
Establishing Reliability and Validity of an Online Placement Test in an Omani Higher Education Institution
 , ,
, ,
Abstract
:1. Introduction
2. Literature Review
2.1. In-House (Local) Versus Commercially Produced Large-Scale PTs
2.2. Validity and Reliability Studies of Placement Tests
3. Research Questions
4. Materials and Methods
4.1. Context of the Study
4.2. A Brief on the in-House Placement Test Used at the HEI
4.3. Validity and Reliability Study of the PT
4.3.1. Content Validity
4.3.2. Criterion-Related Concurrent Validity
4.3.3. Face Validity
4.3.4. Reliability
5. Results
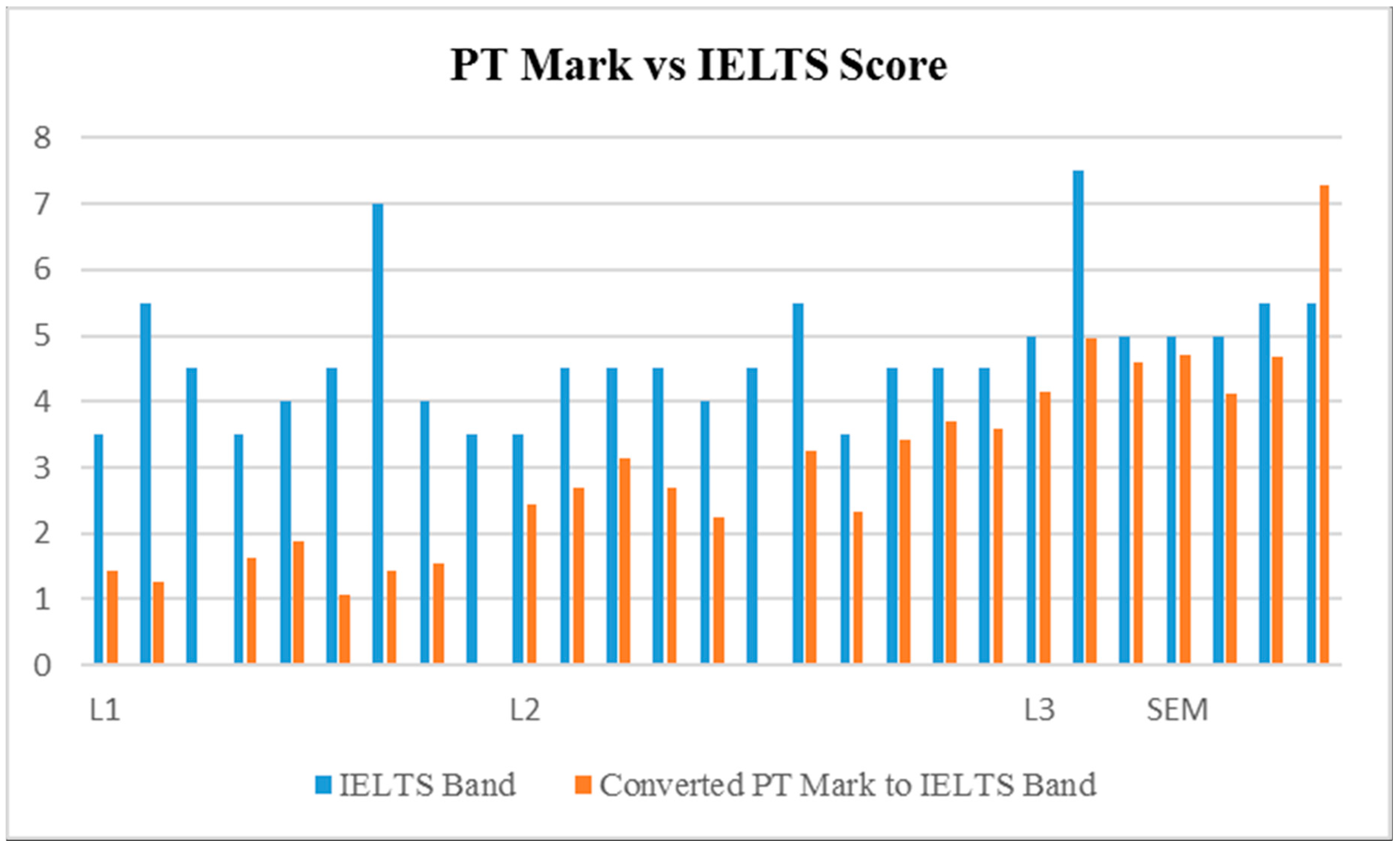
5.1. Criterion-Related Concurrent Validity: Benchmarking with Ielts
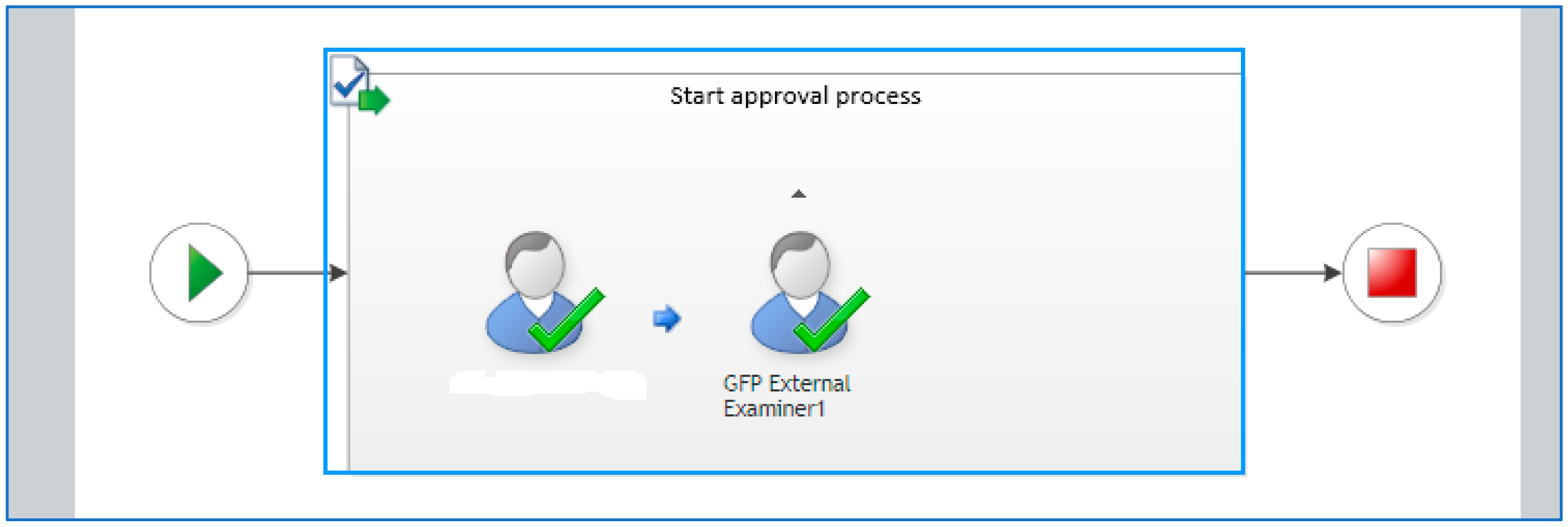
5.2. Content Validity: Internal and External Moderation
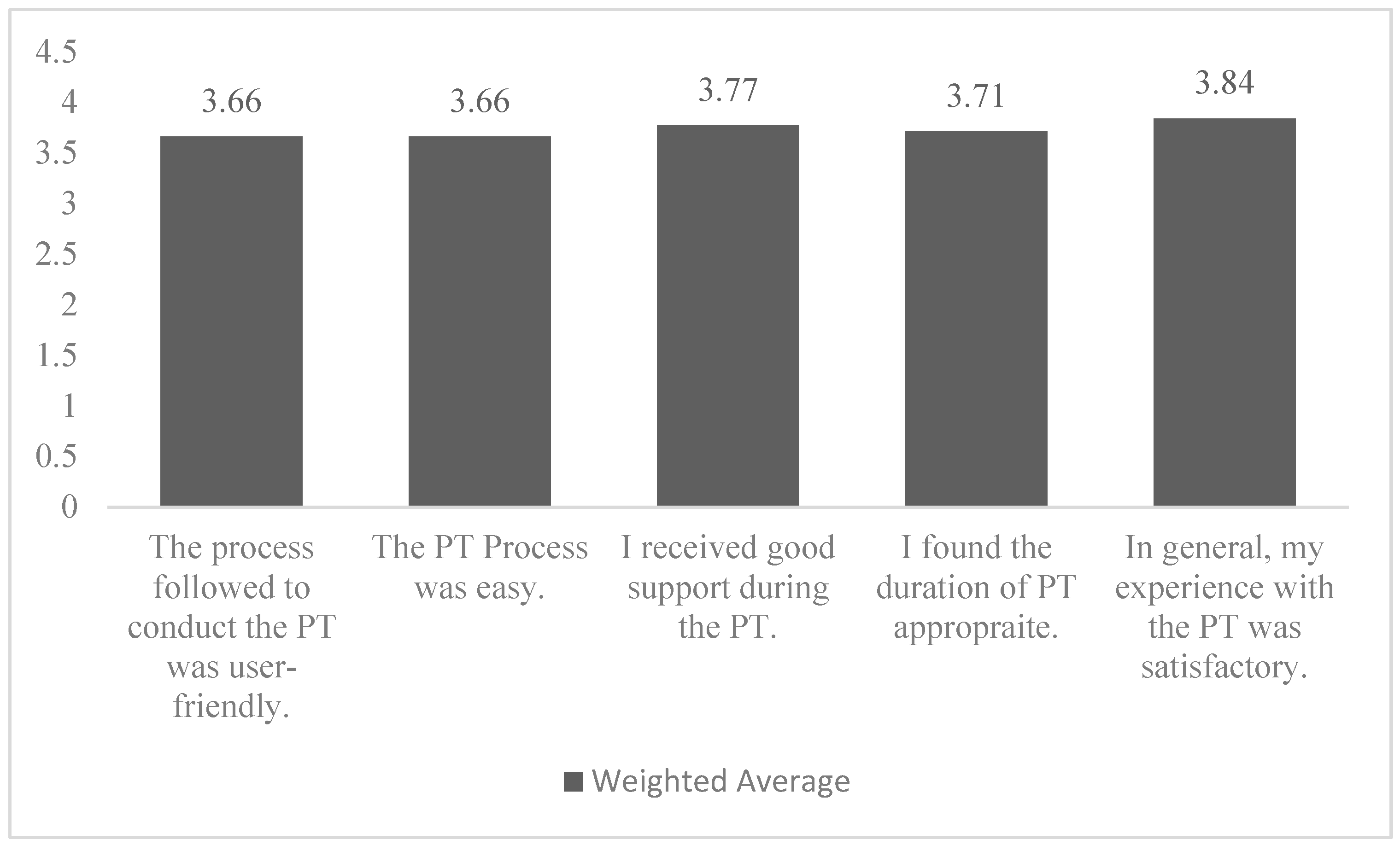
