The concept of
pattern-multiplicative average (PMA), or
pattern-geometric mean, was proposed with regard to matrix population models (MPMs) for the dynamics of discrete-structured populations [
1] in order to summarize the outcome of monitoring a local population of a biological species over several years and to calculate the ensuing measure for assessing the population viability.
1.1. Matrix Population Models
The MPM is represented by a system of difference equations,
for the vector of
population structure,
x(
t) ∈
, with a nonnegative
n ×
n matrix,
L(
t), called the
population projection matrix (
PPM) [
1]. Each component of
x(
t) is the (absolute or relative) number of individuals in the corresponding status-specific group at the observation year
t, while the elements of
L, called
vital rates (
ibidem), bear information about the rates of demographic processes in the population.
The
pattern of matrix
L shows the allocation of zero/nonzero elements in the matrix. It corresponds to the
associated directed graph [
2] called the
life cycle graph (
LCG) [
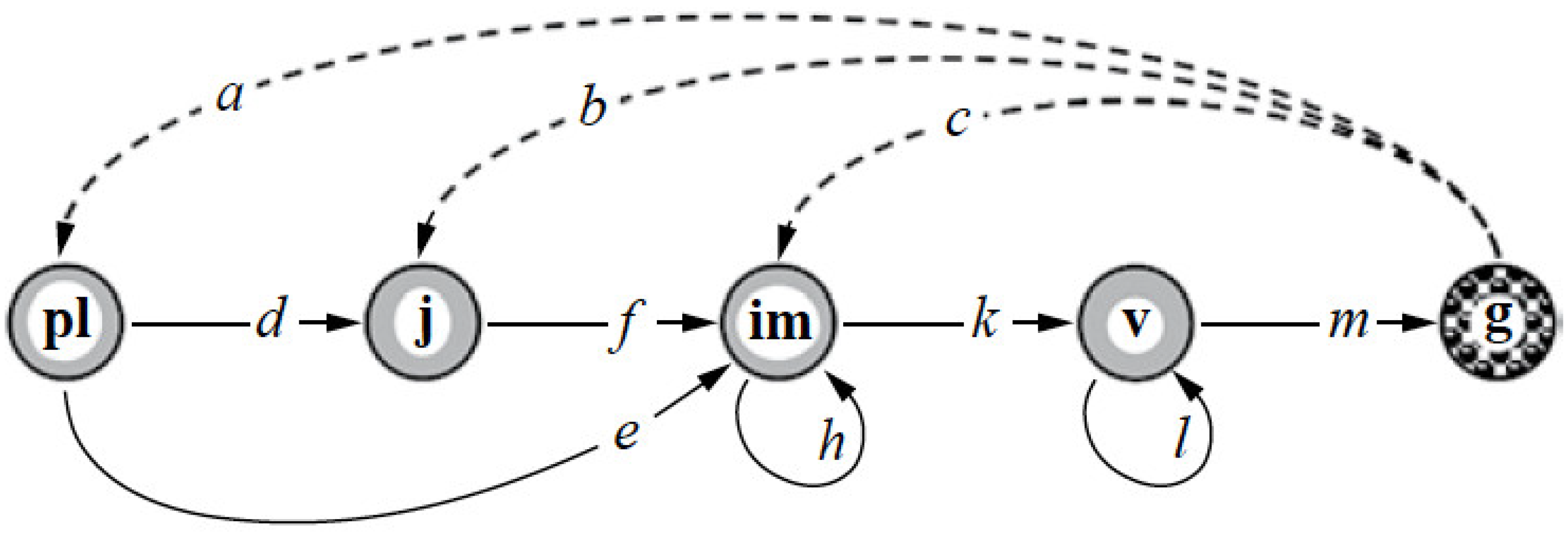
1] as it represents graphically the knowledge of life histories involved into the model in combination with the way the population structure is observed in the field or laboratory (
Figure 1 gives an example). If matrix
L is positive or
L =
0, then its pattern is
trivial. When the LCG is
strongly connected [
2], it signifies a certain integrity of the individuals’ life history and provides for the PPM being
irreducible [
3,
4]. However, the LCG ceases to be
strong when it includes post-reproductive stages (a further, more complicated sample follows).
In theoretical layouts and practical applications, it is convenient to consider the PPM as the sum,
of its parts that are responsible for the transitions (
T) between individual statuses and population recruitment (
F) [
1,
6]. In particular, if we number the graph nodes in
Figure 1 from left to right, then we have
associated with the LCG shown in
Figure 1. Matrix
T is always column substochastic, i.e., its column sums do not exceed 1 according to their biological sense.
