
An Advanced Decision Tree-Based Deep Neural Network in Nonlinear Data Classification


Abstract
:1. Introduction
2. Related Work
2.1. Background on Decision Tree
2.2. Neural Networks and Hybrid Models
3. Materials and Methods
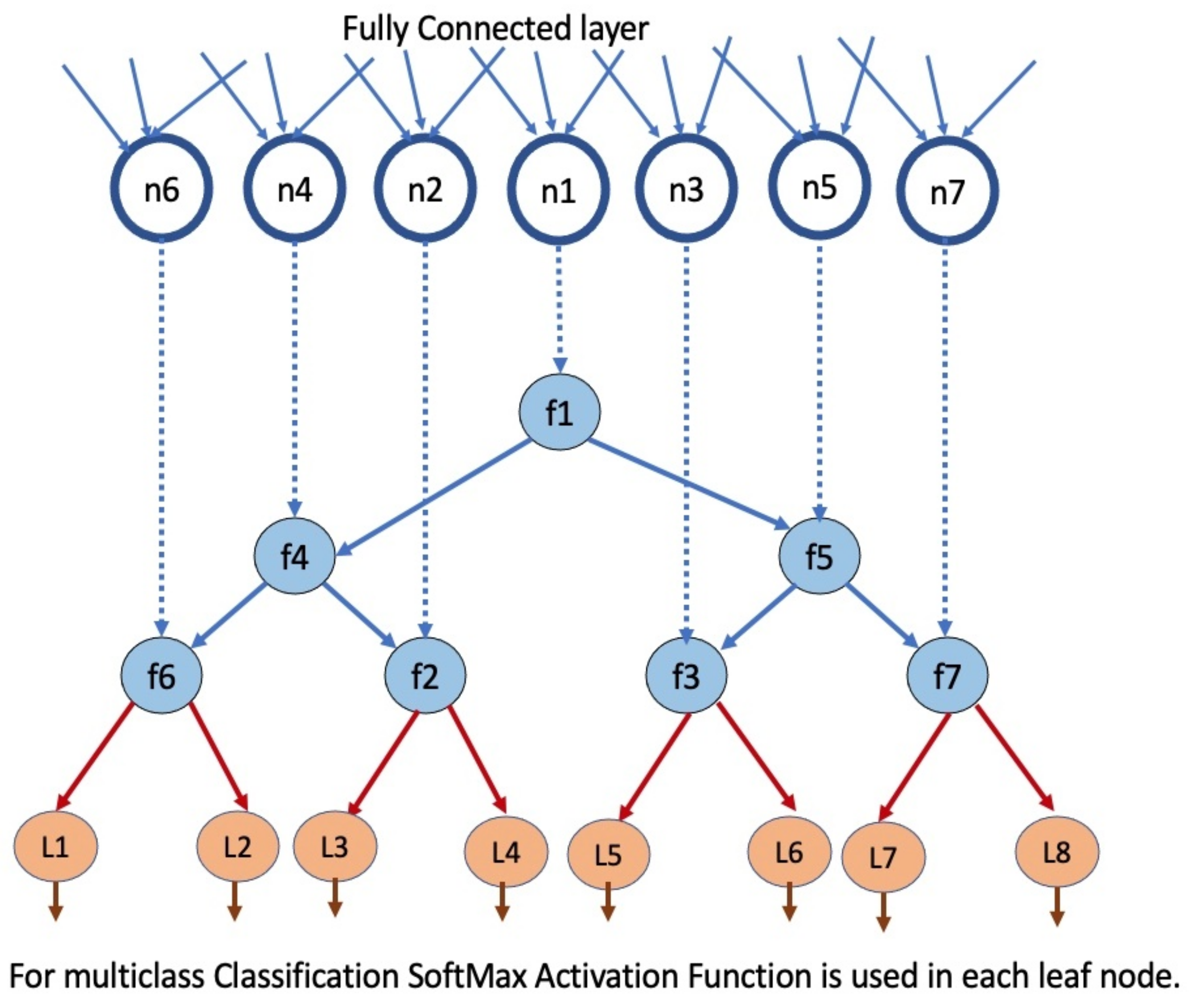
3.1. The Proposed DTBDNN Model
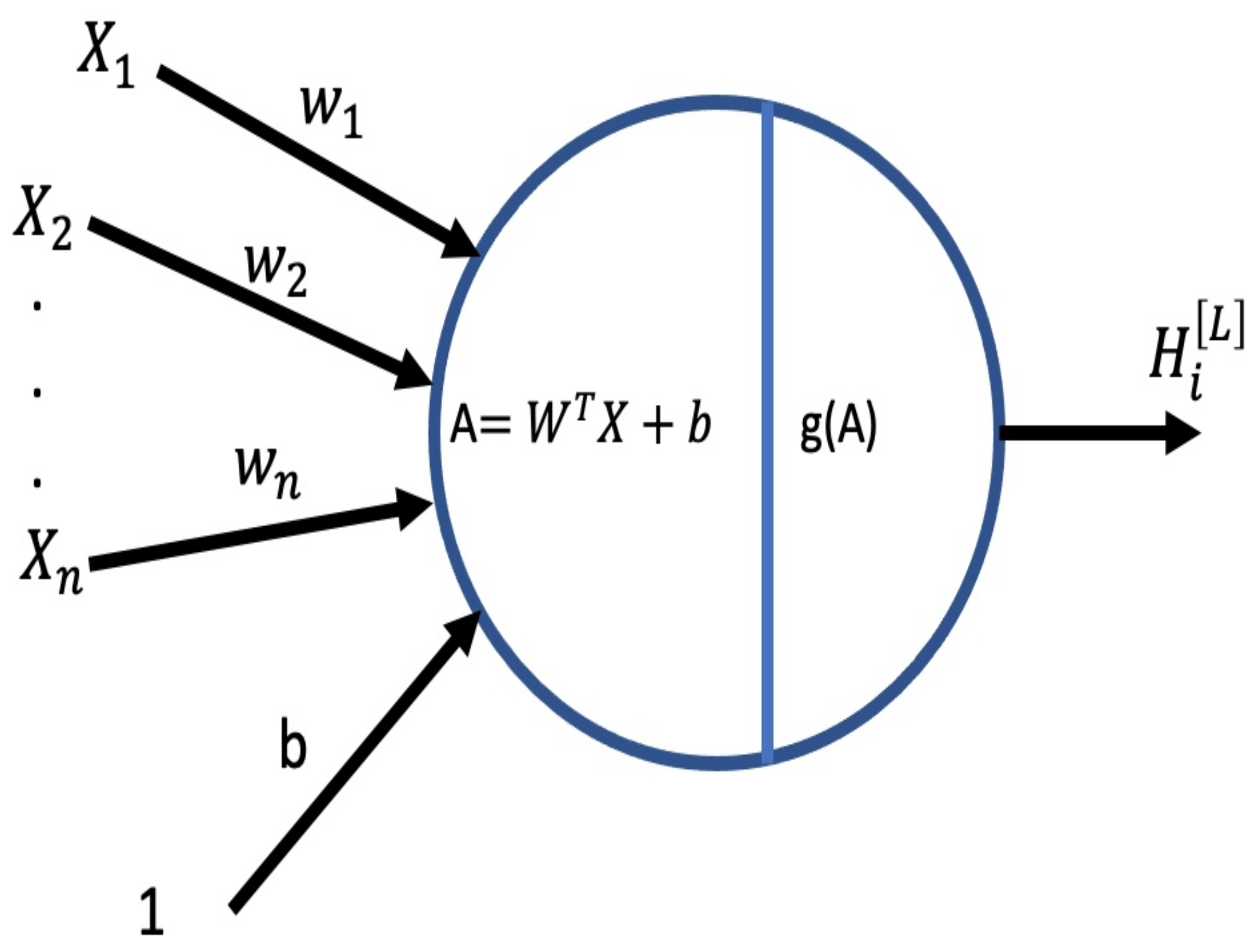
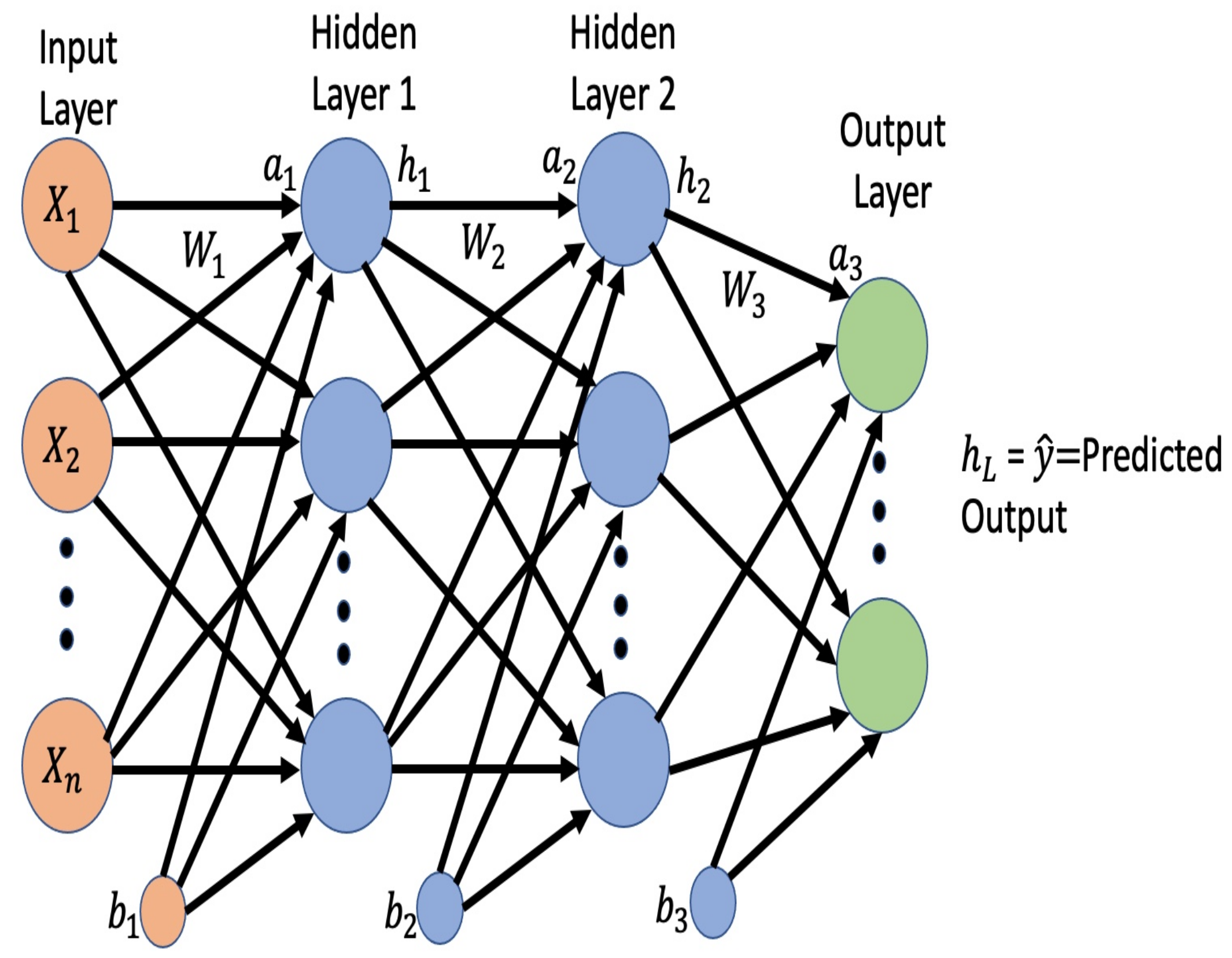
3.1.1. System Model Overview
| Algorithm 1 Deep Learning Algorithm Forward Propagation Along With Gradient Descent. |
| Require: Network depth, L Require: , the weight matrices of the model Require: , the bias parameters of the model Require: X, the input to process Require: y, the target output whiledo while do end while ▹ is the loss function ▹ end while |
3.1.2. Decision Tree-Based Deep Neural Network (DTBDNN) Algorithm
| Algorithm 2 Decision Tree-Based Deep Neural Network (DTBDNN) Algorithm. |
|
4. Experimental Results, Performance Evaluations and Discussion
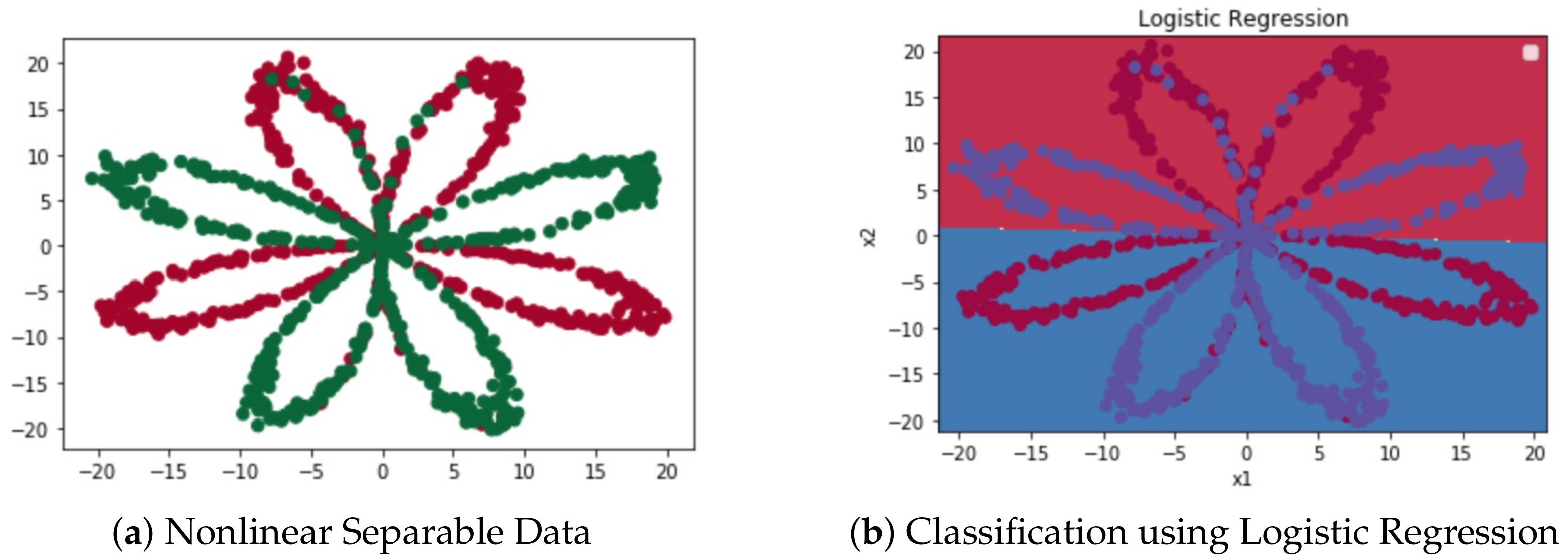
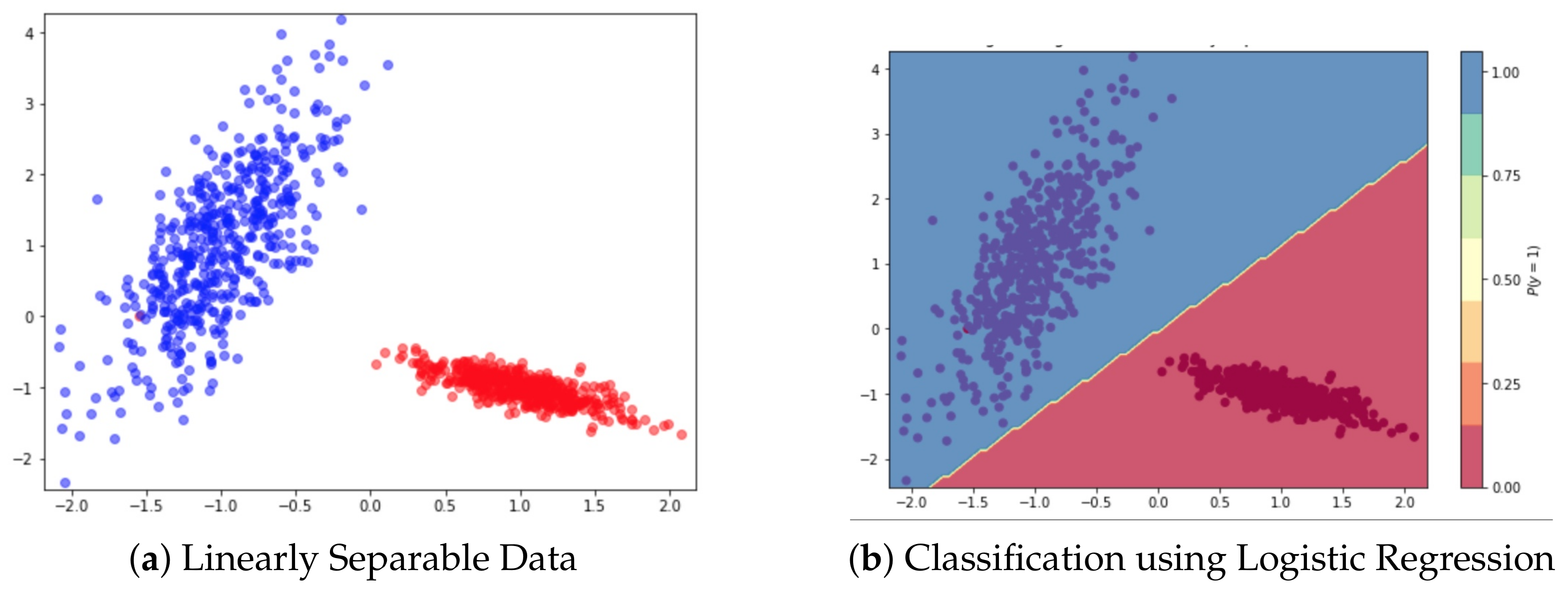
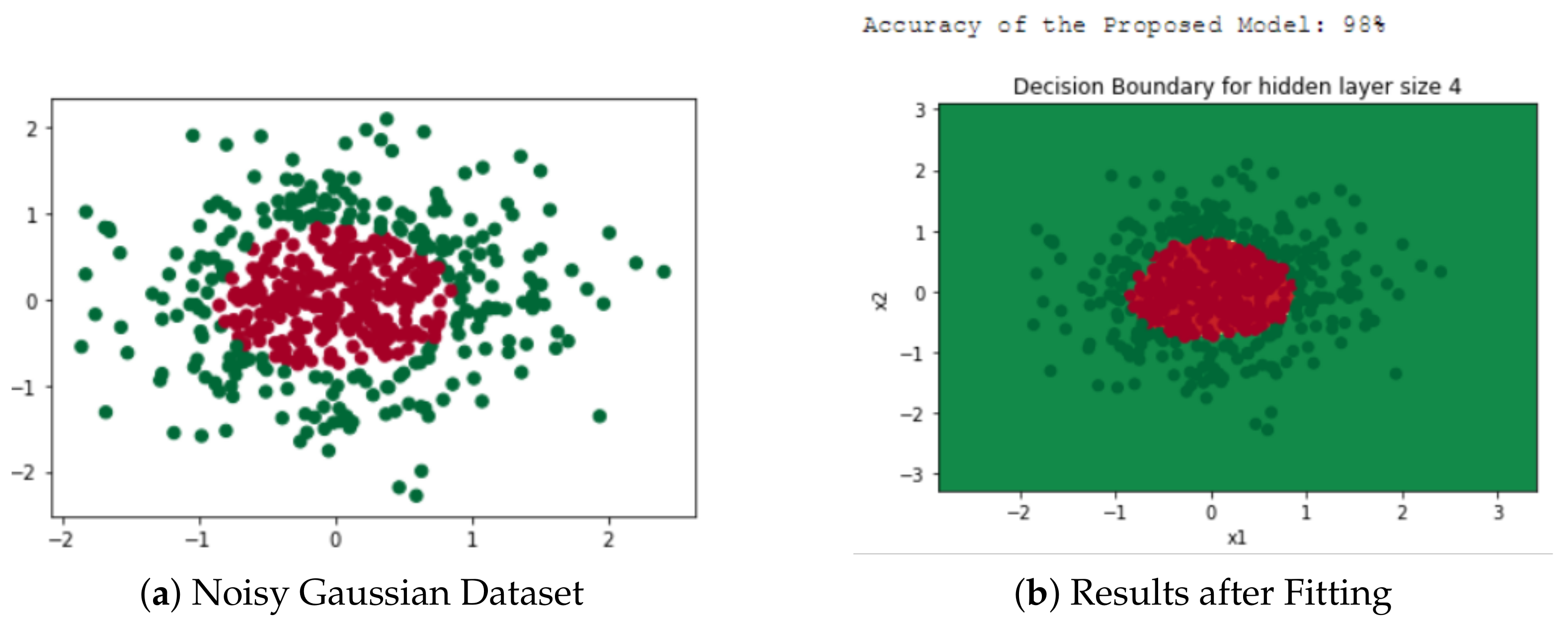
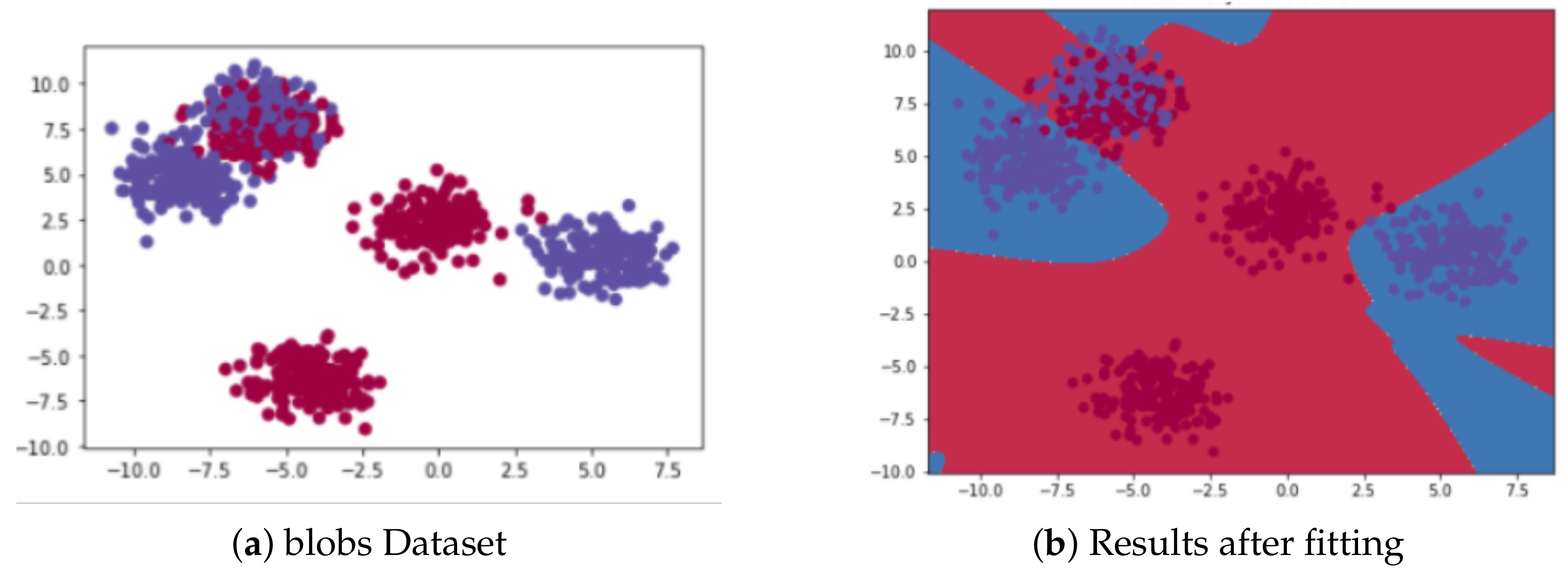
4.1. Dataset and Visualization
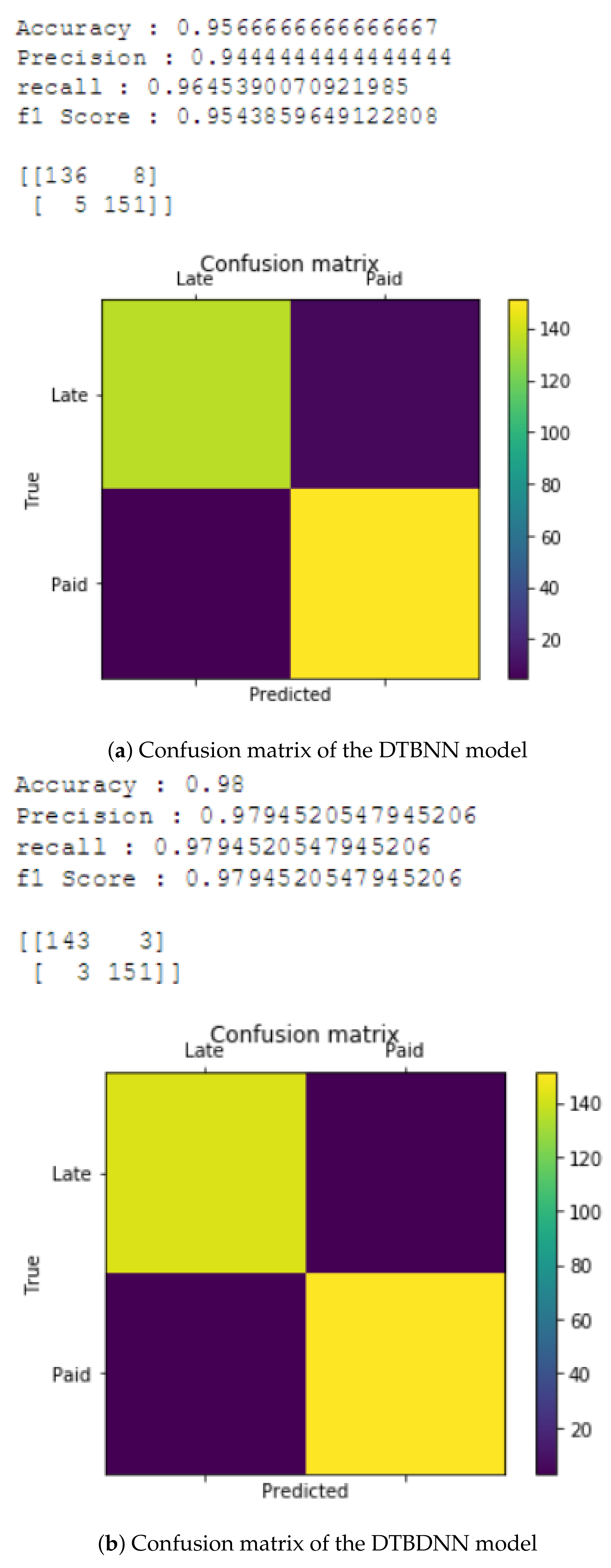
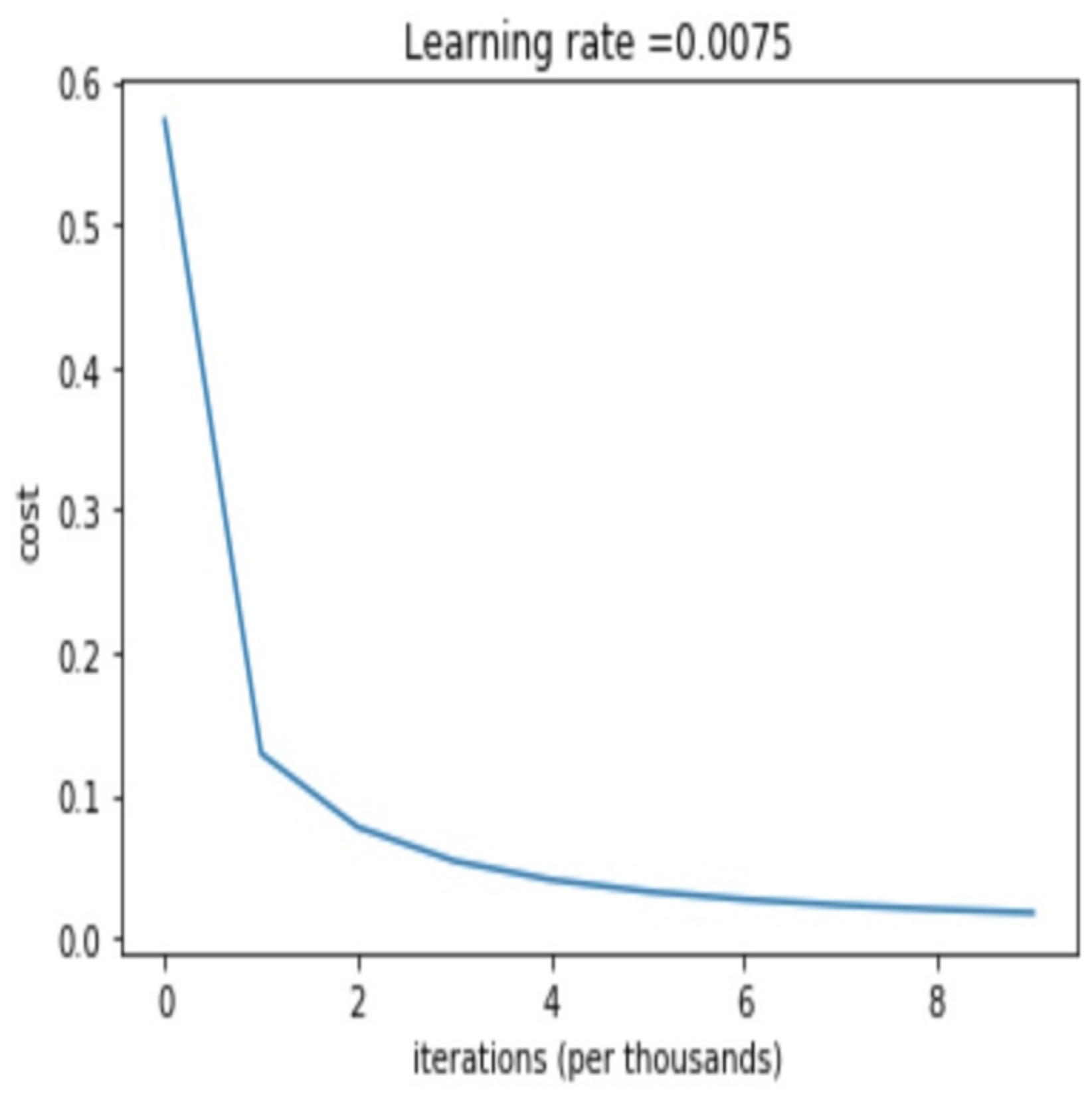
4.2. Context-Based Logistic Regression Model’s Result
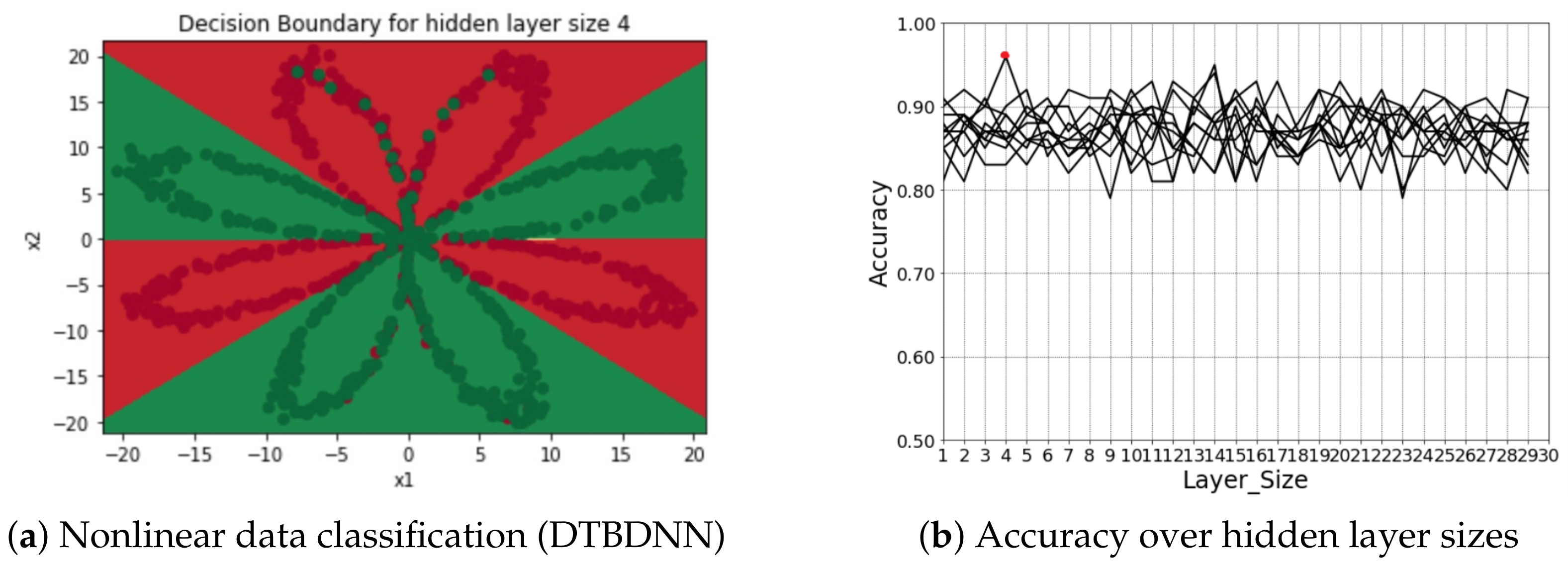
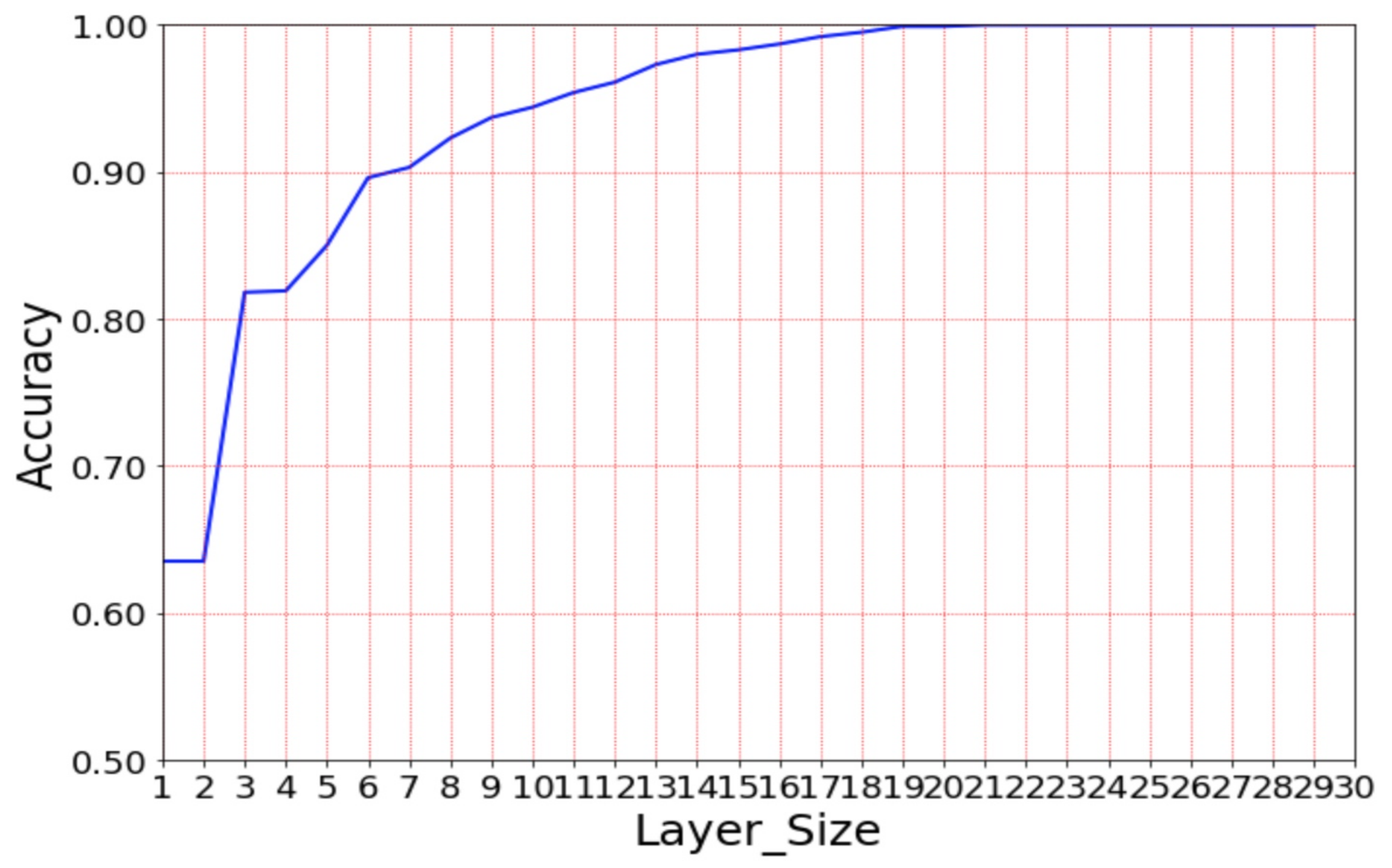
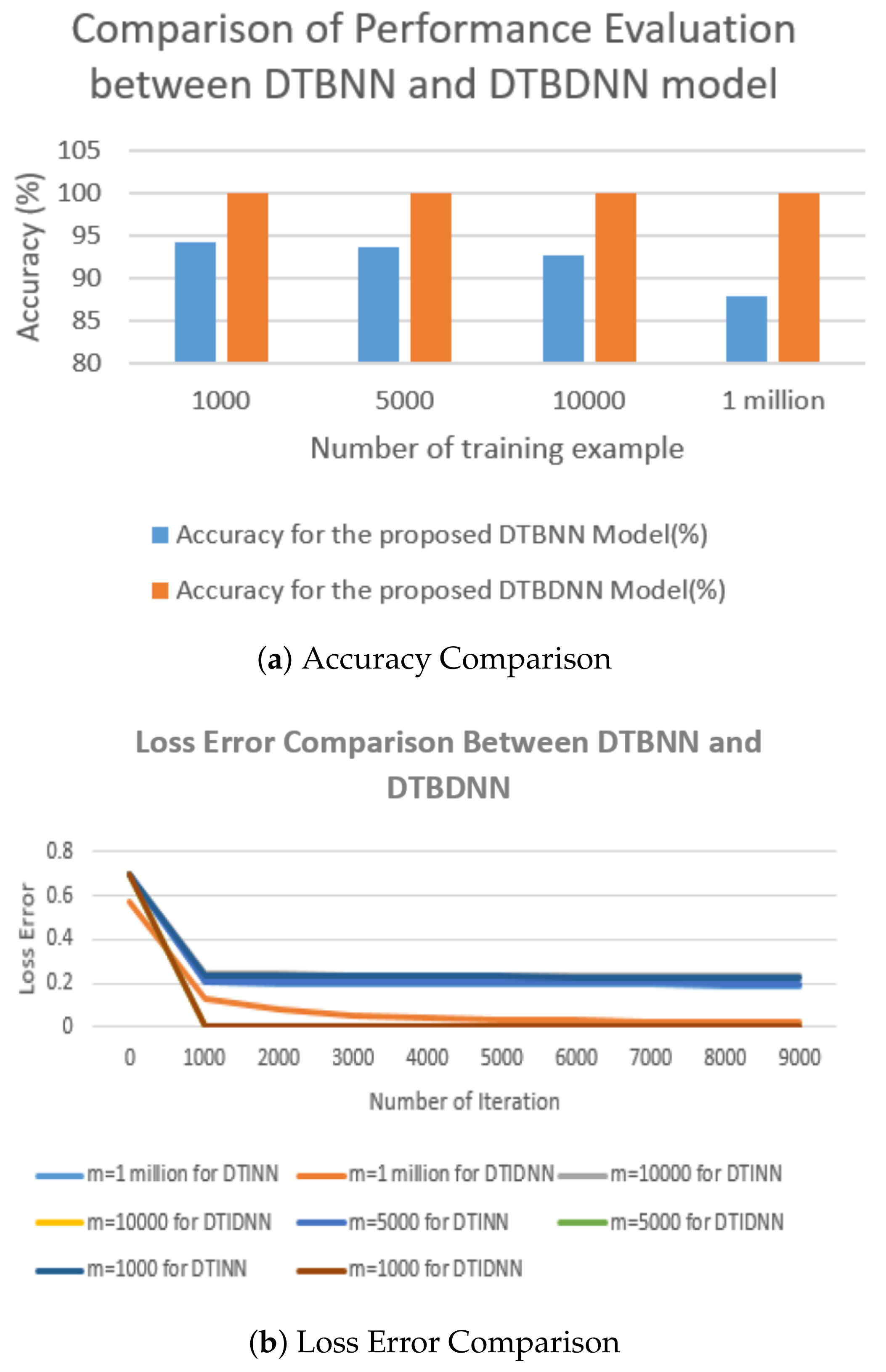
4.3. The Proposed DTBDNN Model’s Result
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Hu, Z.; Bodyanskiy, Y.V.; Kulishova, N.Y.; Tyshchenko, O.K. A multidimensional extended neo-fuzzy neuron for facial expression recognition. Int. J. Intell. Syst. Appl. 2017, 9, 29. [Google Scholar] [CrossRef]
- Hu, Z.; Ivashchenko, M.; Lyushenko, L.; Klyushnyk, D. Artificial Neural Network Training Criterion Formulation Using Error Continuous Domain. Int. J. Mod. Educ. Comput. Sci. 2021, 3, 13–22. [Google Scholar] [CrossRef]
- Hu, Z.; Tereykovskiy, I.A.; Tereykovska, L.O.; Pogorelov, V.V. Determination of structural parameters of multilayer perceptron designed to estimate parameters of technical systems. Int. J. Intell. Syst. Appl. 2017, 9, 57. [Google Scholar] [CrossRef]
