
Onboard Processing in Satellite Communications Using AI Accelerators

 ,
,  ,
,  , , , ,
, , , ,  , and
, and
Abstract
:1. Introduction
- A large and representative training set (labeling) is required to achieve acceptable performance.
- Particular use cases were considered, and typically limited ML techniques were examined.
- Insufficient evaluation and comparison with non-ML designs (note that the evaluation phase was < 4 months).
- The critical requirements for onboard AI/ML processing include power consumption, latency, and accuracy.
- Usage scenarios for onboard AI/ML processing are identified and discussed, including applications in communication satellites.
- Three scores for comparing the applicability of onboard AI/ML processing are defined, including the onboard applicability, the AI gain, and the complexity. These scores provide a quantitative measure of the suitability of various scenarios where AI chipsets can be used for onboard AI/ML processing.
- The authors present a comprehensive review of commercial AI chipsets and compare their specifications concerning the applicability of onboard AI/ML processing.
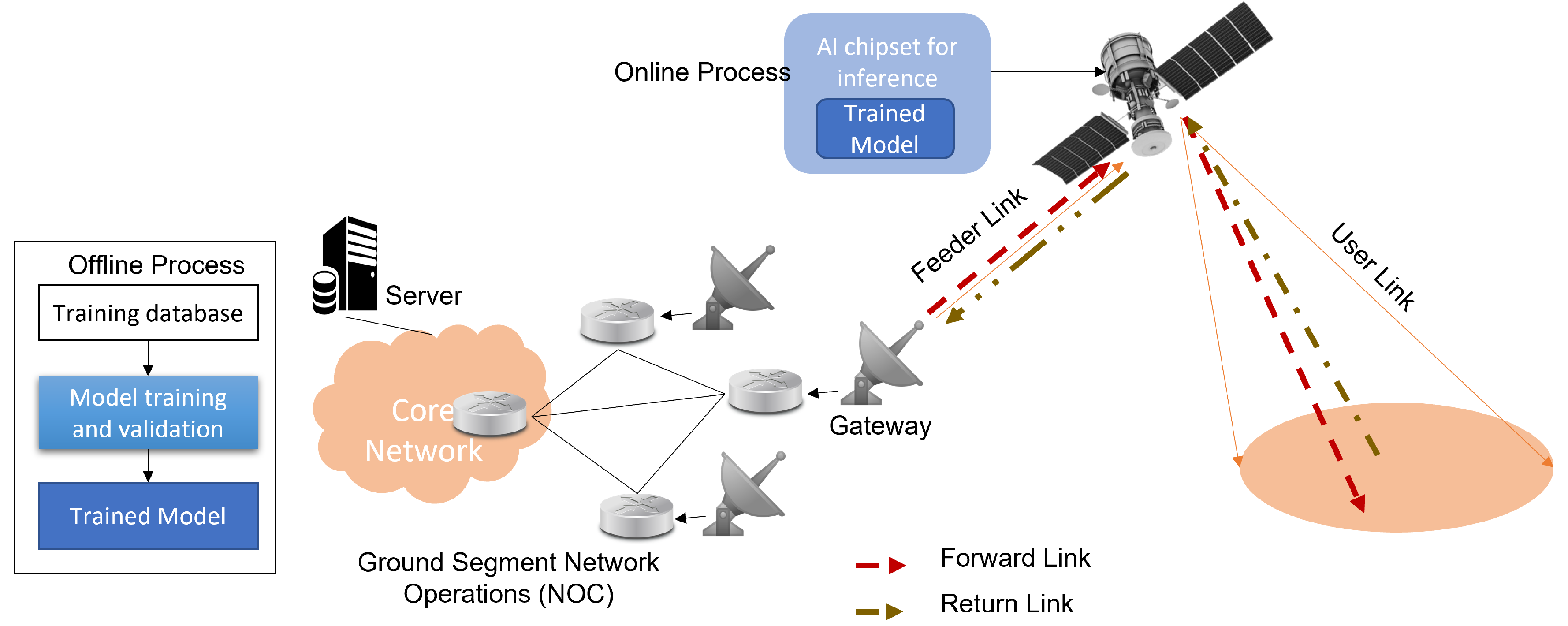
2. Onboard AI Processing
2.1. Onboard Applicability
2.2. AI Gain
2.3. Complexity
- Computational complexity. Number of operations as a function of the input size of an algorithm.
- Computational time. The execution time of an algorithm depends on the machine that executes it.
- Memory. Memory in neural networks is needed to store input data, weight parameters, and activations as input propagates through the network.
- Power consumption. Power is critical in both phases of AI-based techniques, the training phase and the testing phase. All available processing elements are used in a highly parallel fashion for training. For the inference phase, algorithms are optimized to maximize performance for the specific task for which the model is designed.
3. Onboard AI Applications
3.1. Use Cases
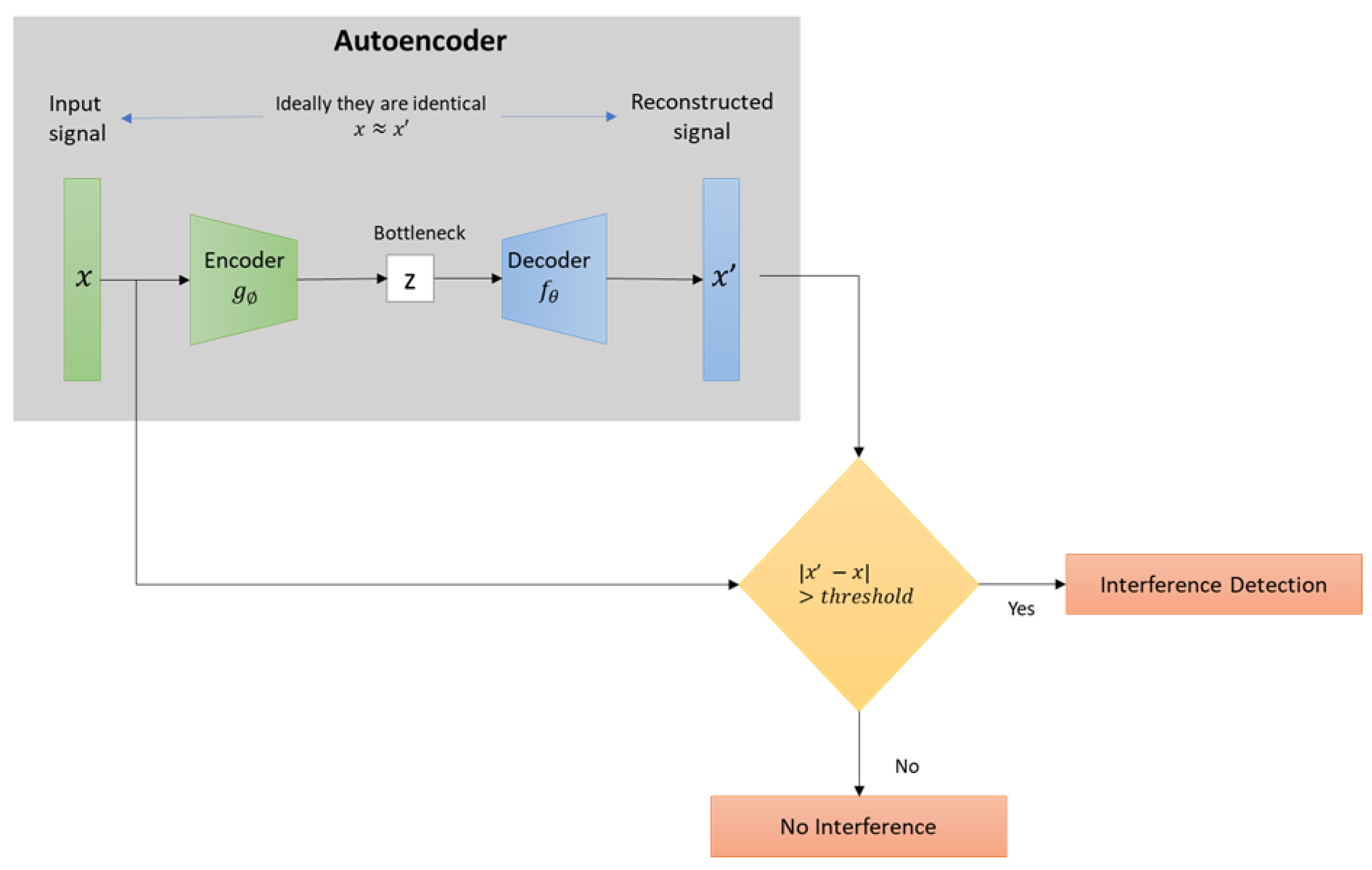
3.1.1. Interference Detection
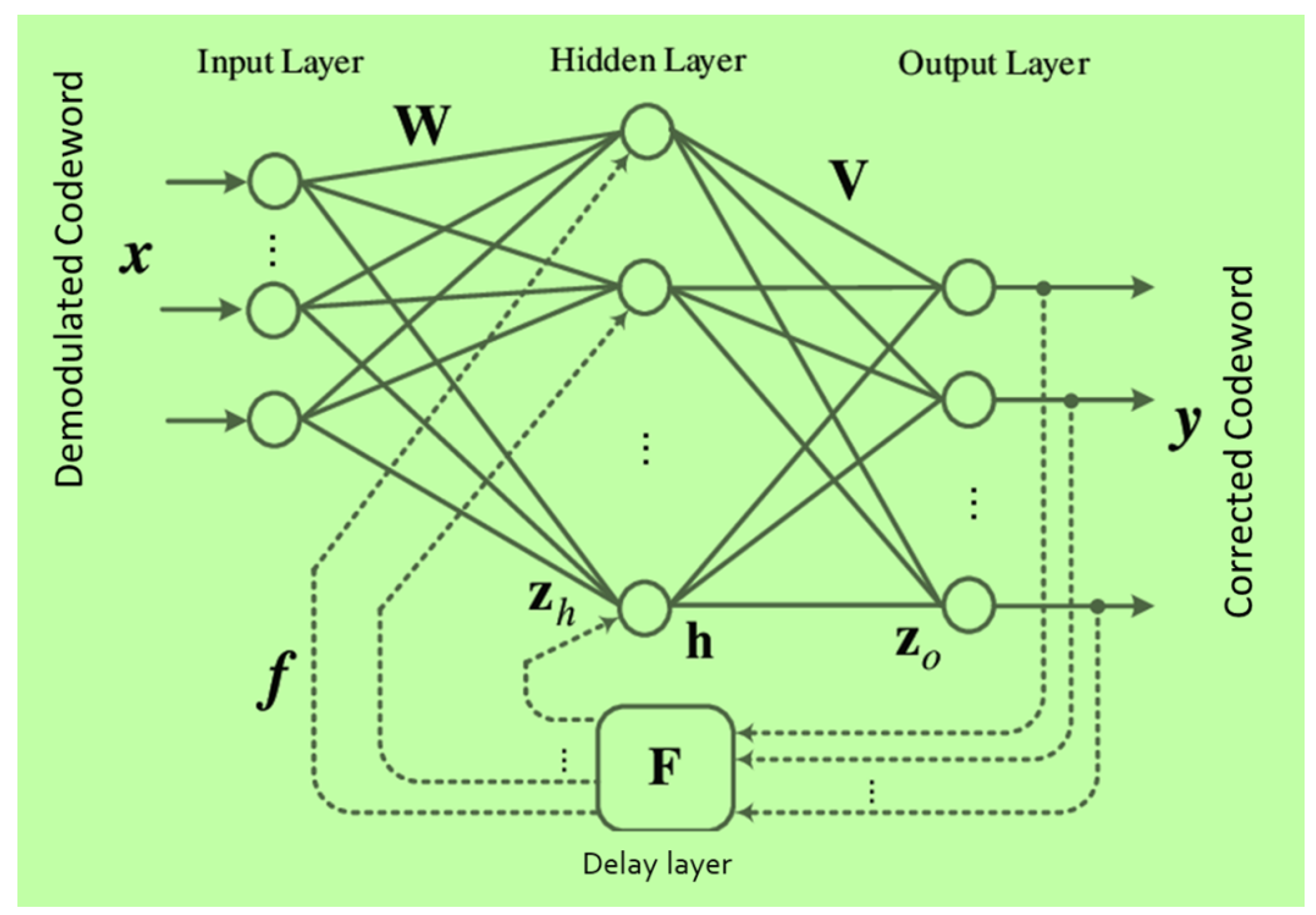
3.1.2. FEC in Regenerative Payload
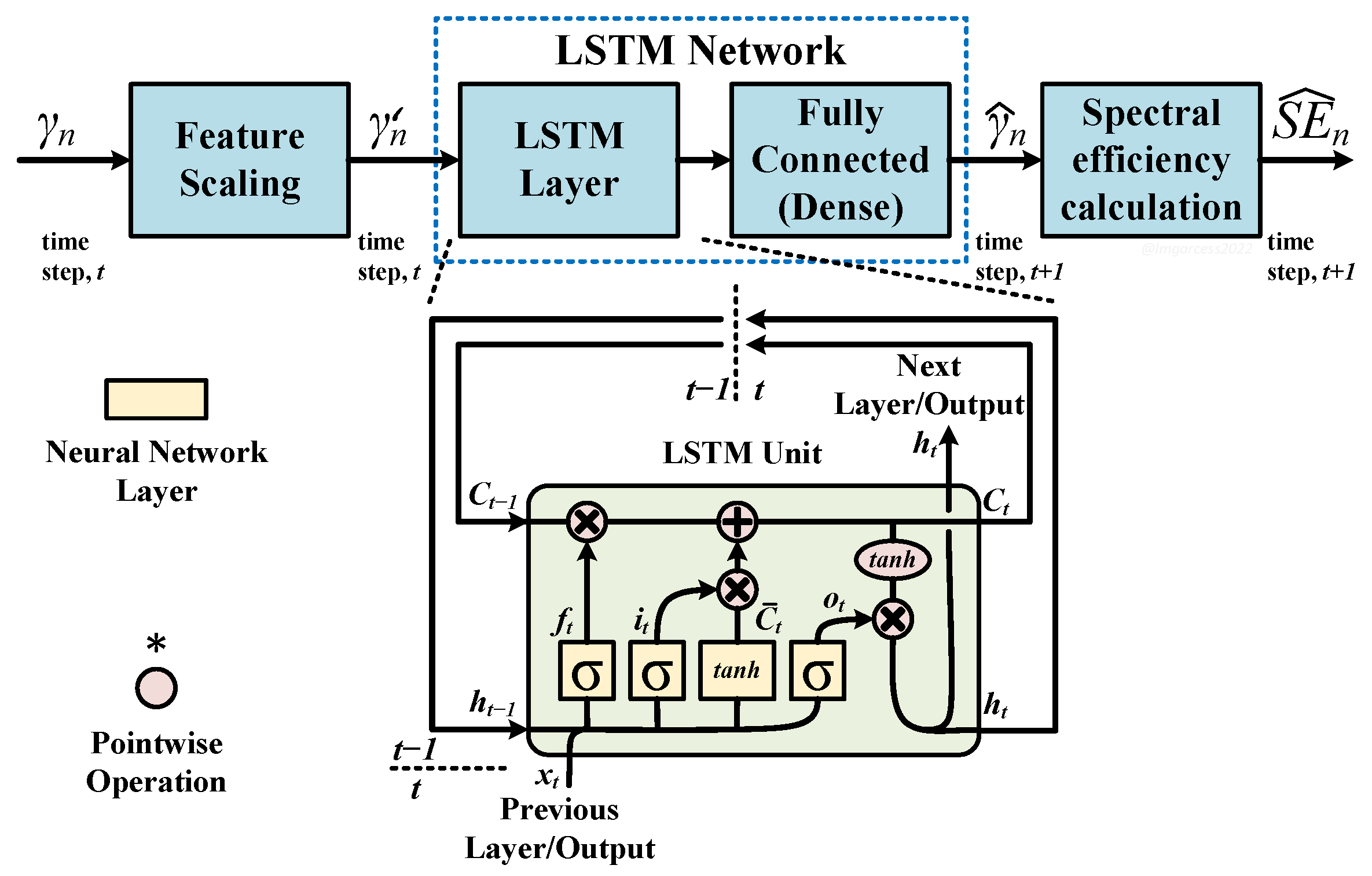
3.1.3. Link Adaption/ACM Optimization
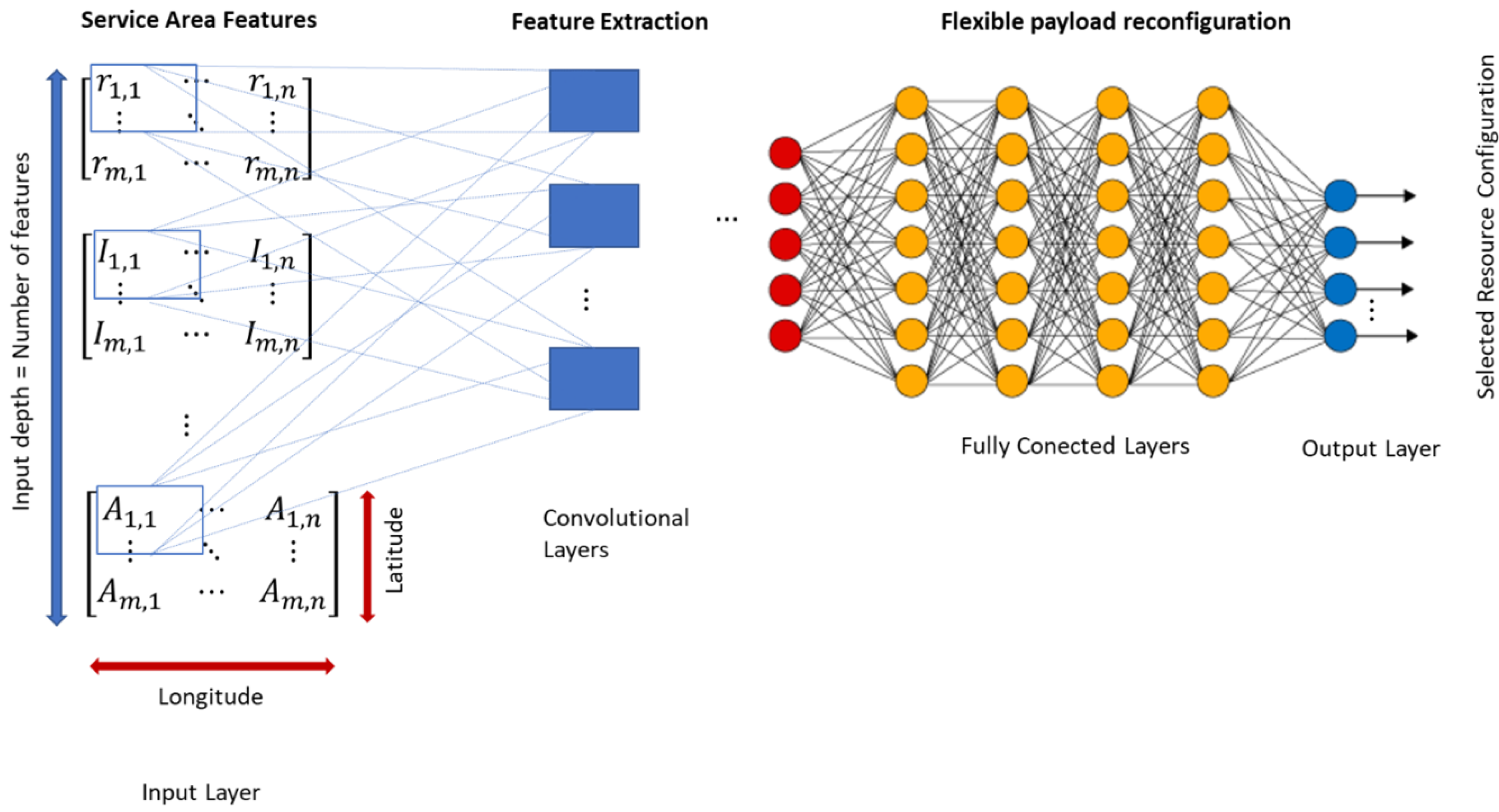
