3.3. Results and Analysis
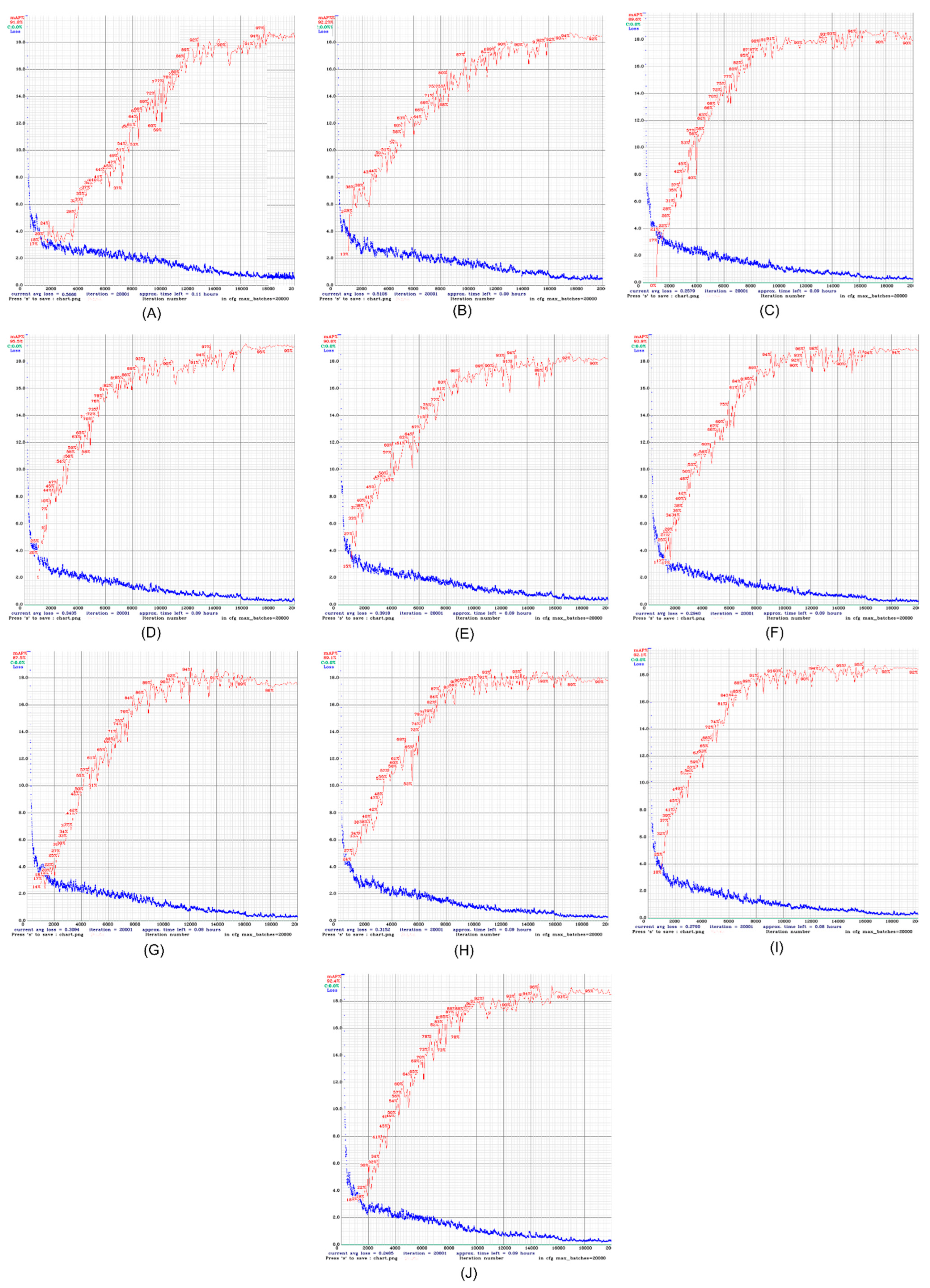
Figure 9A shows the mAP curve and average loss curve of the first experimental results. The results show that when the epoch number is set to 20,000, the mAP value reaches 91.8%, and the average loss rate is 0.5666.
