
Covariants of Gemination in Eastern Andalusian Spanish: /t/ following Underlying /s/, /k/, /p/ and /ks/

Abstract
:1. Introduction
 , ‘two’ (e.g., Villena Ponsoda 2000); vowel opening, to the extent described for EAS, has not been noted in other varieties of Spanish (Henriksen 2017). In this paper, the term deletion is used as a cover term for when a phoneme does not surface directly in the phonetic output, even though it may leave some other assimilatory trace, e.g., esta /ˈesta/
, ‘two’ (e.g., Villena Ponsoda 2000); vowel opening, to the extent described for EAS, has not been noted in other varieties of Spanish (Henriksen 2017). In this paper, the term deletion is used as a cover term for when a phoneme does not surface directly in the phonetic output, even though it may leave some other assimilatory trace, e.g., esta /ˈesta/  ‘this one’. The term Andalusian Spanish is used to refer to both EAS and WAS. More information regarding the differences between these two varieties of Spanish can be found in Jiménez Fernández (1999), Villena Ponsoda (2000), Moya Corral (2010) and Valeš (2014)., ‘this one’, and in es tuyo ‘
‘this one’. The term Andalusian Spanish is used to refer to both EAS and WAS. More information regarding the differences between these two varieties of Spanish can be found in Jiménez Fernández (1999), Villena Ponsoda (2000), Moya Corral (2010) and Valeš (2014)., ‘this one’, and in es tuyo ‘ , ‘it is yours’, and is considered a singleton in cometa [koˈmeta], ‘kite’, and in alto [ˈalto], ‘tall’, in which the underlying /l/ is not deleted.
, ‘it is yours’, and is considered a singleton in cometa [koˈmeta], ‘kite’, and in alto [ˈalto], ‘tall’, in which the underlying /l/ is not deleted. pacto, ‘pact’, in EAS is in contrast, for instance, to Italian, in which all trace of the original non-homorganic consonant (seen in Latin PACTU) is lost at all levels of representation, hence having only /ˈpat:o/ > [ˈpat:o] patto, ‘pact’.
pacto, ‘pact’, in EAS is in contrast, for instance, to Italian, in which all trace of the original non-homorganic consonant (seen in Latin PACTU) is lost at all levels of representation, hence having only /ˈpat:o/ > [ˈpat:o] patto, ‘pact’.1.1. Background
 >
>  . However, all EAS consonants assimilate to the following consonant in word-medial clusters except /l/, /n/ and /r/, which only do so under more limited conditions (Herrero de Haro and Hajek 2022). As a result, the surface geminate inventory is large in EAS.
. However, all EAS consonants assimilate to the following consonant in word-medial clusters except /l/, /n/ and /r/, which only do so under more limited conditions (Herrero de Haro and Hajek 2022). As a result, the surface geminate inventory is large in EAS.1.2. Aims and Research Questions
- Does the deletion of /s/, /k/, /p/ or /ks/ in the word-medial coda position trigger the gemination of a following /t/ in EAS? We expect so, because coda deletion has been shown to trigger gemination in EAS, although no experimental study has investigated this in all of these phonetic contexts.
- Does the closure duration or VOT of /t/ vary consistently depending on whether it follows an underlying /s/, /k/, /p/ or /ks/? We expect so, because some studies have found durational differences in closure and VOT in EAS depending on the underlying consonant, although this has been studied in sequences that are different from the ones investigated here.
- Are there other covariants of gemination? If so, do these vary depending on the underlying preceding consonant, and what is their relative predictive weight? We expect other covariants of gemination to be present because this is the case cross-linguistically, and phonetic changes usually do not occur in isolation. We are unsure regarding their predictive power, as durational differences and vowel formants have both shown to be very reliable cues for identifying underlying consonants in EAS.
- What explains any different phonetic realizations that may arise due to consonant deletion? We believe that some coarticulatory processes might still be at play because some studies have shown evidence that supports underlying consonant-specific coarticulation in EAS. A trading relationship might also explain the patterns of variation of certain features, such as an increase in the duration of a feature being accompanied by a reduction in the duration in another one, because this has been reported for EAS and cross-linguistically.
- What pattern of variation do gemination and covariants of gemination display in a language variety in which gemination is the result of consonant assimilation and the phonemic status of gemination has not been demonstrated? Because surface gemination is the norm in EAS, we anticipate patterns of EAS gemination and covariants of gemination to be similar to those of languages with fully phonemic gemination.
- What cross-linguistic implications derive from the research in this paper? We are interested in knowing to what extent the findings we report follow similar patterns in other languages, perhaps showing a higher degree of similarity with typologically similar languages, such as Italian.
2. Materials and Methods
2.1. Protocol and Speakers
2.2. Data Collection
. All the items used in this study have the structure /ˈe(C)ta/ to control for stress position and vowel category. , ‘sixth’. To avoid any bias, the researcher never modelled the word but defined it so that each speaker drew the pronunciation from their linguistic memory. Tokens were discarded if a participant did not know a particular word and if the researcher said it before the participant. Each speaker was asked to say each word five times, but to minimize any possible listing effect, as identified in Khattab and Al-Tamimi (2014), only the first four repetitions were analyzed. The recordings were made in local schools, at the participant’s house or in the local library, but the process was always the same.
, ‘sixth’. To avoid any bias, the researcher never modelled the word but defined it so that each speaker drew the pronunciation from their linguistic memory. Tokens were discarded if a participant did not know a particular word and if the researcher said it before the participant. Each speaker was asked to say each word five times, but to minimize any possible listing effect, as identified in Khattab and Al-Tamimi (2014), only the first four repetitions were analyzed. The recordings were made in local schools, at the participant’s house or in the local library, but the process was always the same.2.3. Acoustic Analysis
- (a)
- The onset of /e/ was determined at the last zero-crossing before an intense increase in energy in the F2 and F3 of the vowel; using the F2 and F3 of vowels to identify cut points for segmentation as has also been done in other studies (e.g., Torreira 2012). The offset of /e/ was marked at the zero-crossing of the last harmonic cycle before the occlusion of /t/ or, if there was aspiration present, before the period of a breathy voice.
- (b)
- Aspiration before the occlusion of /t/ (if present) was marked at the offset of /e/, as in Stevens and Hajek (2010). Following Torreira (2007a, p. 115), the offset of /e/ was defined as “the point where F2 showed a clear decrease in energy, regardless of whether the following aspiration period displayed some sort of breathy voicing or plain aspiration”. Using a clear decrease in F2 energy to mark the offset of a vowel is common in the literature (e.g., Henriksen and Harper 2016). The offset of pre-aspiration (if present) was marked at the first zero-crossing after the abrupt decrease in energy following the breathy voice period. Following Torreira (2007a) and Henriksen and Harper (2016), the offset of aspiration was identified based on the presence of frication noise in high frequencies (4000–5000 Hz).