- Ng, A. Machine Learning Yearning. 2017. Available online: https://www.mlyearning.org/ (accessed on 1 September 2022).
- Paul, A.K.; Das, D.; Kamal, M.M. Bangla Speech Recognition System Using LPC and ANN. In Proceedings of the 2009 Seventh International Conference on Advances in Pattern Recognition, Kolkata, India, 4–6 February 2009; pp. 171–174. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Mehmood, I.; Rho, S.; Baik, S.W. Convolutional Neural Networks Based Fire Detection in Surveillance Videos. IEEE Access 2018, 6, 18174–18183. [Google Scholar] [CrossRef]
- Paul, A.K.; Sato, T. Localization in Wireless Sensor Networks: A Survey on Algorithms, Measurement Techniques, Applications and Challenges. J. Sens. Actuator Netw. 2017, 6, 24. [Google Scholar] [CrossRef]
- Paul, A.K.; Yanwei, L.; Sato, T. A Distributed Range Free Sensor Localization with Friendly Anchor Selection Strategy in Anisotropic Wireless Sensor Network. Trans. Jpn. Soc. Simul. Technol. 2013, 4, 96–106. [Google Scholar]
- Paul, A.K.; Qu, X.; Wen, Z. Blockchain—A promising solution to internet of things: A comprehensive analysis, opportunities, challenges and future research issues. Peer-to-Peer Netw. Appl. 2021, 14, 2926–2951. [Google Scholar] [CrossRef]
- Asghar, M.A.; Khan, M.J.; Fawad; Amin, Y.; Rizwan, M.; Rahman, M.; Badnava, S.; Mirjavadi, S.S. EEG-Based Multi-Modal Emotion Recognition using Bag of Deep Features: An Optimal Feature Selection Approach. Sensors 2019, 19, 5218. [Google Scholar] [CrossRef]
- Zhai, J.; Wang, X.; Zhang, S.; Hou, S. Tolerance Rough Fuzzy Decision Tree. Inf. Sci. 2018, 465, 425–438. [Google Scholar] [CrossRef]
- Kolsbjerg, E.L.; Peterson, A.A.; Hammer, B. Neural-network-enhanced evolutionary algorithm applied to supported metal nanoparticles. Phys. Rev. B 2018, 97, 195424. [Google Scholar] [CrossRef]
- Fubao, Z.; Mengmeng, T.; Lijie, X.; Haodong, Z. A Classification Algorithm of CART Decision Tree based on MapReduce Attribute Weights. Int. J. Perform. Eng. 2018, 14, 17. [Google Scholar] [CrossRef]
