1. Introduction
Studies on reliability and life testing frequently use censored data. It is necessary for experimenters to gather data using censored samples for reasons including conserving the working experimental units for future use, decreasing the total time on the test, and financial constraints. The two censoring methods that are most commonly applied in life testing and reliability studies are time censoring (Type-I) and failure censoring (Type-II) schemes. These methods lack the flexibility to allow units to be withdrawn from the experiment at any point other than the terminal point. To avoid this disadvantage, a more flexible censoring scheme known as a progressive Type-II censoring scheme is introduced. Kundu and Joarder [
1] suggested a progressive Type-I hybrid censoring scheme, in which
n identical items are tested using a specified progressive censoring scheme
and the test is ended at random time
, where
T is a predetermined time. This scheme has the disadvantage that the useful sample size is random and might be found to be a very small number or zero for reliable products. As a result, the statistical inference methods will be inefficient.
To overcome this drawback, Ng et al. [
2] proposed an adaptive progressive Type-II hybrid censoring scheme to increase the efficiency of statistical analysis. The number of failures
m is predetermined in advance in this scheme, and the testing time is permitted to run over the prefixed time
T. Moreover, we have the progressive censoring scheme
, but the values of some of the
may be adjusted consequently during the test. This scheme can be described briefly as follows: Assume that
n units are placed on a life test and
is the desired number of failures. At the time of the first failure
,
units are randomly removed from the test. Similarly, at the time of the second failure
,
units are randomly withdrawn from the test, and so on. If the
failure happens before time
T , the test stops at this time and we will have the usual progressive Type-II censoring. On the other hand, if
, where
and
is the
failure time happen before time
T, then we will not withdraw any surviving item from the test by putting
and
. This setting allows us to end the test when we reach the preferred number of failures
m, and the total test time will not be too far away from the ideal time
T. Let
be an adaptive progressively Type-II hybrid censored sample from a continuous population with probability density function (PDF)
and cumulative distribution function (CDF)
with progressive censoring scheme
, then the likelihood function of the observed data can be expressed as follows
where
C is a constant that is independent of the parameters. Various studies based on the adaptive progressive Type-II hybrid censoring scheme have been conducted. Hemmati and Khorram [
3] studied the estimation problems of the exponential distribution in the presence of a competing risks model. Nassar and Abo-Kasem [
4] investigated some estimation methods for the inverse Weibull distribution. Ateya and Mohammed [
5] discussed the statistical inferences of the exponentiated exponential distribution. Nassar et al. [
6,
7] studied the estimation of Weibull and Rayleigh distributions, respectively. See also, Sobhi and Soliman [
8], Panahi and Moradi [
9], Chen and Gui [
10], Panahi and Asadi [
11], Okasha et al. [
12] and Alotaibi et al. [
13] among many others.
Furthermore, the Lindley distribution, first proposed by Lindley [
14], has been used extensively in different areas of science and technology. It is an important statistical model for studying stress–strength reliability modeling. Recently, Chouia and Zeghdoudi [
15] proposed a new modification version of the Lindley distribution, as a special mixture of exponential and Lindley distributions, called XLindley (XL) distribution. Suppose that
X is a lifetime random variable of an experimental units follow XL with scale parameter
. Hence, the corresponding PDF and CDF of
X are given by
and
respectively. The reliability characteristics of any lifetime model are the main features for evaluating the capacity of any electronic system that a reliability practitioner has frequently used.
Therefore, some reliability indices of the XL distribution can be also investigated as unknown parameters, namely, reliability function (RF)
and hazard rate function (HRF)
at distinct time
t which can be given, respectively, by
and
The novelty of our study comes from the fact that it is the first to investigate the estimation issues of the XL distribution under the adaptive progressive Type-II hybrid censoring scheme. We can list the main objectives of this study as follows: (1) To obtain the maximum likelihood estimator (MLE) of the scale parameter , RFand HRF along with their approximate confidence intervals (ACIs). (2) To acquire the Bayesian estimators of the different parameters using the squared error loss (SEL) function as well as the associated highest posterior density (HPD) credible intervals. (3) To compare the efficiency of the various point and interval estimators through a simulation study. (4) To show the applicability of the offered methods via exploring two real data sets, and to see how the different proposed methods can work in real-life scenarios.
The rest of the article is structured as follows:
Section 2 is devoted to discussing the MLEs and ACIs of the parameter, and RF and HRF for the the XL distribution. In
Section 3, the Bayesian estimating method is discussed. The findings of a simulation investigation are presented in
Section 4. Two real data sets are examined in
Section 5, and the paper is concluded in
Section 6.
2. Classical Inference
Let
be an adaptive progressively Type-II hybrid censored sample of size
m with progressive censoring scheme
from XL model. In this case, the likelihood function, ignoring the constant term, can be obtained from (
1), (
2) and (
3), as follows
where
for simplicity. Let
be the log-likelihood function, then the MLE of the parameter
, denoted by
, can be obtained by maximizing
expressed as
with respect to
.
Instead of maximizing the objective function in (
7), the MLE
can be acquired by solving the following nonlinear equation
One can see from (
8) that there is no closed form for the MLE
. Hence, to obtain the MLE of the parameter
, a numerical technique may be utilized to solve (
8) to arrive at
. Once
is obtained, it is simple to use the invariance property of the MLE to estimate RF and HRF. By replacing the parameter
with the corresponding MLE
, we can obtain the MLEs of RF and HRF from (
4) and (
5), respectively, as follows
and
Employing the asymptotic properties of the MLE, it is of interest to construct the ACI of the unknown parameter
as well as RF and HRF. Based on the law of large samples, it is known that
is normally distributed with mean
and variance–covariance matrix
, where
is the Fisher information matrix obtained by taking expectation of minus second order derivative of the log-likelihood function. The second-order derivative of
with respect to
is given by
Practically, we usually estimate
by
due to the complex expression of (
11) where the expectation is not possible to obtain in this case. Thus,
Then, using the level of significance
, the
ACI of
can be obtained as
where
is obtained from (
12) and
is the upper
th percentile point of the standard normal distribution.
Furthermore, to create the ACIs of RF and HRF, we need to obtain the variances of their estimators. Here, we utilize the delta method to approximate estimates of the variance of estimators of RF and HRF. It carries a too-complicated function for analytically calculating the variance, makes a linear approximation of that function, and then obtains the variance of the simpler linear function, see Greene [
16].
