
A Machine Learning and Feature Engineering Approach for the Prediction of the Uncontrolled Re-Entry of Space Objects


Abstract
:1. Introduction
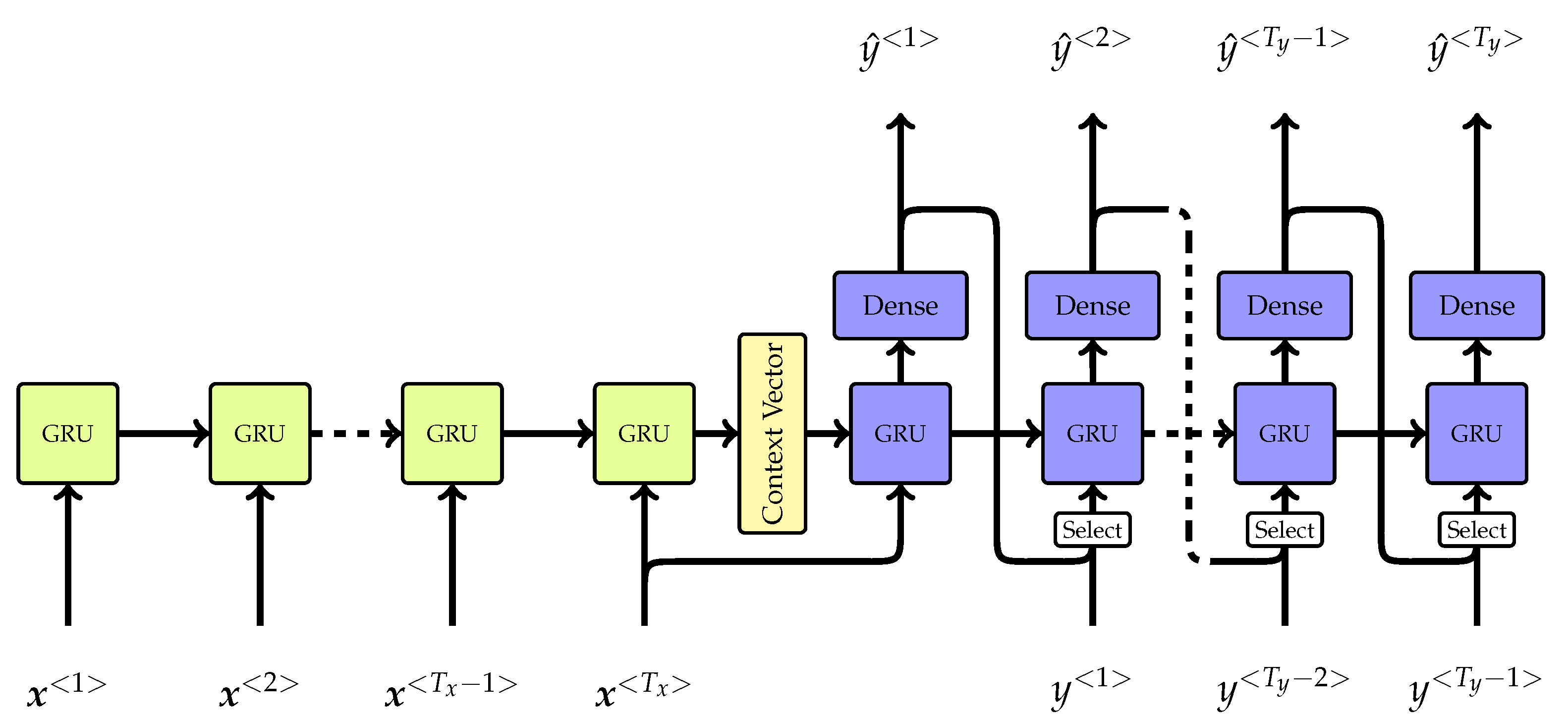
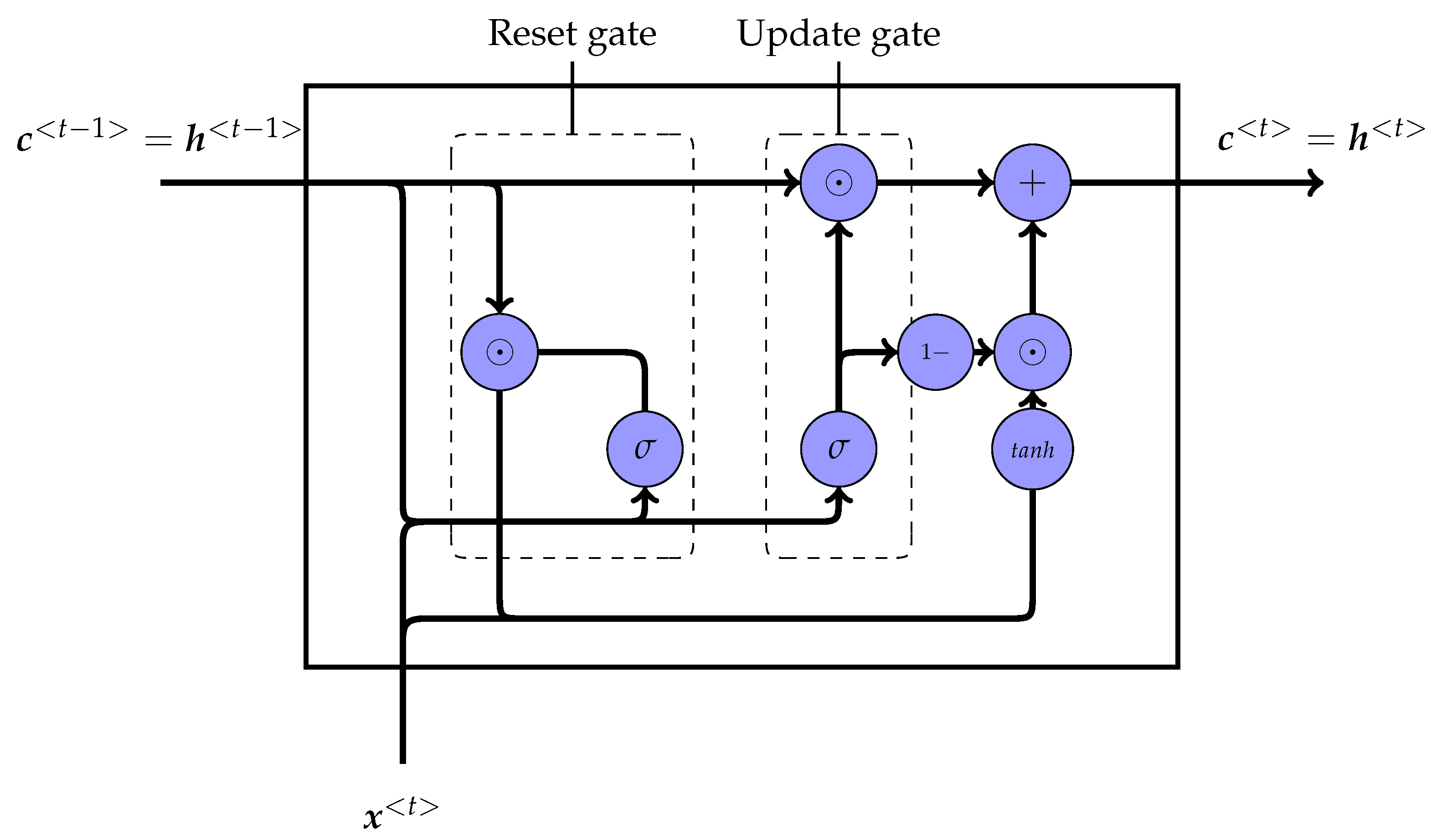
2. Deep Learning Model
Sequence-to-Sequence Architecture
Gate Recurrent Unit
3. Data Pre-Processing
- Identify the presence of TLE corrections by defining a time threshold such that the previous observation is considered incorrect. A common time threshold is half an orbit;
- Identify large time intervals between consecutive TLEs, and, consequently, divide the entire set into different windows in order to ensure TLEs consistency;
- Find and filter out single TLEs with discordant values of the mean motion, based on a robust linear regression technique and on a sliding window of fixed length. In particular, the result obtained through regression is compared with the OMM following the sliding window and an outlier is identified if a relative and an absolute tolerance are exceeded (optimal tuning parameters for the filter can be found in Table 3 of [13]);
- Identify and filter out possible outliers in eccentricity and inclination, using a statistical approach. Particularly, the mean is computed within a sliding window, and it is subtracted from the central orbital element of the interval, obtaining a time series of differences. Afterwards, using another sliding window that scans the aforementioned series of differences, the mean absolute deviation is computed. An outlier is removed if the orbital element presents a difference from the mean that is higher than a given threshold ((optimal tuning parameters for the filter can be found in Tables 4 and 5 of [13]);
- Filter out TLEs that present negative values of because they can be associated with unmodelled dynamics or manoeuvres.