- (c)
- Following Henriksen and Willis (2010, p. 118), “the acoustic cues leading to the determination of an ‘occlusion’ were a reduction or cessation of formant structure and reduced waveform amplitude”. The onset of the occlusion of /t/ was marked at the offset of /e/, at the first zero-crossing after an abrupt decrease in amplitude on the waveform, which (typically) manifested on the spectrogram as a decrease in energy in the F2 and F3 regions of the previous vowel (Torreira 2012), as a decrease in its formant intensity (Henriksen and Harper 2016); and as lack of (Gerfen and Hall 2001) or an abrupt decrease in energy in the waveform (Gerfen and Hall 2001; Hedia and Plag 2017). The offset of occlusion was identified at the beginning of the release of /t/, as in Henriksen and Harper (2016). This release can be easily identified in the waveform as a small increase in amplitude and in the spectrogram as a sudden burst of energy (Gerfen and Hall 2001).
- (d)
- The onset of the VOT of /t/ was marked at the offset of occlusion. The offset of the VOT of /t/ was identified according to the appearance of the clearly defined F1 and F2 of /a/ (if no post-aspiration present), and it was marked at the last zero-crossing before an abrupt increase in energy was first detected after the onset of the VOT. If there was post-aspiration of /t/, the offset of the VOT was marked at the ending point of the VOT at the downward zero-crossing before a whole first cycle could be perceived in the signal (Torreira 2007a); the criteria to identify post-aspiration were the same as those used for pre-aspiration. Using waveforms to identify the VOT has also been done in other studies analyzing varieties of Andalusian Spanish (e.g., Torreira 2007a). As Torreira (2007a, p. 115) stated, “even though this method cannot be considered entirely faithful to the events in the speaker’s glottis, the signal being the result of overlapping supraglottal and glottal gestures, it appeared to be a consistent way of measuring VOT in the absence of articulatory data”. Citing Stevens (1998, p. 456), Torreira (2007a) explained how the stop release, a period of supraglottal frication, and post-aspiration overlap in the signal.