To obtain such variances, let
and
, where
and
Then, the approximate estimated variances of
and
can be acquired, respectively, as
where
is given by (
12). Now, the
approximate confidence intervals for
and
are given, respectively, by
3. Bayes MCMC Paradigm
In this section, we investigate the Bayesian estimation of the unknown parameter
, RF and HRF of XL model under the assumption that the data are adaptive progressively Type-II hybrid censored samples. The Bayesian estimators are acquired utilizing the SEL function which is the most popular symmetric loss function. The selection of prior distributions is essential in Bayesian analysis, despite there being no clear regulation or procedures in the literature on choosing the most suitable priors for the unknown parameters. Here, we assume the gamma prior for the parameter
. It is noted that there is no conjugate prior for the parameter
and it is not easy to employ Jeffrey’s prior due to the complex expression of the Fisher information matrix. Accordingly, we assume the gamma prior in this case. Since the gamma prior supplies different shapes based on parameter values and is flexible in nature, it can be adopted as an appropriate prior for the parameter
and may not deliver difficult inferential cases. For more details on the use of gamma prior, see Ahmed [
17] and Dey et al. [
18]. Suppose that
, thus the prior distribution of
can be expressed up to proportional as
where
a and
b are the hyperparameters. To obtain the Bayesian estimator of the parameter
, we need to derive the corresponding posterior distribution. By combining the likelihood function in (
6) with the prior distribution in (
15), the posterior distribution of the parameter
can be expressed as follows
where
A is the normalized constant expressed as
To obtain the Bayesian estimator of the unknown parameter
or any function of it as RF and HRF, say
, under the SEL function, we need to acquire the posterior mean as follows:
Due to the complex form of (
17), which consists of the ratio of two integrals, it is not possible to obtain the Bayesian estimator of
analytically. Therefore, we adopt the MCMC procedure to obtain the Bayesian estimates of
, RF and HRF, and the associated HPD credible intervals. To apply the MCMC procedure, we must derive the full conditional distribution of the parameter
. From (
16), the full conditional distribution can be written as follows
It is clear from (
18) that the full conditional distribution of the parameter
cannot be reduced to any well-known distribution. Thus, to obtain the Bayesian estimates of the parameter
, RF, and HRF, the Markov chain Monte Carlo (MCMC) method is employed. In our case, the Metropolis–Hastings (M–H) algorithm is considered to generate samples from (
18) and then to obtain the Bayesian estimates as well as the corresponding HPD credible intervals. An important issue when using the M–H procedure is to select the proposal distribution of the parameter
. A simple way is to plot the full conditional distribution in (
18).
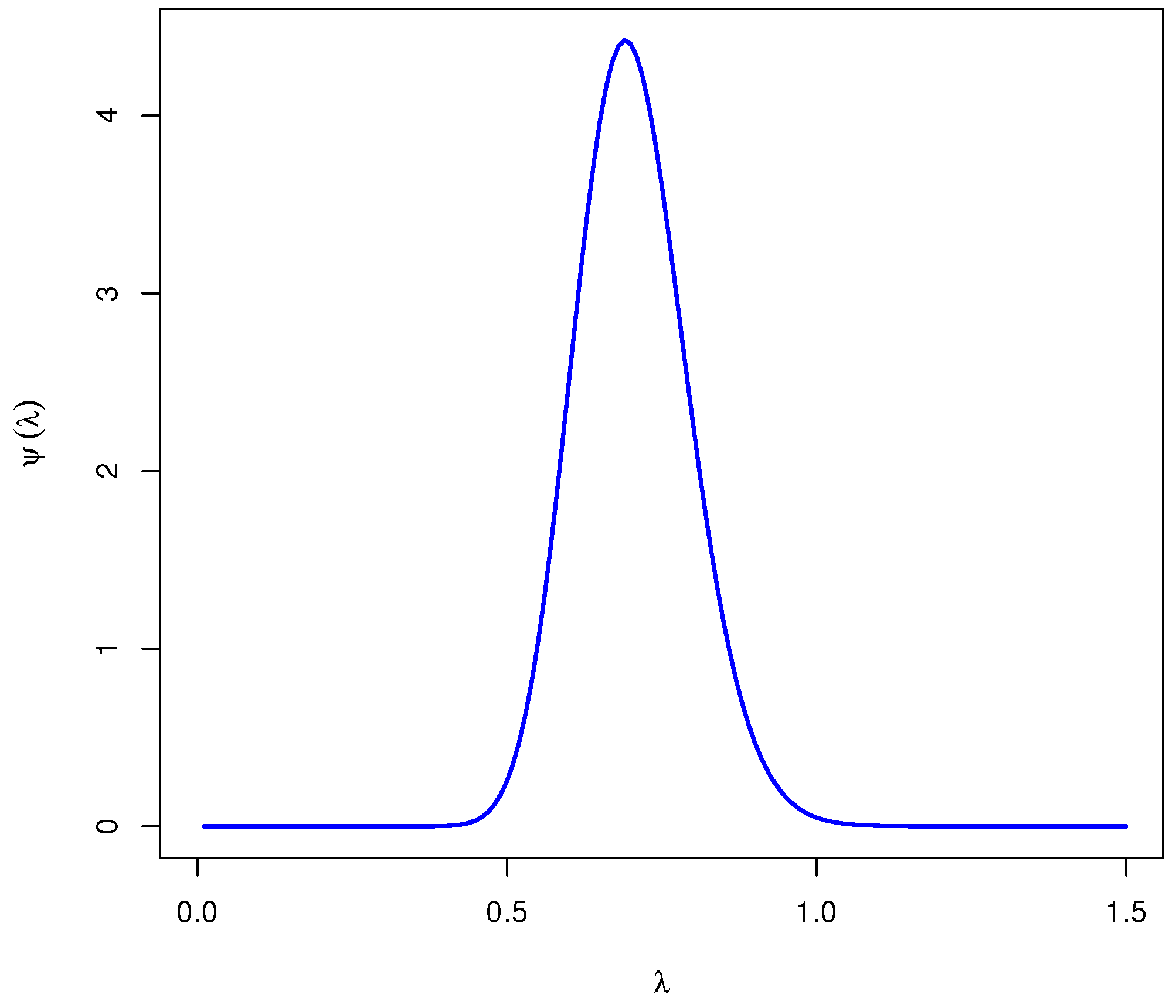
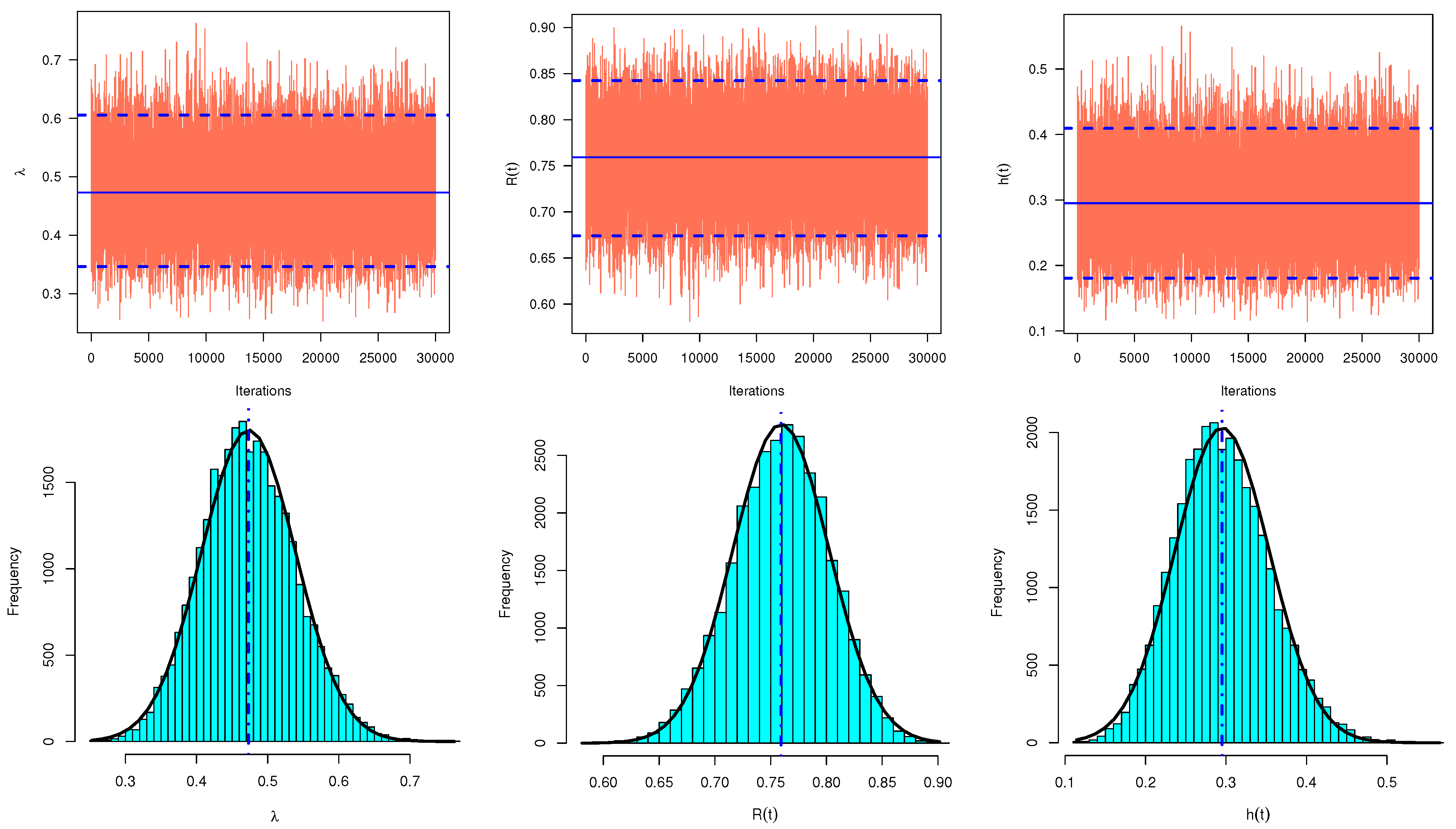
Figure 1 shows that the distribution in (
18) behaves similarly to the normal distribution. Therefore, to generate samples utilizing M–H procedure and calculate the Bayesian estimates of
, RF and HRF and the associated HPD credible intervals, the following steps should be completed:
- Step 1.
