


A Double Penalty Model for Ensemble Learning


1
Data Science and Analytics Thrust, The Hong Kong University of Science and Technology (Guangzhou), Guangzhou 510000, China
2
Departments of Biological Sciences and Statistics, North Carolina State University, Raleigh, NC 27695, USA
*
Author to whom correspondence should be addressed.
Mathematics 2022, 10(23), 4532; https://doi.org/10.3390/math10234532
Submission received: 28 October 2022
/
Revised: 21 November 2022
/
Accepted: 23 November 2022
/
Published: 30 November 2022
(This article belongs to the Topic Machine and Deep Learning)
Abstract
:Modern statistical learning techniques often include learning ensembles, for which the combination of multiple separate prediction procedures (ensemble components) can improve prediction accuracy. Although ensemble approaches are widely used, work remains to improve our understanding of the theoretical underpinnings of aspects such as identifiability and relative convergence rates of the ensemble components. By considering ensemble learning for two learning ensemble components as a double penalty model, we provide a framework to better understand the relative convergence and identifiability of the two components. In addition, with appropriate conditions the framework provides convergence guarantees for a form of residual stacking when iterating between the two components as a cyclic coordinate ascent procedure. We conduct numerical experiments on three synthetic simulations and two real world datasets to illustrate the performance of our approach, and justify our theory.
MSC:
62G08; 62P10; 62J021. Introduction
Ensemble learning [1] uses multiple learning algorithms together to produce an improved prediction rule. Early work on ensemble learning [2] emphasized diversity of ensemble learning components [3], while much subsequent literature concerned collections of weak or strong learners [4]. Aggregation methods such as bagging [5] are technically ensemble methods, but the components are all of similar kind, and this paper is largely concerned with ensembles over different kinds of “strong learners”.
One practical approach to ensemble learning is to perform stacked ensemble approaches sequentially, using the residuals from one model as the input for the next [6]. This approach has been used in kaggle competitions [7], with the potential convenience that different analysts can analyze the data separately in succession. This approach has a connection to boosting, in that (pseudo)residuals focus attention on the poorly-fit observations [8].
For a researcher intending to fit multiple learning models, the practice of starting with an “interpretable” or low-dimensional model favors parsimony in explaining the relationship of predictors to outcome. Much of machine learning development has focused on prediction accuracy as a primary criterion [9]. However, recent commentary has emphasized interpretability of models, both to understand underlying relationships and to improve generalizability [10]. Part of the difficulty in moving forward with an emphasis on interpretability is the lack of guiding theory. Although explainable AI, including SHAP [11] and LIME [12], has gained lots of attention from the machine learning community, such deep learning based models require large size of dataset, and a thorough theoretical development is lacking. In addition, the concept of “interpretability” can be subjective.
In this paper, we study a double penalty model that can be viewed as a special instance of ensemble learning, although it is apparent that extensions beyond two ensemble components can be made by successive grouping of learners. We use the model to formalize theoretical questions concerning consistency and identifiability, which are partly determined by the concept of function separability. Practical considerations include the development of iterative fitting algorithms for the two components, which may be valuable even when separability cannot be established.
Although not our main focus, our model may be of assistance in understanding inherent tradeoffs in model interpretability, if the prediction rule is divided into interpretable and uninterpretable portions/functions, as defined by the investigator. We emphasize that, in our framework, high interpretability may come at the cost of prediction accuracy, but a modest loss in accuracy may be worth the gain in interpretability.
2. A Double Penalty Model and a Fitting Algorithm
Consider a function of interest h, which can be expressed by
where and are two unknown functions with known function classes and , respectively, and is a compact and convex region. Following the motivation for this work, we suppose that the function class consists of functions that are “easy to interpret”, for example, linear functions. We further suppose that is judged to be uninterpretable, for example, the output from a random forest procedure. Suppose we observe data , with , where and ’s are i.i.d. random error with mean zero and finite variance. The goal of this work is to specify or estimate and .
Obviously, it is not necessary that and are unique, or can be statistically identified. For example, for any function , the summation of and is also equal to h. Regardless of the identifiability of and , we propose the following double penalty model for fitting. In the rest of this work, we define the empirical inner product as and the empirical norm . The double penalty model is defined by
where and are convex penalty functions on f and g, and and are estimators of and , respectively. Under some circumstances, if and can be statistically identified, by using appropriate penalty functions and , we can obtain consistent estimators and of and , respectively. Even if and are nonidentifiable, by using the two penalty functions and , the relative contributions of the “easy to interpret” part and “hard to interpret” to a final prediction rule can be controlled.
Directly solving (2) may be difficult, because and may be partly confounded. Here we describe an iterative algorithm to solve the optimization problem in (2).
In Algorithm 1, for each iteration, two separated optimization problems (4) and (3) are solved with respect to f and g, respectively. The idea of Algorithm 1 is similar to the coordinate descent method, which minimizes the objective function with respect to each coordinate direction at a time. Such an idea has been widely used in practice, for example, backfitting algorithm in the generalized additive model, and the method of alternating projections [13]. The minimization in Equations (3) and (4) ensures that the function
decreases as m increases. One can stop Algorithm 1 after reaching a fixed number of iterations or no further improvement of function values can be made.
| Algorithm 1 Iterative algorithm |
Input: Data , , function classes and , and functions and . Set . Let While Stopping criteria are not satisfied do Solve
Set . return and . |
Remark 1.
The model (1) is not the same as additive models [14]. In the additive model, the functions and have different covariates (thus and are identifiable), while in (1), and share the same covariates. Therefore, additional efforts need to be made on addressing the identifiability issue. A more similar model is as in [15], where and are two realizations of Gaussian processes, with one capturing the global information and the other capturing the local fluctuations.
The convergence of Algorithm 1 is ensured if or is strongly convex. Let be a (semi-)norm of a Hilbert space. A function L is said to be strongly convex with respect to (semi-)norm if there exists a parameter such that for any in the domain and ,
As a simple example, is strongly convex for any norm . If or is strongly convex, Algorithm 1 converges, as stated in the following theorem.
Theorem 1.
Suppose or is strongly convex with respect to the empirical norm with parameter . We have
and , as m goes to infinity (The proof can be found in Appendix A).
From Theorem 1, it can be seen that Algorithm 1 can achieve a linear convergence if or is strongly convex, regardless of the identifiability of and . We only require one penalty function to be strongly convex. The convergence rate depends on the parameter , which measures the convexity of a function. If the penalty function is more convex, i.e., is larger, then the convergence of Algorithm 1 is faster. The strong convexity of the penalty function or can be easily fulfilled, because the square of norm of any Hilbert space is strongly convex. For example, the penalty functions in the ridge regression and the neural networks with fixed number of neuron are strongly convex with respect to the empirical norm.
