
Coherent Forecasting for a Mixed Integer-Valued Time Series Model


Abstract
:1. Introduction
2. Background on Integer-Valued Time Series Models
2.1. First-Order Integer-Valued Autoregressive Model
2.2. Pegram’s First-Order Autoregressive Process (AR(1))
2.3. First-Order Mixture of Pegram and Thinning Autoregressive (MPT(1)) Process
3. Likelihood-Based Estimation
3.1. Expectation-Maximization Algorithm
3.2. Asymptotic Distribution
4. Coherent Forecasting
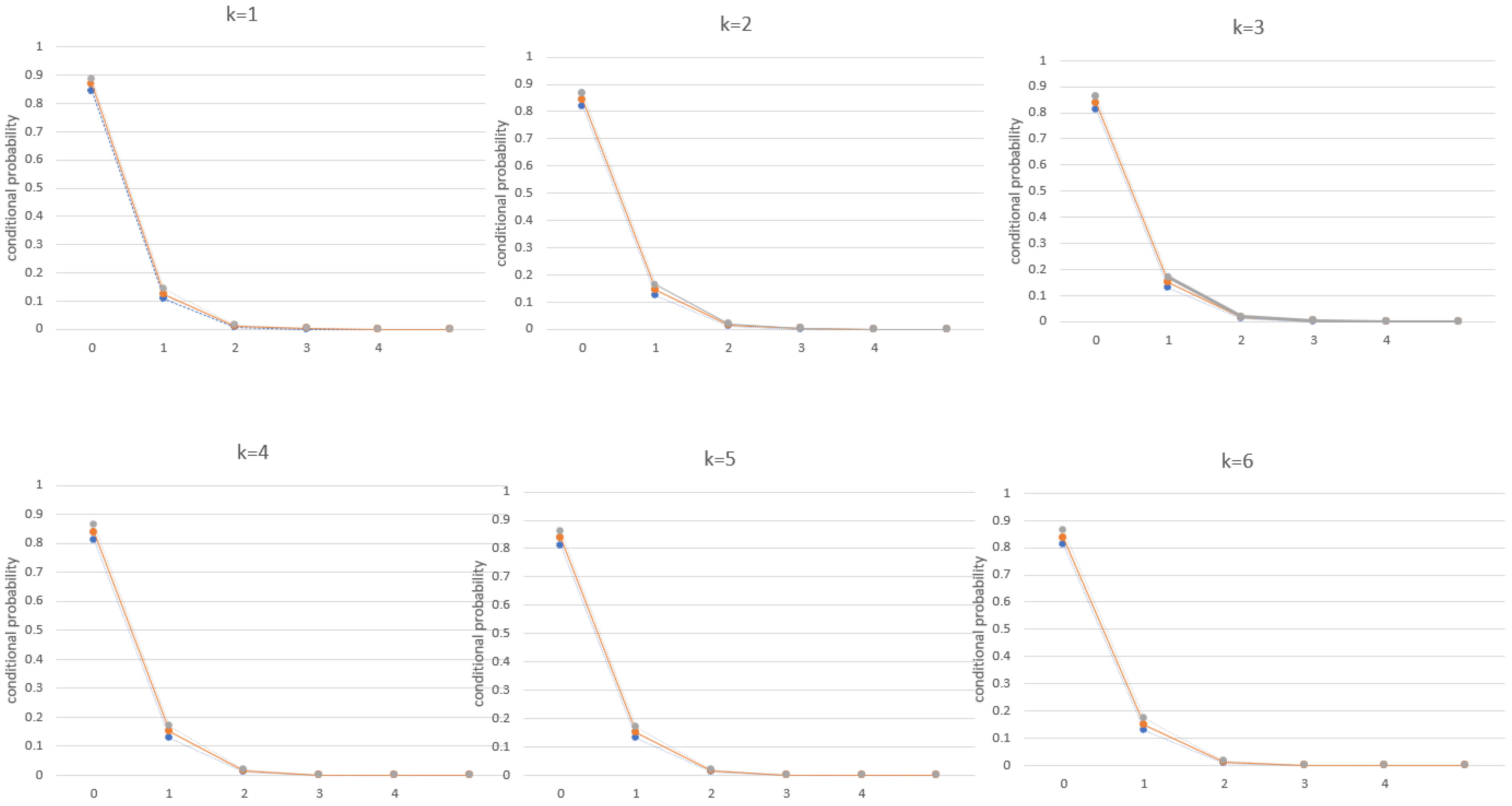
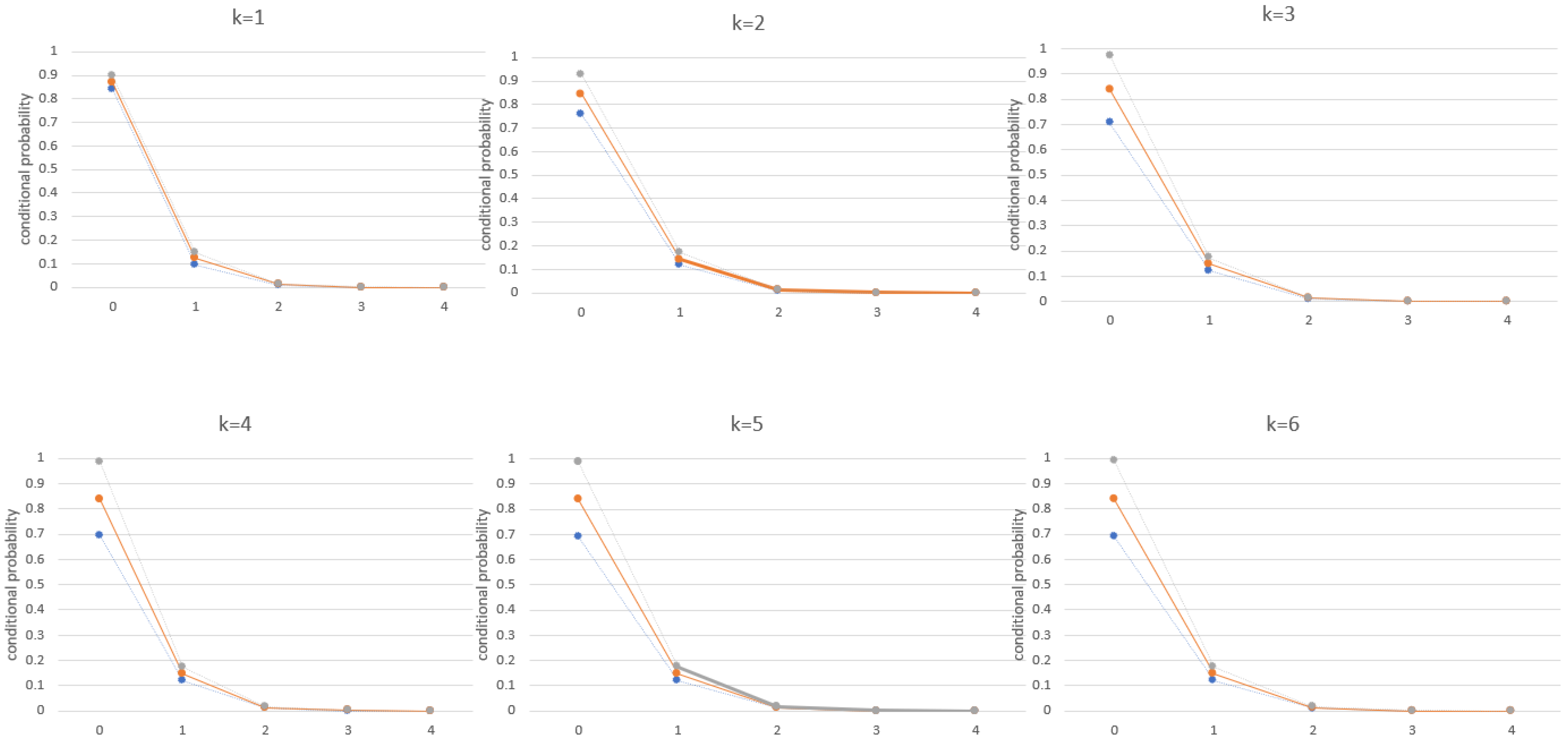
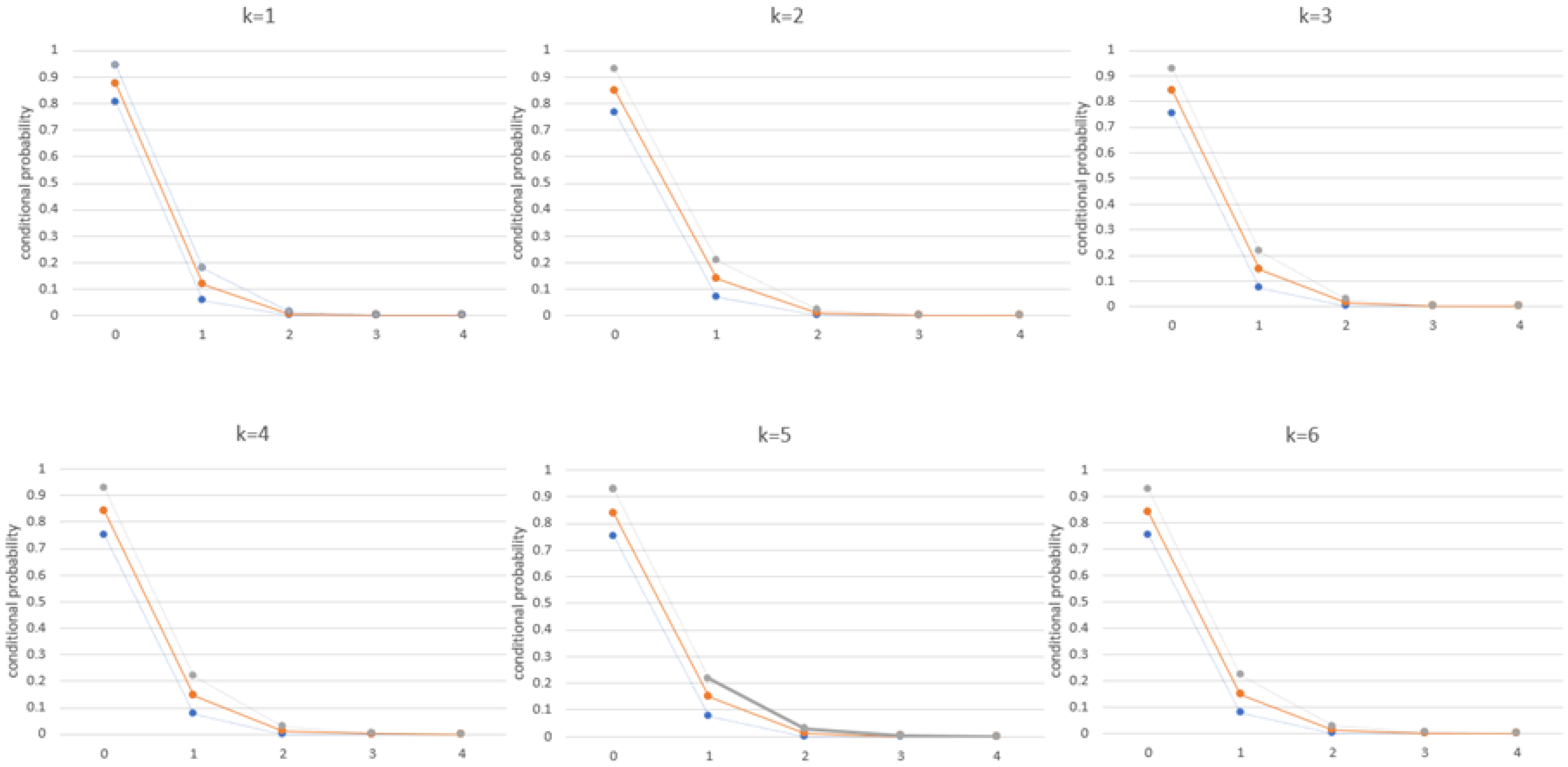
4.1. Descriptive Measures
- A.
