1. Introduction
Aesthetics, in the world of photography, refers to the appreciation of beauty in the form of art. Image aesthetic quality assessment aims to use computers to simulate human perception of aesthetics and automatically evaluate the aesthetics of images. It has found great applications in many areas, such as photo ranking [
1], image recommendation [
2], and image retrieval and editing [
3]. Thus, image aesthetic assessment has attracted increasing attention in recent years [
4,
5,
6,
7,
8,
9].
In the early stages, the research of image aesthetics mainly focuses on designing hand-crafted features according to the photographic rules such as the lightning, color, and global image layout. Such methods first extract hand-crafted features from images and then learn a mapping of these features to subjective aesthetic quality [
4,
5,
6]. Later, with the proposal and development of convolution neural network [
10,
11], deep features have been used to capture the low-level and high-level descriptive aesthetic attributes, which significantly improves the performance of image aesthetic quality evaluation tasks [
7,
8,
9]. However, most of these methods are adapted from classical image classification networks, not specific to image aesthetic quality assessment tasks and often focus only on image features without considering other relevant data resources, thus the performance is limited.
With the popularity of the Internet, the modern digital world we live in is multimodal in nature: images on the web are often accompanied with text. For example, on Photo.net (
https://www.photo.net/, accessed on 1 May 2022), Dpchallenge (
https://www.dpchallenge.com/, accessed on 1 May 2022) and other image sharing websites, users are allowed to make subjective comments on images. The comments describe the content of the image and the feelings it brings to people; thus, it is helpful in image aesthetic assessment tasks. Recently, a mushrooming number of works have been proposed to exploit the textual features. For example, Zhou et al. [
12] utilize multimodal Deep Boltzmann Machine (DBM) to encode both visual and textual information. Zhang et al. [
13] propose a Multimodal Recurrent Attention Convolutional Neural Network (MRACNN) to leverage the semantic power of user comments. Although the aforementioned methods obtain effective results, they often assume the completeness of modality in both training and test data as illustrated in
Figure 1. However, such an assumption may not always hold in the real world. For example, we may not be able to access textual data since many voters only give aesthetic scores without textual comments. Thus, an interesting yet challenging research question then arises: Can we learn a multimodal image aesthetic quality assessment model from an incomplete dataset while its performance should as close as possible to the one that learns from a full-modality dataset? In addition, existing multimodal methods [
12,
14] often use the concatenation or element-wise summations for multimodal feature fusion. Since the visual features and the textual features may vary significantly, traditional multimodal fusion methods may be insufficient, limiting the final prediction performance.
In this paper, we systematically study this problem and propose the Missing-Modility-Multimodal-Bert (MMMB) model. In order to deal with the missing textual modality at any stage, we reconstruct the missing textual description related to aesthetics according to the available image information. The generated textual modality along with the visual features are sent into the token spaces. Then, we make full use of the multi-head self-attention in the Bert model to fuse the multimodalities information at different levels, rather than only at the final layer.
The contributions of this paper are as follows:
To the best of our knowledge, we are the first work to systematically study the problem of missing modality data in both train set and test set in the field of multimodal image aesthetic quality assessment.
Inspired by self-supervised pretraining of Transformer-style architectures, we use the multi-head self-attention mechanism to capture the complex associations between the visual features from images and the textual features from comments at different levels. The experimental results demonstrate that the proposed multimodal fusion module significantly outperforms existing multimodal approaches.
We conducted extensive experiments to prove the superiority of the proposed method over other latest works on a two benchmark dataset.
The remainder of this paper is organized as follows:
Section 2 summarizes the related work.
Section 3 introduces the proposed approach.
Section 4 quantitatively analyses the effectiveness of the proposed method and compares it with state-of-the-art results. Finally,
Section 5 contains a summary and plans for future work.