- (e)
- The onset of /a/ was marked at the offset of the VOT. The onset of the vowel was defined as the first zero-crossing of the first oscillation of the waveform following the burst (Turk et al. 2006; Nadeu 2016). If there was post-aspiration, the offset of post-aspiration was identified according to the appearance of the clearly defined F1 and F2 of /a/. Although F2 is more reliable when identifying the onset of a vowel after a stop (e.g., Idemaru and Guion 2008), both F1 and F2 were used to minimize any potential errors. Although voicing has been used in other studies of WAS to mark the onset of a vowel (e.g., Torreira 2012), using voicing in that way was avoided in the present paper, as breathy voice can be voiced in Spanish (e.g., Torreira and Ernestus 2011), and some of our samples showed that aspiration can be voiced in EAS. This phenomenon has been reported before (e.g., Navarro Tomás 1939; Alarcos Llorach 1958). Moreover, some of our samples presented voicing of the stop closure. This phenomenon has been documented in other varieties of Spanish spoken in Spain and Latin America (O’Neill 2010; Torreira and Ernestus 2011 and references therein; Ruch and Peters 2016), but the voicing of voiceless stops is more frequent in Almería than it is in other Andalusian provinces, such as Granada, Seville and Cádiz (O’Neill 2010). Therefore, all measurements were taken manually, as automatic procedures could not be relied upon (e.g., segmenting using pitch trackers based on ESPS/Waves as in Scheffers 1983). Furthermore, lenition is linked to a higher percentage of voicing as a coarticulatory effect of the glottis having to adapt to conflicting configurations (Hoole 1999).
- (f)
- The offset of /a/ was marked at the first zero-crossing in the waveform after an abrupt decrease in energy in the F2 of the vowel, as per Torreira (2007a). Using changes in energy levels in the F2 has also been used to delimit the offset of vowels by other researchers (e.g., Turk et al. 2006; Nadeu 2016).
- (g)
- As with /e/, the F1 and F2 of /a/ were measured from the stable section closest to the peak of intensity.