“When calibrated reliably from data, matrix
L(
t) gives rise to a rich repertoire of qualitative properties and quantitative indices characterizing the population under study at the place where and the time when the data were mined” ([
7], p. 2/15). In particular, the
dominant eigenvalue,
λ1(
L) > 0, of matrix
L, which coincides with
ρ(
L) (the spectral radius of
L) and exists by the classical Perron–Frobenius theorem for nonnegative matrices [
3,
8,
9], “gives a quantitative measure of how the local population is adapted to its environment [
9], thus serving as an efficient tool of comparative demography [
1] and enabling a forecast of population viability. This ability ensues from the dynamics of trajectory
x(
t) as
t tends to +∞ when (a primitive [
4])
L(
t) =
L does not change with time” ([
7], p. 2/15). In formal terms, we have
where
x* is a positive eigenvector corresponding to
λ1, with a norm depending on
x(0) [
1]. Thus,
and the location of
λ1 relative to 1 may serve as a forecast of population viability if we believe that the vital rates do not change with
t.
In practice, however, they do change quantitatively (yet retaining their single pattern) with time when
t > 2. Each pair of consecutive years of observation generate a particular annual PPM
L(
t) obeying Equation (1) [
1,
5,
10], and we have a finite set,
L(0),
L(1), …,
L(
M − 1), of
M annual PPMs as a result of
M + 1 observation years. Different PPMs generate different or even controversial (Table 3 in [
9]) forecasts of population viability, and these motivate a task to average the set of PPMs in order to summarize all the years of observation.
1.2. Pattern-Multiplicative Average of Several PPMs
The logic behind averaging may be implicit or explicit and vary in complexity from the ordinariness of the arithmetic mean [
11,
12] through the weighted mean values of matrix elements [
13] to the PMA concept [
14] explained below.
Given a vector
x(0) at the initial year of observation and a vector
x(
M) at the final year, it follows from (1) that
i.e., the product of
M annual PPMs (in the chronological order) transforms
x(0) exactly to
x(
M). The logic of PMA suggests that the average matrix
G should do exactly the same when raised to the
Mth power. This is supposedly true for any observed vectors, whereby we conclude that
One more natural constraint on G consists in the pattern of G coinciding with that of the PPMs to be averaged.
Definition 1. Let L(0), L(1), …, L(M − 1) be nonnegative square matrices with a single nontrivial pattern. Matrix G = G{L(0), L(1), …, L(M − 1)} is called the pattern-multiplicative average (or pattern-geometric average) of the M given matrices if it has the same pattern and obeys the averaging Equation (7).
Note that the vector-matrix Equation (7) with an
n ×
n matrix
G is equivalent to a system of
n2 scalar algebraic equations, and the question is how many unknown elements of
G the system has to contain. When the pattern of
G is trivially complete, i.e., when all the nonnegative matrices
L(
t) are actually
positive, the number of unknowns equals
n2 as well, so that Equation (7) may have a nontrivial
exact solution (Table 3 in [
15]). However, when the pattern of
L(
t) is nontrivial, matching a real LCG, the number (
k) of unknown positive entries in
G is less than
n2, so that system (7) becomes an
overdetermined system of algebraic equations (see, e.g., [
16]). There is no reason to consider the remaining (
n2 −
k) equations as a linear combination of the former
k ones, so that the overdetermined system (7) is inconsistent and has no exact solutions.
The task to average M given PPMs can therefore be accomplished as an approximate solution to system (7), with a logical requirement to minimize the approximation error, which is measured in some reasonable way.
Definition 2. Let L(0), L(1), …, L(M − 1) be nonnegative square matrices with a single nontrivial pattern. Matrix G = G{L(0), L(1), …, L(M − 1)} is called an approximate pattern-multiplicative average (APMA) of the M given matrices if it has the same pattern and represents a solution to a constrained minimization problem for the approximation error in solving system (7).
In what follows, we use the same notation G for the APMA matrix.
1.3. Minimization Problem for the Approximation Error
Equation (7) is obviously equivalent to
so that a norm of the left-hand side can be considered as the approximation error when
G is an approximate solution rather than the exact one. When the matrix size (
n ×
n) and the number of cofactors (
M) are not too high, e.g.,
n = 5,
M = 7 in
Figure 1 and Equation (3), the APMA problem can be solved numerically by means of a modern software system such as MATLAB
® with an acceptable accuracy (Tables 3 and 4 and Appendix A in [
5]).
However, the standard MATLAB tools return very rough estimates for higher dimensions n. This is seen, for example, in the sample calculations with n = 11 and M = 12. This phenomenon is quite natural since the error function is highly non-convex, in which case the optimization problem is notoriously hard. The number of local minima can grow exponentially with n. Therefore, the standard computer optimization software suffers when n is relatively large. In this case, one needs to choose special mathematical tools suitable for a particular problem. We find those tools as combinations of modern algorithms for local and global optimization.




{kind=link}
{kind=link}