An Example
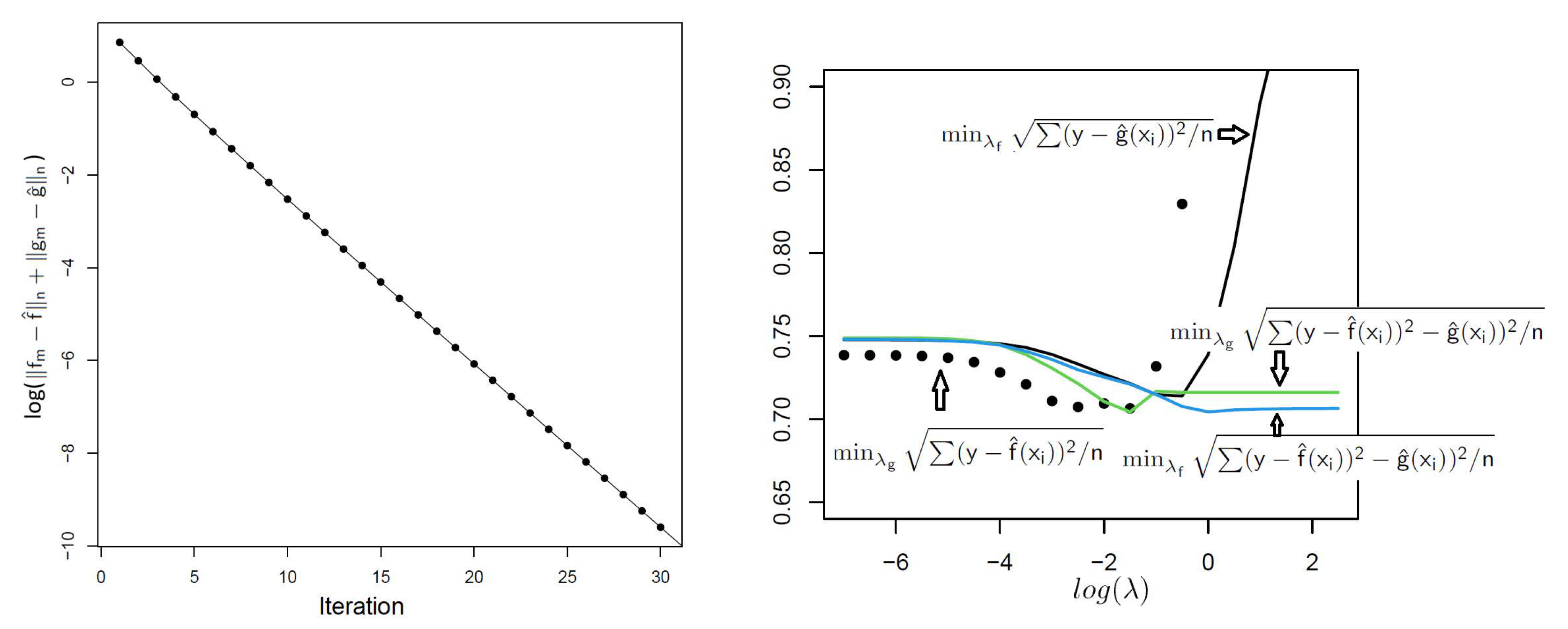
We demonstrate Theorem 1 and the double penalty model by considering regression with an penalty on the coefficients for f and an penalty on the coefficients for g. Thus, the form is the familiar elastic net [16], which we here re-characterize as a mix of LASSO regression (more interpretable because coefficients are sparse) and less-interpretable ridge regression. Although extremely fast elastic net algorithms have been developed [17], the conditions of Theorem 1 hold, and we illustrate using the diabetes dataset [18] with 442 observations and 64 predictors, including interactions. The glmnet package (v 4.0-2) [19] was used in successive LASSO and ridge steps, as in Algorithm 1. Figure 1 left panel shows the convergence of (root mean squared error) for , (the results from a minimum grid search, although any pair will do). The right panel shows various root mean squared minima (RMSE and root mean squared variation) over using 10-fold cross-validation. The results suggest choices of that can nearly achieve the overall minimum RMSE, while placing the bulk of variation/explanatory variation on the more interpretable f.
3. Separable Function Classes
Suppose and can be statistically specified. It can be seen that , for otherwise and would be another decomposition of h for any . For example, we can consider be a function class that h lies in, be a subset of , and be ’s orthogonal complement in . Nevertheless, we consider a more general case in the sense defined here. We define and as -separable if there exists such that for any functions and ,
where denotes the norm of a function , and denotes the inner product of functions . Roughly speaking, the minimal angle of and is strictly bounded away from zero. If two function classes are -separable, then and are unique, as stated in the following lemma.
Lemma 1.
Suppose (5) is true for any functions and , then and are unique, up to a difference on a measure zero set (The proof can be found in Appendix B).
3.1. A Separable Additive Model with the Same Covariates
Suppose two function classes , and , where is the Sobolev space with known smoothness . We assume that and are bounded, i.e., there exist constants and such that and , for all and , respectively. Typically, the “easy to interpret” part has a higher smoothness, thus we assume . In order to estimate and , we employ the idea from kernel ridge regression.
Let be the (isotropic) Matérn family [20], defined by
where is the modified Bessel function of the second kind, , and is the range parameter. We use to denote the reproducing kernel Hilbert space generated by , and to denote the norm of . By Corollary 10.48 in [21], coincides with . We use the solution to
to estimate and , and the corresponding estimators are denoted by and , respectively. Note that if only contains zero function, then (7) reduces to kernel ridge regression. We further require that (5) holds such that and are identifiable.
First, we consider the consistency of and , which is provided in the following theorem.
Theorem 2.
Suppose ’s are uniformly distributed on Ω, and the noise ’s are i.i.d. sub-Gaussian, i.e., satisfying for some constants K and , and all . If , we have (The proof can be found in Appendix C)
Remark 2.
Note that in Theorem 2, we only require upper bounds on , which is because and are bounded. In particular, we can set . However, if and are large, it is more likely that and , which allows us to solve (7) efficiently.
Remark 3.
Because and share the same covariates, the convergence speed of is slower than the optimal rate . We cannot confirm whether the rate in Theorem 2 is optimal for .