3. Method
Problem Formulation. In multimodality image aesthetic prediction problems, we are given a multimodal dataset containing two modalities, i.e., image and text comments. Formally, we let denote a multimodal image aesthetic dataset. represent the full-modality samples, where and represent visual modality and textual modality of i-th sample respectively, and is the corresponding aesthetic label. are the modality-incomplete samples. We assume visual modality is available for all samples, while textual modality is available for only a portion of the subjects. Our target is to leverage both modality-complete and modality-incomplete data for model training.
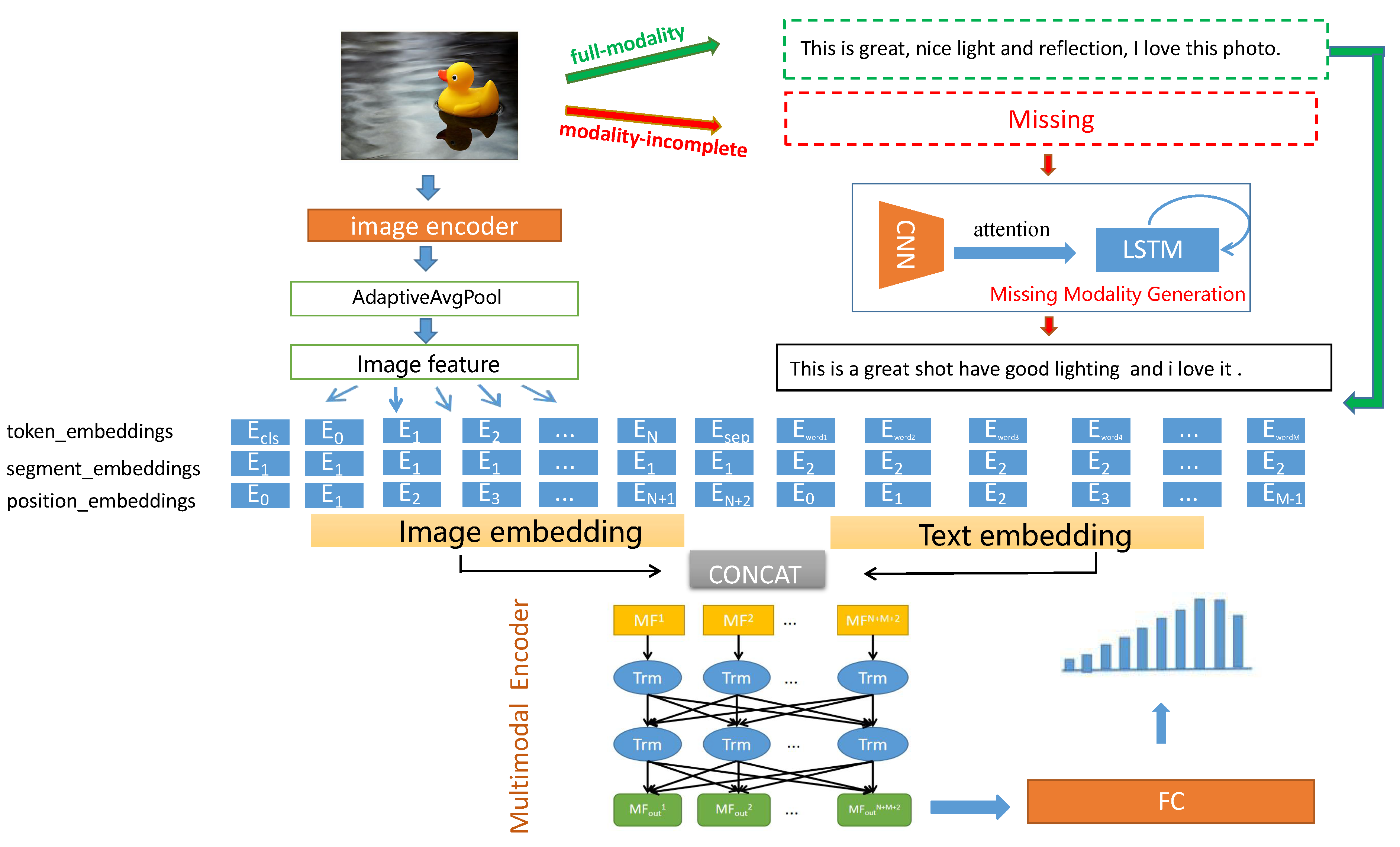
In this paper, we propose a novel multimodal image aesthetic quality assessment method, i.e., MMMB model. The overview of the approach is shown in
Figure 2. For the full-modality samples, we first use the image encoder to extract the raw features of the image and then map the extracted visual features to the token space. In the token spaces, the visual features, connected with the textual embedding features, are sent to the multimodal encoder, which uses the self-attention mechanism for multi-level and fine-grained fusion. In the case of missing textual modality, we generated the missing textual modality conditioned on existing modality images and then form a multimodal joint representation. Finally, the feature vectors output by the multimodal encoder are sent to the aesthetic prediction layer for aesthetic value assessment.
