
Improved G-Optimal Designs for Small Exact Response Surface Scenarios: Fast and Efficient Generation via Particle Swarm Optimization

Abstract
:1. Introduction
- 1.
- A brief literature survey of the last 20 years of algorithm development and approaches for generating exact G-optimal designs in small exact response surface scenarios.
- 2.
- Application of the PSO version with local communication topology, as described in Walsh and Borkowski (2022) to generating exact G-optimal designs for 29 design scenarios for experimental factors and a range of N (experiment sizes) [23].
- 3.
- For most of the 29 design scenarios, PSO was able to find a better G-optimal design than those currently known, and we provide a detailed catalogue of these new designs in the Supplementary Material.
- 4.
2. -Optimal Design for Small Exact Response Surface Scenarios
2.1. Small Exact Response Surface Designs
- 1.
- The number of design points N that can be afforded in the experiment.
- 2.
- The structure of the model one wishes to fit (here the second-order model).
- 3.
- A criterion which defines an optimal design. This is a function of .
2.2. G-Optimal Design
3. Literature Review: Algorithm Development and Current Best-Known Exact -Optimal Designs
Evaluating the -Score for Candidate Design
4. Particle Swarm Optimization for Generating Optimal Designs
- 1.
- few-to-no assumptions about the properties of the objective function to be optimized,
- 2.
- PSO is demonstrated to be robust to entrapment in local optima, and thereby is a good match to the exact optimal design generation problem,
- 3.
- simplicity—the core function of the algorithm can be explained via two simple update equations, and
- 4.
- in contrast to other meta-heuristics where studying a range of tuning parameters can yield more efficient searches for specific problems, PSO only has three tuning parameters and these have been studied extensively, both theoretically and empirically, with optimal values demonstrated for searches (such as ours) that reside in the common Cartesian product space with the typical Euclidean geometry, see [34,38,39,40] among others.
