
Conceptual Number in Bilingual Agreement Computation: Evidence from German Pseudo-Partitives


Abstract
:1. Introduction
| (1) | Eine | Tüte | Nüsse | kostet/kosten | zwei | Euro. |
| one | bag | nuts | costs/cost | two | Euros | |
| ‘One bag of nuts costs/cost two Euros.’ | ||||||
1.1. Grammatical versus Conceptual Number in Subject–Verb Agreement
| (2) | a. | the key to the cabinets |
| b. | a bunch of flowers | |
| c. | neither Paul nor Ringo |
| (3) | a. | the key to the cabinets | [non-distributive reading, notionally singular] |
| b. | the label on the bottles | [distributive reading, notionally plural] |
1.2. Agreement with Pseudo-Partitives in German
| (4) | a. | eine | Tüte | Nüsse | [singular–plural pseudo-partitive, container NP1] |
| one | bag | nuts | |||
| ‘one bag of nuts’ | |||||
| b. | zwei | Tüten | Nüsse | [plural-plural pseudo-partitive, container NP1] | |
| two | bags | nuts | |||
| ‘two bags of nuts’ | |||||
| (5) | zwei | Pfund | Nüsse | [plural-plural pseudo-partitive, measure NP1] | |
| two | pound | nuts | |||
| ‘two pounds of nuts’ | |||||
| (6) | zwei | Pfund | Mehl | [plural-singular pseudo-partitive, measure NP1] | |
| two | pound | flour | |||
| ‘two pounds of flour’ | |||||
1.3. Conceptual Number in Bilingual Agreement Computation
1.4. The Present Study
| (7) | iki | kutu | elma |
| two | box | apple | |
| ‘two boxes of apples’ | |||
| I. | (a) | When computing agreement with German pseudo-partitives, do speakers use |
| the first (NP1) or the second noun phrase (NP2) as the agreement controller? | ||
| (b) | Do L1 speakers and early bilinguals differ in their preference for NP1 versus | |
| NP2 as the agreement controller? | ||
| II. | (a) | What is the role of conceptual number in agreement computation |
| (operationalized through different types of NP1 and notional-number ratings)? | ||
| (b) | Does the role of conceptual number in agreement computation differ for L1 | |
| speakers versus early bilinguals? |
2. Method
2.1. Participants
2.2. Materials
2.2.1. Sentence Completion Task
2.2.2. Plurality-Rating Task
2.3. Procedure
2.4. Analyses
3. Results
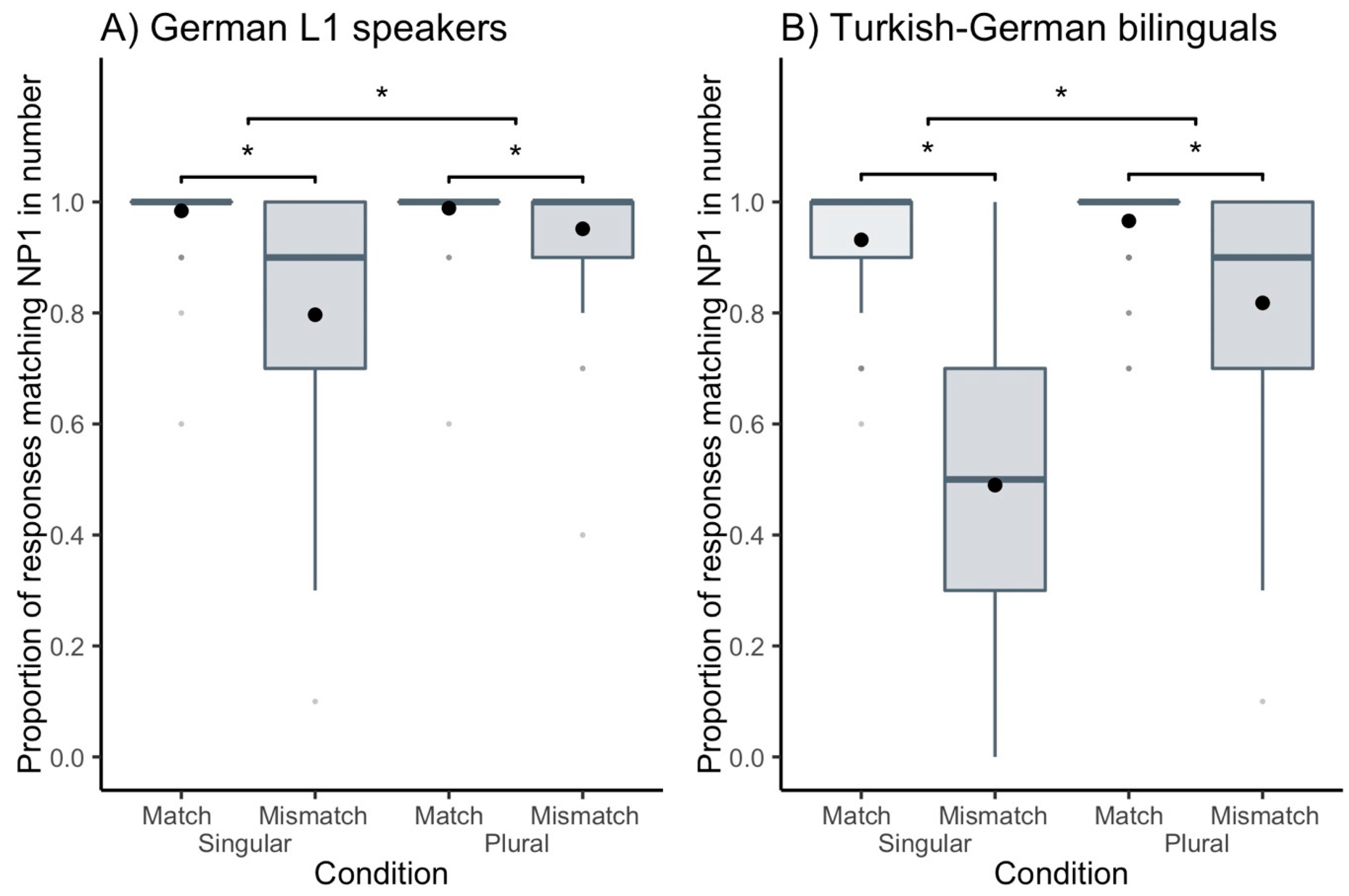
3.1. Analysis I: Across All Items
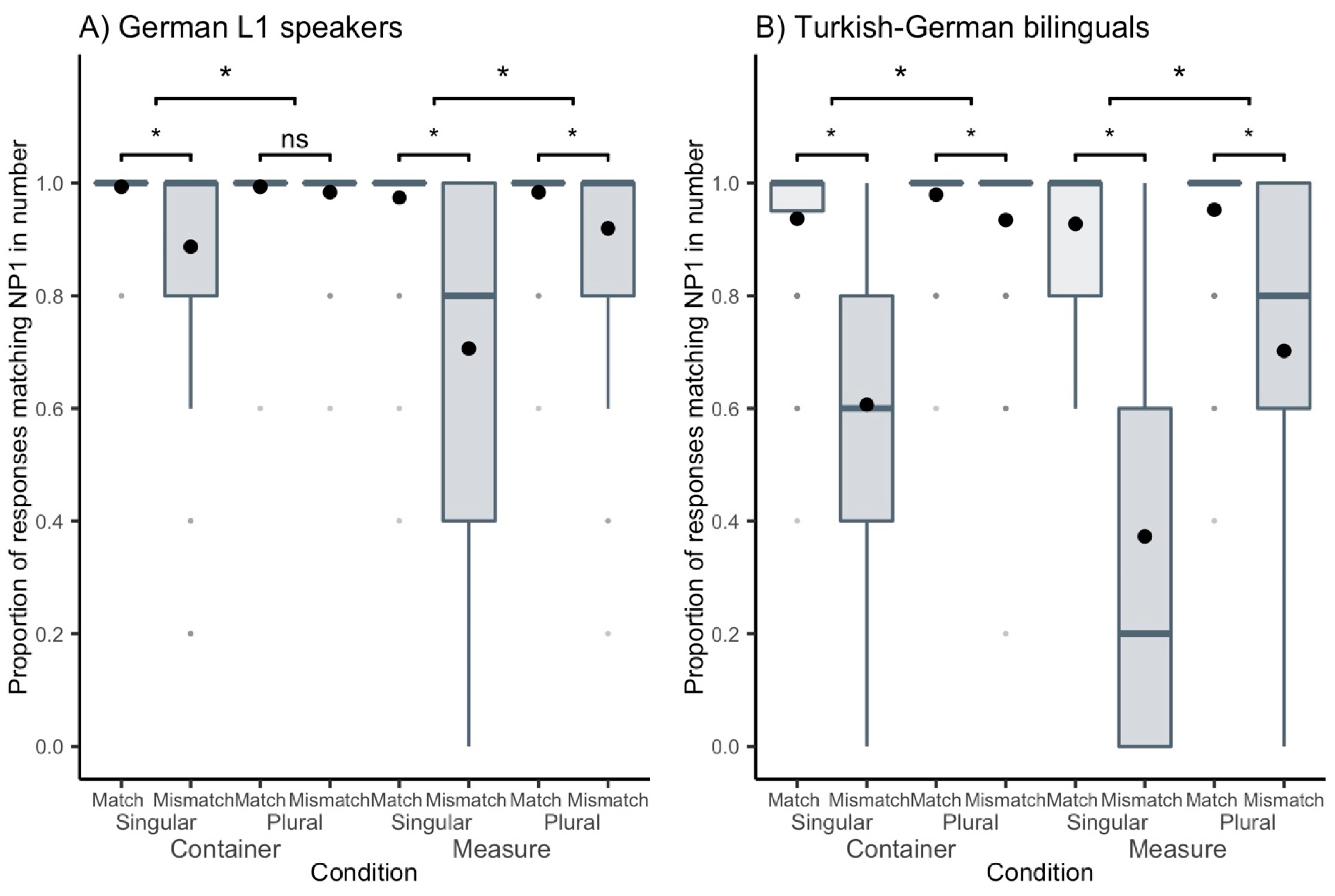
3.2. Analysis II: Semantic Category
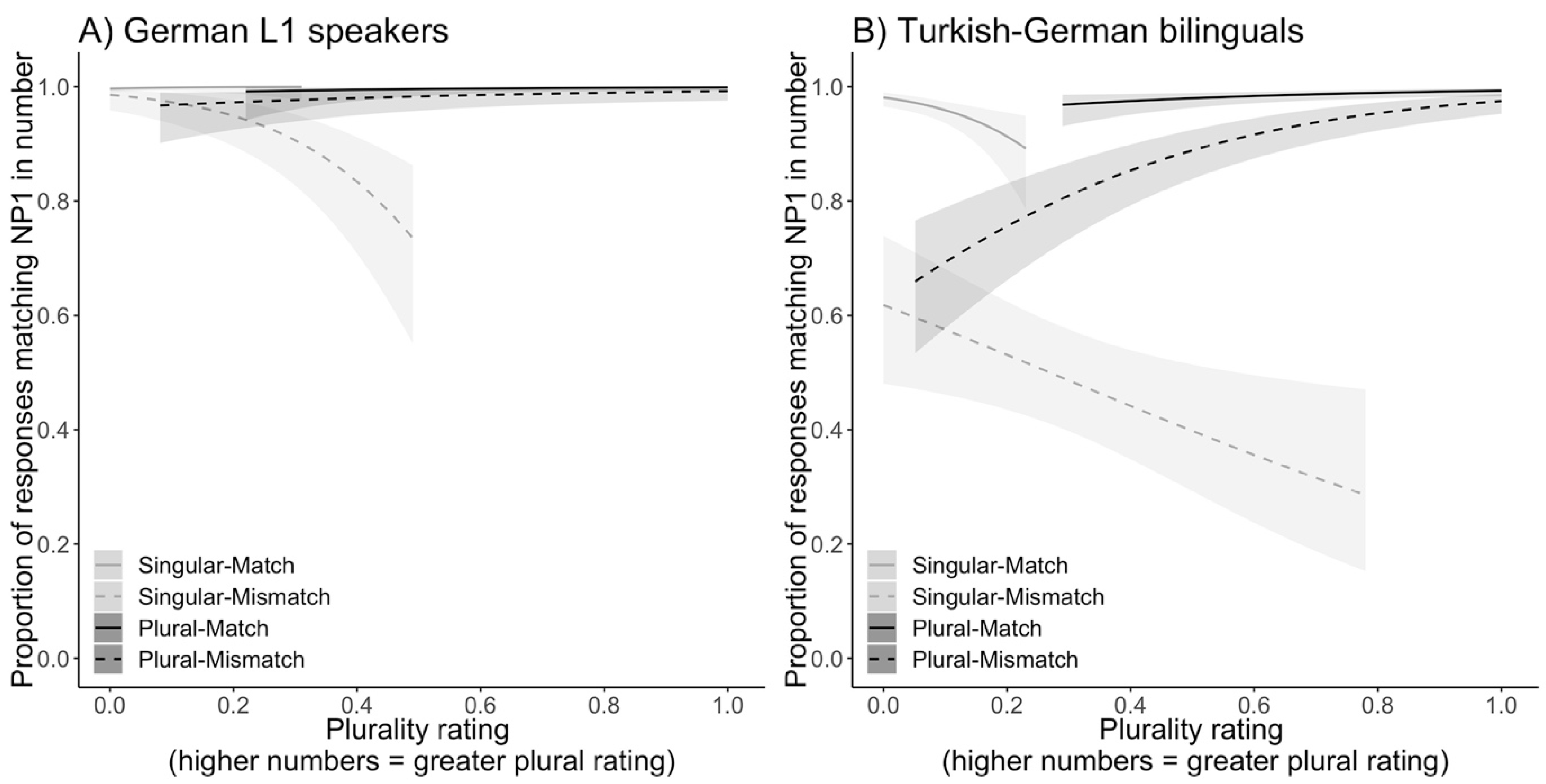
3.3. Analysis III: Plurality Ratings
4. Discussion
| I. | (a) | When computing agreement with German pseudo-partitives, do speakers use |
| the first (NP1) or the second noun phrase (NP2) as the agreement controller? | ||
| (b) | Do L1 speakers and early bilinguals differ in their preference for NP1 versus | |
| NP2 as the agreement controller? | ||
| II. | (a) | What is the role of conceptual number in agreement computation |
| operationalized through different types of NP1 and notional-number ratings)? | ||
| (b) | Does the role of conceptual number in agreement computation differ for L1 | |
| speakers versus early bilinguals? |
4.1. Pseudo-Partitive Agreement in Native Speakers and Early Bilinguals
4.2. The Role of Conceptual Number in Pseudo-Partitive Agreement
4.3. Limitations and Future Directions
4.4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | The word eine (masculine and neuter ein) can be interpreted as either the indefinite article ‘a’ or the numeral ‘one.’ Importantly, in either case it denotes a singular entity. For brevity, we will use the translation ‘one’ throughout the manuscript. |
| 2 | The statistics reported in the paper are not designed to answer this specific question. |
| 3 | For example, measures that are often encountered as containers of that size might yield container readings. Speakers in Europe may more readily interpret a liter of milk as a container of milk of that size than a gallon of milk, while the reverse might be the case for speakers in the U.S. Conversely, certain measure terms are derived from container words (e.g., Tonne in German, which means both the container ‘barrel’ and the measure ‘tonne’). Some words may even equally likely represent a container or a measure (e.g., cup in English), or their interpretation may depend on the NP2 (e.g., a cup of tea vs. a cup of flour). |