5.3. Face Validity: Student Feedback on Placement Test
5.4. Reliability and Validity of the Four English Language Components of the in-House PT
5.4.1. Reading Skills Test
5.4.2. Listening Skills Test
5.4.3. Writing Skills Test
5.4.4. Speaking Skills Test
6. Discussion
7. Limitations and Implications for Further Study
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abdelkarim, Osama, Fritsch Julian, Jekauc Darko, and Bös Klaus. 2021. Examination of Construct Validity and Criterion-Related Validity of the German Motor Test in Egyptian Schoolchildren. International Journal of Environmental Research and Public Health 18: 8341. [Google Scholar] [CrossRef] [PubMed]
- Al-Adawi, Sharifa Said Ali, and Aaisha Abdul Rahim Al-Balushi. 2016. Investigating Content and Face Validity of English Language Placement Test Designed by Colleges of Applied Science. English Language Teaching (Online) 9: 107–21. [Google Scholar] [CrossRef] [Green Version]
- Ashraf, Hamid, and Samaneh Zolfaghari. 2018. EFL Teachers’ Assessment Literacy and Their Reflective Teaching. International Journal of Instruction 11: 425–36. [Google Scholar] [CrossRef]
- Buras, Avery. 1996. Test Equating Procedures: A primer on the Logic and Applications of Test Equating. ERIC Document Reproduction Service No. ED 395 038. New Orleans: Southwest Educational Research Association. [Google Scholar]
- Chun, Jean Young. 2011. The Construct Validation of ELI Listening Placement Tests. Education Psychology 30: 1–47. Available online: http://www.hawaii.edu/sls/wp-content/uploads/2014/09/Chun-Jean-Young1.pdf (accessed on 21 October 2022).