- := number of candidate designs (i.e., particles) in the swarm,
- := candidate design ,
- := the best design found by particle ,
- := the best design found by the particles in particle is communication neighborhood,
- := the best best design found by the swarm; this is the proposed optimal design,
- = -dimensional multivariate uniform distribution with lower and upper bound vectors and , respectively,
- := random matrix with elements ,
- ⊙:= Hadamard product (elementwise multiplication).
| Algorithm 1: PSO for Generating Exact Optimal Designs on the Hypercube |
|
5. Study Structure: Experimental Design and PSO Run Parameters
6. Results
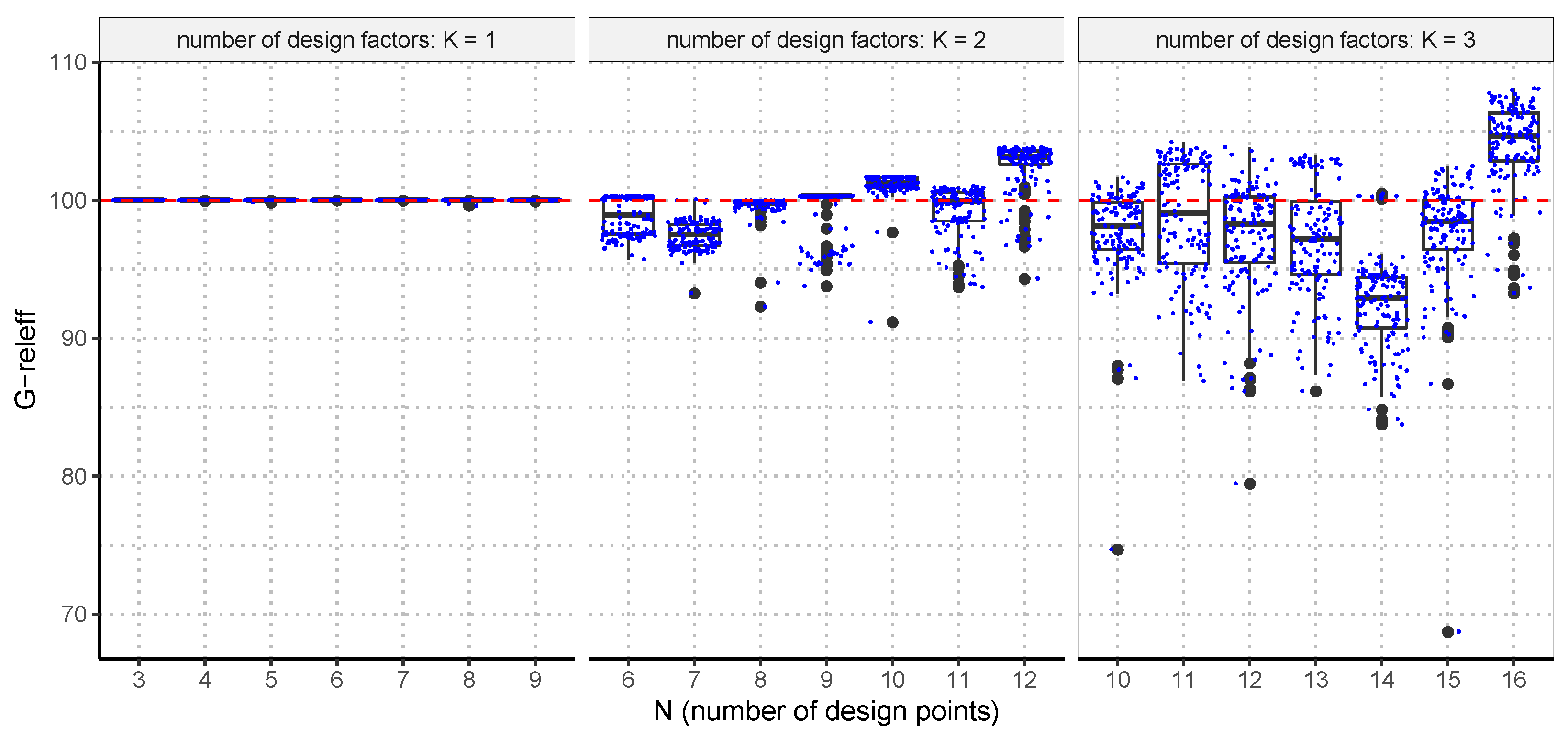
6.1. The Design Scenarios
6.2. The Design Scenarios
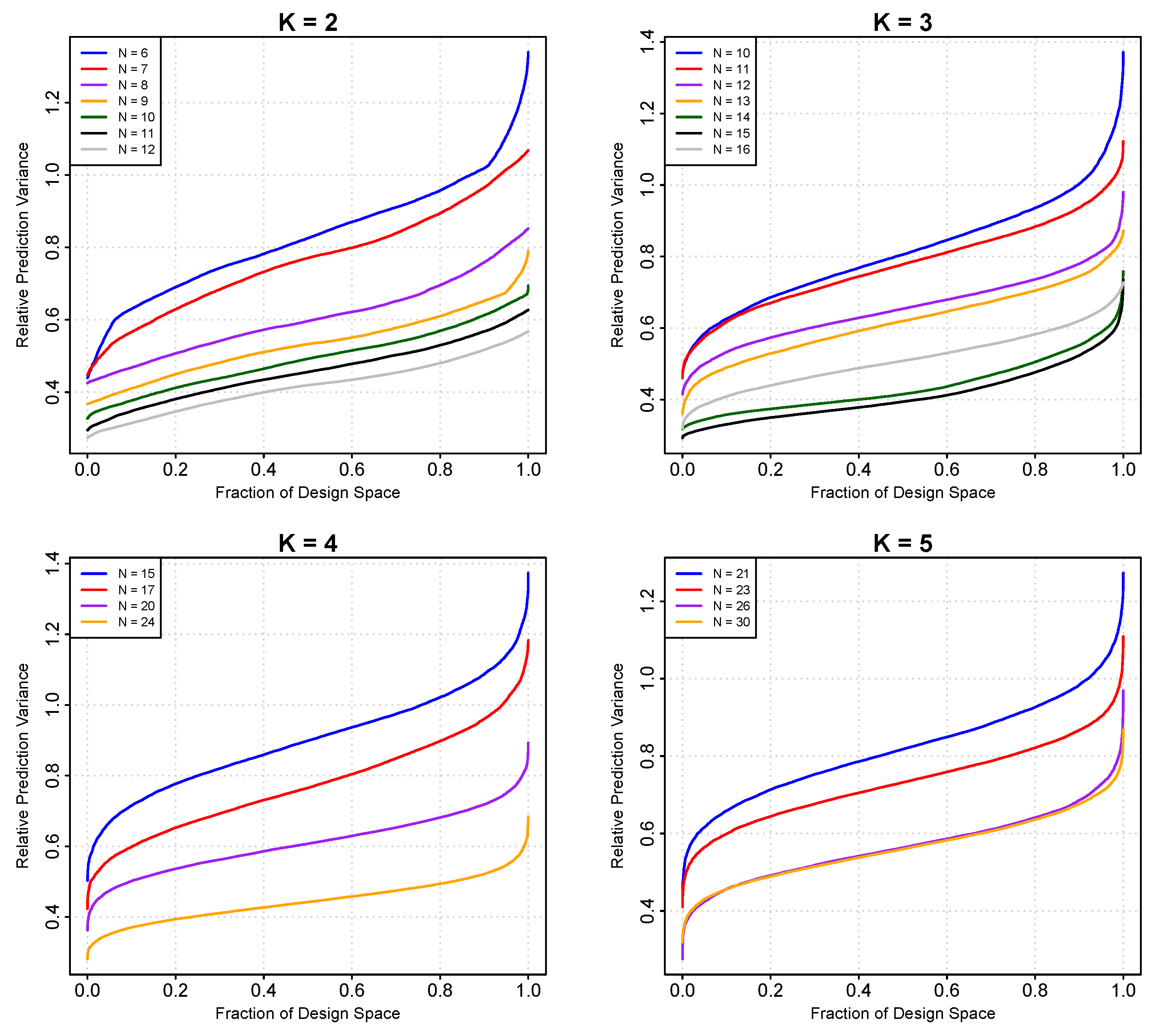
6.3. Prediction Variance Properties of the New -Efficient Designs
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Smith, K. On the standard deviations of adjusted and interpolated values of an observed polynomial function and its constants and the guidance they give towards the proper choice of the distributions of observations. Biometrika 1918, 12, 1–85. [Google Scholar] [CrossRef] [Green Version]
- Atkinson, A.; Bailey, R. One hundred years of the design of experiments on and off the pages of Biometrika. Biometrika 2001, 88, 53–97. [Google Scholar] [CrossRef]
- Kiefer, J. Optimum Experimental Designs. J. R. Stat. Soc. Ser. Methodol. 1959, 21, 272–319. [Google Scholar] [CrossRef]
- Kiefer, J. Optimum Designs in Regression Problems, II. Ann. Math. Stat. 1961, 32, 298–325. [Google Scholar] [CrossRef]
- Kiefer, J.; Wolfowitz, J. The Equivalence of Two Extremum Problems. Can. J. Math. 1960, 12, 363–366. [Google Scholar] [CrossRef]
- Dykstra, O. The Augmentation of Experimental Data to Maximize |X′X|. Technometrics 1971, 13, 682–688. [Google Scholar] [CrossRef]
- Mitchell, T.J. An Algorithm for the Construction of “D-Optimal” Experimental Designs. Technometrics 1974, 16, 203–210. [Google Scholar]
