
Multiple Scenarios of Quality of Life Index Using Fuzzy Linguistic Quantifiers: The Case of 85 Countries in Numbeo

 , ,
, ,
Abstract
:1. Introduction
2. Theoretical Framework
2.1. Composite Indicators
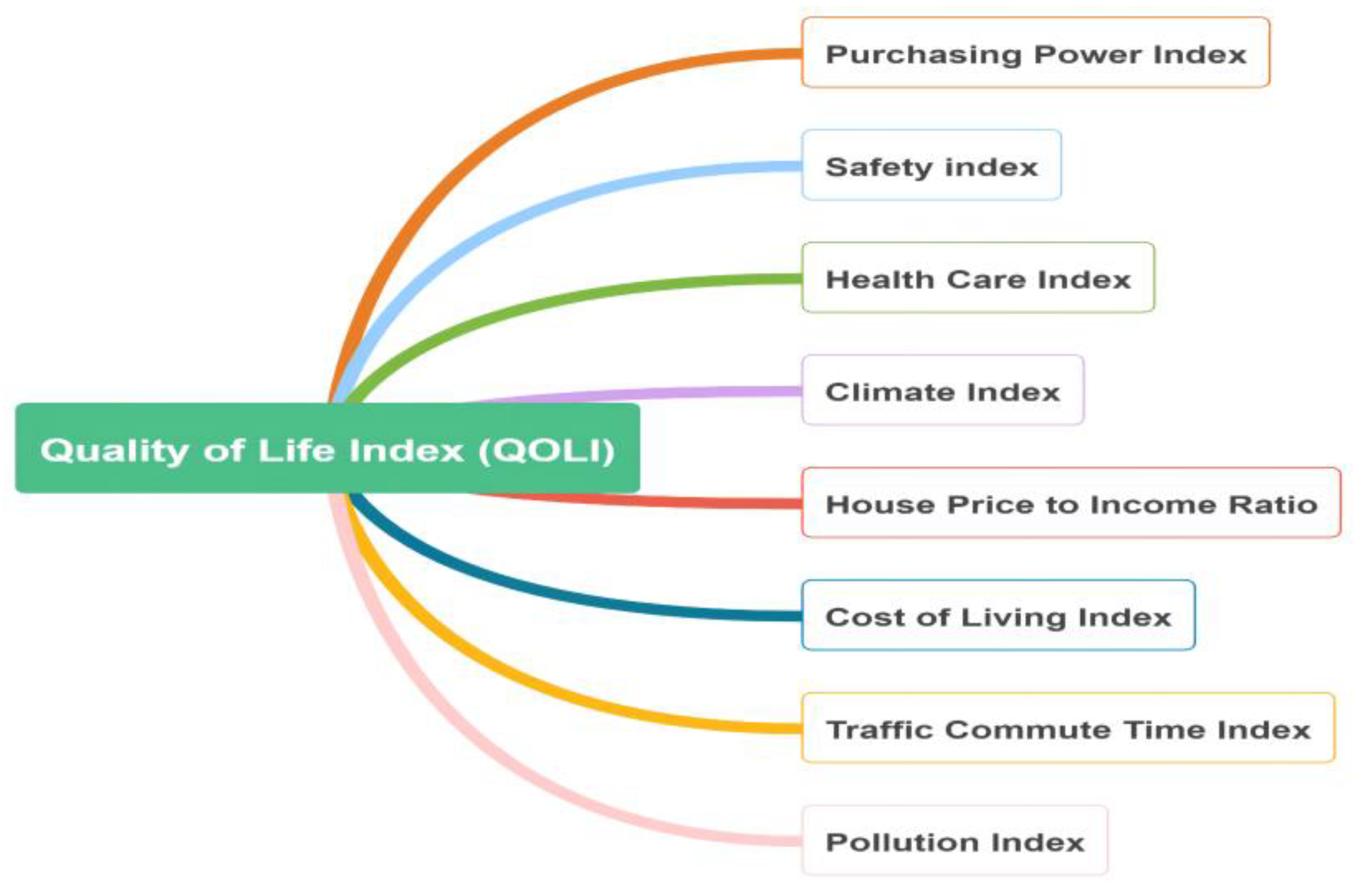
2.2. The Quality of Life Index
- Purchasing power index (, including rent index): a relative purchasing power in buying goods and services in a given city or country for the average net salary;
- Safety index (): an indicator taking into account concerns about robberies, vehicle theft, and other crimes, as well as the incidence of narcotics, property crime, violent crime, and corruption and bribery. This index is the opposite of the crime index;
- Health care index (): an estimation of the overall quality of the health care system, health care professionals, equipment, staff, doctors, cost, etc.;
- Climate index (): an estimation of the climate likability of a given city or a country;
- House price to income ratio (): the basic measure for apartment purchase affordability. It is calculated as the ratio of median apartment prices to median familial disposable income, expressed as years of income;
- Cost of living index (, excluding rent index): a relative indicator of consumer goods prices, including groceries, restaurants, transportation, and utilities. This index does not include accommodation expenses such as mortgage or rent;
- Traffic commute time index (): a composite index of time consumed in traffic due to job commute, estimation of time consumption dissatisfaction, estimation of CO2 consumption in traffic, and overall inefficiencies in the traffic system;
- Pollution index (): an estimation of the overall pollution in a given city or a country, taking into account air pollution, water pollution, and other pollution types.
2.3. The 2-Tuple Linguistic Model
- If G < M, is smaller than ;
- If G = M, when:
- , is the same as ;
- , is smaller than ;
- , is larger than ;
- If G > M, is larger than .
2.4. The Ordered Weighted Averaging (OWA) Operator
2.5. The 2-Tuple Linguistic Ordered Weighted Averaging (2LOWA) Operator
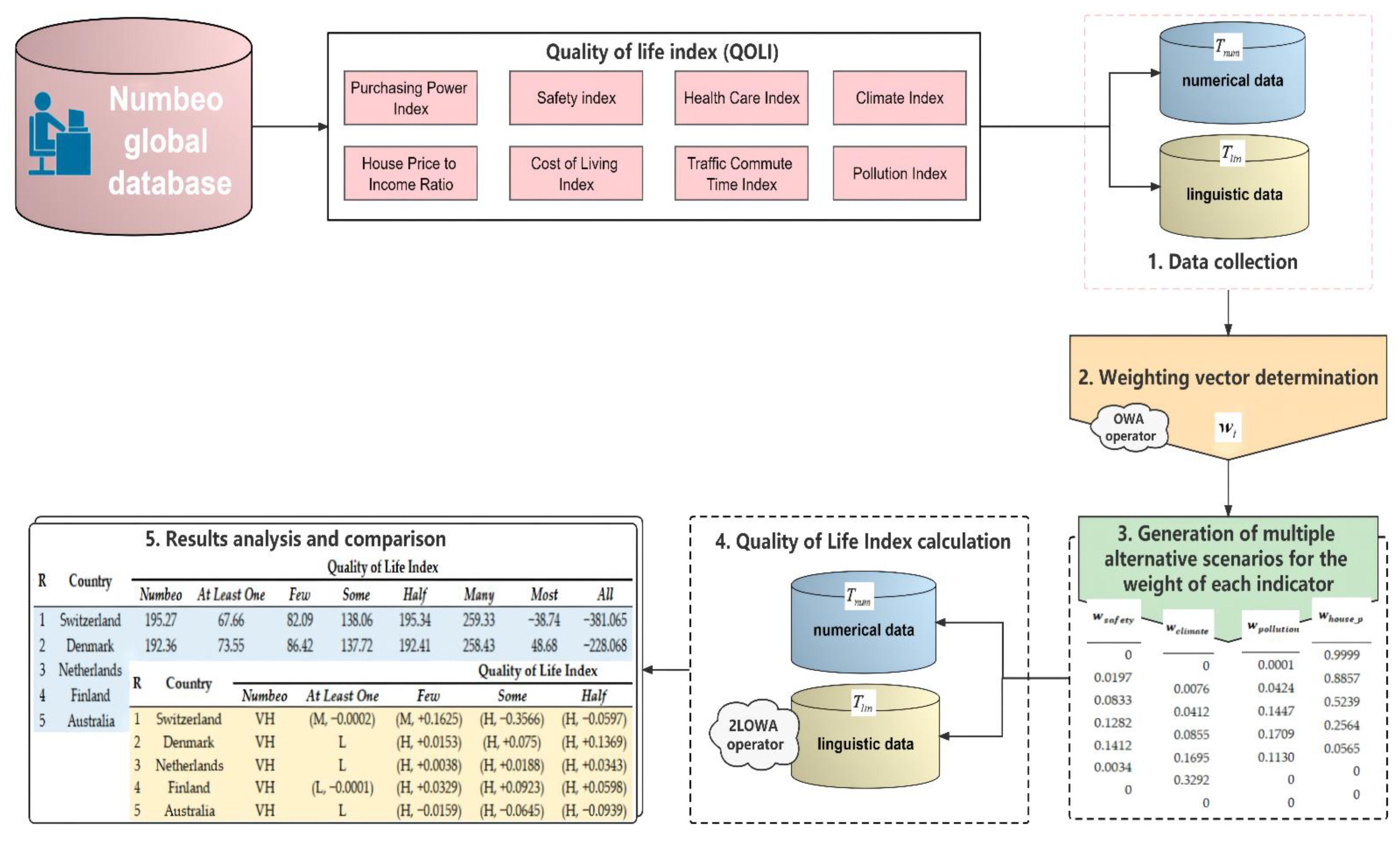
3. Methodology
- Step 1. Data collection.