In order to solve the optimization problem in (7), we apply Algorithm 1. In each iteration of Algorithm 1, and are solved by
which have explicit forms as
if and , where
for , and . The explicit forms allow us to solve (17) efficiently.
By Theorem 1, the convergence of Algorithm 1 can be guaranteed. However, if the two function classes separate well, we can achieve a faster convergence, as shown in the following theorem.
Theorem 3.
Suppose two function classes and are -separable satisfying (5), and ’s are uniformly distributed on Ω. For , with probability at least , we have either
or
where N and ’s are constants only depending on , and Ω (The proof can be found in Appendix D).
In the proof of Theorem 3, the key step is to show that with high probability, (5) implies that the separability holds with respect to the empirical norm, i.e.,
with some close to . It can be seen that in Theorem 3, if and are separable with respect to the norm, Algorithm 1 achieves a linear convergence. The parameter determines the convergence speed. If is small, then the convergence of Algorithm 1 is fast, and a few iterations are enough. By Theorems 2 and 3, it can be seen that the approximation error (the difference between the optimal solution and numerical solution) can be much smaller than the statistical error, which is typical. In particular, we can conclude that the solution obtained by Algorithm 1 satisfies
where we apply Lemma 5.16 of [22], which ensures the asymptotic equivalence of norm and the empirical norm of .
3.2. Finite Dimensional Function Classes
As a special case of the model in Section 3.1, suppose two function classes and have finite dimensions. To be specific, suppose
where ’s are known functions defined on a compact set , and and are known constants. Furthermore, assume and are -separable. Since the dimension of each function class is finite, we can use the least squares method to estimate and , i.e.,
By applying standard arguments in the theory of Vapnik-Chervonenkis subgraph class [22], the consistency of and holds. We do not present detailed discussion for the conciseness of this paper.
Although the exact solution to the optimization problem in (11) is available, we can still use Algorithm 1 to solve it. By comparing the exact solution with numeric solution obtained by Algorithm 1, we can study the convergence rate of Algorithm 1 via numerical simulations. The detailed numerical studies of the convergence rate is provided in Section 5.1.
4. Non-Separable Function Classes
In Section 3, we consider the case that and are -separable, which implies and are statistically identifiable. However, in many practical cases, and are not -separable. Such examples include as a linear function class and as the function space generated by a neural network. If and are not -separable, then and are not statistically identifiable. To see this, note that there exist two sequences of functions and such that . This implies that and are not statistically identifiable, which implies that we cannot consistently estimate and .
Although and can be not -separable, we can still use (2) to specify and . We propose choosing with simple structure and to be “easy to interpret”, and choosing to be flexible to improve the prediction accuracy. The tradeoff between interpretation and prediction accuracy can be adjusted by applying different penalty functions and . If is large, then (2) forces to be small and to be large, which indicates that the model is more flexible, but is less interpretable. On the other hand, if is large, then the model is more interpretable, but may reduce the power of prediction.
Another way is to make and separable. Specifically, suppose , where and p is the dimension. Then we construct a new function class such that , where is the perpendicular component of in . Although in general, it is not easy to find ( may also be empty), in some cases, it is possible to build , for example, is of finite dimension. In the next subsection, we provide a specific example of building the perpendicular component of and study the convergence property of its corresponding double penalty model.
A Generalization of Partially Linear Models
In this subsection, we consider a generalization of partially linear models. The responses in a typical partially linear model can be expressed as
In the partially linear models (12), is a vector of regression coefficients associated with x, g is an unknown function of t with some known smoothness, which is usually a one dimensional scalar, and is a random noise. The partially linear model (12) can be estimated by the partial spline estimator [23,24], partial residual estimator [25,26], or SCAD-penalized regression [27].
In this work, we consider a more general model. Suppose we observe data on for , where
and ’s are i.i.d. random errors with mean zero and finite variance. We assume that the function , where is the Sobolev space with known smoothness . This is a standard assumption in nonparametric regression, see [22,28] for example. It is natural to define the two function classes by
and , where denotes the Euclidean distance, and are known constants. In practice, we can choose a sufficient large such that and are large enough. Note that in (13), the linear part and nonlinear part share the same covariates, which is different with (12). It can be seen that and are non-identifiable because . Furthermore, is more interpretable compared with because it is linear.
In order to uniquely identify and , we need to restrict function class such that and are separable. This can be done by applying a newly developed approach, employing the projected kernel [29]. Let , be an orthonormal basis of . Then can be defined as a linear span of the basis , and the projection of a function on is given by
The perpendicular component is
By (14) and (15), we can split into two perpendicular classes as and , where . Let , where . Since and are perpendicular, they are -separable. By Lemma 1, and are unique. However, in practice it is usually difficult to find a function directly. We propose using projected kernel ridge regression, which depends on the reproducing kernel Hilbert space generated by the projected kernel.
The reproducing kernel Hilbert space generated by the projected kernel can be defined in the following way. Define the linear operators and : as
for . The projected kernel of can be defined by
The function class then is equivalent to the reproducing kernel Hilbert space generated by , denoted by , and the norm is denoted by . For detailed discussion and properties of and , we refer to [29].
By using the projected kernel of , the double penalty model is
where are estimators of . In practice, we can use generalized cross validation (GCV) to choose the tuning parameter [29,30]. If the tuning parameter is chosen properly, we can show that are consistent, as stated in the following theorem. In the rest of this paper, we use the following notation. For two positive sequences and , we write if, for some constants , .
Theorem 4.
Suppose ’s are uniformly distributed on Ω, and the noise ’s are i.i.d. sub-Gaussian, i.e., satisfying for some constants K and , and all . If , we have
Theorem 4 is a direct result of Theorem 3, thus the proof is omitted. Theorem 4 shows that the double penalty model (17) can provide consistent estimators of and , and the convergence rate of is known to be optimal [31]. The convergence rate of in Theorem 4 is slower than the convergence rate in the linear model. We conjecture that this is because the convergence rate is influenced by the estimation of , which may introduce extra error because functions in and have the same input space.
In order to solve the optimization problem in (17), we apply Algorithm 1. By Theorem 1, the convergence of Algorithm 1 can be guaranteed. In each iteration of Algorithm 1, and are solved by
which have explicit forms as
where
and . The explicit forms allow us to solve (17) efficiently. Furthermore, because and are orthogonal, Theorem 3 implies that a few iterations of Algorithm 1 are sufficient to obtain a good numeric solution.