- Chung, Sun Joo, Haider Iftekhar, and Boyd Ryan. 2015. The English placement test at the University of Illinois at Urbana-Champaign. Language Teaching 48: 284–87. [Google Scholar] [CrossRef]
- Coombe, Christine, Vafadar Hossein, and Mohebbi Hassan. 2020. Language assessment literacy: What do we need to learn, unlearn, and relearn? Language Testing in Asia 10: 1–16. [Google Scholar] [CrossRef]
- Cronbach, Lee Joseph. 1951. Coefficient alpha and the internal structure of tests. Psychometrika 16: 297–334. Available online: http://cda.psych.uiuc.edu/psychometrika_johnson/CronbachPaper%20(1).pdf (accessed on 20 September 2022). [CrossRef] [Green Version]
- Dimova, Slobodanka, Yan Xun, and Ginther April. 2022. Local tests, local contexts. Language Testing 39: 341–54. [Google Scholar] [CrossRef]
- Dong, Manxia, Cenyu Gan, Yaqiu Zheng, and Runsheng Yang. 2022. Research Trends and Development Patterns in Language Testing Over the Past Three Decades: A Bibliometric Study. Frontiers in Psychology 13: 1–15. [Google Scholar] [CrossRef]
- Dörnyei, Zoltan, and Lucy Katona. 1992. Validation of the C-test amongst Hungarian EFL Learners. Language Testing 9: 187–206. [Google Scholar] [CrossRef]
- Emperador-Garnace, Xenia Ribaya. 2021. Speaking Assessments in Multilingual English Language Teaching. Online Submission 25: 39–65. Available online: https://files.eric.ed.gov/fulltext/ED620449.pdf (accessed on 22 October 2022).
- Fan, Jason, and Yan Jin. 2020. Standards for language assessment: Demystifying university-level English placement testing in China. Asia Pacific Journal of Education 40: 386–400. [Google Scholar] [CrossRef]
- Fink, Arlene. 2010. Survey research methods. In International Encyclopedia of Education. Amsterdam: Elsevier, pp. 152–60. [Google Scholar] [CrossRef]
- Fox, Jana D. 2009. Moderating top-down policy impact and supporting EAP curricular renewal: Exploring the potential of diagnostic assessment. Journal of English for Academic Purposes 8: 26–42. [Google Scholar] [CrossRef]
- Fulcher, Glenn. 1997. An English Language placement test: Issues in reliability and validity. Language Testing (Online) 14: 113–38. Available online: http://languagetesting.info/articles/store/Placement%20Testing.pdf (accessed on 8 October 2022). [CrossRef] [Green Version]
- Fulcher, Glenn. 1999. Computerizing an English language placement test. ELT Journal 53: 289–99. [Google Scholar] [CrossRef]
- Fulcher, Glenn, Ali Panahi, and Hassan Mohebbi. 2022. Language Teaching Research Quarterly. Language Teaching Research 29: 20–56. [Google Scholar] [CrossRef]
- Genç, Eda, Hacer Çalişkan, and Dogan Yuksel. 2020. Language Assessment Literacy Level of EFL Teachers: A Focus on Writing and Speaking Assessment. Sakarya University Journal of Education 10: 274–91. [Google Scholar] [CrossRef]
- George, Darren, and Paul Mallery. 2003. SPSS for Windows Step by Step: A Simple Guide and Reference 11.0 Update, 4th ed. Boston: Allyn and Bacon. [Google Scholar]
- Hilgers, Aimee. 2019. Placement Testing Instruments for Modality Streams in an English Language Program. Ph.D. thesis, Minnesota State University Moorhead, Moorhead, MN, USA. [Google Scholar]