- is the name of each country, with , and ;
- are the numerical values of eight sub-indicators for each country;
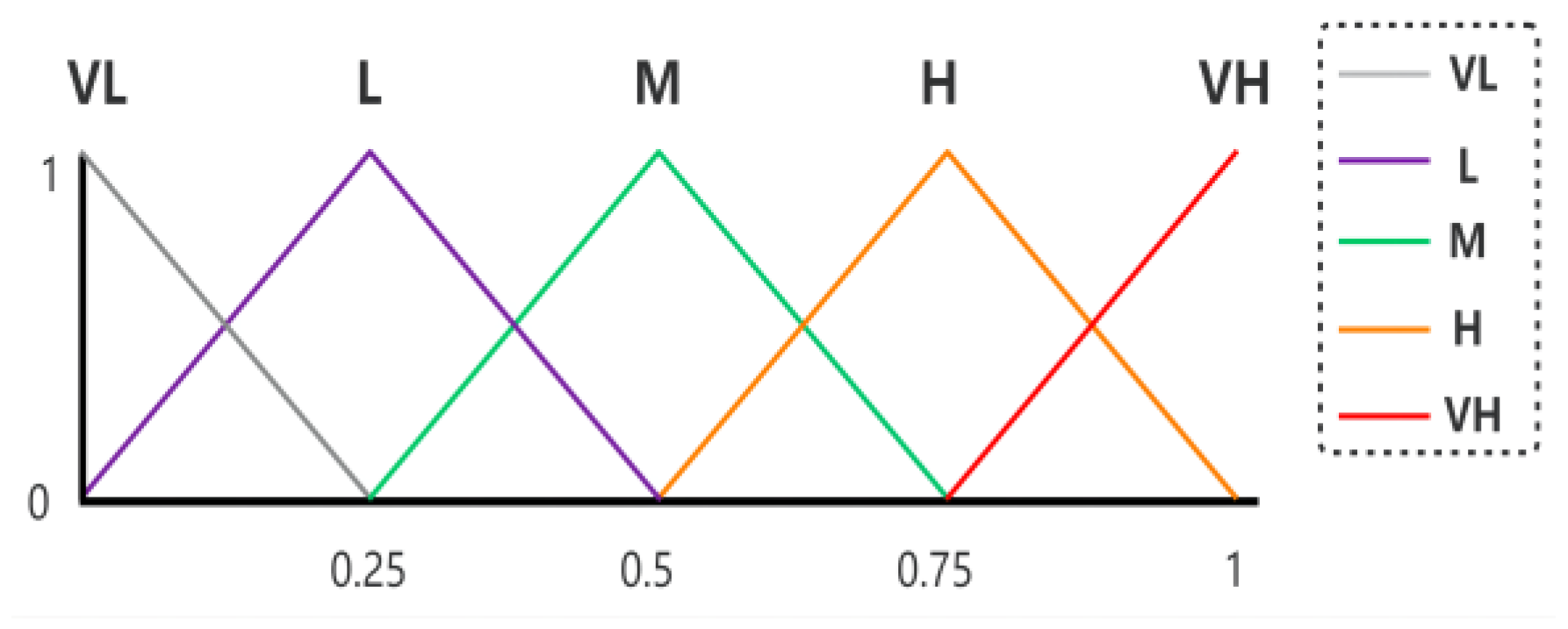
- are the 2-tuple values of eight sub-indicators for each country, expressed on a linguistic scale. Based on Numbeo, this linguistic scale contains five values: “Very Low”, “Low”, “Moderate”, “High”, and “Very High”. These linguistic values are symmetrical, whose center value is neutral (i.e., “Moderate”) [83,84,85]. They can be modeled by fuzzy triangular labels, as shown in Figure 2.
- Step 2. Weighting vector determination.
- Step 3. Generation of multiple alternative scenarios for the weight of each indicator.
- ;
- ;
- ;
- ;
- ;
- ;
- ;
- .
- Step4. Quality of Life Index calculation.
- For the numerical data:
- For the linguistic data:
- Step 5. Results analysis and comparison.
4. Analysis of Results and Comparison
5. Discussion
- When comparing the QOLI value with GDP per capita, GDP per capita has a significant relationship with all the QOLIs generated by those seven linguistic quantifiers, although it is highly negatively correlated with the QOLI calculated by the quantifiers Most and All. The QOLI generated by the quantifier Some has a highly positive association (PCC > 0.7, whether in numerical value or 2-tuple value) with GDP per capita. It means that if a country calculates its QOLI using the quantifier Some, its QOLI grows in lockstep with its GDP per capita. Moreover, the correlation between them is considerably stronger than that between the quantifier Half and GDP per capita, while the QOLI obtained by the quantifier Some and the QOLI acquired by the quantifier Half are strongly positively correlated. Therefore, the QOLI generated by the quantifier Some can be considered the “best” choice to replace Numbeo´s QOLI, especially because it is more closely correlated with GDP per capita;
- When comparing the QOLI ranking with that of GDP per capita, the same conclusion is drawn as before. For example, the ranking of GDP per capita is strongly negatively related to that of the QOLI generated by quantifier All. Combined with Table 14, it indicates that the country with a high position in GDP per capita also has increased house prices, so its QOLI and QOLI ranking are low in this scenario. Furthermore, except for the quantifier Half, the quantifier Some obtains a QOLI ranking highly similar to the GDP per capita ranking, and they are stronger correlated when ranked using the 2-tuple value of the QOLI.
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- OECD. OECD Guidelines on Measuring Subjective Well-Being. Available online: https://read.oecd-ilibrary.org/economics/oecd-guidelines-on-measuring-subjective-well-being_9789264191655-en (accessed on 10 April 2022).