3.1.4. Flexible Payload Reconfiguration
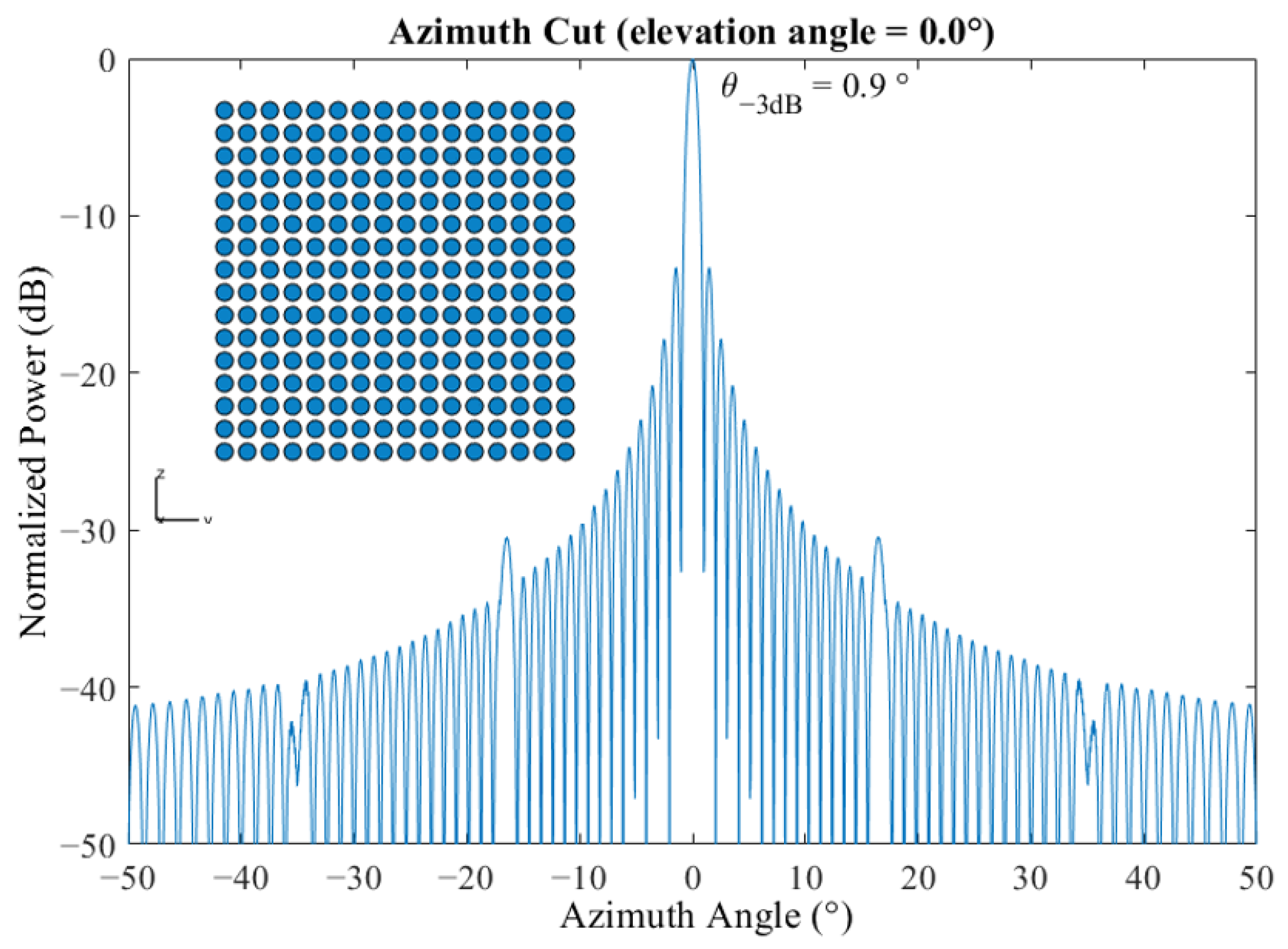
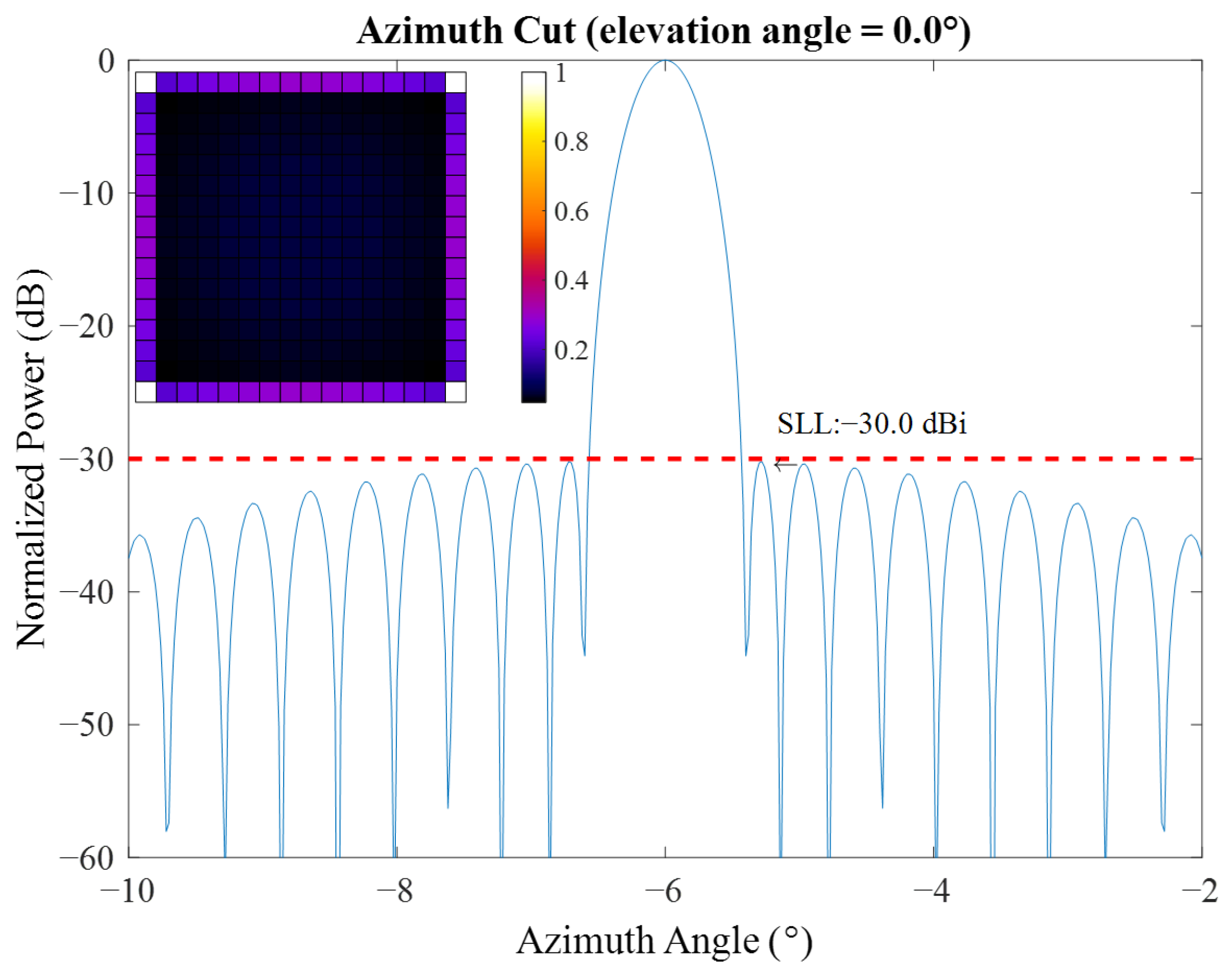
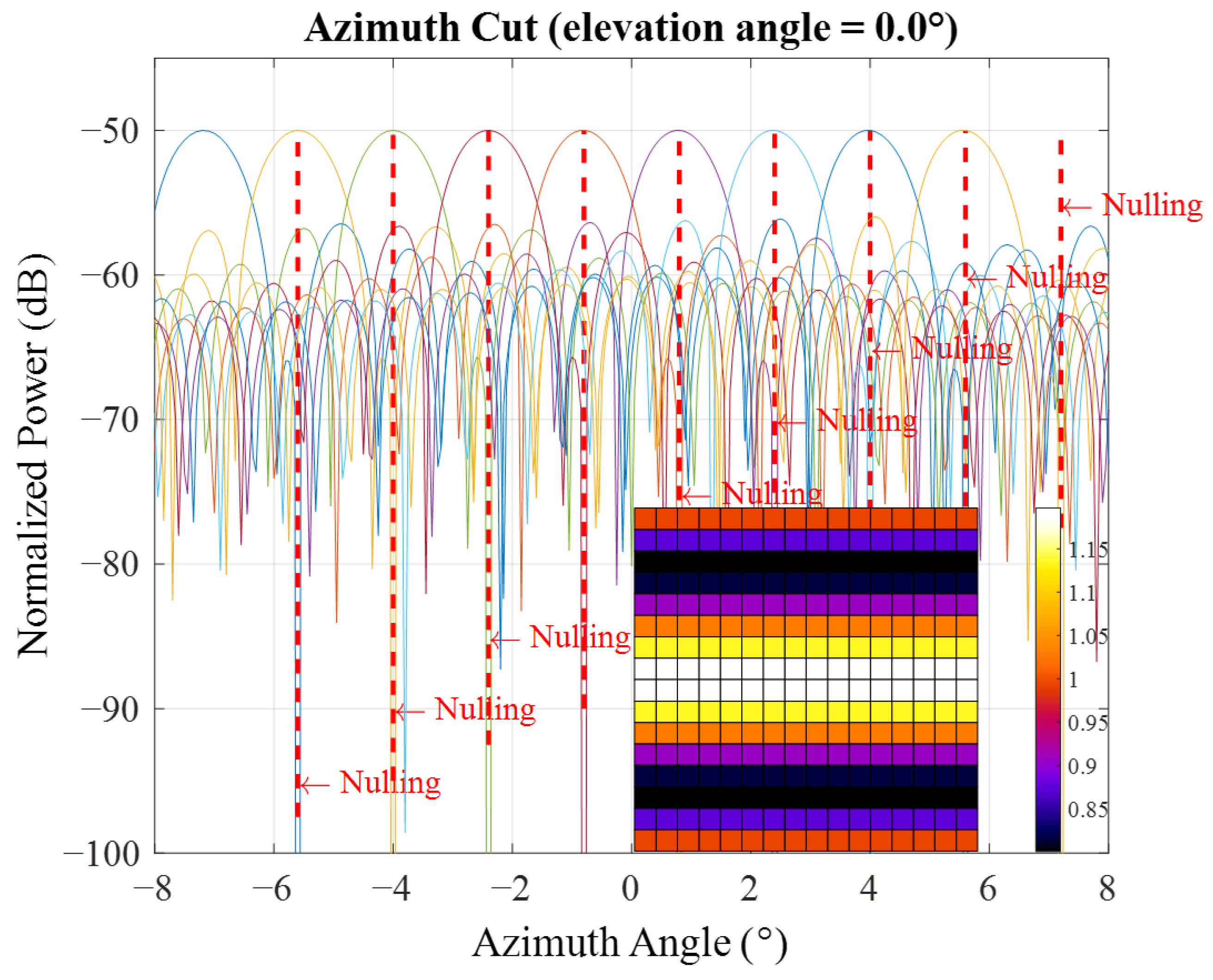
3.1.5. Antenna Beamforming
Beamwidth
Side Lobe Levels
Nulling
3.2. Use Cases Assessment
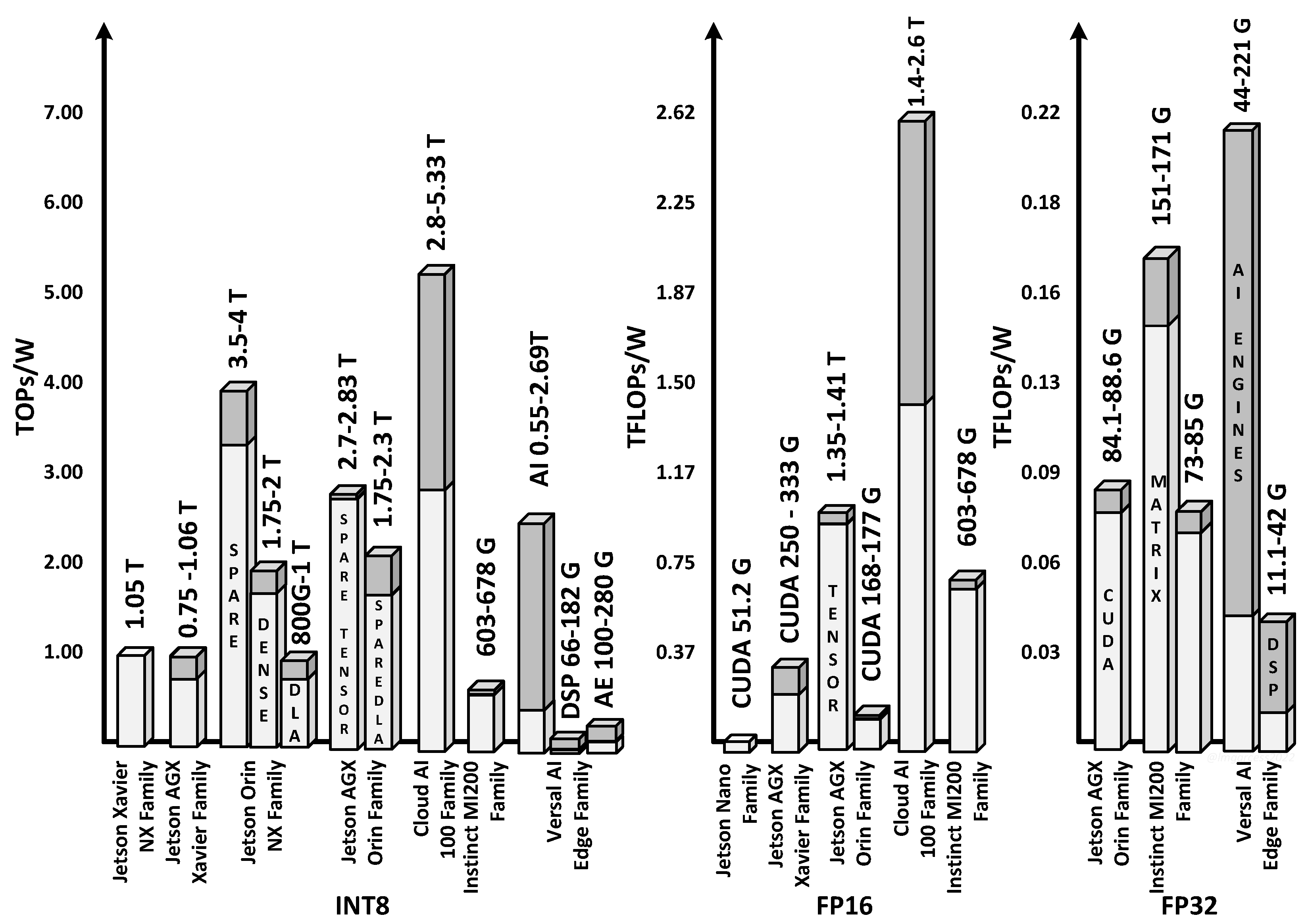
4. AI-Capable Commercial Chipsets
5. Conclusions and Future Challenges
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACM | Adaptive Coding and Modulation |
| AG-DPA | Assignment-Game-based Dynamic Power Allocation |
| AI | Artificial Intelligence |
| ANN | Artificial Neural Network |
| BP | Belief Propagation |
| CNN | Convolutional Neural Network |
| COTS | Commercial off-the-Shelf |
| CPU | Central Processing Units |
| CR | Cognitive Radio |
| CSI | Channel State Information |
| CU | Centralized Unit |
| DCA | Dynamic Channel Allocation |
| DDQL | Double Deep Q-Learning |
| DL | Deep Learning |
| DQL | Deep Q-Learning |
| DRA | Direct Radiating Array |
| DRL | Deep Reinforcement Learning |
| DSP | Digital Signal Processor |
| DTP | Digital Transparent Payload |
| DU | Distributed Unit |
