
Visual Navigation Algorithm for Night Landing of Fixed-Wing Unmanned Aerial Vehicle


Abstract
:1. Introduction
- (1)
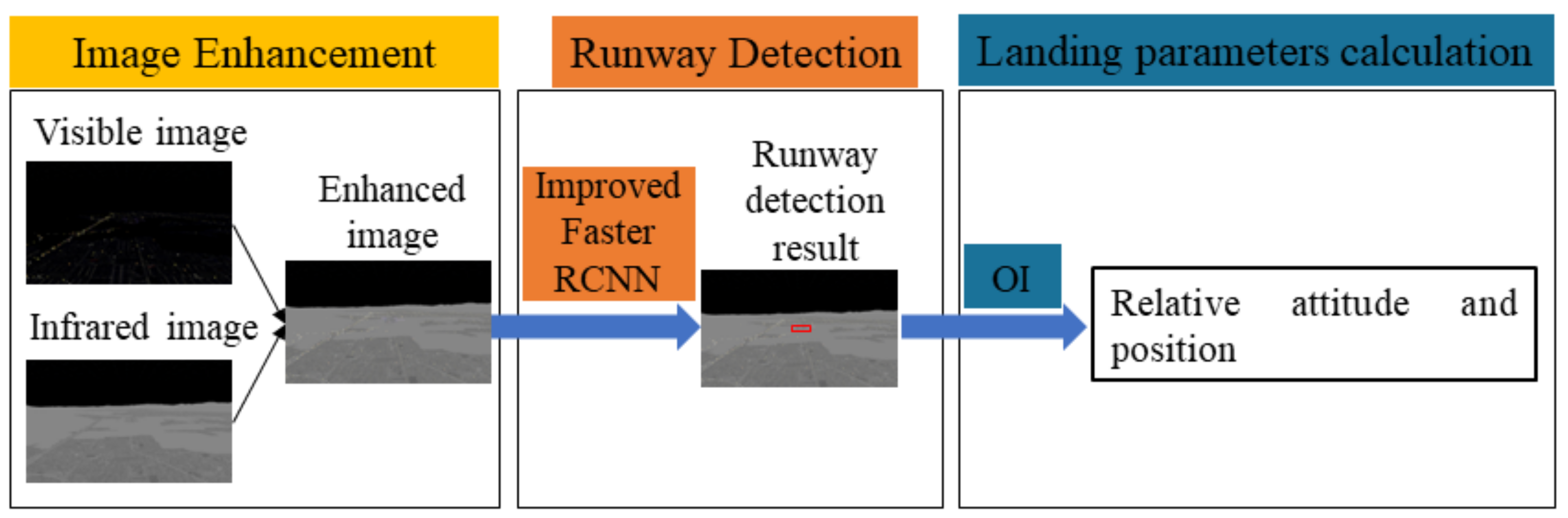
- For fixed-wing UAV autonomous landing at night, an image brightness enhancement method based on visible and infrared images fusion is proposed. While effectively enhancing brightness, more texture information is preserved.
- (2)
- Since it is difficult for ordinary visual detection algorithms to detect runway targets from the enhanced image, a runway detection algorithm based on an improved Faster R-CNN is proposed. The ResNet101 model that is most suitable for the runway detection scene is selected, and the size of the anchor is tailored specifically according to the statistical analysis results of the runway ground-truth box label.
- (3)
- As an indirect result, this manuscript presents a complete system for fixed-wing UAVs landing at night by means of visual navigation.
2. Illuminance Enhancement Based on Visible and Infrared Image Fusion
2.1. Establishment of Objective Function
2.2. Solving Objective Function
| Algorithm 1 Visible and infrared image fusion algorithm. |
| Input: visible image I, infrared image V, parameter Output: fused image F