Set the start value for the parameter , say .
- Step 2.
Put .
- Step 3.
Generate
from the full conditional distribution in (
18) from the normal distribution
.
- Step 4.
- Step 5.
Generate w, where .
- Step 6.
If , set , otherwise, set .
- Step 7.
Based on a distinct value
t, obtain
and
as
and
- Step 8.
Put .
- Step 9.
Redo Steps 3–8
H times to bring
- Step 10.
Calculate the Bayesian estimates of
,
and
employing the SEL function, after a burn-in period
M, as
- Step 11.
To acquire the HPD credible intervals of
, RF, and HRF: First, sort the generated samples of
,
and
after burn-in period as
,
,
,
and
, respectively. Employing the procedure suggested by Chen and Shao [
19], the
two-sided HPD credible interval for the unknown parameter
is given by
where
is selected such that
The largest integer less than or equal to x is denoted by . Then, the HPD credible interval of x with the smallest length is that interval. The HPD credible intervals of RF and HRF can be easily computed using the same approach.
4. Monte Carlo Simulation
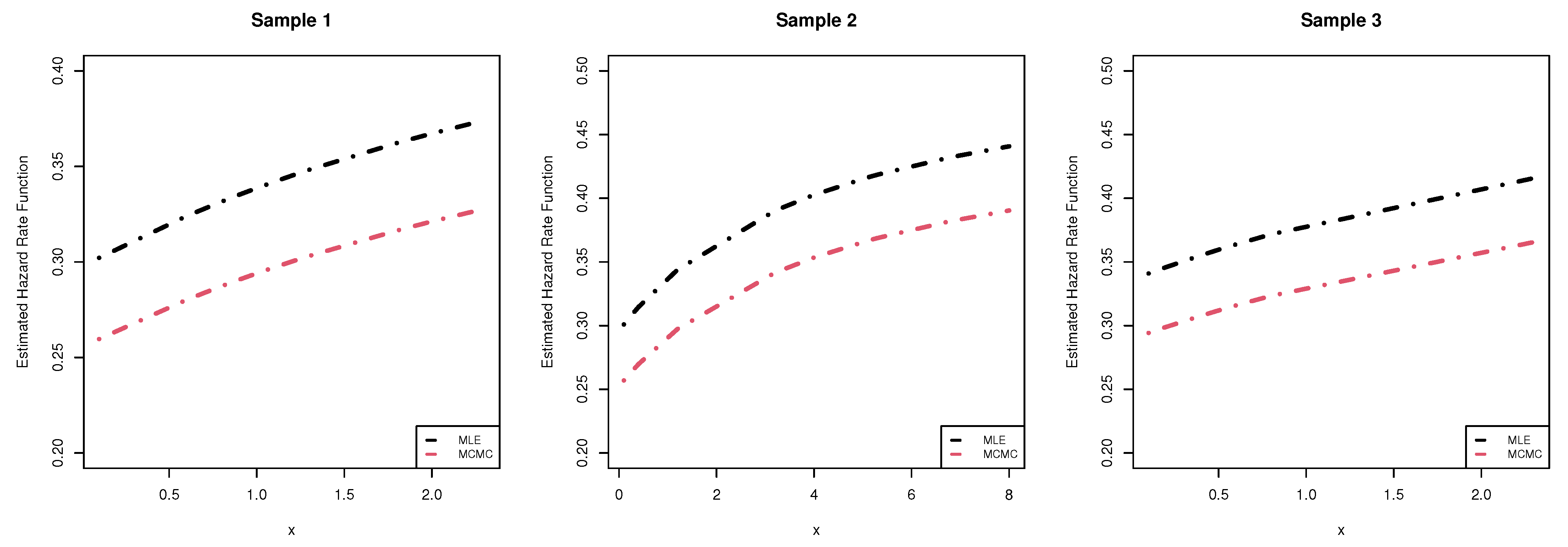
To evaluate the behavior of the proposed estimators of the unknown parameters , , and obtained in the proceeding sections, based on two different true values of as and , some Monte Carlo simulations are conducted. At given time , the true value of the reliability characteristics and are 0.972 and 0.283 for as well as 0.881 and 1.266 for , respectively. Using various combinations of n, m, R, and T, a 1000 adaptive Type-II progressively hybrid censored samples are generated. Using various choices of n (total sample size), (failure information percentage (FIP)) and T (threshold time point) such as: n (=40, 80), m (=30, 60, 90)% and T (=1, 2), the simulation study is performed. Once the observed number of failed subjects achieves (or exceeds) a certain value m, the experiment is stopped.
In addition, to assess the performance of removal patterns
, various progressive censoring schemes (PCSs) are also taken into account as
To simulate adaptive Type-II progressively hybrid censored samples of size m from a given sample of size n with given progressive Type-II censoring scheme , perform the following procedure:
- Step 1.
Generate an ordinary Type-II progressive censored sample
as discussed in Balakrishnan and Cramer [
20] as
- (i)
Generate m independent observations as .
- (ii)
Set for
- (iii)
Set for . Hence, is a simulated sample of size m from the uniform distribution.
- (iv)
Set the Type-II progressive censored sample from is generated.
- Step 2.
Obtain d-th failure and discard for .
- Step 3.
Obtain order statistics from a truncated distribution with sample size .
To assess the performance of the gamma conjugate priors on the Bayesian estimates, by considering two information criteria for selecting the hyperparameter values called prior mean and prior variance, two sets of the hyperparameters are used, namely:
Prior-I (say P1):(1.5, 3) and Prior-II (say P2):(2.5, 5) when .
Prior-I (say P1):(4.5, 3) and Prior-II (say P2):(7.5, 5) when .