5. Numerical Examples
5.1. Convergence Rate of Algorithm 1
In this subsection, we report numerical studies on the convergence rate of Algorithm 1, and verify that the convergence rate in Theorem 3 is sharp. We consider two finite function classes such that the analytic solution of (11) is available, as stated in Section 3.2. By comparing the numeric solution and the analytic solution, we can verify the convergence rate is sharp.
We consider two function classes and , where , is a known parameter which controls the degree of separation of two function classes, i.e., the parameter in Lemma 1. It is easy to verify that for and ,
where
Suppose the underlying function with . Let be the solution to (11), and be the values obtained at mth iteration of Algorithm 1. By Theorem 3,
where . By taking logarithms on both sides of (18), we have
If the convergence rate in Theorem 3 is sharp, then is an approximate linear function with respect to m and the slope is close to .
In our simulation studies, we choose . We choose the noise , where is a normal distribution with mean zero and variance . The algorithm stops if the left hand side of (18) is less than . We choose 50 uniformly distributed points as training points. We run 100 simulations and take the average of the regression coefficient and the number of iterations needed for each . The results are shown in Table 1.
Theorem 3 shows that the approximation in (19) is more accurate when the sample size is larger. We conduct numerical studies using sample sizes . We choose . The results are presented in Table 2.
From Table 1 and Table 2, we find that the absolute difference increases as increases and sample size decreases. When decreases, the iteration number decreases, which implies the convergence of Algorithm 1 becomes faster. These results corroborate our theory. The regression coefficients are close to our theoretical assertion , which indicates that the convergence rate in Theorem 3 is sharp.
5.2. Prediction of Double Penalty Model
To study the prediction performance of double penalty model, we consider two examples, with -separable function classes and non--separable function classes, respectively. In these examples, we would like to stress that we only show the double penalty model can provide relatively accurate estimator with a large part attributing to the “interpretable” part. Since accuracy is not the only goal of our estimator, models that may have extremely high prediction accuracy but may hard to interpret is not preferred in our case. Furthermore, the definition of “interpretable” can be subjective and depends on the user. Therefore, we choose our subjective “interpretable” model in these examples and only show the prediction performance of our model.
Example 1.
Consider function [32]
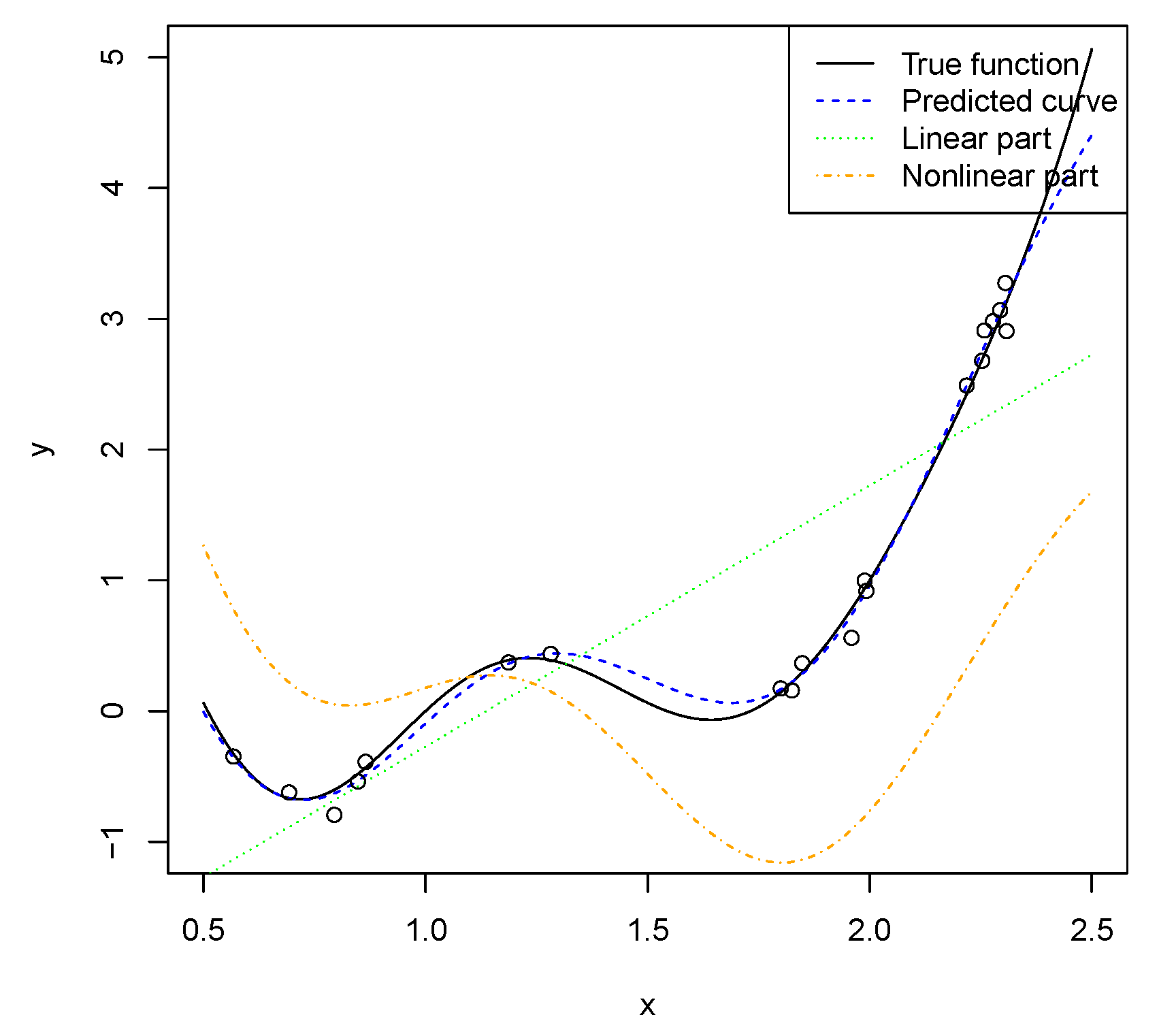
Let , and be the reproducing kernel Hilbert space generated by the projected kernel. The projected kernel is calculated as in (16), where Ψ is as in (6) with and . We use 20 uniformly distributed points from as training points, and let . For each simulation, we calculate the mean squared prediction error, which is approximated by calculating the mean squared prediction error on 201 evenly spaced points. We run 100 simulations, and the average mean squared prediction error is 0.016. In this example, the iteration number needed in Algorithm 1 is less than three because the two function classes are orthogonal, which corroborates the results in Theorem 3.