- Hille, Kathryn, and Yeonsuk Cho. 2020. Placement testing: One test, two tests, three tests? How many tests are sufficient? Language Testing 37: 453–71. [Google Scholar] [CrossRef]
- Huang, Becky H., Mingxia Zhi, and Yangting Wang. 2020. Investigating the Validity of a University-Level ESL Speaking Placement Test via Mixed Methods Research. International Journal of English Linguistics 10: 1–15. [Google Scholar] [CrossRef]
- Jamieson, Jeremy P., Matthew K. Nock, and Wendy Berry Mendes. 2013. Improving acute stress responses: The power of reappraisal. Current Directions in Psychological Science 22: 51–56. [Google Scholar] [CrossRef] [Green Version]
- Johnson, Robert C., and A. Mehdi Riazi. 2017. Validation of a Locally Created and Rated Writing Test Used for Placement in a Higher Education EFL Program. Assessing Writing 32: 85–104. [Google Scholar] [CrossRef]
- Kane, Michael T. 2013. Validating the Interpretations and Uses of Test Scores. Journal of Educational Measurement 50: 1–73. [Google Scholar] [CrossRef]
- Kaplan, Robert Malcolm, and Dennis P. Saccuzzo. 2005. Psychological testing: Principles, Applications and Issues, 6th ed. Belmont: Thomson Wadsworth. [Google Scholar]
- Kim, Young-Mi, and Misook Kim. 2017. Validations of an English Placement Test for a General English Language Program at the Tertiary Level. JLTA Journal 20: 17–34. [Google Scholar] [CrossRef] [Green Version]
- Kim, Hyun Jung, and Hye Won Shin. 2006. A reading and writing placement test: Design, evaluation, and analysis. Studies in Applied Linguistics and TESOL 6: 2. [Google Scholar]
- Klein-Braley, Christine. 1997. C-tests in the context of reduced redundancy testing: An appraisal. Language Testing 14: 47–84. [Google Scholar] [CrossRef]
- Kokhan, Kateryna. 2013. An argument against using standardized test scores for placement of international undergraduate students in English as a Second Language (ESL) courses. Language Testing 30: 467–89. [Google Scholar] [CrossRef]
- Li, Zhi. 2015. Using an English self-assessment tool to validate an English Placement Test. Language Testing and Assessment 4: 59–96. Available online: https://arts.unimelb.edu.au/__data/assets/pdf_file/0003/1770672/Li.pdf (accessed on 1 October 2022).
- Liao, Yen-Fen. 2022. Using the English GSAT for placement into EFL classes: Accuracy and validity concerns. Language Testing in Asia 12: 1–23. [Google Scholar] [CrossRef]
- Liskinasih, Ayu, and Rizky Lutviana. 2016. The validity evidence of TOEFL test as placement test. Jurnal Ilmiah Bahan dan Sastra 3: 173–80. Available online: https://www.researchgate.net/publication/314110391 (accessed on 25 October 2022). [CrossRef] [Green Version]
- Mahfoud, Bashir Ghit. 2021. Examining the Content and Face Validity of English Placement Test at the Technical College of Civil Aviation and Meteorology, Tripoli, Libya. AL-JAMEAI 33: 5–19. Available online: https://www.aljameai.org.ly/index.php/aljameai/article/view/802 (accessed on 11 September 2022).