Using the MCMC algorithm described in
Section 3, 12,000 MCMC samples are generated and then the first 2,000 MCMC variates are discarded as burn-in. After that, the Bayes estimates of
,
, and
utilizing the SEL function and associated 95% HPD credible intervals are computed based on the remaining 10,000 MCMC samples. However, based on each setting, both frequentist/Bayes point estimates as well as the asymptotic/HPD credible interval estimates of
,
, and
are obtained. The average estimates of
,
, and
(say
) based on any method are obtained as
where
is the number of generated sequence data,
is the calculated estimate of
at the
j-th simulated sample,
,
and
.
Further, the comparison between the point estimates of
is made based on their root mean squared errors (RMSEs) and mean relative absolute biases (MRABs) as
and
respectively. Furthermore, the comparison between interval estimates is made using their average confidence lengths (ACLs) and coverage percentages (CPs) given, respectively, by
and
where
is the indicator function and
and
denote the lower and upper bounds of the interval estimate.
Using three useful packages programmed in
4.1.2 software, namely, the ‘coda’ (by Plummer et al. [
21]), ‘maxLik’ (by Henningsen and Toomet [
22]), and ‘GoFKernel’ (by Pavia [
23]) packages, all numerical evaluations were implemented. Recently, these packages were also recommended by Elshahhat and Nassar [
24] and Elshahhat and Elemary [
25]. The
codes that support the findings of this study are available from the corresponding author upon reasonable request. All simulation results of
,
, and
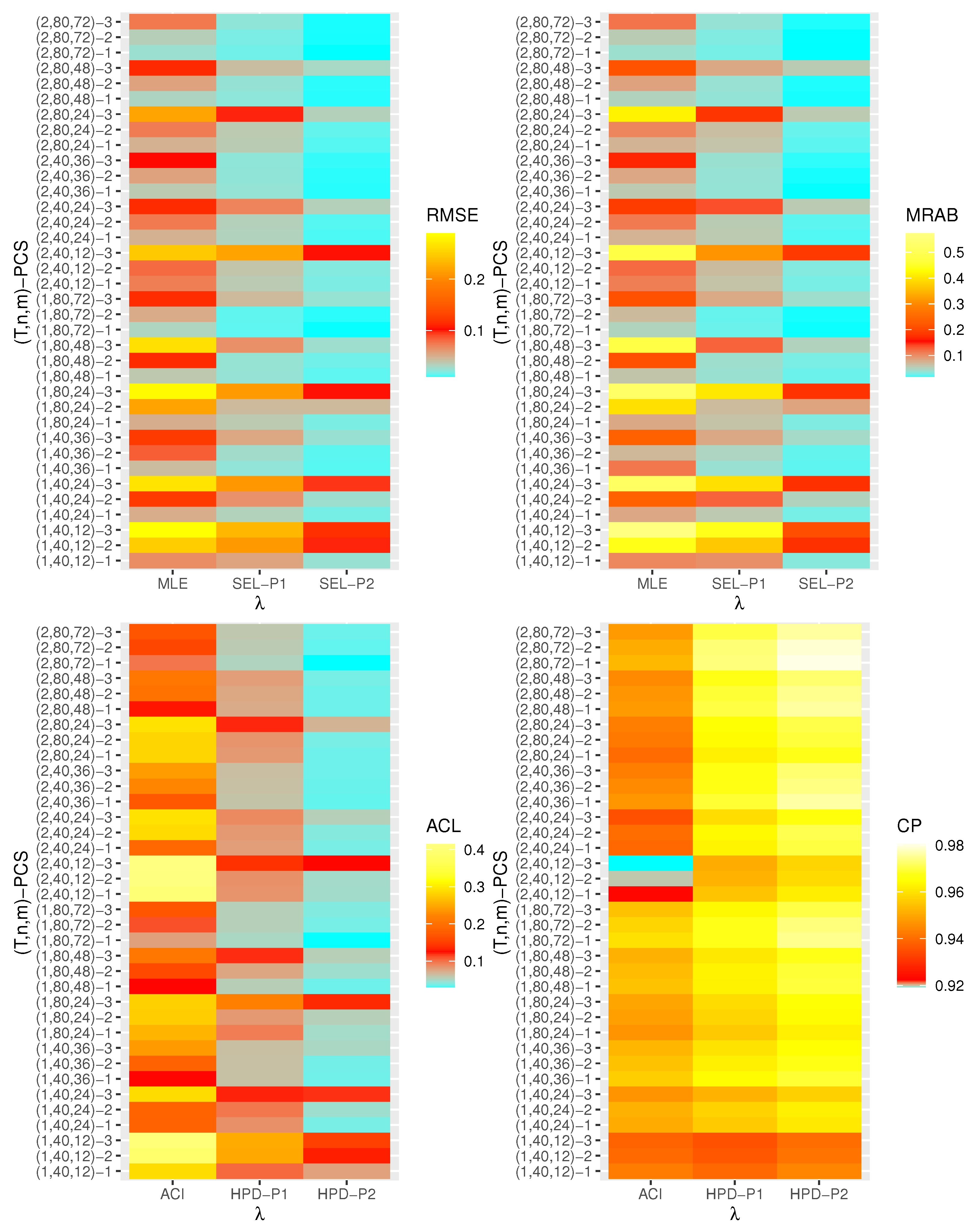
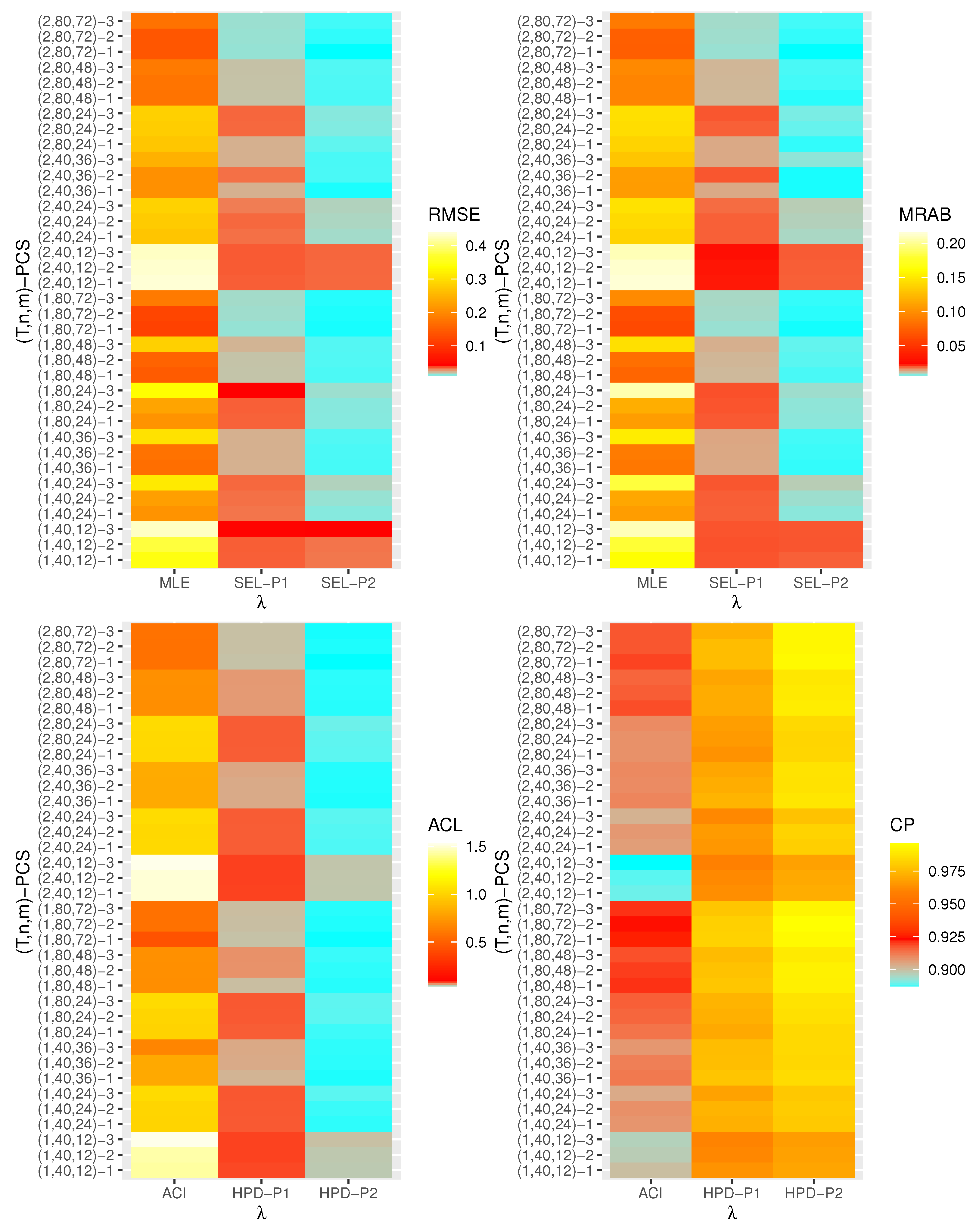
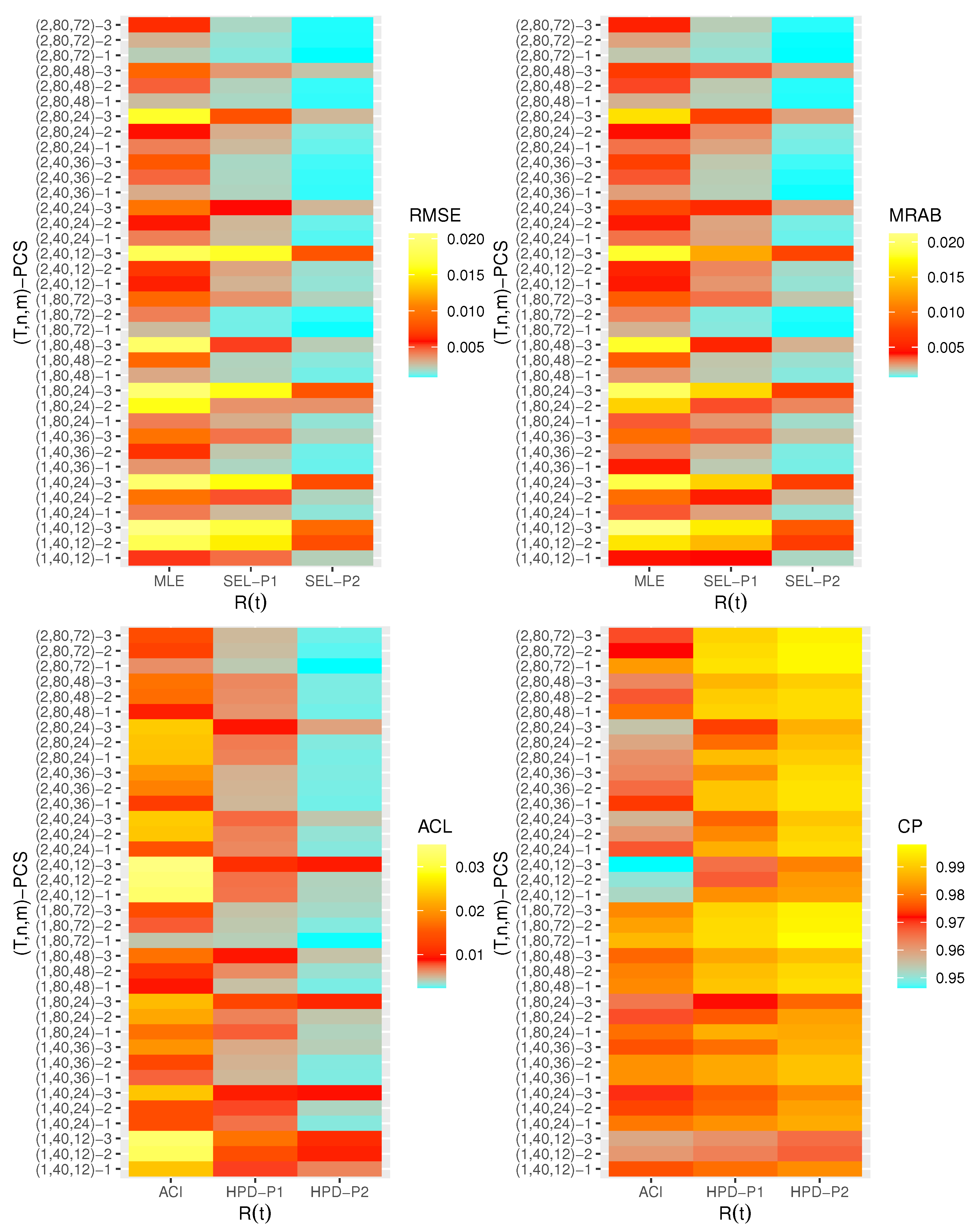
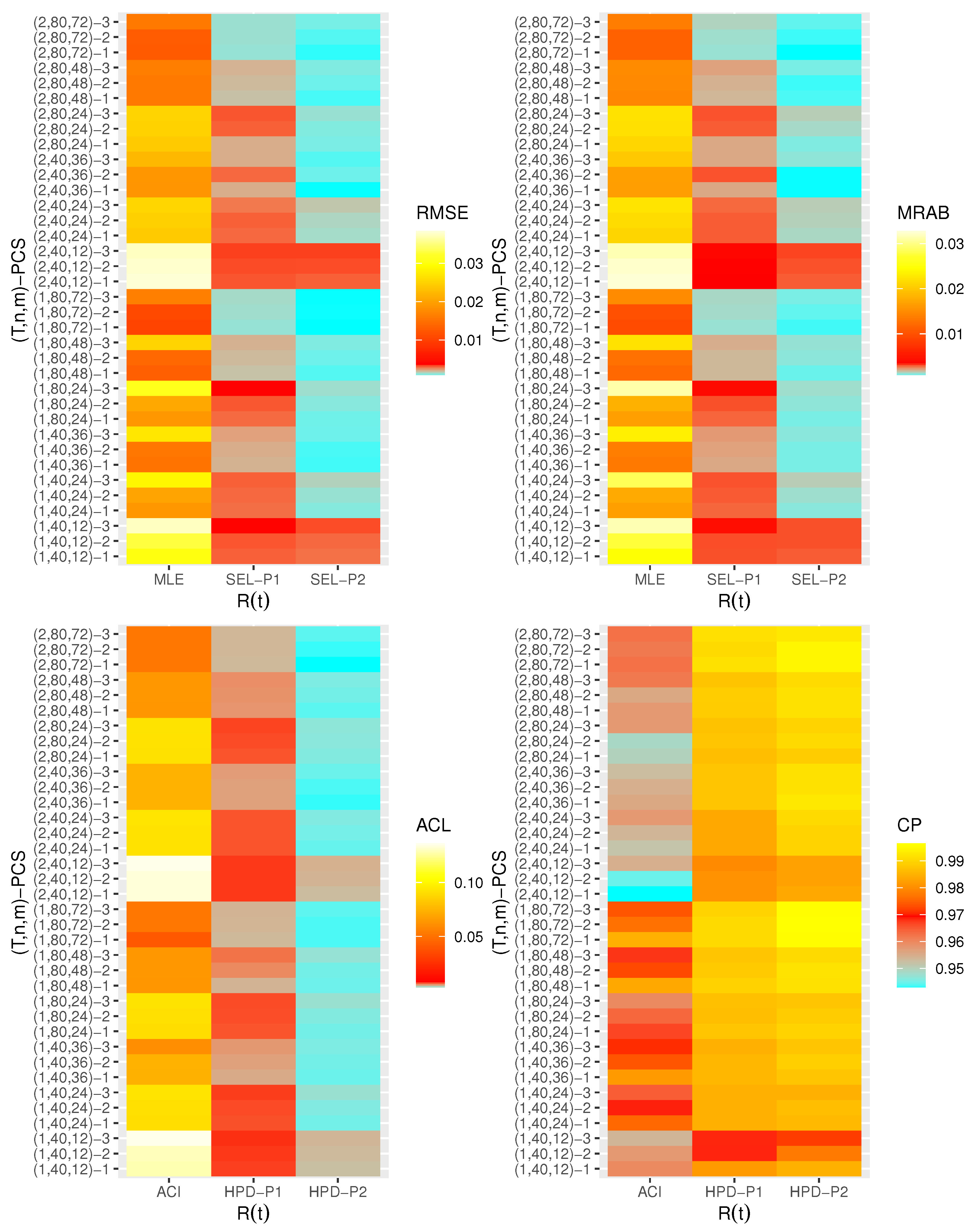
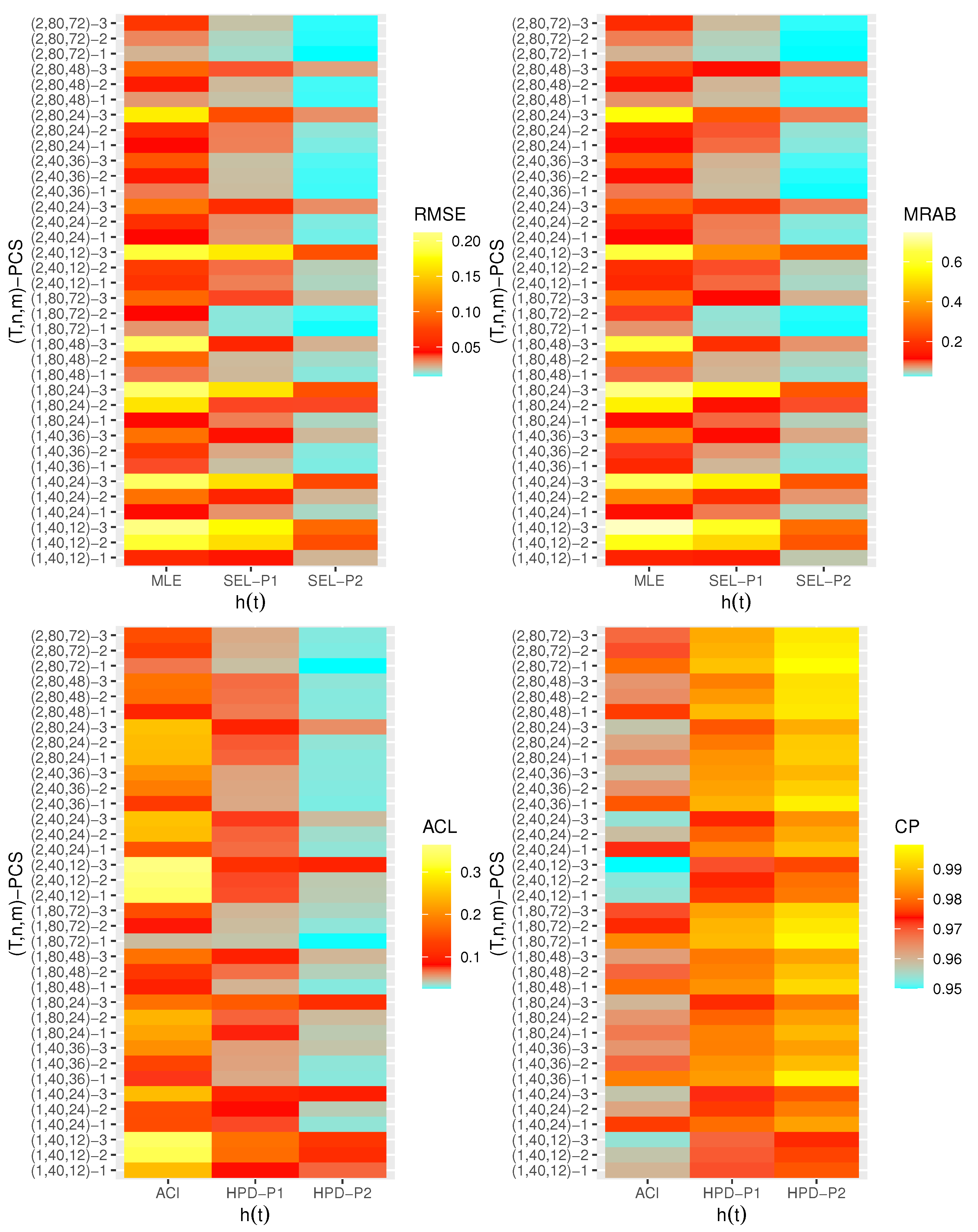
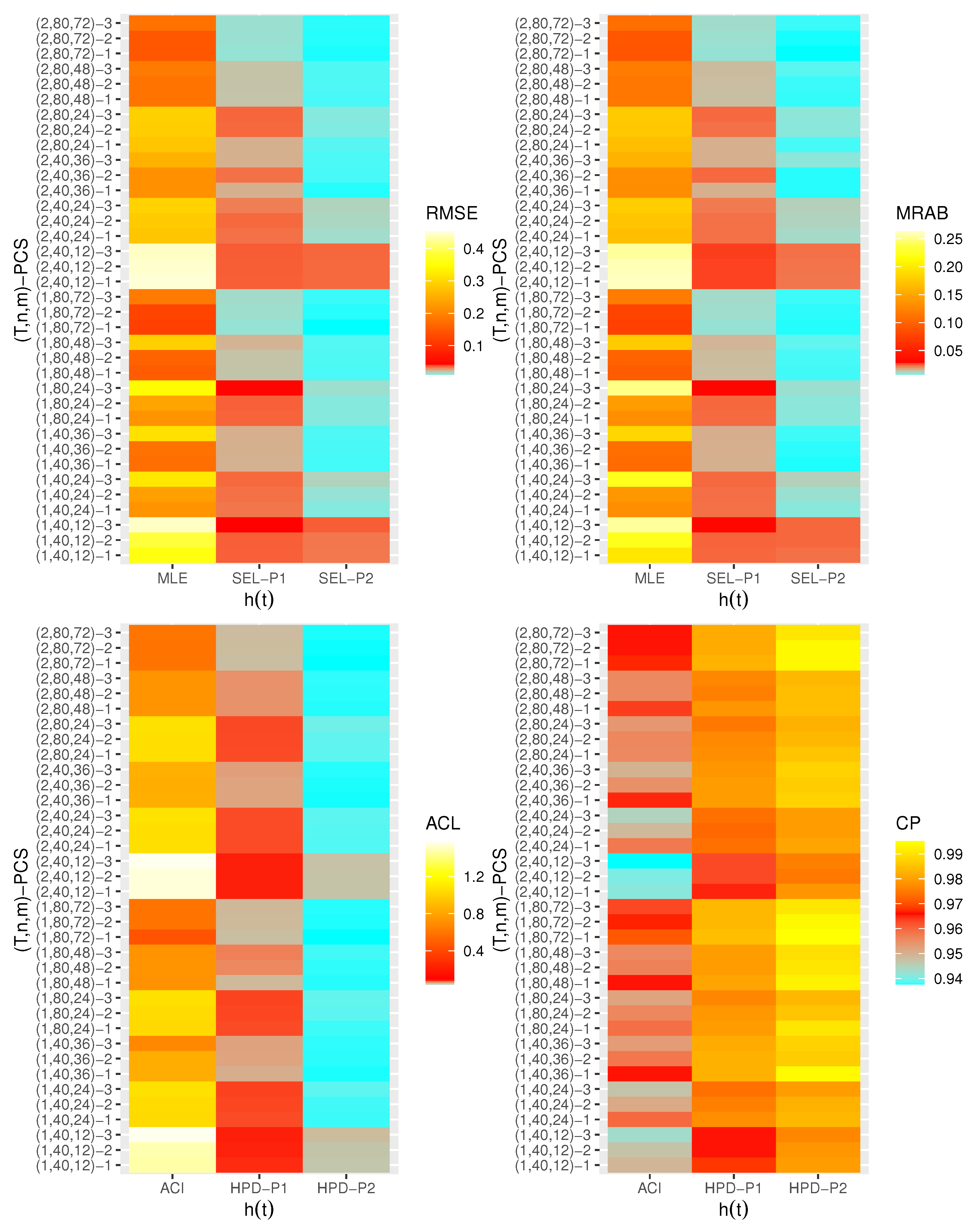
are displayed with heatmap plots in
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7, respectively, while all numerical results are provided in the
Supplementary File. In each heatmap plot, ‘
’ displays the proposed estimation methods, while ‘
’ represents the different choices of