|
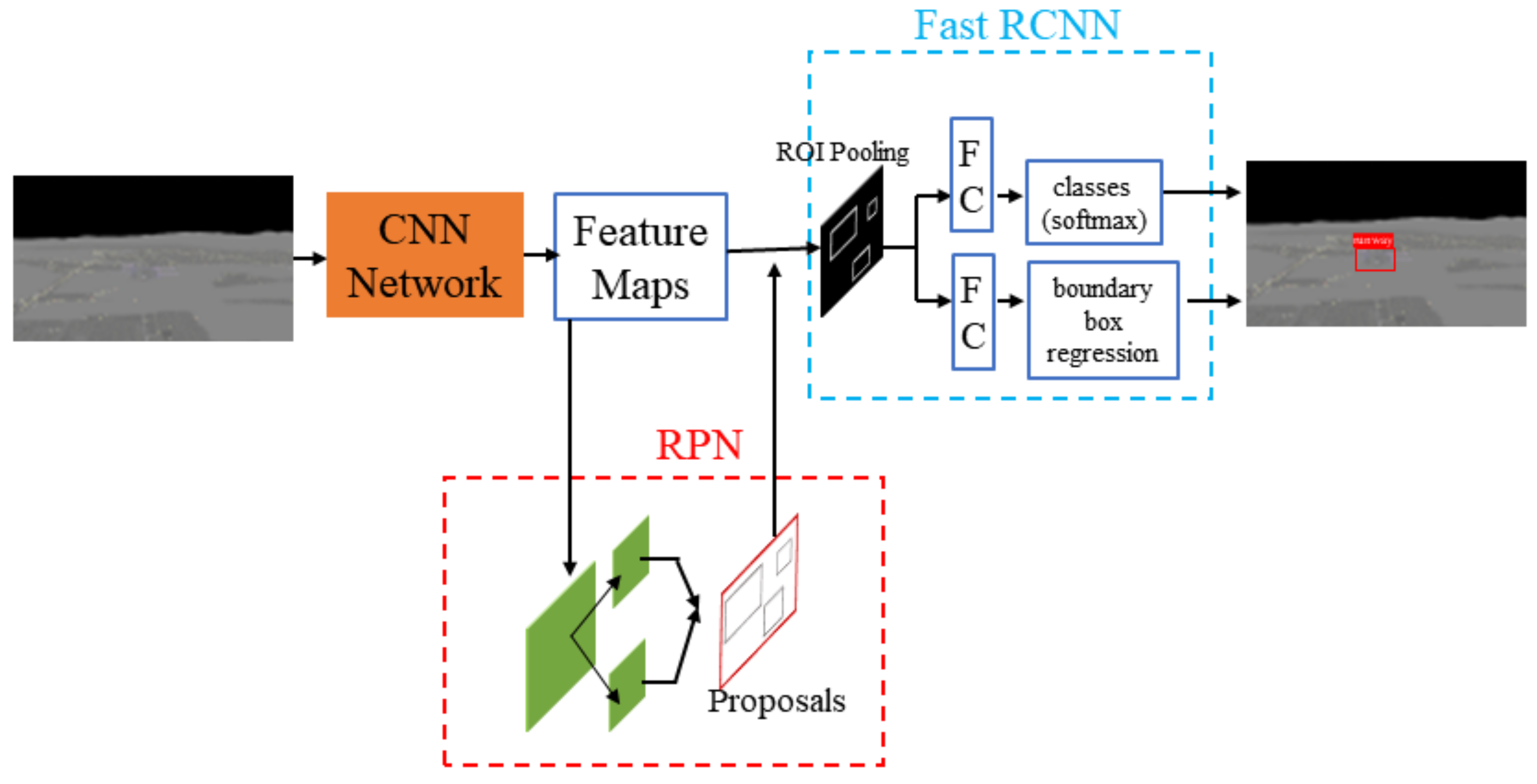
3. Runway Detection Based on Improved Faster R-CNN
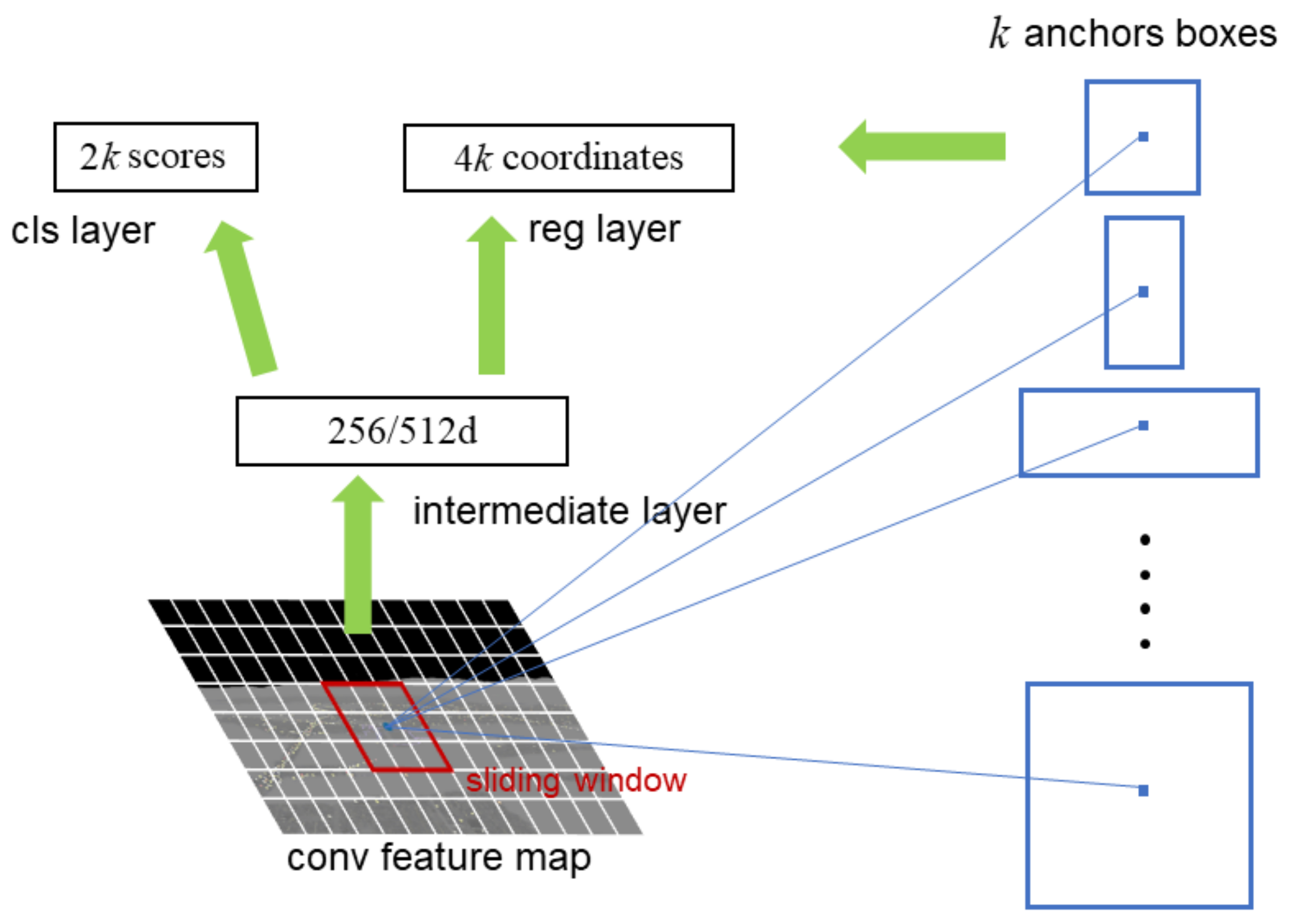
3.1. Region Proposal Network
3.2. Fast R-CNN Detector
4. Landing Parameter Calculation
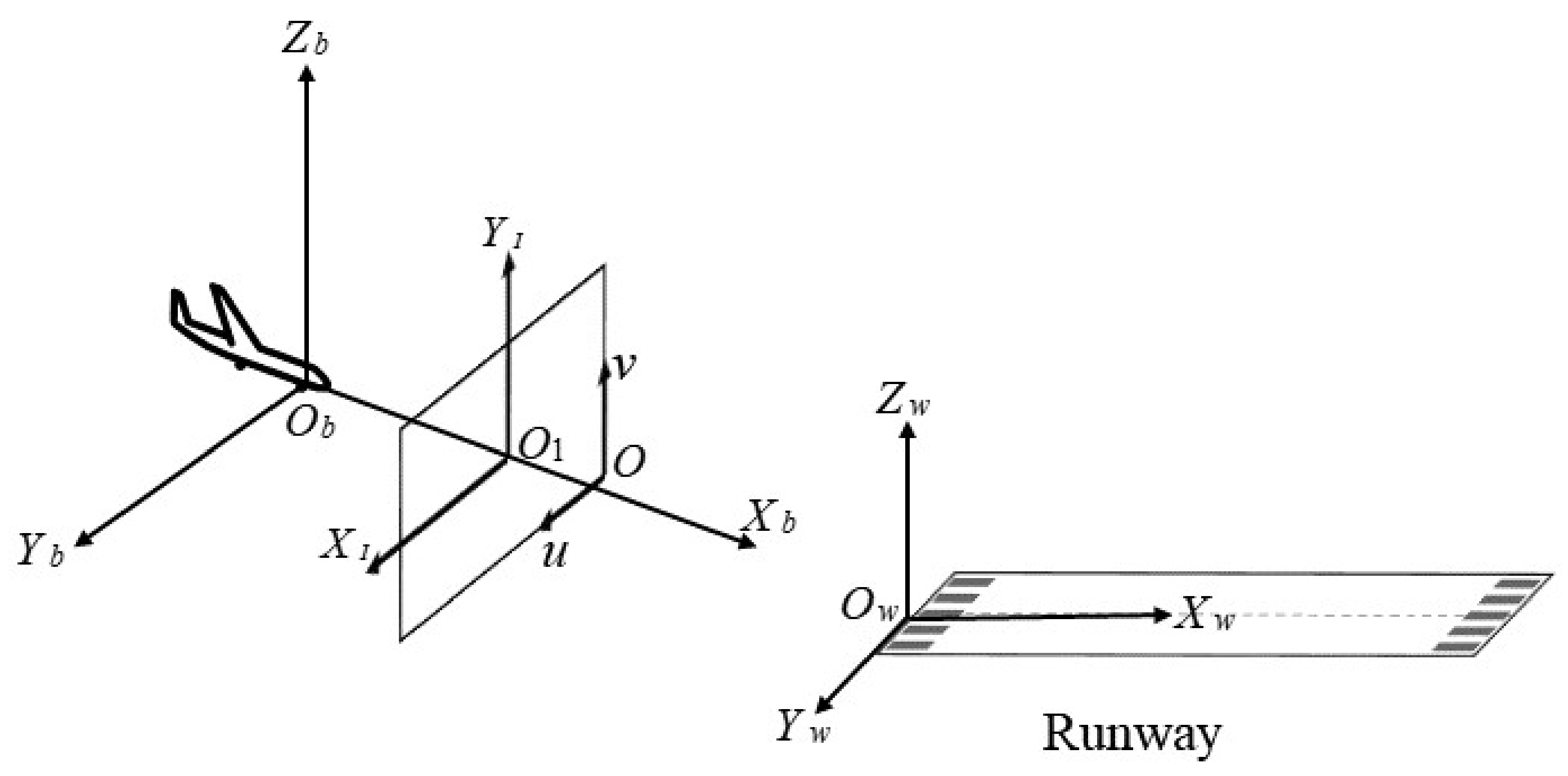
4.1. Construction of Reference Coordinate System
- (1)
- Earth-fixed coordinate system : the origin of Earth-fixed coordinate system can be fixed anywhere. Since the study only focuses on the attitude and position of the UAV relative to the runway, the Earth-fixed coordinate system was set at the runway plane.
- (2)
- Camera reference coordinate system : the camera was fixed at the center of the UAV body. Thus, the body coordinate system and camera reference coordinate system are the same.
- (3)
- Image coordinate system : the origin of Image coordinate system is the intersection of the camera optical axis and the image plane, usually the image center point.
- (4)
- Pixel coordinate system : the Pixel coordinate system is established on the pixel plane, and the unit is pixel. The digital image is stored in the form of , so the pixel coordinate represents the position of the pixel in the array .