- Maximum re-entry uncertainty: 20 min;
- Maximum average altitude of the initial TLE: 200 km;
- Minimum average altitude of the final TLE: 180 km;
- Maximum eccentricity: 0.1;
- Minimum number of points: 4 TLE.
4. Features Engineering
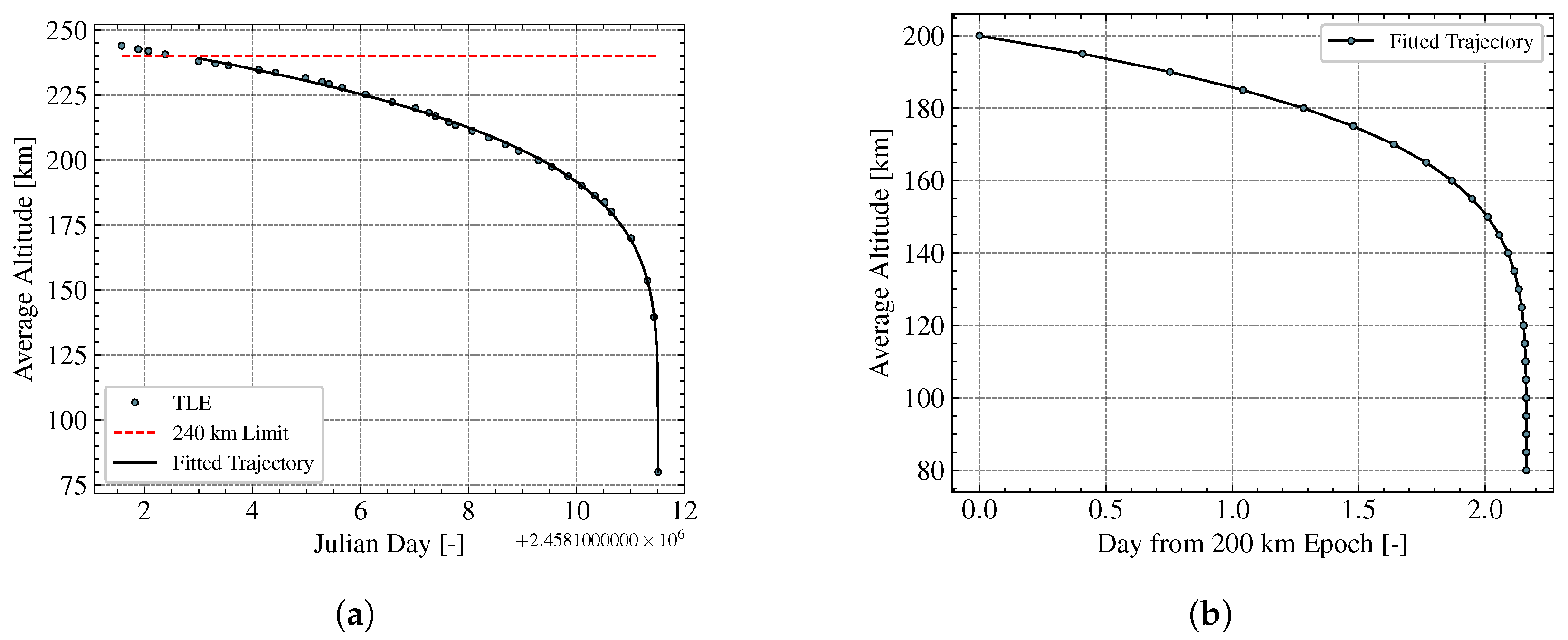
4.1. Average Altitude
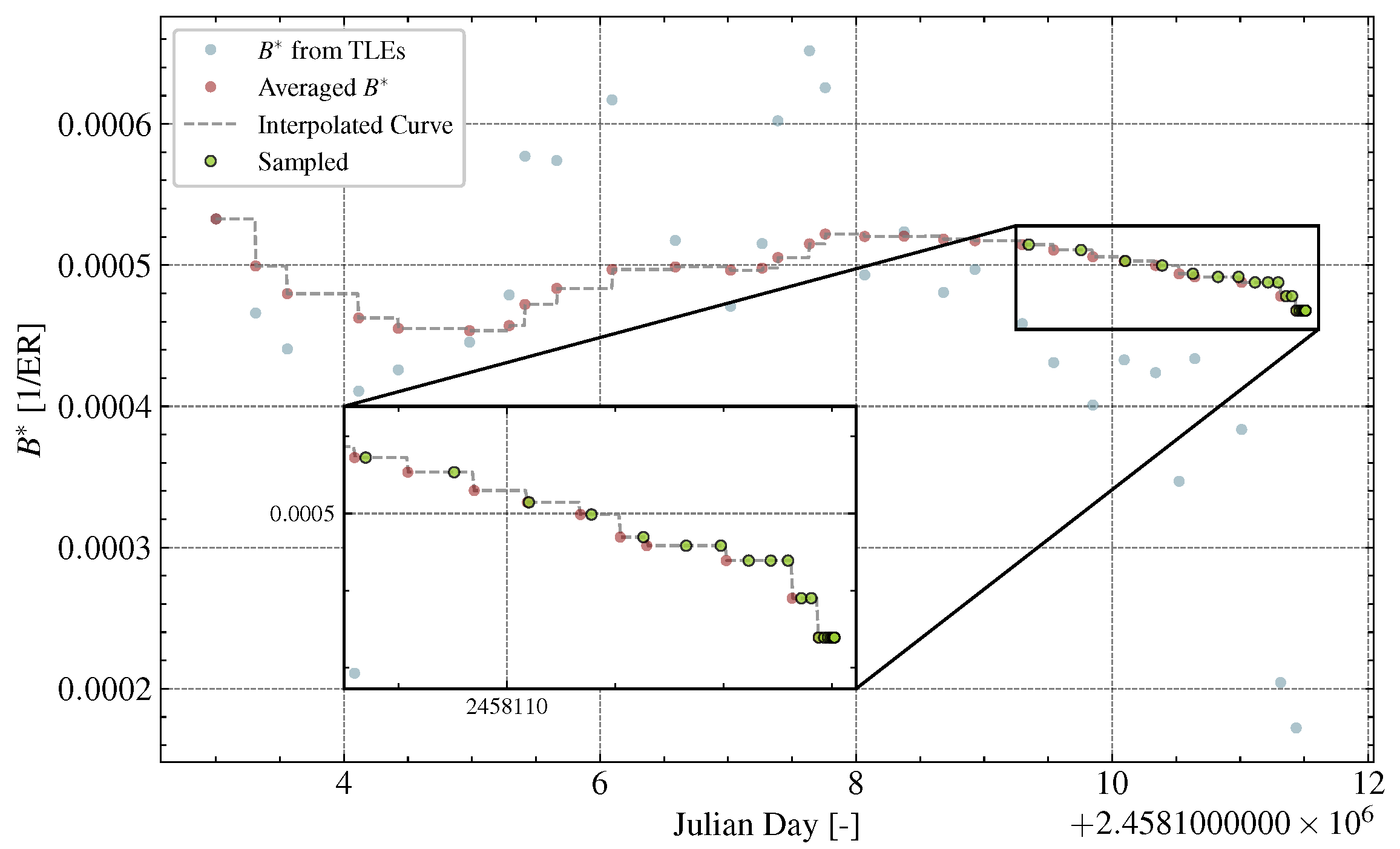
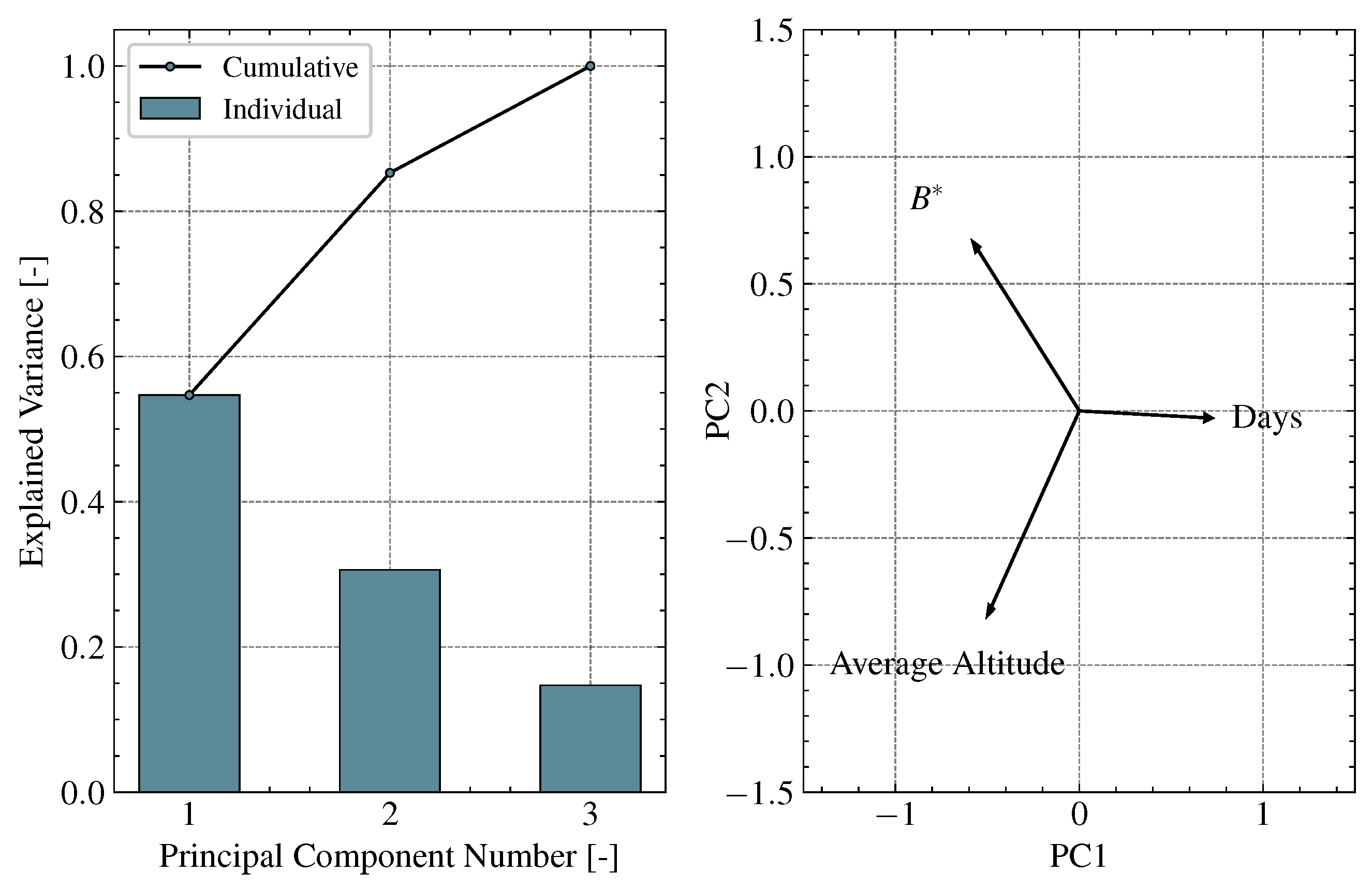
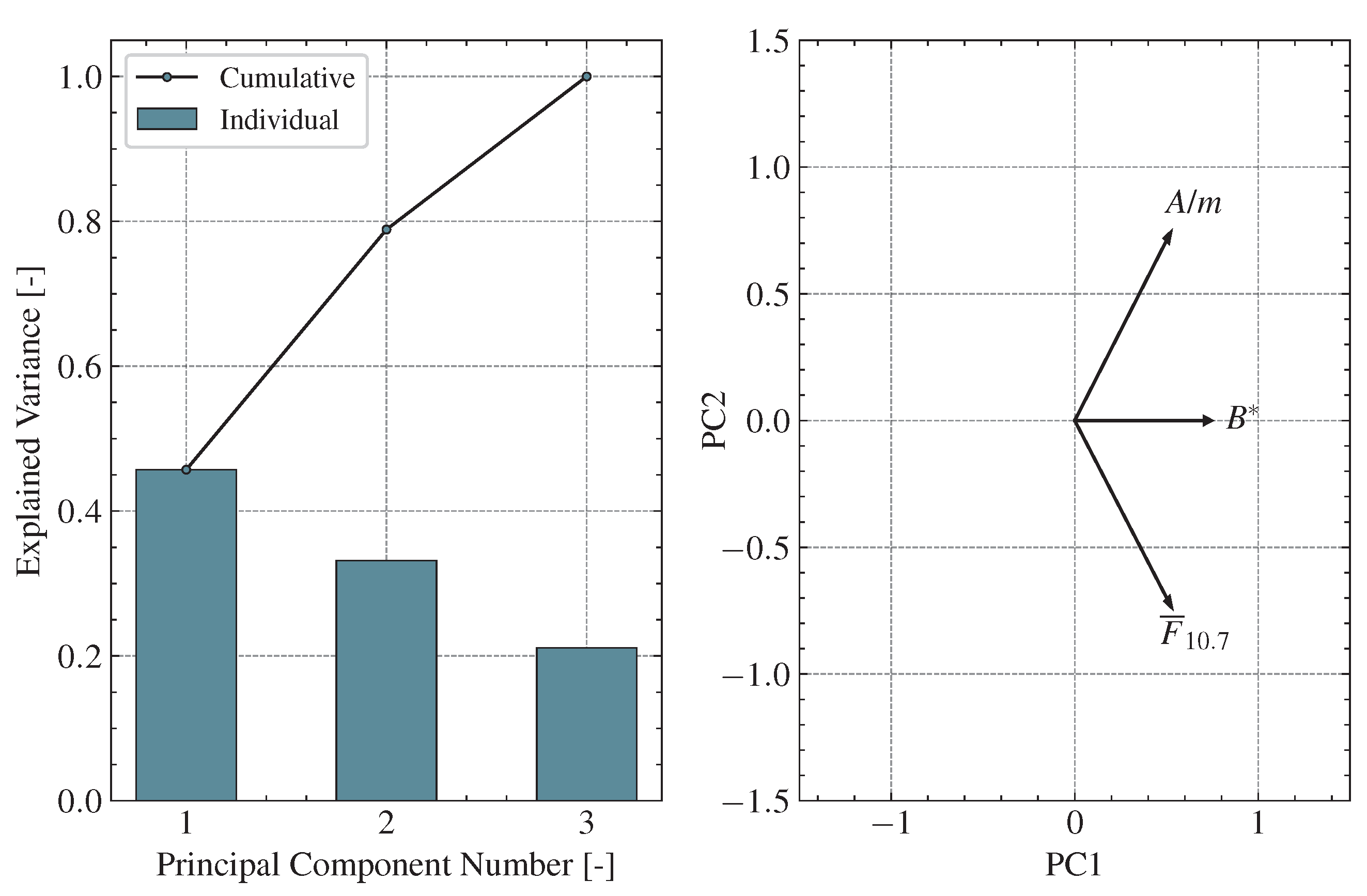
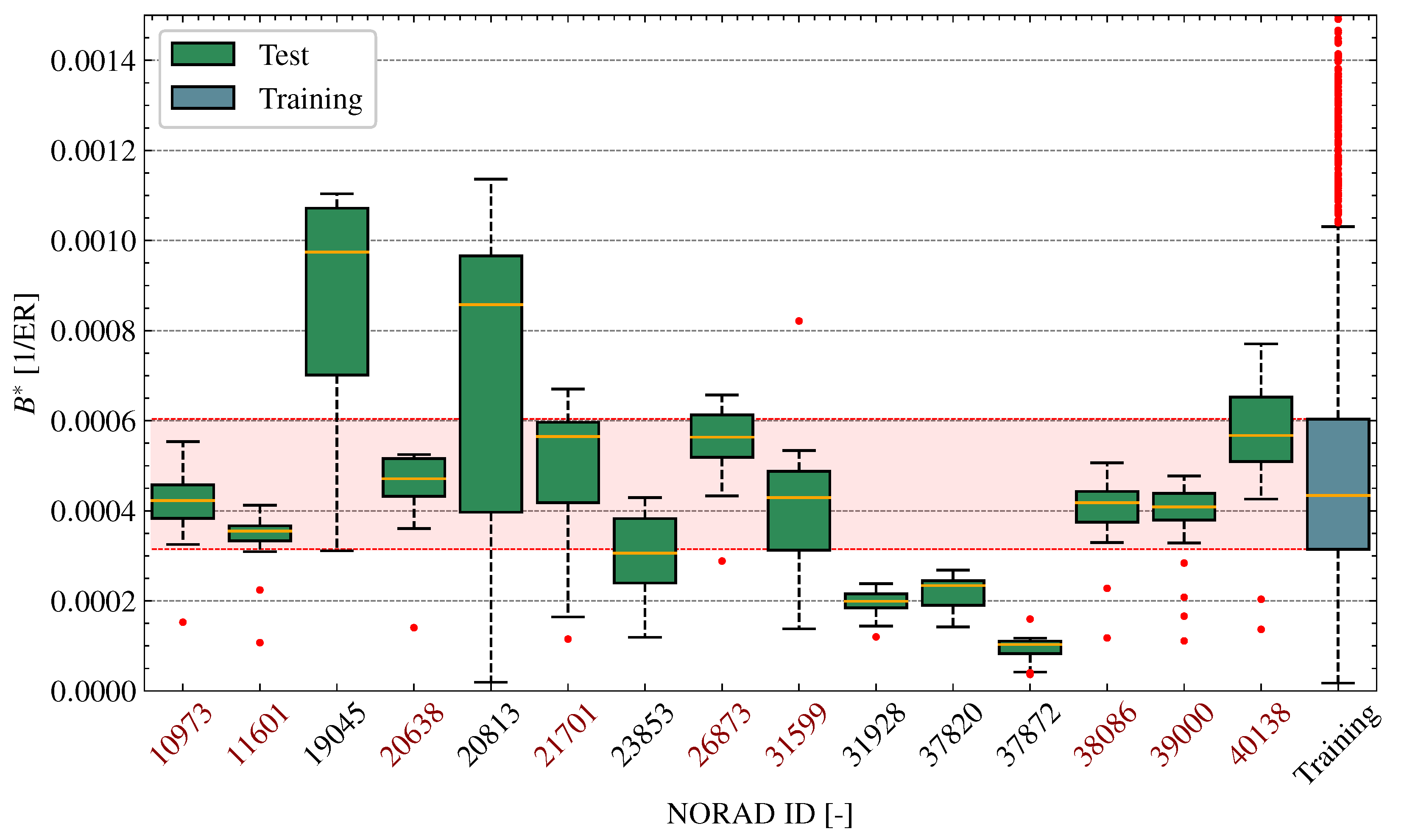
4.2. Ballistic Coefficient and B*
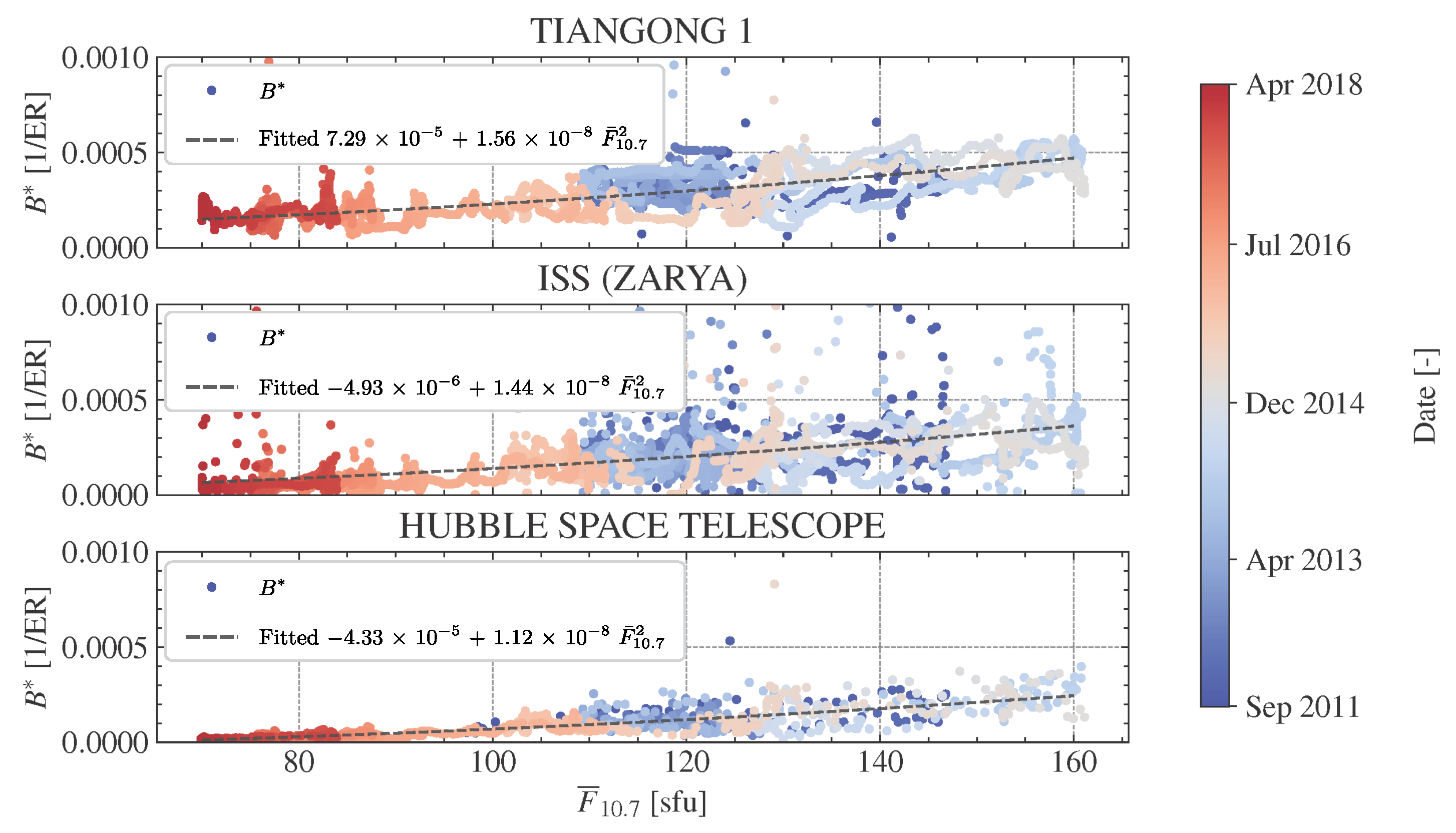
4.3. Solar Index
4.4. Data Regularisation
5. Results
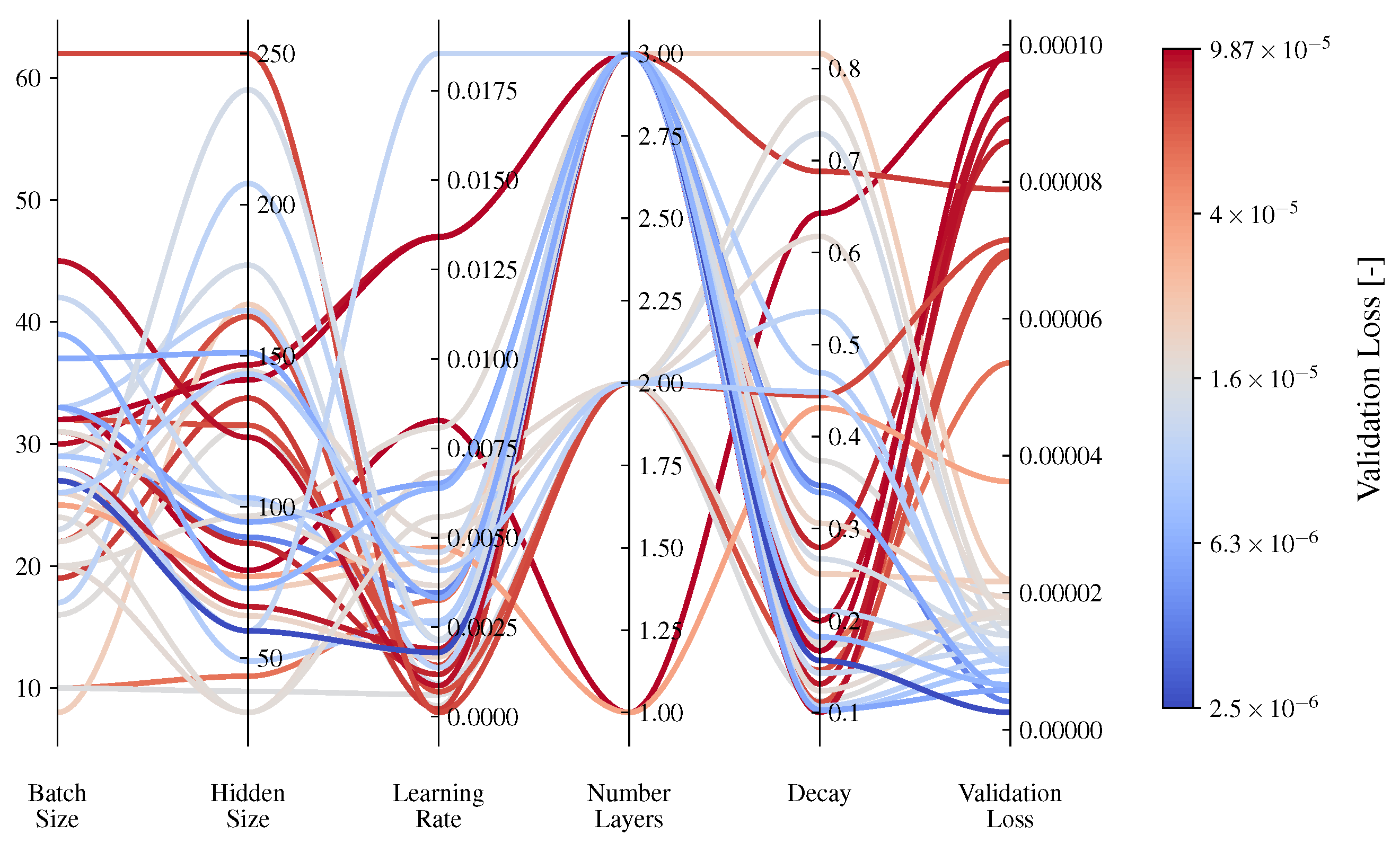
5.1. Hyperparameters Optimisation
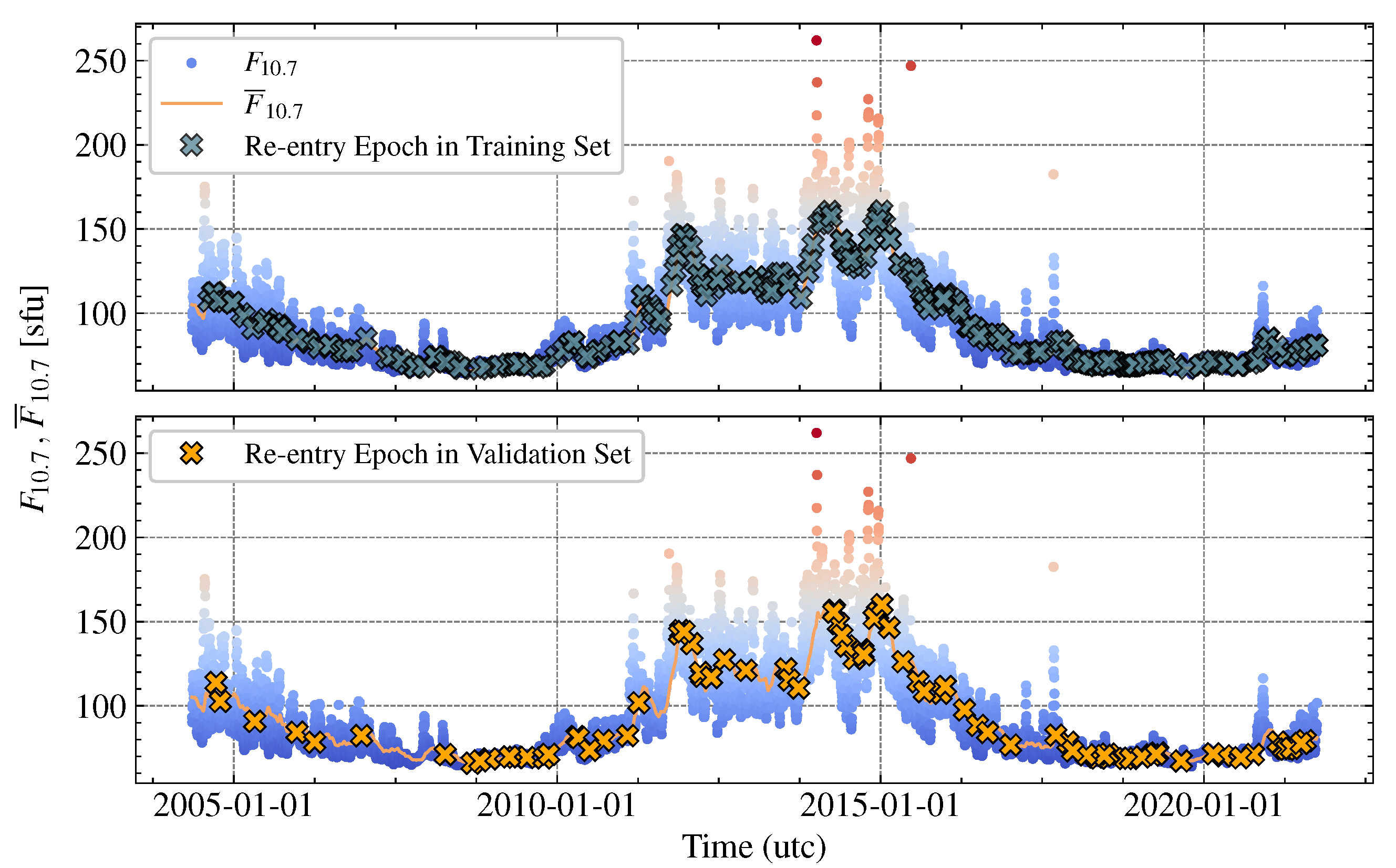
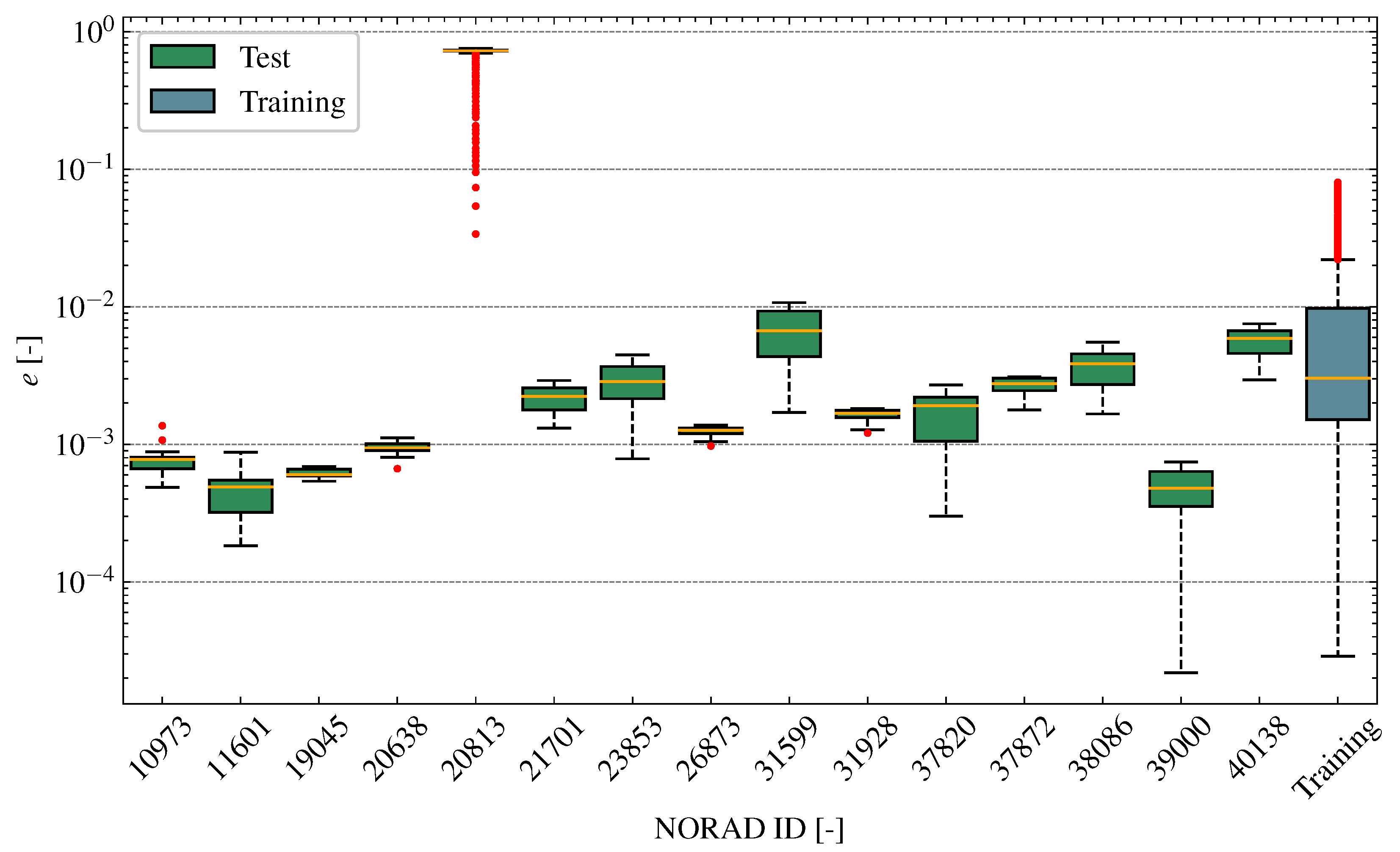
5.2. Dataset Characterisation
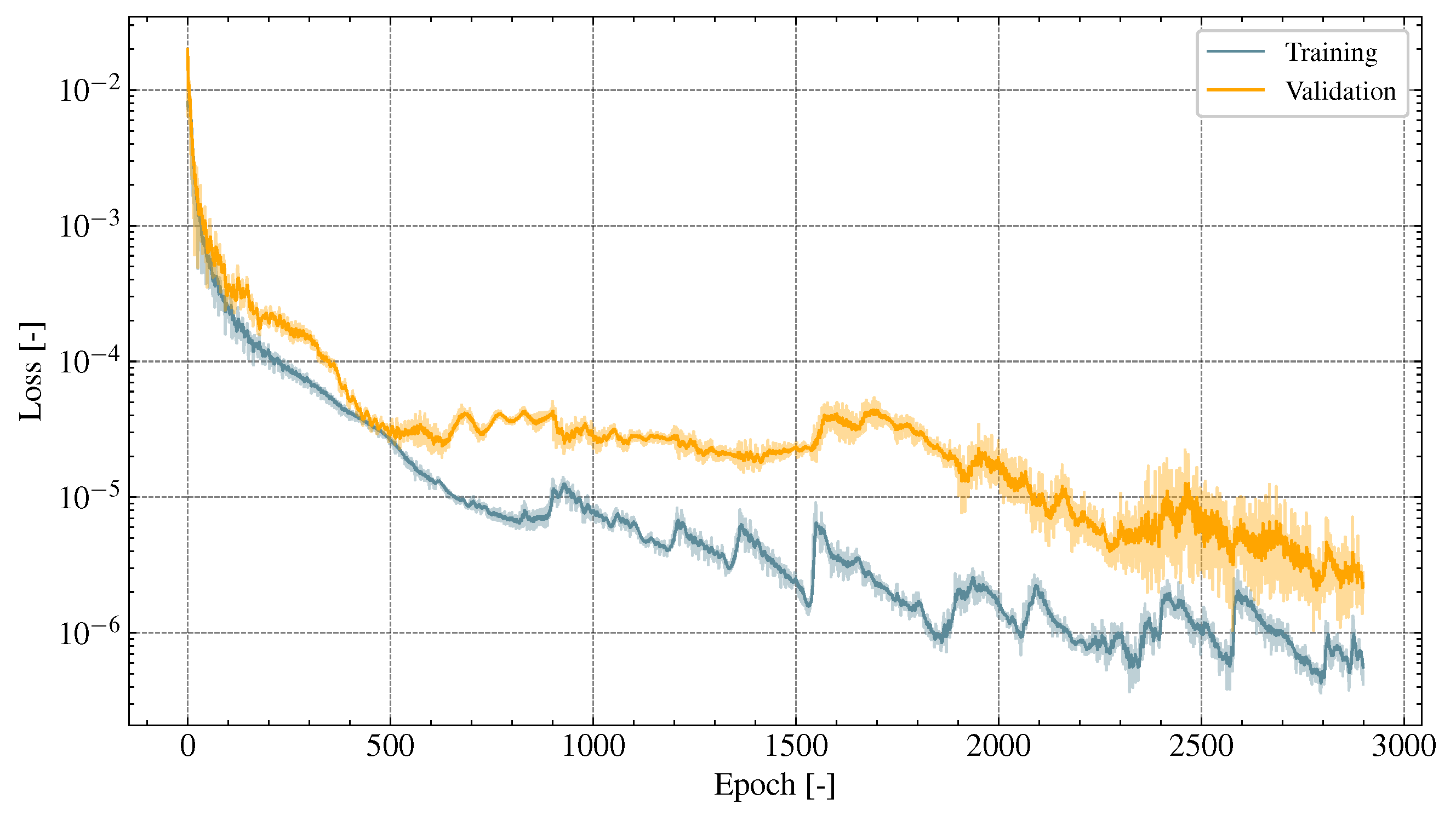
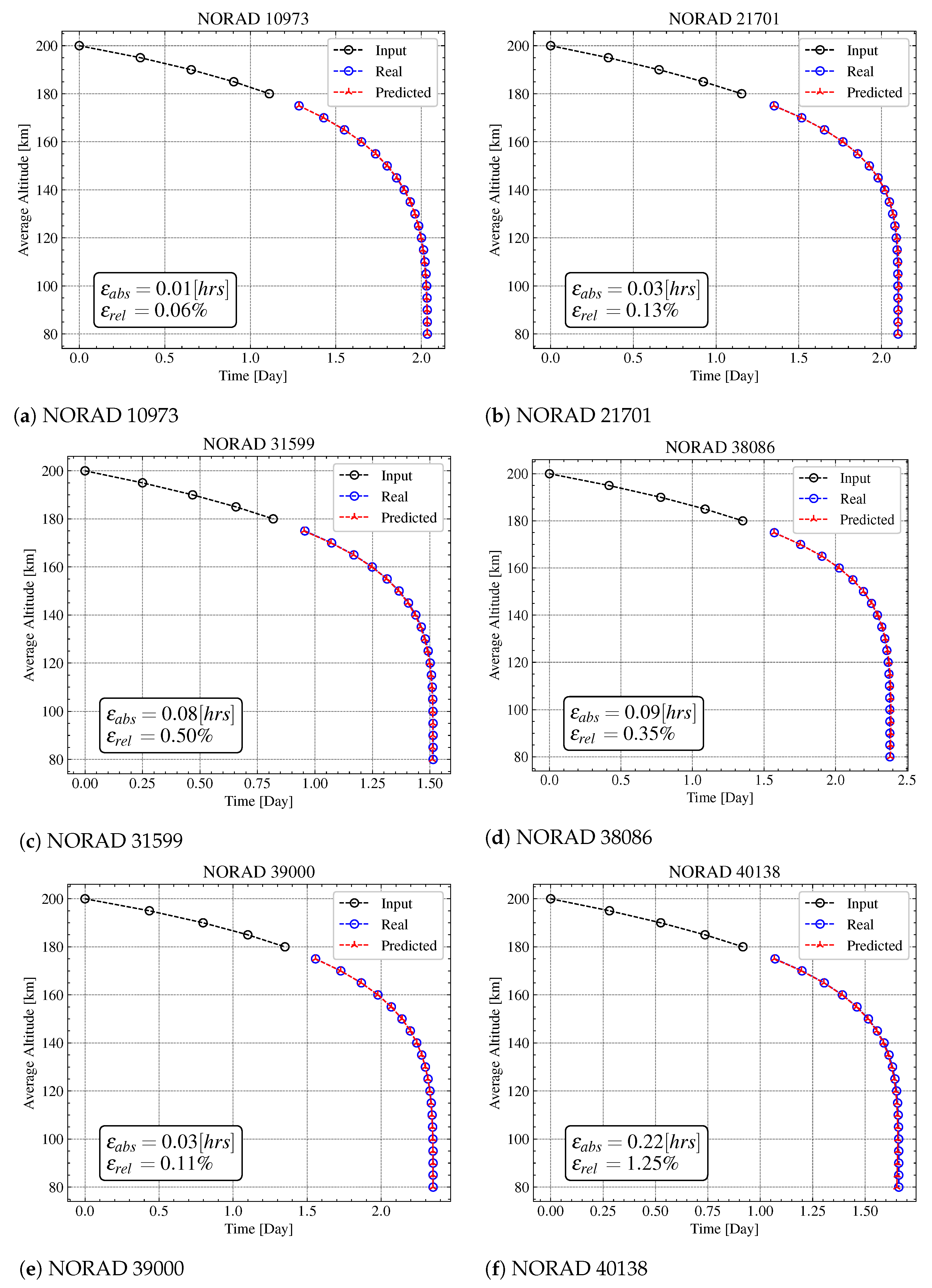
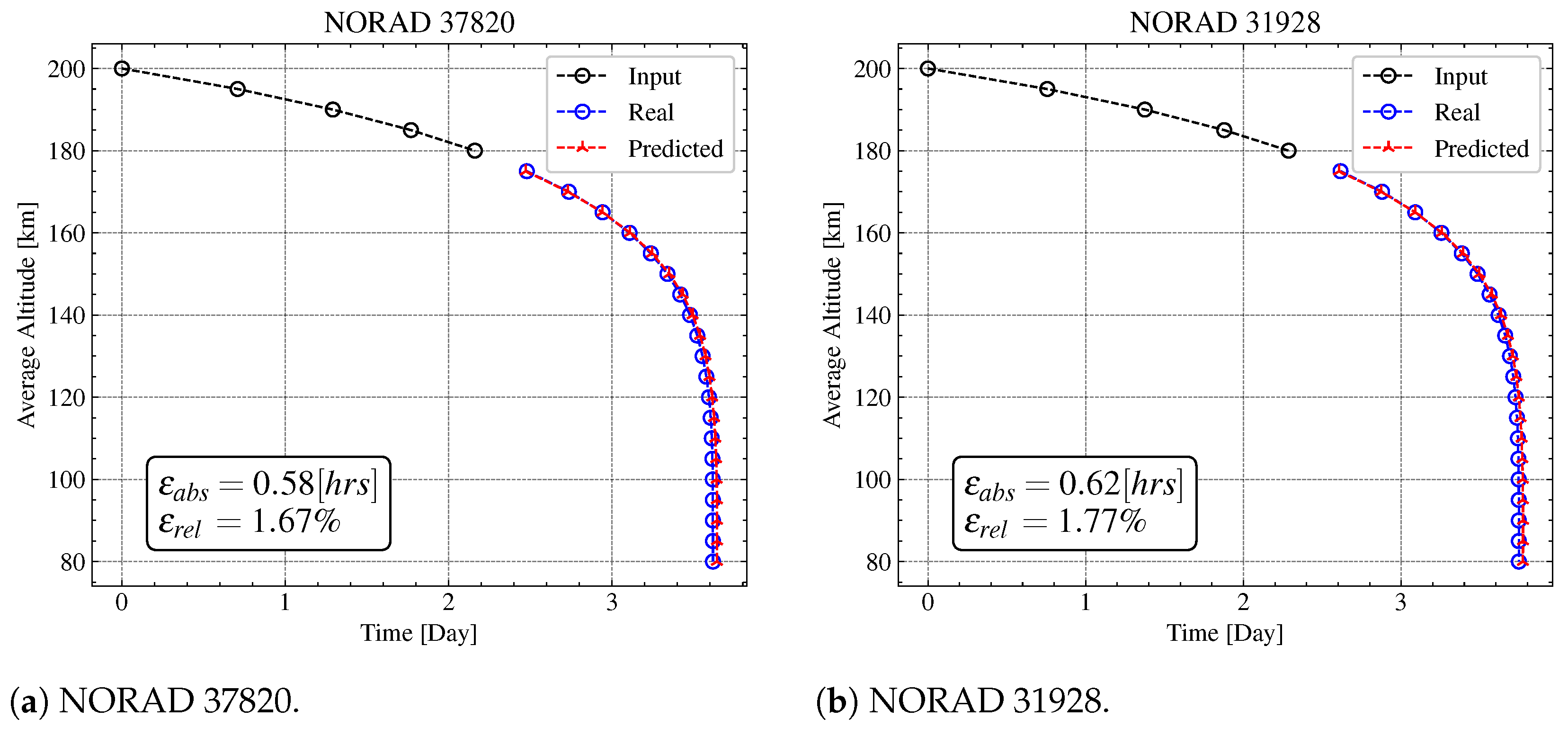
5.3. Testing
Orbit Prediction—Case A
6. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| TLE | Two Line Element |