- OrShea, J.; Crockett, K.; Khan, W.; Bandar, Z.; Bandar, Z. A hybrid model combining neural networks and decision tree for comprehension detection. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Wang, R.; He, Y.L.; Chow, C.Y.; Ou, F.F.; Zhang, J. Learning ELM-Tree from Big Data Based on Uncertainty Reduction. Fuzzy Sets Syst. 2015, 258, 79–100. [Google Scholar] [CrossRef]
- Zhang, J.; Yu, K.; Wen, Z.; Qi, X.; Paul, A.K. 3D Reconstruction for Motion Blurred Images Using Deep Learning-Based Intelligent Systems. Comput. Mater. Contin. 2021, 66, 2087–2104. [Google Scholar] [CrossRef]
- Peng, X.; Feng, J.; Xiao, S.; Yau, W.Y.; Zhou, J.T.; Yang, S. Structured AutoEncoders for Subspace Clustering. IEEE Trans. Image Process. 2018, 27, 5076–5086. [Google Scholar] [CrossRef]
- Raissi, M.; Wang, Z.; Triantafyllou, M.S.; Karniadakis, G.E. Deep learning of vortex-induced vibrations. J. Fluid Mech. 2018, 861, 119–137. [Google Scholar] [CrossRef]
- Ma, T.; Benon, K.; Arnold, B.; Yu, K.; Yang, Y.; Hua, Q.; Wen, Z.; Paul, A.K. Bottleneck Feature Extraction-Based Deep Neural Network Model for Facial Emotion Recognition. In Proceedings of the Mobile Networks and Management; Loke, S.W., Liu, Z., Nguyen, K., Tang, G., Ling, Z., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 30–46. [Google Scholar]
- Chhowa, T.T.; Rahman, M.A.; Paul, A.K.; Ahmmed, R. A Narrative Analysis on Deep Learning in IoT based Medical Big Data Analysis with Future Perspectives. In Proceedings of the 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’s Bazar, Bangladesh, 7–9 February 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Canziani, A.; Paszke, A.; Culurciello, E. An Analysis of Deep Neural Network Models for Practical Applications. arXiv 2016, arXiv:1605.07678. [Google Scholar] [CrossRef]
- Bianco, S.; Cadene, R.; Celona, L.; Napoletano, P. Benchmark Analysis of Representative Deep Neural Network Architectures. IEEE Access 2018, 6, 64270–64277. [Google Scholar] [CrossRef]
- Cheng, G.; Li, Z.; Yao, X.; Guo, L.; Wei, Z. Remote Sensing Image Scene Classification Using Bag of Convolutional Features. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1735–1739. [Google Scholar] [CrossRef]