2.4. Statistical Analysis
2.5. Inter-Rater Reliability Test
3. Results
3.1. Acoustic Analysis
3.2. F1 of /e/
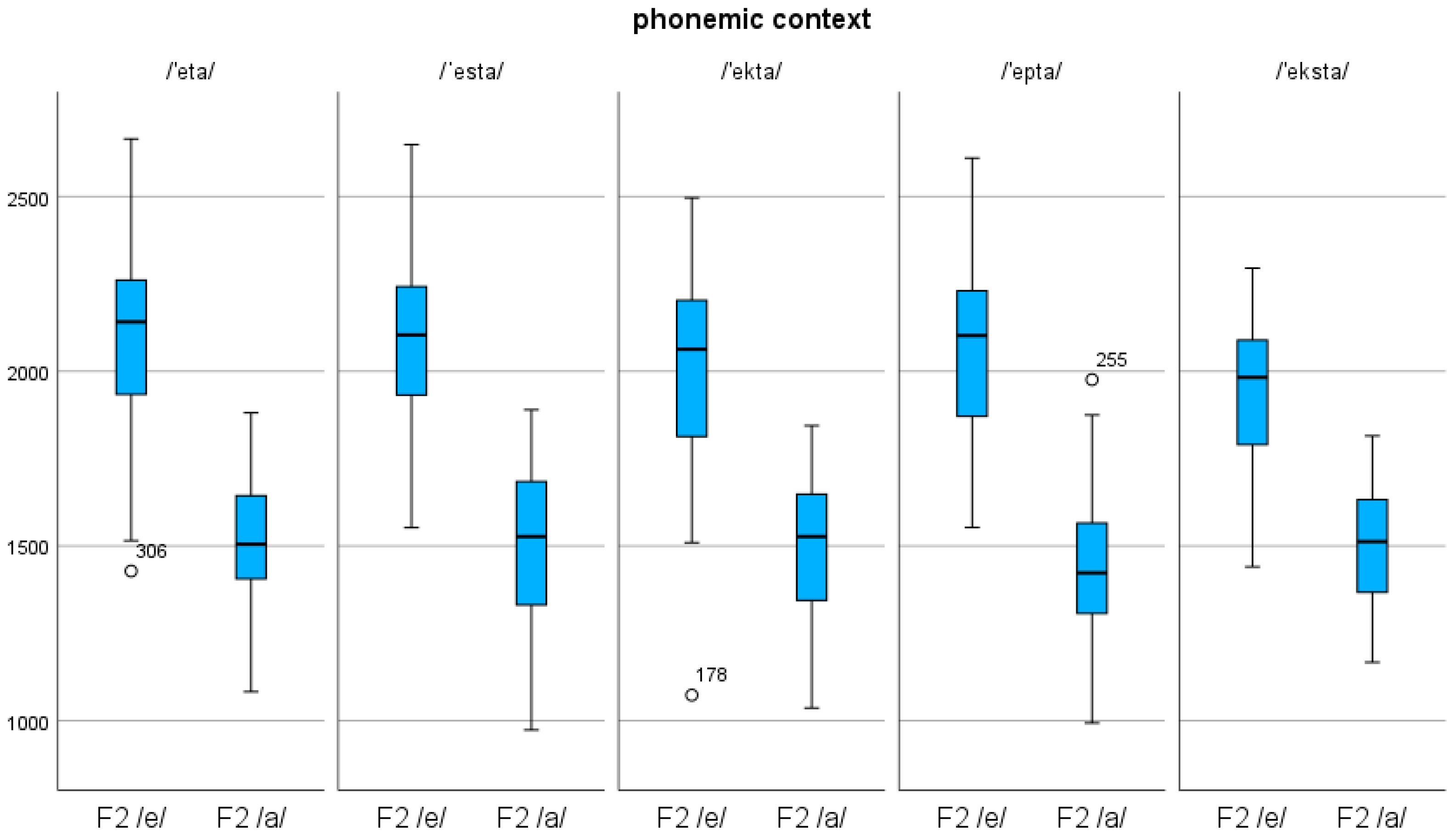
3.3. F2 of /e/
3.4. Duration of /e/
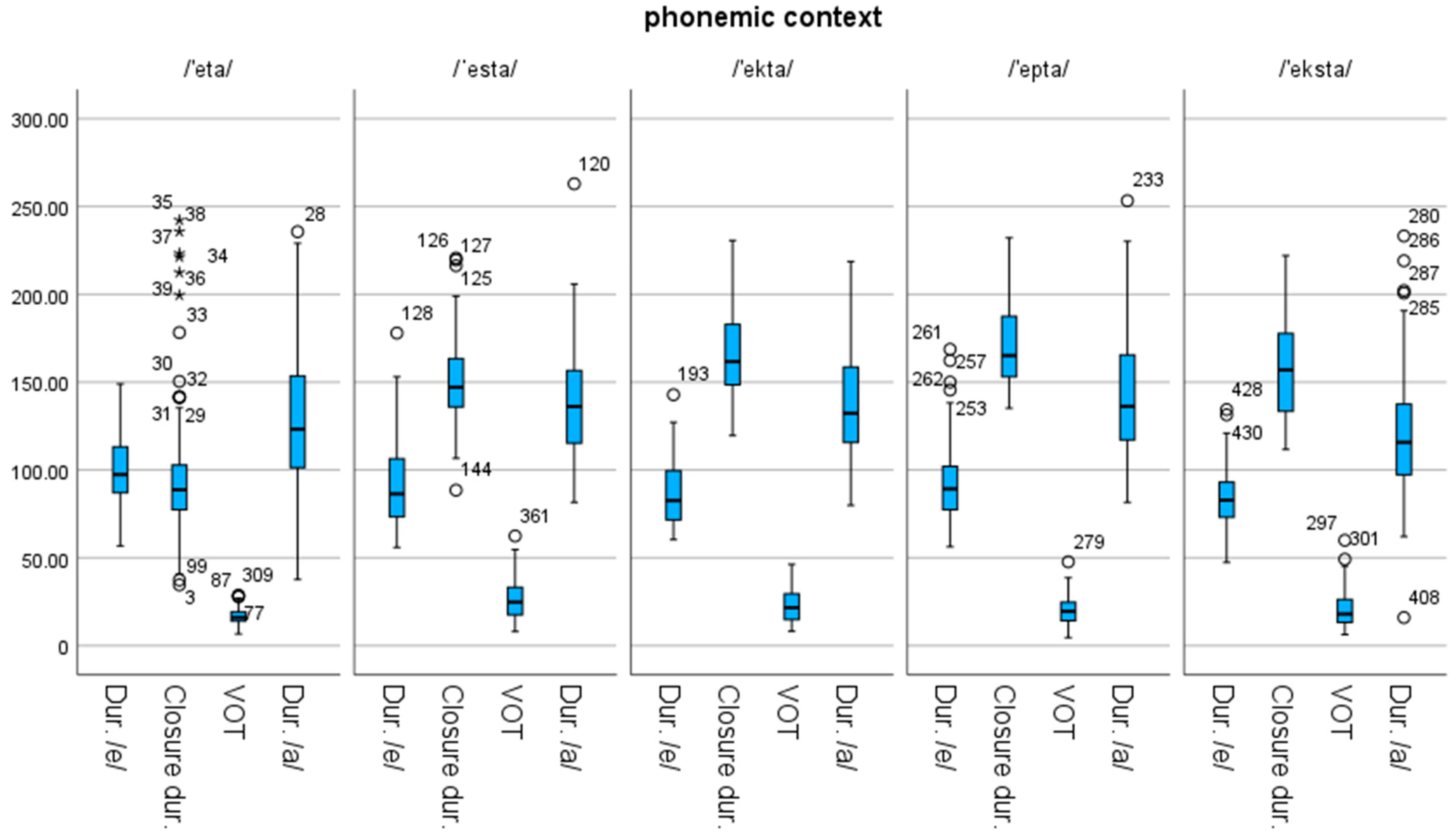
3.5. Closure Duration
3.6. VOT of /t/
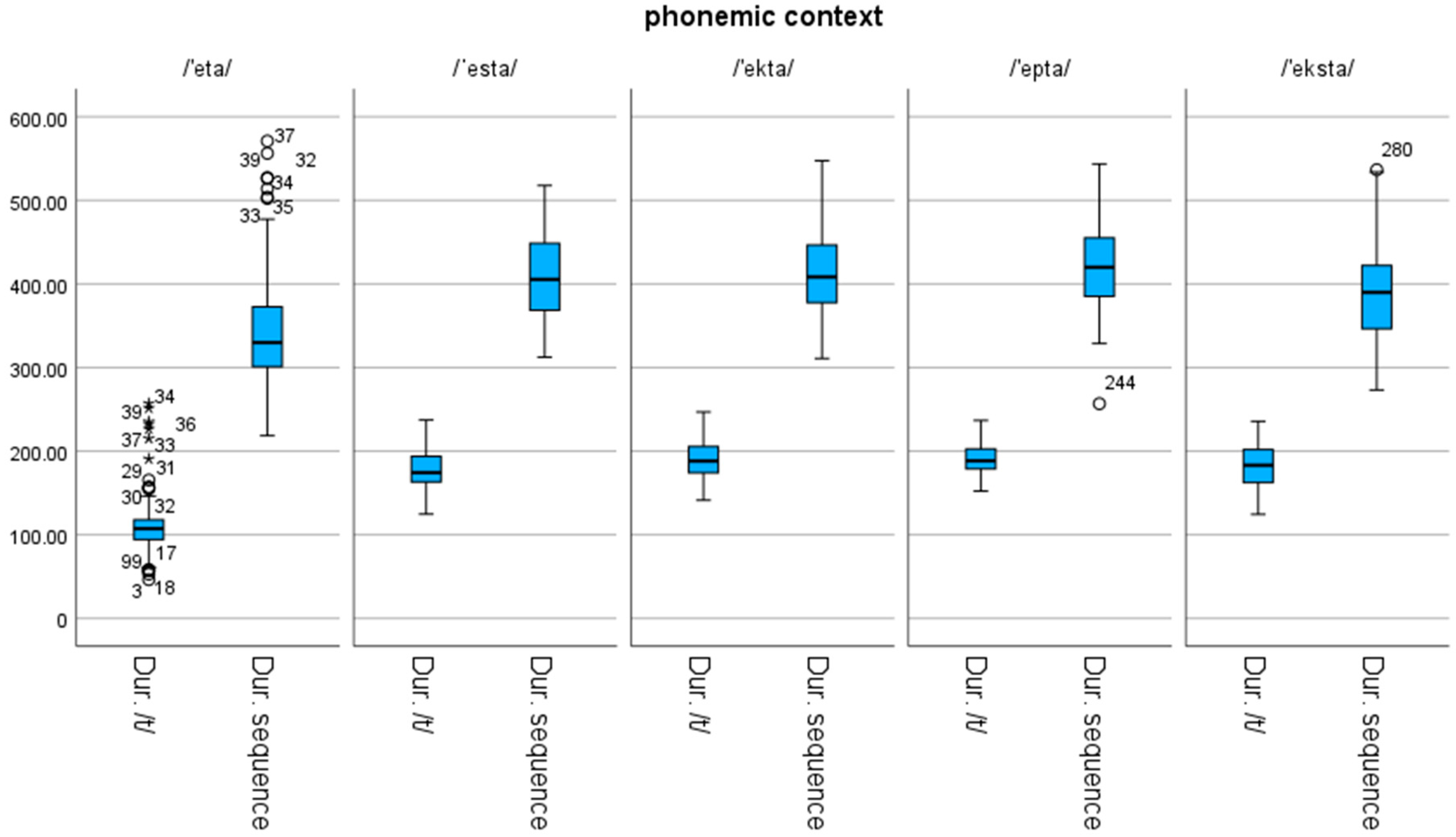
3.7. Total Duration of /t/
3.8. F1 of /a/
3.9. F2 of /a/
3.10. Duration of /a/
3.11. Overall Duration of Sequence
3.12. Identification of Phonemic Contexts from Acoustic Measures
4. Discussion
4.1. Formant Values
4.2. Durational Features
4.3. Relevance of Covariants in Gemination Cross-Linguistically
4.4. Review of the Research Questions
. However, the precise stage of evolution of these potential mergers and their implications for EAS and language evolution in general also need further consideration.5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abramson, Arthur S. 1992. Amplitude as a cue to word-initial consonant length: Pattani Malay. Haskins Laboratories Status Report on Speech Research SR-109/110: 251–54. [Google Scholar]
- Alarcos Llorach, Emilio. 1958. Fonología y fonética (a propósito de las vocales andaluzas). Archivum: Revista de la Facultad de Filología 8: 193–205. [Google Scholar]
- Al-Tamimi, Jalal, and Ghada Khattab. 2015. Acoustic cue weighting in the singleton vs geminate contrast in Lebanese Arabic: The case of fricative consonants. The Journal of the Acoustical Society of America 138: 344–60. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Baayen, R. H. 2008. Analyzing Linguistic Data. A Practical Introduction to Statistics Using R. Cambridge: Cambridge University Press. [Google Scholar]
- Bishop, Jason B. 2007. Incomplete neutralization in Eastern Andalusian Spanish: Perceptual consequences of durational differences involved in s-aspiration. In Proceedings of the International Congress of Phonetic Sciences. Edited by Jürgen Trouvain and William J. Barry. Dudweiler: Pirrot, pp. 1765–68. [Google Scholar]
- Boersma, Paul, and David Weenink. 2016. Praat: Doing Phonetics by Computer (Version Version 6.0.19). Available online: http://www.praat.org (accessed on 26 August 2016).
