
A Numerical Algorithm for Self-Learning Model Predictive Control in Servo Systems
Abstract
:1. Introduction
- A self-learning model is established for estimating the system parameters in an uncertain system with drifting parameters, improving the robustness of the control system.
- The continuous tracking and learning of uncertain parameters can more accurately reflect the structure of the MPC system under uncertainty and reduce the influence of parameter changes.
- Compared with the traditional adaptive MPC algorithm, the control laws in the proposed MPC method with parameter self-learning ability is closer to the optimal control rate based on known parameters.
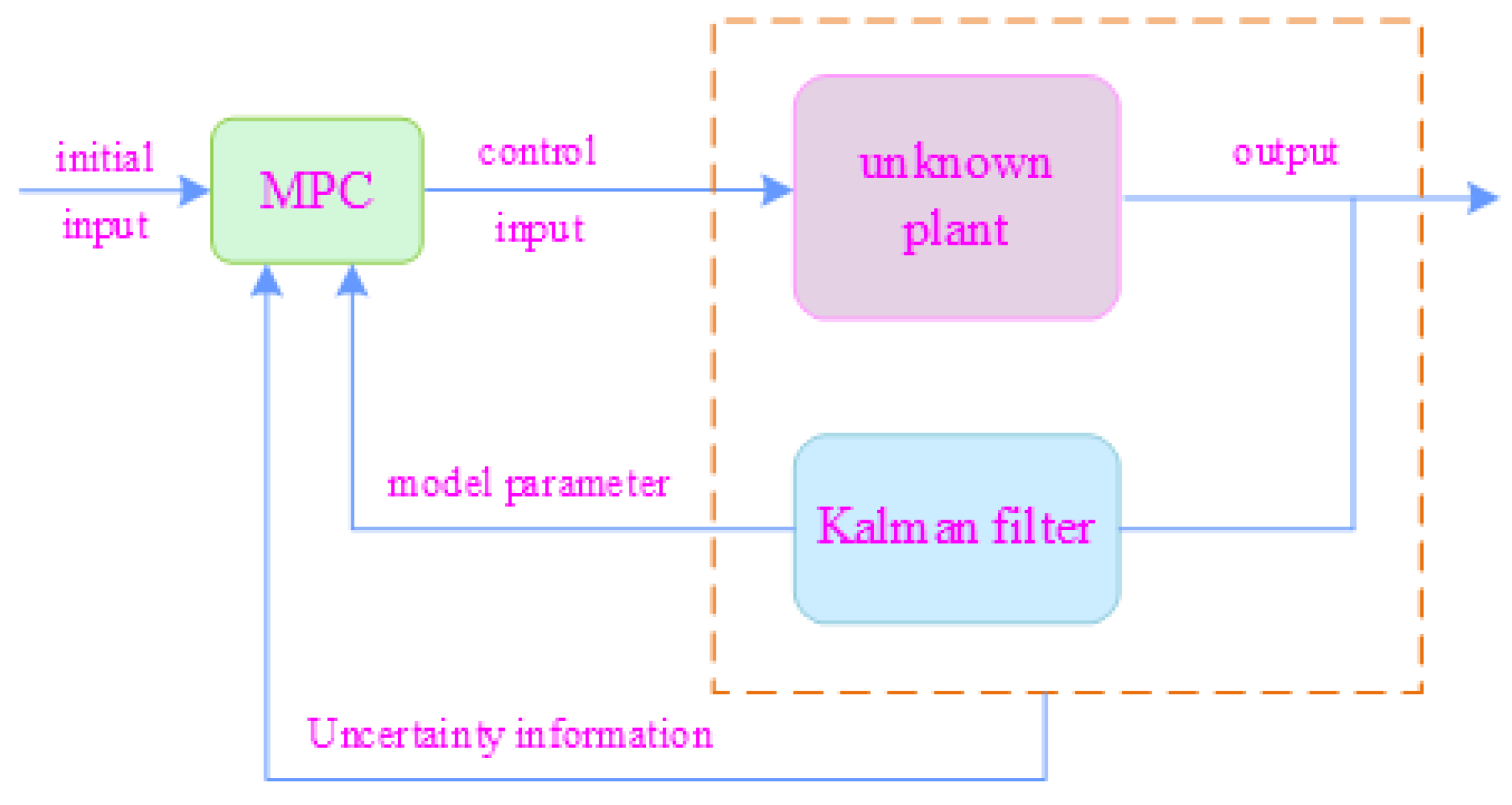