| 4 | The ages-of-arrival in Germany for these three participants were five years, two years, and less than one year of age, respectively. |
| 5 | In the interest of conciseness and clarity, statistics for follow-up analyses to interactions at the lowest level are presented in Supplementary Materials (see table notes). |
| 6 | It is worth noting that the bilingual group in our study likely differed from the L1 speakers regarding the amount and nature of (especially early-life) exposure to German, as German was not necessarily the (only) language of the household, or they may have been exposed to a different variety of German as compared to the L1 speakers. This point is particularly relevant considering experimental work indicating that language experience can shape agreement preferences via long-term statistical learning of distributional patterns (Haskell et al. 2010). However, it is presently not clear why the language environment our bilingual group was exposed to during childhood might be expected to show distributional properties that render this group more prone to using notional number during agreement computation than the L1 speaker group. |
| 7 | We are thankful to an anonymous reviewer for this phrasing. |
References
- Alarcón, Irma. 2021. Adjectival and verbal agreement in the oral production of early and late bilinguals: Fluency, complexity, and integrated knowledge. Revista Española de Lingüística Aplicada/Spanish Journal of Applied Linguistics 34: 371–401. [Google Scholar] [CrossRef]
- Altman, Douglas G., and Patrick Royston. 2006. The cost of dichotomising continuous variables. British Medical Journal 332: 1080. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Balota, David A., Michael J. Cortese, Susan D. Sergent-Marshall, David H. Spieler, and Melvin J. Yap. 2004. Visual word recognition of single-syllable words. Journal of Experimental Psychology: General 133: 283–316. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barr, Dale J., Roger Levy, Christoph Scheepers, and Harry J. Tily. 2013. Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language 68: 255–78. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bates, Douglas M., Martin Mächler, Benjamin M. Bolker, and Steven C. Walker. 2015. Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67: 1–48. [Google Scholar] [CrossRef]
- Bauer, Laurie. 1994. Watching English change: An introduction to the study of linguistic change in Standard Englishes in the twentieth century. In Watching English Change. London: Routledge. [Google Scholar] [CrossRef]
- Bock, Kathryn, Kathleen M. Eberhard, J. Cooper Cutting, Antje S. Meyer, and Herbert J. Schriefers. 2001. Some attractions of verb agreement. Cognitive Psychology 43: 83–128. [Google Scholar] [CrossRef]
- Bock, Kathryn, and Carol A. Miller. 1991. Broken agreement. Cognitive Psychology 23: 45–93. [Google Scholar] [CrossRef]
- Brehm, Laurel, and Kathryn Bock. 2013. What counts in grammatical number agreement? Cognition 128: 149–69. [Google Scholar] [CrossRef] [Green Version]
- Brehm, Laurel, Pyeong Whan Cho, Paul Smolensky, and Matthew A. Goldrick. 2022. PIPS: A Parallel Planning Model of Sentence Production. Cognitive Science 46: e13079. [Google Scholar] [CrossRef]
- Chen, Lang, Hua Shu, Youyi Liu, Jingjing Zhao, and Ping Li. 2007. ERP signatures of subject–verb agreement in L2 learning. Bilingualism: Language and Cognition 10: 161–74. [Google Scholar] [CrossRef] [Green Version]