- Bouarourou, Fayssal, Tomoki Koya, Saïd Bouzidi, Béatrice Vaxelaire, and Rudolph Sock. 2018. Cross-language and language-specific acoustic correlates of gemination in Berber and Japanese. In 2nd International Conference on Natural Language Speech Processing. Algiers: IEEE, pp. 160–165. [Google Scholar]
- Burns, Robert, and Richard Burns. 2008. Business Research Methods and Statistics Using SPSS. London: Sage. [Google Scholar]
- Carlson, Kristin M. 2012. An acoustic and perceptual analysis of compensatory processes in vowels preceding deleted post-nuclear /s/ in Andalusian Spanish. Concentric: Literary and Cultural Studies 38: 39–67. [Google Scholar]
- Cicchetti, Domenic V. 1994. Guidelines, criteria, and rules of thumb for evaluating normed and standardized assessment instruments in psychology. Psychological Assessment 6: 284–90. [Google Scholar] [CrossRef]
- Eddington, David. 2015. Statistics for Linguists: A Step-by-Step Guide for Novices. Newcastle upon Tyne: Cambridge Scholars Publishing. [Google Scholar]
- Esposito, Anna, and Maria Gabriella Di Benedetto. 1999. Acoustical and perceptual study of gemination in Italian stops. The Journal of the Acoustical Society of America 106: 2051–62. [Google Scholar] [CrossRef] [Green Version]
- Fernández Sevilla, Julio. 1980. Los fonemas implosivos en español. Thesaurus 35: 456–505. [Google Scholar]
- Field, Andy. 2018. Discovering Statistics using IBM SPSS Statistics: North American Edition, 5th ed. Thousand Oaks: Sage. [Google Scholar]
- Gerfen, Chip. 2002. Andalusian codas. Probus 14: 247–77. [Google Scholar] [CrossRef]
- Gerfen, Chip, and Kathleen Hall. 2001. Coda Aspiration and Incomplete Neutralization in Eastern Andalusian Spanish. Manuscript, Chapel Hill: University of North Carolina at Chapel Hill. [Google Scholar]
- Hallgren, Kevin A. 2012. Computing inter-rater reliability for observational data: An overview and tutorial. Tutorials in Quantitative Methods for Psychology 8: 23–34. [Google Scholar] [CrossRef] [Green Version]
- Ham, William. 2001. Phonetic and Phonological Aspects of Geminate Timing. New York: Routledge. [Google Scholar]
- Hamzah, Mohd Hilmi, Janet Fletcher, and John Hajek. 2016. Closure duration as an acoustic correlate of the word-initial singleton/geminate consonant contrast in Kelantan Malay. Journal of Phonetics 58: 135–51. [Google Scholar] [CrossRef]
- Hedia, Sonia Ben, and Ingo Plag. 2017. Gemination and degemination in English prefixation: Phonetic evidence for morphological organization. Journal of Phonetics 62: 34–49. [Google Scholar] [CrossRef]
- Helgason, Pétur, and Catherine Ringen. 2008. Voicing and aspiration in Swedish stops. Journal of Phonetics 36: 607–28. [Google Scholar] [CrossRef]
- Henriksen, Nicholas. 2017. Patterns of vowel laxing and harmony in Iberian Spanish: Data from production and perception. Journal of Phonetics 63: 106–26. [Google Scholar] [CrossRef]
- Henriksen, Nicholas, and Sarah K. Harper. 2016. Investigating lenition patterns in south-central Peninsular Spanish /sp st sk/ clusters. Journal of the International Phonetic Association 46: 1–24. [Google Scholar] [CrossRef]
- Henriksen, Nicholas C., and Erik W Willis. 2010. Acoustic characterization of phonemic trill production in Jerezano Andalusian Spanish. In 4th Conference on Laboratory Approaches to Spanish Phonology. Edited by Marta Ortega-Llebaria. Somerville: Cascadilla Proceedings Project, pp. 115–27. [Google Scholar]
- Herrero de Haro, Alfredo. 2016. Four mid front vowels in Western Almería: The effect of /s/, /r/, and /θ/ deletion in Eastern Andalusian Spanish. Zeitschrift für Romanische Philologie 132: 118–48. [Google Scholar] [CrossRef]
- Herrero de Haro, Alfredo. 2017a. Four mid back vowels in Eastern Andalusian Spanish: The effect of /s/, /r/, and /θ/ deletion on preceding /o/ in the town of El Ejido. Zeitschrift für Romanische Philologie 133: 82–114. [Google Scholar] [CrossRef]
- Herrero de Haro, Alfredo. 2017b. The phonetics and phonology of Eastern Andalusian Spanish: A review of literature from 1881 to 2016. Íkala, Revista de Lenguaje y Cultura 22: 313–57. [Google Scholar] [CrossRef] [Green Version]
- Herrero de Haro, Alfredo. 2017c. Four low central vowels in Eastern Andalusian Spanish: /a/ before underlying /-s/, /-r/, and /-θ/ in El Ejido. Dialectologia et Geolinguistica 25: 23–50. [Google Scholar] [CrossRef] [Green Version]
- Herrero de Haro, Alfredo. 2018. Context and vowel harmony: Are they essential to identify underlying word-final /s/ in Eastern Andalusian Spanish? Dialectologia 20: 107–45. [Google Scholar]
- Herrero de Haro, Alfredo. 2019a. Consonant deletion and Eastern Andalusian Spanish vowels: The effect of word-final /s/, /r/, and /θ/ deletion on /i/. Australian Journal of Linguistics 39: 107–31. [Google Scholar] [CrossRef]
- Herrero de Haro, Alfredo. 2019b. The vowel /u/ before deleted word-final /s/, /r/, and /θ/ in Eastern Andalusian Spanish. Lengua y Habla 23: 56–75. [Google Scholar]
- Herrero de Haro, Alfredo. 2019c. Catorce vocales del andaluz oriental: Producción y percepción de /i/, /e/, /a/, /o/ y /u/ en posición final y ante /-s/, /-r/ y /-θ/ subyacentes en Almería. Nueva Revista de Filología Hispánica 67: 411–46. [Google Scholar] [CrossRef] [Green Version]
- Herrero de Haro, Alfredo, and John Hajek. 2022. Illustrations of the IPA: Eastern Andalusian Spanish. Journal of the International Phonetic Association 52: 135–56. [Google Scholar] [CrossRef]
- Herrero de Haro, Alfredo. 2023. Descripción acústica del andaluz oriental: Estado de la cuestión. In Sistematicidad y Variación en la Fonología del Español. Edited by Á. Arias. A Coruña: Editorial Axac., pp. 213–50. [Google Scholar]
- Hoole, Phil. 1999. Laryngeal coarticulation. Section A: Coarticulatory investigations of the devoicing gesture. In Coarticulation: Theory, Data and Techniques. Edited by William J. Hardcastle and Nigel Hewlett. Cambridge: Cambridge University Press, pp. 260–69. [Google Scholar]