4.2. Calculation of Relative Attitude and Position
5. Simulation Results and Discussion
5.1. Simulation Dataset Setup
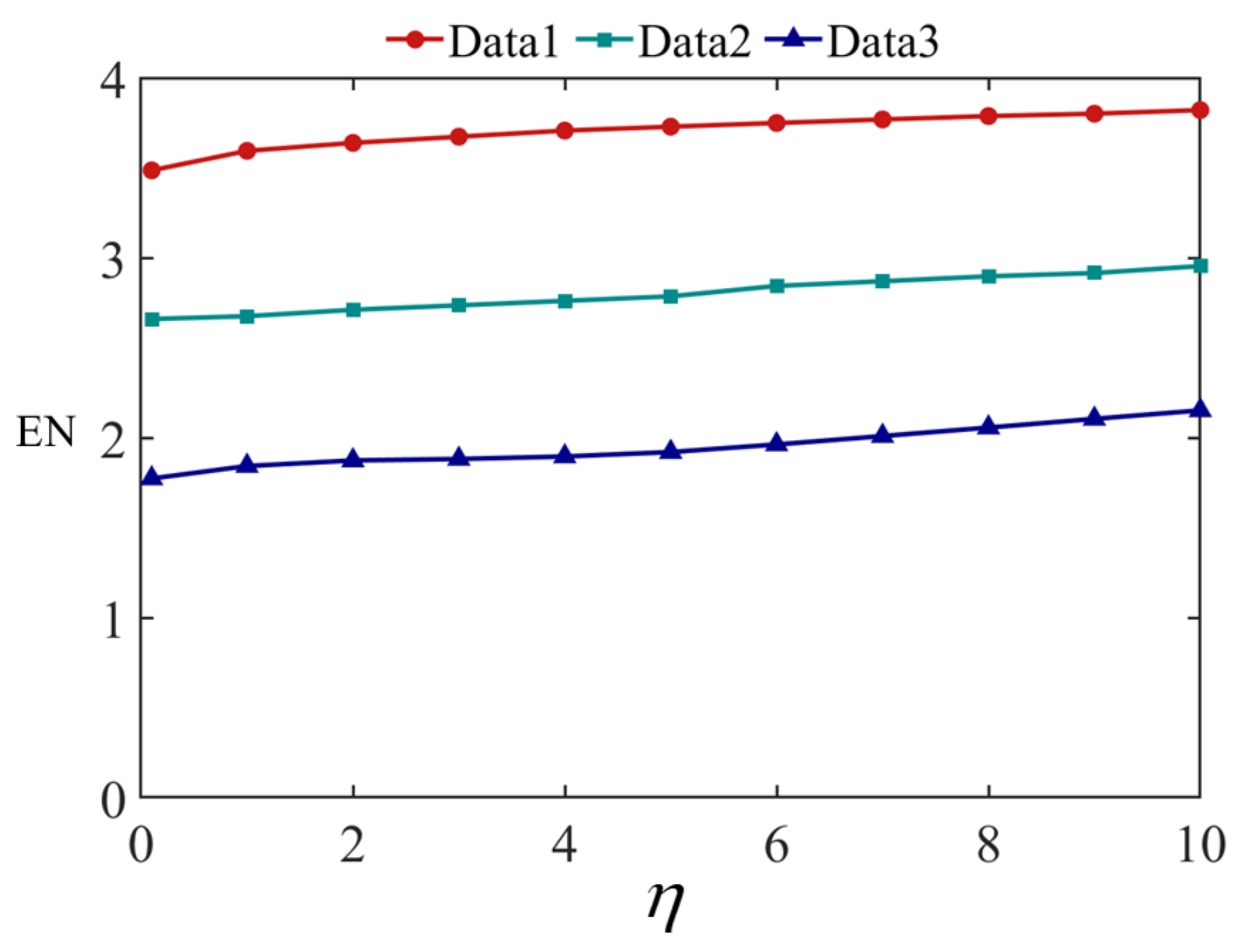
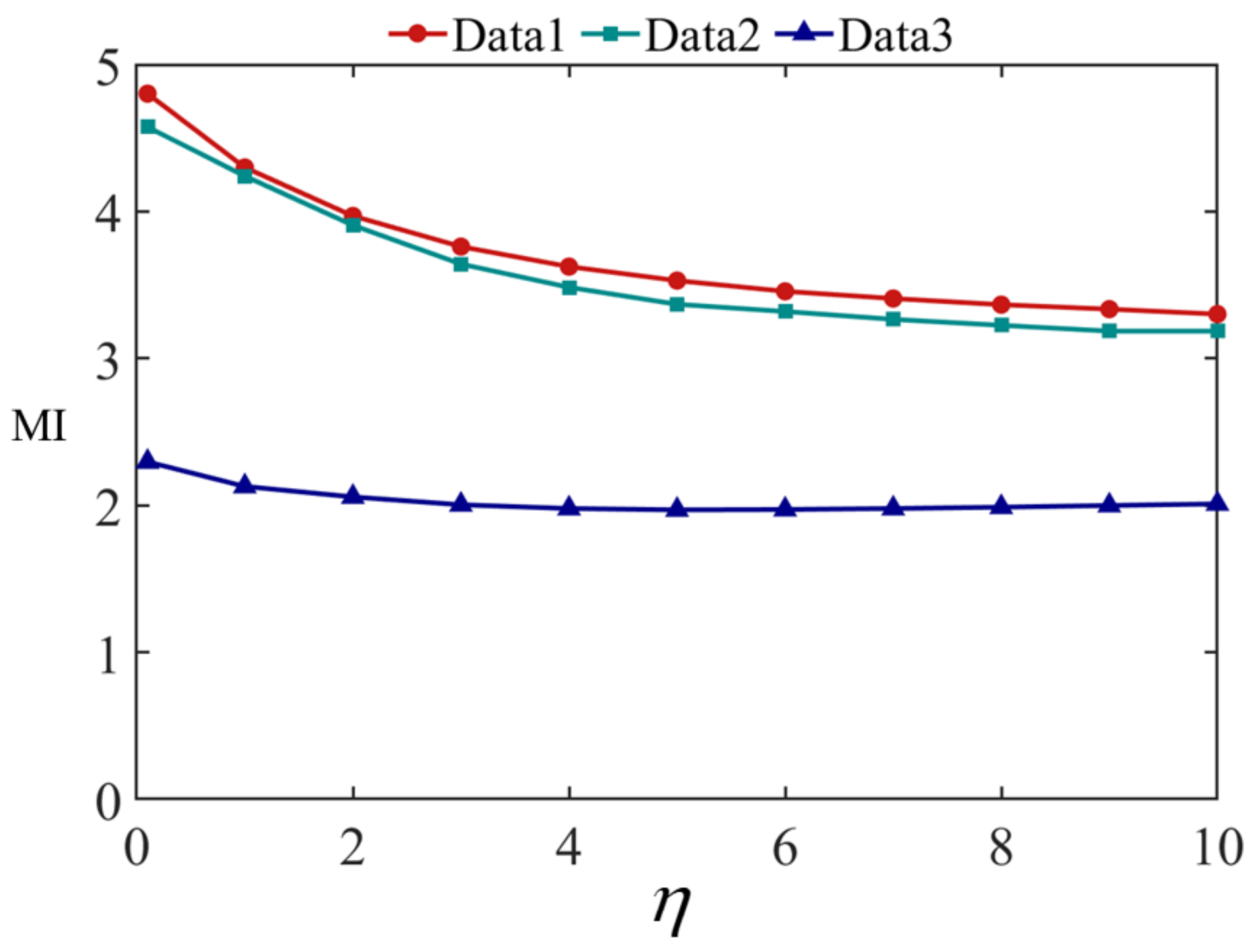
5.2. Fusion Experiment when Changes
- EN evaluates the amount of image information after fusion.
- MI evaluates the image fusion performance by measuring the amount of information a given variable contains about another variable. In other words, it measures the dependence between the infrared and visible images.
- evaluates the amount of detail texture information in the fused image that was transferred from the infrared and visible images.