Figure 2 shows that the linear part can capture the trend. However, it can be seen from the figure that the difference between the true function and the linear part is still large. Therefore, a nonlinear part is needed to make good predictions. It also indicates that the function in this example is not easy to interpret.
Example 2.
Consider a modified function of [33]
for . We use , and as the reproducing kernel Hilbert space generated by Ψ, where Ψ is as in (6) with and . Note that and are not -separable because .
The double penalty model is
and the solution is denoted by . We choose , where is the sample size. The noise , where is chosen to be and . The iteration numbers are fixed in each simulation, with values . We choose maximin Latin hypercube design [34] with sample size 50 as the training set. We run 100 simulations for each case and calculated the mean squared prediction error on the testing set, which is the first 1000 points of the Halton sequence [35].
Table 3 and Table 4 show the simulation results when the variance of noise is 0.1 and 0.01, respectively. We run simulations with iteration numbers for each , and we find the results are not of much difference. For the briefness, we only present the full simulation results of to show the similarity, and present the results with 5 iterations for other values of . In Table 3 and Table 4, we calculate the mean squared prediction error on the training set and the testing set. We also calculate the norm of and as in (20), which is approximated by the empirical norm using the first 1000 points of the Halton sequence.
From Table 3 and Table 4, we can obtain the following results: (i) The prediction error in all cases are small, which suggests that the double penalty model can make accurate predictions. (ii) If we increase , the training error decreases. The prediction error decreases when is relatively large, and becomes large when is too small. (iii) One iteration in Algorithm 1 is sufficient to obtain a good solution of (20). (iv) The training error of the case with smaller is smaller. If is chosen properly, the prediction error of the case with smaller is small. However, there is not much difference in the prediction error under the cases and when is large. (v) For all values of , the norm of the linear function does not vary a lot. The norm of , on the other hand, increases as decreases. This is because a smaller implies a lower penalty on g. (vi) Comparing the values of the norm of and the norm of , we can see the norm of is much larger, which is desired because we tend to maximize the interpretable part, which is linear functions in this example.
6. Application to Real Datasets
To illustrate, we apply the approach to two datasets. The first dataset is [36], which includes 50 human fecal microbiome features for unrelated individuals, of genetic sequence tags corresponding to bacterial taxa, and with a response variable of log-transformed body mass index (BMI). To increase the prediction accuracy, we first reduce the number of original features to the final dataset using the HFE cross-validated approach [37], as discussed in [38]. The second dataset is the diabetes dataset from the lars R package, widely used to illustrate penalized regression [39]. The response is a log-transformed measure of disease progression one year after baseline, and predictor features are ten baseline variables, age, sex, BMI, average blood pressure, and six blood serum measurements.
Following Algorithm 1, we let f denote the LASSO algorithm ([40], interpretable part), and use the built-in penalty as , with parameter as implemented in the R package glmnet. For the “uninterpretable” part, we use the xgboost decision tree approach, with built-in penalty as , with parameter as implemented in the R package xgboost [41]. For xgboost, we set an penalty as zero throughout, with other parameters (tree depth, etc.), set by cross-validation internally, while preserving convexity of . We also set the maximum number of boosting iterations at ten. At each iterative step of LASSO and xgboost, ten simulations of five-fold cross-validation were performed and the predicted values were then averaged.
Finally, in order to explore the tradeoffs between the interpretable and uninterpretable parts, we first establish a range-finding exercise for the penalty tuning parameters on the logarithmic scale, such that for constant c. We refer to this tradeoff as the transect between the tuning parameters, with low values of , for example, emphasizing and placing weight on the interpretable part by enforcing a low penalty for overfitting. To illustrate performance, we use the Pearson correlation coefficient between the response vector y and the average (cross-validated) values of , and over the transect. The correlations are of course directly related to the objective function term , but are easier to interpret. Note that and are not orthogonal, so the correlations do not partition into the overall correlation of y with . Additionally, as a final comparison, we compute these correlation values over the entire grid of values, to ensure that the transect was largely capturing the best choice of tuning parameters.
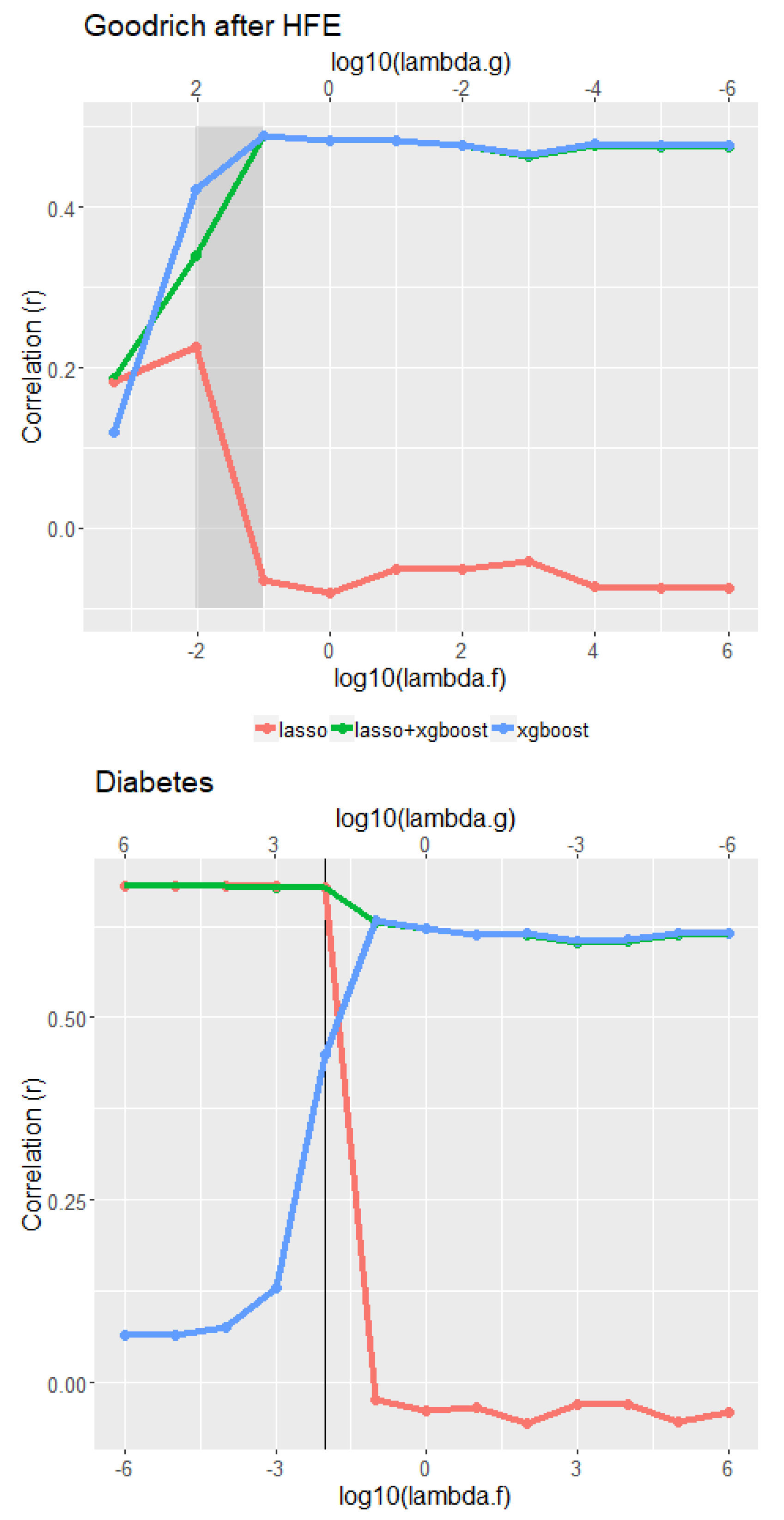
For the Goodrich microbiome data, Figure 3 top panel shows the correlations between y and the three cross-validated predictors over the transect. Low values of are favored, although it is clear that the decision tree is favored throughout most of the transect, i.e., y has much higher correlations with than with . Using in the range of (−2, −1) maximizes the correlation with the interpretable portion, while still achieving near the overall maximum correlation for the combined prediction rule (correlation of nearly 0.5). Our subjective “best balance" region for the interpretable portion is shown on the figure.