- Meyer, R.K.; Nachtsheim, C.J. The Coordinate-Exchange Algorithm for Constructing Exact Optimal Experimental Designs. Technometrics 1995, 37, 60–69. [Google Scholar] [CrossRef]
- Goos, P.; Jones, B. Optimal Design of Experiments: A Case study approach.; John Wiley and Sons, Ltd.: Hoboken, NJ, USA, 2011. [Google Scholar]
- Borkowski, J. Using a Genetic Algorithm to Generate Small Exact Response Surface Designs. J. Probab. Stat. Sci. 2003, 1, 65–88. [Google Scholar]
- Hernandez, L.N.; Nachtsheim, C.J. Fast Computation of Exact G-Optimal Designs Via Iλ-Optimality. Technometrics 2018, 60, 297–305. [Google Scholar] [CrossRef]
- Limmun, W.; Borkowski, J.; Chomtee, B. Using a Genetic Algorithm to Generate D-optimal Designs for Mixture Experiments. Qual. Reliab. Eng. Int. 2019, 35, 2657–2676. [Google Scholar] [CrossRef]
- Chen, R.B.; Hsu, Y.W.; Hung, Y.; Wang, W. Discrete particle swarm optimization for constructing uniform design on irregular regions. Comput. Stat. Data Anal. 2014, 72, 282–297. [Google Scholar] [CrossRef]
- Chen, R.B.; Hsieh, D.N.; Hung, Y.; Wang, W. Optimizing Latin hypercube designs by particle swarm. Stat. Comput. 2013, 23, 663–676. [Google Scholar] [CrossRef]
- Chen, R.B.; Li, C.H.; Hung, Y.; Wang, W. Optimal Noncollapsing Space-Filling Designs for Irregular Experimental Regions. J. Comput. Graph. Stat. 2019, 28, 74–91. [Google Scholar] [CrossRef]
- Lukemire, J.; Mandal, A.; Wong, W.K. d-QPSO: A Quantum-Behaved Particle Swarm Technique for Finding D-Optimal Designs With Discrete and Continuous Factors and a Binary Response. Technometrics 2019, 61, 77–87. [Google Scholar] [CrossRef] [Green Version]
- Mak, S.; Joseph, V.R. Minimax and Minimax Projection Designs Using Clustering. J. Comput. Graph. Stat. 2018, 27, 166–178. [Google Scholar] [CrossRef]
- Wong, W.K.; Chen, R.B.; Huang, C.C.; Wang, W. A Modified Particle Swarm Optimization Technique for Finding Optimal Designs for Mixture Models. PLoS ONE 2015, 10, 1–23. [Google Scholar] [CrossRef]
- Li, C.; Coster, D. A Simulated Annealing Algorithm for D-Optimal Design for 2-Way and 3-Way Polynomial Regression with Correlated Observations. J. Appl. Math. 2014, 2014, 746914. [Google Scholar] [CrossRef]
