

Assessing the Relevance of Information Sources for Modelling Student Performance in a Higher Mathematics Education Course
 , and
, and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Statistical Learning Models
2.1.1. Gaussian Process Regression
2.1.2. Partial Least Squares
2.1.3. LASSO
2.1.4. Ridge Regression
2.2. Data-Set Harmonisation
2.2.1. Moodle Log-File Data
2.2.2. Socio-Economic Data
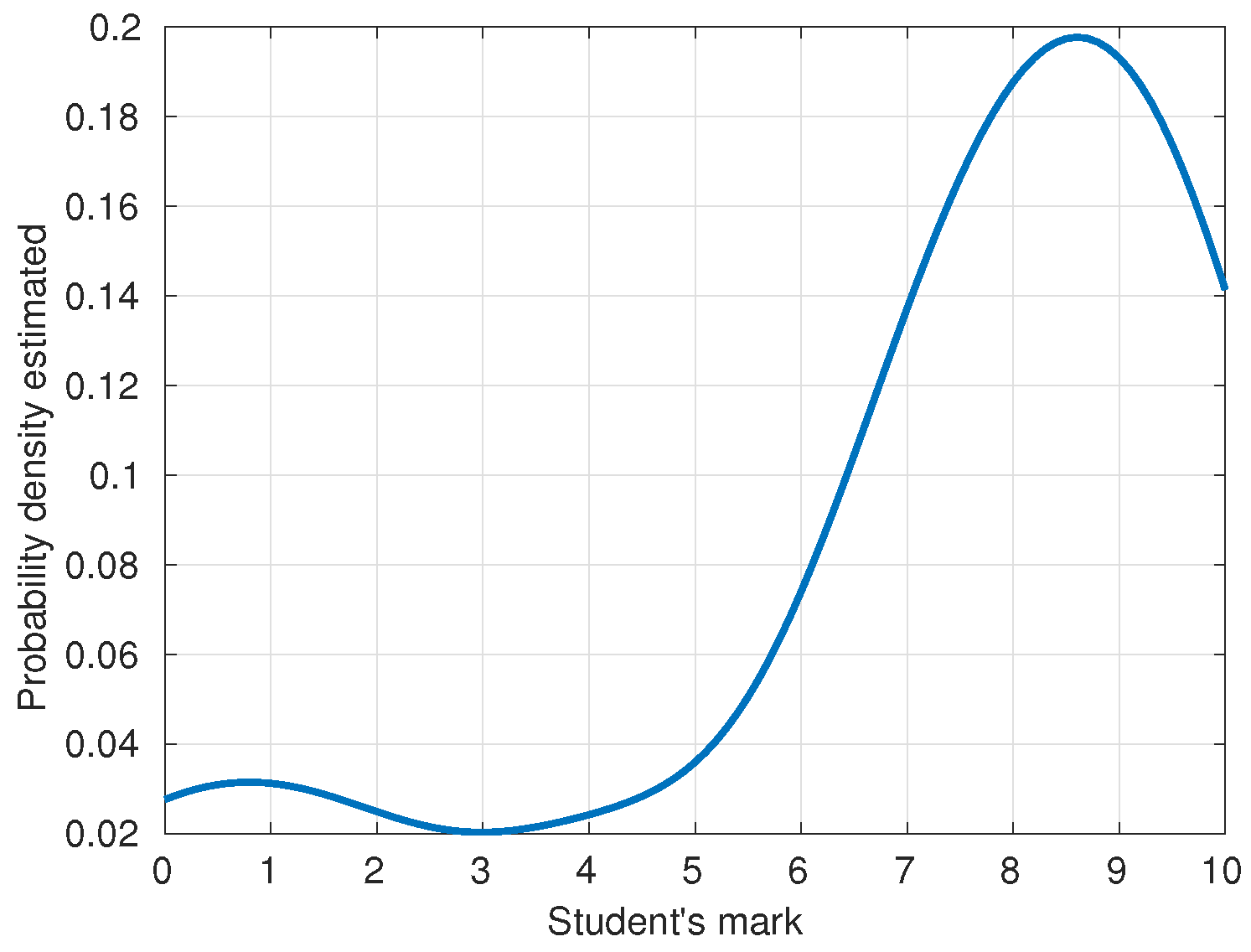
2.2.3. Course Marks
3. Experiments and Results
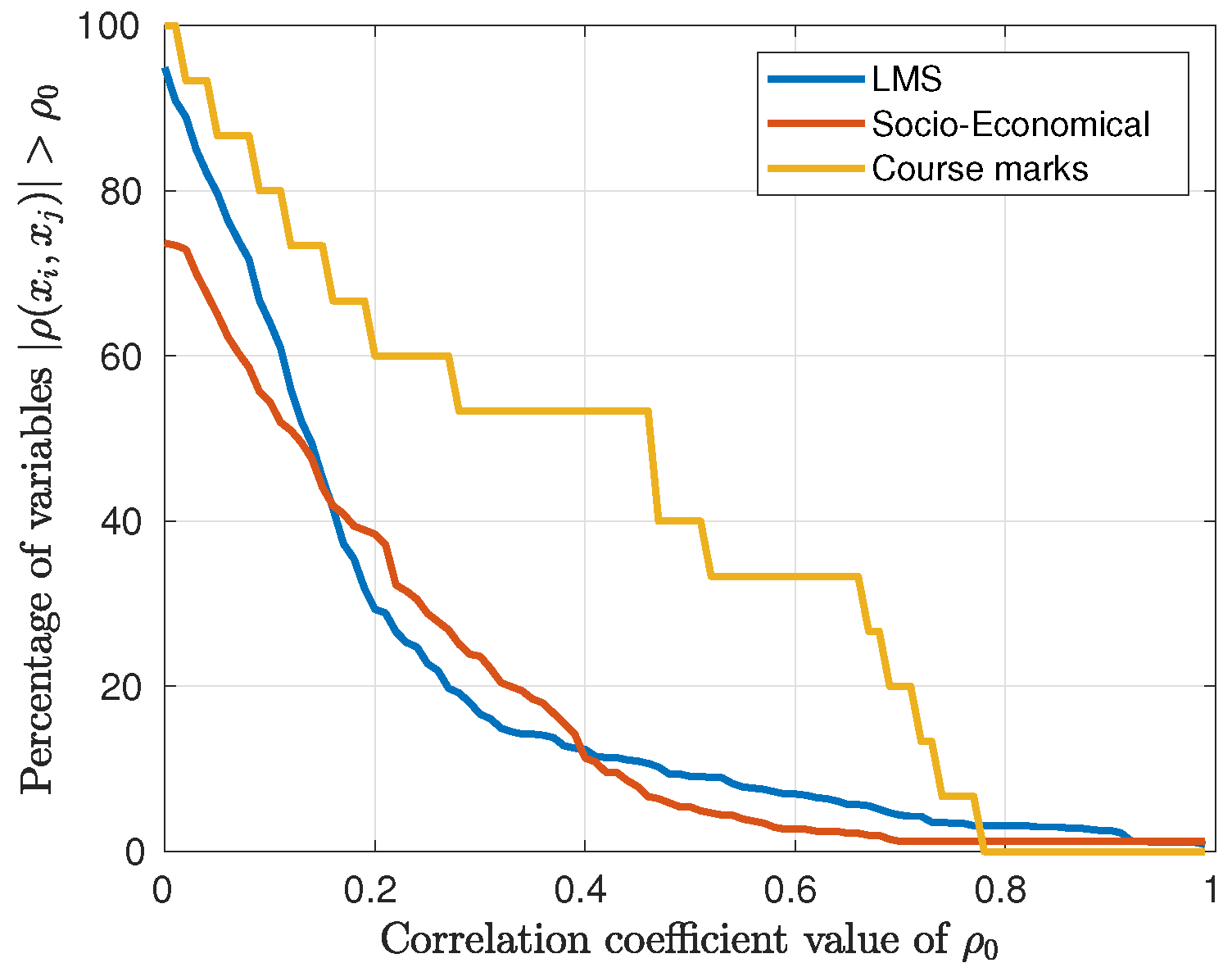
3.1. Correlation Analysis
3.1.1. Correlation between Input Variables
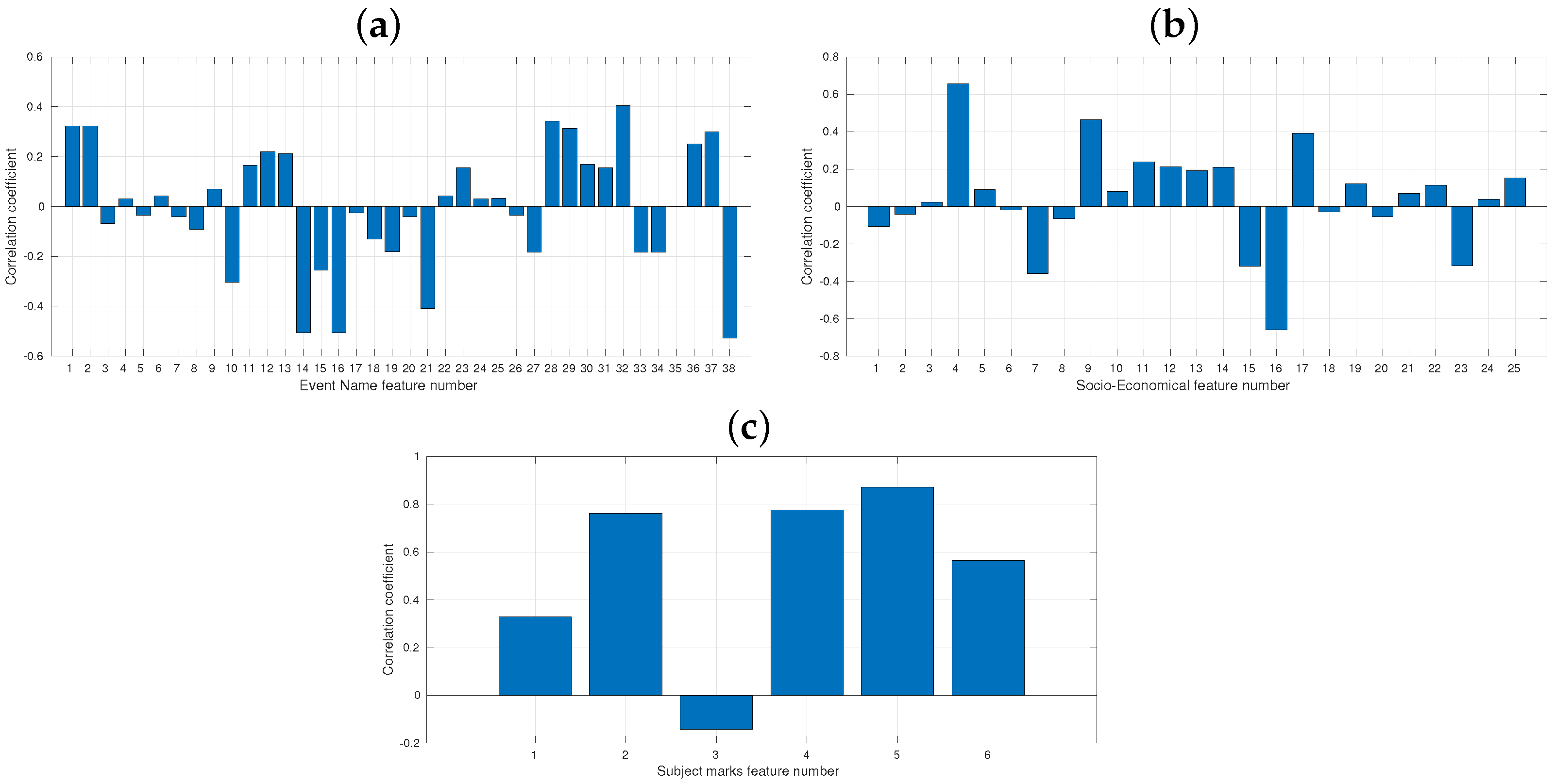
3.1.2. Correlation between Inputs and Output Variable
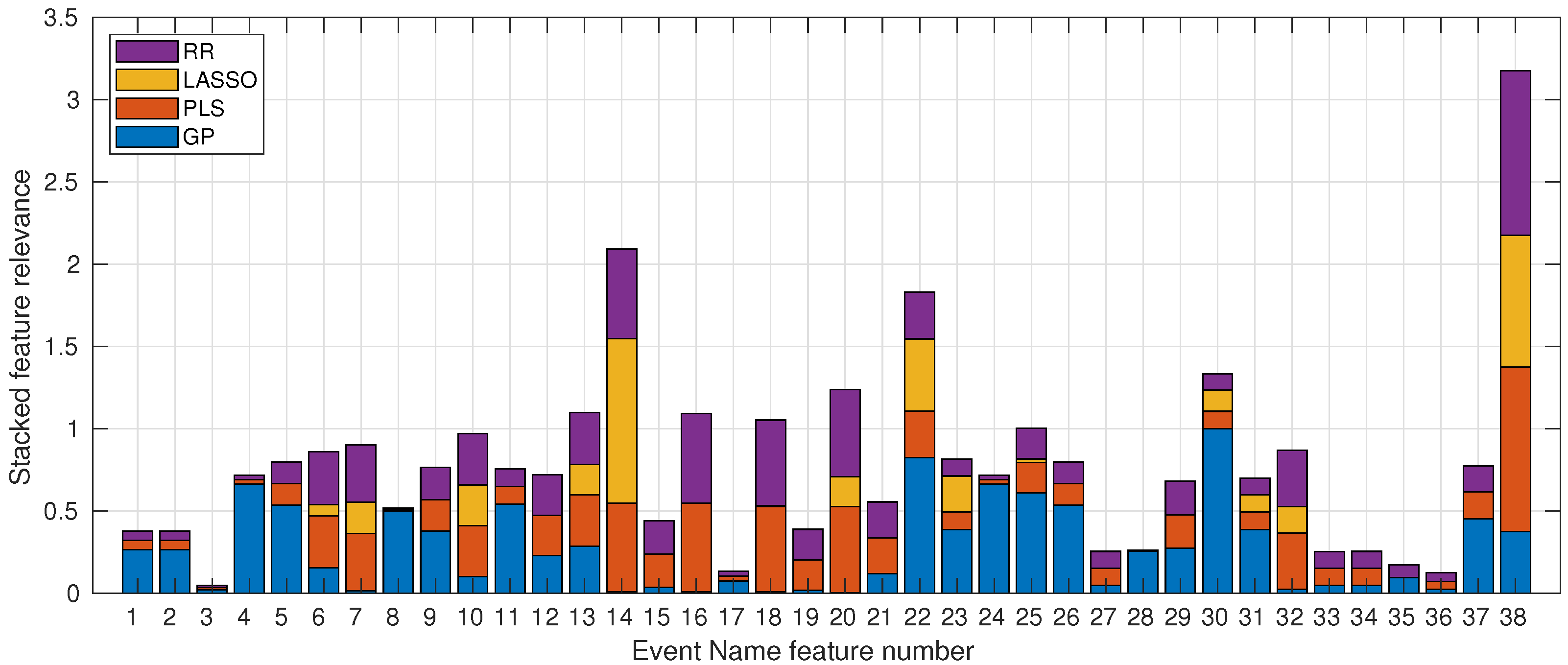
3.2. Feature Ranking Analysis
3.2.1. Moodle LMS
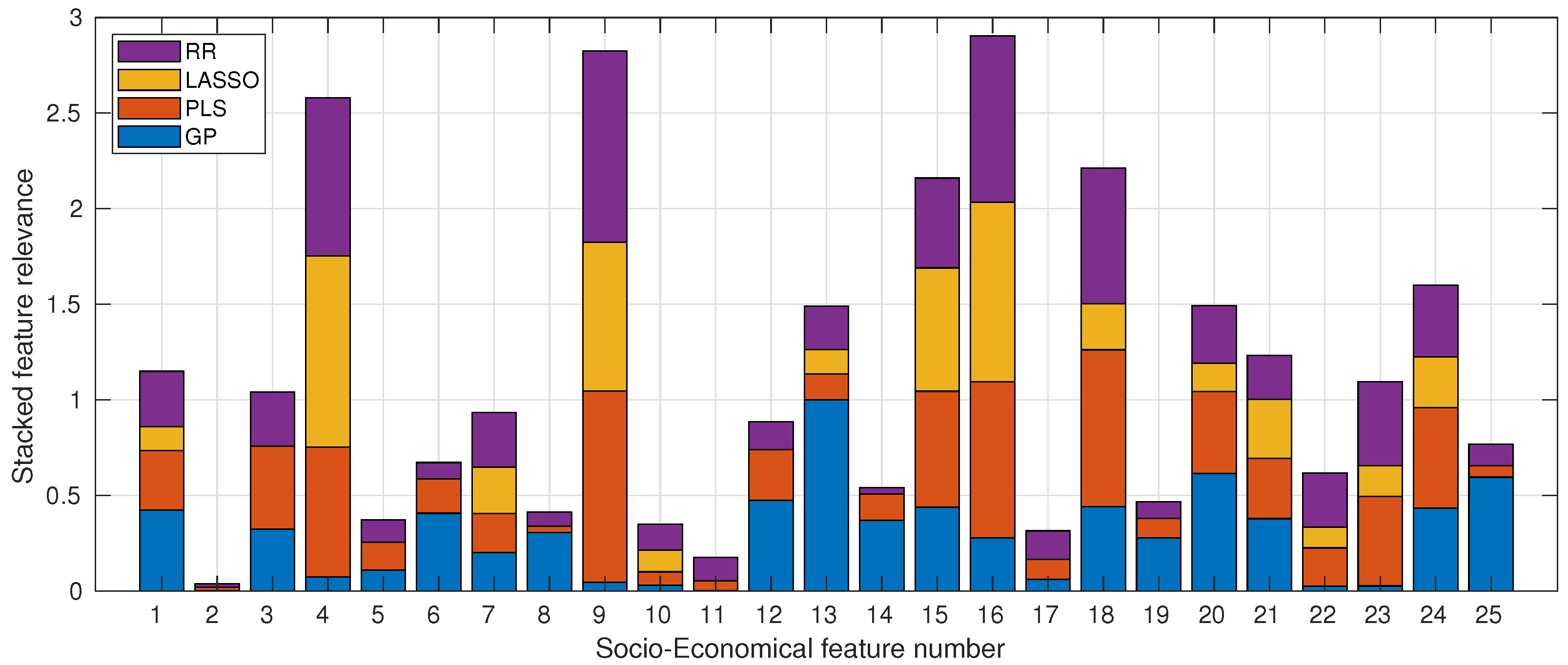
3.2.2. Socio-Economic Data
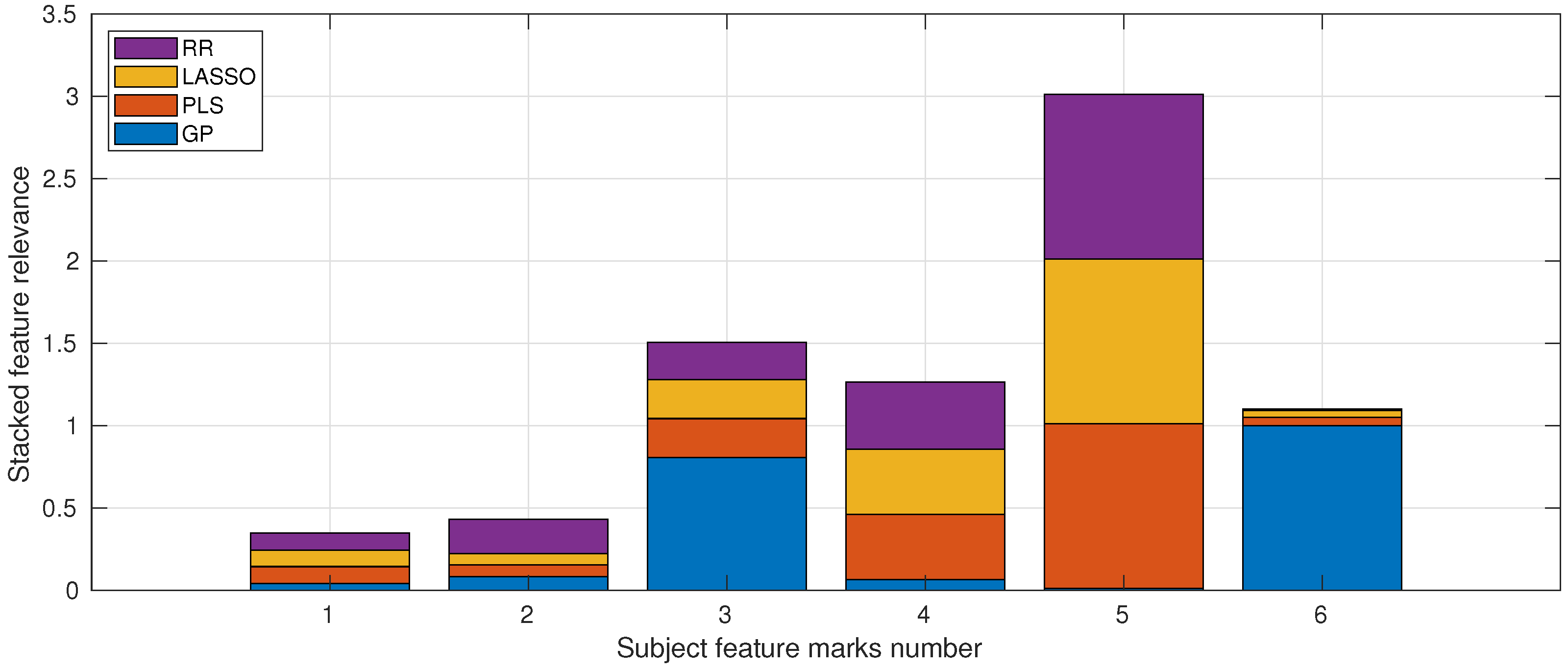
3.2.3. Subject’s Marks
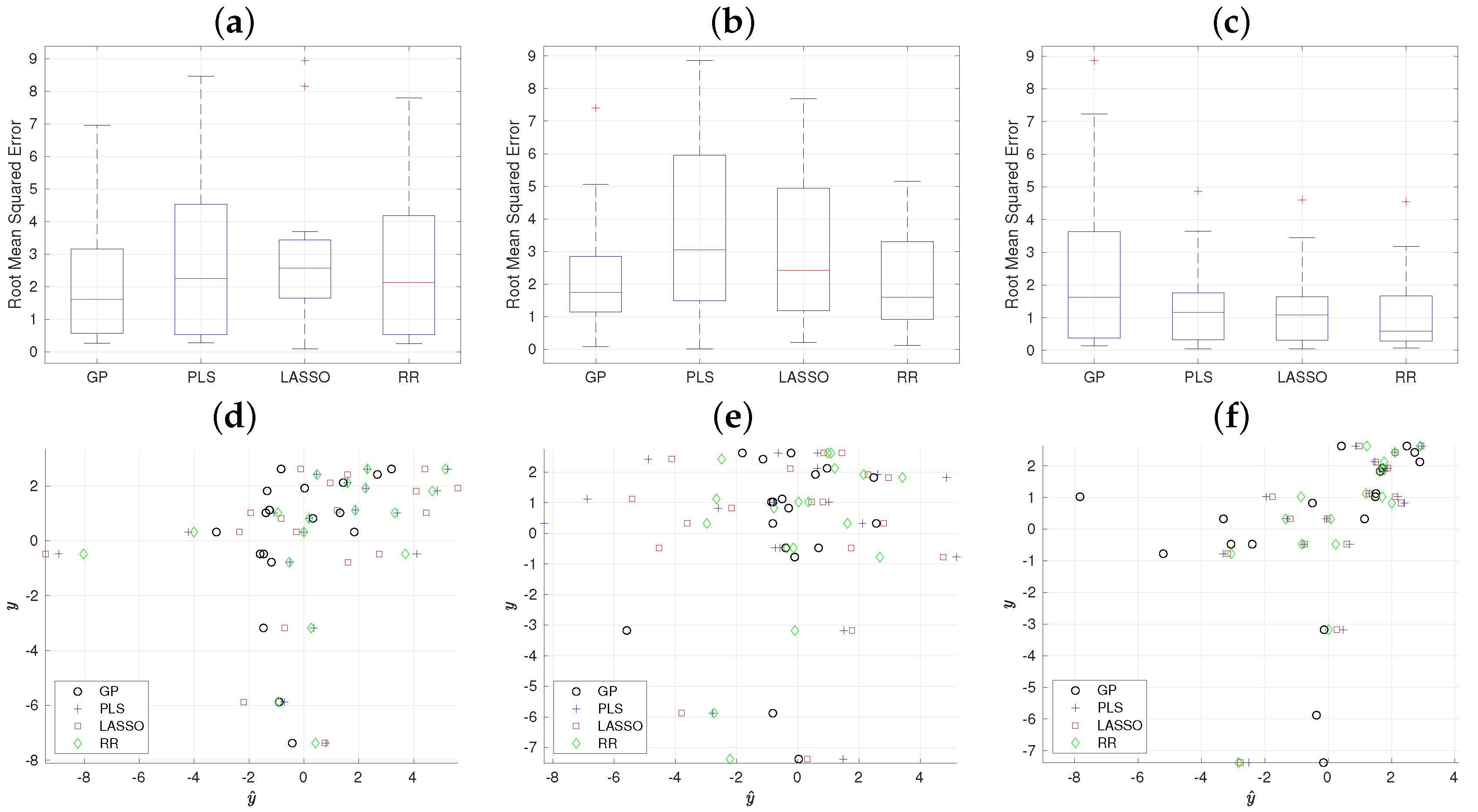
3.3. Student Performance Analysis
4. Conclusions and Future Work
4.1. Conclusions from the Presented Study
4.2. Limitations and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- González, H.B.; Kuenzi, J.J. Science, Technology, Engineering, and Mathematics (STEM) Education: A Primer; Technical Report; Congressional Research Service: Washington, DC, USA, 2012. [Google Scholar]