5.3. Runway Detection
5.3.1. Influence of Different Feature Extraction Networks on Runway Detection
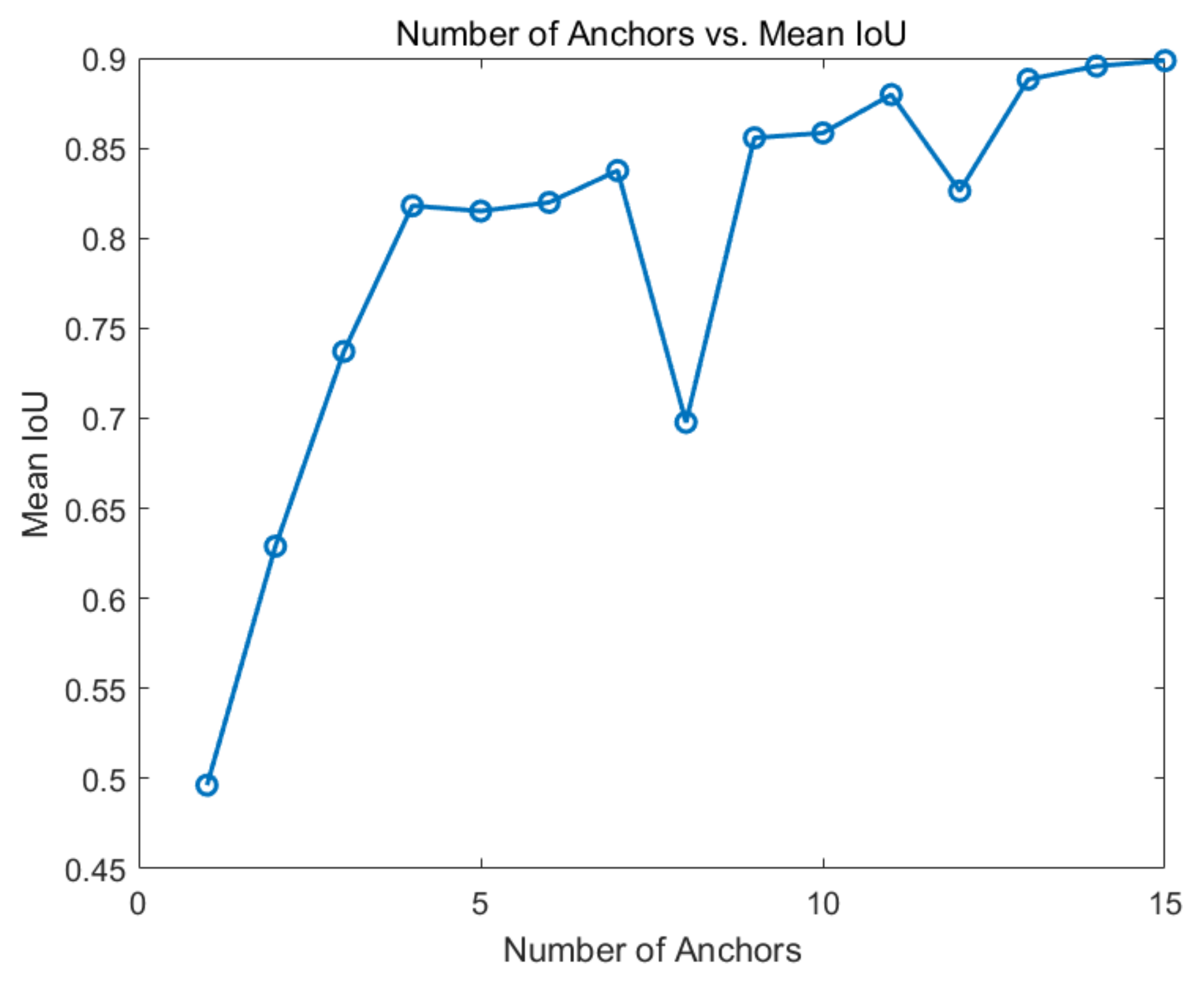
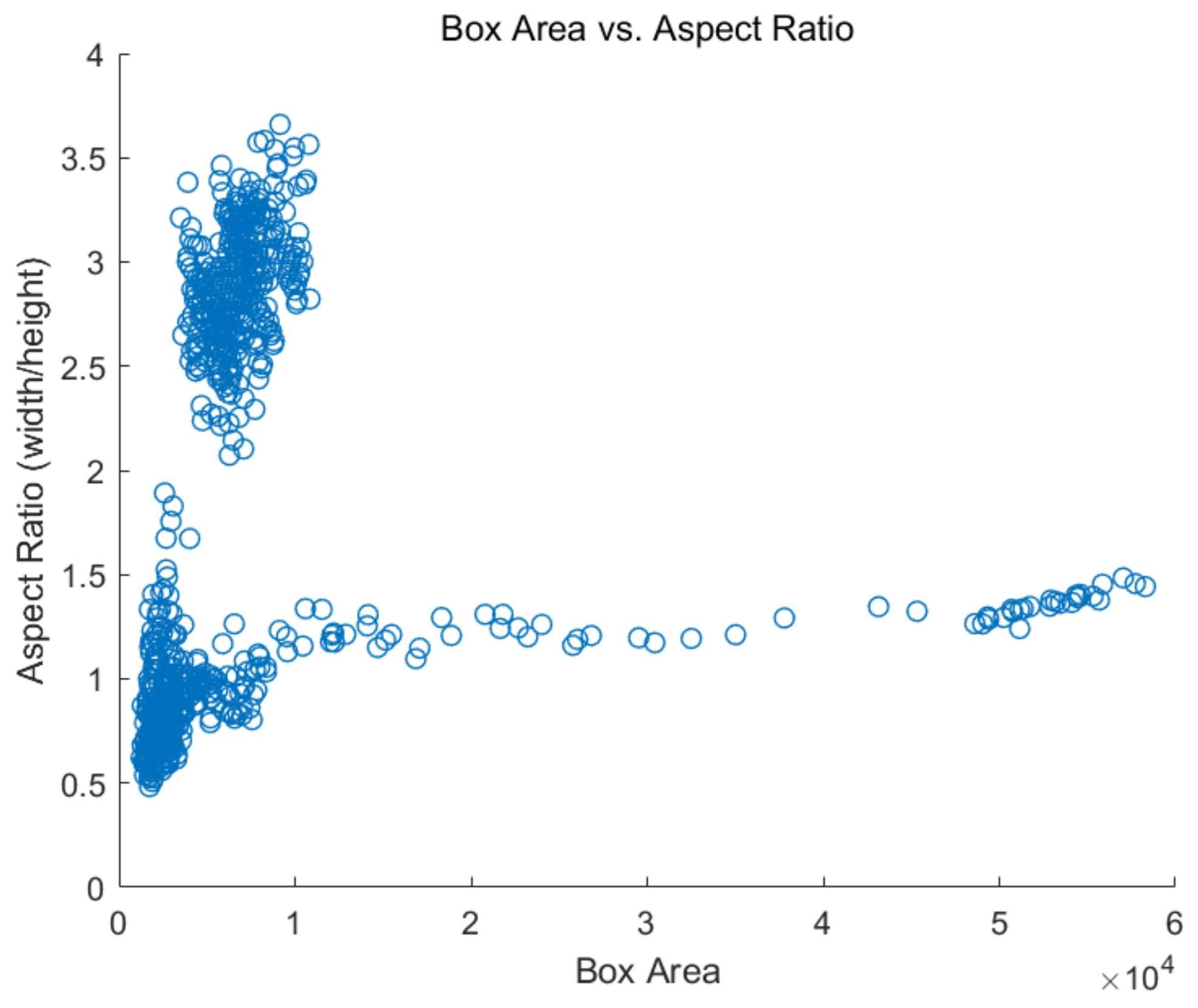
5.3.2. Influence of Different Anchor Size on Runway Detection
5.4. Relative Attitude and Position Calculation
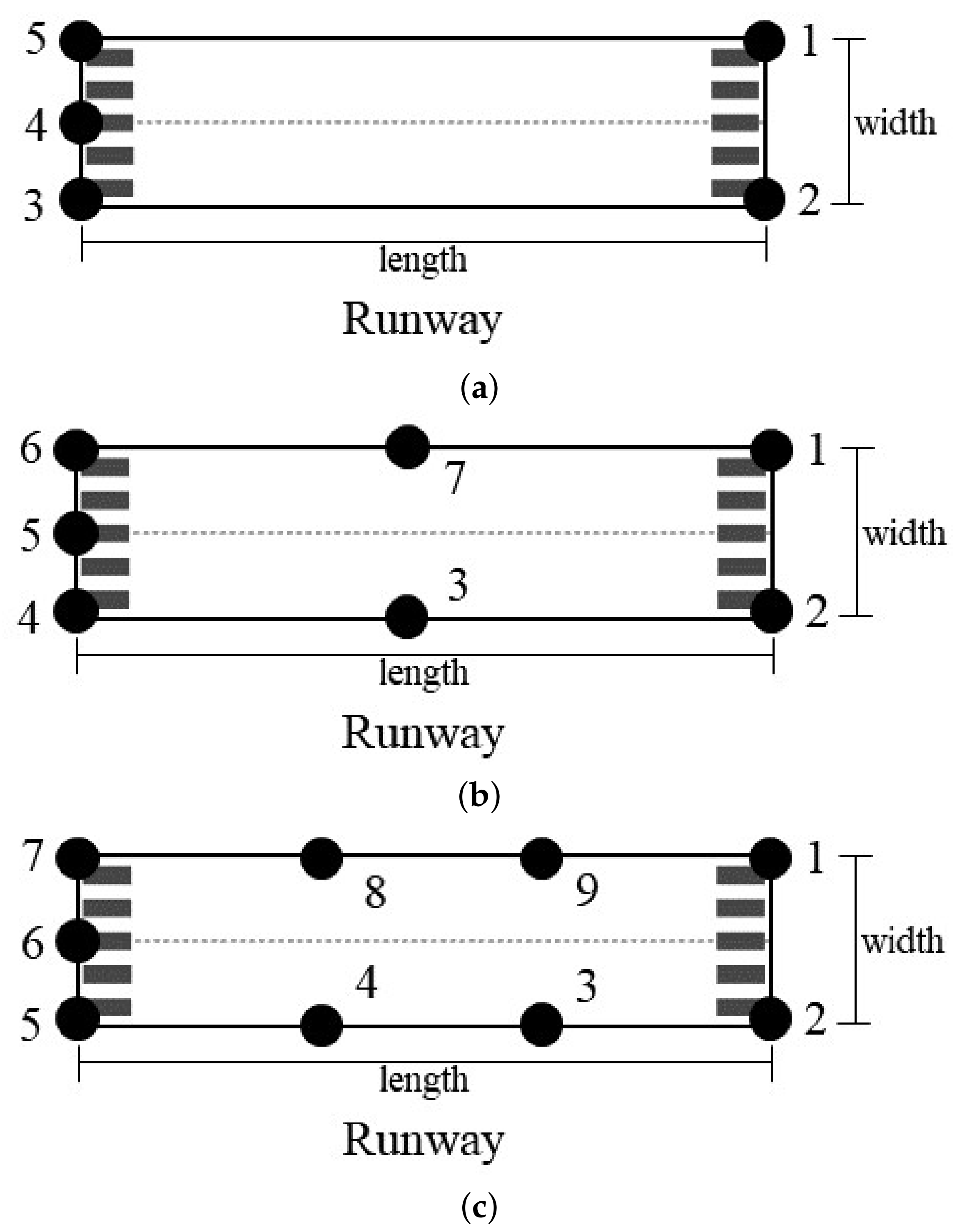
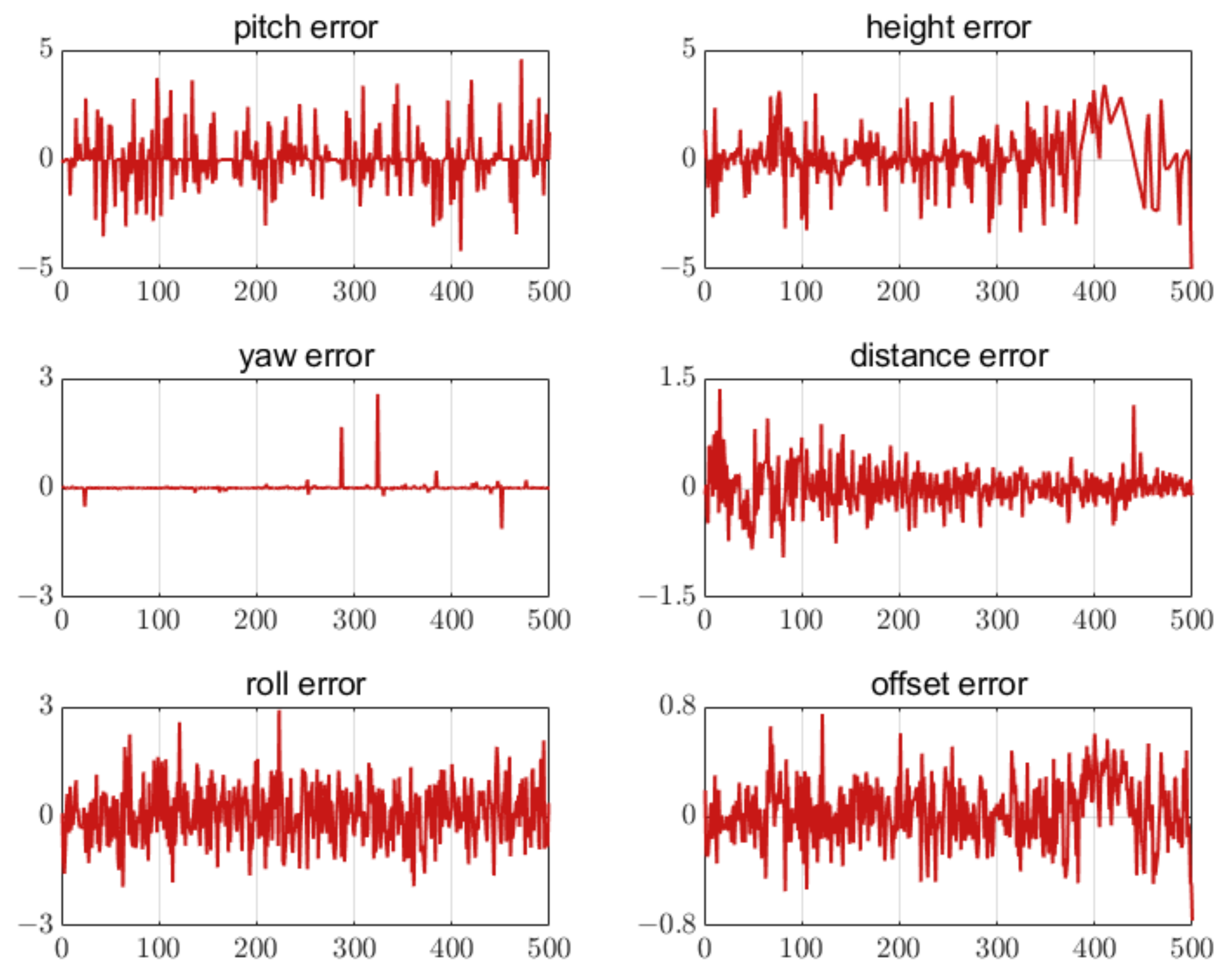
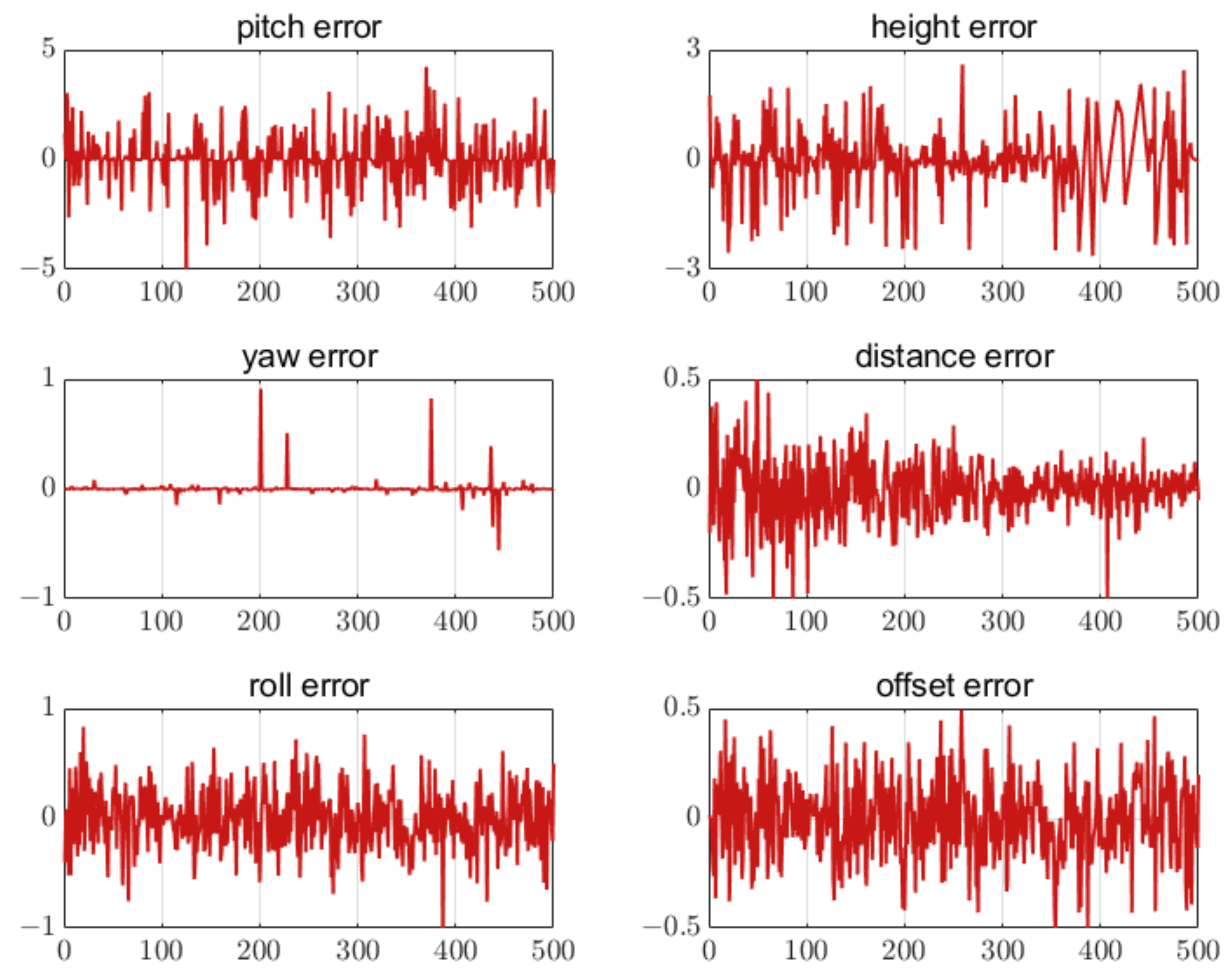
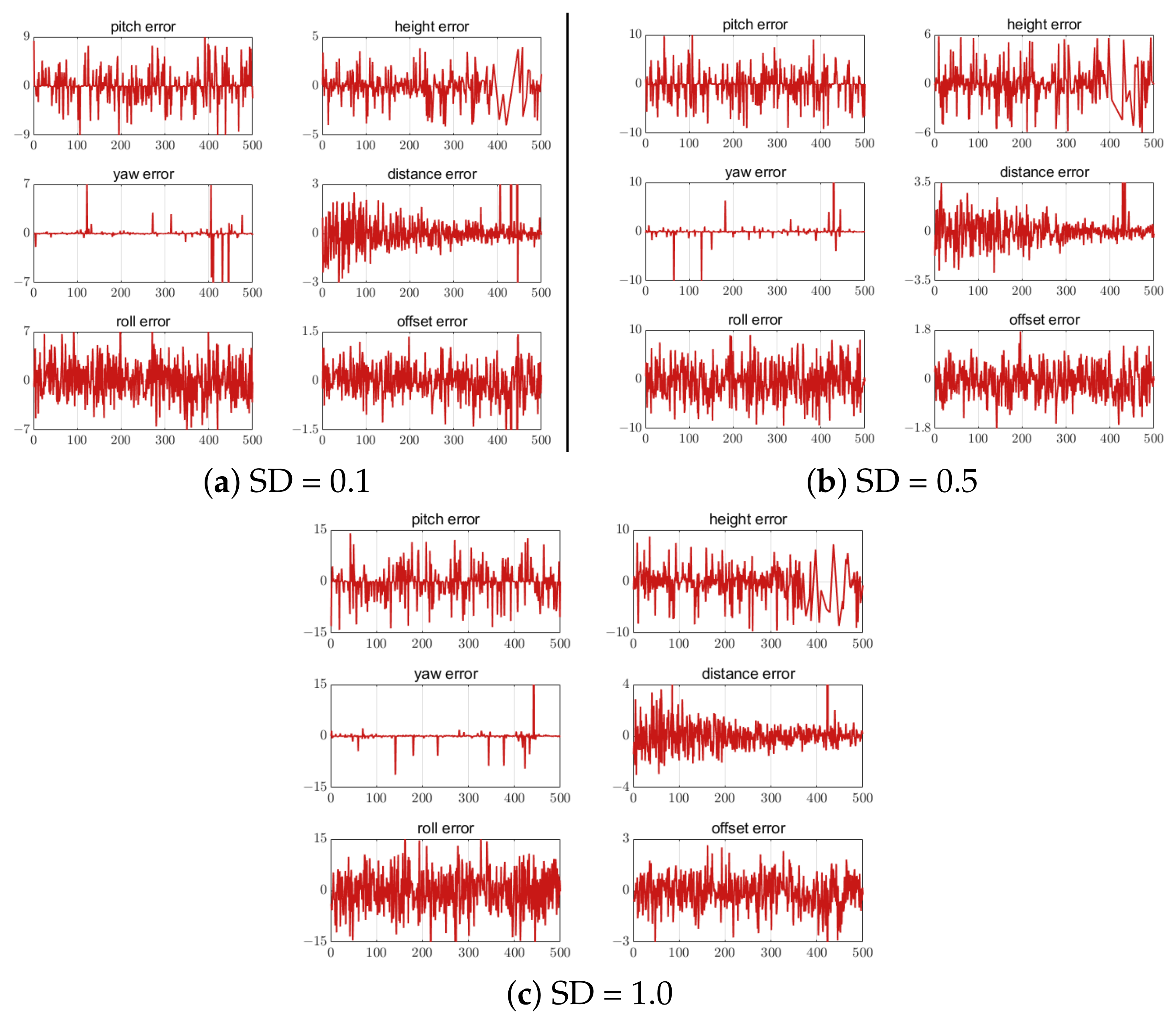
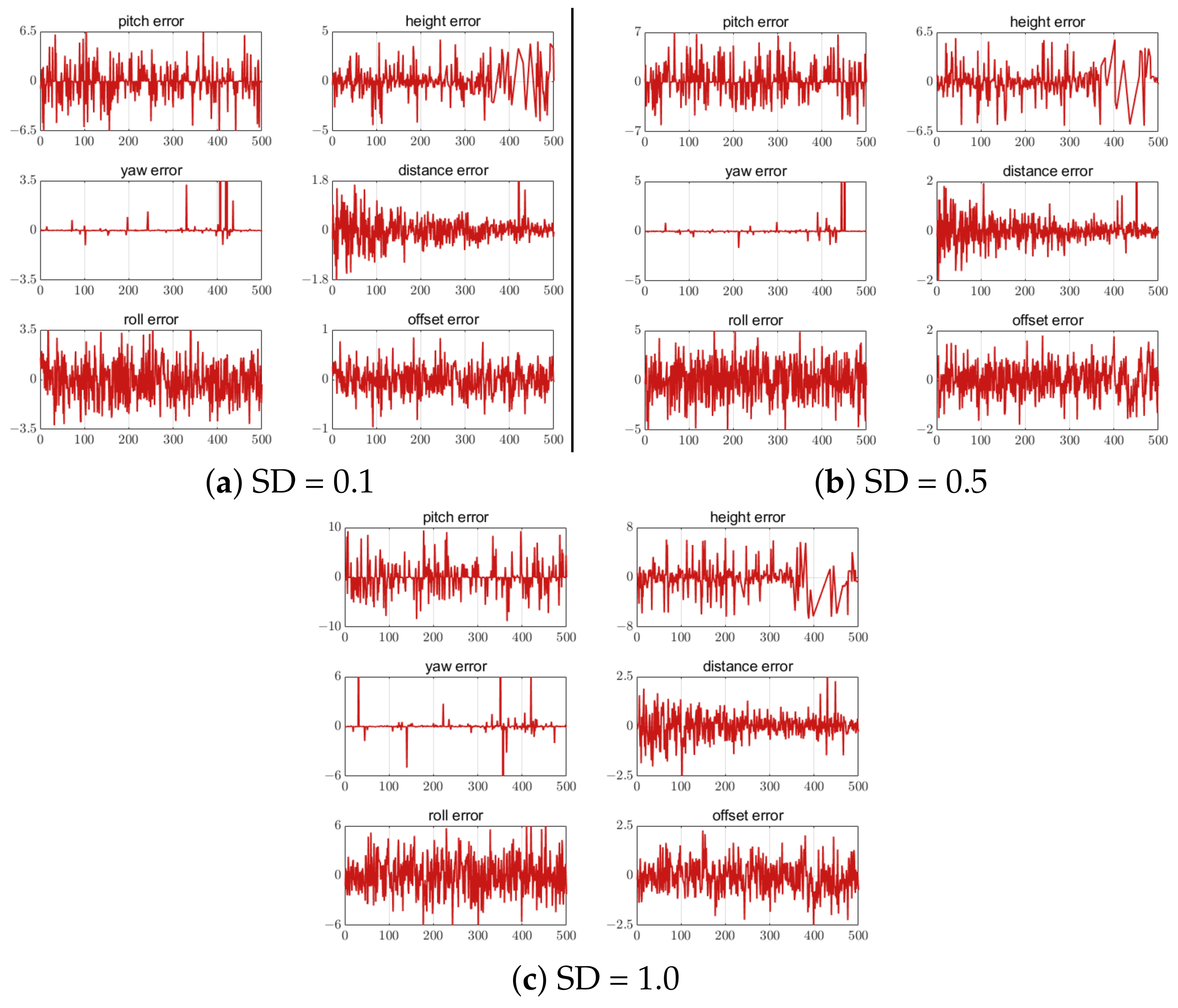
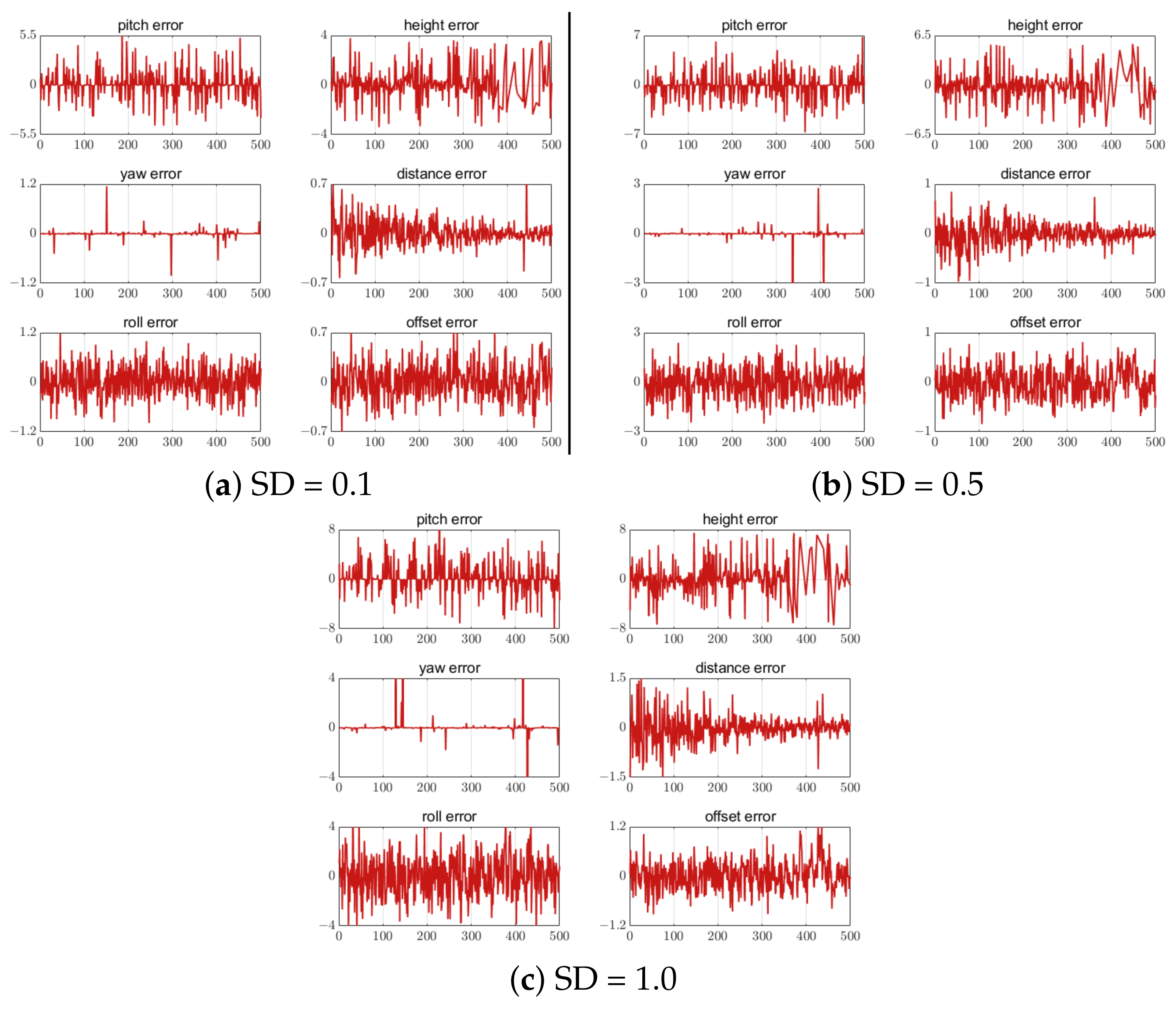
5.4.1. Error of Different Numbers of Feature Points
5.4.2. Feature Point Extraction Error
5.4.3. Computational Cost as Feature Points Increase
5.5. Comparison with Other Methods
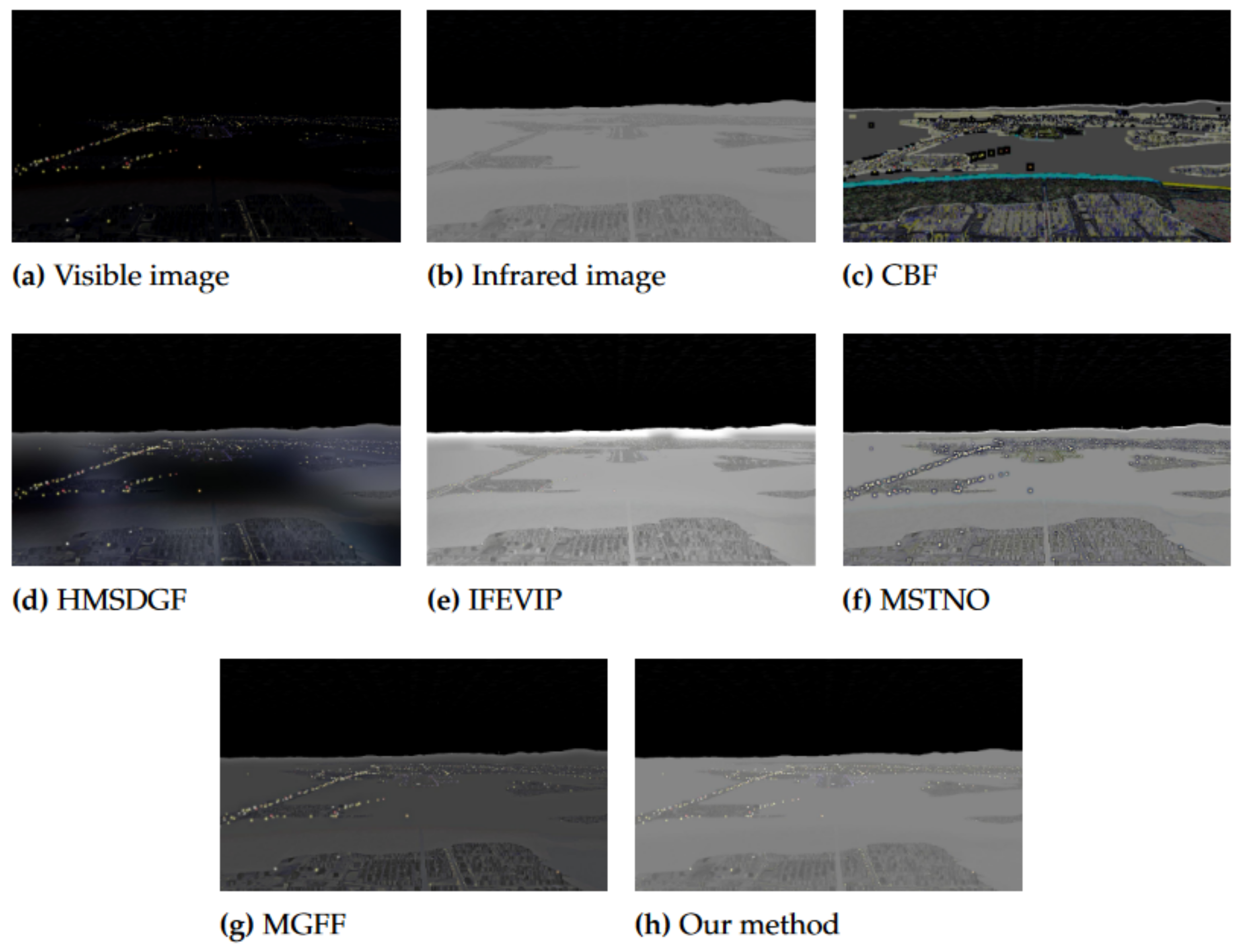
5.5.1. Fusion Comparison
5.5.2. Runway Detection Comparison
5.5.3. Pose Calculation Comparison
6. Conclusions
- For the problem of the low brightness of airborne images taken at night, which make it difficult to extract runway information and identify runway objects, an image fusion method based on gradient descent to obtain the enhanced images was proposed. This method ensures the retention of more texture details and other feature information while enhancing the brightness.
- For the problem in which the original Faster R-CNN could not be effectively applied to the runway detection scene, the anchors were redesigned and improved. Additionally, the ResNet101 network was selected, which is the most suitable for runway feature extraction. The simulation results show that, for runway detection, we can achieve 1.85% improvement of AP by the improved Faster R-CNN.