| TIP | Tracking and Impact Prediction |
| PCA | Principal Component Analysis |
| Seq2Seq | Sequence to Sequence |
| TPE | Tree-structured Parzen Estimator |
| ASHA | Asynchronous Successive Halving Algorithm |
| ANN | Artificial Neural Network |
| RNN | Recurrent Neural Network |
| GRU | Gated Recurrent Unit |
| MSE | Mean Squared Error |
| OMM | Orbital Mean-Elements Message |
Appendix A
Appendix A.1. Norad IDs of Training Set
Appendix A.2. Norad IDs of Validation Set
Appendix A.3. Norad IDs of Test Set
Test Set Subdivision in Category 1 and Category 2

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | NORAD IDs | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 10973 | 11601 | 20638 | 21701 | 26873 | 31599 | 38086 | 39000 | 40138 |
| 2 | 19045 | 20813 | 23853 | 31928 | 37820 | 37872 | |||
References
- ESA Space Debris Office. ESA’S Annual Space Environent Report; ESA Space Debris Office: Darmstadt, Germany, 2021. [Google Scholar]
- Alby, F.; Alwes, D.; Anselmo, L.; Baccini, H.; Bonnal, C.; Crowther, R.; Flury, W.; Jehn, R.; Klinkrad, H.; Portelli, C.; et al. The European Space Debris Safety and Mitigation Standard. Adv. Space Res. 2004, 34, 1260–1263. [Google Scholar] [CrossRef]
- NASA. Process for Limiting Orbital Debris, NASA-STD-8719.14B; NASA: Washington, DC, USA, 2019.
- Pardini, C.; Anselmo, L. Re-entry predictions for uncontrolled satellites: Results and challenges. In Proceedings of the 6th IAASS Conference “Safety Is Not an Option”, Montreal, QC, Canada, 21–23 May 2013. [Google Scholar]
- Pardini, C.; Anselmo, L. Performance evaluation of atmospheric density models for satellite reentry predictions with high solar activity levels. Trans. Jpn. Soc. Aeronaut. Space Sci. 2003, 46, 42–46. [Google Scholar] [CrossRef] [Green Version]
- Pardini, C.; Anselmo, L. Assessing the risk and the uncertainty affecting the uncontrolled re-entry of manmade space objects. J. Space Saf. Eng. 2018, 5, 46–62. [Google Scholar] [CrossRef]