- Vo, H.M.; Zhu, C.; Diep, N.A. The effect of blended learning on student performance at course-level in higher education: A meta-analysis. Stud. Educ. Eval. 2017, 53, 17–28. [Google Scholar] [CrossRef]
- Turnbull, D.; Chugh, R.; Luck, J. Learning Management Systems: An Overview. In Encyclopedia of Education and Information Technologies; Tatnall, A., Ed.; Springer International Publishing: Cham, Switzerland, 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Van Vaerenbergh, S.; Pérez-Suay, A. Intelligent Learning Management Systems: Overview and Application in Mathematics Education. In Strategy, Policy, Practice, and Governance for AI in Higher Education Institutions; Almaraz-Menéndez, F., Maz-Machado, A., López-Esteban, C., Almaraz-López, C., Eds.; IGI Global: Hershey, PA, USA, 2022; pp. 206–232. [Google Scholar]
- Bravo-Agapito, J.; Romero, S.J.; Pamplona, S. Early prediction of undergraduate Student’s academic performance in completely online learning: A five-year study. Comput. Hum. Behav. 2021, 115, 106595. [Google Scholar] [CrossRef]
- Pérez-Suay, A.; Van Vaerenbergh, S.; Diago, P.D.; Pascual-Venteo, A.B.; Ferri, F.J. Data-Driven Modelling through the Moodle Learning Management System: An Empirical Study based on a Mathematics Teaching Subject. IEEE Rev. Iberoam. Tecnol. Aprendiz. 2023, 18, 19–27. [Google Scholar] [CrossRef]
