1. Introduction
In real scenarios, since data typically originates from various sources or consists of different features, a large amount of multi-view data emerges. For example, an object can be described by audio, images, video, and text; news can also be written in different languages [
1]. Since the majority of the data is unlabeled, multi-view clustering, which combines the latent information from multiple views and separates the data into different categories [
2,
3], has become a significant application [
4,
5,
6].
Graph-oriented learning is an efficient approach for modeling heterogeneous relationships and complex structures hidden in data and therefore has been widely adopted in multi-view clustering [
7,
8,
9]. Among them, multi-view clustering based on the adaptive neighbor technique [
10], which conducts local manifold structure learning and clustering simultaneously, has been widely utilized with superior performance. The method in [
11] learns an optimized graph for each view by assigning adaptive neighbors and then integrates these graphs into a global graph in a well-designed way. To allocate each data sample to the most appropriate cluster and guarantee consistency across views, the method in [
12] proposes to make all views share the same similarity matrix. The method in [
13,
14] learns a similarity graph for each view, and an automated weighting strategy is then adopted to combine the different views efficiently into a unified one. Since all samples in separate views have the same cluster structure, the method in [
15] exploits the shared information derived from the links between the different views to obtain a better consensus clustering result. Instead of constructing a similarity graph in the original feature space, the method in [
16] learns the critical graph in a spectral embedding space to eliminate the disturbance of noise and redundant information. In addition, the adaptive neighbor technique has been effectively applied to the field of incomplete multi-view clustering [
17]. At the same time, there are methods designed to solve the clustering task [
18,
19].
Although these methods have demonstrated excellent performance, they typically work on Euclidean space and ignore the manifold topological structure, which is crucial for clustering data in the manifold. In this paper, we explicitly explore the manifold topological structure across multiple adaptive graphs by learning a consensus graph. We further manipulate the consensus graph with a useful rank constraint so that its connected components precisely correspond to distinct clusters. As a result, our model is able to directly achieve the discrete clustering result without any post-processing. Our model seamlessly accomplishes three subtasks: It constructs an adaptive graph for each view, integrates the multiple adaptive graphs into a consensus graph with the manifold topological structure considered, and allocates the discrete cluster label for each sample. By leveraging the interactions between these three subtasks in a unified framework, each subtask is iteratively boosted in a mutual reinforcement manner. An iterative updating algorithm is introduced to solve the optimization problem. Experiments on several real-world datasets demonstrate the effectiveness of the proposed model, compared to the state-of-the-art competitors, in terms of four widely used clustering evaluation metrics.
The main contributions of this work are summarized as follows:
The proposed multi-view graph clustering method, for the first time to the best of our knowledge, explores the topological manifold structure from multiple adaptive graphs such that the topological relevance across multiple views can be explicitly detected.
Essentially as an end-to-end single-stage learning paradigm, our model seamlessly achieves three subtasks: It constructs the adaptive graphs for each view, explores the topological manifold structure across multiple graphs, and allocates the discrete cluster label for each sample.
An iterative updating algorithm is carefully designed to solve the optimization problem. Experiments on several benchmark datasets demonstrate the effectiveness of the proposed model.
The remainder of this paper is as follows: In
Section 2, we introduce the preliminary work.
Section 3 describes the model in detail proposed in this paper.
Section 4 introduces the solution and optimization algorithm of the model.
Section 5 verifies the validity of the model proposed in this paper through experiments. We conclude the paper in
Section 6.
Notations. Throughout this paper, a boldface uppercase letter, e.g., , denotes a matrix. and represent the i-th column and the -th element of , respectively. denotes the Frobenius norm, and is a column vector with all its elements being 1. represents the identity matrix with proper size.
2. Preliminary Work
Previous works have proven that real-world data are usually sampled from a nonlinear low-dimensional manifold that is embedded in high-dimensional ambient space [
20,
21,
22]. Thus, it is beneficial to reveal the manifold structure implied within the data to boost the corresponding learning performance.