- Manganello, Marc. 2011. Correlations in the New Toefl Era: An Investigation of the Statistical Relationships Between Ibt Scores, Placement Test Performance, and Academic Success of International Students at Iowa State University. Unpublished Master’s thesis, Iowa State University, Ames, IA, USA. [Google Scholar]
- McCoubrie, Paul. 2005. Improving the fairness of multiple-choice questions: A literature review. Medical Teacher 26: 709–12. [Google Scholar] [CrossRef] [PubMed]
- MEC. 2021. Unpublished Raw Data on New Student Survey. Seeb: Middle East College. [Google Scholar]
- Messick, Samuel. 1996. Validity and washback in language testing. Language Testing 13: 241–56. Available online: https://files.eric.ed.gov/fulltext/ED403277.pdf (accessed on 15 September 2022). [CrossRef]
- Nakamura, Yuji. 2007. A Rasch-based analysis of an in-house English placement test. In Paper presented at the Second Language Acquisition—Theory and pedagogy: Proceedings of the 6th annual JALT Pan-SIG Conference, Online, May 12–13; pp. 97–109. [Google Scholar]
- Rahal, Hadeel El, and Huda Dimashkie. 2020. Creational Reverse Engineering: A Project to Enhance English Placement Test Security, Validity, and Reliability. In The Assessment of L2 Written English across the MENA Region. London: Palgrave Macmillan, pp. 43–68. [Google Scholar]
- Rouhani, Mahmood. 2008. Another look at the C-Test: A validation study with Iranian EFL learners. The Asian EFL Journal Quarterly March 10: 154. [Google Scholar]
- Shin, Sun-Young, and Ryan Lidster. 2017. Evaluating different standard-setting methods in an ESL placement testing context. Language Testing 34: 357–81. [Google Scholar] [CrossRef]
- Sireci, Stephen. G. 1998. The construct of content validity. Social Indicators Research 45: 83–117. Available online: https://www.jstor.org/stable/27522338 (accessed on 15 September 2022). [CrossRef]
- Topor, F. Sigmond. 2014. A sentence repetition placement test for ESL/EFL learners in Japan. In Handbook of Research on Education and Technology in a Changing Society. Hershey: IGI Global, pp. 971–988. [Google Scholar] [CrossRef] [Green Version]
- Wall, Dianne, Caroline Clapham, and J. Charles Alderson. 1994. Evaluating a placement test. Language Testing 11: 321–44. [Google Scholar] [CrossRef]
- Wallen, Norman E., and Jack R. Fraenkel. 2013. Educational Research: A guide to the Process. Beijing: Routledge. [Google Scholar]
- Weber, Robert Philip. 2004. Content analysis. In Social Research Methods: A Reader. Edited by Clive Seale. Oxford: Routledge, pp. 117–24. [Google Scholar]
- Westrick, Paul. 2005. Score Reliability and Placement Testing. JALT Journal 27: 71–94. Available online: https://jalt-publications.org/sites/default/files/pdf-article/jj-27.1-art4.pdf (accessed on 20 October 2022). [CrossRef]
- Xu, Xiaomeng, Sierra Kauer, and Samantha Tupy. 2016. Multiple-choice questions: Tips for optimizing assessment in-seat and online. Scholarship of Teaching and Learning in Psychology 2: 147. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Skills | Test Components | Mode | Duration | Marks | Total Marks |
|---|---|---|---|---|---|
| Reading | Two reading texts | Computer-based Online | 40 min | 30 | 100 |
| Writing | Two questions: (i) Description of a chart/graph or a process using the visual (word limit-150 words); (ii) Essay writing-argumentative/persuasive genre (word limit-250 words) | 40 min | 70 | ||