2. Problem Description
3. MPC Control Strategy with Learning Characteristics
3.1. Parameter Estimation and Uncertainty
3.2. MPC Optimization Problem
4. Simulation Test and Result Analysis
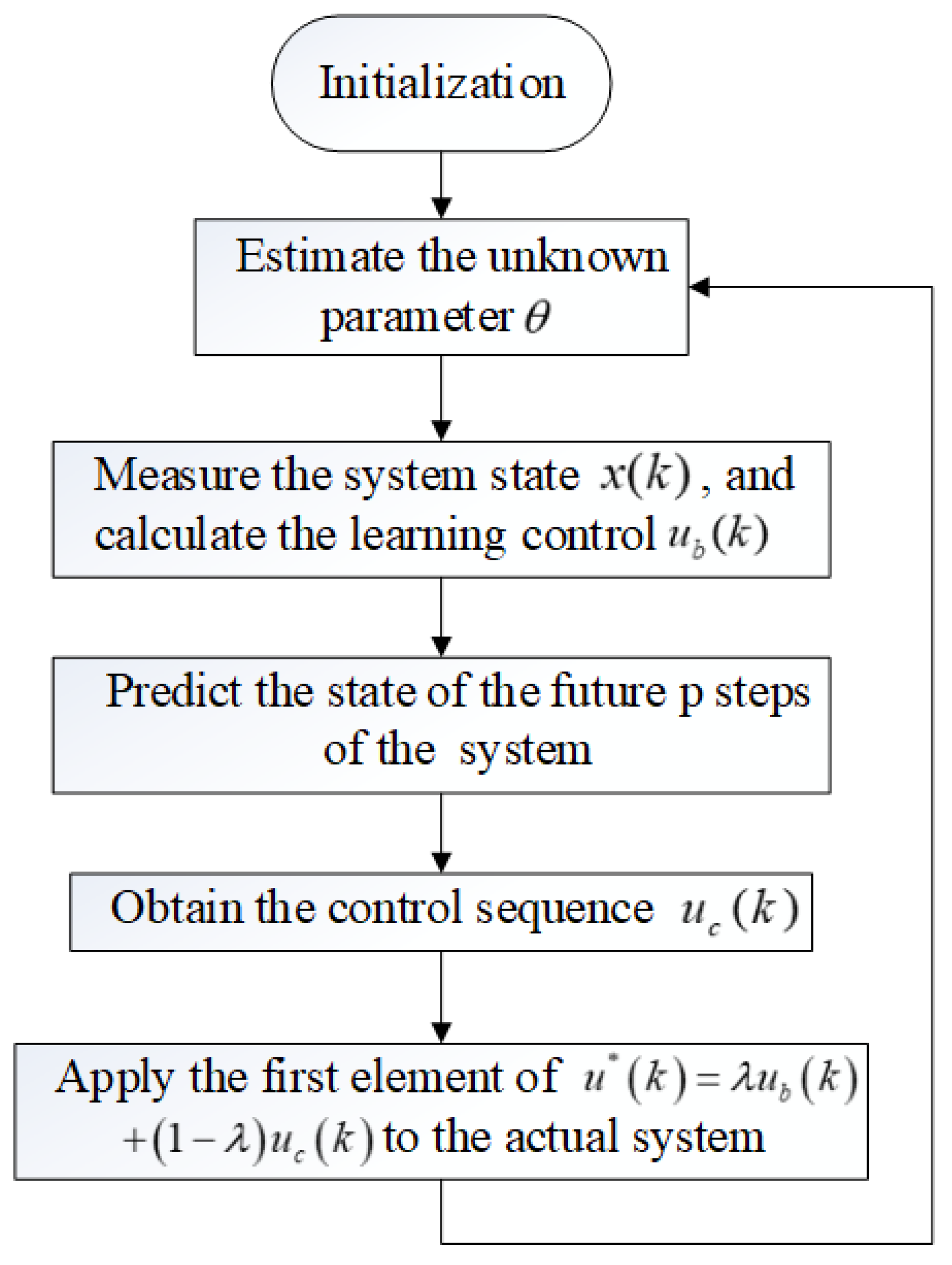
4.1. Numerical Algorithm Steps
- Initialize at time given the predictive horizon (p) and the stopping time N;
- Use the Kalman filter (i.e., (9)–(12)) to estimate the unknown parameter ;
- Measure the system state , and use (23) to calculate the learning control ;
- The estimated state obtained via (20) predicts the state of the future p steps of the system;
- Solve the QP problem using (32) and obtain the control sequence ;
- Apply the first element of to the actual system;
- Set and go to Step 1.