- Diener, E. The Remarkable Changes in the Science of Subjective Well-Being. Perspect. Psychol. Sci. 2013, 8, 663–666. [Google Scholar] [CrossRef] [PubMed]
- Hicks, S.; Tinkler, L.; Allin, P. Measuring Subjective Well-Being and Its Potential Role in Policy: Perspectives from the UK Office for National Statistics. Soc. Indic Res. 2013, 114, 73–86. [Google Scholar] [CrossRef]
- Diener, E.; Oishi, S.; Lucas, R.E. National Accounts of Subjective Well-Being. Am. Psychol. 2015, 70, 234–242. [Google Scholar] [CrossRef] [PubMed]
- Zuzanek, J.; Zuzanek, T. Of Happiness and of Despair, Is There a Measure? Time Use and Subjective Well-Being. J. Happiness Stud. 2015, 16, 839–856. [Google Scholar] [CrossRef]
- Diener, E.; Oishi, S.; Tay, L. Advances in Subjective Well-Being Research. Nat. Hum. Behav. 2018, 2, 253–260. [Google Scholar] [CrossRef] [PubMed]
- Clark, W.A.V.; Yi, D.; Huang, Y. Subjective Well-Being in China’s Changing Society. Proc. Natl. Acad. Sci. USA 2019, 116, 16799–16804. [Google Scholar] [CrossRef] [Green Version]
- Mouratidis, K. Compact City, Urban Sprawl, and Subjective Well-Being. Cities 2019, 92, 261–272. [Google Scholar] [CrossRef]
- Rogge, N.; Van Nijverseel, I. Quality of Life in the European Union: A Multidimensional Analysis. Soc. Indic Res. 2019, 141, 765–789. [Google Scholar] [CrossRef]
- McGuire, J.; Kaiser, C.; Bach-Mortensen, A.M. A Systematic Review and Meta-Analysis of the Impact of Cash Transfers on Subjective Well-Being and Mental Health in Low- and Middle-Income Countries. Nat. Hum. Behav. 2022, 6, 359–370. [Google Scholar] [CrossRef]
- Campbell, A.; Converse, P.E.; Rodgers, W.L. The Quality of American Life: Perceptions, Evaluations, and Satisfactions; Russell Sage Foundation: New York, NY, USA, 1976. [Google Scholar]
- Cella, D.F. Quality of Life: Concepts and Definition. J. Pain Symptom Manag. 1994, 9, 186–192. [Google Scholar] [CrossRef]
- Diener, E.; Suh, E.; Lucas, R.; Smith, H. Subjective Well-Being: Three Decades of Progress. Psychol. Bull. 1999, 125, 276–302. [Google Scholar] [CrossRef]
- Bonomi, A.E.; Patrick, D.L.; Bushnell, D.M.; Martin, M. Validation of the United States’ Version of the World Health Organization Quality of Life (WHOQOL) Instrument. J. Clin. Epidemiol. 2000, 53, 1–12. [Google Scholar] [CrossRef]
- Şeker, M. Quality of Life Index: A Case Study of Istanbul. Ekonom. Ve İstat. Sayı 2015, 23, 1–15. [Google Scholar]
- Jiménez, G.E.; Zulueta, Y. A 2-Tuple Linguistic Multi-Period Decision Making Approach for Dynamic Green Supplier Selection. DYNA 2017, 84, 199–206. [Google Scholar] [CrossRef]
- Paruolo, P.; Saisana, M.; Saltelli, A. Ratings and Rankings: Voodoo or Science? J. R. Stat. Soc. Ser. A (Stat. Soc.) 2013, 176, 609–634. [Google Scholar] [CrossRef] [Green Version]
- Munda, G.; Nardo, M. Constructing Consistent Composite Indicators: The Issue of Weights. 2005. Available online: https://www.researchgate.net/publication/239751435_Constructing_Consistent_Composite_Indicators_The_Issue_of_Weights (accessed on 2 June 2022).
- Pearson, K. LIII. On Lines and Planes of Closest Fit to Systems of Points in Space. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef] [Green Version]
- Gharizadeh Beiragh, R.; Alizadeh, R.; Shafiei Kaleibari, S.; Cavallaro, F.; Zolfani, S.H.; Bausys, R.; Mardani, A. An Integrated Multi-Criteria Decision Making Model for Sustainability Performance Assessment for Insurance Companies. Sustainability 2020, 12, 789. [Google Scholar] [CrossRef] [Green Version]
- Nardo, M.; Saisana, M.; Saltelli, A.; Tarantola, S.; Hoffman, A.; Giovannini, E. Handbook on Constructing Composite Indicators: Methodology and User Guide; OECD Statistics Working Paper 2005/3; OECD Publishing: Paris, France, 2005. [Google Scholar]
- Pareto, A. Methods for Constructing Composite Indices: One for All or All for One? Riv. Ital. Econ. Demogr. E Stat. 2013, LXVII, 67–80. [Google Scholar]
- Samira, E.G.; Núñez, T.; Ruiz, F. Building Composite Indicators Using Multicriteria Methods: A Review. J. Bus. Econ. 2019, 89, 1–24. [Google Scholar]
- Saaty, R.W. The Analytic Hierarchy Process—What It Is and How It Is Used. Math. Model. 1987, 9, 161–176. [Google Scholar] [CrossRef] [Green Version]
- NIEMIRA, M.P.; Niemira, M.P. An AHP-Based Composite Cyclical-Performance Index. Indian Econ. Rev. 2001, 36, 241–250. [Google Scholar]
- Gómez-Limón, J.; Arriaza, M.; Guerrero-Baena, M. Building a Composite Indicator to Measure Environmental Sustainability Using Alternative Weighting Methods. Sustainability 2020, 12, 4398. [Google Scholar] [CrossRef]
- Abdar, Z.K.; Amirtaimoori, S.; Mehrjerdi MR, Z.; Boshrabadi, H.M. A Composite Index for Assessment of Agricultural Sustainability: The Case of Iran. Environ. Sci. Pollut. Res. Int. 2022. [Google Scholar] [CrossRef] [PubMed]
- Saaty, T. Decision Making with Dependence and Feedback: The Analytic Network Process: The Organization and Prioritization of Complexity; RWS Publications: Pittsburgh, PA, USA, 1996. [Google Scholar]
- Asadzadeh, A.; Kötter, T.; Zebardast, E. An Augmented Approach for Measurement of Disaster Resilience Using Connective Factor Analysis and Analytic Network Process (F’ANP) Model. Int. J. Disaster Risk Reduct. 2015, 14, 504–518. [Google Scholar] [CrossRef]
- Mao, F.; Zhao, X.; Ma, P.; Chi, S.; Richards, K.; Clark, J.; Hannah, D.M.; Krause, S. Developing Composite Indicators for Ecological Water Quality Assessment Based on Network Interactions and Expert Judgment. Environ. Model. Softw. 2019, 115, 51–62. [Google Scholar] [CrossRef]
- Diakoulaki, D.; Mavrotas, G.; Papayannakis, L. Determining Objective Weights in Multiple Criteria Problems: The Critic Method. Comput. Oper. Res. 1995, 22, 763–770. [Google Scholar] [CrossRef]
- Ren, J. China’s Energy Security: Analysis, Assessment and Improvement; World Scientific: Singapore, 2020. [Google Scholar]
- Charnes, A.; Cooper, W.W.; Rhodes, E. Measuring the Efficiency of Decision Making Units. Eur. J. Oper. Res. 1978, 2, 429–444. [Google Scholar] [CrossRef]
- Murias, P.; de Miguel, J.C.; Rodríguez, D. A Composite Indicator for University Quality Assesment: The Case of Spanish Higher Education System. Soc. Indic Res. 2008, 89, 129–146. [Google Scholar] [CrossRef]
- Athanassoglou, S. Revisiting Worst-Case DEA for Composite Indicators. Soc. Indic Res. 2015, 128, 1259–1272. [Google Scholar] [CrossRef] [Green Version]
- Roy, B. Classement et choix en présence de points de vue multiples. R.I.R.O. 1968, 2, 57–75. [Google Scholar] [CrossRef]
- Pereira, D.V.e.S.; Mota, C.M.d.M. Human Development Index Based on ELECTRE TRI-C Multicriteria Method: An Application in the City of Recife. Soc Indic Res 2016, 125, 19–45. [Google Scholar] [CrossRef]
- Attardi, R.; Cerreta, M.; Sannicandro, V.; Torre, C.M. Non-Compensatory Composite Indicators for the Evaluation of Urban Planning Policy: The Land-Use Policy Efficiency Index (LUPEI). Eur. J. Oper. Res. 2018, 264, 491–507. [Google Scholar] [CrossRef]