| Listening | MCQs (based on IELTS pattern) | 40 min | 50 | 100 | |
| Speaking | Oral (conversation) test consisting of 3 Sections (based on IELTS pattern) | 10 min | 50 |
| Validity | |||
|---|---|---|---|
| Type of Validity | Mode/Test/Method | No of Participants | |
| Content validity | Automated workflow created on Content Management System (CMS) | 2 Internal moderators | 1 External moderator |
| (1 Faculty and GFP Programme Manager) | (External expert) | ||
| Criterion-related Concurrent Validity | Paper-based IELTS exam | 29 students | |
| Face validity | Online survey | 57 students | |
| Skill | Method |
|---|---|
| Reading | Cronbach’s alpha |
| Listening | Standard deviation |
| Writing | Paired sample t-test (dependent t-test) Double-blind marking |
| Speaking | Paired sample t-test (dependent t-test) conducted in the presence of two examiners |
| Correlations | |||
|---|---|---|---|
| PT | Bands | ||
| PT | Pearson Correlation | 1 | 0.437 * |
| Sig. (2-tailed) | 0.023 | ||
| N | 27 | 27 | |
| Bands | Pearson Correlation | 0.437 * | 1 |
| Sig. (2-tailed) | 0.023 | ||
| N | 27 | 27 | |
| Reading Placement Test | Cronbach’s Alpha | Mean | Variance | Std. Deviation | N of Items |
|---|---|---|---|---|---|
| Set A | 0.804 Good | 17.12 | 51.172 | 7.153 | 17 |
| Set B | 0.804 Good | 18.51 | 41.979 | 6.479 | 17 |
| Set C | 0.720 Acceptable | 18.83 | 44.866 | 6.698 | 9 |
| Set D | 0.787 Acceptable | 18.1364 | 47.609 | 6.89992 | 17 |
| Set E | 0.810 Good | 21.8750 | 41.794 | 6.46480 | 17 |
| Set F | 0.646 Questionable | 19.55 | 29.099 | 5.394 | 9 |
| N | Minimum | Maximum | Mean | Std. Deviation | |
|---|---|---|---|---|---|
| Total | 15 | 41.25 | 48.75 | 46.0833 | 2.20929 |
| Valid N (listwise) | 15 |
| N | Minimum | Maximum | Mean | Std. Deviation | |
|---|---|---|---|---|---|
| Total | 33 | 28.75 | 48.75 | 44.5833 | 5.23535 |
| Valid N (listwise) | 33 |
| Paired Differences | T | df | Sig. (2-Tailed) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Mean | Std. Deviation | Std. Error Mean | 95% Confidence Interval of the Difference | ||||||
| Lower | Upper | ||||||||
| Pair 1 | Marker_1–Marker_2 | 0.850 | 4.664 | 0.602 | −0.355 | 2.055 | 1.412 | 59 | 0.163 |
| Paired Differences | T | df | Sig. (2-Tailed) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Mean | Std. Deviation | Std. Error Mean | 95% Confidence Interval of the Difference | ||||||
| Lower | Upper | ||||||||
| Pair 1 | Marker_1–Marker_2 | −0.673 | 2.800 | 0.340 | −1.351 | 0.005 | 1.981 | 67 | 0.052 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naqvi, S.; Srivastava, R.; Al Damen, T.; Al Aufi, A.; Al Amri, A.; Al Adawi, S. Establishing Reliability and Validity of an Online Placement Test in an Omani Higher Education Institution. Languages 2023, 8, 61. https://doi.org/10.3390/languages8010061
Naqvi S, Srivastava R, Al Damen T, Al Aufi A, Al Amri A, Al Adawi S. Establishing Reliability and Validity of an Online Placement Test in an Omani Higher Education Institution. Languages. 2023; 8(1):61. https://doi.org/10.3390/languages8010061
Chicago/Turabian StyleNaqvi, Samia, Reema Srivastava, Tareq Al Damen, Asma Al Aufi, Amal Al Amri, and Suleiman Al Adawi. 2023. "Establishing Reliability and Validity of an Online Placement Test in an Omani Higher Education Institution" Languages 8, no. 1: 61. https://doi.org/10.3390/languages8010061