| DVB-S2X | Digital Video Broadcasting–Second Generation Satellite Extensions |
| ED | Energy Detector |
| ESA | European Space Agency |
| FEC | Forward Error Correction |
| FOV | Field of Vision |
| FP | Floating point |
| GPU | Graphics Processing Unit |
| GSO | Geostationary Satellite Orbit |
| HSN | Heterogeneous Satellite Network |
| KPI | Key Performance Indicators |
| LDPC | Low-Density Parity Check |
| LEO | Low Earth Orbit |
| LSTM | Long Short-Term Memory Network |
| MEO | Medium Earth Orbit |
| MICP | Mixed-Integer Convex Programming |
| ML | Machine Learning |
| MLSAT | Machine Learning and Artificial Intelligence for Satellite Communication |
| MODCOM | Modulation and Coding |
| NGSO | Non-Geostationary Satellite Orbit |
| NVDLA | NVIDIA Deep Learning Accelerator |
| OPEX | Operational Expenditure |
| OPs | Operations per second |
| PHY | Physical layer |
| PL | Programmable Logic |
| PPA | Proportional Power Allocation |
| PVA | Programmable Vision Accelerator |
| QL | Q-Learning |
| QoS | Quality of Service |
| RAN | Radio Access Network |
| RNN | Recurrent Neural Network |
| RRM | Radio Resource Management |