- Chen, R.B.; Chang, S.P.; Wang, W.; Tung, H.C.; Wong, W.K. Minimax optimal designs via particle swarm optimization methods. Stat. Comput. 2015, 25, 975–988. [Google Scholar] [CrossRef]
- Shi, Y.; Zhang, Z.; Wong, W. Particle swarm based algorithms for finding locally and Bayesian D-optimal designs. J. Stat. Distrib. Appl. 2019, 6, 3. [Google Scholar] [CrossRef]
- Chen, P.Y.; Chen, R.B.; Wong, W.K. Particle swarm optimization for searching efficient experimental designs: A review. WIREs Comput. Stat. 2022, 14, e1578. [Google Scholar] [CrossRef]
- Walsh, S.J.; Borkowksi, J.J. Generating Exact Optimal Designs via Particle Swarm Optimization: Assessing Efficacy and Efficiency via Case Study. Qual. Eng. 2022. [Google Scholar] [CrossRef]
- Rodríguez, M.; Jones, B.; Borror, C.M.; Montgomery, D.C. Generating and Assessing Exact G-Optimal Designs. J. Qual. Technol. 2010, 42, 3–20. [Google Scholar] [CrossRef]
- Myers, R.; Montgomery, D.; Anderson-Cook, C. Response Surface Methodology: Process and Product Optimization Using Designed Experiments, 4th ed.; John Wiley and Sons, Ltd.: Hoboken, NJ, USA, 2016. [Google Scholar]
- Saleh, M.; Pan, R. A clustering-based coordinate exchange algorithm for generating G-optimal experimental designs. J. Stat. Comput. Simul. 2016, 86, 1582–1604. [Google Scholar] [CrossRef]
- Cao, Y.; Smucker, B.; Robinson, T. A hybrid elitist Pareto-based coordinate exchange algorithm for constructing multi-criteria optimal experimental designs. Stat. Comput. 2017, 27, 423–437. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar] [CrossRef]
- Zambrano-Bigiarini, M.; Clerc, M.; Rojas-Mujica, R. Standard Particle Swarm Optimisation 2011 at CEC-2013: A baseline for future PSO improvements. In Proceedings of the 2013 IEEE Congress on Evolutionary Computation, Cancun, Mexico, 20–23 June 2013; pp. 2337–2344. [Google Scholar]
- Clerc, M. Standard Particle Swarm Optimisation. Technical Report, HAL Achives-Ouvertes. 2012. Available online: https://hal.archives-ouvertes.fr/hal-00764996/ (accessed on 20 August 2022).