- Christianson, Kiel, Carrick C. Williams, Rose T. Zacks, and Fernanda Ferreira. 2006. Younger and older adults’ “good-enough” interpretations of garden-path sentences. Discourse Processes 42: 205–38. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Clahsen, Harald, and Claudia Felser. 2018. Some notes on the Shallow Structure Hypothesis. Studies in Second Language Acquisition 40: 693–706. [Google Scholar] [CrossRef]
- Cunnings, Ian. 2017. Parsing and working memory in bilingual sentence processing. Bilingualism: Language and Cognition 20: 659–78. [Google Scholar] [CrossRef]
- Dekeyser, Xavier. 1975. Number and Case Relations in 19th Century British English: A Comparative Study of Grammar and Usage. Amsterdam: De Nederlandsche Boekhandel. [Google Scholar]
- Depraetere, Ilse. 2003. On verbal concord with collective nouns in British English. English Language and Linguistics 7: 85–127. [Google Scholar] [CrossRef]
- Eberhard, Kathleen M. 1997. The marked effect of number on subject–verb agreement. Journal of Memory and Language 36: 147–64. [Google Scholar] [CrossRef]
- Eberhard, Kathleen M., J. Cooper Cutting, and Kathryn Bock. 2005. Making syntax of sense: Number agreement in sentence production. Psychological Review 112: 531–59. [Google Scholar] [CrossRef] [Green Version]
- Foote, Rebecca. 2010. Age of acquisition and proficiency as factors in language production: Agreement in bilinguals. Bilingualism: Language and Cognition 13: 99–118. [Google Scholar] [CrossRef]
- Foote, Rebecca. 2011. Integrated knowledge of agreement in early and late English–Spanish bilinguals. Applied Psycholinguistics 32: 187–220. [Google Scholar] [CrossRef]
- Gangopadhyay, Ishanti, Meghan M. Davidson, Susan Ellis Weismer, and Margarita Kaushanskaya. 2016. The role of nonverbal working memory in morphosyntactic processing by school-aged monolingual and bilingual children. Journal of Experimental Child Psychology 142: 171–94. [Google Scholar] [CrossRef] [Green Version]
- Gillespie, Maureen, and Neal J. Pearlmutter. 2011. Effects of semantic integration and advance planning on grammatical encoding in sentence production. In Proceedings of the 33rd Annual Conference of the Cognitive Science Society. Edited by Laura A. Carlson, Christoph Hoelscher and Thomas F. Shipley. Austin: Cognitive Science Society, pp. 1625–30. [Google Scholar]
- Grestenberger, Laura. 2015. Number marking in German measure phrases and the structure of pseudo-partitives. Journal of Comparative Germanic Linguistics 18: 93–138. [Google Scholar] [CrossRef]
- Grosjean, François. 2001. The bilingual’s language modes. In One Mind, Two Languages: Bilingual Language Processing. Edited by Janet L. Nicol. Hoboken: Wiley Blackwell, pp. 1–22. [Google Scholar] [CrossRef]
- Hacohen, Aviya, and Jeannette Schaeffer. 2007. Subject realization in early Hebrew/English bilingual acquisition: The role of crosslinguistic influence. Bilingualism: Language and Cognition 10: 333–44. [Google Scholar] [CrossRef] [Green Version]
- Hartsuiker, Robert J., and Pashiera Barkhuysen. 2006. Language production and working memory: The case of subject-verb agreement. Language and Cognitive Processes 21: 181–204. [Google Scholar] [CrossRef]
- Haskell, Todd R., Robert Thornton, and Maryellen C. MacDonald. 2010. Experience and grammatical agreement: Statistical learning shapes number agreement production. Cognition 114: 151–64. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hennig, Mathilde, Jan G. Schneider, Ralf Osterwinter, and Anja Steinhauer. 2016. Duden—Das Wörterbuch der sprachlichen Zweifelsfälle. In Der Duden in zwölf Bänden—Das Standardwerk der deutschen Sprache. Edited by Mathilde Hennig. Berlin: Dudenverlag, Band 9. [Google Scholar]
- Hopp, Holger. 2006. Syntactic features and reanalysis in near-native processing. Second Language Research 22: 369–97. [Google Scholar] [CrossRef] [Green Version]
- Hopp, Holger. 2010. Ultimate attainment in L2 inflection: Performance similarities between non-native and native speakers. Lingua 120: 901–31. [Google Scholar] [CrossRef]