3.1. Image Encoder
Experiments have proved that the convolutional neural network architecture pretrained on ImageNet [
10] can be used to extract more effective visual features. In our method, any type of CNN can be used as a visual feature extractor. We take Resnet50 [
27] as an example in this section. The input image
I is first resized to
and then fed into the CNN to extract the deep features. In order to obtain
N independent embeddings consistent with the text information, we replace the original pool layer with an Adaptivepool layer. In addition, the output of the feature map is thus a tensor with dimensions
, where
W and
H represent the spatial resolution, and
D is the channel dimension. The extractor produces
vectors, which can be represented as follows:
where
represents
D-dimensional representation corresponding to a part of the image.
3.2. Missing Modality Generation
For the problem of missing modality data, traditional methods often directly discard the samples with missing modality data or reconstruct a multimodal joint representation of hidden space to encode multimodal information. However, these methods either lead to the reduction of sample count and loss of some important information, or need to update all samples at the same time, which is not applicable on large scale datasets for the image aesthetic quality assessment task. In this paper, we generate feature representation of missing textual modality in the latent space based on the available visual modality. Given the observed visual modality
, in order to obtain the reconstruction
of the missing modality, we optimize the following objective for the reconstruction network:
where
are the parameters of our reconstruction model. However, it is non-trivial to train a reconstruction network from limited modality complete samples. Inspired by [
28], we use an attention-based approach to generate approximate feature representations of textual modality using LSTM networks by attention to the salient part of an image. In order to learn the general aesthetic textual representation and reduce the complexity of the network, we first pretrained the reconstruction network on the DPC dataset [
29] (DPC-Captions dataset is an image aesthetic caption dataset, which contains 154,384 images and 2,427,483 comments from
DPChallenge.com (accessed on 1 May 2022) ).
Specifically, given the observable visual modality, the convolution neural network is used to extract the visual features
. The attention weight
, which is used to measure the weight of the image feature at the
i-
position when generating the
t-
word, is calculated for each position
i:
where
is a multilayer perception,
is the previous hidden state. We can calculate the context vector
after obtaining the attention weight:
Then, a long short-term memory (LSTM) [
30] network is used to produce the missing textual comments conditioned on a context vector
, the previous hidden state
, and the previously generated words. Our implementation of LSTM follows the one used in [
31]:
where
,
,
,
, and
are the input, forget, memory, output, and hidden state of the LSTM, respectively.
is an embedding matrix,
represents the sigmoid activation function, and ∘ represents the element-wise multiplication.
By using a deep output layer [
32], we can calculate the probability of each word in the wordmap as follows:
where
,
,
and
E are learned parameters initialized randomly. Finally, the word with the highest probability is taken as the currently generated word and used as the input of the next time.
3.3. Embedding Model
In this section, we will introduce the Embedding Layer, which generates input for the multimodal encoder.
3.3.1. Segment and Position Embedding
Segment embedding is used to distinguish different modalities. Specifically, we assign a segment ID to image modality and text modality, respectively. In specific experiments, we set the segment ID of image modality to 0and the segment ID of text modality to 1. Position embedding represents each embedding the relative position information in the segment. Each segment is counted from 0.