- Cortez, P.; Silva, A.M.G. Using Data Mining to Predict Secondary School Student Performance. In Proceedings of the 5th Future Business Technology Conference (FUBUTEC 2008), Porto, Portugal, 9–11 April 2008; Brito, A., Teixeira, J., Eds.; pp. 5–12. [Google Scholar]
- Van Vaerenbergh, S.; Pérez-Suay, A. A Classification of Artificial Intelligence Systems for Mathematics Education. In Mathematics Education in the Age of Artificial Intelligence: How Artificial Intelligence can Serve Mathematical Human Learning; Richard, P.R., Vélez, M.P., Van Vaerenbergh, S., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 89–106. [Google Scholar]
- Maor, D.; Taylor, P.C. Teacher epistemology and scientific inquiry in computerized classroom environments. J. Res. Sci. Teachnol. 1995, 32, 839–854. [Google Scholar] [CrossRef]
- Kim, M.C.; Hannafin, M.J.; Bryan, L.A. Technology-enhanced inquiry tools in science education: An emerging pedagogical framework for classroom practice. Sci. Educ. 2007, 91, 1010–1030. [Google Scholar] [CrossRef]
- Engelbrecht, J.; Harding, A. Teaching Undergraduate Mathematics on the Internet: PART 1: “Technologies and Taxonomy”. Educ. Stud. Math. 2005, 58, 235–252. [Google Scholar] [CrossRef]
- Balacheff, N.; Kaput, J.J. Computer-Based Learning Environments in Mathematics. In International Handbook of Mathematics Education; Bishop, A.J., Keitel, C., Kilpatrick, J., Laborde, C., Eds.; Kluwer Academic Publishers: Dordrect, The Netherlands, 1996; pp. 469–504. [Google Scholar]