- Hoshino, Noriko, Paola E. Dussias, and Judith F. Kroll. 2010. Processing subject–verb agreement in a second language depends on proficiency. Bilingualism: Language and Cognition 13: 87–98. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jackson, Carrie N., Elizabeth Mormer, and Laurel Brehm. 2018. The production of subject-verb agreement among Swedish and Chinese second language speakers of English. Studies in Second Language Acquisition 40: 907–21. [Google Scholar] [CrossRef] [Green Version]
- Jaeger, Christoph. 1992. Probleme der syntaktischen Kongruenz. Tübingen: Niemeyer. [Google Scholar]
- Jessen, Anna, Lara Schwarz, and Claudia Felser. 2021. Gradience in subject-verb number agreement: Can bilinguals tune in? Applied Psycholinguistics 42: 1523–51. [Google Scholar] [CrossRef]
- Juul, Arne. 1975. On Concord of Number in Modern English. Copenhagen: Nova. [Google Scholar]
- Kandel, Margaret, Cassidy R. Wyatt, and Colin Phillips. 2022. Agreement attraction error and timing profiles in continuous speech. Glossa Psycholinguistics 1: 1–46. [Google Scholar] [CrossRef]
- Keating, Gregory D. 2009. Sensitivity to violations of gender agreement in native and nonnative Spanish: An eye-movement investigation. Language Learning 59: 503–35. [Google Scholar] [CrossRef]
- Kornfilt, Jaklin. 1997. Turkish. London: Routledge. [Google Scholar]
- Lardiere, Donna. 1998. Dissociating syntax from morphology in a divergent L2 end-state grammar. Second Language Research 14: 359–75. [Google Scholar] [CrossRef]
- Lehtonen, Minna, Valantis Fyndanis, and Jussa Jylkkä. 2023. The relationship between bilingual language use and executive functions. Nature Reviews Neuroscience. [Google Scholar] [CrossRef]
- Levin, Magnus. 2001. Agreement with Collective Nouns in English. Lund: Lund University. [Google Scholar]
- Levin, Magnus. 2006. Collective nouns and language change. English Language and Linguistics 10: 321–43. [Google Scholar] [CrossRef]
- Liedtke, Ernst A. 1910. Die numerale Auffassung der Kollektiva im Verlaufe der englischen Sprachgeschichte. Königsberg: Karg and Manneck. [Google Scholar]
- Lorimor, Heidi. 2007. Conjunctions and Grammatical Agreement. Champaign: University of Illinois at Urbana-Champaign. [Google Scholar]
- Lorimor, Heidi, Carrie N. Jackson, Katharina Spalek, and Janet G. van Hell. 2016. The impact of notional number and grammatical gender on number agreement with conjoined noun phrases. Language, Cognition and Neuroscience 31: 646–61. [Google Scholar] [CrossRef]
- Mallinson, Graham, and Barry Blake. 1981. Language Typology: Crosslinguistic Studies in Syntax. Amsterdam: North Holland. [Google Scholar]
- McDonald, Janet L. 2006. Beyond the critical period: Processing-based explanations for poor grammaticality judgment performance by late second language learners. Journal of Memory and Language 55: 381–401. [Google Scholar] [CrossRef]
- McDonald, Janet L., and Christine C. Roussel. 2010. Past tense grammaticality judgment and production in non-native and stressed native English speakers. Bilingualism: Language and Cognition 13: 429–48. [Google Scholar] [CrossRef]
- Nicol, Janet L., and Delia Greth. 2003. Production of subject-verb agreement in Spanish as a second language. Experimental Psychology 50: 196–203. [Google Scholar] [CrossRef]
- Nicol, Janet L., Matthew Teller, and Delia Greth. 2001. The production of verb agreement in monolingual, bilingual, and second language speakers. In One Mind, Two Languages: Bilingual Language Processing. Edited by Janet L. Nicol. Oxford: Blackwell, pp. 117–33. [Google Scholar]
- Prehn, Kristin, Benedikt Taud, Jana Reifegerste, Harald Clahsen, and Agnes Flöel. 2018. Neural correlates of grammatical inflection in older native and second-language speakers. Bilingualism: Language and Cognition 21: 1–12. [Google Scholar] [CrossRef] [Green Version]
- Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech, and Jan Svartnik. 1985. A Comprehensive Grammar of the English Language. London: Longman House. [Google Scholar] [CrossRef]
- Reifegerste, Jana, Lauren E. Russell, David A. Balota, Daniel Lipscomb, George Luta, Marcus Meinzer, Michael D. Rugg, Kyle F. Shattuck, Peter E. Turkeltaub, Ashley S. VanMeter, and et al. 2022. What’s that word again? The contribution of the hippocampus to word-finding declines in aging. Paper Presented at the 2022 Cognitive Aging Conference, Atlanta, GA, USA, April 7–10. [Google Scholar]
- Reifegerste, Jana, Rebecca Jarvis, and Claudia Felser. 2020. Effects of chronological age on native and nonnative sentence processing: Evidence from subject-verb agreement in German. Journal of Memory and Language 111: 104083. [Google Scholar] [CrossRef]
- Royston, Patrick, Douglas G. Altman, and Willi Sauerbrei. 2006. Dichotomizing continuous predictors in multiple regression: A bad idea. Statistics in Medicine 25: 127–41. [Google Scholar] [CrossRef] [PubMed]
- Sagarra, Nuria, and Julia Herschensohn. 2010. The role of proficiency and working memory in gender and number agreement processing in L1 and L2 Spanish. Lingua 120: 2022–39. [Google Scholar] [CrossRef]
- Sato, Mikako, and Claudia Felser. 2010. Sensitivity to morphosyntactic violations in English as a second language. Second Language 9: 101–18. [Google Scholar]
- Scontras, Gregory. 2014. The Semantics of Measurement. Cambridge: Harvard University. [Google Scholar]
- Selkirk, Elisabeth O. 1977. Some remarks on noun phrase structure. In Studies in Formal Syntax. Edited by Adrian Akmajian, Peter Culicover and Thomas A. Wasow. New York: Academic Press. [Google Scholar]
- Shibuya, Mayumi, and Shigenori Wakabayashi. 2008. Why are L2 learners not always sensitive to subject-verb agreement? EUROSLA Yearbook 8: 235–58. [Google Scholar] [CrossRef]
- Siemund, Rainer. 1995. “For who the bell tolls”—Or why corpus linguistics should carry the bell in the study of language change in present-day English. Arbeiten aus Anglistik und Amerikanistik 20: 351–77. [Google Scholar]
- Smith, Garrett, Julie Franck, and Whitney Tabor. 2018. A self-organizing approach to subject–verb number agreement. Cognitive Science 42: 1043–74. [Google Scholar] [CrossRef] [Green Version]
- Smolensky, Paul, Matthew Goldrick, and Donald Mathis. 2014. Optimization and quantization in gradient symbol systems: A framework for integrating the continuous and the discrete in cognition. Cognitive Science 38: 1102–38. [Google Scholar] [CrossRef]
- Solomon, Eric S., and Neal J. Pearlmutter. 2004. Semantic integration and syntactic planning in language production. Cognitive Psychology 49: 1–46. [Google Scholar] [CrossRef]
- Staub, Adrian. 2009. On the interpretation of the number attraction effect: Response time evidence. Journal of Memory and Language 60: 308–27. [Google Scholar] [CrossRef] [Green Version]
- Staub, Adrian. 2010. Response time distributional evidence for distinct varieties of number attraction. Cognition 114: 447–54. [Google Scholar] [CrossRef] [PubMed]
- Stickney, Helen. 2009. The Emergence of DP in the Partitive Structure. Amherst: University of Massachusetts Amherst. [Google Scholar]
- VanPatten, Bill, Gregory D. Keating, and Michael J. Leeser. 2012. Missing verbal inflections as a representational problem: Evidence from self-paced reading. Linguistic Approaches to Bilingualism 2: 109–40. [Google Scholar] [CrossRef]
- Veenstra, Alma, Daniel J. Acheson, and Antje S. Meyer. 2014a. Keeping it simple: Studying grammatical encoding with lexically reduced item sets. Frontiers in Psychology 5: 783. [Google Scholar] [CrossRef] [Green Version]
- Veenstra, Alma, Daniel J. Acheson, Kathryn Bock, and Antje S. Meyer. 2014b. Effects of semantic integration on subject–verb agreement: Evidence from Dutch. Language, Cognition and Neuroscience 29: 355–80. [Google Scholar] [CrossRef]