To accurately measure the intrinsic similarity relationships of crowds, the authors in [
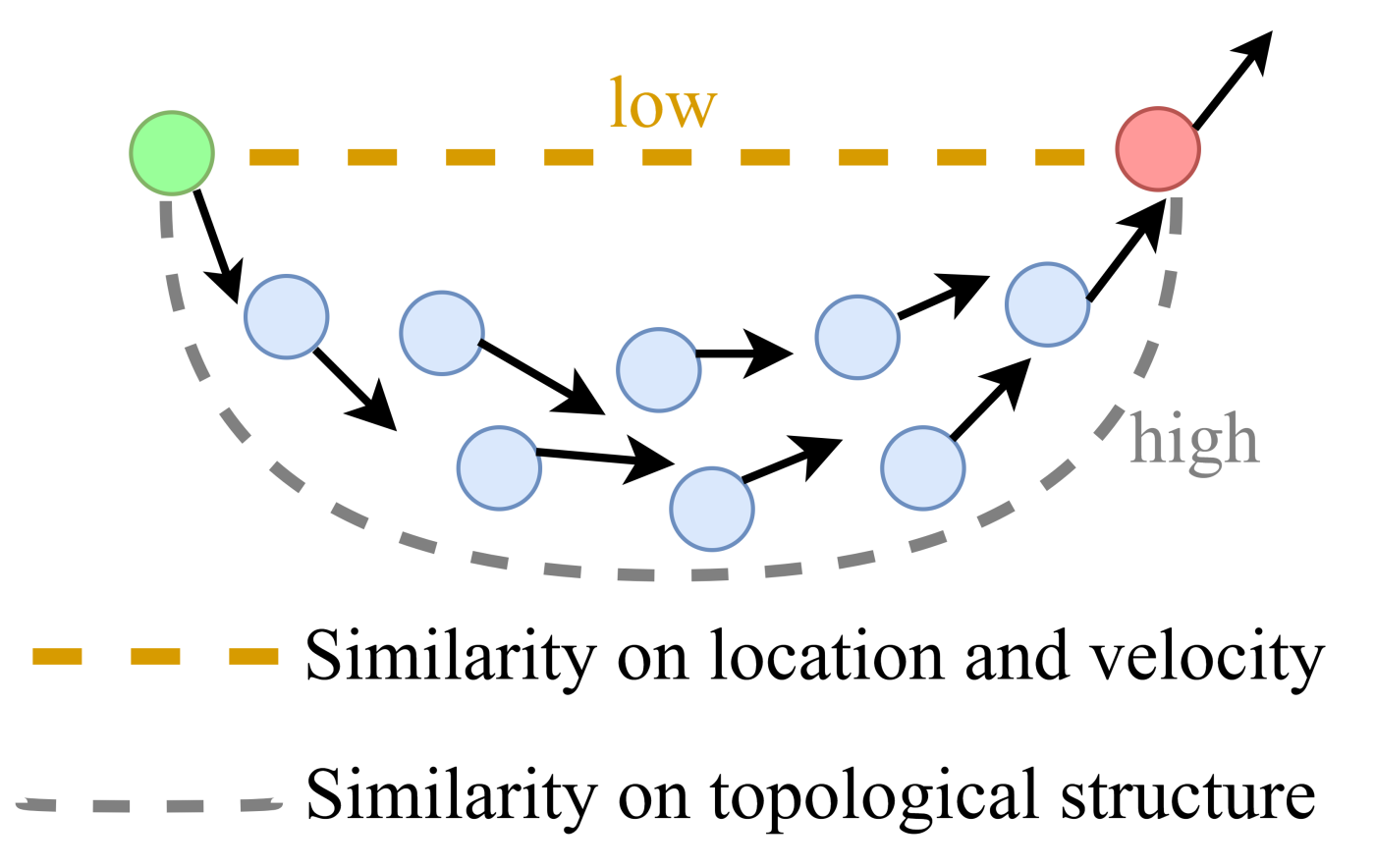
23] explored the topological relationship between individuals by using a propagation-based manifold learning method. It aims to uncover the topological relevance such that the manifold topological structure can be explicitly considered. There is a simple and intuitive assumption for this consideration: the topological connectivities between distinct individuals could be propagated from near to far. In other words, the spatial similarity between two individuals may be low, but their topological relevance to each other would be high if they are linked by consecutive neighbors. Instead of only making use of the Euclidean structure, it is expected that a more suitable manifold topological structure will be adopted to carry out intrinsic similarity learning.
Figure 1 visualizes the manifold topological structure learning procedure. As we can see, though the green and red samples have low similarity in terms of spatial location and velocity, they are closely connected to each other considering the high topological relevance between them. That is to say, if two samples maintain a high consistency, their topological relevance to any other sample should be similar.
Suppose a predefined similarity graph
that depicts the intrinsic similarity relationships of data
with
n samples and
d features. Based on the assumption that data samples with large similarity share similar topological relevance to any other sample, the authors in [
23] extract the topological relationship of data samples by solving the following problem:
where
is a balance parameter,
is the target topological relationship matrix, and
denotes the data sample
j’s topological relevance to
i. The first term in Equation (1) is a smoothness constraint that guarantees that the data samples
j and
k share a similar topological relationship with sample
i if
j and
k are similar. The second term is a fitting constraint that avoids the trivial solution. Based on Equation (1), the topological consistency is propagated through neighbors with high similarities, and the distant data samples will maintain a close relationship if they are linked by consecutive neighbors. Finally, we can search the topological relationship matrix
by solving the problem defined in Equation (1).