| RU | Radio Unit |
| SAGIN | Space–Air–Ground Integrated Networks |
| SatCom | Satellite Communication |
| SATAI | Machine Learning and Artificial Intelligence for Satellite Communications |
| SHAVE | Streaming Hybrid Architecture Vector Engine |
| SINR | Signal-to-Interference-plus-Noise Ratio |
| SLL | Side Lobe Level |
| SNR | Signal-to-Noise Ratio |
| SVM | Support Vector Machine |
| UHTS | Ultra-High-Throughput Satellite |
References
- Vazquez, M.A.; Henarejos, P.; Pappalardo, I.; Grechi, E.; Fort, J.; Gil, J.C.; Lancellotti, R.M. Machine Learning for Satellite Communications Operations. IEEE Commun. Mag. 2021, 59, 22–27. [Google Scholar] [CrossRef]
- Ortiz-Gomez, F.G.; Lei, L.; Lagunas, E.; Martinez, R.; Tarchi, D.; Querol, J.; Salas-Natera, M.A.; Chatzinotas, S. Machine Learning for Radio Resource Management in Multibeam GEO Satellite Systems. Electronics 2022, 11, 992. [Google Scholar] [CrossRef]
- Kodheli, O.; Lagunas, E.; Maturo, N.; Sharma, S.K.; Shankar, B.; Montoya, J.F.M.; Duncan, J.C.M.; Spano, D.; Chatzinotas, S.; Kisseleff, S.; et al. Satellite Communications in the New Space Era: A Survey and Future Challenges. IEEE Commun. Surv. Tutorials 2021, 23, 70–109. [Google Scholar] [CrossRef]
- Morocho-Cayamcela, M.E.; Lee, H.; Lim, W. Machine learning for 5G/B5G mobile and wireless communications: Potential, limitations, and future directions. IEEE Access 2019, 7, 137184–137206. [Google Scholar] [CrossRef]
- Jiang, C.; Zhang, H.; Ren, Y.; Han, Z.; Chen, K.C.; Hanzo, L. Machine Learning Paradigms for Next-Generation Wireless Networks. IEEE Wirel. Commun. 2017, 24, 98–105. [Google Scholar] [CrossRef] [Green Version]
- Cornejo, A.; Landeros-Ayala, S.; Matias, J.M.; Ortiz-Gomez, F.; Martinez, R.; Salas-Natera, M. Method of Rain Attenuation Prediction Based on Long–Short Term Memory Network. Neural Process. Lett. 2022, 1–37. [Google Scholar] [CrossRef]
- SATAI | ESA TIA. Available online: https://artes.esa.int/projects/satai (accessed on 15 September 2022).
- MLSAT | ESA TIA. Available online: https://artes.esa.int/projects/mlsat (accessed on 15 September 2022).
- Glenn Research Center|NASA. Cognitive Communications; Glenn Research Center|NASA: Cleveland, OH, USA, 2020.