- Brans, J.P.; Vincke, P. Note-A Preference Ranking Organisation Method: The PROMETHEE Method for Multiple Criteria Decision-Making. Manage. Sci. 1985, 31, 647–656. [Google Scholar] [CrossRef] [Green Version]
- Antanasijević, D.; Pocajt, V.; Ristić, M.; Perić-Grujić, A. A Differential Multi-Criteria Analysis for the Assessment of Sustainability Performance of European Countries: Beyond Country Ranking. J. Clean. Prod. 2017, 165, 213–220. [Google Scholar] [CrossRef]
- Churchman, C.W.; Ackoff, R.L. An Approximate Measure of Value. OR 1954, 2, 172–187. [Google Scholar] [CrossRef]
- Haider, H.; Hewage, K.; Umer, A.; Ruparathna, R.; Chhipi-Shrestha, G.; Culver, K.; Holland, M.; Kay, J.; Sadiq, R. Sustainability Assessment Framework for Small-Sized Urban Neighbourhoods: An Application of Fuzzy Synthetic Evaluation. Sustain. Cities Soc. 2018, 36, 21–32. [Google Scholar] [CrossRef]
- Hwang, C.L.; Yoon, K. Multiple Attribute Decision Making: Methods and Applications: A State-of-the-Art Survey; Springer-Verlag: Berlin, Germany, 1981. [Google Scholar]
- Bao, Q.; Ruan, D.; Shen, Y.; Hermans, E.; Janssens, D. Improved Hierarchical Fuzzy TOPSIS for Road Safety Performance Evaluation. Knowl.-Based Syst. 2012, 32, 84–90. [Google Scholar] [CrossRef]
- Bouslah, K.; Liern, V.; Ouenniche, J.; Pérez-Gladish, B. Ranking Firms Based on Their Financial and Diversity Performance Using Multiple-Stage Unweighted TOPSIS. Int. Trans. Oper. Res. 2022, 1, 1–21. [Google Scholar] [CrossRef]
- Meng, Y.; Wu, H.; Zhao, W.; Chen, W.; Dinçer, H.; Yüksel, S. A Hybrid Heterogeneous Pythagorean Fuzzy Group Decision Modelling for Crowdfunding Development Process Pathways of Fintech-Based Clean Energy Investment Projects. Financ. Innov. 2021, 7, 33. [Google Scholar] [CrossRef]
- Yager, R.R. On Ordered Weighted Averaging Aggregation Operators in Multicriteria Decisionmaking. IEEE Trans. Syst. Man Cybern. 1988, 18, 183–190. [Google Scholar] [CrossRef]
- Badea, A.C.; Rocco, S.C.M.; Tarantola, S.; Bolado, R. Composite Indicators for Security of Energy Supply Using Ordered Weighted Averaging. Reliab. Eng. Syst. Saf. 2011, 96, 651–662. [Google Scholar] [CrossRef]
- Marzi, S.; Mysiak, J.; Essenfelder, A.H.; Amadio, M.; Giove, S.; Fekete, A. Constructing a Comprehensive Disaster Resilience Index: The Case of Italy. PLoS ONE 2019, 14, e0221585. [Google Scholar] [CrossRef] [PubMed]
- Duckstein, L.; Opricovic, S. Multiobjective Optimization in River Basin Development. Water Resour. Res. 1980, 16, 14–20. [Google Scholar] [CrossRef]
- Muhamad, S.N.N.; Halim, R.A.; Shahidan WN, W.; Hussain, N.J.; Sarkam, S.F. Ranking Academic Performance Using Fuzzy Vikor: A Case of Secondary Schools At Perlis. J. Comput. Res. Innov. 2018, 3, 31–38. [Google Scholar] [CrossRef]
- Melyn, W.; Moesen, W. Towards a Synthetic Indicator of Macroeconomic Performance: Unequal Weighting When Limited Information Is Available; Public Economics Research Paper; Katholieke Universiteit Leuven: Leuven, Belgium, 1991. [Google Scholar]
- Gaaloul, H.; Khalfallah, S. Application of the “Benefit-Of-the-Doubt” Approach for the Construction of a Digital Access Indicator: A Revaluation of the “Digital Access Index”. Soc. Indic. Res. 2014, 118, 45–56. [Google Scholar] [CrossRef]
- Ravanos, P.; Karagiannis, G. A VEA Benefit-of-the-Doubt Model for the HDI. Soc. Indic. Res. 2021, 155, 27–46. [Google Scholar] [CrossRef]
- Mariano, E.; Ferraz, D.; Gobbo, S. The Human Development Index with Multiple Data Envelopment Analysis Approaches: A Comparative Evaluation Using Social Network Analysis. Soc. Indic. Res. 2021, 157, 443–500. [Google Scholar] [CrossRef]
- Gupta, V. Composite Non-Paramertric CRS Index for Public Sector Banks of India. PalArch’s J. Archaeol. Egypt / Egyptol. 2021, 18, 1589–1607. [Google Scholar]
- Munda, G. Multiple Criteria Decision Analysis and Sustainable Development. In Multiple Criteria Decision Analysis: State of the Art Surveys; Greco, S., Ehrgott, M., Figueira, J.R., Eds.; International Series in Operations Research & Management Science; Springer: New York, NY, USA, 2016; pp. 1235–1267. [Google Scholar]
- Roszkowska, E.; Filipowicz-Chomko, M. Measuring Sustainable Development in the Education Area Using Multi-Criteria Methods: A Case Study. Cent. Eur. J. Oper. Res. 2020, 28, 1219–1241. [Google Scholar] [CrossRef] [Green Version]
- Bouyssou, D. Some Remarks on the Notion of Compensation in MCDM. Eur. J. Oper. Res. 1986, 26, 150–160. [Google Scholar] [CrossRef]
- Munda, G. “Measuring Sustainability”: A Multi-Criterion Framework. Environ. Dev. Sustain. 2005, 7, 117–134. [Google Scholar] [CrossRef]
- Rothrock, L.; Yin, J. Integrating Compensatory and Noncompensatory Decision-Making Strategies in Dynamic Task Environments. In Decision Modeling and Behavior in Complex and Uncertain Environments; Kugler, T., Smith, J.C., Connolly, T., Son, Y.-J., Pardalos, P.M., Eds.; Springer Optimization and Its Applications Series; Springer: New York, NY, USA, 2008; Volume 21, pp. 125–141. [Google Scholar]
- Rowley, H.V.; Peters, G.M.; Lundie, S.; Moore, S.J. Aggregating Sustainability Indicators: Beyond the Weighted Sum. J. Environ. Manag. 2012, 111, 24–33. [Google Scholar] [CrossRef] [PubMed]
- Alexander, E.; Beimborn, E. Sensitivity Analysis of Multiple-Choice Decision Methods for Transportation. Transp. Res. Rec. 1987, 1124, 36–42. [Google Scholar]
- Antunes, C.H.; Clímaco, J.N. Sensitivity Analysis in MCDM Using the Weight Space. Oper. Res. Lett. 1992, 12, 187–196. [Google Scholar] [CrossRef]
- Triantaphyllou, E.; Sánchez, A. A Sensitivity Analysis Approach for Some Deterministic Multi-Criteria Decision-Making Methods. Decis. Sci. 1997, 28, 151–194. [Google Scholar] [CrossRef]
- Alexander, E.R. Sensitivity Analysis in Complex Decision Models. J. Am. Plan. Assoc. 1989, 55, 323–333. [Google Scholar] [CrossRef]
- Saisana, M.; Saltelli, A.; Tarantola, S. Uncertainty and Sensitivity Analysis Techniques as Tools for the Quality Assessment of Composite Indicators. J. R. Stat. Soc A 2005, 168, 307–323. [Google Scholar] [CrossRef]
- Grupp, H.; Mogee, M.E. Indicators for National Science and Technology Policy: How Robust Are Composite Indicators? Res. Policy 2004, 33, 1373–1384. [Google Scholar] [CrossRef]
- Grupp, H.; Schubert, T. Review and New Evidence on Composite Innovation Indicators for Evaluating National Performance. Res. Policy 2010, 39, 67–78. [Google Scholar] [CrossRef]
- Vaida-Muntean, C. Uncertainty and Sensitivity in Statistical Data. Rev. Română Stat. Supl. 2014, 12, 29–36. [Google Scholar]
- WHO. The World Health Organization Quality of Life (WHOQOL). Available online: https://www.who.int/publications-detail-redirect/WHO-HIS-HSI-Rev.2012.03 (accessed on 27 March 2022).