- For the low efficiency and poor real-time performance of nonlinear algorithms in calculating the R and T, a relative attitude and position estimation method based on the OI algorithm was proposed. The simulation results show that the reprojection error of rotation and translation for pose estimation can be as little as and 0.581%, respectively.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, X.; Phang, S.K.; Chen, B.M. System integration of a vision-guided UAV for autonomous tracking on moving platform in low illumination condition. In Proceedings of the ION 2017 Pacific PNT Meeting, Honolulu, HI, USA, 1–4 May 2017. [Google Scholar]
- Hai, J.; Hao, Y.; Zou, F.; Lin, F.; Han, S. A Visual Navigation System for UAV under Diverse Illumination Conditions. Appl. Artif. Intell. 2021, 35, 1529–1549. [Google Scholar] [CrossRef]
- Dudek, P.; Richardson, T.; Bose, L.; Carey, S.; Chen, J.; Greatwood, C.; Liu, Y.; Mayol-Cuevas, W. Sensor-level computer vision with pixel processor arrays for agile robots. Sci. Robot. 2022, 7, eabl7755. [Google Scholar] [CrossRef] [PubMed]
- Benini, A.; Rutherford, M.J.; Valavanis, K.P. Real-time, GPU-based pose estimation of a UAV for autonomous takeoff and landing. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016. [Google Scholar]
- Kumar V, S.; Kashyap, S.K.; Kumar, N.S. Detection of Runway and Obstacles using Electro-optical and Infrared Sensors before Landing. Def. Sci. J. 2014, 64, 67–76. [Google Scholar]
