS-GCN(SO) | 62.7 | 97.9 | 85.5 | 95.6 |
| HS-GCN(HPI) | 62.3 | 97.9 | 84.5 | 96.7 |
| HS-GCN(HDI) | 62.3 | 97.9 | 85.5 | 95.6 |
| HS-GCN(LLHN) | 62.8 | 97.9 | 84.5 | 96.7 |
| HS-GCN(PA) | 62.1 | 97.9 | 85.0 | 97.8 |
| HS-GCN | 63.1 | 97.9 | 85.5 | 97.8 |
| Cora | Citeseer | Pubmed | ACM | |
|---|---|---|---|---|
| HS-GCN(RA) | 5, 0.0001 | 0.5, 0.1 | 10, 0.01 | 5, 1 |
| HS-GCN(CAR) | 5, 0.1 | 0.5, 0.001 | 10, 1 | 5, 0.01 |
| HS-GCN(CCLP) | 5, 0.01 | 1, 0.1 | 5, 0.1 | 1, 0.0001 |
| UAI2010 | 414Ego | 1912Ego | 2106Ego | |
| HS-GCN(RA) | 0.5, 0.01 | 1, 1 | 0.5, 1 | 5, 0.001 |
| HS-GCN(CAR) | 0.5, 1 | 5, 1 | 0.5, 0.01 | 1, 0.0001 |
| HS-GCN(CCLP) | 0.5, 0.0001 | 1, 0.1 | 5, 0.1 | 1, 0.001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Li, Q.; Wei, W.; Zheng, Z. Convolution Based Graph Representation Learning from the Perspective of High Order Node Similarities. Mathematics 2022, 10, 4586. https://doi.org/10.3390/math10234586
Li X, Li Q, Wei W, Zheng Z. Convolution Based Graph Representation Learning from the Perspective of High Order Node Similarities. Mathematics. 2022; 10(23):4586. https://doi.org/10.3390/math10234586
Chicago/Turabian StyleLi, Xing, Qingsong Li, Wei Wei, and Zhiming Zheng. 2022. "Convolution Based Graph Representation Learning from the Perspective of High Order Node Similarities" Mathematics 10, no. 23: 4586. https://doi.org/10.3390/math10234586