- Hollebrands, K.; Anderson, R.; Oliver, K. Online Learning in Mathematics Education; Research in Mathematics Education; Springer International Publishing: Cham, Switzerland, 2021. [Google Scholar]
- Gordon Smith, G.; Ferguson, D. Diagrams and math notation in e-learning: Growing pains of a new generation. Int. J. Math. Educ. Sci. Technol. 2004, 35, 681–695. [Google Scholar] [CrossRef]
- Bitter, G.G.; Hatfield, M.M. Training Elementary Mathematics Teachers Using Interactive Multimedia. Educ. Stud. Math. 1994, 26, 405. [Google Scholar] [CrossRef]
- Xingfeng, H.; Huang, R.; Trouche, L. Teachers’ learning from addressing the challenges of online teaching in a time of pandemic: A case in Shanghai. Educ. Stud. Math. 2022, 112, 103–121. [Google Scholar] [CrossRef]
- Gujarati, D. Multicollinearity: What Happens If the Regressors Are Correlated; Economic Series; McGraw Hill: New York, NY, USA, 2003. [Google Scholar]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer Series in Statistics; Springer: New York, NY, USA, 2001. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning); The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Schölkopf, B.; Smola, A.J.; Bach, F. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Garthwaite, P.H. An Interpretation of Partial Least Squares. J. Am. Stat. Assoc. 