- Kato, N.; Fadlullah, Z.M.; Tang, F.; Mao, B.; Tani, S.; Okamura, A.; Liu, J. Optimizing Space-Air-Ground Integrated Networks by Artificial Intelligence. IEEE Wirel. Commun. 2019, 26, 140–147. [Google Scholar] [CrossRef] [Green Version]
- Wang, A.; Lei, L.; Lagunas, E.; Chatzinotas, S.; Ottersten, B. Dual-DNN Assisted Optimization for Efficient Resource Scheduling in NOMA-Enabled Satellite Systems. In Proceedings of the IEEE GLOBECOM 2021, Madrid, Spain, 7–11 December 2021. [Google Scholar]
- Deng, B.; Jiang, C.; Yao, H.; Guo, S.; Zhao, S. The Next Generation Heterogeneous Satellite Communication Networks: Integration of Resource Management and Deep Reinforcement Learning. IEEE Wirel. Commun. 2020, 27, 105–111. [Google Scholar] [CrossRef]
- Ferreira, P.V.R.; Paffenroth, R.; Wyglinski, A.M.; Hackett, T.M.; Bilen, S.G.; Reinhart, R.C.; Mortensen, D.J. Multiobjective Reinforcement Learning for Cognitive Satellite Communications Using Deep Neural Network Ensembles. IEEE J. Sel. Areas Commun. 2018, 36, 1030–1041. [Google Scholar] [CrossRef]
- Luis, J.J.G.; Guerster, M.; Del Portillo, I.; Crawley, E.; Cameron, B. Deep reinforcement learning for continuous power allocation in flexible high throughput satellites. In Proceedings of the IEEE Cognitive Communications for Aerospace Applications Workshop, CCAAW 2019, Cleveland, OH, USA, 25–26 June 2019. [Google Scholar] [CrossRef]
- Liu, S.; Hu, X.; Wang, W. Deep Reinforcement Learning Based Dynamic Channel Allocation Algorithm in Multibeam Satellite Systems. IEEE Access 2018, 6, 15733–15742. [Google Scholar] [CrossRef]
- Liao, X.; Hu, X.; Liu, Z.; Ma, S.; Xu, L.; Li, X.; Wang, W.; Ghannouchi, F.M. Distributed intelligence: A verification for multi-agent DRL-based multibeam satellite resource allocation. IEEE Commun. Lett. 2020, 24, 2785–2789. [Google Scholar] [CrossRef]
- Ortiz-Gomez, F.G.; Tarchi, D.; Martinez, R.; Vanelli-Coralli, A.; Salas-Natera, M.A.; Landeros-Ayala, S. Cooperative Multi-Agent Deep Reinforcement Learning for Resource Management in Full Flexible VHTS Systems. IEEE Trans. Cogn. Commun. Netw. 2021, 8, 335–349. [Google Scholar] [CrossRef]
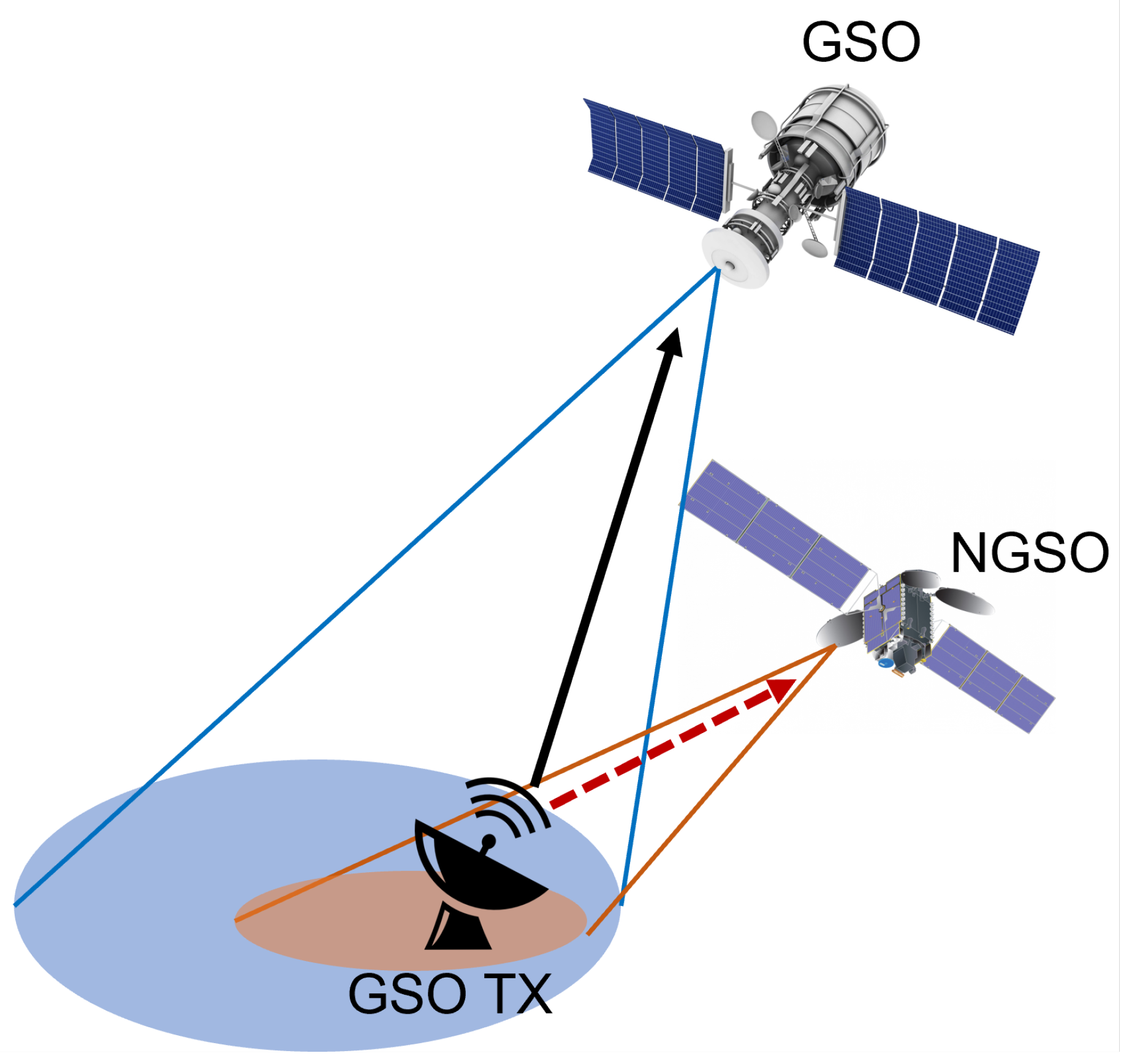
- Jalali, M.; Ortiz, F.; Lagunas, E.; Kisseleff, S.; Emiliani, L.; Chatzinotas, S. Radio Regulation Compliance of NGSO Constellations’ Interference towards GSO Ground Stations. In Proceedings of the IEEE International Symposium on Personal, Indoor and Mobile Radio Communications PIMRC, Kyoto, Japan, 12–15 September 2022. [Google Scholar]
- Politis, C.; Maleki, S.; Tsinos, C.; Chatzinotas, S.; Ottersten, B. Weak interference detection with signal cancellation in satellite communications. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing—Proceedings, New Orleans, LA, USA, 5–9 March 2017; pp. 6289–6293. [Google Scholar] [CrossRef] [Green Version]
- Politis, C.; Maleki, S.; Tsinos, C.; Chatzinotas, S.; Ottersten, B. On-board the satellite interference detection with imperfect signal cancellation. In Proceedings of the IEEE Workshop on Signal Processing Advances in Wireless Communications, SPAWC, Edinburgh, UK, 3–6 July 2016. [Google Scholar] [CrossRef]
- Prakash, C.; Bhimani, D.; Chakka, V.K. Interference detection & filtering in satellite transponder. In Proceedings of the International Conference on Communication and Signal Processing, ICCSP 2014—Proceedings, Melmaruvathur, India, 3–5 April 2014; pp. 1394–1399. [Google Scholar] [CrossRef]
- Regenerative Payload Using End-to-End Fec Protection. 2018. Available online: https://data.epo.org/publication-server/document?iDocId=5548983{&}iFormat=0 (accessed on 21 October 2022).
