
Flight Anomaly Detection via a Deep Hybrid Model


Abstract
:1. Introduction
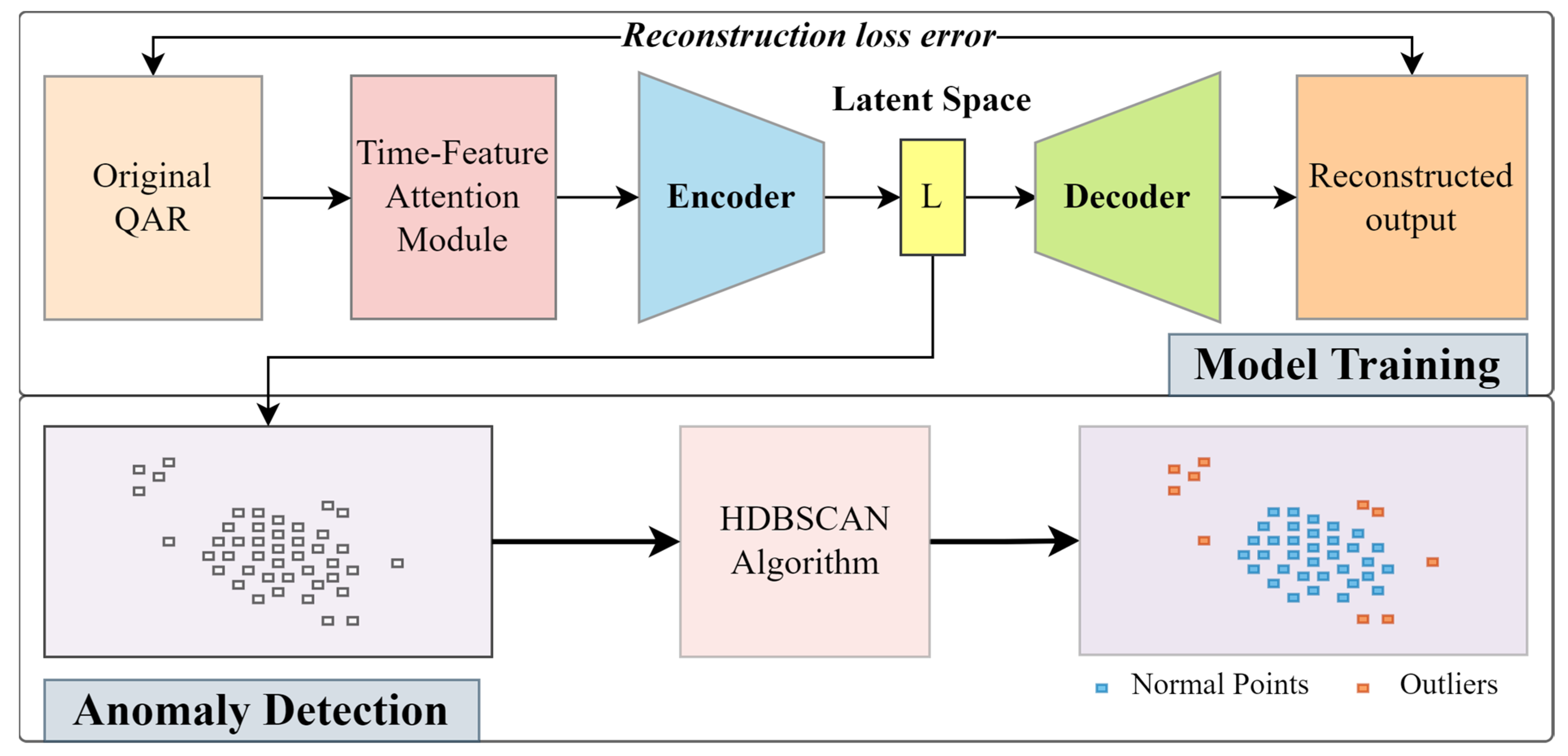
2. Method
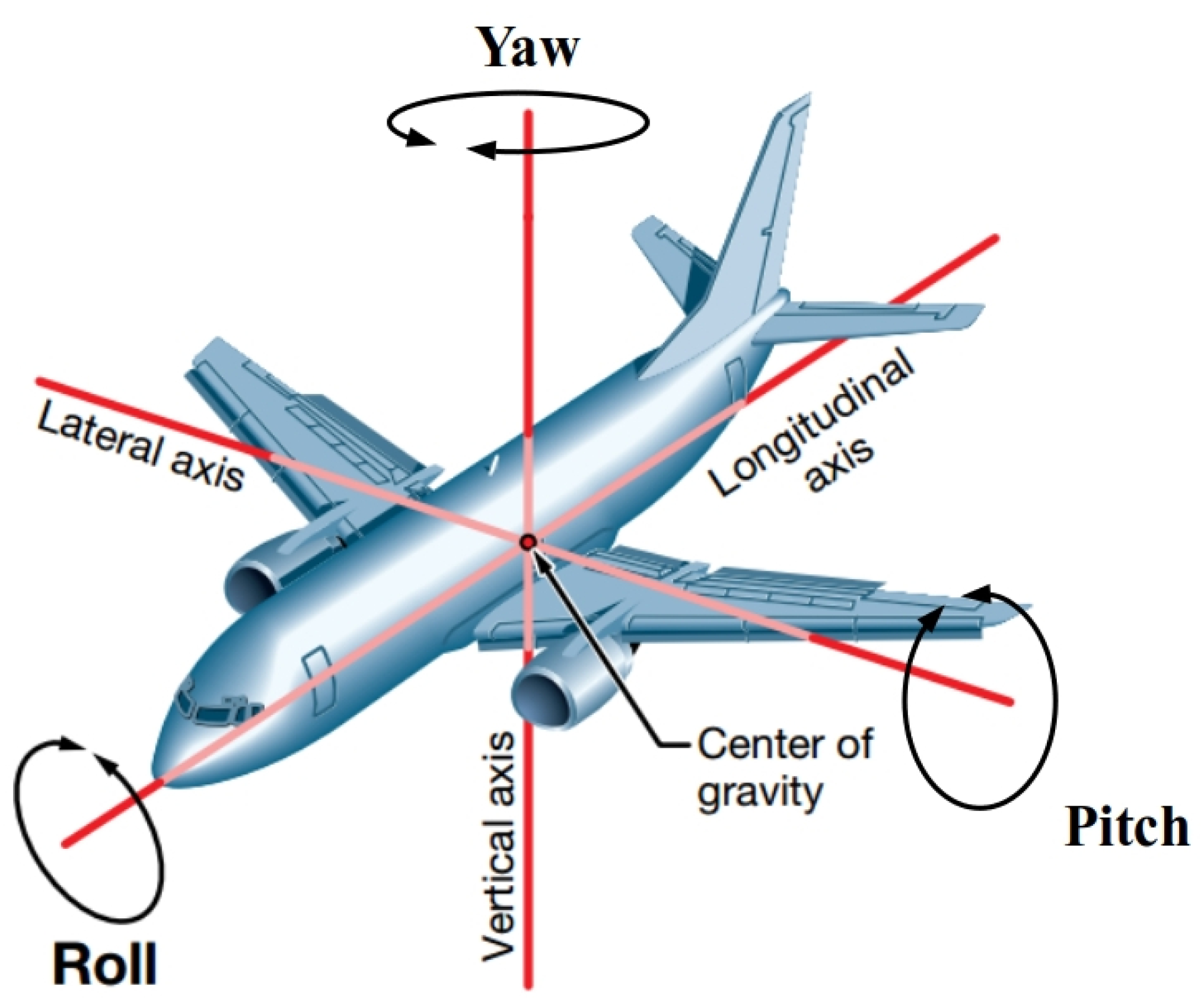
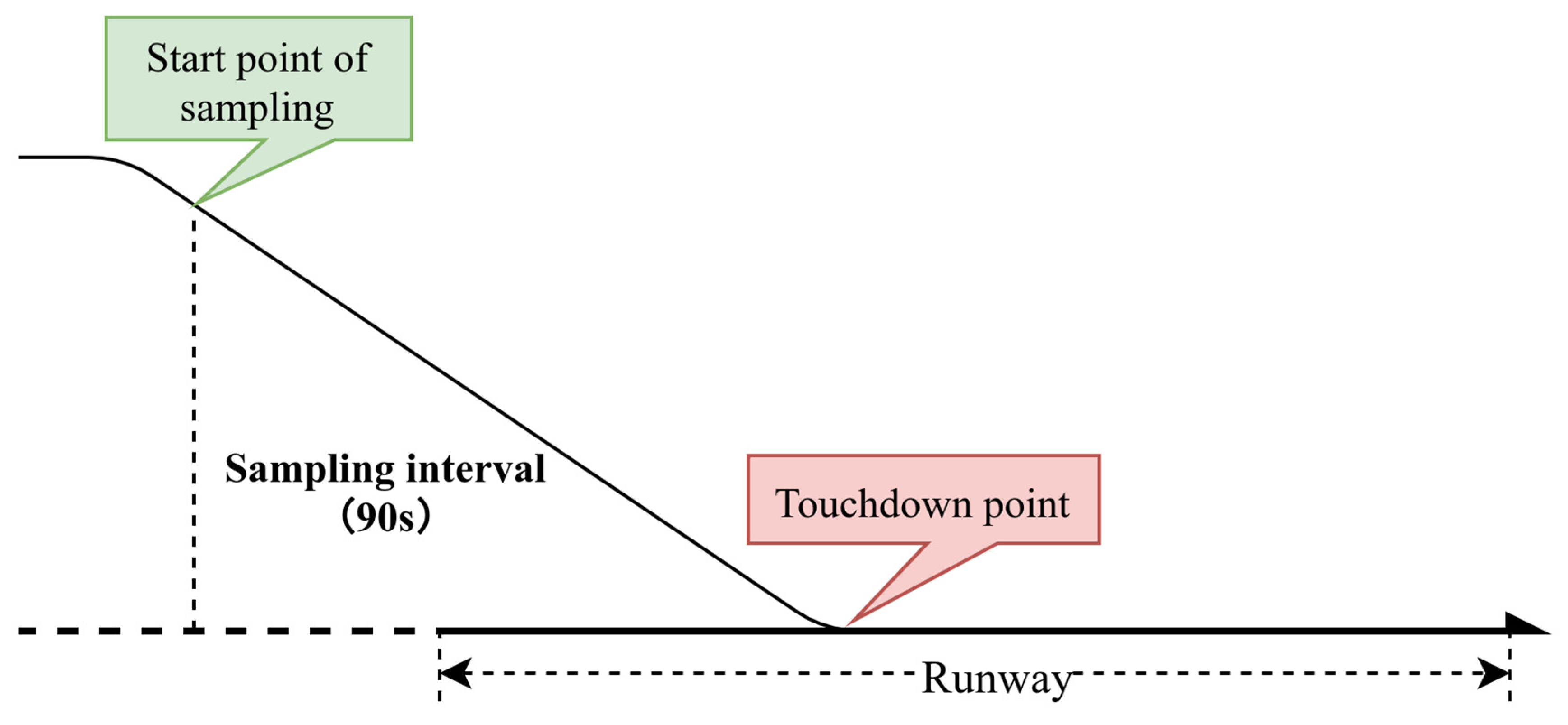
2.1. Data Preprocessing
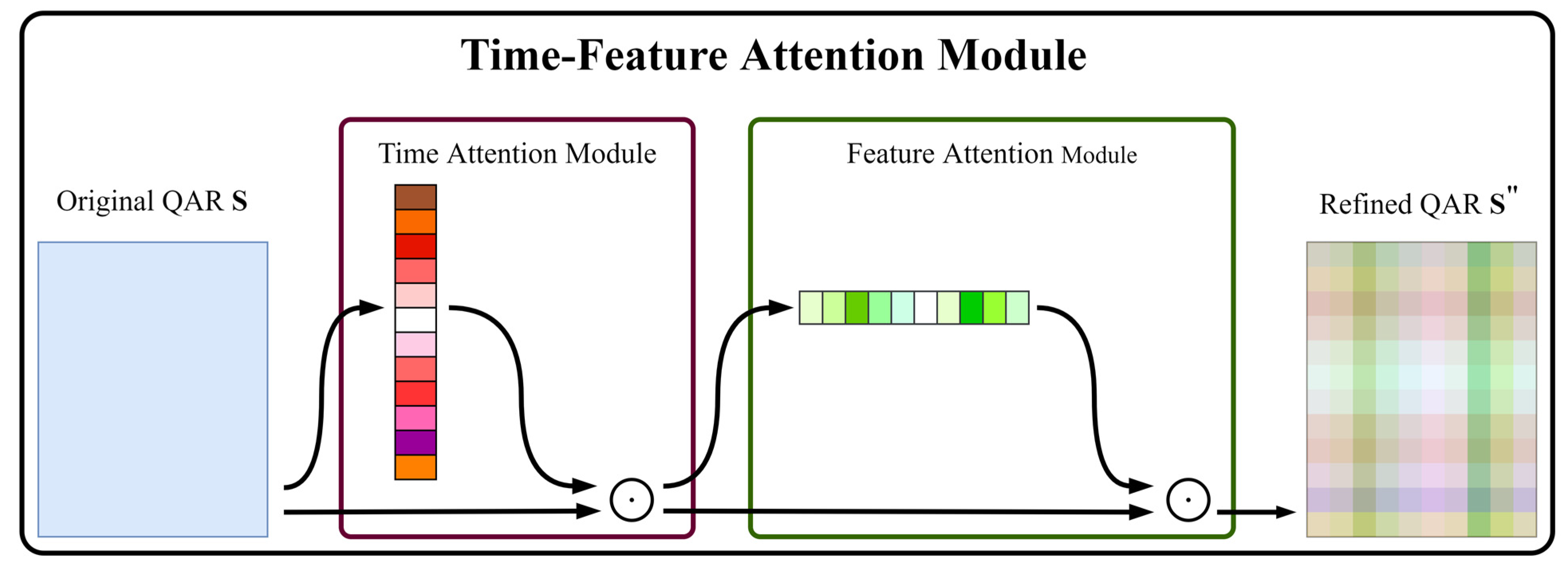
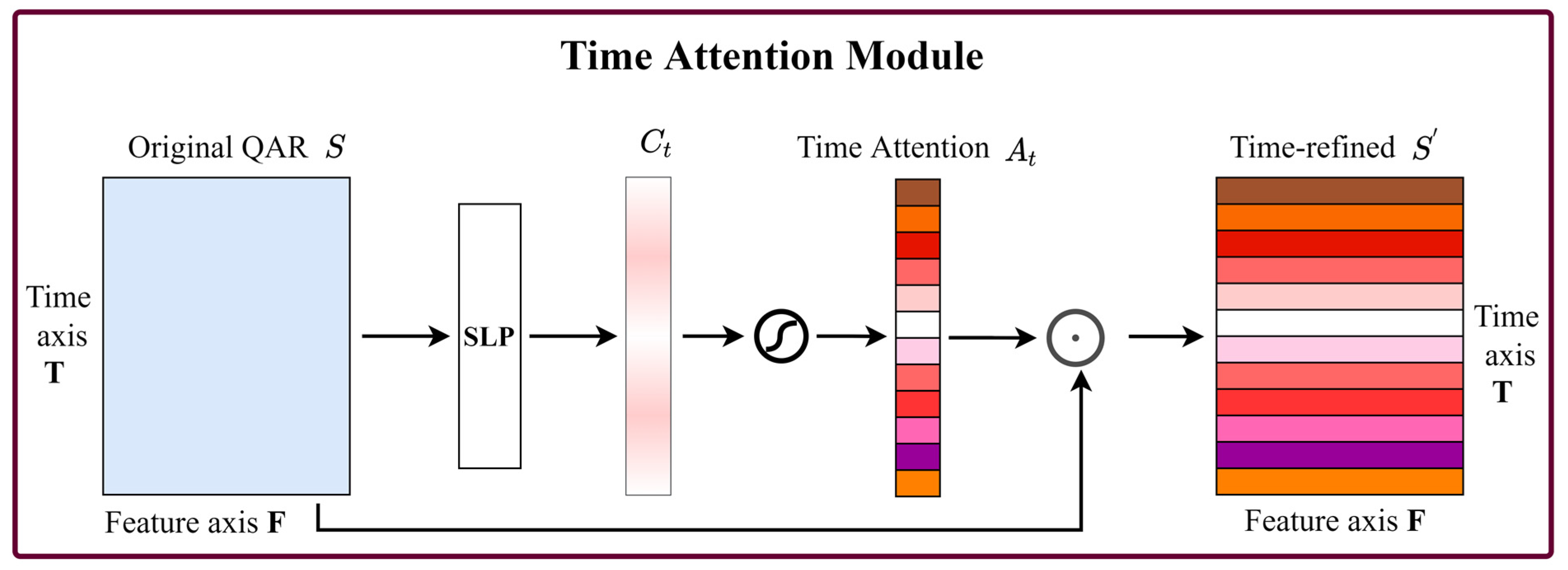
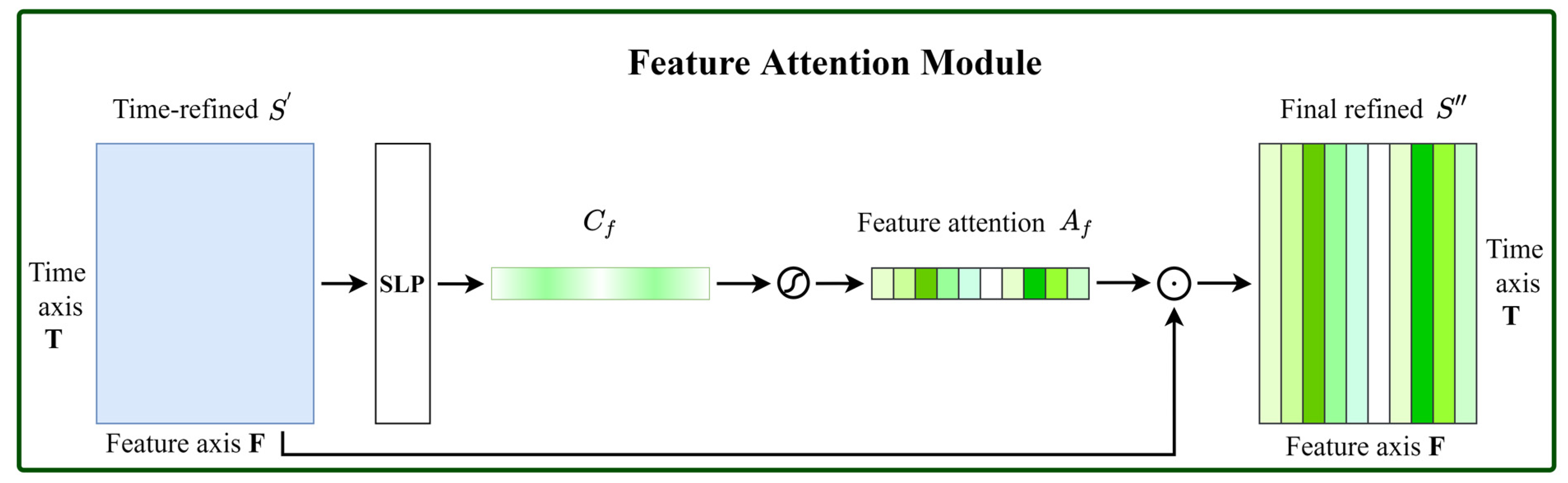