Note that the similarity graph
involved in Equation (1) is a fixed graph that might not be optimal for subsequent learning. More often, it is expected a similarity graph will be automatically learned from the original data. To do so, the method described in [
10] was proposed to automatically learn a similarity graph for clustering tasks by assigning the adaptive and optimal neighbors for each data sample based on the local connectivity. It is based on a natural assumption that the data samples with a smaller distance should have a larger probability of being neighbors. Instead of a predefined similarity graph, an adaptive graph can be automatically learned by solving the problem as follows:
where
is a trade-off parameter and can be determined according to the number of adaptive neighbors [
10].
Let
be a multi-view dataset with
m views and
features for the
v-th view. Equation (2) is easily extended to a multi-view formulation as
where
denotes the adaptive graph learned from the
v-th view.
3. The Proposed Model
Note that the formulation in Equation (1) has several drawbacks. First, if a data sample is connected with many similar neighbors, it will largely affect the objective value. Hence, it is required that a normalized version of Equation (1) be designed, such that each sample is treated equally. That is to say, a data sample with too many connections would dominate the objective function. The normalization has two main purposes: (1) it ensures that each sample is treated equally; (2) it is equivalent to a sparse constraint, i.e., a
-norm on a similarity graph. Second, the learned
does not contain the explicit cluster structures, so a subsequent postprocessing step is needed to output the final discrete clustering results. It is preferred that the similarity graph and cluster structure are learned simultaneously. It sounds unrealistic to achieve such a pure structured graph. Fortunately, we can tackle this problem with a useful rank constraint. Taking the above concerns into consideration, Equation (1) can be upgraded to
where
is the degree matrix of
,
is the Laplacian matrix of
, and
is a rank constraint that guarantees that
contains exactly
c connected components (
c is the cluster number of data). The rank constraint has been successfully used to achieve a clear cluster structure [
10,
24]. Note that, unlike Equation (1), here we constrain the sum of each row of
to be one, and all elements of
are nonnegative. Finally, a structured target graph
that reveals the topological relevance can be acquired by solving Equation (4).
In this paper, we extract the topological relevance from multiple adaptive graphs such that the manifold topological structure can be explicitly detected for the clustering task. Combining Equation (4) and Equation (3), our new multi-view graph clustering model can be formulated as
where
denotes the weight of the
v-th view and can be determined by an inverse distance weighting strategy, i.e.,
Note that Equation (6) is essentially a kind of auto-weighted strategy, which has been widely utilized in previous works [
7,
25,
26]. To further verify the effect of an auto-weighting strategy, we will conduct an ablation study in a later section.
Note that, if we denote
as the
i-th smallest eigenvalue of
, the rank constraint
would be satisfied if
since
is a positive semidefinite matrix. According to Ky Fan’s Theorem [
27] that
, we can incorporate the rank constraint term into the objective function, and finally we arrive at
where
is a self-adjusted parameter, and
denotes the cluster indicator matrix. When
is large enough, the optimal solution
for Equation (7) will enforce the last term
, i.e.,
, to be zero. Thus, the constraint
in Equation (7) could be satisfied. Moreover, according to [
26],
can be tuned in a heuristic way: initialize
to a positive value (e.g.,
) and we then automatically halve (i.e.,
) or double (i.e.,
) it when its number of connected components is greater or smaller than the cluster number
c in each iteration. In this way, the target graph
will be modified until it contains precisely
c connected components.
5. Experiments
To verify the efficiency of our proposed method, we compare it with the following state-of-the-art methods: self-weighted multi-view clustering (
SwMC) [
7], multi-view learning with adaptive neighbours (
MLAN) [
12], multi-view clustering via adaptively weighted procrustes (
AWP) [
32], weighted multi-view spectral clustering (
WMSC) [
33], multi-view consensus graph clustering (
MCGC) [
15], consistent and specific multi-view subspace clustering (
CSMSC) [
34], graph-based multi-view clustering (
GMC) [
14], consensus one-step multi-view subspace clustering (
COMSC) [
35], and multi-view clustering via consensus graph learning (
CGL) [
16].
We conduct the experiments on several prevalent datasets, namely, 3Sources, MSRC, BBCSport, COIL-20, Caltech-7, and Caltech-20. The detailed information of all datasets is as follows:
3Sources (
http://mlg.ucd.ie/datasets/3sources.html (accessed on 26 April 2022)) is collected from three news sources, i.e., Reuters, BBC, and The Guardian. There are 948 news articles covering 416 different news stories. Among them, 169 news stories were reported in all three sources, and each story was annotated with one of six topical labels: business, health, politics, entertainment, sport, and technology.
MSRC is comprised of 240 images in eight classes. We selected seven classes with each class containing 30 images. For each image, five visual features are extracted for a comprehensive description.
BBCSport is a sports news dataset that consists of 544 articles in 5 areas with 2 views. The 2 views are 3183 dimension MTX features and 3203 dimension TERMS features, respectively.