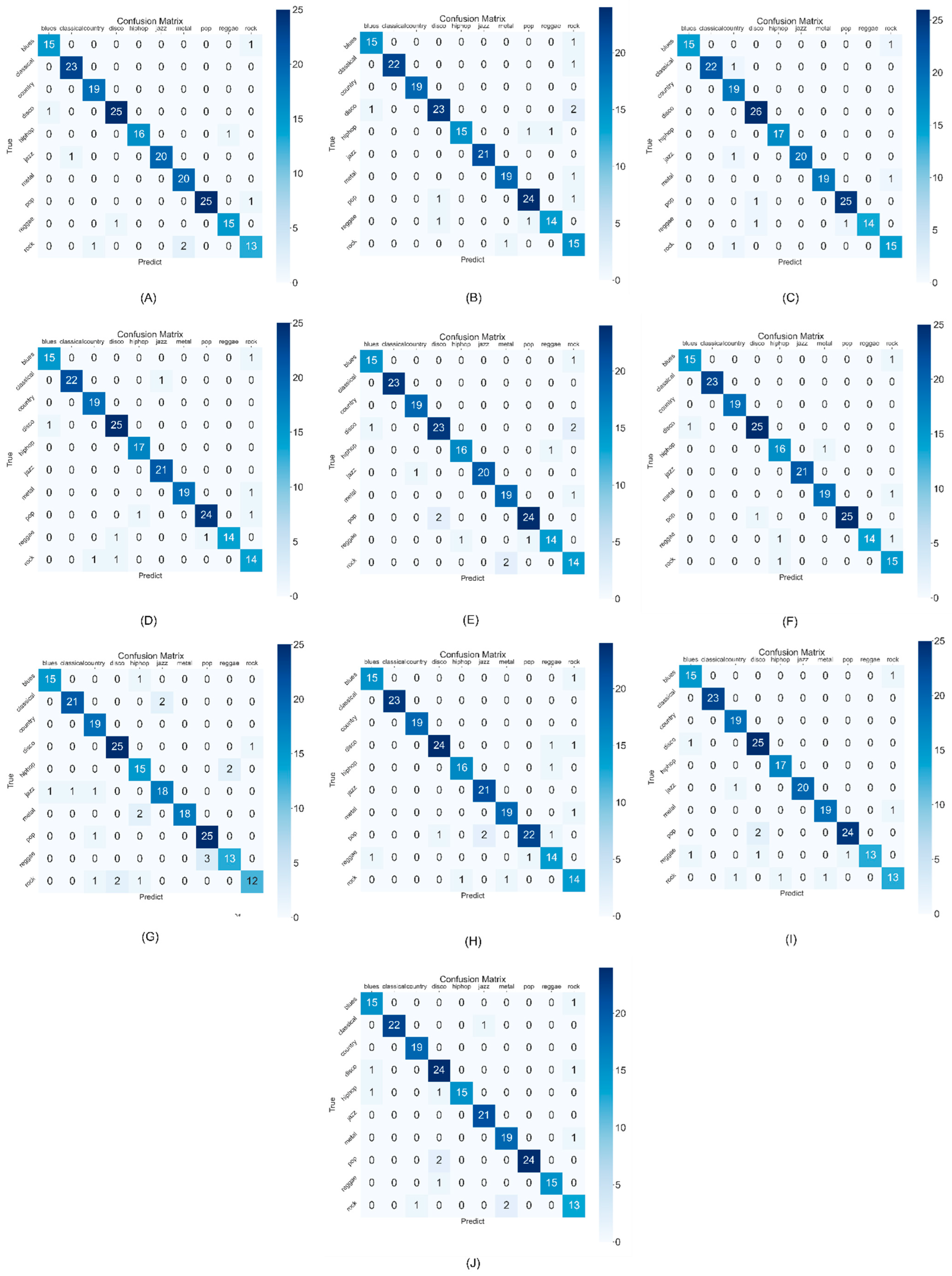
Figure 10A shows the confusion matrix using the weights of the first experiment on the test set. The results show a mAP result of 94.57% using the test set, Precision of 0.96, Recall of 0.96, F1-score of 0.96, and Accuracy of 0.955. From
Figure 9A, the mAP value increased in a curve from 17% at the beginning to 97% at the highest value, while the average figure was 91.8%. It can be seen that the curve rises and occasionally falls, but continues to rise upwards. Therefore, the results show that the Dropblock of the model plays a role in learning, so that the machine reduces the incidence of overfitting during the learning process. Trends falling and rising indicate that the model is learning steadily rather than one-shot, which also indicates that the generalization ability of the model will be improved. As can be seen from
Figure 10, there are a total of 200 songs in the test set for testing. These songs are not applied to the training process, so they can be used as data to judge the quality of the model. It can be seen that the song distribution of 10 genres is not balanced, adding the number of songs on the
x-axis is the total number of genres in the test set, such as 16 blues, 23 classical, and so on. The number of songs of each genre in the test set is shown in
Table 4. Therefore, as mentioned above, our method is not accurate in the accuracy scoring index. In the confusion matrix, the
x-axis is the order in which the model predicts the music styles, and the
y-axis is the order in which the real music styles are. Therefore, the result of cross comparison is that the middle color is darker, that is, the model predicts the correct number of songs in the test set. From this result, it can be seen that our method can obtain good accuracy in the test set, but there are still some genre classification errors. The reason will be analyzed in the last of the results.
Figure 9B shows the mAP curve and the average loss curve of the second experimental results, where the mAP value is 92.2%, the average loss rate is 0.5106, and the number of epochs is 20,000.
Figure 10B shows the confusion matrix using the second experiment weights on the test set, and the Precision is 0.95, the Recall is 0.97, the F1-score is 0.96, the Accuracy is 0.935, and the mAP result using the test set is 96.48%. As can be seen from