- Numbeo. About Quality of Life Indices At This Website. Available online: https://www.numbeo.com/quality-of-life/indices_explained.jsp (accessed on 27 March 2022).
- Herrera, F.; Martinez, L. A 2-Tuple Fuzzy Linguistic Representation Model for Computing with Words. IEEE Trans. Fuzzy Syst. 2000, 8, 746–752. [Google Scholar]
- Zadeh, L.A. Fuzzy Logic = Computing with Words. IEEE Trans. Fuzzy Syst. 1996, 4, 103–111. [Google Scholar] [CrossRef] [Green Version]
- Ekel, P.; Pedrycz, W.; Pereira, J., Jr. Multicriteria Decision-Making Under Conditions of Uncertainty: A Fuzzy Set Perspective; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar]
- Peláez, J.; Doña, J. LAMA: A Linguistic Aggregation of Majority Additive Operator. Int. J. Intell. Syst. 2003, 18, 809–820. [Google Scholar] [CrossRef]
- Libório, M.P.; da Silva Martinuci, O.; Ekel, P.I.; Hadad, R.M.; de Mello Lyrio, R.; Bernardes, P. Measuring Inequality through a Non-Compensatory Approach. GeoJournal 2021. [Google Scholar] [CrossRef]
- Yager, R.R. Quantifier Guided Aggregation Using OWA Operators. Int. J. Intell. Syst. 1996, 11, 49–73. [Google Scholar] [CrossRef]
- Boroushaki, S.; Malczewski, J. Implementing an Extension of the Analytical Hierarchy Process Using Ordered Weighted Averaging Operators with Fuzzy Quantifiers in ArcGIS. Comput. Geosci. 2008, 34, 399–410. [Google Scholar] [CrossRef]
- Jiang, H.; Eastman, J.R. Application of Fuzzy Measures in Multi-Criteria Evaluation in GIS. Int. J. Geogr. Inf. Sci. 2000, 14, 173–184. [Google Scholar] [CrossRef]
- Numbeo. Quality of Life Index by Country 2022. Available online: https://www.numbeo.com/quality-of-life/rankings_by_country.jsp (accessed on 20 March 2022).
- Numbeo. Quality of Life in Canada. Available online: https://www.numbeo.com/quality-of-life/country_result.jsp?country=Canada (accessed on 2 June 2022).
- Carrasco, R.; Blasco, F.; Garcia-Madariaga, J.; Pedreño Santos, A.; Herrera-Viedma, E. A Model to Obtain a Servperf Scale Evaluation of the Crm Customer Complaints: An Application to the 4g Telecommunications Sector. Technol. Econ. Dev. Econ. 2018, 24, 1606–1629. [Google Scholar] [CrossRef]
- Dombi, J.; Jónás, T. Likert Scale-Based Evaluations with Flexible Fuzzy Numbers. In Advances in the Theory of Probabilistic and Fuzzy Data Scientific Methods with Applications; Dombi, J., Jónás, T., Eds.; Studies in Computational Intelligence; Springer International Publishing: Cham, Switzerland, 2021; pp. 167–187. [Google Scholar]
- Bueno, I.; Carrasco, R.A.; Porcel, C.; Herrera-Viedma, E. Profiling Clients in the Tourism Sector Using Fuzzy Linguistic Models Based on 2-Tuples. Procedia Comput. Sci. 2022, 199, 718–724. [Google Scholar] [CrossRef]
- Mokarram, M.; Hojati, M. Using Ordered Weight Averaging (OWA) Aggregation for Multi-Criteria Soil Fertility Evaluation by GIS (Case Study: Southeast Iran). Comput. Electron. Agric. 2017, 132, 1–13. [Google Scholar] [CrossRef]
- Yusoff, B.; Merigó, J.M.; Ceballos, D.; Peláez, J.I. Weighted-Selective Aggregated Majority-OWA Operator and Its Application in Linguistic Group Decision Making. Int. J. Intell. Syst. 2018, 33, 1929–1948. [Google Scholar] [CrossRef]
- Llorens, M.; Carrasco, R.; Bueno, I.; Herrera-Viedma, E.; Morente-Molinera, J.A. Multiple Criteria Approach Applied to Digital Transformation in Fashion Stores: The Case of Physical Retailers in Spain. Technol. Econ. Dev. Econ. 2022, 28, 500–530. [Google Scholar] [CrossRef]
- IMF World Economic Outlook. World GDP Ranking 2021. Available online: https://statisticstimes.com/economy/projected-world-gdp-ranking.php (accessed on 6 April 2022).
- Lin, B. Why Chinese Cities Are the Most Expensive Places in the World to Buy Real Estate. Available online: https://mcgillbusinessreview.com/articles/why-chinese-cities-are-the-most-expensive-places-in-the-world-to-buy-real-estate (accessed on 8 April 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Description | Literature | Application |
|---|---|---|---|
| Analytic hierarchy process (AHP) | A method for measuring the weights of structure components by using a paired comparison scale. | Saaty, 1987 [24] | Composite cyclical-performance index [25], environmental sustainability index [26], agricultural sustainability index [27] |
| Analytic network process (ANP) | An extension of the AHP that allows for interdependencies between criteria. | Saaty, 1996 [28] | Disaster resilience indicator [29], ecological water quality index [30] |
| Criteria importance through intercriteria correlation (CRITIC) | A method for determining objective weights for each criterion by employing correlation analysis between criteria. | Diakoulaki et al., 1995 [31] | Energy security index [32] |
| Data envelopment analysis (DEA) | A non-parametric method for measuring the efficiency of a group of multiple decision-making units, with multiple inputs and outputs. | Charnes et al., 1978 [33] | Spanish public university quality index [34], sustainability index [35] |
| Elimination et choix traduisant la realité (ELECTRE) | A method for determining the concordance and discordance indices of a group of alternatives, and ranking them from best to worst. | Roy, 1968 [36] | Human development index [37], land-use policy efficiency index [38] |
| Preference Ranking Organization Method for Enrichment Evaluation (PROMETHEE) | A method for producing a ranking based on choosing a preference function for each criterion in an MCDM issue. | Brans and Vincke, 1985 [39] | European countries sustainability index [40] |
| Simple Additive Weighting (SAW) | A method for calculating a weighted score for each alternative by multiplying each attribute’s contributions by their weights. | Churchman and Ackoff, 1954 [41] | Neighborhood sustainability index [42] |
| Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) | A compensatory aggregation method for choosing between the shortest Euclidean distance to the ideal solution, and the biggest distance to the negative ideal solution. | Hwang and Yoon, 1981 [43] | Road safety performance index [44], financial and diversity performance index [45], clean energy index [46] |
| Ordered weighted averaging (OWA) | A symmetric aggregation method for distributing weights based on the input value and unifies multiple inputs in one operator. | Yager, 1988 [47] | Energy supply security index [48], disaster resilience index [49] |
| Visekriterijumska Optimizacija I kompromisno resenje (VIKOR) | A method for calculating the compromise ranking list of a group of alternatives, based on the measure of closeness to the ideal option. | Duckstein and Opricovic, 1980 [50] | Academic performance index [51] |
| Benefit of the doubt (BoD) | A method derived from the DEA, which is a linear mathematical programming methodology, to assign the most favorable weight for each observation. These weights enable both data normalization and objective weighing. | Melyn and Moesen, 1991 [52] | Digital access index [53], human development index [54,55], non-parametric corporate social responsibility index [56] |
| Linguistic Quantifier | |
|---|---|
| At least one | 0.0001 |
| Few | 0.1 |
| Some | 0.5 |
| Half | 1 |
| Many | 2 |
| Most | 10 |
| All | 1000 |
| Linguistic Quantifier | Weighting Vector | |||||
|---|---|---|---|---|---|---|
| At least one | 0.9998 | 0.0001 | 0 | 0 | 0 | 0 |
| Few | 0.8360 | 0.06 | 0.0371 | 0.0272 | 0.0217 | 0.0181 |
| Some | 0.4082 | 0.1691 | 0.1298 | 0.1094 | 0.0964 | 0.0871 |
| Half | 0.1667 | 0.1667 | 0.1667 | 0.1667 | 0.1667 | 0.1667 |
| Many | 0.0278 | 0.0833 | 0.1389 | 0.1944 | 0.2500 | 0.3056 |
| Most | 0 | 0 | 0.0010 | 0.0164 | 0.1442 | 0.8385 |
| All | 0 | 0 | 0 | 0 | 0 | 1 |
| Linguistic Quantifier | whouse_p | wpollution | wsafety | wtraffic_t | wpurcahsing_p | whealth_c | wclimate | wcost_liv | Orness | Tradeoff |
|---|---|---|---|---|---|---|---|---|---|---|
| At least one | 0.9999 | 0.0001 | 0 | 0 | 0 | 0 | 0 | 0 | 0.9999 | 0.0002 |
| Few | 0.8857 | 0.0424 | 0.0197 | 0.0197 | 0.0115 | 0.0115 | 0.0076 | 0.0019 | 0.9215 | 0.1960 |
| Some | 0.5239 | 0.1447 | 0.0833 | 0.0833 | 0.0562 | 0.0562 | 0.0412 | 0.0112 | 0.6844 | 0.7015 |
| Half | 0.2564 | 0.1709 | 0.1282 | 0.1282 | 0.1026 | 0.1026 | 0.0855 | 0.0256 | 0.5000 | 1 |
| Many | 0.0565 | 0.1130 | 0.1412 | 0.1412 | 0.1582 | 0.1582 | 0.1695 | 0.0622 | 0.3055 | 0.7454 |
| Most | 0 | 0 | 0.0034 | 0.0034 | 0.0449 | 0.0449 | 0.3292 | 0.5742 | 0.0360 | 0.1821 |
| All | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| Numbeo Database | |||
|---|---|---|---|
| * | 8.78 | M | |
| * | 39.66 | L | |
| 66.13 | H | ||
| * | 29.24 | L | |
| 70.04 | M | ||
| 78.37 | H | ||
| 93.83 | VH | ||
| * | 53.88 | L | |
| Quality of life index | 168.48 | VH | |
| Linguistic Quantifier | Quality of Life Index | |
|---|---|---|
| Tnum | Tlin | |
| At least one | 65.75 | (M, −0.0001) 2 |
| Few | 74.99 | (M, +0.1104) |
| Some | 116.92 | (M, +0.4611) |
| Half | 168.52 1 | (H, −0.2735) |
| Many | 241.42 | (H, −0.0452) |
| Most | 126.29 | (H, +0.2843) |
| All | −110.13 | L 3 |
| R | Country | Quality of Life Index | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Numbeo | At Least One | Few | Some | Half | Many | Most | All | ||
| 1 | Switzerland | 195.27 | 67.66 | 82.09 | 138.06 | 195.34 | 259.33 | −38.74 | −381.065 |
| 2 | Denmark | 192.36 | 73.55 | 86.42 | 137.72 | 192.41 | 258.43 | 48.68 | −228.068 |
| 3 | Netherlands | 185.38 | 72.11 | 83.95 | 132.31 | 185.44 | 252.14 | 71.64 | −195.074 |
| 4 | Finland | 184.96 | 68.99 | 82.63 | 134.12 | 185.00 | 240.60 | 38.69 | −185.48 |
| 5 | Australia | 183.81 | 71.91 | 83.20 | 130.33 | 183.87 | 254.85 | 77.19 | −203.225 |
| 6 | Iceland | 182.26 | 75.19 | 87.54 | 134.84 | 182.30 | 233.81 | 1.78 | −269.954 |
| 7 | Germany | 180.27 | 65.17 | 76.93 | 125.68 | 180.32 | 251.08 | 90.29 | −155.762 |
| 8 | Austria | 179.16 | 58.07 | 71.66 | 124.53 | 179.21 | 243.47 | 67.57 | −177.06 |
| 9 | New Zealand | 176.81 | 68.95 | 79.94 | 125.51 | 176.86 | 244.79 | 85.09 | −190.628 |
| 10 | Norway | 176.39 | 68.64 | 80.74 | 127.87 | 176.44 | 231.53 | −9.25 | −293.51 |
| 1 | Switzerland | VH | (M, −0.0002) | (M, +0.1625) | (H, −0.3566) | (H, −0.0597) | (H, +0.0281) | (L, +0.3223) | VH |
| 2 | Denmark | VH | L | (H, +0.0153) | (H, +0.075) | (H, +0.1369) | (H, +0.2033) | (M, +0.2257) | H |
| 3 | Netherlands | VH | L | (H, +0.0038) | (H, +0.0188) | (H, +0.0343) | (H, +0.0451) | (M, +0.1808) | H |
| 4 | Finland | VH | (L, −0.0001) | (H, +0.0329) | (H, +0.0923) | (H, +0.0598) | (H, −0.1187) | (M, +0.0966) | M |
| 5 | Australia | VH | L | (H, −0.0159) | (H, −0.0645) | (H, −0.0939) | (H, −0.0961) | (M, +0.1774) | H |
| 6 | Iceland | VH | (L, −0.0001) | (H, +0.0449) | (H, +0.1382) | (H, +0.1197) | (H, −0.0906) | (L, +0.2359) | VH |
| 7 | Germany | VH | (M, −0.0001) | (M, +0.12) | (H, −0.4939) | (H, −0.1965) | (H, +0.0508) | (H, −0.245) | M |
| 8 | Austria | VH | (M, −0.0001) | (M, +0.1206) | (M, +0.492) | (H, −0.2564) | (H, −0.1357) | (M, +0.3843) | M |
| 9 | New Zealand | VH | (M, −0.0001) | (M, +0.0869) | (M, +0.3554) | (H, −0.4529) | (H, −0.3108) | (M, +0.1325) | H |
| 10 | Norway | VH | (M, −0.0002) | (M, +0.1592) | (H, −0.3857) | (H, −0.1367) | (H, −0.1471) | (L, +0.2359) | VH |
| R | Country | Quality of Life Index | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Numbeo | At Least One | Few | Some | Half | Many | Most | All | ||
| 76 | Indonesia | 90.36 | 14.49 | 19.40 | 47.99 | 90.39 | 158.17 | 122.05 | −39.82 |
| 77 | Vietnam | 89.95 | 19.87 | 22.57 | 46.85 | 89.99 | 163.68 | 123.32 | −46.17 |
| 78 | Egypt | 89.87 | 53.02 | 50.55 | 58.36 | 89.90 | 159.22 | 164.06 | −15.13 |
| 79 | Philippines | 83.74 | −15.61 | −7.62 | 31.80 | 83.77 | 160.90 | 121.78 | −44.53 |