- Zhang, Y.D.; Zhang, Y.; Hou, X.X.; Chen, H.; Wang, S.H. Seven-Layer Deep Neural Network Based on Sparse Autoencoder for Voxelwise Detection of Cerebral Microbleed. Multimed. Tools Appl. 2018, 77, 10521–10538. [Google Scholar] [CrossRef]
- Tang, B.; Tu, Y.; Zhang, Z.; Lin, Y. Digital Signal Modulation Classification With Data Augmentation Using Generative Adversarial Nets in Cognitive Radio Networks. IEEE Access 2018, 6, 15713–15722. [Google Scholar] [CrossRef]
- Yao, X.; Guo, J.; Hu, J.; Cao, Q. Using Deep Learning in Semantic Classification for Point Cloud Data. IEEE Access 2019, 7, 37121–37130. [Google Scholar] [CrossRef]
- Miikkulainen, R.; Liang, J.; Meyerson, E.; Rawal, A.; Fink, D.; Francon, O.; Raju, B.; Shahrzad, H.; Navruzyan, A.; Duffy, N.; et al. Evolving Deep Neural Networks. arXiv 2017, arXiv:1703.00548. [Google Scholar] [CrossRef]
- Wang, J.; Ding, Y.; Bian, S.; Peng, Y.; Liu, M.; Gui, G. UL-CSI Data Driven Deep Learning for Predicting DL-CSI in Cellular FDD Systems. IEEE Access 2019, 7, 96105–96112. [Google Scholar] [CrossRef]
- Paul, A.K.; Khan, J.M.; Parvin, T.T. Convolutional Neural Network Based Real Time Pneumonia Detection Using Transfer Learning and Image Augmentation. In Proceedings of the ICSTEM4IR 2022, Khulna, Bangladesh, 1–3 July 2022; pp. 28–39. [Google Scholar]
- Goodfellow, I.J.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 1 September 2022).
- Yang, Y.; Morillo, I.G.; Hospedales, T.M. Deep Neural Decision Trees. arXiv 2018, arXiv:1806.06988. [Google Scholar] [CrossRef]
- Song, Q.; Xu, F.; Jin, Y.Q. Reconstruction of Full-Pol SAR Data from Partialpol Data Using Deep Neural Networks. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4383–4386. [Google Scholar] [CrossRef]
- Guan, J.; Lai, R.; Xiong, A. Wavelet Deep Neural Network for Stripe Noise Removal. IEEE Access 2019, 7, 44544–44554. [Google Scholar] [CrossRef]
- Xu, G.; Su, X.; Liu, W.; Xiu, C. Target Detection Method Based on Improved Particle Search and Convolution Neural Network. IEEE Access 2019, 7, 25972–25979. [Google Scholar] [CrossRef]
- Hatcher, W.G.; Yu, W. A Survey of Deep Learning: Platforms, Applications and Emerging Research Trends. IEEE Access 2018, 6, 24411–24432. [Google Scholar] [CrossRef]