-PCS. For designation, based on P1, for example, we have used the notation “SEL-P1” for the Bayes estimates from the SEL function and “HPD-P1” denotes to HPD credible intervals, respectively. In each heatmap, the colors vary from blue to yellow through red color. For example, in the case of the RMSE of
in
Figure 2, when the color tends to be blue, it indicates that the RMSE has a small value, while the yellow color refers to a high value of the RMSE. A moderate value for the RMSE is presented in red color. From
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7, the following conclusions can be drawn:
Generally, the proposed estimates of the unknown parameters , , and behave well in terms of lowest RMSE, MRAB, and ACL values, as well as the highest CP values;
As n(or m) increases, all estimates of , , and perform better. A similar result is found in the case of the total number of removal patterns, as , decreases;
Comparing PCSs 1, 2 and 3, we can observe that the RMSEs, MRABs, ACLs, and CPs of all unknown parameters are critically good based on PCS-1 (when the live items are removed at the first stage) compared to others. Since the expected duration of the life test experiment based on the first stage is greater than any other, the data collected under PCS-1 provided more information about the unknown parameters , , and than those obtained based on any others;
Comparing the gamma priors P1 and P2 on the Bayesian analysis, since the variance of P2 is less than the variance of P1, it can be seen that the Bayesian point/interval estimators of all unknown parameters from P2 perform more satisfactorily than those obtained from P1 in terms of the lowest RMSE, MRAB, and ACL values and largest CP values;
As T increases, the RMSEs and MRABs of all estimates of all unknown parameters for decrease, while there is an increase for ;
As T increases, the ACLs of all ACIs of all unknown parameters increase for both and , whereas the associated CPs decrease.
As T increases, the ACLs of all HPD credible interval estimates of all unknown parameters decrease for and increase for . The opposite behavior is also observed in case of the CPs for all HPD credible interval estimates of , , and ;