- Idemaru, Kaori, and Susan G. Guion. 2008. Acoustic covariants of length contrast in Japanese stops. Journal of the International Phonetic Association 38: 167–86. [Google Scholar] [CrossRef]
- Jiménez Fernández, Rafael. 1999. El andaluz. Madrid: Arco/Libros. [Google Scholar]
- Khattab, Ghada, and Jalal Al-Tamimi. 2014. Geminate timing in Lebanese Arabic: The relationship between phonetic timing and phonological structure. Laboratory Phonology 5: 231–69. [Google Scholar] [CrossRef]
- Klatt, Dennis H., and William E. Cooper. 1975. Perception of segment duration in sentence contexts. In Structure and Process in Speech Perception. Edited by Antonie Cohen and Sibout G. Nooteboom. Heidelberg: Springer, pp. 69–89. [Google Scholar]
- Kluender, R. Keith, Randy L. Diehl, and Richard A. Wright. 1998. Vowel-length differences between voiced and voiceless consonants: An auditory explanation. Journal of Phonetics 16: 153–69. [Google Scholar] [CrossRef]
- Koo, Terry K., and Mae Y. Li. 2016. A guideline of selecting and reporting intraclass correlation coefficients for reliability research. Journal of Chiropractic Medicine 15: 155–63. [Google Scholar] [CrossRef] [Green Version]
- Kubozono, Haruo, ed. 2017. The Phonetics and Phonology of Geminate Consonants. Oxford: Oxford University Press. [Google Scholar]
- Landers, Richard N. 2015. Computing intraclass correlations (ICC) as estimates of interrater reliability in SPSS. The Winnower 2: 1–4. [Google Scholar]
- Local, John, and Adrian Simpson. 1999. Phonetic implementation of geminates in Malayalam nouns. In Proceedings of the 14th International Congress of Phonetic Sciences (ICPhS 14). Edited by John J. Ohala, Yoko Hasegawa, Manjari Ohala, Daniel Granville and Ashlee C. Bailey. San Francisco: University of California, pp. 595–98. [Google Scholar]
- Maddieson, Ian. 1984. Patterns of Sounds. Cambridge: Cambridge University Press. [Google Scholar]
- Maddieson, Ian. 1985. Phonetic cues to syllabification. In Phonetic Linguistics. Edited by Victoria Fromkin. London: Academic Press, pp. 203–21. [Google Scholar]
- Martínez Melgar, Antonia. 1986. Estudio experimental sobre un muestreo de vocalismo andaluz. Estudios de Fonética Experimental 2: 198–248. [Google Scholar]
- McGraw, Kenneth O., and Seok P. Wong. 1996. Forming inferences about some intraclass correlation coefficients. Psychological Methods 1: 30–46. [Google Scholar] [CrossRef]
- Méndez Dosuna, Julián. 1985. La duración de -s en los grupos sp, st, sk: A propósito del orden regular de difusión en algunos cambios fonéticos. In Symbolae Ludovico Mitxelena Septuagenario Oblatae. Edited by Luis Michelena and José Melena. Vitoria: Universidad del País Vasco, pp. 647–55. [Google Scholar]
- Monroy, Rafael, and Juan Manuel Hernández-Campoy. 2015. Illustrations of the IPA: Murcian Spanish. Journal of the International Phonetic Association 45: 229–40. [Google Scholar] [CrossRef] [Green Version]
- Morrison, Geoffrey Stewart, and Paola Escudero. 2007. A cross-dialect comparison of Peninsular- and Peruvian-Spanish vowels. In Proceedings of the 16th Congress of Phonetic Sciences. Edited by Jürgen Trouvain and William J. Barry. Saarbrücken: Universität des Saarlandes, pp. 1505–08. [Google Scholar]
- Moya Corral, Juan A. 2010. El oriente andaluz y el español común. In XVI Jornadas sobre la Lengua Española y su Enseñanza. Edited by Juan A. Moya Corral and Marcin Sosinski. Granada: Universidad de Granada, pp. 101–15. [Google Scholar]
- Nadeu, Marianna. 2016. Phonetic and phonological vowel reduction in Central Catalan. Journal of the International Phonetic Association 46: 33–60. [Google Scholar] [CrossRef]
- Navarro Tomás, Tomás. 1938. Dédoublement de phonèmes dans le dialecte andalou. Travaux du Cercle Linguistique de Prague 8: 184–86. [Google Scholar]
- Navarro Tomás, Tomás. 1939. Desdoblamiento de fonemas vocálicos. Revista de Filologia hispÁnica 1: 165–67. [Google Scholar]
- O’Neill, Paul. 2010. Variación y cambio en las consonantes oclusivas del español de Andalucía. Estudios de Fonética Experimental 19: 11–41. [Google Scholar]
- Oh, Grace E., and Melissa A. Redford. 2012. The production and phonetic representation of fake geminates in English. Journal of Phonetics 40: 82–91. [Google Scholar] [CrossRef] [Green Version]
- Parrell, Benjamin. 2012. The role of gestural phasing in Western Andalusian Spanish aspiration. Journal of Phonetics 40: 37–45. [Google Scholar] [CrossRef] [Green Version]
- Payne, E. M. 2005. Phonetic variation in Italian consonant gemination. Journal of the International Phonetic Association 35: 153–81. [Google Scholar] [CrossRef]
- Peñalver Castillo, Manuel. 2006. El habla de Cabra: Situación actual. Anuario de Estudios Filológicos 29: 247–53. [Google Scholar]
- Pickett, Emily, Sheila Blumstein, and Martha Burton. 1999. Effects of speaking rate on the singleton/geminate contrast in Italian. Phonetica 56: 135–57. [Google Scholar] [CrossRef]
- Regan, Brendan. 2017. A study of ceceo variation in Western Andalusia (Huelva). Studies in Hispanic and Lusophone Linguistics 10: 119–60. [Google Scholar] [CrossRef]
- Ridouane, Rachid, and Giuseppina Turco. 2019. Why is gemination contrast prevalently binary? Insights from Moroccan Arabic. Radical: A Journal of Phonology 1: 62–91. [Google Scholar]
- Ruch, Hanna, and Jonathan Harrington. 2014. Synchronic and diachronic factors in the change from pre-aspiration to post-aspiration in Andalusian Spanish. Journal of Phonetics 45: 12–25. [Google Scholar] [CrossRef] [Green Version]
- Ruch, Hanna, and Sandra Peters. 2016. On the origin of post-aspirated stops: Production and perception of /s/ + voiceless stop sequences in Andalusian Spanish. Laboratory Phonology: Journal of the Association for Laboratory Phonology 7: 1–36. [Google Scholar]