- Eberhart, R.; Kennedy, J. A new optimizer using particle swarm theory. In MHS’95, Proceedings of the Sixth International Symposium on Micro Machine and Human Science, Nagoya, Japan, 4–6 October 1995; IEEE: Piscatvey, NJ, USA, 1995; pp. 39–43. [Google Scholar] [CrossRef]
- Kennedy, J. The particle swarm: Social adaptation of knowledge. In Proceedings of the 1997 IEEE International Conference on Evolutionary Computation (ICEC ’97), Indianapolis, IN, USA, 13–16 April 1997; pp. 303–308. [Google Scholar] [CrossRef]
- Eberhart, R.C.; Shi, Y. Comparison between genetic algorithms and particle swarm optimization. In Proceedings of the Evolutionary Programming VII 7th International Conference, EP98, San Diego, CA, USA, 25 March 1998; Porto, V.W., Saravanan, N., Waagen, D., Eiben, A.E., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; pp. 611–616. [Google Scholar]
- Clerc, M.; Kennedy, J. The particle swarm-explosion, stability, and convergence in a multidimensional complex space. IEEE Trans. Evol. Comput. 2002, 6, 58–73. [Google Scholar] [CrossRef] [Green Version]
- Engelbrecht, A.P. Particle Swarm Optimization: Global Best or Local Best? In Proceedings of the 2013 BRICS Congress on Computational Intelligence and 11th Brazilian Congress on Computational Intelligence, Ipojuca, Brazil, 8–11 September 2013; pp. 124–135. [Google Scholar] [CrossRef]
- Kennedy, J. Swarm Intelligence. In Handbook of Nature Inspired and Innovative Computing: Integrating Classical Models with Emerging Technologies; Springer: Berlin/Heidelberg, Germany, 2006; pp. 187–220. [Google Scholar]
- Bratton, D.; Kennedy, J. Defining a Standard for Particle Swarm Optimization. In Proceedings of the 2007 IEEE Swarm Intelligence Symposium, Honolulu, HI, USA, 1–5 April 2007; pp. 120–127. [Google Scholar] [CrossRef]
- Eberhart, R.C.; Shi, Y. Comparing inertia weights and constriction factors in particle swarm optimization. In Proceedings of the 2000 Congress on Evolutionary Computation, CEC00 (Cat. No.00TH8512), La Jolla, CA, USA, 16–19 July 2000; pp. 84–88. [Google Scholar] [CrossRef]
- Clerc, M. The swarm and the queen: Towards a deterministic and adaptive particle swarm optimization. In Proceedings of the 1999 Congress on Evolutionary Computation-CEC99 (Cat. No. 99TH8406), Washington, DC, USA, 6–9 July 1999; pp. 1951–1957. [Google Scholar] [CrossRef]
- Shi, Y.; Eberhart, R.C. Parameter selection in particle swarm optimization. In Proceedings of the Evolutionary Programming VII 7th International Conference, EP98, San Diego, CA, USA, 25 March 1998; Porto, V.W., Saravanan, N., Waagen, D., Eiben, A.E., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; pp. 591–600. [Google Scholar]