- Vigliocco, Gabriella, Brian Butterworth, and Carlo Semenza. 1995. Constructing subject-verb agreement in speech: The role of semantic and morphological factors. Journal of Memory and Language 34: 186–215. [Google Scholar] [CrossRef] [Green Version]
- Vigliocco, Gabriella, Brian Butterworth, and Merrill F. Garrett. 1996a. Subject-verb agreement in Spanish and English: Differences in the role of conceptual constraints. Cognition 61: 261–98. [Google Scholar] [CrossRef]
- Vigliocco, Gabriella, Robert J. Hartsuiker, Gonia Jarema, and Herman H. J. Kolk. 1996b. One or more labels on the bottles? Notional concord in Dutch and French. Language and Cognitive Processes 11: 407–42. [Google Scholar] [CrossRef] [Green Version]
- Villata, Sandra, and Julie Franck. 2020. Similarity-based interference in agreement comprehension and production: Evidence from object agreement. Journal of Experimental Psychology: Learning Memory and Cognition 46: 170–88. [Google Scholar] [CrossRef]
- Villata, Sandra, and Whitney Tabor. 2022. A self-organized sentence processing theory of gradience: The case of islands. Cognition 222: 104943. [Google Scholar] [CrossRef]
- Wegerer, Martina. 2012. Die Numeruskongruenz von Subjekt und finitem Verb im Deutschen: Untersuchung der grammatischen Entscheidungsprozeduren bei zweifelhafter Kongruenzrelationen. Wien: University of Vienna. [Google Scholar]
- Wei, Xiaoyan, Baoguo Chen, Lijuan Liang, and Susan Dunlap. 2015. Native language influence on the distributive effect in producing second language subject–verb agreement. Quarterly Journal of Experimental Psychology 68: 2370–83. [Google Scholar] [CrossRef]
- Wickham, Hadley. 2016. ggplot2: Elegant Graphics for Data Analysis. New York: Springer-Verlag. [Google Scholar]
- Wood, Taffeta, Amy S. Pratt, Kathleen Durant, Stephanie McMillen, Elizabeth D. Peña, and Lisa M. Bedore. 2021. Contribution of nonverbal cognitive skills on bilingual children’s grammatical performance: Influence of exposure, task type, and language of assessment. Languages 6: 36. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| L1 Speakers | Bilinguals | Group Differences | |||
|---|---|---|---|---|---|
| Demographic information | |||||
| n | 62 | 88 | |||
| Age | 35.5 (14.3) | 27.1 (6.7) | t(149) = 4.82, p < 0.001 | ||
| Sex | female | 42 | 65 | χ2(1, N = 150) = 0.67, p = 0.414 | |
| male | 20 | 23 | |||
| Education (highest degree) | less than 12 years | 3 | 5 | χ2(4, N = 150) = 7.56, p = 0.109 | |
| high school diploma | 13 | 29 | |||
| vocational training | 4 | 6 | |||
| Bachelor’s degree | 16 | 29 | |||
| Master’s degree and above | 26 | 19 | |||
| Language information | German | Turkish | Differences between languages | ||
| Age-of-acquisition | since birth | – | 36 | 86 | χ2(1, N = 88) = 66.79, p < 0.001 |
| during early childhood (before primary school) | – | 52 | 2 | ||
| Language skills (out of 10) | Speaking | – | 9.4 (0.8) | 8.5 (1.3) | t(87) = 6.13, p < 0.001 |
| Listening | – | 9.7 (0.8) | 9.2 (1.0) | t(87) = 4.00, p < 0.001 | |
| Writing | – | 9.5 (1.0) | 8.0 (1.8) | t(87) = 6.59, p < 0.001 | |
| Reading | – | 9.7 (0.7) | 8.7 (1.6) | t(87) = 5.90, p < 0.001 | |
| Overall | – | 9.6 (0.7) | 8.6 (1.2) | t(87) = 6.65, p < 0.001 | |
| Enjoyment (out of 5) | – | 4.4 (0.8) | 4.5 (0.6) | t(87) = 0.43, p = 0.669 | |
| Semantic Category | Condition | Preamble | NP1 | NP2 | Verb | Auxiliary | ||
|---|---|---|---|---|---|---|---|---|
| SG | PL | |||||||
| Container | Singular-Match | Oskar glaubt, dass Oskar thinks that | eine one | Schüssel bowl | Joghurt yogurt | gegessen eaten | wurde. was. | *wurden. *were. |
| Singular-Mismatch | Oskar glaubt, dass Oskar thinks that | eine one | Schüssel bowl | Beeren berries | gegessen eaten | wurde. was. | wurden. were. | |
| Plural-Match | Oskar glaubt, dass Oskar thinks that | vier four | Schüsseln bowls | Beeren berries | gegessen eaten | *wurde. *was. | wurden. were. | |