- Min, E.; Guo, X.; Liu, Q.; Zhang, G.; Cui, J.; Long, J. A Survey of Clustering With Deep Learning: From the Perspective of Network Architecture. IEEE Access 2018, 6, 39501–39514. [Google Scholar] [CrossRef]
- Wang, W.; Gao, Z.; Zhao, M.; Li, Y.; Liu, J.; Zhang, X. DroidEnsemble: Detecting Android Malicious Applications With Ensemble of String and Structural Static Features. IEEE Access 2018, 6, 31798–31807. [Google Scholar] [CrossRef]
- Dougherty, J.; Kohavi, R.; Sahami, M. Supervised and Unsupervised Discretization of Continuous Features. In Machine Learning Proceedings 1995; Prieditis, A., Russell, S., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 1995; pp. 194–202. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining Concepts and Techniques, 3rd ed.; Morgan Kaufmann Publishers: Waltham, MA, USA, 2012. [Google Scholar]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Shin, H.C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. arXiv 2016, arXiv:1602.03409. [Google Scholar] [CrossRef]
- Shrestha, A.; Mahmood, A. Review of Deep Learning Algorithms and Architectures. IEEE Access 2019, 7, 53040–53065. [Google Scholar] [CrossRef]
- Aytekin, C. Neural Networks are Decision Trees. arXiv 2022, arXiv:2210.05189. [Google Scholar] [CrossRef]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv 2013, arXiv:1312.6034. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. arXiv 2013, arXiv:1311.2901. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. arXiv 2015, arXiv:1512.04150. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Generalized Gradient-Based Visual Explanations for Deep Convolutional Networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar] [CrossRef]
- Draelos, R.L.; Carin, L. Use HiResCAM instead of Grad-CAM for faithful explanations of convolutional neural networks. arXiv 2020, arXiv:2011.08891. [Google Scholar] [CrossRef]
- Humbird, K.D.; Peterson, J.L.; Mcclarren, R.G. Deep Neural Network Initialization With Decision Trees. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 1286–1295. [Google Scholar] [CrossRef]
- Kontschieder, P.; Fiterau, M.; Criminisi, A.; Bulo, S.R. Deep Neural Decision Forests. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1467–1475. [Google Scholar] [CrossRef]