1994, 89, 122–127. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics), 1st ed.; Springer: New York, NY, USA, 2007. [Google Scholar]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. (Ser. B) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Bogarín Vega, A.; Romero Morales, C.; Cerezo Menéndez, R. Aplicando minería de datos para descubrir rutas de aprendizaje frecuentes en Moodle. Edmetic 2016, 5, 73–92. [Google Scholar] [CrossRef]
- Pearson, K. Note on regression and inheritance in the case of two parents. Proc. R. Soc. Lond. 1895, 58, 240–242. [Google Scholar]
- Spearman, C. The Proof and Measurement of Association between Two Things. Am. J. Psychol. 1987, 100, 441–471. [Google Scholar] [CrossRef] [PubMed]
- Bunge, M. A General Black Box Theory. Philos. Sci. 1963, 30, 346–358. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning, 2nd ed.; Lulu Press: Morrisville, NC, USA, 2022. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Description | # | Description |
|---|---|---|---|
| 1 | A file has been uploaded | 20 | Quiz attempt submitted |
| 2 | A submission has been submitted | 21 | Quiz attempt summary viewed |
| 3 | Badge listing viewed | 22 | Quiz attempt viewed |
| 4 | Calendar event created | 23 | Remove submission confirmation viewed |
| 5 | Calendar event deleted | 24 | Scheduler booking added |
| 6 | Comment created | 25 | Scheduler booking form viewed |
| 7 | Comment deleted | 26 | Scheduler booking removed |
| 8 | Course module instance list viewed | 27 | Step shown |
| 9 | Course module viewed | 28 | Submission created |
| 10 | Course user report viewed | 29 | Submission form viewed |
| 11 | Course viewed | 30 | Submission updated |
| 12 | Grade overview report viewed | 31 | Status’ submission has been updated |
| 13 | Grade user report viewed | 32 | Status’ submission has been viewed |
| 14 | Group deleted | 33 | Tour ended |
| 15 | Group member added | 34 | Tour started |
| 16 | Group member removed | 35 | User graded |
| 17 | Group updated | 36 | User list viewed |
| 18 | Quiz attempt reviewed | 37 | User profile viewed |
| 19 | Quiz attempt started | 38 | Zip archive of folder downloaded |
| # | Name | Detailed Description |
|---|---|---|
| 1 | gender | student’s gender (male, female, other) |
| 2 | age | student’s age |
| 3 | address | student’s home address type (urban or rural) |
| 4 | famsize | family size |
| 5 | Pstatus | parent’s cohabitation status |
| 6 | Medu | mother’s education |
| 7 | Fedu | father’s education |
| 8 | Mjob | mother’s job |
| 9 | Fjob | father’s job |
| 10 | reason | reason for choosing this university |
| 11 | guardian | student’s guardian |