- Prediction root-mean-squared error (PRMSE):
- B.
- Prediction mean absolute deviation (PMAD):
- C.
- Percentage of true prediction (PTP):
4.2. Confidence Interval
5. Simulation Study
6. Real Applications
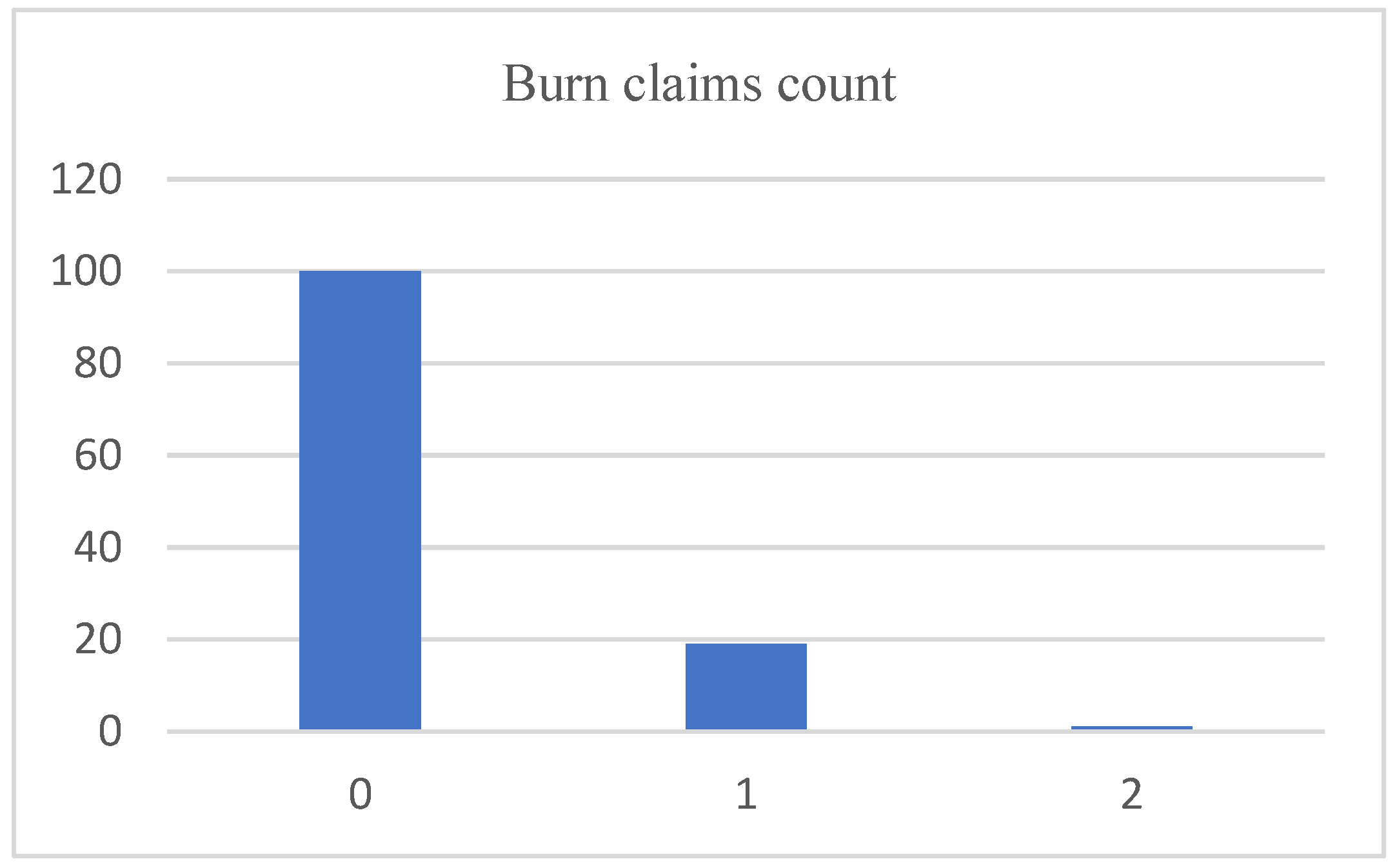
6.1. Burn Claims Data
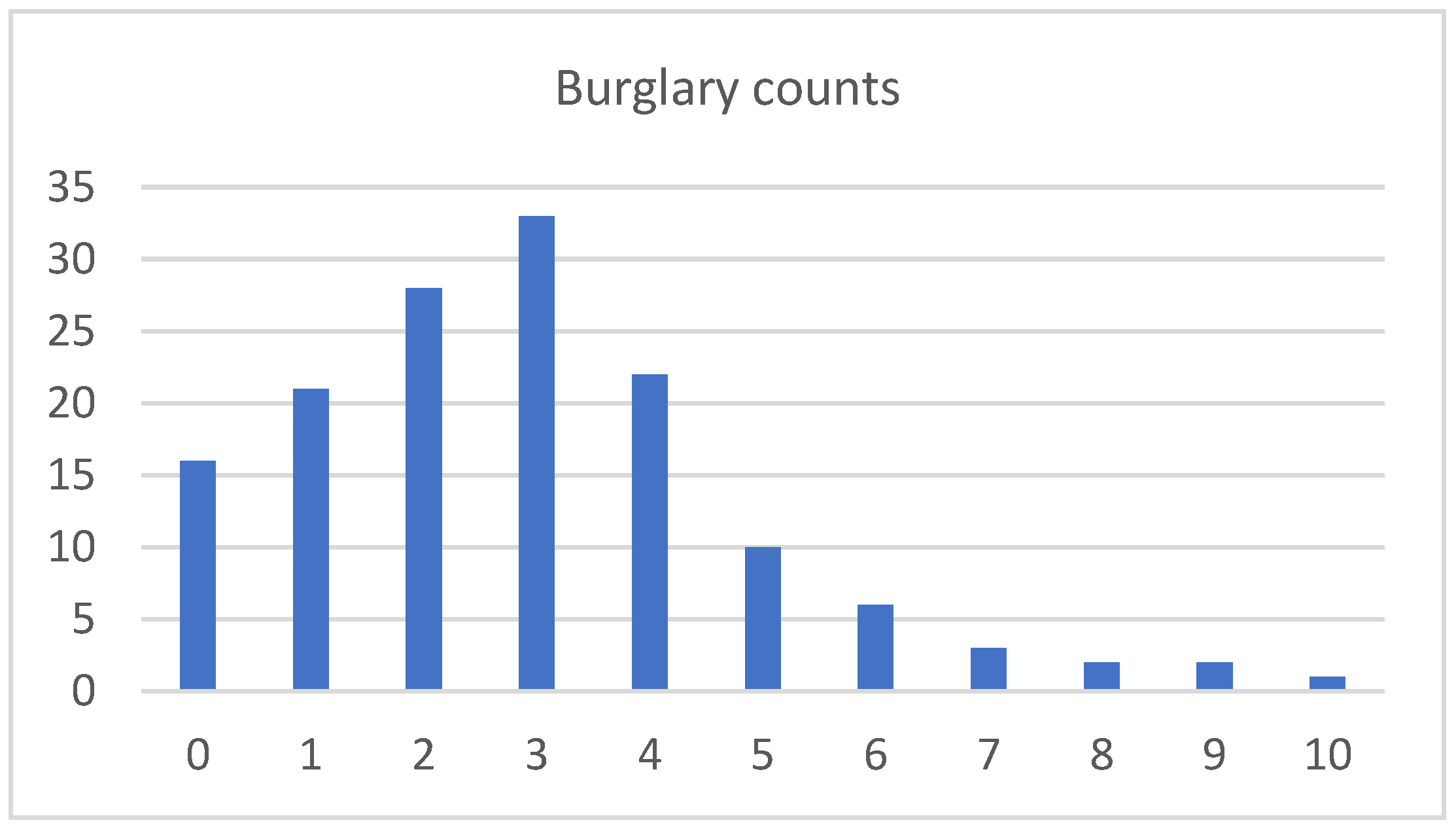
6.2. Burglary Data
7. Final Remarks
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Khoo, W.C.; Ong, S.H.; Biswas, A. Modeling time series of counts with a new class of INAR(1) model. Stat. Pap. 2017, 58, 393–416. [Google Scholar] [CrossRef]
- Shirozhan, M.; Mohammadpour, M. An INAR(1) model based on the Pegram and thinning operators with serially dependent innovation. Commun. Stat. Simul. Comput. 2020, 49, 2617–2638. [Google Scholar] [CrossRef]
- Kang, Y.; Wang, D.; Yang, K. A new INAR(1) process with bounded support for counts showing equidispersion, underdispersion and overdispersion. Stat. Pap. 2021, 62, 745–767. [Google Scholar] [CrossRef]
- Yan, H.; Wang, D.H.; Li, C. A study for the NMBAR(1) processes. Commun. Stat. Simul. Comput. 2022, 1–22. [Google Scholar] [CrossRef]
- McKenzie, E. Some simple models for discrete variate time series. Water Resour. Bull. 1985, 21, 645–650. [Google Scholar] [CrossRef]
- Freeland, R.K. Statistical Analysis of Discrete Time Series with Application to the Analysis of Workers’ Compensation Claims Data. Ph.D. Thesis, The University of British Columbia, Vancouver, BC, Canada, 1998. [Google Scholar]