- Jagannath, J.; Jagannath, A.; Furman, S.; Gwin, T. Deep learning and reinforcement learning for autonomous unmanned aerial systems: Roadmap for theory to deployment. In Deep Learning for Unmanned Systems; Springer: Berlin/Heidelberg, Germany, 2021; pp. 25–82. [Google Scholar]
- Araar, O.; Aouf, N.; Vitanov, I. Vision based autonomous landing of multirotor UAV on moving platform. J. Intell. Robot. Syst. 2017, 85, 369–384. [Google Scholar] [CrossRef]
- Brukarczyk, B.; Nowak, D.; Kot, P.; Rogalski, T.; Rzucidło, P. Fixed Wing Aircraft Automatic Landing with the Use of a Dedicated Ground Sign System. Aerospace 2021, 8, 167. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, S.; Chen, G.; Dong, W. Robust Visual Positioning of the UAV for the Under Bridge Inspection With a Ground Guided Vehicle. IEEE Trans. Instrum. Meas. 2021, 71, 1–10. [Google Scholar] [CrossRef]
- Liang, X.; Chen, G.; Zhao, S.; Xiu, Y. Moving target tracking method for unmanned aerial vehicle/unmanned ground vehicle heterogeneous system based on AprilTags. Meas. Control 2020, 53, 427–440. [Google Scholar] [CrossRef] [Green Version]
- Khazetdinov, A.; Zakiev, A.; Tsoy, T.; Svinin, M.; Magid, E. Embedded ArUco: A novel approach for high precision UAV landing. In Proceedings of the 2021 International Siberian Conference on Control and Communications (SIBCON), Kazan, Russia, 13–15 May 2021. [Google Scholar]
- Pang, Y.; Cheng, S.; Hu, J.; Liu, Y. Evaluating the robustness of bayesian neural networks against different types of attacks. arXiv 2021, arXiv:2106.09223. [Google Scholar]