3.3.2. Text Embedding
For full-modality samples, we input the text comment rounds in the comment dataset. However, for the samples with missing textual modality, we input the reconstructed textual modality data. We adopt the same coding method as Bert [
33] to process text input, which firstly divides text into a word sequence, and then uses the WordPiece [
34] method to tokenize each word. Then, the token embedding is transformed into a 768-dimensional vector representation. We use
to represent the input text sequence, where
M represents the number of words, and
d represents the embedded 768 dimension. Similar to the traditional Bert, we add position embedding and segment embedding. The final text comment can be represented as
, and the textual representation at the
i-
position is calculated by:
where LayerNorm [
35] is a normalized function,
represents position embedding, and
represents segment embedding. We set
to 1 in this work.
3.3.3. Image Embedding
The
N independent image embedding obtained in
Section 3.1 corresponds to the
N tokens in the text modality. Firstly, we learn a randomly initialized weight matrix
to project each 2048 dimensional image feature of the
N image embeddings to the same
d dimension as the text embedding, as shown in the following:
represents the
i-
output after the adaptive pooling layer. Then, we represent the visual features as
, where
N represents
N independent embedding of image features after the last adaptive pooling layer. Similarly, we add position embedding and segment embedding to get the final visual representation
, and calculate the visual representation on the
i-
position as follows:
where
is set to 0.
3.4. Multimodal Encoder
After obtaining the sentence embedding vector and the visual embedding vector, we add two special tags [CLS] and [SEP] to construct the multimodal input sequence. [CLS] is used to learn the joint classification features, and [SEP] separates the embedding of different modality. The final input of the multimodal encoder is expressed as:
We then send the multimodal input
into the multimodal encoder based on transformer. The encoder contains a set of Bert layers for automatically modeling the rich interaction between textual and visual modality information. The architecture of Bert model is shown in
Figure 3, where “Trm” stands for transformer [
36], which is the infrastructure of Bert.
Firstly, the multimodal input
through the multi-head self-attention layer pays attention to the information of different subspace to capture richer feature information. For the
i-
head attention, the input
uses dot-product attention mechanism as follows:
where
m represents the number of heads,
,
,
represent query, key, and value in
i-
head attention, respectively.
,
,
are three randomly initialized weight matrixes. In the BERT-base model,
m is set to 12.
aims to turn the attention matrix into a standard normal distribution. Then, all attention heads are concatenated and multiplied by a weight matrix
to obtain the output of multi-head self-attention, which is as shown as follows:
Finally, residual connection and LayerNorm [
35] operation are performed on the output of multi-head self-attention. The function of the LayerNorm operation aims to normalize the hidden layers in the neural network into standard normal distribution and accelerate convergence. Specific operations are as follows:
In addition, through the operation of two-layer linear mapping feed forward layer with Gelu [
37] activation function and Equation (
16), the output of an encoder in multimodal encoder is calculated as follows:
Then, is used as the input of the next multimodal encoder. The entire multimodal encoder stacks 12 of such encoder. Finally, the first token [CLS] of the last hidden layer is sent to the aesthetic prediction module to evaluate the image aesthetic distribution.
3.5. Aesthetic Prediction
After obtaining the multimodal feature vector through the above operations, we send it into a fully connected layer to output the aesthetic label distribution of the image. After that, the normalization operation will be carried out through the softmax layer. Similar with the work [
13,
14], this paper uses the Earth Mover’s Distance (EMD) [
19] loss function, which can calculate the minimum distance of the two sequential distributions, to optimize the network. The EMD loss is defined as follows:
where
p represents the real aesthetic score distribution of the image, and
represents the predicted aesthetic score distribution.
represents the cumulative distribution function.
N represents the number of points. Similar to previous work [
8,
38], we choose
for its simplicity in optimization.







{kind=link}
{kind=link}
{kind=link}
{kind=link}