2.2. Time-Feature Attention Module
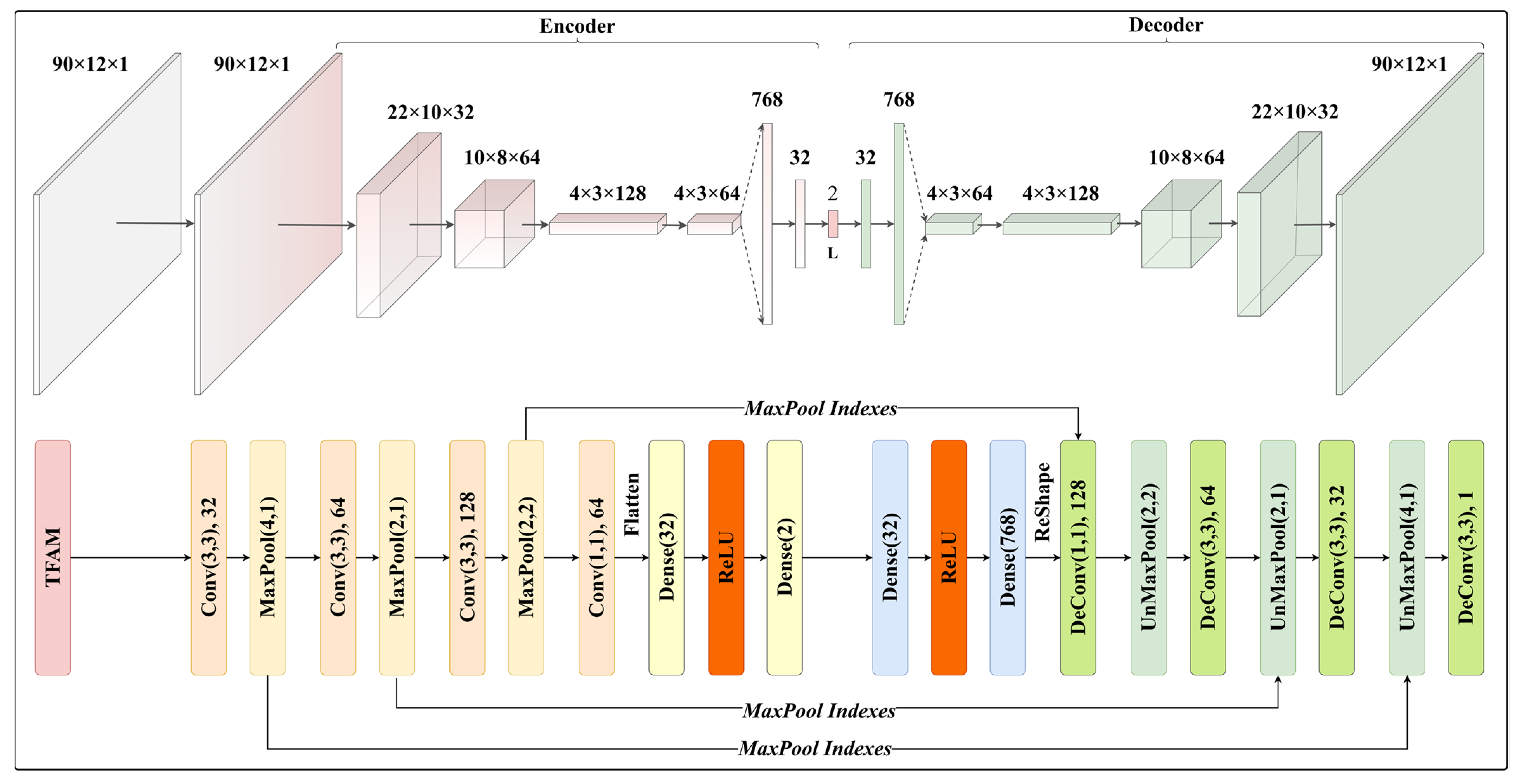
2.3. Time-Feature Attention-Based Convolutional Autoencoder (TFA-CAE)
2.4. HDBSCAN
- (1)
- Transform the space. In the HDBSCAN algorithm, a new distance metric between points called the mutual reachability distance is first defined to spread apart points with low densities:where is the mutual reachability distance; and are the core distances defined for parameter for points and , respectively; and is the original metric distance between and . With this metric, points with high density maintain the same distance from each other, while the sparse points are separated from other points by at least their core distance.