COIL-20 is a subset of an object database (
http://www.cs.columbia.edu/CAVE/software/softlib/coil-100.php (accessed on 26 April 2022)) that includes 100 categories. Images of each object were taken five degrees apart as the object was rotated on a turntable, and each object has 72 gray images. Each image is described by three types of features.
Caltech101 is an object recognition dataset with 101 categories. This dataset is represented by 6 types of features. Following [
12], we selected 1474 images within 7 classes (
Caltech-7) and 2386 images within 20 classes (
Caltech-20).
The specific characteristics of the datasets are given in
Table 2.
The parameters for comparison algorithms were set according to the recommendations in their corresponding paper. The parameter settings of our model will be introduced later. All algorithms were repeated 10 times, and the average results are presented.
To achieve a comprehensive evaluation, four widely used metrics (clustering accuracy (ACC), normalized mutual information (NMI), purity, and F-score) are adopted in this paper.
5.1. Clustering Results
The clustering performance of different methods on all datasets is reported in
Table 3. Note that the best performance is in bold, and the second-best performance is underlined. As we can see, our method outperforms other methods in most cases, which verifies the effectiveness of the proposed model. Specifically, our method outperforms the most competitive competitors by 1.5%, 12.2%, 3.1%, 1.1%, 15.2%, and 24.5%, respectively, on different datasets in terms of ACC. In terms of the F-score, the number becomes 2.8%, 17.3%, 4.9%, 1.0%, 15.0%, and 4.4%, respectively. With other clustering metrics, it can also be observed that the improvement is notable.
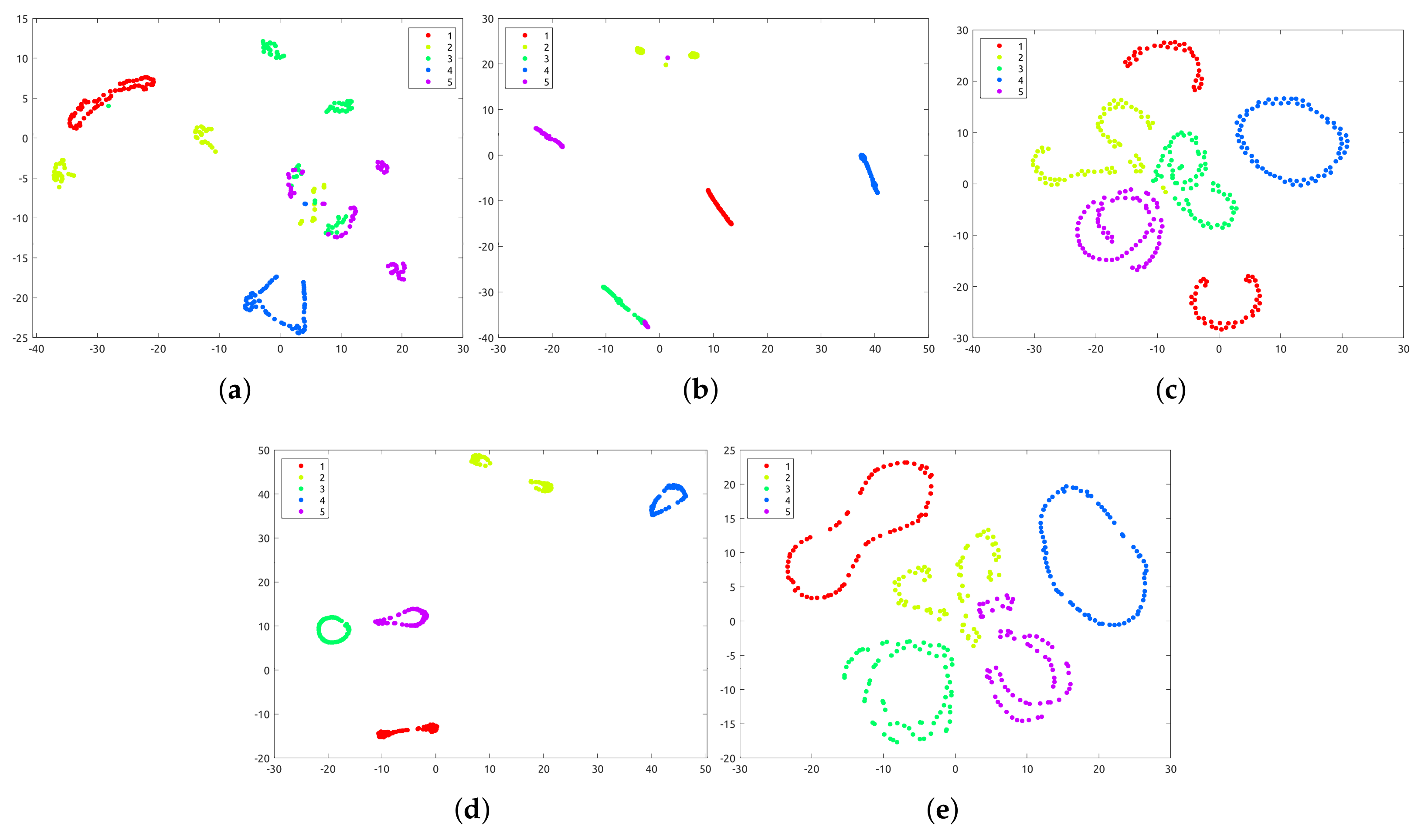
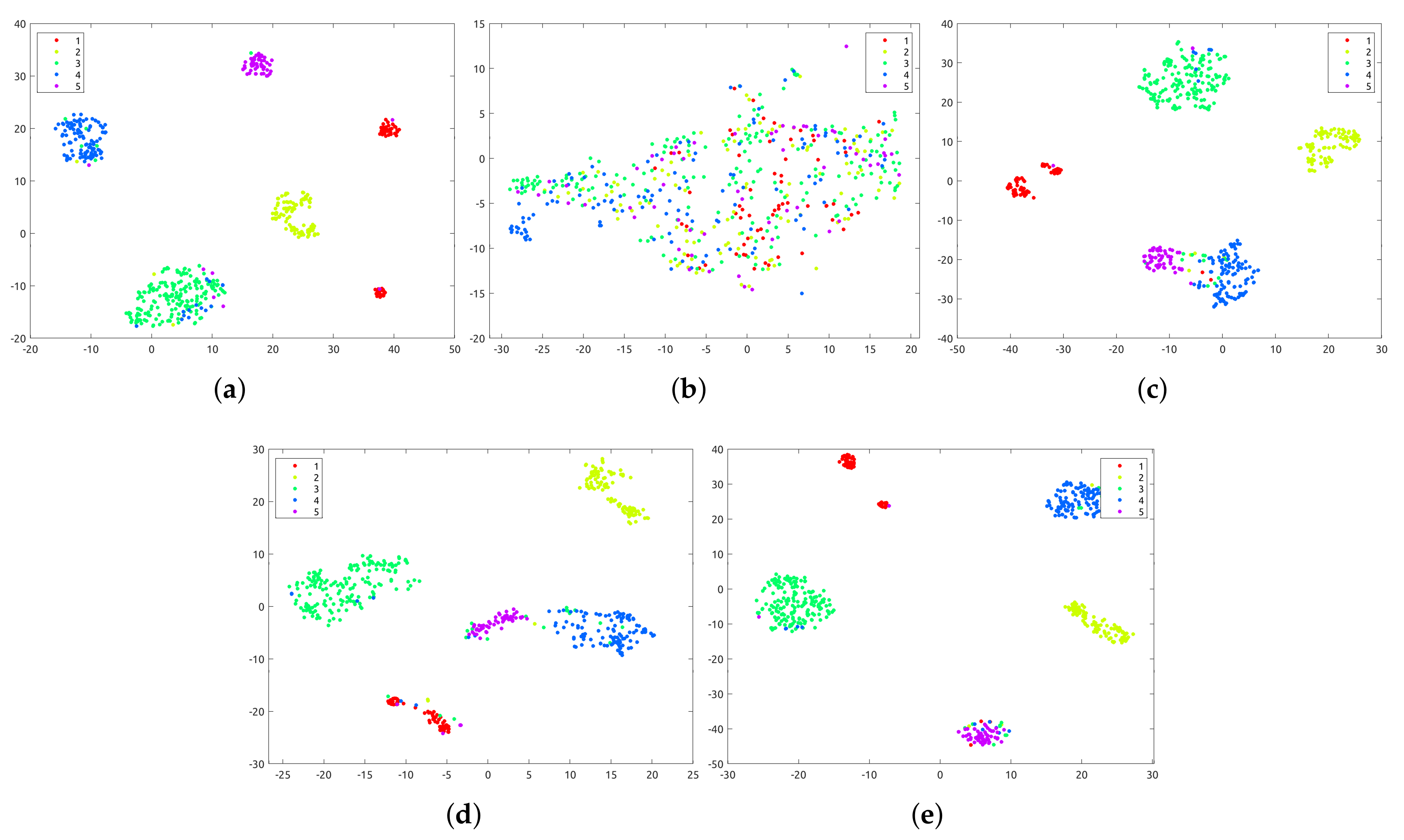
It is worth noting that MLAN, MCGC, GMC, and CGL are all multi-view clustering methods that involve the adaptive graph. From the results, we can say the proposed method that adopts the manifold topological structure has a superior performance, which further illustrates the effectiveness of adaptive manifold learning. Taking the datasets COIL-20 and BBCSport as examples, we carried out the t-SNE [
36] to visualize the clustering results. As shown in
Figure 2 and
Figure 3, our model obviously achieves a much clearer clustering structure with better separability, and the gap between different clusters is evident, which further validates that our model can better uncover the intrinsic structure of the data. Considering that real-world data are usually sampled from a nonlinear low-dimensional manifold, our method is able to achieve a promising clustering performance in the general case.