As increases, the RMSEs and MRABs of the MLEs of , , and increase, while those based on the MCMC of decrease and increase for and in most cases;
As increases, the associated ACLs of the ACIs of , , and become wider, while those based on the HPD credible interval estimates of decrease and increase for and in most cases. Additionally, as increases, the opposite behavior is noted in the case of CPs for ACI/HPD credible interval estimates of , , and ;
To sum up, the Bayesian paradigm utilizing the M–H algorithm is advised to estimate the scale parameter and the reliability indices RF and HRF of the XL distribution in the presence of the adaptive Type-II progressively hybrid censored scheme.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
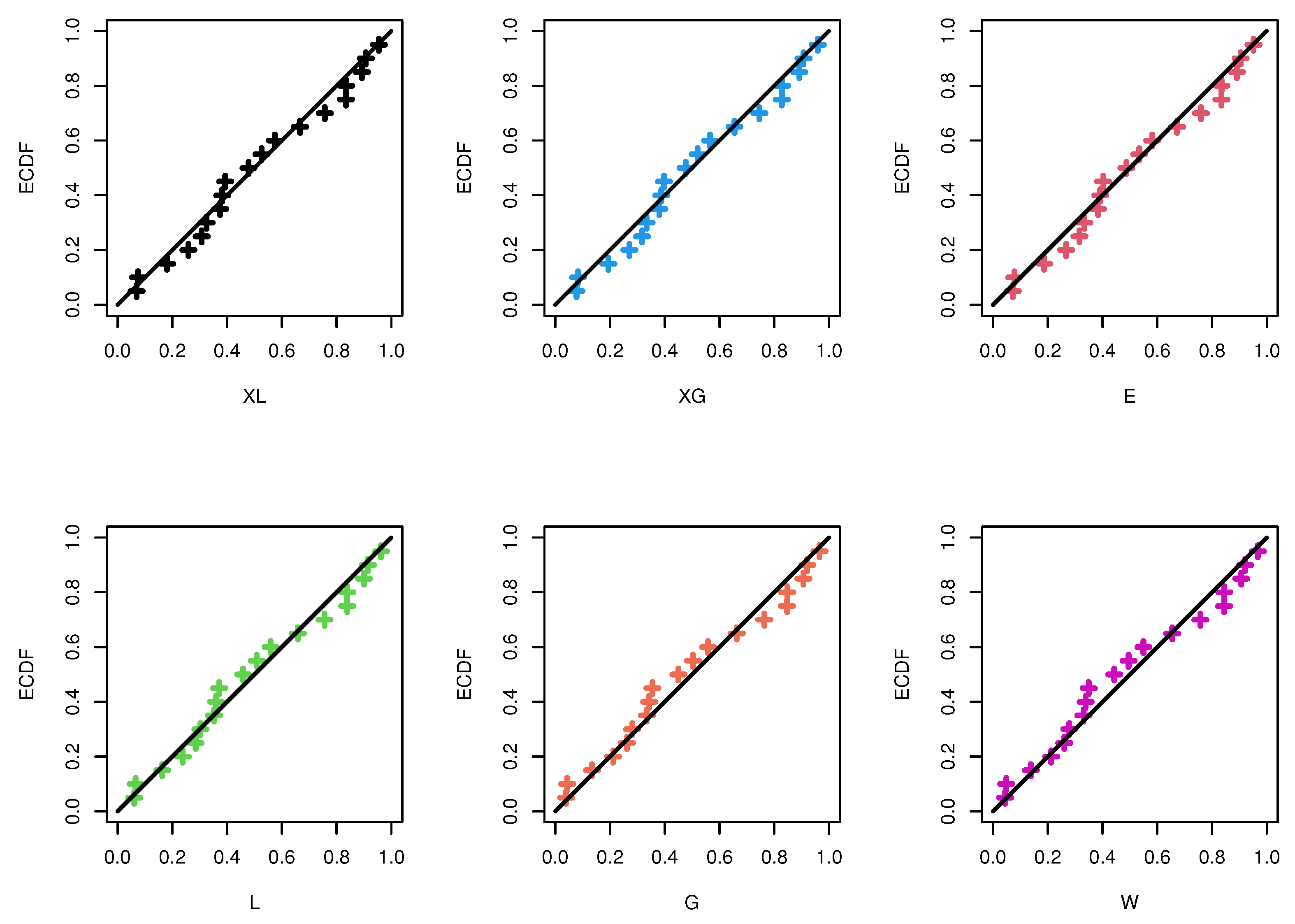{kind=link}
{kind=link}
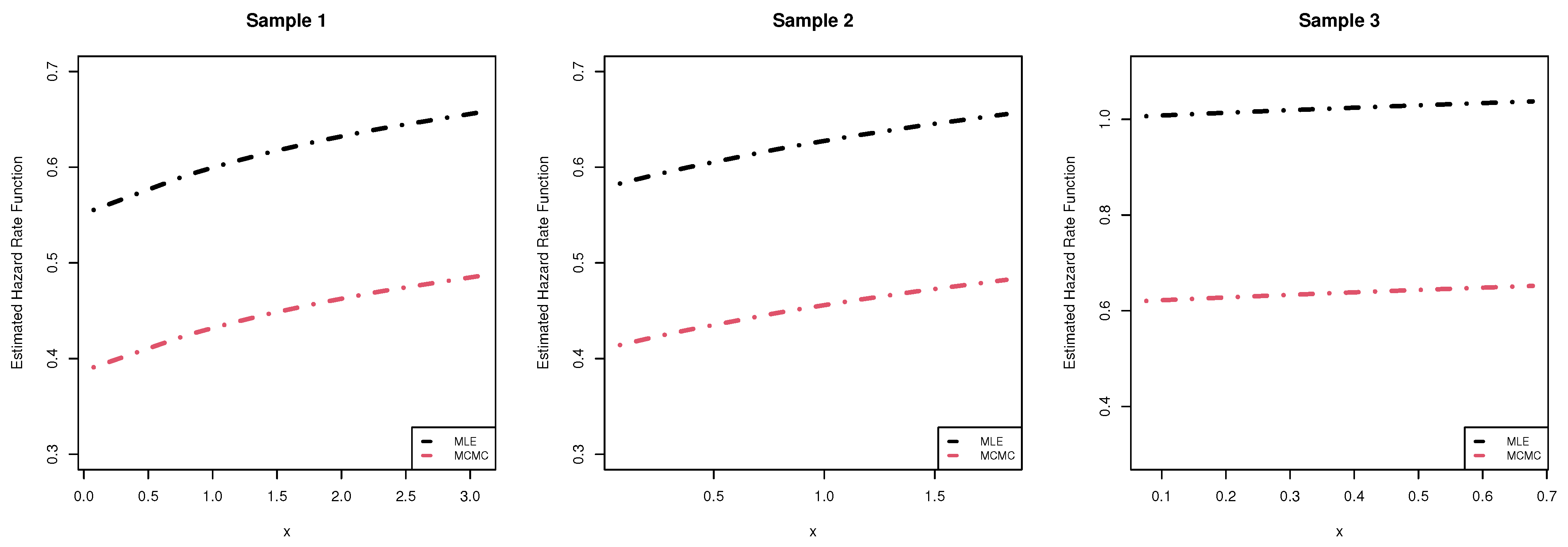{kind=link}
{kind=link}
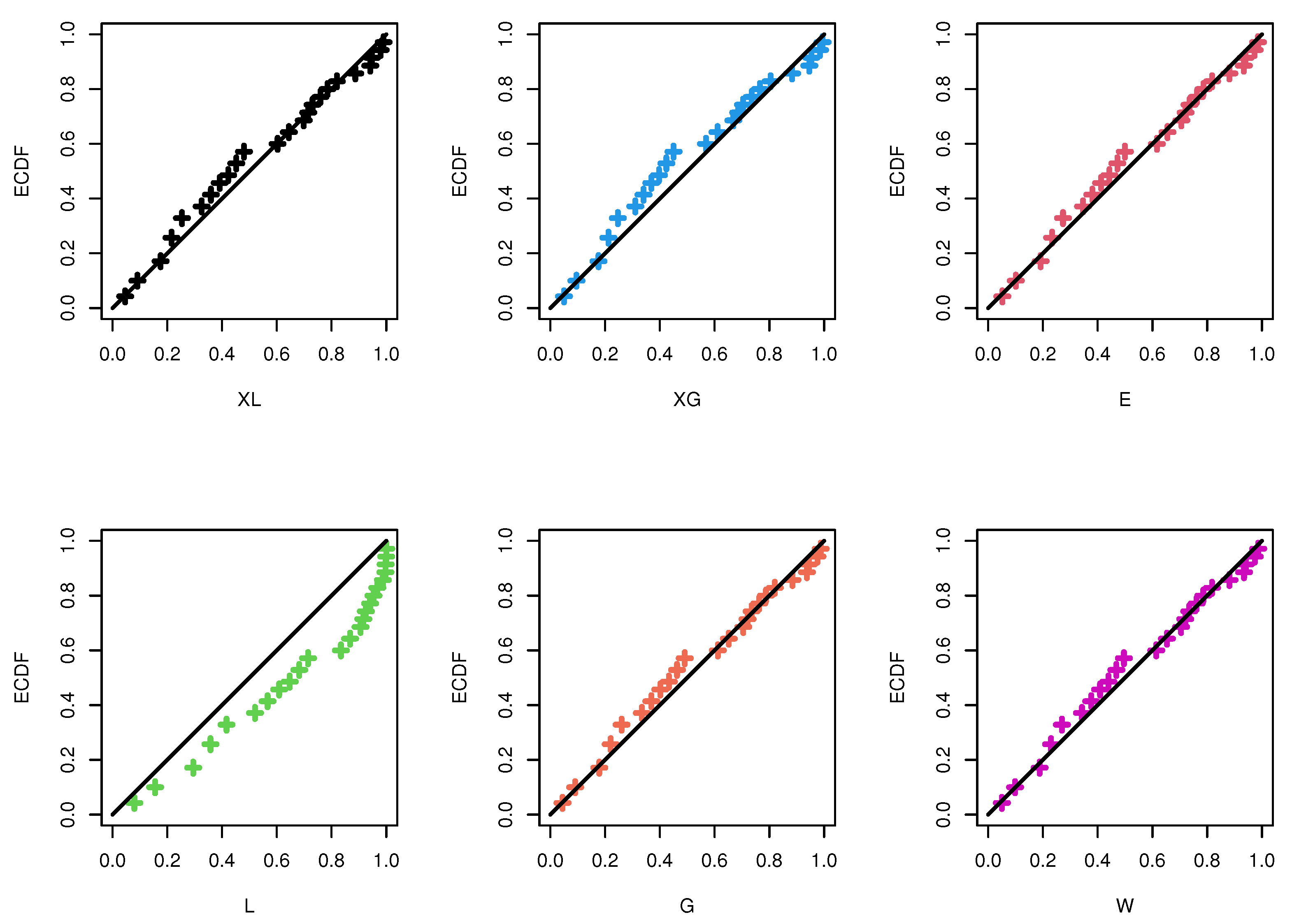{kind=link}
{kind=link}
{kind=link}