| Plural-Mismatch | Oskar glaubt, dass Oskar thinks that | vier four | Schüsseln bowls | Joghurt yogurt | gegessen eaten | wurde. was. | wurden. were. | |
| Measure | Singular-Match | Sophia sagt, dass Sophia says that | ein one | Pfund pound | Mehl flour | bestellt ordered | ist. is. | *sind. *are. |
| Singular-Mismatch | Sophia sagt, dass Sophia says that | ein one | Pfund pound | Nüsse nuts | bestellt ordered | ist. is. | sind. are. | |
| Plural-Match | Sophia sagt, dass Sophia says that | drei three | Pfund pound | Nüsse nuts | bestellt ordered | *ist. *is. | sind. are. | |
| Plural-Mismatch | Sophia sagt, dass Sophia says that | drei three | Pfund pound | Mehl flour | bestellt ordered | ist. is. | sind. are. | |
| Proportion of Responses Matching the Number of NP1 | L1 Speakers | Bilinguals | |||||
|---|---|---|---|---|---|---|---|
| NP1 Number | NP1 Number | ||||||
| SG | PL | average | SG | PL | average | ||
| Match | match | 0.984 (0.126) | 0.989 (0.106) | 0.986 (0.116) | 0.932 (0.252) | 0.966 (0.182) | 0.949 (0.220) |
| mismatch | 0.797 (0.403) | 0.952 (0.215) | 0.874 (0.332) | 0.490 (0.500) | 0.818 (0.386) | 0.654 (0.476) | |
| average | 0.890 (0.313) | 0.970 (0.170) | 0.930 (0.255) | 0.711 (0.454) | 0.892 (0.310) | 0.801 (0.399) | |
| Effect of Match (Difference match vs. mismatch) | 0.187 | 0.037 | 0.112 | 0.442 | 0.148 | 0.295 | |
| Random Effects | Variance | SD | Correlation | ||||
| subjects | Intercept | 1.2918 | 1.1366 | ||||
| NP1 Number | 3.0084 | 1.7345 | −0.15 | ||||
| items | Intercept | 0.7172 | 0.8469 | ||||
| Fixed Effects | b | SE | z-Value | p-Value | |||
| Intercept | 3.4568 | 0.2019 | 17.12 | <0.001 | |||
| NP1 Number | 1.2450 | 0.2631 | 4.73 | <0.001 | |||
| Match | −2.7643 | 0.1712 | −16.15 | <0.001 | |||
| Group | 1.9420 | 0.2699 | 7.20 | <0.001 | |||
| NP1 Number × Match | 1.5601 | 0.3343 | 4.67 | <0.001 | |||
| NP1 Number × Group | −0.3849 | 0.4758 | −0.81 | 0.419 | |||
| Match × Group | 0.2691 | 0.3292 | 0.82 | 0.414 | |||
| NP1 Number × Match × Group | 0.3911 | 0.6578 | 0.60 | 0.552 | |||
| Proportion of Responses Matching the Number of NP1 | L1 Speakers | Bilinguals | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Container | Measure | Container | Measure | ||||||||||
| NP1 Number | NP1 Number | NP1 Number | NP1 Number | ||||||||||
| SG | PL | average | SG | PL | average | SG | PL | average | SG | PL | average | ||
| Match | match | 0.994 (0.080) | 0.994 (0.080) | 0.994 (0.080) | 0.974 (0.159) | 0.984 (0.126) | 0.979 (0.143) | 0.936 (0.244) | 0.980 (0.142) | 0.958 (0.201) | 0.927 (0.260) | 0.952 (0.213) | 0.940 (0.238) |
| mismatch | 0.887 (0.317) | 0.984 (0.126) | 0.935 (0.246) | 0.706 (0.456) | 0.919 (0.273) | 0.813 (0.390) | 0.607 (0.489) | 0.934 (0.248) | 0.770 (0.421) | 0.373 (0.484) | 0.702 (0.458) | 0.537 (0.499) | |
| average | 0.940 (0.237) | 0.989 (0.106) | 0.965 (0.185) | 0.840 (0.367) | 0.952 (0.215) | 0.896 (0.305) | 0.772 (0.420) | 0.957 (0.203) | 0.864 (0.343) | 0.650 (0.477) | 0.827 (0.378) | 0.739 (0.440) | |
| Effect of Match (Difference match vs. mismatch) | 0.107 | 0.010 | 0.059 | 0.268 | 0.065 | 0.166 | 0.329 | 0.046 | 0.188 | 0.554 | 0.250 | 0.403 | |
| Random Effects | Variance | SD | Correlation | ||||
| subjects | Intercept | 1.3547 | 1.1639 | ||||
| NP1 Number | 3.1895 | 1.7859 | −0.08 | ||||
| items | Intercept | 0.2088 | 0.4569 | ||||
| Fixed Effects | b | SE | z-Value | p-Value | |||
| Intercept | 3.5134 | 0.1770 | 19.85 | <0.001 | |||
| NP1 Number | 1.4008 | 0.2929 | 4.78 | <0.001 | |||
| Match | −2.6145 | 0.1922 | −13.61 | <0.001 | |||
| Semantic Category | 1.3949 | 0.2369 | 5.89 | <0.001 | |||
| Group | −2.0331 | 0.2937 | −6.92 | <0.001 | |||
| NP1 Number × Match | 1.6816 | 0.3800 | 4.43 | <0.001 | |||
| NP1 Number × Semantic Category | 0.4737 | 0.3738 | 1.27 | 0.205 | |||
| NP1 Number × Group | 0.8563 | 0.3696 | 2.32 | 0.021 | |||
| Match × Semantic Category | 0.4771 | 0.5275 | 0.91 | 0.366 | |||