| 80 | Peru | 80.42 | 24.12 | 24.33 | 41.10 | 80.47 | 159.20 | 167.14 | −26.87 |
| 81 | Venezuela | 77.43 | 44.01 | 41.70 | 48.56 | 77.47 | 143.22 | 140.90 | −68.48 |
| 82 | Sri Lanka | 67.88 | −79.29 | −62.99 | 0.82 | 67.91 | 152.14 | 121.84 | −22.03 |
| 83 | Bangladesh | 67.59 | 47.17 | 42.58 | 42.89 | 67.62 | 129.66 | 128.91 | −29.21 |
| 84 | Iran | 64.89 | −28.72 | −21.35 | 15.57 | 64.92 | 139.29 | 112.96 | −45.82 |
| 85 | Nigeria | 52.44 | 37.14 | 31.93 | 29.96 | 52.47 | 111.76 | 119.50 | −18.91 |
| 76 | Indonesia | VL | (VH, −0.0001) | (VL, +0.1664) | (L, −0.2684) | (L, +0.2222) | (M, −0.2315) | (H, +0.4293) | VL |
| 77 | Vietnam | VL | VH | (VL, +0.1519) | (L, −0.3027) | (L, +0.2051) | (M, −0.2203) | (H, +0.3912) | VL |
| 78 | Egypt | VL | (M, +0.0001) | (M, −0.1085) | (M, −0.3803) | (M, −0.453) | (M, −0.2202) | (VH, −0.2864) | VL |
| 79 | Philippines | VL | (VH, −0.0001) | (VL, +0.1664) | (L, −0.2684) | (L, +0.2222) | (M, −0.2315) | (H, +0.4293) | VL |
| 80 | Peru | VL | VH | (VL, +0.1004) | (VL, +0.4886) | (L, −0.094) | (M, −0.4744) | (VH, −0.2898) | VL |
| 81 | Venezuela | VL | (VH, −0.0001) | (VL, +0.1491) | (L, −0.3508) | (L, +0.0769) | (M, −0.4406) | (H, +0.0945) | L |
| 82 | Sri Lanka | VL | (VH, −0.0001) | (VL, +0.1391) | (L, −0.3929) | (L, +0.0085) | (L, +0.4578) | (H, +0.0967) | VL |
| 83 | Bangladesh | VL | (H, +0.0001) | (L, −0.0412) | (L, −0.112) | (L, −0.0513) | (L, +0.2714) | (H, +0.3776) | VL |
| 84 | Iran | VL | (VH, −0.0001) | (VL, +0.1549) | (L, −0.3246) | (L, +0.1196) | (M, −0.3897) | (H, +0.3844) | VL |
| 85 | Nigeria | VL | (H, +0.0001) | (L, −0.0412) | (L, −0.112) | (L, −0.0513) | (L, +0.2714) | (H, +0.3776) | VL |
| R | Country | RGDP | Quality of Life Index | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Numbeo | At Least One | Few | Some | Half | Many | Most | All | |||
| 15 | United States | 1 | 170.72 | 84.54 | 91.56 | 125.86 | 170.77 | 235.98 | 72.49 | −173.51 |
| 66 | China | 2 | 105.07 | −13.28 | −3.60 | 43.61 | 105.11 | 194.63 | 129.67 | −62.90 |
| 16 | Japan | 3 | 169.48 | 57.01 | 67.85 | 114.74 | 169.53 | 242.05 | 66.82 | −200.42 |
| 7 | Germany | 4 | 180.27 | 65.17 | 76.93 | 125.68 | 180.32 | 251.08 | 90.29 | −155.76 |
| 22 | United Kingdom | 5 | 161.74 | 65.43 | 73.65 | 112.39 | 161.79 | 233.13 | 85.99 | −171.64 |
| 59 | India | 6 | 110.99 | 60.35 | 60.43 | 75.5838 | 111.02 | 178.76 | 149.23 | 4.72 |
| 26 | France | 7 | 156.65 | 61.22 | 69.13 | 107.22 | 156.71 | 229.38 | 78.32 | −189.11 |
| 36 | Italy | 8 | 141.07 | 66.40 | 70.91 | 98.66 | 141.12 | 209.46 | 91.35 | −159.23 |
| 23 | Canada | 9 | 160.38 | 70.66 | 79.35 | 116.86 | 160.43 | 216.83 | 42.83 | −173.86 |
| 45 | South Korea | 10 | 125.04 | −14.67 | −0.66 | 58.35 | 125.09 | 210.35 | 52.22 | −185.56 |
| 69 | Russia | 11 | 103.28 | 42.11 | 45.26 | 67.44 | 103.32 | 161.58 | 100.99 | −37.51 |
| 64 | Brazil | 12 | 107.04 | 36.57 | 40.77 | 66.64 | 107.07 | 177.15 | 165.19 | −29.64 |
| 5 | Australia | 13 | 183.81 | 71.91 | 83.20 | 130.33 | 183.87 | 254.85 | 77.19 | −203.23 |
| 18 | Spain | 14 | 168.48 | 65.75 | 74.99 | 116.92 | 168.52 | 241.42 | 126.29 | −110.13 |
| 46 | Mexico | 15 | 124.9 | 66.09 | 68.08 | 87.92 | 124.94 | 191.92 | 148.31 | −37.87 |
| 15 | United States | 1 | VH | (VL, +0.0001) | (VH, −0.1359) | (H, +0.4294) | (H, +0.1026) | (H, −0.1469) | (M, +0.4224) | M |
| 66 | China | 2 | L | VH | (VL, +0.173) | (L, −0.2015) | (L, +0.3847) | (M, +0.0339) | (H, −0.0932) | L |
| 16 | Japan | 3 | VH | (M, −0.0001) | (M, +0.1099) | (M, +0.4678) | (H, −0.2477) | (H, +0.0056) | (M, +0.2223) | H |
| 7 | Germany | 4 | VH | (M, −0.0001) | (M, +0.12) | (H, −0.4939) | (H, −0.1965) | (H, +0.0508) | (H, −0.245) | M |
| 22 | United Kingdom | 5 | VH | M | (M, +0.0579) | (M, +0.2781) | (H, −0.4956) | (H, −0.2034) | (H, −0.2484) | M |
| 59 | India | 6 | L | (M, +0.0001) | (M, −0.0507) | (M, −0.1644) | (M, −0.1624) | (M, +0.0397) | (H, +0.4742) | VL |
| 26 | France | 7 | H | M | (M, +0.0363) | (M, +0.1836) | (M, +0.3506) | (H, −0.4068) | (M, +0.1774) | H |
| 36 | Italy | 8 | M | M | (M, +0.0464) | (M, +0.2219) | (M, +0.4018) | (H, −0.3616) | (H, −0.2933) | M |
| 23 | Canada | 9 | VH | L | (H, −0.0292) | (H, −0.1357) | (H, −0.2393) | (H, −0.3729) | (M, +0.0932) | M |
| 45 | South Korea | 10 | M | (VH, −0.0001) | (VL, +0.2346) | (L, +0.0332) | (M, −0.2904) | (M, +0.3389) | (M, −0.1518) | H |
| 69 | Russia | 11 | L | H | (L, +0.0527) | (L, +0.2414) | (L, +0.4187) | (M, −0.3615) | (H, +0.0586) | VL |
| 64 | Brazil | 12 | L | (VH, −0.0002) | (VL, +0.1852) | (L, −0.222) | (L, +0.2478) | (M, −0.2484) | (VH, −0.2898) | VL |
| 5 | Australia | 13 | VH | L | (H, −0.0159) | (H, −0.0645) | (H, −0.0939) | (H, −0.0961) | (M, +0.1774) | H |
| 18 | Spain | 14 | VH | (M, −0.0001) | (M, +0.1104) | (M, +0.4611) | (H, −0.2735) | (H, −0.0452) | (H, +0.2843) | L |
| 46 | Mexico | 15 | M | M | (M, +0.0075) | (M, +0.0486) | (M, +0.1196) | (M, +0.3052) | (VH, −0.2381) | VL |
| R | Numbeo | At Least One | Few | Some | Half | Many | Most | All | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tnum | Tlin | Tnum | Tlin | Tnum | Tlin | Tnum | Tlin | Tnum | Tlin | Tnum | Tlin | Tnum | Tlin | Tnum | Tlin | |
| 1 | CH | CH | SA | OM | US | OM | CH | OM | CH | OM | CH | DK | TR | BG | PK | NG |
| 2 | DK | DK | ZAF | US | SA | US | DK | DK | DK | DK | DK | OM | TN | BA | IN | PE |
| 3 | NL | NL | US | PR | OM | UAE | ISL | ISL | NL | ISL | AU | DE | CO | MX | CO | SL |
| 4 | FI | FI | PR | ZAF | UAE | SA | FI | US | FI | US | NL | NL | KE | EC | TN | ID |
| 5 | AU | AU | UAE | UAE | ZAF | ZAF | NL | FI | AU | FI | DE | EE | PE | TR | TR | MY |
| 6 | ISL | ISL | OM | SA | ISL | PR | AU | NL | ISL | NL | NZ | CH | AR | CO | KZ | BD |
| 7 | DE | DE | QA | ISL | DK | ISL | OM | UAE | DE | UAE | LUX | JP | BR | KE | EG | IR |
| 8 | AT | AT | ISL | FI | PR | FI | NO | CH | AT | CH | AT | ES | EG | AR | AZ | PK |