- Sethi, I. Entropy nets: From decision trees to neural networks. Proc. IEEE 1990, 78, 1605–1613. [Google Scholar] [CrossRef]
- Wu, M.; Hughes, M.C.; Parbhoo, S.; Zazzi, M.; Roth, V.; Doshi-Velez, F. Beyond Sparsity: Tree Regularization of Deep Models for Interpretability. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Frosst, N.; Hinton, G. Distilling a Neural Network Into a Soft Decision Tree. arXiv 2017, arXiv:1711.09784. [Google Scholar] [CrossRef]
- Shazeer, N.; Fatahalian, K.; Mark, W.R.; Mullapudi, R.T. HydraNets: Specialized Dynamic Architectures for Efficient Inference. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8080–8089. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar] [CrossRef]
- Murdock, C.; Li, Z.; Zhou, H.; Duerig, T. Blockout: Dynamic Model Selection for Hierarchical Deep Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2583–2591. [Google Scholar] [CrossRef] [Green Version]
- Murthy, V.N.; Singh, V.; Chen, T.; Manmatha, R.; Comaniciu, D. Deep Decision Network for Multi-class Image Classification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2240–2248. [Google Scholar] [CrossRef]
- Roy, A.; Todorovic, S. Monocular Depth Estimation Using Neural Regression Forest. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5506–5514. [Google Scholar] [CrossRef]
- McGill, M.; Perona, P. Deciding How to Decide: Dynamic Routing in Artificial Neural Networks. arXiv 2017, arXiv:1703.06217. [Google Scholar] [CrossRef]
- Veit, A.; Belongie, S. Convolutional Networks with Adaptive Inference Graphs. arXiv 2017, arXiv:1711.11503. [Google Scholar] [CrossRef]
- Wan, A.; Dunlap, L.; Ho, D.; Yin, J.; Lee, S.; Jin, H.; Petryk, S.; Bargal, S.A.; Gonzalez, J.E. NBDT: Neural-Backed Decision Trees. arXiv 2020, arXiv:2004.00221. [Google Scholar] [CrossRef]
- Zhao, R.; Ouyang, W.; Li, H.; Wang, X. Saliency detection by multi-context deep learning. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1265–1274. [Google Scholar] [CrossRef]
- García, Á.A.; Álvarez, J.A.; Soria-Morillo, L.M. Deep neural network for traffic sign recognition systems: An analysis of spatial transformers and stochastic optimisation methods. Neural Netw. 2018, 99, 158–165. [Google Scholar] [CrossRef]