Figure 3 bottom panel shows the analogous results for the diabetes dataset. Here LASSO provides overall good predictions for small tuning parameter , and provides good correlations (in the range 0.55–0.6) of y with , and . As the tuning parameter increases, the correlation between y and falls off dramatically, and our suggested “best balance” point is also shown. In no instance were the correlation values for the full grid of more than 0.015 greater than the greatest value observed along the transects.
7. Discussion
In this work, we propose using a double penalty model as a means of isolating and studying the effects and implications of ensemble learning. We have established conditions for local algorithmic convergence under relatively general convexity conditions. We highlight the fact that in some settings identifiability is not necessary for effective use of the model in prediction. If two function classes are orthogonal, the convergence of the algorithm provided in this work is very fast. This observation inspires potential future work, given any two function classes, to construct two separable function classes that are orthogonal, and to obtain subsequent consistency results, since the two portions are identifiable.
Although our interest here is theoretical, we have also illustrated how the fitting algorithm can be used in practice to make the relative contribution of large, while not substantially degrading overall predictive performance. The examples here are relatively straightforward, serving to illustrate the theoretical concepts. Further practical implications and implementation issues will be described elsewhere.
Author Contributions
Conceptualization, Y.-H.Z.; methodology, W.W. and Y.-H.Z.; formal analysis; validation, W.W. and Y.-H.Z.; formal analysis, W.W. and Y.-H.Z.; investigation, Y.-H.Z.; resources, Y.-H.Z.; data curation, W.W. and Y.-H.Z.; writing—original draft preparation, W.W. and Y.-H.Z.; writing—review and editing, W.W. and Y.-H.Z.; supervision, Y.-H.Z.; visualization, Y.-H.Z.; project administration, Y.-H.Z.; funding acquisition, Y.-H.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Environmental Protection Agency, grant number: 84045001 and Texas A&M Superfund Research Program, grant number: P42ES027704.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Theorem 1
Without loss of generality, assume is strongly convex. For any , by the strong convexity of , we have
We can rewrite (A1) as
which is the same as
Taking limit in (A2) yields
Since is the solution to (2), for any , it is true that
By the similar approach as shown in (A1)–(A3), we can show
Combining (A3) and (A4) leads to
Thus,
Applying the same procedure to function , and noting that we do not have the strong convexity of , we have
By (A5) and (A6), we have
which implies converges to zero. By (A5), also converges to zero. The rest of the proof is similar to the proof of Theorem 3. Thus, we finish the proof.
Appendix B. Proof of Lemma 1
The proof is straightforward. Suppose there exist another two functions and such that . By (5), we have
where the equality holds only when , i.e., , since . Thus, we finish the proof.
Appendix C. Proof of Theorem 2
Because and are derived by (7), we have
which can be rewritten as
Note coincides , for . By the entropy number of a unit ball in the Sobolev space [42] and Lemma 8.4 of [22], it can be shown that
which implies
since is bounded. Following a similar argument, we have
Let
Thus, and with and . Applying Lemma A2 yields
where we also use and are bounded. By the interpolation inequality, we have
where the last inequality is because and is bounded. Similarly,
By applying Lemma 5.16 of [22], we can conclude the asymptotic equivalence of norm and the empirical norm of , i.e.,
for some constants and (if , then the conclusions automatically hold, and there is nothing needs to be proved). Therefore, we can replace and by and in (A7), respectively. Plugging (A8), (A9), (A10), (A11), and (A12) into (A7), we obtain
where the first inequality is because of the Cauchy-Schwarz inequality, the second inequality is because and are separable with respect to norm, and the first equality is because is bounded. Therefore, since either
or
Consider (A14) first. If , then (A14) implies
Similarly, if , then (A14) implies
Combining (A15), (A16), and (A17), we finish the proof.
Appendix D. Proof of Theorem 3
We first present some lemmas used in this proof.
Let be a metric space with metric d, and T is a space. Let denote the -covering number of the metric space , and be the entropy number. We need the following two lemmas. Lemma A1 is a direct result of Theorem 2.1 of [43], which provides an upper bound on the difference between the empirical norm and norm. Lemma A2 is a direct result of Theorem 3.1 of [43], which provides an upper bound on the empirical inner product. In Lemmas A1 and A2, we use the following definition. For , we define
where is a constant, and is the entropy of for a function class .
Lemma A1.
Let , and , where is a class. Then for all , with probability at least ,
where is a constant.
Lemma A2.