- Sadakata, Makiko, and James M. McQueen. 2013. High stimulus variability in nonnative speech learning supports formation of abstract categories: Evidence from Japanese geminates. The Journal of the Acoustical Society of America 134: 1324–35. [Google Scholar] [CrossRef] [Green Version]
- Scheffers, Michael. 1983. Simulation of auditory analysis of pitch: An elaboration of the DWS Pitch Meter. Journal of the Acoustical Society of America 74: 1716–25. [Google Scholar] [CrossRef] [Green Version]
- Schuchardt, Hugo. 1881. Die Cantes Flamencos. Zeitschrift für Romanische Philologie 5: 249–322. [Google Scholar] [CrossRef] [Green Version]
- Shrotriya, Nisheeth, Sada Siva Sarma, Rajesh Verma, and Shyam Sunder Agrawal. 1995. Acoustic and perceptual characteristics of geminate Hindi stop consonants. In International Conference of Phonetic Sciences. Edited by Kjell Elenius and Peter Branderud. Stockholm: Arne Strömbergs Grafiska, vol. 4, pp. 132–35. [Google Scholar]
- Stevens, Kenneth N. 1998. Acoustic Phonetics. Cambridge and London: The MIT Press. [Google Scholar]
- Stevens, Mary, and John Hajek. 2007. Towards a phonetic conspectus of preaspiration: Acoustic evidence from Sienese Italian. In Proceedings of the 16th International Congress of Phonetic Science. Edited by Jürgen Trouvain and William J. Barry. Saarbrücken: Universität des Saarlandes, pp. 429–34. [Google Scholar]
- Stevens, Mary, and John Hajek. 2010. Pre-aspirated /pp tt kk/ in standard Italian: A sociophonetic v. phonetic analysis. In 13th Australasian Annual Conference on Speech Science and Technology. Edited by Marija Tabain, Janet Fletcher, David Grayden, John Hajek and Andew Butcher. Melbourne: Australasian Speech Science and Technology Association, pp. 14–16. [Google Scholar]
- Strycharczuk, Patrycja, and Sebregts Koen. 2018. Articulatory dynamics of (de) gemination in Dutch. Journal of Phonetics 68: 138–49. [Google Scholar] [CrossRef] [Green Version]
- Takeyasu, Hahime, and Mikio Giriko. 2017. Effects of duration and phonological length of the preceding/following segments on perception of the length contract in Japanese. In The Phonetics and Phonology of Geminate Consonants. Edited by Haruo Kubozono. Oxford: Oxford University Press, pp. 85–117. [Google Scholar]
- Torreira, Francisco. 2007a. Coarticulation between aspirated-s and voiceless stops in Spanish. An interdialectal comparison. In Selected proceedings of the 9th Hispanic Linguistics Symposium. Edited by Nuria Sagarra and Almeida Jacqueline Toribio. Somerville: Cascadilla Press, pp. 113–20. [Google Scholar]
- Torreira, Francisco. 2007b. Pre-and postaspirated stops in Andalusian Spanish. In Segmental and Prosodic Issues in Romance Phonology. Edited by Pilar Prieto, Joan Mascaró and María Josep Solé. Amsterdam: Benjamins, pp. 67–82. [Google Scholar]
- Torreira, Francisco. 2012. Investigating the nature of aspirated stops in Western Andalusian Spanish. Journal of the International Phonetic Association 42: 49–63. [Google Scholar] [CrossRef] [Green Version]
- Torreira, Francisco, and Mirjam Ernestus. 2011. Realization of voiceless stops and vowels in conversational French and Spanish. Laboratory Phonology 2: 331–53. [Google Scholar] [CrossRef] [Green Version]
- Tucker, Benjamin V., and Mirjam Ernestus. 2016. Why we need to investigate casual speech to truly understand language production, processing and the mental lexicon. The Mental Lexicon 11: 375–400. [Google Scholar] [CrossRef] [Green Version]
- Turco, Giuseppina, and Bettina Braun. 2016. An acoustic study on non-local anticipatory effects of Italian length contrast. The Journal of the Acoustical Society of America 140: 2247–56. [Google Scholar]
- Turk, Alice, Satsuki Nakai, and Mariko Sugahara. 2006. Acoustic segment durations in prosodic research: A practical guide. In Methods in Empirical Prosody Research. Edited by Stefan Sudhoff, Denisa Lenertová, Roland Meyer, Sandra Pappert, Petra Augurzky, Ina Mleinek, Nicole Richter and Johannes Schließer. Berlin: Walter de Gruyter, pp. 1–27. [Google Scholar]
- Valeš, Miroslav. 2014. Panorama de la sociolingüística andaluza. Linguistica Pragensia 24: 45–54. [Google Scholar]
- Van Son, Rob J. J. H., and Louis C. W. Pols. 1990. Formant frequencies of Dutch vowels in a text, read at normal and fast rate. The Journal of the Acoustical Society of America 88: 1683–93. [Google Scholar] [CrossRef]
- Vihman, Marilyn, and Marinella Majorano. 2017. The role of geminates in infants’ early word production and word-form recognition. Journal of Child Language 44: 158–84. [Google Scholar] [CrossRef]
- Villena Ponsoda, Juan Andrés. 2000. Identidad y variación lingüística: Prestigio nacional y lealtad vernacular en el español hablado en Andalucía. In Identidades lingüísticas en la España autonómica. Edited by Georg Bossong and Francisco Báez de Aguilar González. Madrid: Iberoamericana Vervuert, pp. 107–50. [Google Scholar]
- Wallenstein, Sylvan, Christine L. Zucker, and Joseph L. Fleiss. 1980. Some statistical methods useful in circulation research. Circulation Research 47: 1–9. [Google Scholar] [CrossRef] [Green Version]
- Walley, Amanda C., and James E. Flege. 1999. Effect of lexical status on children’s and adults’ perception of native and non-native vowels. Journal of Phonetics. Journal of Phonetics 27: 307–32. [Google Scholar]
- Warren, Paul. 2018. Quality and quantity in New Zealand English vowel contrasts. Journal of the International Phonetic Association 48: 305–30. [Google Scholar] [CrossRef] [Green Version]
- Wikström, Jussi. 2013. An acoustic study of the RP English LOT and THOUGHT vowels. Journal of the International Phonetic Association 43: 37–47. [Google Scholar] [CrossRef]
 , ‘straight’, pronounced by a 38-year-old male speaker.