| 12 | traveltime | home-t0 faculty travel time |
| 13 | studytime | weekly study time |
| 14 | failures | number of past class failures |
| 15 | famsup | family educational support |
| 16 | paid | extra paid classes within the course subject |
| 17 | activities | extra-curricular activities |
| 18 | higher | wants to take higher education (post-grade) |
| 19 | romantic | with a romantic relationship |
| 20 | famrel | quality of family relationships |
| 21 | freetime | free time after school |
| 22 | goout | going out with friends |
| 23 | Walc | weekend alcohol consumption |
| 24 | health | current health status |
| 25 | absences | number of school absences |
| Number | Detailed Description |
|---|---|
| 1 | Classroom works mark |
| 2 | Exam mark |
| 3 | Videos’ mark |
| 4 | Seminars’ mark |
| 5 | Practicals’ marks |
| 6 | Voluntary homework’s marks |
| Metric | Data Source | GP | PLS | LASSO | RR |
|---|---|---|---|---|---|
| RMSE | Moodle | 2.04 (1.82) | 2.76 (2.58) | 2.93 (2.30) | 2.61 (2.39) |
| Socio-Economic | 2.26 (1.84) | 3.58 (2.98) | 3.15 (2.30) | 2.10 (1.58) | |
| Subject marks | 2.45 (2.59) | 1.38 (1.36) | 1.29 (1.28) | 1.11 (1.22) | |
| NRMSE | Moodle | 0.20 (0.18) | 0.28 (0.26) | 0.29 (0.23) | 0.26 (0.24) |
| Socio-Economic | 0.23 (0.18) | 0.36 (0.30) | 0.31 (0.23) | 0.21 (0.16) | |
| Subject marks | 0.24 (0.26) | 0.14 (0.14) | 0.13 (0.13) | 0.11 (0.12) | |