Let and be two function classes. Let
Suppose that . Assume
and
Then for , with probability at least ,
If , then the results automatically hold. Suppose . Since is the solution to (), for any , we have
where the last inequality is because is convex. Rewriting (A18) yields
which is the same as
Because , (A19) implies
Taking limit in (A20) leads to
Since is the solution to (2), for any , it is true that
which implies
Since , (A23) implies
Letting in (A25) yields
Combining (A26) and (A21), it can be checked that
which implies
Applying similar approach to , we obtain
Let
Thus, and with and . Applying Lemma A2 yields that with probability at least ,
where the last inequality is by the interpolation inequality, and and are bounded. Similarly, by Lemma A2, we also obtain that with probability at least ,
and
Since and satisfy (5), together with (A30)–(A32), we have that with probability at least
where the last inequality is by Lemma A1 and .
If , then (A29) implies . If , then by (A28), we also have . Thus, and , which, together with (A33), yields
Define . By (A27) and (A36), we have
Applying the same procedure to function , we have
By (A37) and (A38), it can be seen that
Taking and finishes the proof.
References
- Opitz, D.; Maclin, R. Popular ensemble methods: An empirical study. J. Artif. Intell. Res. 1999, 11, 169–198. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Krogh, A.; Vedelsby, J. Neural network ensembles, cross validation, and active learning. Adv. Neural Inf. Process. Syst. 1994, 7, 231–238. [Google Scholar]
- Wyner, A.J.; Olson, M.; Bleich, J.; Mease, D. Explaining the success of adaboost and random forests as interpolating classifiers. J. Mach. Learn. Res. 2017, 18, 1558–1590. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Nettleton, D.; Zhu, Z. Regression-enhanced random forests. arXiv 2019, arXiv:1904.10416. [Google Scholar]
- Bojer, C.S.; Meldgaard, J.P. Kaggle forecasting competitions: An overlooked learning opportunity. Int. J. Forecast. 2021, 37, 587–603. [Google Scholar] [CrossRef]
- Li, C. A Gentle Introduction to Gradient Boosting. 2016. Available online: http://www.ccs.neu.edu/home/vip/teach/MLcourse/4_boosting/slides/gradient_boosting.pdf (accessed on 1 January 2019).
- Abbott, D. Applied Predictive Analytics: Principles and Techniques for the Professional Data Analyst; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4765–4774. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Bickel, P.J.; Klaassen, C.A.; Bickel, P.J.; Ritov, Y.; Klaassen, J.; Wellner, J.A.; Ritov, Y. Efficient and Adaptive Estimation for Semiparametric Models; Springer: Berlin/Heidelberg, Germany, 1993; Volume 4. [Google Scholar]
- Hastie, T.J.; Tibshirani, R.J. Generalized Additive Models; Routledge: London, UK, 2017. [Google Scholar]
- Ba, S.; Joseph, V.R. Composite Gaussian process models for emulating expensive functions. Ann. Appl. Stat. 2012, 6, 1838–1860. [Google Scholar] [CrossRef] [Green Version]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Q.; Chen, W.; Song, S.; Gardner, J.; Weinberger, K.; Chen, Y. A reduction of the elastic net to support vector machines with an application to GPU computing. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. [Google Scholar]
- Zou, H.; Hastie, T.; Tibshirani, R. On the “degrees of freedom” of the lasso. Ann. Stat. 2007, 35, 2173–2192. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularization paths for generalized linear models via coordinate descent. J. Stat. Softw. 2010, 33, 1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stein, M.L. Interpolation of Spatial Data: Some Theory for Kriging; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Wendland, H. Scattered Data Approximation; Cambridge University Press: Cambridge, UK, 2004; Volume 17. [Google Scholar]
- van de Geer, S. Empirical Processes in M-Estimation; Cambridge University Press: Cambridge, UK, 2000; Volume 6. [Google Scholar]
- Wahba, G. Partial spline models for the semi-parametric estimation of several variables. In Statistical Analysis of Time Series, Proceedings of the Japan US Joint Seminar; 1984; pp. 319–329. Available online: https://cir.nii.ac.jp/crid/1573387449750539264 (accessed on 27 October 2022).
- Heckman, N.E. Spline smoothing in a partly linear model. J. R. Stat. Soc. Ser. B (Methodol.) 1986, 48, 244–248. [Google Scholar] [CrossRef]
- Speckman, P. Kernel smoothing in partial linear models. R. Stat. Soc. Ser. B (Methodol.) 1988, 50, 413–436. [Google Scholar] [CrossRef]
- Chen, H. Convergence rates for parametric components in a partly linear model. Ann. Stat. 1988, 16, 136–146. [Google Scholar] [CrossRef]
- Xie, H.; Huang, J. SCAD-penalized regression in high-dimensional partially linear models. Ann. Stat. 2009, 37, 673–696. [Google Scholar] [CrossRef]
- Gu, C. Smoothing Spline ANOVA Models; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; Volume 297. [Google Scholar]
- Tuo, R. Adjustments to Computer Models via Projected Kernel Calibration. SIAM/ASA J. Uncertain. Quantif. 2019, 7, 553–578. [Google Scholar] [CrossRef] [Green Version]
- Wahba, G. Spline Models for Observational Data; SIAM: Philadelphia, PA, USA, 1990; Volume 59. [Google Scholar]
- Stone, C.J. Optimal global rates of convergence for nonparametric regression. Ann. Stat. 1982, 5, 1040–1053. [Google Scholar] [CrossRef]
- Gramacy, R.B.; Lee, H.K. Cases for the nugget in modeling computer experiments. Stat. Comput. 2012, 22, 713–722. [Google Scholar] [CrossRef]
- Sun, L.; Hong, L.J.; Hu, Z. Balancing exploitation and exploration in discrete optimization via simulation through a Gaussian process-based search. Oper. Res. 2014, 62, 1416–1438. [Google Scholar] [CrossRef]
- Santner, T.J.; Williams, B.J.; Notz, W.I. The Design and Analysis of Computer Experiments; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Niederreiter, H. Random Number Generation and Quasi-Monte Carlo Methods; SIAM: Philadelphia, PA, USA, 1992; Volume 63. [Google Scholar]
- Goodrich, J.K.; Waters, J.L.; Poole, A.C.; Sutter, J.L.; Koren, O.; Blekhman, R.; Beaumont, M.; Van Treuren, W.; Knight, R.; Bell, J.T. Human genetics shape the gut microbiome. Cell 2014, 159, 789–799. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Oudah, M.; Henschel, A. Taxonomy-aware feature engineering for microbiome classification. BMC Bioinform. 2018, 19, 227. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, Y.H.; Gallins, P. A Review and Tutorial of Machine Learning Methods for Microbiome Host Trait Prediction. Front. Genet. 2019, 10, 579. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.; Franklin, J. The elements of statistical learning: Data mining, inference and prediction. Math. Intell. 2005, 27, 83–85. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Adams, R.A.; Fournier, J.J. Sobolev Spaces; Academic Press: Cambridge, MA, USA, 2003; Volume 140. [Google Scholar]
- van de Geer, S. On the uniform convergence of empirical norms and inner products, with application to causal inference. Electron. J. Stat. 2014, 8, 543–574. [Google Scholar] [CrossRef]
Figure 1.