- (2)
- Build the minimum spanning tree. The dataset is then represented by a mutual reachability graph with the data points as vertices and a weighted edge between any two points with weights equal to the mutual reachability distances of those points. A minimum spanning tree of the graph, in which all the weights of all edges are the smallest, is constructed so that removing any edges of the tree will split the graph. The minimum spanning tree can be built quickly and efficiently with Prim’s algorithm [54].
- (3)
- Build the cluster hierarchy. Given the above minimum spanning tree, the next step is to convert it into a hierarchy of connected components. This is most easily done in the reverse order: sort the edges of the tree by the distances in increasing order and then iterate through them, creating a new merged cluster for each edge. The key here is to identify the two clusters for each edge to join together, which is easily achieved with a union-find data structure [55].
- (4)
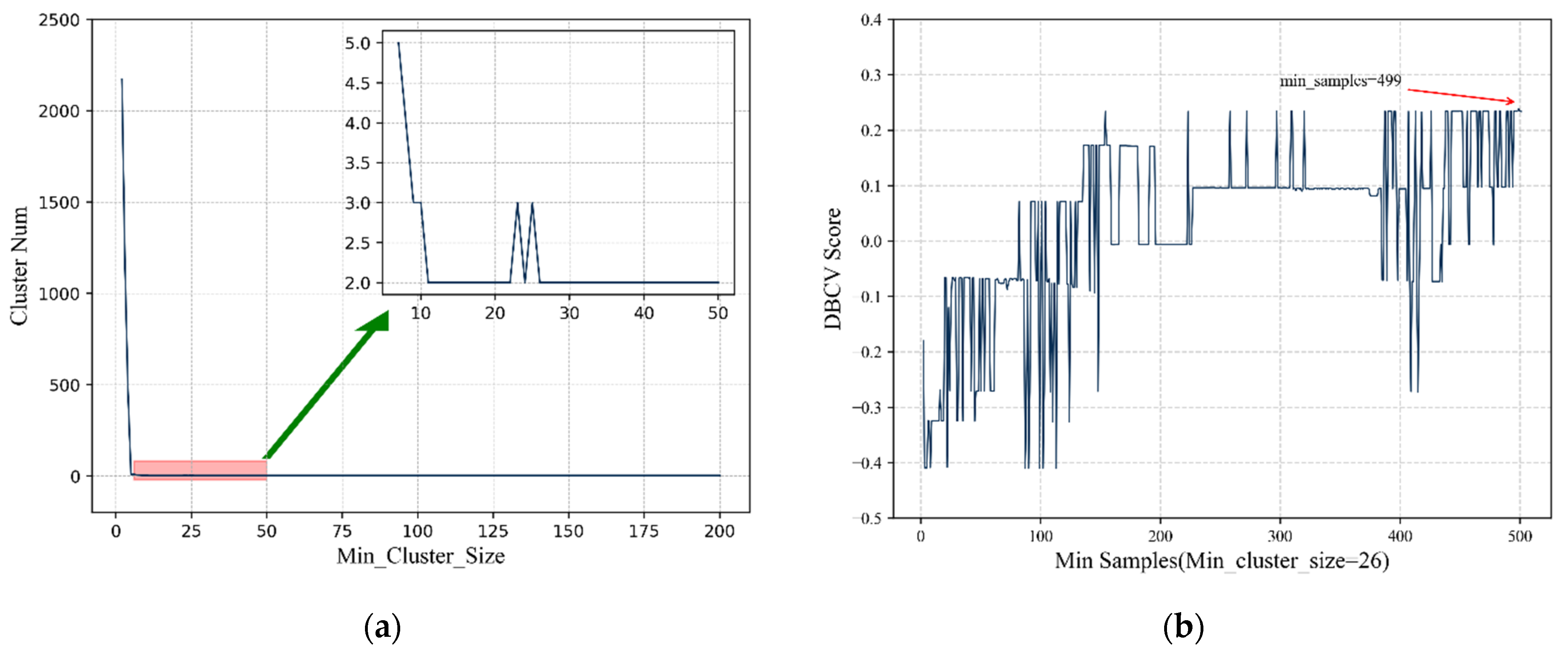
- Condense the cluster tree. This step condenses down the large and complicated cluster hierarchy into a smaller tree with slightly more data attached to each node. As the most important parameter of HDBSCAN, min_cluster_size is needed to make this concrete. Starting from the root, when each cluster is split, the samples of subclusters with sizes less than min_cluster_size are detected and marked as “outliers”. If all the subclusters contain fewer than min_cluster_size objects, the cluster is considered to have disappeared at this density level. After walking through the whole hierarchy and completing this process, a tree with a small number of nodes, the condensed cluster tree, is obtained.
- (5)
- Extract the clusters. HDBSCAN uses to measure the persistence of clusters and introduces the stability indicator. For each cluster, the stability is computed as:
- the lambda value when the cluster is formed;
- the lambda value when the cluster is split into two subclusters;
- the lambda value when point falls out of the cluster.
where and is the stability of the cluster. As a solution to cluster extraction, HDBSCAN’s selection algorithm traverses the condensed cluster tree from bottom to top and selects the cluster with the highest stability on each path.
3. Experimental Result
3.1. Experimental Data
3.2. Model Training
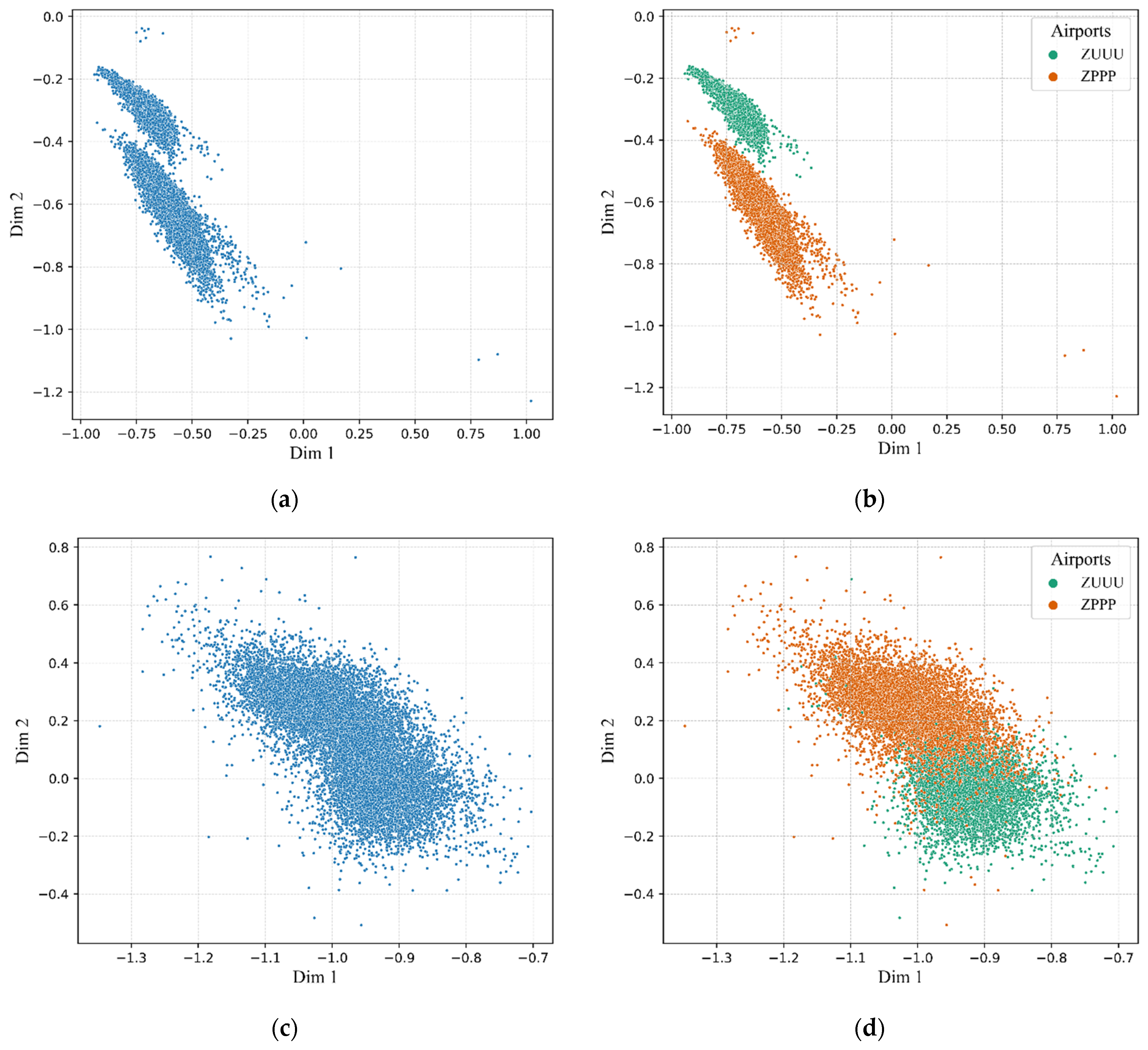
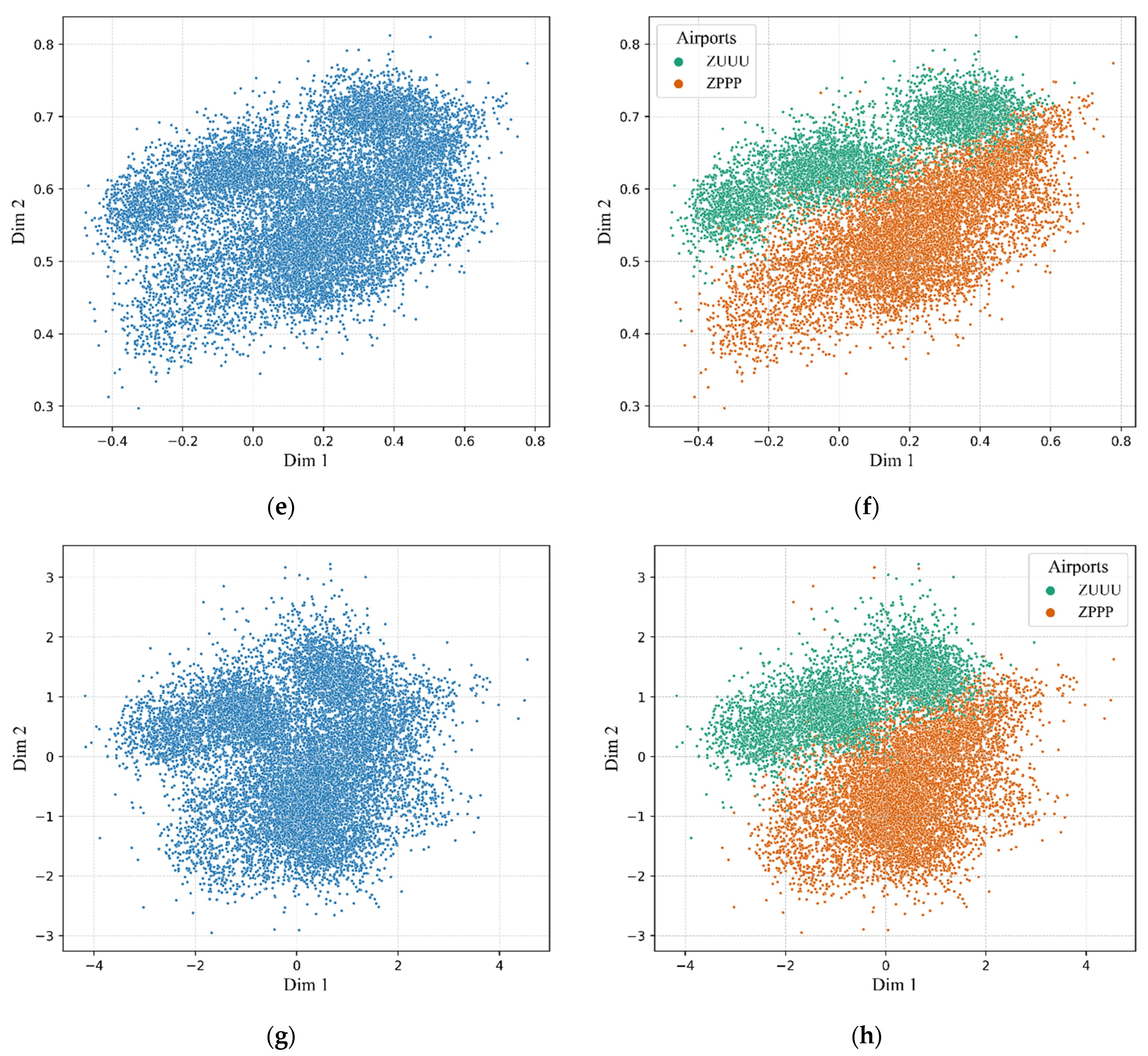
3.3. Visualization of the Extracted Flight Features
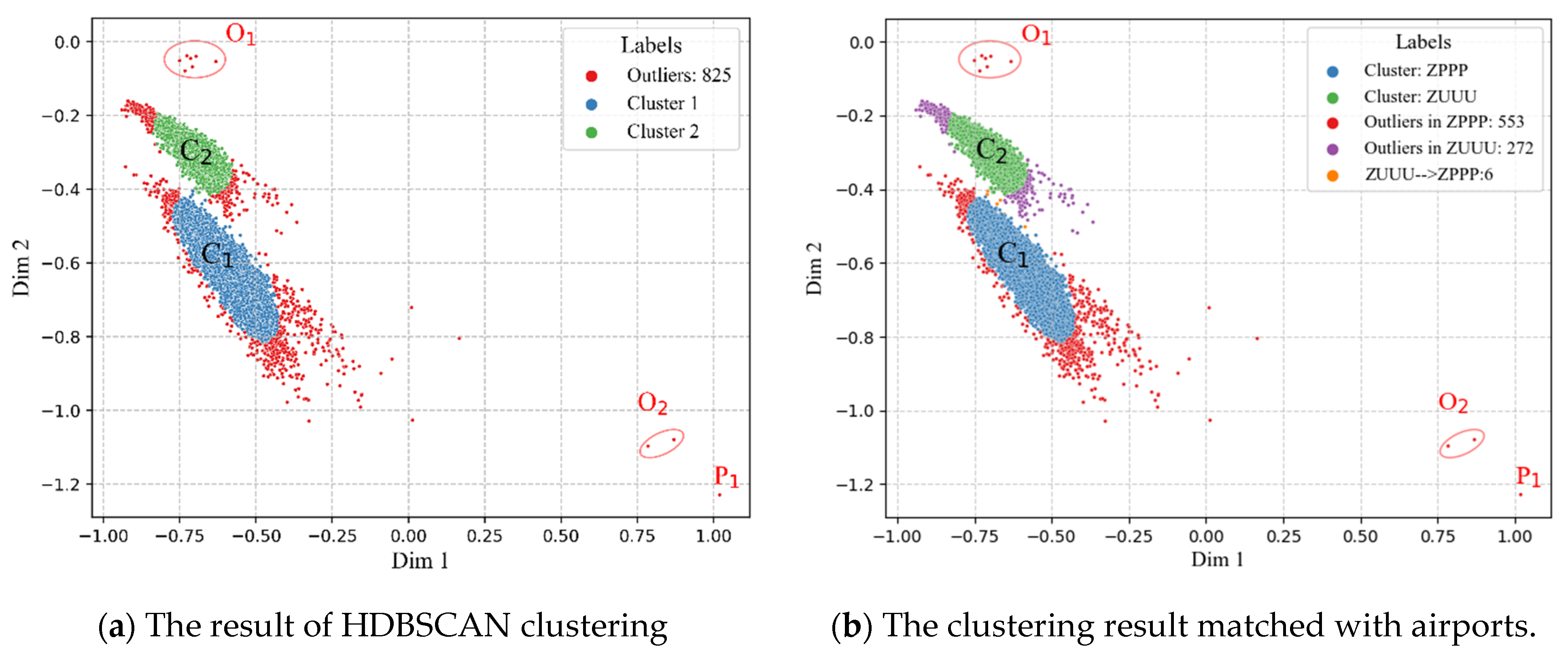
3.4. Result of HDBSCAN Clustering
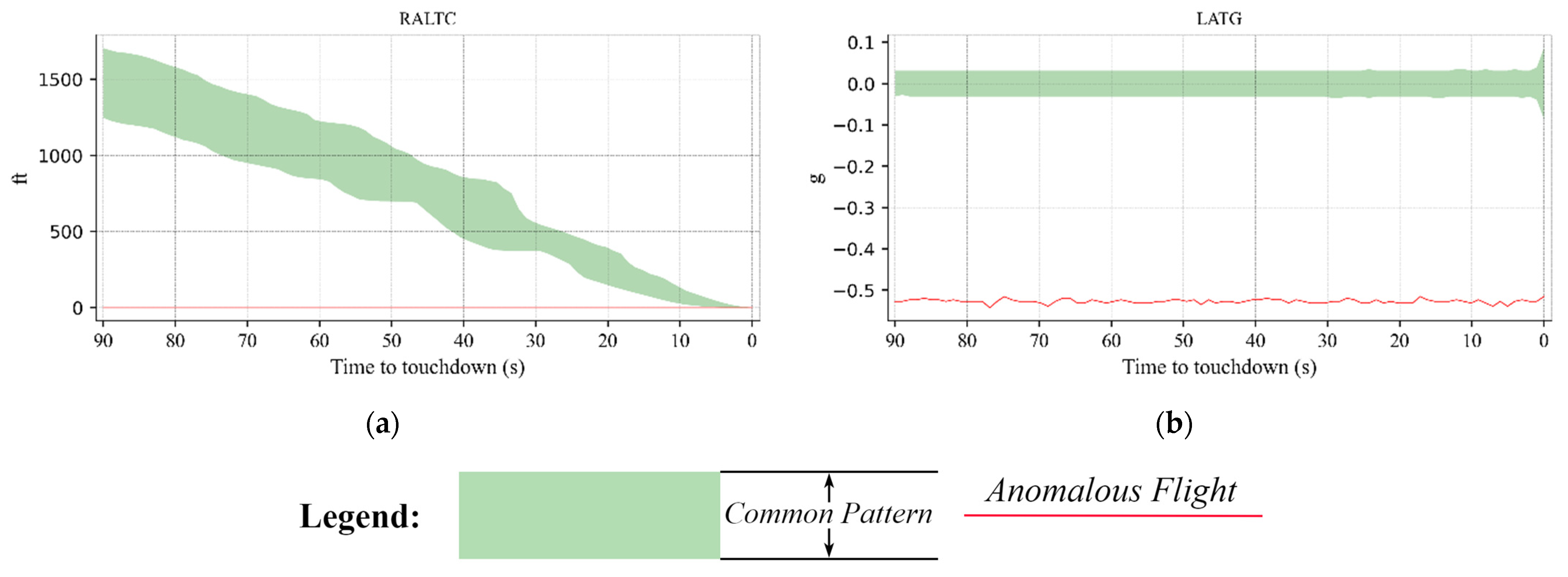