- Walsh, S.J. Development and Applications of Particle Swarm Optimization for Constructing Optimal Experimental Designs. Ph.D. Thesis, Montana State University, Bozeman, MT, USA, 2021. [Google Scholar]
- Bezanson, J.; Edelman, A.; Karpinski, S.; Shah, V.B. Julia: A fresh approach to numerical computing. SIAM Rev. 2017, 59, 65–98. [Google Scholar] [CrossRef] [Green Version]
- Zahran, A.; Anderson-Cook, C.M.; Myers, R.H. Fraction of Design Space to Assess Prediction Capability of Response Surface Designs. J. Qual. Technol. 2003, 35, 377–386. [Google Scholar] [CrossRef]
- Jensen, W.A. Open problems and issues in optimal design. Qual. Eng. 2018, 30, 583–593. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| # Exp. Factors | Experiment Sizes | Algorithms | Authors |
|---|---|---|---|
| 1 | 3, 4, 5, 6, 7, 8, 9 | GA -CEXCH | Borkowski (2003) Hernandez and Nachtsheim (2018) |
| 2 | 6, 7, 8, 9, 10,11, 12 | GA CEXCH cCEA ( = 7 to 12) | Borkowski (2003) Rodriquez et al. (2010) Saleh and Pan (2015) |
| 3 | 10, 11,12,13,14,15,16 | GA CEXCH cCEA ( = 11 to 16) | Borkowski (2003) Rodriquez et al. (2010) Saleh and Pan (2015) |
| 4 | 15, 20, 24 | CEXCH cCEA ( = 24) | Rodriguez et al. (2010) Saleh and Pan (2015) |
| 16 | cCEA | Saleh and Pan (2015) | |
| 17 | -CEXCH | Hernandez and Nachtsheim (2018) | |
| 5 | 21, 26, 30 | CEXCH cCEA ( = 26) | Rodriquez et al. (2010) Saleh and Pan (2015) |
| 23 | -CEXCH | Hernandez and Nachtsheim (2018) |
| Design Scenario | Best Design Efficiency Relative to G-GA) | |||
|---|---|---|---|---|
| -PSO | -CEXCH | -CEXCH | ||
| 3 | 100.0 | 100.0 | 100.0 | |
| 4 | 100.0 | 96.2 | 98.7 | |
| 5 | 100.0 | 97.0 | 98.7 | |
| 1 | 6 | 100.0 | 100.0 | 100.0 |
| 7 | 100.0 | 98.8 | 99.7 | |
| 8 | 100.0 | 94.7 | 99.4 | |
| 9 | 100.0 | 100.0 | 89.4 | |
| 6 | 100.3 | 94.1 | 96.5 | |
| 7 | 100.1 | 95.5 | 97.9 | |
| 8 | 100.0 | 94.7 | 99.7 | |
| 2 | 9 | 100.3 | 95.8 | 97.0 |
| 10 | 101.7 | 93.2 | 97.5 | |
| 11 | 101.0 | 97.0 | 94.0 | |
| 12 | 103.9 | 95.1 | 101.2 | |
| 10 | 101.6 | 95.4 | 93.1 | |
| 11 | 104.2 | 96.9 | 92.9 | |
| 12 | 103.8 | 90.3 | 90.7 | |
| 3 | 13 | 103.2 | 99.9 | 92.9 |
| 14 | 100.5 | 100.0 | 87.6 | |
| 15 | 102.5 | 100.1 | 98.5 | |
| 16 | 108.1 | 100.2 | 100.1 | |
| Design Scenario | G-PSO | -CEXCH | G-CEXCH | G-GA | |||
|---|---|---|---|---|---|---|---|
| estimate | 95% CI | ||||||