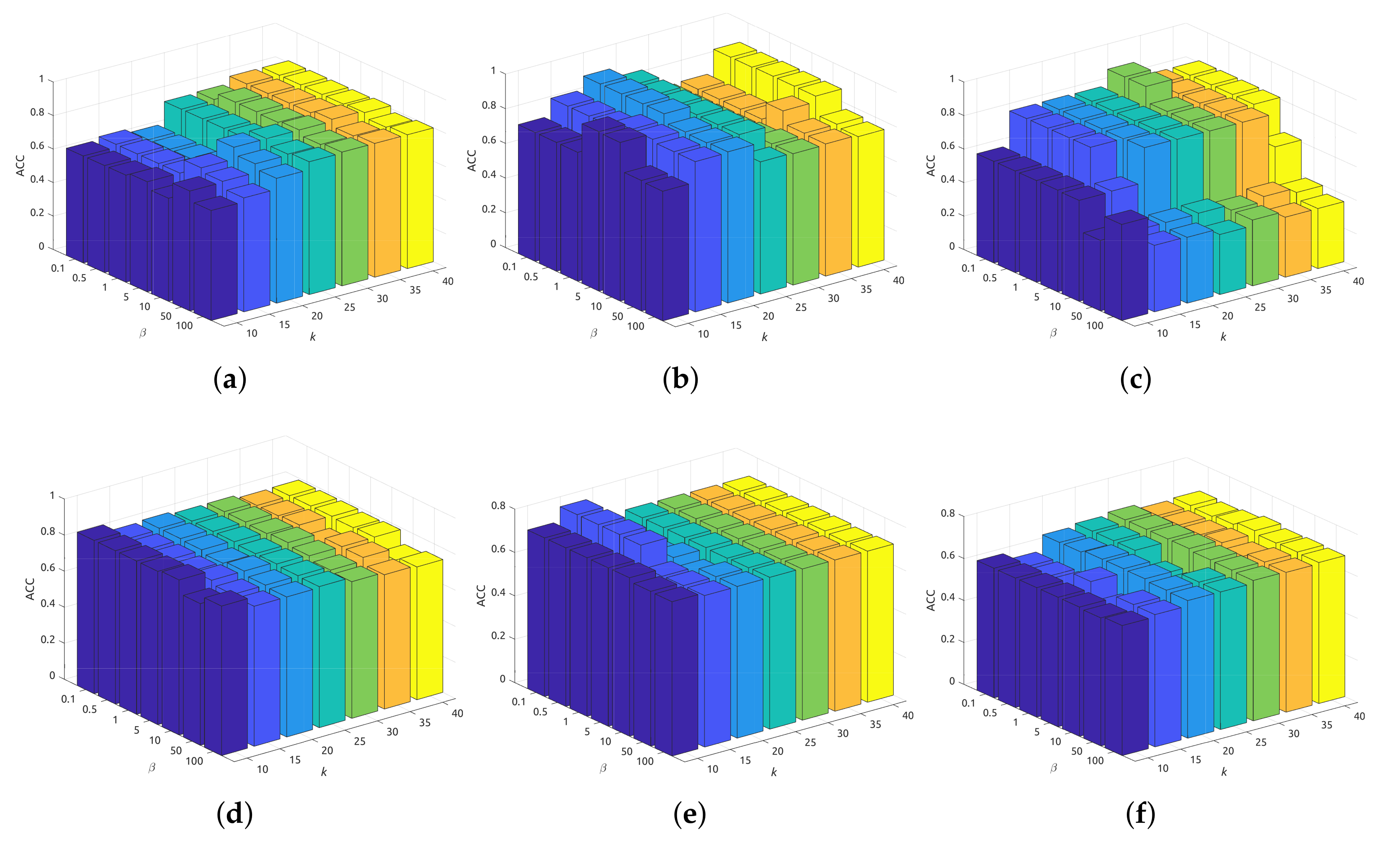
5.2. Sensitivity Analysis
We showcase the sensitivity of the proposed model with respect to different parameter settings. As described before,
is a self-adjusted parameter and can be tuned in a heuristic way. Thus, we only need to search the parameters
and
properly. As mentioned in Equation (2),
can be determined according to the number of adaptive neighbors [
10]. In this paper, we empirically search the adaptive neighbors
k in the range [10,15,20,25,30,35,40] and
in the range [0.1,0.5,1,5,10,50,100]. The clustering results of all datasets are plotted in
Figure 4. It is obvious that our performance is relatively stable under a wide range of parameter settings, which pinpoints the robustness of our model. Generally speaking, we can expect a promising clustering performance when
varies from 0.5 to 10, and
k from 15 to 30, respectively.