Left panel: Convergence of using Algorithm 1 for the diabetes dataset. Right panel: For each curve, the label shows which portion (f or g has been subjected to minimization, and the x-axis corresponds to the other not minimized. The LASSO portion of the elastic net example achieves nearly the same minimum RMSE as the full elastic net for these data, which would be favored in terms of interpretability.
Figure 1.
Left panel: Convergence of using Algorithm 1 for the diabetes dataset. Right panel: For each curve, the label shows which portion (f or g has been subjected to minimization, and the x-axis corresponds to the other not minimized. The LASSO portion of the elastic net example achieves nearly the same minimum RMSE as the full elastic net for these data, which would be favored in terms of interpretability.

Figure 2.
One simulation result of Example 1 in Section 5.2. Each dot represents an observation on randomly sampled point.
Figure 2.
One simulation result of Example 1 in Section 5.2. Each dot represents an observation on randomly sampled point.

Figure 3.
Top panel: cross-validated correlations between y and each of , , and for the microbiome dataset, where the tuning parameters vary along the transect as described in the text. Bottom panel: the analogous correlations for the diabetes dataset. Grey region and black vertical line represent suggested tuning parameter values to maximize interpretability while preserving high prediction accuracy.
Figure 3.
Top panel: cross-validated correlations between y and each of , , and for the microbiome dataset, where the tuning parameters vary along the transect as described in the text. Bottom panel: the analogous correlations for the diabetes dataset. Grey region and black vertical line represent suggested tuning parameter values to maximize interpretability while preserving high prediction accuracy.


{kind=link}
{kind=link}
{kind=link}
Table 1.
The simulation results when the sample size is fixed. The last column show the absolute difference between the third column and the fourth column, given by Regression coefficient|.
Table 1.
The simulation results when the sample size is fixed. The last column show the absolute difference between the third column and the fourth column, given by Regression coefficient|.
| Regression Coefficient | Iteration Numbers | Absolute Difference | |||
|---|---|---|---|---|---|
| 2 | 0.978 | −0.045 | −0.050 | 491.55 | 0.006 |
| 3 | 0.828 | −0.378 | −0.419 | 59.02 | 0.040 |
| 3.5 | 0.615 | −0.973 | −1.121 | 22.34 | 0.148 |
| 4 | 0.304 | −2.383 | −2.624 | 10 | 0.241 |
Table 2.
The simulation results under different sample sizes. The last column shows the absolute difference between and regression coefficients, given by Regression coefficient|.
Table 2.
The simulation results under different sample sizes. The last column shows the absolute difference between and regression coefficients, given by Regression coefficient|.
| Sample Size | Regression Coefficient | Iteration Numbers | Absolute Difference |
|---|---|---|---|
| 20 | −0.110 | 225.05 | 0.269 |
| 50 | −0.410 | 60.26 | 0.0315 |
| 100 | −0.404 | 61 | 0.0260 |
| 150 | −0.363 | 68 | 0.0148 |
| 200 | −0.381 | 65 | 0.00244 |
Table 3.
Simulation results when . The third column shows the mean squared prediction error on the training points. The fourth column shows the mean squared prediction error on the testing points. The fifth column and the last column show the approximated norm of and as in (20), respectively.
Table 3.
Simulation results when . The third column shows the mean squared prediction error on the training points. The fourth column shows the mean squared prediction error on the testing points. The fifth column and the last column show the approximated norm of and as in (20), respectively.
| Iteration Number | Training Error | Prediction Error | Linear | Nonlinear | |
|---|---|---|---|---|---|
| 1 | 1 | 0.02951 | 0.01714 | 1.5336 | 0.0034 |
| 2 | 0.02950 | 0.01712 | 1.5312 | 0.0054 | |
| 3 | 0.02949 | 0.01711 | 1.5288 | 0.0076 | |
| 4 | 0.02947 | 0.01710 | 1.5265 | 0.0097 | |
| 5 | 0.02946 | 0.01709 | 1.5242 | 0.0119 | |
| 0.1 | 5 | 0.02404 | 0.01400 | 1.5264 | 0.02224 |
| 0.001 | 5 | 0.0043 | 0.0059 | 1.5285 | 0.1331 |
| 5 | 0.03388 | 1.5324 | 0.2174 |
Table 4.
Simulation results when . The third column shows the mean squared prediction error on the training points. The fourth column shows the mean squared prediction error on the testing points. The fifth column and the last column show the approximated norm of and as in (20), respectively.
Table 4.
Simulation results when . The third column shows the mean squared prediction error on the training points. The fourth column shows the mean squared prediction error on the testing points. The fifth column and the last column show the approximated norm of and as in (20), respectively.
| Iteration Number | Training Error | Prediction Error | Linear | Nonlinear | |
|---|---|---|---|---|---|
| 1 | 1 | 0.01812 | 0.01759 | 1.5316 | 0.002998 |
| 2 | 0.01811 | 0.01757 | 1.5294 | 0.004763 | |
| 3 | 0.01810 | 0.01755 | 1.5274 | 0.006664 | |
| 4 | 0.01809 | 0.01754 | 1.5253 | 0.008581 | |
| 5 | 0.01808 | 0.01753 | 1.5234 | 0.010481 | |
| 0.1 | 5 | 0.01336 | 0.01387 | 1.5203 | 0.017585 |
| 0.001 | 5 | 0.00071 | 0.00088 | 1.5287 | 0.120022 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Wang, W.; Zhou, Y.-H. A Double Penalty Model for Ensemble Learning. Mathematics 2022, 10, 4532. https://doi.org/10.3390/math10234532
AMA Style
Wang W, Zhou Y-H. A Double Penalty Model for Ensemble Learning. Mathematics. 2022; 10(23):4532. https://doi.org/10.3390/math10234532
Chicago/Turabian StyleWang, Wenjia, and Yi-Hui Zhou. 2022. "A Double Penalty Model for Ensemble Learning" Mathematics 10, no. 23: 4532. https://doi.org/10.3390/math10234532
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.