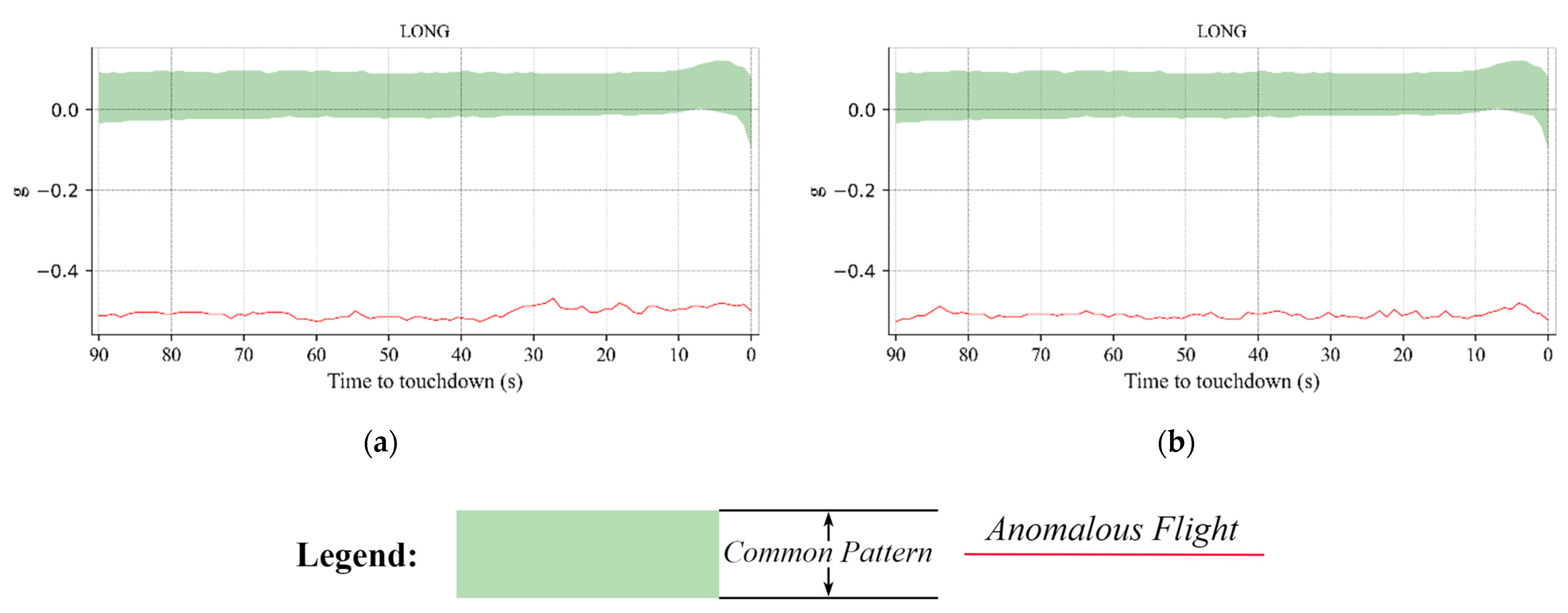
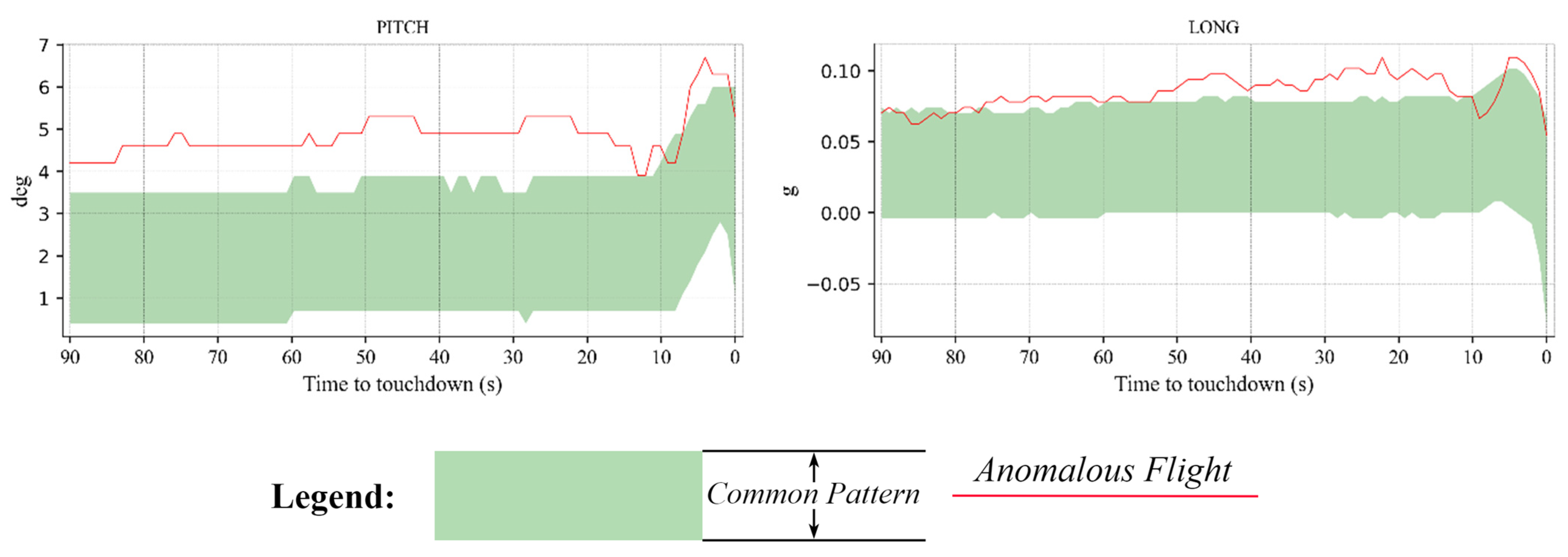
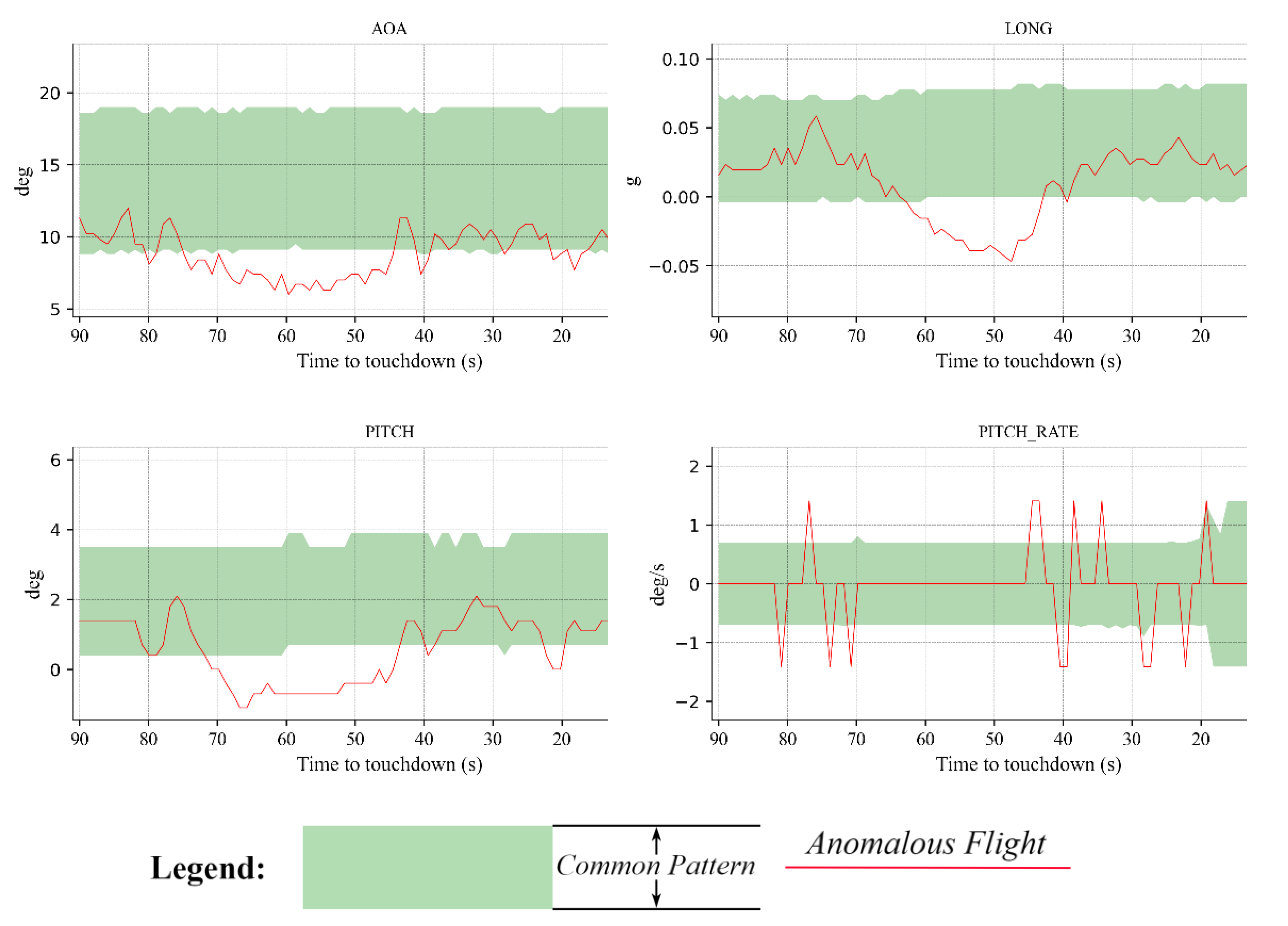
3.5. Anomalous Flights Detected during the Landing Phase
3.5.1. Examples of Anomalous Flights That Landed at the ZPPP Airport
3.5.2. Examples of Anomalous Flights That Landed at the ZUUU Airport
4. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Memarzadeh, M.; Matthews, B.; Avrekh, I. Unsupervised Anomaly Detection in Flight Data Using Convolutional Variational Auto-Encoder. Aerospace 2020, 7, 115. [Google Scholar] [CrossRef]
- Qing, W.A.; Kaiyuan, W.U.; Zhangt, T.; Yi’nan, K.O.; Weiqi, Q.I. Aerodynamic modeling and parameter estimation from QAR data of an airplane approaching a high-altitude airport. Chin. J. Aeronaut. 2012, 25, 361–371. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Outlier detection: A survey. ACM Comput. Surv. 2007, 14, 15. [Google Scholar]
- Hawkins, D.M. Identification of Outliers; Chapman and Hall: London, UK, 1980. [Google Scholar]
- Bach, F.R.; Lanckriet, G.R.; Jordan, M.I. Multiple kernel learning, conic duality, and the SMO algorithm. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; p. 6. [Google Scholar]
- Lanckriet, G.R.; Cristianini, N.; Bartlett, P.; Ghaoui, L.E.; Jordan, M.I. Learning the kernel matrix with semidefinite programming. J. Mach. Learn. Res. 2004, 5, 27–72. [Google Scholar]
- Tax, D.M.; Duin, R.P. Support vector domain description. Pattern Recognit. Lett. 1999, 20, 1191–1199. [Google Scholar] [CrossRef]
- Li, L.; Das, S.; Hansman, R.J.; Palacios, R.; Srivastava, A.N. Analysis of Flight Data Using Clustering Techniques for Detecting Abnormal Operations. J. Aerosp. Inf. Syst. 2015, 12, 587–598. [Google Scholar] [CrossRef] [Green Version]
- Chalapathy, R.; Chawla, S. Deep learning for anomaly detection: A survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Javaid, A.; Niyaz, Q.; Sun, W.; Alam, M. A deep learning approach for network intrusion detection system. Eai Endorsed Trans. Secur. Saf. 2016, 3, e2. [Google Scholar]
- Peng, H.K.; Marculescu, R. Multi-scale compositionality: Identifying the compositional structures of social dynamics using deep learning. PLoS ONE 2015, 10, e0118309. [Google Scholar] [CrossRef]
- Tuor, A.; Kaplan, S.; Hutchinson, B.; Nichols, N.; Robinson, S. Deep learning for unsupervised insider threat detection in structured cybersecurity data streams. In Proceedings of the Workshops at the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Washington, DC, USA, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Reddy, K.K.; Sarkar, S.; Venugopalan, V.; Giering, M. Anomaly Detection and Fault Disambiguation in Large Flight Data: A Multi-modal Deep Auto-encoder Approach. Annu. Conf. Progn. Health Monit. Soc. 2016, 8, 7. [Google Scholar]