| CV | Moodle | 0.89 | 0.93 | 0.78 | 0.92 |
| Socio-Economic | 0.81 | 0.83 | 0.73 | 0.75 | |
| Subject marks | 1.06 | 0.99 | 0.99 | 1.09 | |
| Pearson | Moodle | 0.33 | 0.25 | 0.30 | 0.30 |
| Socio-Economic | 0.24 | −0.06 | 0.07 | 0.42 | |
| Subject marks | 0.22 | 0.74 | 0.77 | 0.81 | |
| Spearman | Moodle | 0.50 | 0.54 | 0.45 | 0.57 |
| Socio-Economical | −0.02 | −0.10 | −0.01 | 0.34 | |
| Subject marks | 0.67 | 0.73 | 0.75 | 0.81 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pérez-Suay, A.; Ferrís-Castell, R.; Van Vaerenbergh, S.; Pascual-Venteo, A.B. Assessing the Relevance of Information Sources for Modelling Student Performance in a Higher Mathematics Education Course. Educ. Sci. 2023, 13, 555. https://doi.org/10.3390/educsci13060555
Pérez-Suay A, Ferrís-Castell R, Van Vaerenbergh S, Pascual-Venteo AB. Assessing the Relevance of Information Sources for Modelling Student Performance in a Higher Mathematics Education Course. Education Sciences. 2023; 13(6):555. https://doi.org/10.3390/educsci13060555
Chicago/Turabian StylePérez-Suay, Adrián, Ricardo Ferrís-Castell, Steven Van Vaerenbergh, and Ana B. Pascual-Venteo. 2023. "Assessing the Relevance of Information Sources for Modelling Student Performance in a Higher Mathematics Education Course" Education Sciences 13, no. 6: 555. https://doi.org/10.3390/educsci13060555