| 9 | NZ | NZ | CYP | DK | NL | DK | SE | EE | NZ | EE | JP | LUX | AZ | SRB | GE | UA |
| 10 | NO | NO | IE | NL | AU | NL | US | AU | NO | AU | ES | ISL | PK | GE | NG | VN |
| R | Numbeo | At Least One | Few | Some | Half | Many | Most | All | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tnum | Tlin | Tnum | Tlin | Tnum | Tlin | Tnum | Tlin | Tnum | Tlin | Tnum | Tlin | Tnum | Tlin | Tnum | Tlin | |
| 76 | ID | ID | VN | KE | VN | CO | ID | BR | ID | BR | PH | ID | IL | IL | IE | IE |
| 77 | VN | VN | TH | CL | TH | KR | VN | CO | VN | ID | EG | PH | DK | QA | JP | JP |
| 78 | EG | EG | ID | TH | ID | CHN | CHN | KR | EG | PH | PE | BR | CA | FI | AU | AU |
| 79 | PH | PH | KE | CO | KE | ID | KR | ID | PH | VN | ID | RUS | KW | CA | LUZ | LUX |
| 80 | PE | PE | AR | AZ | AR | PH | BD | PH | PE | IR | SL | IR | FI | IE | SG | SG |
| 81 | VE | VE | CHN | SRB | KR | IR | PE | VN | VE | VE | KZ | VE | QA | KR | DK | IL |
| 82 | SL | SL | KR | KR | CHN | VN | PH | IR | SL | SL | VE | PE | SG | SG | IL | DK |
| 83 | BD | BD | PH | PR | PH | VE | NG | VE | BD | BD | IR | SL | ISL | CH | ISL | ISL |
| 84 | IR | IR | IR | VN | IR | SL | IR | SL | IR | NG | BD | BD | NO | ISL | NO | NO |
| 85 | NG | NG | SL | CHN | SL | PE | SL | PE | NG | PE | NG | NG | CH | NO | CH | CH |
| R | Country | RGDP | At Least One | Few | Some | Half | Many | Most | All | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tnum | Tlin | Tnum | Tlin | Tnum | Tlin | Tnum | Tlin | Tnum | Tlin | Tnum | Tlin | Tnum | Tlin | |||
| 15 | US | 1 | US | US | US | US | AU | US | AU | US | AU | DE | BR | MX | IN | IN |
| 66 | CHN | 2 | AU | AU | AU | AU | US | AU | DE | AU | DE | JP | IN | BR | BR | BR |
| 16 | JP | 3 | CA | CA | CA | CA | DE | CA | US | DE | JP | ES | MX | IN | RUS | RUS |
| 7 | DE | 4 | IT | DE | DE | DE | ES | DE | JP | CA | ES | AU | CHN | ES | MX | MX |
| 22 | UK | 5 | MX | ES | ES | ES | CA | JP | ES | JP | US | US | ES | RUS | CHN | CHN |
| 59 | IN | 6 | ES | JP | UK | JP | JP | ES | UK | ES | UK | UK | RUS | CHN | ES | ES |
| 26 | FR | 7 | UK | UK | IT | UK | UK | UK | CA | UK | FR | IT | IT | DE | DE | DE |
| 36 | IT | 8 | DE | IT | FR | IT | FR | IT | FR | IT | CA | CA | DE | UK | IT | UK |
| 23 | CA | 9 | FR | FR | MX | FR | IT | FR | IT | FR | KR | FR | UK | IT | UK | IT |
| 45 | KR | 10 | IN | MX | JP | MX | MX | MX | KR | MX | IT | KR | FR | US | US | US |
| 69 | RUS | 11 | JP | IN | IN | IN | IN | IN | MX | IN | CHN | MX | AU | JP | CA | CA |
| 64 | BR | 12 | RUS | RUS | RUS | RUS | RUS | RUS | IN | KR | MX | IN | US | AU | KR | AU |
| 5 | AU | 13 | BR | BR | BR | KR | BR | KR | BR | RUS | IN | CHN | JP | FR | FR | FR |
| 18 | ES | 14 | CHN | KR | KR | BR | KR | CHN | CHN | CHN | BR | BR | KR | CA | JP | JP |
| 46 | MX | 15 | KR | CHN | CHN | CHN | CHN | BR | RUS | BR | RUS | RUS | CA | KR | AU | KR |
| 15.29 | 10.94 | 3.48 | 0 | 4 | 36.24 | 37.08 | ||
| 14.68 | 11.88 | 5.07 | 0.78 | 6.18 | 38.26 | 43.89 |
| GDP per Capita ($) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Numerical value | GDP per capita ($) | Pearson correlation coefficient (PCC) | 1 | 0.696 ** | 0.359 ** | 0.460 ** | 0.703 ** | 0.696 ** | 0.680 ** | −0.780 ** | −0.813 ** |
| Sig. (2-tailed) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| QOLINumbeo | Pearson correlation coefficient (PCC) | 0.696 ** | 1 | 0.624 ** | 0.752 ** | 0.977 ** | 1.000 ** | 0.970 ** | −0.621 ** | −0.735 ** | |
| Sig. (2-tailed) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| 2-tuple value | GDP per capita ($) | Pearson correlation coefficient (PCC) | 1 | 0.673 ** | 0.374 ** | 0.406 ** | 0.713 ** | 0.662 ** | 0.623 ** | −0.802 ** | −0.808 ** |
| Sig. (2-tailed) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| QOLINumbeo | Pearson correlation coefficient (PCC) | 0.673 ** | 1 | 0.587 ** | 0.632 ** | 0.934 ** | 0.907 ** | 0.794 ** | −0.611 ** | −0.666 ** | |
| Sig. (2-tailed) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| GDP per Capita ($) | QOLINumbeo | QOLIAt Least One | QOLIFew | QOLISome | QOLIHalf | QOLIMany | QOLIMost | QOLIAll | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Numerical value | GDP per capita ($) | Pearson correlation coefficient (PCC) | 1 | 0.754 ** | 0.508 ** | 0.613 ** | 0.747 ** | 0.754 ** | 0.732 ** | −0.762 ** | −0.784 ** |
| Sig. (2-tailed) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| QOLINumbeo | Pearson correlation coefficient (PCC) | 0.754 ** | 1 | 0.690 ** | 0.832 ** | 0.978 ** | 1.000 ** | 0.974 ** | −0.619 ** | −0.758 ** | |
| Sig. (2-tailed) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| 2-tuple value | GDP per capita ($) | Pearson correlation coefficient (PCC) | 1 | 0.754 ** | 0.559 ** | 0.567 ** | 0.753 ** | 0.751 ** | 0.695 ** | −0.763 ** | −0.714 ** |
| Sig. (2-tailed) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| QOLINumbeo | Pearson correlation coefficient (PCC) | 0.754 ** | 1 | 0.778 ** | 0.794 ** | 0.939 ** | 0.967 ** | 0.841 ** | −0.605 ** | −0.603 ** | |
| Sig. (2-tailed) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shu, Z.; Carrasco, R.A.; García-Miguel, J.P.; Sánchez-Montañés, M. Multiple Scenarios of Quality of Life Index Using Fuzzy Linguistic Quantifiers: The Case of 85 Countries in Numbeo. Mathematics 2022, 10, 2091. https://doi.org/10.3390/math10122091
Shu Z, Carrasco RA, García-Miguel JP, Sánchez-Montañés M. Multiple Scenarios of Quality of Life Index Using Fuzzy Linguistic Quantifiers: The Case of 85 Countries in Numbeo. Mathematics. 2022; 10(12):2091. https://doi.org/10.3390/math10122091
Chicago/Turabian StyleShu, Ziwei, Ramón Alberto Carrasco, Javier Portela García-Miguel, and Manuel Sánchez-Montañés. 2022. "Multiple Scenarios of Quality of Life Index Using Fuzzy Linguistic Quantifiers: The Case of 85 Countries in Numbeo" Mathematics 10, no. 12: 2091. https://doi.org/10.3390/math10122091