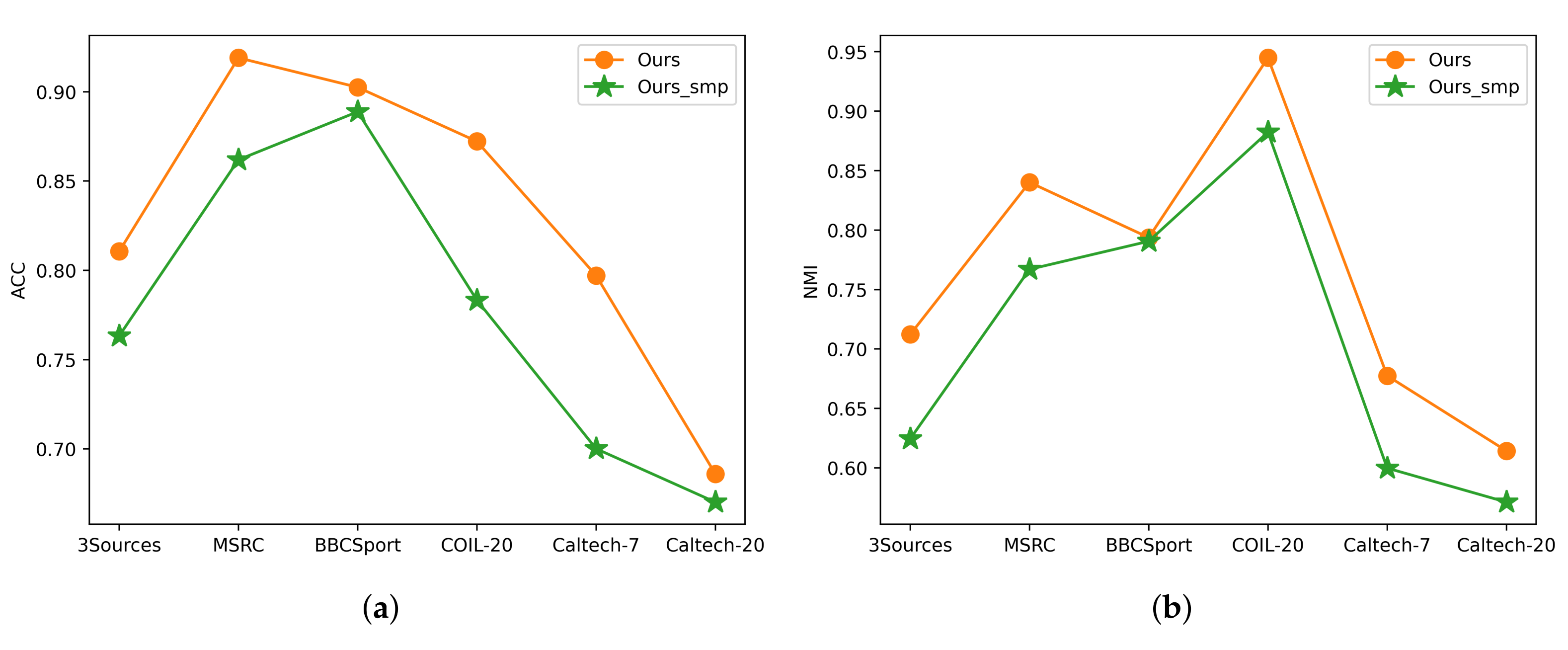
5.3. Ablation Study
In order to verify the importance of the auto-weight learning strategy in Equation (6), we tested a special case where all views are of the same importance to the clustering task, i.e.,
, denoted as the simple version of our model. As shown in
Figure 5, we report the clustering performance of two evaluation indexes (ACC and NMI) on six datasets, respectively. We can see that the experimental results of the auto-weight learning strategy (as described in Equation (6) are superior to those obtained by the simple average weighting strategy. Moreover, it can be seen that the overall improvement is remarkable, which obviously showcases the effectiveness of our auto-weight learning strategy.
5.4. Computational Performance
Given the computational complexity of our algorithm theoretical analyzed above, here, we empirically compare the computational speed of our method with other multi-view graph clustering approaches. The computational time of all algorithms on a machine with 2.60 GHz Intel Xeon Gold 6240 CPU and 256 GB RAM is shown in
Table 4. We see that COMSC and SwMC are the two timesaving-most algorithms, especially COMSC, which is slower than other methods by nearly two orders of magnitude. Generally speaking, our algorithm is faster than COMSC and SwMC and in line with other methods, which validates the efficiency of the proposed algorithm.