, ‘straight’, pronounced by a 38-year-old male speaker.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Phonemic Context | Word | Expected Phonetic Realization in EAS | Meaning |
|---|---|---|---|
| /ˈeta/ | cometa | [koˈmeta] | ‘kite’ |
| zeta | [ˈθeta] | ‘zed’ | |
| chaqueta | [tʃaˈketa] | ‘jacket’ | |
| maleta | [maˈleta] | ‘suitcase’ | |
| /ˈesta/ | honesta |  | ‘honest, feminine’ |
| resta | | ‘subtraction’ | |
| cesta |  | ‘basket’ | |
| /ˈekta/ | secta |  | ‘cult’ |
| recta | | ‘straight line’ | |
| arquitecta |  | ‘female architect’ | |
| /ˈepta/ | inepta |  | ‘inept, feminine’ |
| acepta |  | ‘she accepts’ | |
| adepta | | ‘affiliated, feminine’ | |
| /ˈeksta/ | sexta | | ‘sixth’ |
| decimosexta |  | ‘sixteenth’ |
| Male | Female | Total | |
|---|---|---|---|
| /ˈeta/ | 74 | 75 | 149 |
| /ˈesta/ | 29 | 44 | 73 |
| /ˈekta/ | 44 | 45 | 89 |
| /ˈepta/ | 45 | 28 | 73 |
| /ˈeksta/ | 30 | 30 | 60 |
| Total | 222 | 222 | 444 |
| Variable | /ˈeta/ | /ˈesta/ | /ˈekta/ | /ˈepta/ | /ˈeksta/ |
|---|---|---|---|---|---|
| F1 /e/ | 0.689/0.816 | 0.802/0.890 | 0.922/0.959 | 0.959/0.979 | 0.986/0.993 |
| F2 /e/ | 0.954/0.976 | 0.944/0.971 | 0.986/0.993 | 0.953/0.976 | 0.994/0.997 |
| Dur /e/ | 0.799/0.889 | 0.441/0.612 | 0.812/0.896 | 0.800/0.889 | 0.987/0.993 |
| Closure duration | 0.821/0.902 | 0.825/0.904 | 0.796/0.887 | 0.896/0.945 | 0.884/0.938 |
| VOT /t/ | 0.619/0.765 | 0.957/0.978 | 0.821/0.902 | 0.844/0.916 | 0.928/0.963 |
| Dur /t/ | 0.831/0.908 | 0.789/0.882 | 0.776/0.974 | 0.848/0.918 | 0.510/0.676 |
| F1 /a/ | 0.828/0.906 | 0.975/0.988 | 0.755/0.860 | 0.728/0.842 | 0.996/0.998 |
| F2 /a/ | 0.939/0.968 | 0.910/0.953 | 0.959/0.979 | 0.986/0.993 | 0.989/0.994 |
| Dur /a/ | 0.842/0.914 | 0.796/0.887 | 0.763/0.866 | 0.694/0.819 | 0.921/0.959 |
| Duration sequence | 0.870/0.930 | 0.924/0.960 | 0.875/0.933 | 0.755/0.860 | 0.978/0.989 |
| F1/e/ (Hz) | F2/e/ (Hz) | Dur /e/ (ms) | Closure (ms) | VOT (ms) | Dur /t/ (ms) | F1 /a/ (Hz) | F2 /a/ (Hz) | Dur/a/ (ms) | Total dur (ms) | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| /ˈeta/ | Male | 450 | 1945 | 99.01 | 101.98 | 17.1 | 119.08 | 663 | 1407 | 159.96 | 378.06 |
| Female | 489 | 2268 | 101.73 | 85.01 | 15.87 | 100.88 | 728 | 1640 | 106.71 | 309.33 | |
| Both | 470 | 2108 | 100.38 | 93.44 | 16.48 | 109.92 | 695 | 1524 | 133.16 | 343.46 | |
| /ˈesta/ | Male | 474 | 1870 | 84.16 (0.85) | 160.52 (1.57) | 25.10 (1.47) | 185.62 (1.56) | 679 | 1307 | 162.37 (1.02) | 432.14 (1.14) |
| Female | 509 | 2240 | 98.77 (0.97) | 145.51 (1.71) | 27.15 (1.71) | 172.66 (1.71) | 794 | 1631 | 124.39 (1.17) | 395.82 (1.28) | |
| Both | 495 | 2093 | 92.97 (0.93) | 151.47 (1.62) | 26.34 (1.6) | 177.81 (1.62) | 748 | 1502 | 139.48 (1.05) | 410.25 (1.19) | |
| /ˈekta/ | Male | 465 | 1851 | 82.28 (0.83) | 177.03 (1.74) | 20.97 (1.23) | 198.00 (1.66) | 672 | 1344 | 155.01 (0.97) | 435.29 (1.15) |
| Female | 507 | 2143 | 91.14 (0.89) | 158.27 (1.86) | 24.29 (1.53) | 182.56 (1.81) | 741 | 1639 | 119.95 (1.12) | 393.65 (1.27) | |
| Both | 486 | 1999 | 86.76 (0.86) | 167.54 (1.79) | 22.65 (1.37) | 190.19 (1.73) | 707 | 1493 | 137.28 (1.03) | 414.24 (1.21) | |
| /ˈepta/ | Male | 467 | 1938 | 89.44 (0.90) | 175.46 (1.72) | 18.51 (1.08) | 193.97 (1.63) | 693 | 1350 | 156.36 (0.98) | 435.07 (1.15) |
| Female | 533 | 2293 | 100.26 (0.99) | 162.95 (1.92) | 23.29 (1.47) | 186.24 (1.85) | 783 | 1599 | 122.56 (1.15) | 409.06 (1.32) | |
| Both | 492 | 2074 | 93.59 (0.93) | 170.66 (1.83) | 20.34 (1.23) | 191 (1.74) | 727 | 1446 | 143.39 (1.08) | 425.09 (1.24) | |
| /ˈeksta/ | Male | 471 | 1816 | 85.85 (0.87) | 163.25 (1.6) | 18.90 (1.11) | 182.15 (1.53) | 651 | 1372 | 131.57 (0.82) | 399.57 (1.06) |
| Female | 524 | 2055 | 85.65 (0.84) | 159.43 (1.88) | 23.88 (1.5) | 183.31 (1.82) | 755 | 1646 | 109.98 (1.03) | 377.95 (1.22) | |
| Both | 498 | 1936 | 85.25 (0.85) | 161.34 (1.73) | 21.39 (1.3) | 182.73 (1.66) | 703 | 1509 | 120.77 (0.91) | 388.75 (1.13) |
| Factor | /ˈeta/ | /ˈesta/ | /ˈekta/ | /ˈepta/ | /ˈeksta/ | Average |
|---|---|---|---|---|---|---|
| F1 of /e/ | 64.4% | 2.7% | 10.1% | 2.7% | 48.3% | 25.6% |
| Duration of /e/ | 52.3% | 1.4% | 5.6% | 11% | 60% | 26.1% |
| Closure duration | 90.6% | 54.8% | 6.7% | 45.2% | 15.1% | 42.5% |
| VOT of /t/ | 65.1% | 52.1% | 6.7% | 5.5% | 3.3% | 26.54% |
| Total duration of /t/ | 91.9% | 56.2% | 9.0% | 43.8% | 8.3% | 41.84% |
| Total duration of sequence | 72.5% | 15.1% | 5.6% | 4.1% | 26.7% | 24.8% |
| Average | 72.80% | 30.38% | 7.28% | 18.72% | 26.95% | 31.23% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Herrero de Haro, A.; Hajek, J. Covariants of Gemination in Eastern Andalusian Spanish: /t/ following Underlying /s/, /k/, /p/ and /ks/. Languages 2023, 8, 99. https://doi.org/10.3390/languages8020099
Herrero de Haro A, Hajek J. Covariants of Gemination in Eastern Andalusian Spanish: /t/ following Underlying /s/, /k/, /p/ and /ks/. Languages. 2023; 8(2):99. https://doi.org/10.3390/languages8020099
Chicago/Turabian StyleHerrero de Haro, Alfredo, and John Hajek. 2023. "Covariants of Gemination in Eastern Andalusian Spanish: /t/ following Underlying /s/, /k/, /p/ and /ks/" Languages 8, no. 2: 99. https://doi.org/10.3390/languages8020099