Figure 9B, compared with the first experiment, the increase rate of mAP in the second experiment is faster and continues to rise. Therefore, compared with 91.8% in the first experiment, the accuracy of the second experiment reaches 92.2%, and the map curve tends to be stable when the epochs are 16,000, while it has been stable since the epochs is 14,000 in the first experiment, resulting in better results in the second experiment.
Figure 9C shows the mAP curve and the average loss curve of the third experimental results, where the mAP value is 89.6%, the average loss rate is 0.2579, and the number of epochs is 20,000.
Figure 10C shows the confusion matrix using the third experiment weights on the test set, and the Precision is 0.95, the Recall is 0.96, the F1-score is 0.96, the Accuracy is 0.96, and the mAP result using the test set is 97.84%. As can be seen from
Figure 9C, compared with the second experiment, the front part of the mAP curve in the third experiment rises steeply, and there are large fluctuations in the later stage. Therefore, the average mAP value is 89.6%, which is lower than 92.2% in the second experiment, which means that if you learn everything too fast and the epoch times are not prolonged, the training accuracy will be low. The average loss curve also shows a gradual decline and tends to be stable. Compared with the average loss curve of the second experiment, the fluctuation of the average loss curve of the third experiment is smaller than that of the second experiment. Therefore, the average loss rate comes to 0.2579, half of that of the second experiment.
Figure 9D shows the mAP curve and the average loss curve of the fourth experimental results, where the mAP value is 95.5%, the average loss rate is 0.3435, and the number of epochs is 20,000.
Figure 10D shows the confusion matrix using the fourth experiment weights on the test set, and the Precision is 0.94, the Recall is 0.99, the F1-score is 0.97, the Accuracy is 0.95, and the mAP result using the test set is 98.82%. As can be seen from
Figure 9D, the mAP curve of the fourth experiment has a larger amplitude than that of the previous two experiments, so there is a higher mAP value when the epochs are 16,000. The average loss curve also shows a continuous downward and stable trend, reaching the value of 0.3435, which is similar to the third experiment. The fluctuation range of the curve is also small, but it is larger than the value of the third experiment.
Figure 9E shows the mAP curve and the average loss curve of the fifth experimental results, where the mAP value is 90.8%, the average loss rate is 0.3918, and the number of epochs is 20,000.