- Wu, Q.; Fan, C.; Chen, H.; Gu, D. Construction of a Neural Network and its Application on Target Classification. IEEE Access 2019, 7, 29709–29721. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Y.; Ding, L. Scene Classification Based on Two-Stage Deep Feature Fusion. IEEE Geosci. Remote Sens. Lett. 2018, 15, 183–186. [Google Scholar] [CrossRef]
- Frank, E.; Wang, Y.; Inglis, S.; Holmes, G.; Witten, I.H. Using Model Trees for Classification. Mach. Learn. 1998, 32, 63–76. [Google Scholar] [CrossRef]
- Huang, G.B.; Wang, D.H.; Lan, Y. Extreme learning machines: A survey. Int. J. Mach. Learn. Cybern. 2011, 2, 107–122. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man, Cybern. Part B 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Alazab, M.; Soman, K.P.; Poornachandran, P.; Al-Nemrat, A.; Venkatraman, S. Deep Learning Approach for Intelligent Intrusion Detection System. IEEE Access 2019, 7, 41525–41550. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Reyes-Nava, A.; Sánchez, J.; Alejo, R.; Flores-Fuentes, A.; Rendón, E. Performance Analysis of Deep Neural Networks for Classification of Gene-Expression Microarrays. In Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2018; pp. 105–115. [Google Scholar] [CrossRef]
- Bosman, A.S.; Engelbrecht, A.; Helbig, M. Visualising basins of attraction for the cross-entropy and the squared error neural network loss functions. Neurocomputing 2020, 400, 113–136. [Google Scholar] [CrossRef]
- Rusiecki, A. Trimmed Robust Loss Function for Training Deep Neural Networks with Label Noise. In Proceedings of the ICAISC, Zakopane, Poland, 16–20 June 2019. [Google Scholar]
- Wang, S.; Liu, W.; Wu, J.; Cao, L.; Meng, Q.; Kennedy, P.J. Training deep neural networks on imbalanced data sets. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 4368–4374. [Google Scholar] [CrossRef]
- UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml/index.php (accessed on 25 October 2022).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attributes | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0 | 0.93 | 0.92 | 0.93 | 500 |