- Zhou, C.; Paffenroth, R.C. Anomaly Detection with Robust Deep Autoencoders. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’17), Halifax, NS, Canada, 13–17 August 2017; pp. 665–674. [Google Scholar]
- Xu, H.; Chen, W.; Zhao, N.; Li, Z.; Bu, J.; Li, Z.; Liu, Y.; Zhao, Y.; Peii, D.; Feng, Y.; et al. Unsupervised Anomaly Detection via Variational Auto-Encoder for Seasonal KPIs in Web Applications. In Proceedings of the 2018 WorldWideWeb Conference, Lyon, France, 23–27 April 2018; pp. 187–196. [Google Scholar]
- An, J.; Cho, S. Variational Autoencoder based Anomaly Detection using Reconstruction Probability. Spec. Lect. IE 2015, 2, 1–18. [Google Scholar]
- Zimmerer, D.; Kohl, S.A.; Petersen, J.; Isensee, F.; Maier-Hein, K.H. Context-encoding variational autoencoder for unsupervised anomaly detection. arXiv 2018, arXiv:1812.05941. [Google Scholar]
- Zenati, H.; Foo, C.S.; Lecouat, B.; Manek, G.; Chandrasekhar, V.R. Efficient gan-based anomaly detection. arXiv 2018, arXiv:1802.06222. [Google Scholar]
- Li, D.; Chen, D.; Goh, J.; Ng, S.k. Anomaly Detection with Generative Adversarial Networks for Multivariate Time Series. arXiv 2018, arXiv:1809.04758. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery. In Information Processing in Medical Imaging; Niethammer, M., Styner, M., Aylward, S., Zhu, H., Oguz, I., Yap, P.T., Shen, D., Eds.; Springer International Publishing: Cham, Switzerland, 2017; Volume 10265, pp. 146–157. [Google Scholar]
- Hinton, G.; SAlakhutdinov, R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic backpropagation and approximate inference in deep generative models. In Proceedings of the 31st International Conference on Machine Learning (ICML-14), Beijing, China, 21–26 June 2014; pp. 1278–1286. [Google Scholar]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational Inference: A Review for Statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef] [Green Version]
- Basora, L.; Olive, X.; Dubot, T. Recent advances in anomaly detection methods applied to aviation. Aerospace 2019, 6, 117. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Neural Information Processing Systems Conference 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Langs, G.; Schmidt-Erfurth, U. f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks. Med. Image Anal. 2019, 54, 30–44. [Google Scholar] [CrossRef] [PubMed]
- Campello, R.J.; Moulavi, D.; Sander, J. Density-based clustering based on hierarchical density estimates. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Gold Coast, QLD, Australia, 14–17 April 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 160–172. [Google Scholar]