Figure 10E shows the confusion matrix using the fifth experiment weights on the test set, and the Precision is 0.94, the Recall is 0.96, the F1-score is 0.95, the Accuracy is 0.935, and the mAP result using the test set is 98.81%. As can be seen from
Figure 9E, the mAP curve of the fifth experiment is relatively unstable compared with the first three experiments, and the curve rise is not high when the epochs are 4000 to 6000, and the first four experiments have fluctuations. But the duration is less, and the duration of the fifth experiment is about 2000 epochs, which may be the reason why the average mAP of the fifth experiment is only 90.8%.
Figure 9F shows the mAP curve and the average loss curve of the sixth experimental results, where the mAP value is 93.9%, the average loss rate is 0.2940, and the number of epochs is 20,000.
Figure 10F shows the confusion matrix using the sixth experiment weights on the test set, and the Precision is 0.93, the Recall is 0.96, the F1-score is 0.95, the Accuracy is 0.96, and the mAP result using the test set is 98.53%. As can be seen from
Figure 9F, the sixth experiment obtained the maximum mAP value of 96%, and there was a large curve fluctuation between epochs 12,000 and epochs 15,000, but since the mAP value at that time had reached a high point, the average value is accurate. The accuracy rate has little effect. It can be concluded that the average accuracy rate is 93.9%, and the average loss rate is also reduced to 0.2940, which is close to the average loss rate of the third experiment.
Figure 9G shows the mAP curve and the average loss curve of the seventh experimental results, where the mAP value is 87.5%, the average loss rate is 0.3094, and the number of epochs is 20,000.
Figure 10G shows the confusion matrix using the sixth experiment weights on the test set, and the Precision is 0.87, the Recall is 0.96, the F1-score is 0.91, the Accuracy is 0.905, and the mAP result using the test set is 99.26%. It can be seen from
Figure 9G that in the seventh experiment, the curve slipped when the epochs were 16,000, and the AP fluctuated greatly at each epoch, which resulted in the mAP value of this experiment being only 87.5%. Although the average loss curve also showed a continuous downward trend, it finally stayed at 0.3094.
Figure 9H shows the mAP curve and the average loss curve of the eighth experimental results, where the mAP value is 89.1%, the average loss rate is 0.3152, and the number of epochs is 20,000.
Figure 10H shows the confusion matrix using the eighth experiment weights on the test set, and the Precision is 0.91, the Recall is 0.94, the F1-score is 0.93, the Accuracy is 0.935, and the mAP result using the test set is 97.91%. It can be seen from
Figure 9H that in the eighth experiment, the curve also showed a downward trend after the epochs were 18,000, but the magnitude was not as large as that in the seventh experiment, so the mAP value was not so much affected, reaching 89.1%. The average loss rate fluctuates greatly when the epochs are 2000 to 4000, and then stabilizes in the later period, but there is still room for decline in terms of trends.
Figure 9I shows the mAP curve and the average loss curve of the ninth experimental results, where the mAP value is 92.1%, the average loss rate is 0.2790, and the number of epochs is 20,000.
Figure 10I shows the confusion matrix using the ninth experiment weights on the test set, and the Precision is 0.96, the Recall is 0.98, the F1-score is 0.97, the Accuracy is 0.94, and the mAP result using the test set is 98.87%. It can be seen from
Figure 9I that the mAP curve of the ninth experiment is similar to that of the fourth experiment; the difference is that the time for the fourth experiment to stabilize is later than that of the ninth experiment, so a higher accuracy rate is obtained. Compared with the fourth experiment, the average loss rate of the ninth experiment was lower than that of the fourth experiment, reaching a value of 0.2790.
Figure 9J shows the mAP curve and the average loss curve of the ninth experimental results, where the mAP value is 92.4%, the average loss rate is 0.2485, and the number of Epochs is 20,000.
Figure 10J shows the confusion matrix using the ninth experiment weights on the test set, and the Precision is 0.95, the Recall is 0.95, the F1-score is 0.95, the Accuracy is 0.935, and the mAP result using the test set is 98.19%. It can be seen from
Figure 9J that the results of the tenth experiment are close to the results of the second experiment, but the difference from the second experiment is that the mAP value of the tenth experiment is steeper when rising. The average loss rate was half that of the second experiment, coming to 0.2485.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}