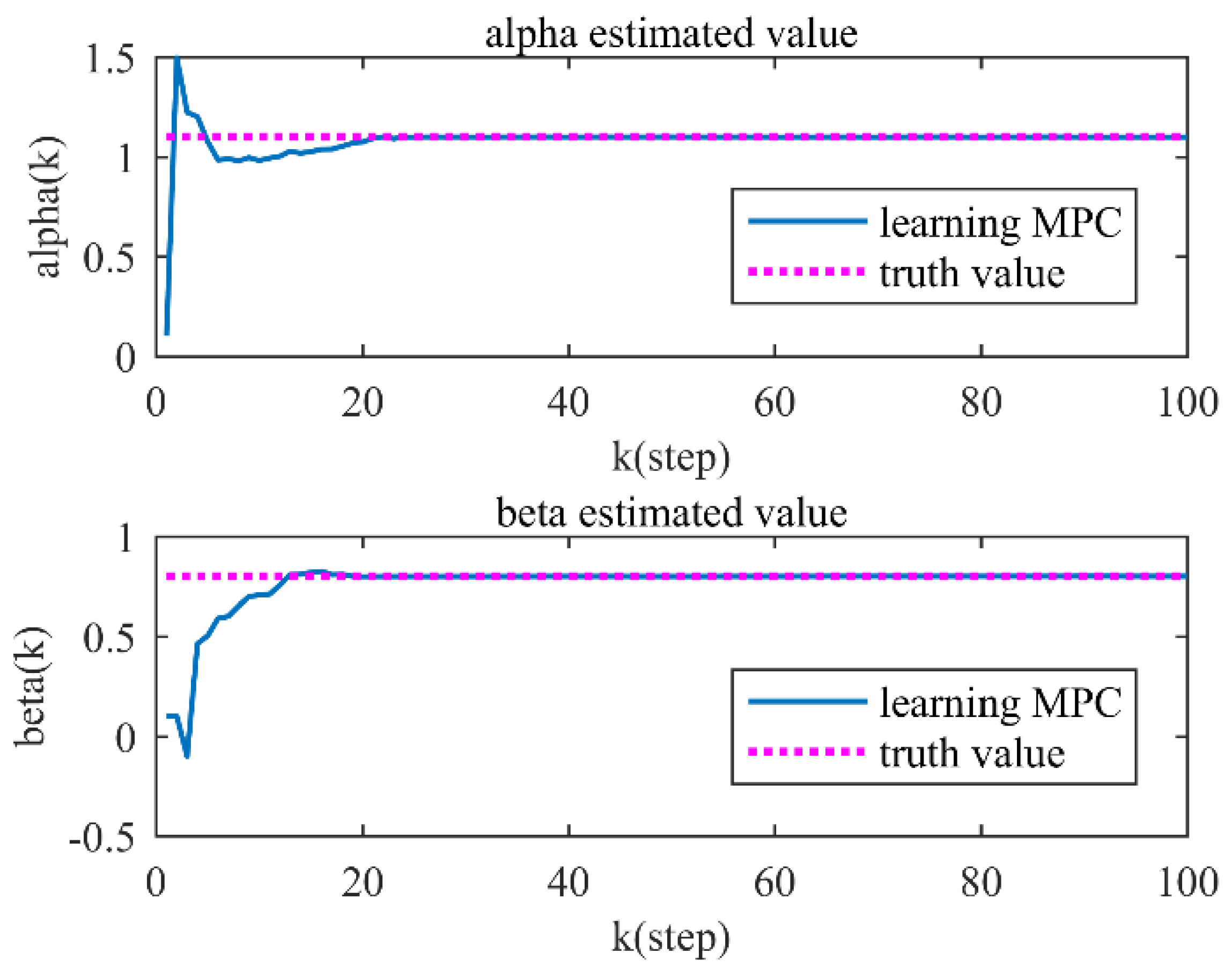
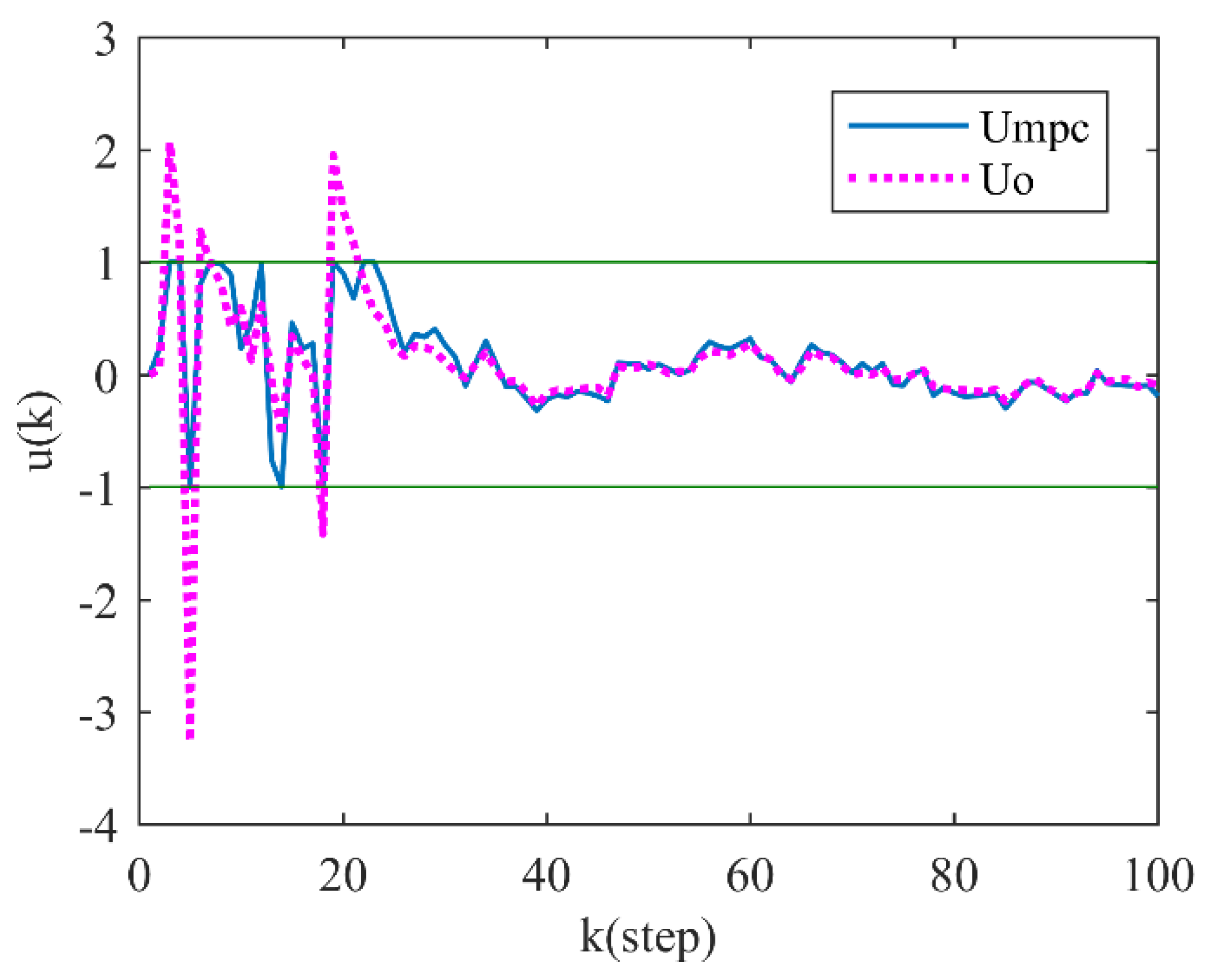
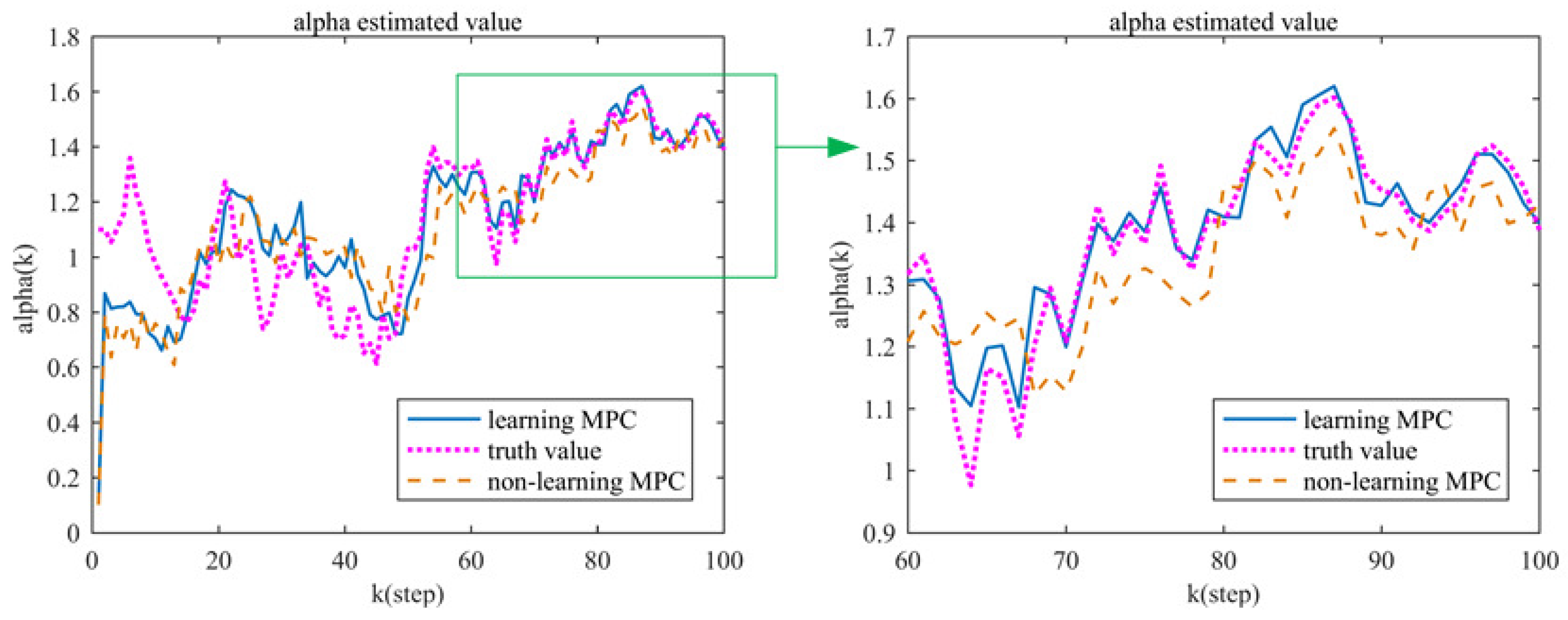
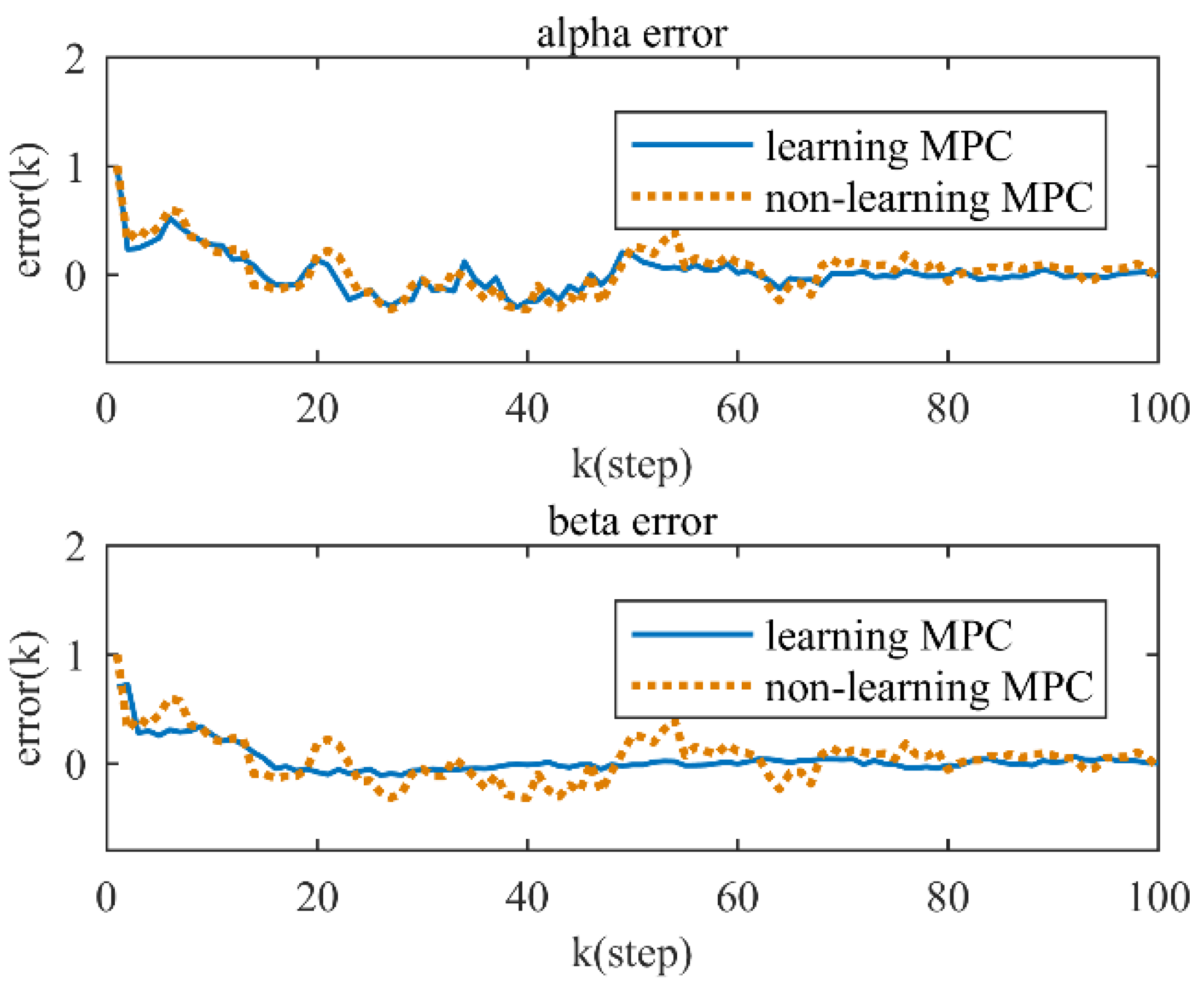
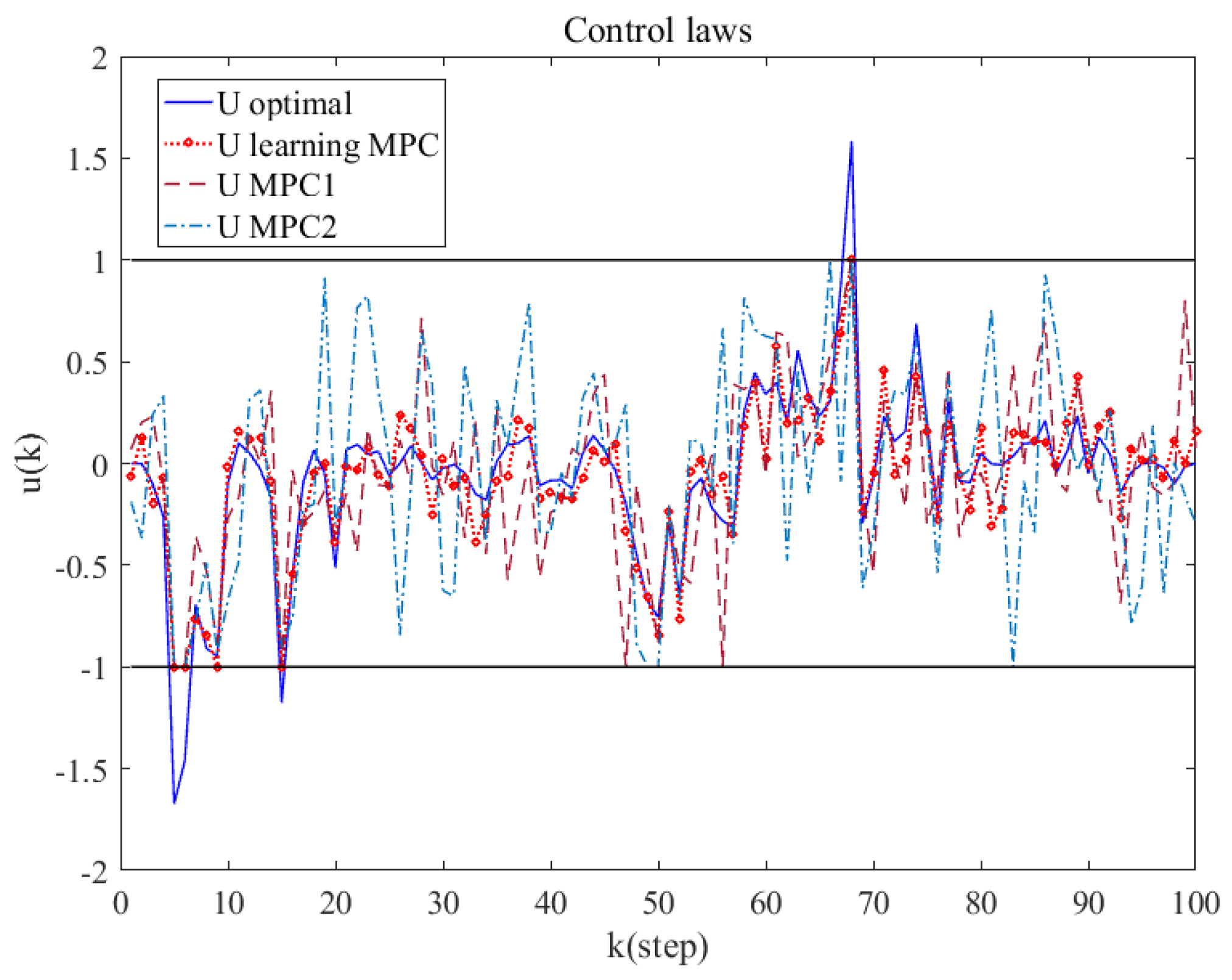
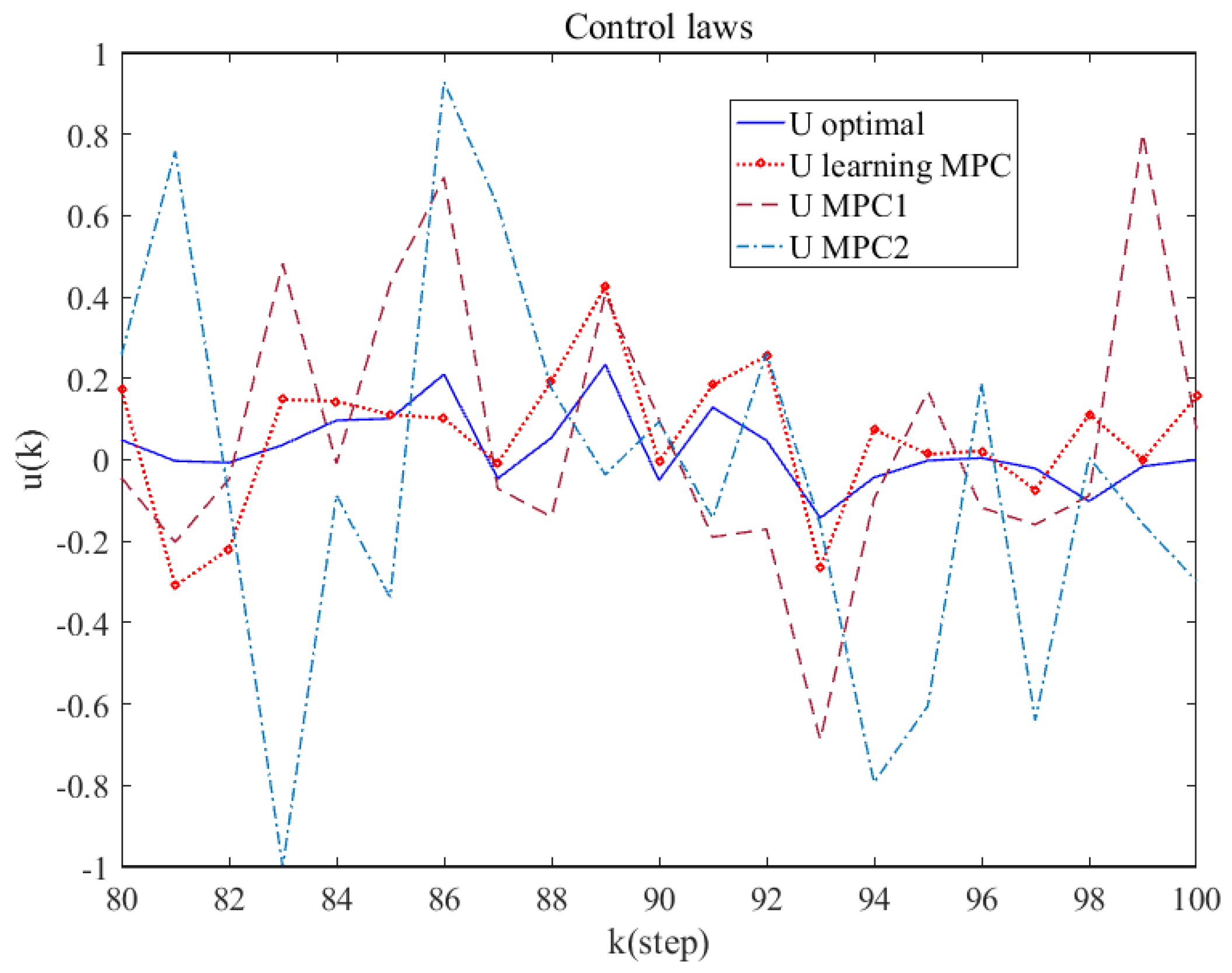
4.2. Simulation and Result Analysis
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kikuchi, T.; Matsumoto, Y.; Chiba, A. Fast initial speed estimation for induction motors in the low-speed range. IEEE Trans. Ind. Inform. 2018, 54, 3415–3425. [Google Scholar] [CrossRef]
- Xi, Y.; Li, D.; Lin, S. Model predictive control—Status and challenges. Acta Autom. Sin. 2013, 39, 222–236. [Google Scholar] [CrossRef]
- Banholzer, S.; Fabrini, G.; Grüne, L.; Volkwein, S. Multiobjective Model Predictive Control of a Parabolic Advection-Diffusion-Reaction Equation. Mathematics 2019, 29, 4987–5001. [Google Scholar] [CrossRef]