- Freeland, R.K.; McCabe, B.P.M. Forecasting discrete valued low count time series. Int. J. Forecast. 2004, 20, 427–434. [Google Scholar] [CrossRef]
- Bu, R.B.; McCabe, B.; Hadri, K. Maximum likelihood estimation of higher-order integer-valued autoregressive process. J. Time Ser. Anal. 2009, 29, 973–994. [Google Scholar] [CrossRef]
- McCabe, B.P.M.; Martin, G.M. Bayesian predictions of low count time series. Int. J. Forecast. 2005, 21, 315–330. [Google Scholar] [CrossRef]
- Jung, R.C.; Tremayne, A.R. Coherent forecasting in integer time series models. Int. J. Forecast. 2006, 22, 223–238. [Google Scholar] [CrossRef]
- Kim, H.Y.; Park, Y. Markov chain approach to forecast in the binomial autoregressive models. Commun. Korean Stat. Soc. 2010, 17, 441–450. [Google Scholar] [CrossRef]
- Maiti, R.; Biswas, A.; Das, S. Coherent forecasting for count time series using Box-Jenkins’s AR(p) model. Stat. Neerl. 2016, 70, 123–145. [Google Scholar] [CrossRef]
- Maiti, R.; Biswas, A.; Das, S. Time series of zero-inflated counts and their coherent forecasting. J. Forecast. 2015, 34, 694–707. [Google Scholar] [CrossRef]
- Awale, M.; Ramanathan, T.V.; Kale, M. Coherent forecasting in integer-valued AR(1) models with geometric marginals. J. Data Sci. 2017, 15, 95–114. [Google Scholar] [CrossRef]