- Braun, V.; Flegel, S.; Gelhaus, J.; Kebschull, C.; Moeckel, M.; Wiedemann, C.; Sánchez-Ortiz, N.; Krag, H.; Vörsmann, P. Impact of Solar Flux Modeling on Satellite Lifetime Predictions. In Proceedings of the 63rd International Astronautical Congress, Naples, Italy, 1–5 October2012. [Google Scholar]
- Vallado, D.A.; Finkleman, D. A critical assessment of satellite drag and atmospheric density modeling. Acta Astronaut. 2014, 95, 141–165. [Google Scholar] [CrossRef]
- Vallado, D. Fundamentals of Astrodynamics and Applications, 2nd ed.; Springer: Dordrecht, The Netherlands, 2001. [Google Scholar]
- Anselmo, L.; Pardini, C. Computational methods for reentry trajectories and risk assessment. Adv. Space Res. 2005, 35, 1343–1352. [Google Scholar] [CrossRef]
- Frey, S.; Colombo, C.; Lemmens, S. Extension of the King-Hele orbit contraction method for accurate, semi-analytical propagation of non-circular orbits. Adv. Space Res. 2019, 64, 1–17. [Google Scholar] [CrossRef]
- Jung, O.; Seong, J.; Jung, Y.; Bang, H. Recurrent neural network model to predict re-entry trajectories of uncontrolled space objects. Adv. Space Res. 2021, 68, 2515–2529. [Google Scholar] [CrossRef]
- Lidtke, A.A.; Gondelach, D.J.; Armellin, R. Optimising filtering of two-line element sets to increase re-entry prediction accuracy for GTO objects. Adv. Space Res. 2019, 63, 1289–1317. [Google Scholar] [CrossRef]
- Flohrer, T.; Krag, H.; Klinkrad, H. Assessment and categorization of TLE orbit errors for the US SSN catalogue. In Proceedings of the Advanced Maui Optical and Space Surveillance Technologies (AMOS) Conference, Maui, HI, USA, 17–19 September 2008. [Google Scholar]
- Levit, C.; Marshall, W. Improved orbit predictions using two-line elements. Adv. Space Res. 2011, 47, 1107–1115. [Google Scholar] [CrossRef] [Green Version]
- Aida, S.; Kirschner, M. Accuracy assessment of SGP4 orbit information conversion into osculating elements. In Proceedings of the 6th European Conference on Space Debris, Darmstadt, Germany, 22–25 April 2013. [Google Scholar]
- Raschka, S. Python Machine Learning, 3rd ed.; Packt Publishing Ltd.: Birmingham, UK, 2019. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 8–13 December 2014; MIT Press: Cambridge, MA, USA, 2014; Volume 2, pp. 3104–3112. [Google Scholar]
- Zhang, A.; Lipton, Z.C.; Li, M.; Smola, A.J. Dive into Deep Learning. arXiv 2021, arXiv:2106.11342. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, UK, 2016. [Google Scholar]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1724–1734. [Google Scholar] [CrossRef]
- Bengio, S.; Vinyals, O.; Jaitly, N.; Shazeer, N. Scheduled sampling for sequence prediction with recurrent neural networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1171–1179. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems (Software). 2015. Available online: https://www.tensorflow.org (accessed on 10 January 2022).