- Lorenzen, M.; Müller, M.A.; Allgöwer, F. Stochastic model predictive control without terminal constraints. Int. J. Robust Nonlinear Control 2019, 29, 4987–5001. [Google Scholar] [CrossRef]
- Heirung, T.A.N.; Paulson, J.A.; Lee, S.J.; Mesbah, A. Model predictive control with active learning under model uncertainty: Why, when, and how. AIChE J. 2018, 64, 3071–3081. [Google Scholar] [CrossRef]
- Mesbah, A. Stochastic model predictive control: An overview and perspectives for future research. IEEE Control Syst. 2016, 36, 30–44. [Google Scholar]
- Campo, P.J.; Morari, M. Robust model predictive control. In Proceedings of the 1987 American Control Conference, Minneapolis, MN, USA, 10–12 June 1987; pp. 1021–1026. [Google Scholar]
- Xie, L.; Xie, L.; Su, H. A comparative study on algorithms of robust and stochastic MPC for uncertain systems. Acta Autom. Sin. 2017, 43, 969–992. [Google Scholar]
- Zhang, K.; Yang, S. Adaptive model predictive control for a class of constrained linear systems with parametric uncertainties. Automatica 2020, 117, 108974. [Google Scholar] [CrossRef]
- Zhang, S.; Dai, L.; Xia, Y. Adaptive MPC for constrained systems with parameter uncertainty and additive disturbance. IET Control Theory Appl. 2019, 13, 2500–2506. [Google Scholar] [CrossRef]
- Ding, B.; Pan, H. Output feedback robust MPC for LPV system with polytopic model parametric uncertainty and bounded disturbance. Int. J. Control 2016, 89, 1554–1571. [Google Scholar] [CrossRef]
- Pipino, H.A.; Adam, E.J. MPC for linear systems with parametric uncertainty. In Proceedings of the 2019 XVIII Workshop on Information Processing and Control, Salvador, Brazil, 18–20 September 2019; pp. 42–47. [Google Scholar]
- Dhar, A.; Bhasin, S. Indirect adaptive mpc for discrete-time lti systems with parametric uncertainties. IEEE Trans. Automat. Contr. 2021, 66, 5498–5505. [Google Scholar] [CrossRef]