- Nik, S.; Weiss, C. CLAR(1) point forecasting under estimation uncertainty. Stat. Neerl. 2020, 74, 489–526. [Google Scholar] [CrossRef]
- Weiss, C. Thinning operations for modelling time series of counts—A survey. AStA Adv. Stat. Anal. 2008, 92, 319. [Google Scholar] [CrossRef]
- Pegram, G.G.S. An autoregressive model for multilag Markov chain. J. Appl. Probab. 1980, 17, 350–362. [Google Scholar] [CrossRef]
- Biswas, A.; Song, X.-K. Peter. Discrete-valued ARMA processes. Stat. Probab. Lett. 2009, 79, 1884–1889. [Google Scholar] [CrossRef]
- Jacobs, P.A.; Lewis, A.W. Discrete Time Series Generated by Mixtures III: Autoregressive Processes (DAR(p)); Naval Postgraduate School: Monterey, CA, USA, 1978. [Google Scholar]
- Grunwald, G.K.; Hyndman, R.J.; Tedesco, L.; Tweedie, R.L. Non-Gaussian conditional linear AR(1) models. Aust. N. Z. J. Stat. 2000, 42, 479–495. [Google Scholar] [CrossRef]
- Dempster, A.; Laird, N.; Rubin, D. Maximum Likelihood from Incomplete Data via the EM Algorithm. J. R. Stat. Soc. B 1977, 39, 1–38. [Google Scholar]
- Karlis, D.; Xekalaki, E. Improving the EM algorithm for mixtures. Stat. Comput. 1999, 9, 303–307. [Google Scholar] [CrossRef]
- Marcellino, M.; Stock, J.H.; Watson, M.W. A comparison of direct and iterated multistep AR methods for forecasting macroeconomic time series. J. Econ. 2006, 135, 499–526. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Parameters | PRMSE | PMAD | PTP (%) |