| 3 | 6.000 | 6.155 | (6.145, 6.165) | 6.0 | 5.5 | 6.9 | |
| 4 | 6.535 | 6.690 | (6.684, 6.695) | 6.4 | 5.7 | 7.0 | |
| 5 | 6.681 | 6.835 | (6.831, 6.840) | 6.6 | 5.8 | 7.1 | |
| 1 | 6 | 6.226 | 6.381 | (6.373, 6.388) | 6.4 | 5.9 | 7.2 |
| 7 | 6.685 | 6.840 | (6.835, 6.845) | 6.8 | 6.0 | 7.2 | |
| 8 | 6.761 | 6.916 | (6.912, 6.921) | 6.8 | 6.0 | 7.3 | |
| 9 | 6.405 | 6.560 | (6.553, 6.566) | 6.9 | 6.1 | 7.4 | |
| 6 | 7.088 | 7.243 | (7.240, 7.246) | 7.2 | 7.3 | 8.4 | |
| 7 | 7.086 | 7.241 | (7.238, 7.244) | 7.4 | 7.3 | 8.5 | |
| 8 | 7.042 | 7.197 | (7.194, 7.200) | 7.2 | 7.5 | 8.6 | |
| 2 | 9 | 7.119 | 7.274 | (7.271, 7.277) | 7.0 | 7.5 | 8.6 |
| 10 | 7.163 | 7.318 | (7.315, 7.321) | 7.3 | 7.6 | 8.7 | |
| 11 | 7.221 | 7.376 | (7.373, 7.378) | 7.4 | 7.6 | 8.7 | |
| 12 | 7.196 | 7.351 | (7.348, 7.354) | 7.7 | 7.7 | 8.7 | |
| 10 | 7.437 | 7.592 | (7.590, 7.594) | 8.0 | 8.7 | 9.6 | |
| 11 | 7.511 | 7.666 | (7.664, 7.668) | 7.8 | 8.8 | 9.7 | |
| 12 | 7.544 | 7.699 | (7.697, 7.701) | 7.9 | 8.8 | 9.7 | |
| 3 | 13 | 7.538 | 7.692 | (7.691, 7.694) | 7.5 | 8.9 | 9.7 |
| 14 | 7.543 | 7.698 | (7.696, 7.700) | 7.6 | 9.0 | 9.8 | |
| 15 | 7.515 | 7.670 | (7.668, 7.671) | 7.6 | 9.2 | 9.8 | |
| 16 | 7.556 | 7.711 | (7.709, 7.713) | 7.6 | 9.9 | 9.8 | |
| Design Scenario | PSO Peformance | Published Design Quality | |||
|---|---|---|---|---|---|
| -PSO Design Relative Efficiency | -PSO | CEXCH Algorithm | -CEXCH | ||
| 4 | 14 | 145.41 | 71.09 | CEXCH | 48.89 |
| 17 | 105.36 | 73.90 | -CEXCH | 70.14 | |
| 20 | 123.18 | 80.20 | CEXCH | 65.11 | |
| 24 | 106.5 | 85.95 | CEXCH | 81.05 | |
| 5 | 21 | 177.26 | 68.67 | CEXCH | 38.74 |
| 23 | 100.24 | 73.19 | -CEXCH | 73.02 | |
| 26 | 103.92 | 75.31 | CEXCH | 72.47 | |
| 30 | 100.47 | 76.16 | CEXCH | 75.80 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Walsh, S.J.; Borkowski, J.J. Improved G-Optimal Designs for Small Exact Response Surface Scenarios: Fast and Efficient Generation via Particle Swarm Optimization. Mathematics 2022, 10, 4245. https://doi.org/10.3390/math10224245
Walsh SJ, Borkowski JJ. Improved G-Optimal Designs for Small Exact Response Surface Scenarios: Fast and Efficient Generation via Particle Swarm Optimization. Mathematics. 2022; 10(22):4245. https://doi.org/10.3390/math10224245
Chicago/Turabian StyleWalsh, Stephen J., and John J. Borkowski. 2022. "Improved G-Optimal Designs for Small Exact Response Surface Scenarios: Fast and Efficient Generation via Particle Swarm Optimization" Mathematics 10, no. 22: 4245. https://doi.org/10.3390/math10224245