- Liu, J.; Jayakumar, P.; Stein, J.L.; Ersal, T. Improving the robustness of an MPC-based obstacle avoidance algorithm to parametric uncertainty using worst-case scenarios. Veh. Syst. Dyn. 2019, 57, 874–913. [Google Scholar] [CrossRef]
- Adetola, V.; DeHaan, D.; Guay, M. Adaptive model predictive control for constrained nonlinear systems. Syst. Control Lett. 2009, 58, 320–326. [Google Scholar] [CrossRef]
- Gonçalves, G.A.A.; Guay, M. Robust discrete-time set-based adaptive predictive control for nonlinear systems. J. Process Control 2016, 39, 111–122. [Google Scholar] [CrossRef]
- Mesbah, A. Stochastic model predictive control with active uncertainty learning: A Survey on dual control. Annu. Rev. Control 2018, 45, 107–117. [Google Scholar] [CrossRef]
- Shang, T.; Qian, F.; Zhang, X.; Xie, G. Research on dual control algorithm for LQG with unknown parameters. Acta Autom. Sin. 2017, 43, 1478–1484. [Google Scholar]
- Yang, H.; Gao, S.; Qian, F. A suboptimal Dual Control Method for the Stochastic Systems with Parameters Drifting. Asian J. Control 2019, 21, 609–616. [Google Scholar] [CrossRef]
- Heirung, T.A.N.; Ydsite, B.E.; Foss, B. Dual adaptive model predictive control. Automatica 2017, 80, 340–348. [Google Scholar] [CrossRef]
- Houska, B.; Tenlen, D.; Logist, F.; Impe, J.V. Self-reflective model predictive control. SIAM J. Control Optim. 2016, 55, 2959–2980. [Google Scholar] [CrossRef]
- Feng, X.; Houska, B. Real-time algorithm for self-reflective model predictive control. J. Process Control 2018, 65, 68–77. [Google Scholar] [CrossRef]
- Zeng, J.; Liu, J. Distributed State Estimation Based Distributed Model Predictive Control. Mathematics 2021, 9, 1327. [Google Scholar] [CrossRef]
- Cao, W.; Li, S. Enhanced parameterizable uncertainty to dual adaptive model predictive control. Control Theory Appl. 2019, 36, 1197–1206. [Google Scholar]
- Chen, H. Model Predictive Control; Science Press: Beijing, China, 2013; pp. 161–165. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Control Model | Calculation Time |
|---|---|
| Optimal control law | 1 |
| Learning MPC | 1.65 |
| MPC1 | 1.41 |
| MPC2 | 1.73 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Xi, D.; Weng, X.; Qian, F.; Tan, B. A Numerical Algorithm for Self-Learning Model Predictive Control in Servo Systems. Mathematics 2022, 10, 3152. https://doi.org/10.3390/math10173152
Yang H, Xi D, Weng X, Qian F, Tan B. A Numerical Algorithm for Self-Learning Model Predictive Control in Servo Systems. Mathematics. 2022; 10(17):3152. https://doi.org/10.3390/math10173152
Chicago/Turabian StyleYang, Hengzhan, Dian Xi, Xu Weng, Fucai Qian, and Bo Tan. 2022. "A Numerical Algorithm for Self-Learning Model Predictive Control in Servo Systems" Mathematics 10, no. 17: 3152. https://doi.org/10.3390/math10173152