- Chan, T.F.; Esedoglu, S. Aspects of total variation regularized L 1 function approximation. SIAM J. Appl. Math. 2005, 65, 1817–1837. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.Q.; Zheng, P.; Xu, S.t.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, CA, USA, 27–30 June 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29, 4–9. [Google Scholar]
- Wan, S.; Goudos, S. Faster R-CNN for multi-class fruit detection using a robotic vision system. Comput. Netw. 2020, 168, 10703–107042. [Google Scholar] [CrossRef]
- Li, C.j.; Qu, Z.; Wang, S.y.; Liu, L. A method of cross-layer fusion multi-object detection and recognition based on improved faster R-CNN model in complex traffic environment. Pattern Recognit. Lett. 2021, 145, 127–134. [Google Scholar] [CrossRef]
- Yang, Y.; Gong, H.; Wang, X.; Sun, P. Aerial target tracking algorithm based on faster R-CNN combined with frame differencing. Aerospace 2017, 4, 32. [Google Scholar] [CrossRef] [Green Version]
- Doğru, A.; Bouarfa, S.; Arizar, R.; Aydoğan, R. Using convolutional neural networks to automate aircraft maintenance visual inspection. Aerospace 2020, 7, 171. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, CA, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lu, C.P.; Hager, G.D.; Mjolsness, E. Fast and globally convergent pose estimation from video images. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 610–622. [Google Scholar] [CrossRef] [Green Version]
- Download Link if FightGear 2020.3. Available online: https://www.flightgear.org/ (accessed on 1 December 2021).