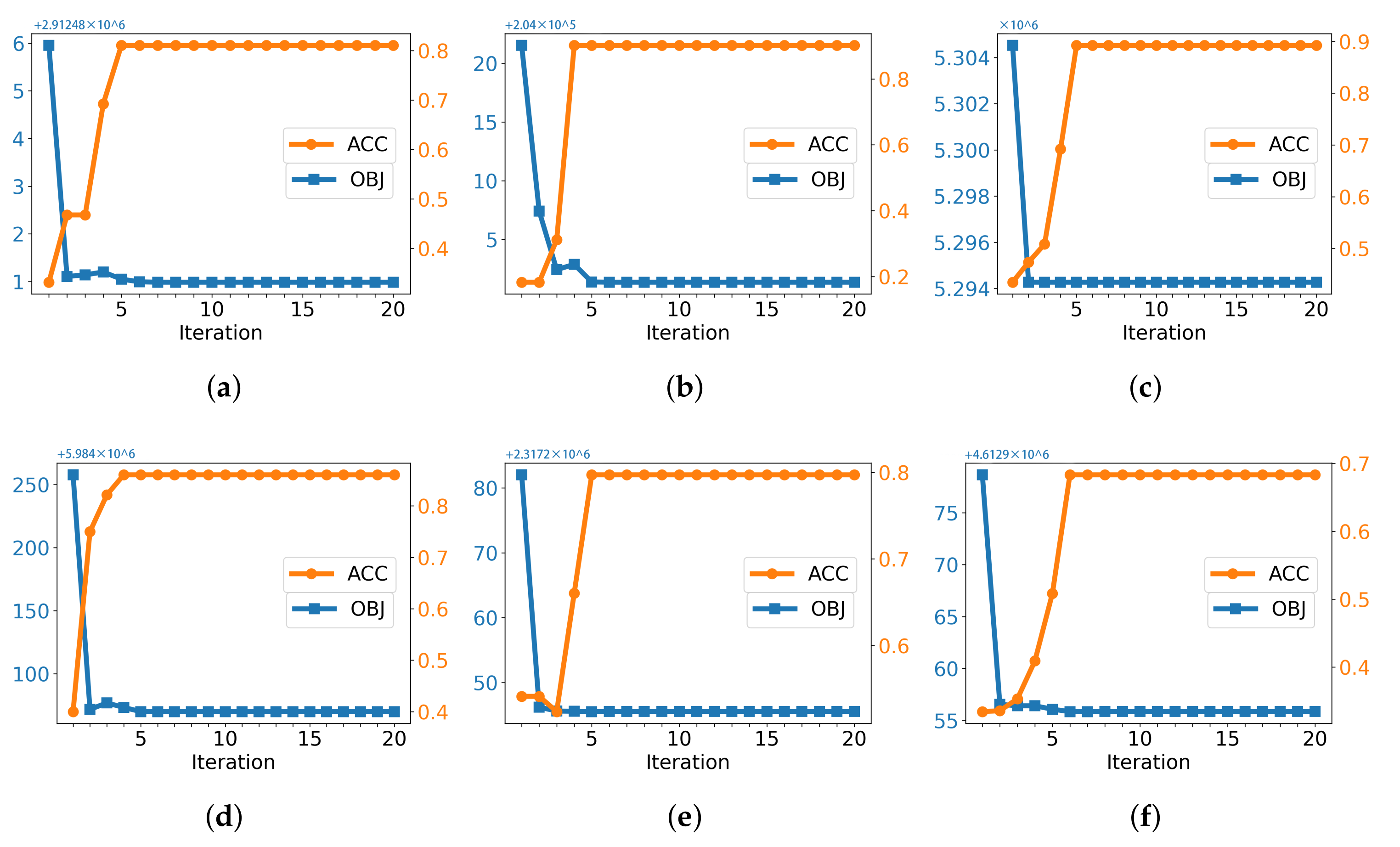
5.5. Convergence Study
The convergence property of our algorithm was theoretically analyzed previously. Here, we empirically validate the convergence speed of the proposed algorithm. The convergence curves along with the clustering results of our algorithm are shown in
Figure 6, where the orange line represents the ACC of the proposed model, and the blue line denotes the value of the objective function. We can observe that the iterative updating algorithm converges very fast, which implies the efficiency of our algorithm.
6. Conclusions
In this paper, we explore the implied adaptive manifold for multi-view graph clustering. Our model seamlessly integrates multiple adaptive graphs into a consensus graph with the manifold topological structure considered. In addition, we manipulate the consensus graph with a useful rank constraint so that its connected components precisely correspond to distinct clusters. As a result, our model is able to directly achieve the discrete clustering result without any post-processing. An alternating iterative algorithm is introduced to solve the optimization problem. Experiments on several benchmark datasets illustrate the effectiveness of the proposed model, compared to the state-of-the-art algorithms in terms of four clustering evaluation metrics. In detail, the experimental results have shown that (1) our model achieved the best results in the majority of cases, (2) the proposed model is very stable across a wide range of parameter settings, and (3) the designed optimization algorithm is very efficient and converges fast. However, our model cannot deal with nonlinear data, which can be considered in future work. Furthermore, we are also interested in extending the proposed framework to other machine learning applications, such as medical data analysis and genetic data analysis.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}