- Wang, L.; Wu, C.; Sun, R. An analysis of flight Quick Access Recorder (QAR) data and its applications in preventing landing incidents. Reliab. Eng. Syst. Saf. 2014, 127, 86–96. [Google Scholar] [CrossRef]
- Robert, F.S. Flight Dynamics; Princeton University Press: Princeton, NJ, USA, 2015. [Google Scholar]
- Federal Aviation Administration. Airplane Flying Handbook (FAA-H-8083-3A); Skyhorse Publishing Inc.: New York, NY, USA, 2011.
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 2204–2212. [Google Scholar]
- Ba, J.; Mnih, V.; Kavukcuoglu, K. Multiple object recognition with visual attention. arXiv 2014, arXiv:1412.7755. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057, PMLR. [Google Scholar]
- Liu, M.; Li, L.; Hu, H.; Guan, W.; Tian, J. Image caption generation with dual attention mechanism. Inf. Process. Manag. 2020, 57, 102178. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. arXiv 2015, arXiv:1506.02025. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Gorokhov, O.; Petrovskiy, M.; Mashechkin, I. Convolutional neural networks for unsupervised anomaly detection in text data. In Proceedings of the International Conference on Intelligent Data Engineering and Automated Learning, Guilin, China, 30 October–1 November 2017; Springer: Cham, Switzerland, 2017; pp. 500–507. [Google Scholar]
- Peter, J.H. “Robust Estimation of a Location Parameter”; Breakthroughs in statistics; Springer: New York, NY, USA, 1992; pp. 492–518. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. Kdd 1996, 96, 226–231. [Google Scholar]
- Malzer, C.; Baum, M. A Hybrid Approach to Hierarchical Density-based Cluster Selection. In Proceedings of the 2020 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), 14 September 2020; pp. 223–228. Available online: https://doi.org/10.48550/arXiv.1911.02282 (accessed on 18 May 2022).
- Ankerst, M.; Breunig, M.M.; Kriegel, H.P.; Sander, J. OPTICS: Ordering points to identify the clustering structure. ACM Sigmod Rec. 1999, 28, 49–60. [Google Scholar] [CrossRef]
- Gupta, G.; Liu, A.; Ghosh, J. Automated hierarchical density shaving: A robust automated clustering and visualization framework for large biological data sets. IEEE/ACM Trans. Comput. Biol. Bioinform. 2008, 7, 223–237. [Google Scholar] [CrossRef]
- Pei, T.; Jasra, A.; Hand, D.J.; Zhu, A.X.; Zhou, C. DECODE: A new method for discovering clusters of different densities in spatial data. Data Min. Knowl. Discov. 2009, 18, 337. [Google Scholar] [CrossRef]