- Liu, Y.; Liu, S.; Wang, Z. A general framework for image fusion based on multi-scale transform and sparse representation. Inf. Fusion 2015, 24, 147–164. [Google Scholar] [CrossRef]
- Qu, G.; Zhang, D.; Yan, P. Information measure for performance of image fusion. Electron. Lett. 2002, 38, 313–315. [Google Scholar] [CrossRef] [Green Version]
- Xydeas, C.; Petrovic, V. Objective image fusion performance measure. Electron. Lett. 2000, 36, 308–309. [Google Scholar] [CrossRef] [Green Version]
- Han, L.; Yu, C.; Xiao, K.; Zhao, X. A new method of mixed gas identification based on a convolutional neural network for time series classification. Sensors 2019, 19, 1960. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bazi, Y.; Al Rahhal, M.M.; Alhichri, H.; Alajlan, N. Simple yet effective fine-tuning of deep CNNs using an auxiliary classification loss for remote sensing scene classification. Remote Sens. 2019, 11, 2908. [Google Scholar] [CrossRef] [Green Version]
- Ji, C.; Cheng, L.; Li, N.; Zeng, F.; Li, M. Validation of global airport spatial locations from open databases using deep learning for runway detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1120–1131. [Google Scholar] [CrossRef]
- Shreyamsha Kumar, B. Image fusion based on pixel significance using cross bilateral filter. Signal Image Video Process. 2015, 9, 1193–1204. [Google Scholar] [CrossRef]
- Zhou, Z.; Dong, M.; Xie, X.; Gao, Z. Fusion of infrared and visible images for night-vision context enhancement. Appl. Opt. 2016, 55, 6480–6490. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, L.; Bai, X.; Zhang, L. Infrared and visual image fusion through infrared feature extraction and visual information preservation. Infrared Phys. Technol. 2017, 83, 227–237. [Google Scholar] [CrossRef]
- Li, G.; Lin, Y.; Qu, X. An infrared and visible image fusion method based on multi-scale transformation and norm optimization. Inf. Fusion 2021, 71, 109–129. [Google Scholar] [CrossRef]
- Bavirisetti, D.P.; Xiao, G.; Zhao, J.; Dhuli, R.; Liu, G. Multi-scale guided image and video fusion: A fast and efficient approach. Circ. Syst. Signal Process. 2019, 38, 5576–5605. [Google Scholar] [CrossRef]
- Xiao, Z.; Gong, Y.; Long, Y.; Li, D.; Wang, X.; Liu, H. Airport detection based on a multiscale fusion feature for optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1469–1473. [Google Scholar] [CrossRef]
- Zhang, P.; Niu, X.; Dou, Y.; Xia, F. Airport detection on optical satellite images using deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1183–1187. [Google Scholar] [CrossRef]
- Abdel-Aziz, Y.I.; Karara, H.M.; Hauck, M. Direct linear transformation from comparator coordinates into object space coordinates in close-range photogrammetry. Photogramm. Eng. Remote Sens. 2015, 81, 103–107. [Google Scholar] [CrossRef]
- Hesch, J.A.; Roumeliotis, S.I. A direct least-squares (DLS) method for PnP. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Kneip, L.; Li, H.; Seo, Y. Upnp: An optimal o (n) solution to the absolute pose problem with universal applicability. In Proceedings of the 2014 European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Zheng, Y.; Kuang, Y.; Sugimoto, S.; Astrom, K.; Okutomi, M. Revisiting the pnp problem: A fast, general and optimal solution. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013. [Google Scholar]




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| UAV | Length | Wingspan | Height | Max Takeoff Weight | Cruising Speed | Range | Endurance |
|---|---|---|---|---|---|---|---|
| MQ-9 | 11 m | 20 m | 3.81 m | 4760 kg | 313 km/h | 1852 km | 14 h |
| Airport | ICAO | Latitude | Longitude | Elevation | Runway Length |
|---|---|---|---|---|---|
| Livermore Municipal Airport | KLVK | 37.693 | −121.821 | 400 ft | 5248 ft |
| George Bush Intercontinental Airport | IAH | 29.983 | −95.342 | 97 ft | 11,995 ft |
| San Francisco International Airport | KSFO | 37.619 | −122.375 | 13 ft | 11,867 ft |
| Test Data | Feature Extraction Model | AP Value |
|---|---|---|
| Airport | VGG19 | 79.23% |
| Airport | ResNet101 | 82.52% |
| Airport | Inception V4 | 80.95% |
| Anchor | Feature Extraction Model | AP Value |
|---|---|---|
| Default | ResNet101 | 82.52% |
| Improved | ResNet101 | 84.37% |
| Feature-Point Number | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|
| Mean rotational reprojection error/ | 15.731 | 6.879 | 5.106 | 3.354 | 0.675 | 0.702 | 0.693 |
| Mean translational reprojection error/% | 13.905 | 11.127 | 4.914 | 2.632 | 0.581 | 0.587 | 0.546 |
| Mean computational time | 1.597 | 3.964 | 4.156 | 6.097 | 9.572 | 10.484 | 15.803 |
| Method | EN | MI | |
|---|---|---|---|
| CBF | 4.519 | 2.166 | 0.415 |
| HMSDGF | 4.229 | 1.857 | 0.437 |
| IFEVIP | 3.908 | 2.576 | 0.280 |
| MSTNO | 4.721 | 2.889 | 0.355 |
| MGFF | 4.213 | 2.628 | 0.408 |
| Our method | 4.823 | 3.033 | 0.467 |
| Method | AP Value |
|---|---|
| Improved Faster R-CNN | 84.37% |
| DCNN | 80.81% |
| DSF | 82.19% |
| Method | Rotational Reprojection Error/ | Translational Reprojection Error/% |
|---|---|---|
| DLT | 2.594 | 2.386 |
| DLS | 1.164 | 0.953 |
| UPnP | 0.776 | 0.627 |
| OPnP | 0.693 | 0.603 |
| Our method | 0.675 | 0.581 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Zhao, D.; Cao, Y. Visual Navigation Algorithm for Night Landing of Fixed-Wing Unmanned Aerial Vehicle. Aerospace 2022, 9, 615. https://doi.org/10.3390/aerospace9100615
Wang Z, Zhao D, Cao Y. Visual Navigation Algorithm for Night Landing of Fixed-Wing Unmanned Aerial Vehicle. Aerospace. 2022; 9(10):615. https://doi.org/10.3390/aerospace9100615
Chicago/Turabian StyleWang, Zhaoyang, Dan Zhao, and Yunfeng Cao. 2022. "Visual Navigation Algorithm for Night Landing of Fixed-Wing Unmanned Aerial Vehicle" Aerospace 9, no. 10: 615. https://doi.org/10.3390/aerospace9100615