| 1 | 0.94 | 0.94 | 0.92 | 500 |
| Micro Avg | 0.94 | 0.93 | 0.93 | 500 |
| Macro Avg | 0.46 | 0.46 | 0.46 | 500 |
| Weighted Avg | 0.93 | 0.93 | 0.93 | 500 |
| Sample Avg | 0.94 | 0.93 | 0.93 | 500 |
| Total | 0.93 | 0.94 | 0.93 | 1000 |
| Hidden Layer Size | Accuracy (%) |
|---|---|
| Accuracy for NN Model (No hidden layers) | 93 |
| Accuracy for 1 hidden unit | 71.30 |
| Accuracy for 2 hidden units | 70.899 |
| Accuracy for 3 hidden units | 70.8 |
| Accuracy for 4 hidden units | 93.10 |
| Accuracy for 5 hidden units | 92.10 |
| Accuracy for 20 hidden units | 93.30 |
| Dataset | No. of Instances | No. of Features | No. of Classes | DTBDNN | DT | ELM-Tree |
|---|---|---|---|---|---|---|
| Wireless Indoor Localization | 2000 | 7 | 4 | 87.21 | 86.79 | 86.4 |
| OBS-Network | 1075 | 22 | 4 | 96.76 | 95.87 | 96.12 |
| Gime-Me-Some-Credit | 201,669 | 10 | 2 | 97.78 | 91.89 | 95.56 |
| SARS B-cell Epitope Prediction | 14,387 | 13 | 2 | 85.34 | 68.93 | 81.1 |
| Pima Indian Diabetes | 768 | 8 | 2 | 67.23 | 71.56 | 74.48 |
| MAGIC Gamma Telescope | 19,020 | 11 | 2 | 83.56 | 80.76 | 82.58 |
| Waveform Noise | 5000 | 40 | 3 | 75.21 | 69.76 | 75.2 |
| Credit Approval | 690 | 15 | 2 | 81.35 | 83.32 | 81.23 |
| Healthy Older People | 75,128 | 9 | 4 | 97.35 | 95.34 | 96.67 |
| Flight Delay | 1,100,000 | 9 | 2 | 77.89 | 66.67 | 75.34 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arifuzzaman, M.; Hasan, M.R.; Toma, T.J.; Hassan, S.B.; Paul, A.K. An Advanced Decision Tree-Based Deep Neural Network in Nonlinear Data Classification. Technologies 2023, 11, 24. https://doi.org/10.3390/technologies11010024
Arifuzzaman M, Hasan MR, Toma TJ, Hassan SB, Paul AK. An Advanced Decision Tree-Based Deep Neural Network in Nonlinear Data Classification. Technologies. 2023; 11(1):24. https://doi.org/10.3390/technologies11010024
Chicago/Turabian StyleArifuzzaman, Mohammad, Md. Rakibul Hasan, Tasnia Jahan Toma, Samia Binta Hassan, and Anup Kumar Paul. 2023. "An Advanced Decision Tree-Based Deep Neural Network in Nonlinear Data Classification" Technologies 11, no. 1: 24. https://doi.org/10.3390/technologies11010024