|---|---|---|---|---|
| Pegram’s AR(1) | (0.5,0.4) | 0.0867 | 1.6135 | 22.3474 |
| (0.3,0.8) | 0.0335 | 0.4000 | 66.7706 | |
| INAR(1) | (0.5,0.4) | 0.9952 | 2.0921 | 14.8930 |
| (0.3,0.8) | 0.0341 | 0.3997 | 65.0158 | |
| MPT(1) | (0.5,0.4) | 0.1482 | 1.4890 | 23.6388 |
| (0.3,0.8) | 0.02446 | 0.4528 | 59.4330 |
| Model | Conditional Mean | Conditional Median | |
|---|---|---|---|
| MPT(1) | PRMSE | 0.5492 | 1.3784 |
| PMAD | 0.3152 | 1.3 | |
| PTP (%) | 50 | 0 | |
| Pegram’s AR(1) | PRMSE | 1.0585 | 1.3784 |
| PMAD | 0.9511 | 1.3 | |
| PTP (%) | 0 | 0 | |
| INAR(1) | PRMSE | 0.9037 | 1.3784 |
| PMAD | 0.7359 | 1.3 | |
| PTP (%) | 0 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khoo, W.C.; Ong, S.H.; Atanu, B. Coherent Forecasting for a Mixed Integer-Valued Time Series Model. Mathematics 2022, 10, 2961. https://doi.org/10.3390/math10162961
Khoo WC, Ong SH, Atanu B. Coherent Forecasting for a Mixed Integer-Valued Time Series Model. Mathematics. 2022; 10(16):2961. https://doi.org/10.3390/math10162961
Chicago/Turabian StyleKhoo, Wooi Chen, Seng Huat Ong, and Biswas Atanu. 2022. "Coherent Forecasting for a Mixed Integer-Valued Time Series Model" Mathematics 10, no. 16: 2961. https://doi.org/10.3390/math10162961