- Chollet, F. Deep Learning with Python; Simon and Schuster: New York, NY, USA, 2021. [Google Scholar]
- Salmaso, F. Machine Learning Model for Uncontrolled Re-Entry Predictions of Space Objects and Feature Engineering. Ph.D. Thesis, Politecnico di Milano, Milan, Italy, 2022. [Google Scholar]
- Dong, G.; Liu, H. Feature Engineering for Machine Learning and Data Analytics; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Curtis, H.D. Orbital Mechanics for Engineering Students, 3rd ed.; Butterworth-Heinemann: Oxford, UK, 2014. [Google Scholar]
- Bergstra, J.; Yamins, D.; Cox, D. Making a Science of Model Search: Hyperparameter Optimization in Hundreds of Dimensions for Vision Architectures. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Volume 28, pp. 115–123. [Google Scholar]
- Li, L.; Jamieson, K.; Rostamizadeh, A.; Gonina, E.; Hardt, M.; Recht, B.; Talwalkar, A. A System for Massively Parallel Hyperparameter Tuning. arXiv 2020, arXiv:1810.05934. [Google Scholar]
- Liaw, R.; Liang, E.; Nishihara, R.; Moritz, P.; Gonzalez, J.E.; Stoica, I. Tune: A research platform for distributed model selection and training. arXiv 2018, arXiv:1807.05118. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]

















| Variable | Training Set | Validation Set | |
|---|---|---|---|
| Ecentricity [-] | |||
| [1/ER] | |||
| NORAD | Name | Re-Entry Epoch [UTC] |
|---|---|---|
| 23853 | COSMOS 2332 | 2005-01-28T18:05 * |
| 26873 | CORONAS F | 2005-12-06T17:24 |
| 10973 | COSMOS 1025 | 2007-03-10T12:56 |
| 31599 | DELTA 2 R/B | 2007-08-16T09:23 |
| 31928 | EAS | 2008-11-03T04:51 |
| 20813 | MOLNIYA 3-39 | 2009-07-08T22:42 |
| 11601 | SL-3 R/B | 2010-04-30T16:44 |
| 21701 | UARS | 2011-09-24T04:00 |
| 20638 | ROSAT | 2011-10-23T01:50 |
| 37872 | PHOBOS-GRUNT | 2012-01-15T17:46 |
| 19045 | COSMOS 1939 | 2014-10-29T15:32 * |
| 40138 | CZ-2D R/B | 2015-06-13T23:58 |
| 39000 | CZ-2C R/B | 2016-06-27T19:04 |
| 38086 | AVUM | 2016-11-02T04:43 |
| 37820 | TIANGONG 1 | 2018-04-02T00:16 |
| Case | [-] | Starting Altitude [km] | Training Epochs [-] |
|---|---|---|---|
| A | 5 | 180 | 2900 |
| B | 9 | 160 | 3000 |
| C | 13 | 140 | 1200 |
| D | 17 | 120 | 1200 |
| Parameter | Value [-] | |
|---|---|---|
| Fixed | Loss | Mean Squared Error |
| Optimiser | Adam | |
| 0.999 | ||
| 0.999 | ||
| Clipnorm | 0.1 |
| Hyperparameter | Interval [min, max] | Sampling Mode |
|---|---|---|
| Learning Rate | [, ] | Uniform Logarithmic |
| Number of layers | [1, 3] | QUniform |
| Hidden size GRU | [16, 256] | QUniform |
| Batch Size | [8, 64] | QUniform |
| Decay Scheduled Sampling | [, ] | Uniform Logarithmic |
| Input | Value |
|---|---|
| Number of Trials | 100 [-] |
| Reduction Factor | 4 [-] |
| Grace Period | 400 [Epochs] |
| Maximum Training Epoch | 2100 [Epochs] |
| Parameter | Value [-] | |
|---|---|---|
| Optimised | Learning Rate | 0.001795 |
| Number of Layers | 3 | |
| Hidden Size GRU | 59 | |
| Batch Size | 27 | |
| Decay Scheduled Sampling | 0.15665 |
| Case | Metric | NORAD | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 10973 | 11601 | 20638 | 21701 | 26873 | 31599 | 38086 | 39000 | 40138 | ||
| Case A | [hrs] | 0.0129 | 0.0012 | 0.0593 | 0.0287 | 0.0381 | 0.0835 | 0.0856 | 0.0263 | 0.2225 |
| [%] | 0.0582 | 0.0051 | 0.2930 | 0.1262 | 0.1800 | 0.5004 | 0.3469 | 0.1093 | 1.2464 | |
| MSE [] | 4.4482 | 1.1707 | 1.0218 | 1.0236 | 1.7067 | 5.2804 | 2.1809 | 1.0643 | 1.9246 | |
| Case B | [hrs] | 0.0915 | 0.0411 | 0.0417 | 0.0021 | 0.0376 | 0.0640 | 0.0187 | 0.0191 | 0.0191 |
| [%] | 0.9903 | 0.4878 | 0.6032 | 0.0265 | 0.4828 | 1.0072 | 0.2198 | 0.2134 | 0.2952 | |
| MSE [] | 7.0168 | 1.8629 | 2.6473 | 4.4563 | 2.6635 | 1.2836 | 1.1987 | 1.7427 | 1.8259 | |
| Case C | [hrs] | 0.0934 | 0.0043 | 0.0125 | 0.0268 | 0.0610 | 0.1025 | 0.0368 | 0.0065 | 0.0198 |
| [%] | 2.8694 | 0.1839 | 0.7061 | 1.3862 | 2.8083 | 5.6717 | 1.7670 | 0.2461 | 1.1732 | |
| MSE [] | 1.8350 | 2.1482 | 9.5146 | 4.1151 | 1.5597 | 5.9912 | 4.7233 | 1.5328 | 6.7500 | |
| Case D | [hrs] | 0.0670 | 0.0560 | 0.0244 | 0.0340 | 0.0581 | 0.0271 | 0.0580 | 0.0420 | 0.0093 |
| [%] | 8.1350 | 14.1151 | 9.1041 | 13.5330 | 15.8149 | 8.8874 | 20.3210 | 8.3022 | 3.7092 | |
| MSE [] | 6.4009 | 3.1455 | 1.3601 | 1.3073 | 2.2189 | 1.0388 | 2.2950 | 2.1382 | 1.5021 | |
| Case | Metric | NORAD | |||||
|---|---|---|---|---|---|---|---|
| 19045 | 20813 | 23853 | 31928 | 37820 | 37872 | ||
| Case A | [hrs] | 0.2994 | 1.2758 | 0.3083 | 0.6206 | 0.5829 | 1.3427 |
| [%] | 2.5476 | 964.0562 | 0.8570 | 1.7715 | 1.6664 | 1.6942 | |
| MSE [] | 6.1088 | 1.1331 | 9.9711 | 3.6330 | 3.2982 | 1.0313 | |
| Case B | [hrs] | 0.0355 | 0.7159 | 0.0273 | 0.0854 | 0.0894 | 2.5015 |
| [%] | 0.8068 | 1309.4202 | 0.2152 | 0.7246 | 0.7297 | 9.3210 | |
| MSE [] | 1.7582 | 2.6453 | 3.2465 | 7.4105 | 5.7928 | 1.2797 | |
| Case C | [hrs] | 0.0029 | 0.2194 | 0.0033 | 0.0080 | 0.0222 | 1.9536 |
| [%] | 0.2301 | 2254.3293 | 0.1022 | 0.2579 | 0.6580 | 31.1668 | |
| MSE [] | 1.1096 | 6.2342 | 6.7083 | 1.6303 | 1.5640 | 1.1795 | |
| Case D | [hrs] | 0.0805 | 0.0098 | 0.1186 | 0.0847 | 0.0788 | 2.9645 |
| [%] | 35.9520 | 2532.4688 | 26.520 | 16.8331 | 13.4101 | 373.4046 | |
| MSE [] | 9.3967 | 2.5700 | 2.4415 | 2.3780 | 1.9272 | 1.5264 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salmaso, F.; Trisolini, M.; Colombo, C. A Machine Learning and Feature Engineering Approach for the Prediction of the Uncontrolled Re-Entry of Space Objects. Aerospace 2023, 10, 297. https://doi.org/10.3390/aerospace10030297
Salmaso F, Trisolini M, Colombo C. A Machine Learning and Feature Engineering Approach for the Prediction of the Uncontrolled Re-Entry of Space Objects. Aerospace. 2023; 10(3):297. https://doi.org/10.3390/aerospace10030297
Chicago/Turabian StyleSalmaso, Francesco, Mirko Trisolini, and Camilla Colombo. 2023. "A Machine Learning and Feature Engineering Approach for the Prediction of the Uncontrolled Re-Entry of Space Objects" Aerospace 10, no. 3: 297. https://doi.org/10.3390/aerospace10030297