| Match × Group | −0.1622 | 0.3761 | −0.43 | 0.666 | |||
| Semantic Category × Group | −0.4106 | 0.3710 | −1.11 | 0.268 | |||
| NP1 Number × Match × Semantic Category | 0.4226 | 0.7360 | 0.57 | 0.566 | |||
| NP1 Number × Match × Group | −0.5833 | 0.7518 | −0.78 | 0.438 | |||
| NP1 Number × Semantic Category × Group | 0.9083 | 0.7416 | 1.23 | 0.221 | |||
| Match × Semantic Category × Group | 0.6765 | 0.7352 | 0.92 | 0.358 | |||
| NP1 Number × Match × Semantic Category × Group | −0.6707 | 1.4688 | −0.46 | 0.648 | |||
| Plurality Rating | L1 Speakers | Bilinguals | |||||
|---|---|---|---|---|---|---|---|
| NP1 Number | Difference between SG and PL | NP1 Number | Difference between SG and PL | ||||
| SG | PL | SG | PL | ||||
| Match | match | 0.056 (0.078) | 0.796 (0.212) | 0.740 | 0.070 (0.062) | 0.742 (0.246) | 0.672 |
| mismatch | 0.270 (0.135) | 0.690 (0.301) | 0.420 | 0.290 (0.155) | 0.599 (0.338) | 0.309 | |
| Difference between match and mismatch | 0.214 | 0.106 | 0.220 | 0.143 | |||
| Random Effects | Variance | SD | Correlation | ||||
|---|---|---|---|---|---|---|---|
| subjects | Intercept | 1.3400 | 1.1576 | ||||
| NP1 Number | 3.0850 | 1.7566 | −0.08 | ||||
| items | Intercept | 0.4070 | 0.6379 | ||||
| Fixed Effects | b | SE | z-Value | p-Value | |||
| Intercept | 3.0147 | 0.2868 | 10.51 | <0.001 | |||
| NP1 Number | −0.7626 | 0.5059 | −1.51 | 0.132 | |||
| Match | −1.9949 | 0.4411 | −4.52 | <0.001 | |||
| Plurality Rating | 0.0053 | 0.0156 | 0.34 | 0.732 | |||
| Group | −1.9802 | 0.4887 | −4.05 | <0.001 | |||
| NP1 Number × Match | 1.1405 | 0.8795 | 1.30 | 0.195 | |||
| NP1 Number × Plurality Rating | 0.0522 | 0.0307 | 1.70 | 0.090 | |||
| NP1 Number × Group | −0.0261 | 0.0306 | −0.85 | 0.393 | |||
| Match × Plurality Rating | 0.0544 | 0.9414 | 0.06 | 0.954 | |||
| Match × Group | −1.8711 | 0.8632 | −2.17 | 0.030 | |||
| Plurality Rating × Group | −0.0469 | 0.0304 | −1.55 | 0.122 | |||
| NP1 Number × Match × Plurality Rating | 0.0440 | 0.0611 | 0.72 | 0.472 | |||
| NP1 Number × Match × Group | 0.4576 | 1.7295 | 0.27 | 0.791 | |||
| NP1 Number × Plurality Rating × Group | 0.1146 | 0.0608 | 1.89 | 0.059 | |||
| Match × Plurality Rating × Group | 0.1580 | 0.0608 | 2.60 | 0.009 | |||
| NP1 Number × Match × Plurality Rating × Group | −0.2544 | 0.1217 | −2.09 | 0.037 | |||
| Fixed Effects | L1 Speakers | Bilinguals | ||||||
|---|---|---|---|---|---|---|---|---|
| b | SE | z-Value | p-Value | b | SE | z-Value | p-Value | |
| Intercept | 3.0147 | 0.2868 | 10.51 | <0.001 | 3.0147 | 0.2868 | 10.51 | <0.001 |
| NP1 Number | −0.7898 | 0.8596 | −0.92 | 0.358 | −0.7354 | 0.4603 | −1.60 | 0.110 |
| Match | −1.0593 | 0.7763 | −1.37 | 0.172 | −2.9304 | 0.3937 | −7.44 | <0.001 |
| Plurality Rating | 0.0288 | 0.0294 | 0.98 | 0.327 | −0.0181 | 0.0091 | −1.99 | 0.046 |
| NP1 Number × Match | 0.9116 | 1.5515 | 0.59 | 0.557 | 1.3692 | 0.7802 | 1.76 | 0.079 |
| NP1 Number × Plurality Rating | −0.0051 | 0.0585 | −0.09 | 0.930 | 0.1095 | 0.0176 | 6.23 | <0.001 |
| Match × Plurality Rating | −0.1051 | 0.0585 | −1.80 | 0.072 | 0.0529 | 0.0174 | 3.04 | 0.002 |
| NP1 Number × Match × Plurality Rating | 1.1012 | 0.5521 | 1.99 | 0.046 | −0.0832 | 0.0345 | −2.41 | 0.016 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Reifegerste, J.; Garibagaoglu, A.; Felser, C. Conceptual Number in Bilingual Agreement Computation: Evidence from German Pseudo-Partitives. Languages 2023, 8, 147. https://doi.org/10.3390/languages8020147
Reifegerste J, Garibagaoglu A, Felser C. Conceptual Number in Bilingual Agreement Computation: Evidence from German Pseudo-Partitives. Languages. 2023; 8(2):147. https://doi.org/10.3390/languages8020147
Chicago/Turabian StyleReifegerste, Jana, Ayse Garibagaoglu, and Claudia Felser. 2023. "Conceptual Number in Bilingual Agreement Computation: Evidence from German Pseudo-Partitives" Languages 8, no. 2: 147. https://doi.org/10.3390/languages8020147