- Sander, J.; Qin, X.; Lu, Z.; Niu, N.; Kovarsky, A. Automatic extraction of clusters from hierarchical clustering representations. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Seoul, Korea, 30 April–2 May 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 75–87. [Google Scholar]
- McInnes, L.; Healy, J. Accelerated hierarchical density-based clustering. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), IEEE, New Orleans, LA, USA, 18–21 November 2017; pp. 33–42. [Google Scholar]
- McInnes, L.; Healy, J.; Astels, S. hdbscan: Hierarchical density based clustering. J. Open Source Softw. 2017, 2, 205. [Google Scholar] [CrossRef]
- Prim, R.C. Shortest connection networks and some generalizations. Bell Syst. Tech. J. 1957, 36, 1389–1401. [Google Scholar] [CrossRef]
- Galler, B.A.; Fisher, M.J. An improved equivalence algorithm. Commun. ACM 1964, 7, 301–303. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Moulavi, D.; Jaskowiak, P.A.; Campello, R.J.; Zimek, A.; Sander, J. Density-based clustering validation. In Proceedings of the 2014 SIAM International Conference on Data Mining, Philadelphia, PA, USA, 24–26 April 2014; pp. 839–847. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Davies, D.L.; Bouldin, D.W. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 1, 224–227. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Parameter Name in QAR | Units |
|---|---|---|
| Angle of attack | AOA | deg |
| Angle of pitch | PITCH | deg |
| Angle of roll | ROLL | deg |
| Angle of flight path | FPA | deg |
| Rate of pitch change | PITCH_RATE | deg/s |
| Indicated air speed of calibration | IASC | knot/s |
| Ground Speed of calibration | GSC | knot/s |
| Instantaneous vertical velocity | IVV | g |
| Lateral acceleration G-Force | LATG | g |
| Longitudinal acceleration G-force | LONG | g |
| Vertical acceleration G-force | VRTG | g |
| Radar altitude of calibration | RALTC | ft |
| Name of Dataset | Size of Dataset |
|---|---|
| Training set | 9936 |
| Validation set | 4259 |
| Models | Loss Errors |
|---|---|
| TFA-CAE | 0.0009 |
| SA-CAE | 0.0013 |
| GRU-AE | 0.0016 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, K.; Wang, Q.; Lu, B.; Sun, H.; Shu, P. Flight Anomaly Detection via a Deep Hybrid Model. Aerospace 2022, 9, 329. https://doi.org/10.3390/aerospace9060329
Qin K, Wang Q, Lu B, Sun H, Shu P. Flight Anomaly Detection via a Deep Hybrid Model. Aerospace. 2022; 9(6):329. https://doi.org/10.3390/aerospace9060329
Chicago/Turabian StyleQin, Kun, Qixin Wang, Binbin Lu, Huabo Sun, and Ping Shu. 2022. "Flight Anomaly Detection via a Deep Hybrid Model" Aerospace 9, no. 6: 329. https://doi.org/10.3390/aerospace9060329