- Nachmani, E.; Be’Ery, Y.; Burshtein, D. Learning to decode linear codes using deep learning. In Proceedings of the 54th Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 27–30 September 2016; pp. 341–346. [Google Scholar]
- Mei, F.; Chen, H.; Lei, Y. Blind Recognition of Forward Error Correction Codes Based on Recurrent Neural Network. Sensors 2021, 21, 3884. [Google Scholar] [CrossRef] [PubMed]
- Monzon Baeza, V.; Lagunas, E.; Al-Hraishawi, H.; Chatzinotas, S. An Overview of Channel Models for NGSO Satellites. In Proceedings of the IEEE Vehicular Technology Conference, VTC-Fall, Beijing, China; London, UK, 26–29 September 2022. [Google Scholar]
- Wang, X.; Li, H.; Wu, Q. Optimizing Adaptive Coding and Modulation for Satellite Network with ML-based CSI Prediction. In Proceedings of the IEEE Wireless Communications and Networking Conference, WCNC, Marrakesh, Morocco, 15–18 April 2019. [Google Scholar] [CrossRef]
- Monzon Baeza, V.; Ha, V.N.; Querol, J.; Chatzinotas, S. Non-Coherent Massive MIMO Integration in Satellite Communication. In Proceedings of the 39th International Communications Satellite Systems Conference (ICSSC 2022), Stresa, Italy, 18–21 October 2022. [Google Scholar]
- Liu, S.; Fan, Y.; Hu, Y.; Wang, D.; Liu, L.; Gao, L. AG-DPA: Assignment game–based dynamic power allocation in multibeam satellite systems. Int. J. Satell. Commun. Netw. 2020, 38, 74–83. [Google Scholar] [CrossRef]
- Lei, L.; Lagunas, E.; Yuan, Y.; Kibria, M.G.; Chatzinotas, S.; Ottersten, B. Beam Illumination Pattern Design in Satellite Networks: Learning and Optimization for Efficient Beam Hopping. IEEE Access 2020, 8, 136655–136667. [Google Scholar] [CrossRef]
- AMD Inc. First Space-Grade Versal AI Core Devices to Ship Early 2023; AMD Inc.: Santa Clara, CA, USA, 2022. [Google Scholar]
- Rodriguez, I.; Kosmidis, L.; Notebaert, O.; Cazorla, F.J.; Steenari, D. An On-board Algorithm Implementation on an Embedded GPU: A Space Case Study. In Proceedings of the Design, Automation and Test in Europe Conference and Exhibition, DATE 2020, Grenoble, France, 9–13 March 2020; Institute of Electrical and Electronics Engineers Inc.: Grenoble, France, 2020; pp. 1718–1719. [Google Scholar] [CrossRef]
- Pang, G. The AI Chip Race. IEEE Intell. Syst. 2022, 37, 111–112. [Google Scholar] [CrossRef]
- NVIDIA. Jetson Modules. 2022. Available online: https://developer.nvidia.com/embedded/jetson-modules (accessed on 14 September 2022).
- AMD. AMD Instinct™ MI250 Accelerator. 2021. Available online: https://www.amd.com/en/products/server-accelerators/instinct-mi250 (accessed on 14 September 2022).
- Intel. Intel® Movidius™ Myriad™ X Vision Processing Unit 4GB. 2019. Available online: https://ark.intel.com/content/www/us/en/ark/products/125926/intel-movidius-myriad-x-vision-processing-unit-4gb.html (accessed on 15 September 2022).
- Qualcomm. Qualcomm®Cloud AI 100; Product Description; Qualcomm Technologies, Inc.: San Diego, CA, USA, 2019. [Google Scholar]
- Xilinx. Versal™ AI Core Series Product Selection Guide; User Guide; Advanced Micro Devices, Inc.: Santa Clara, CA, USA, 2021. [Google Scholar]
- NVIDIA Corp. NVIDIA Jetson Roadmap; NVIDIA Corp.: Santa Clara, CA, USA, 2022. [Google Scholar]
- Kosmidis, L.; Lachaize, J.; Abella, J.; Notebaert, O.; Cazorla, F.J.; Steenari, D. GPU4S: Embedded GPUs in Space. In Proceedings of the 22nd Euromicro Conference on Digital System Design, DSD 2019, Kallithea, Greece, 28–30 August 2019; Institute of Electrical and Electronics Engineers Inc.: Kallithea, Greece, 2019; pp. 399–405. [Google Scholar] [CrossRef]
- Kosmidis, L.; Rodriguez, I.; Jover, Á.; Alcaide, S.; Lachaize, J.; Abella, J.; Notebaert, O.; Cazorla, F.J.; Steenari, D. GPU4S: Embedded GPUs in space - Latest project updates. Microprocess. Microsystems 2020, 77, 103143. [Google Scholar] [CrossRef]
- Kosmidis, L.; Rodríguez, I.; Jover, Á.; Alcaide, S.; Lachaize, J.; Abella, J.; Notebaert, O.; Cazorla, F.J.; Steenari, D. GPU4S (GPUs for Space): Are we there yet? In Proceedings of the European Workshop on On-Board Data Processing (OBDP), Online, 14–17 June 2021; pp. 1–8. [Google Scholar]
- Steenari, D.; Forster, K.; O’Callaghan, D.; Tali, M.; Hay, C.; Cebecauer, M.; Ireland, M.; McBerren, S.; Camarero, R. Survey of High-Performance Processors and FPGAs for On-Board Processing and Machine Learning Applications. In Proceedings of the European Workshop on On-Board Data Processing (OBDP), Online, 14–17 June 2021; p. 28. [Google Scholar]
- Rodriguez, I.; Kosmidis, L.; Lachaize, J.; Notebaert, O.; Steenari, D. Design and Implementation of an Open GPU Benchmarking Suite for Space Payload Processing; Universitat Politecnica de Catalunya: Barcelona, Spain, 2019; pp. 1–6. [Google Scholar]
- Steenari, D.; Kosmidis, L.; Rodriquez-Ferrandez, I.; Jover-Alvarez, A.; Forster, K. OBPMark (On-Board Processing Benchmarks) - Open Source Computational Performance Benchmarks for Space Applications. In Proceedings of the European Workshop on On-Board Data Processing (OBDP), Online, 14–17 June 2021; pp. 14–17. [Google Scholar]
- Marques, H.; Foerster, K.; Bargholz, M.; Tali, M.; Mansilla, L.; Steenari, D. Development methods and deployment of machine learning model inference for two Space Weather on-board analysis applications on several embedded systems. In Proceedings of the ESA Workshop on Avionics, Data, Control and Software Systems (ADCSS), ESA, Virtual, 16–18 November 2021; pp. 1–14. [Google Scholar]
- AMD XILINX Inc. 5G Beamforming with Versal AI Core Series; Technical Report; AMD XILINX Inc.: San Jose, CA, USA, 2021. [Google Scholar]
- XILINX Inc. Beamforming Implementation on AI Engine; Technical Report; XILINX Inc.: San Jose, CA, USA, 2021. [Google Scholar]
- AMD XILINX Inc. XQR Versal for Space 2.0 Applications; Product Brief; AMD XILINX Inc.: San Jose, CA, USA, 2022. [Google Scholar]
- AMD XILINX Inc. AI Inference with Versal AI Core Series; Technical Report; AMD XILINX Inc.: San Jose, CA, USA, 2022. [Google Scholar]
- Ortiz, F.; Lagunas, E.; Martins, W.; Dinh, T.; Skatchkovsky, N.; Simeone, O.; Rajendran, B.; Navarro, T.; Chatzinotas, S. Towards the Application of Neuromorphic Computing to Satellite Communications. In Proceedings of the 39th International Communications Satellite Systems Conference (ICSSC), Stresa, Italy, 18–21 October 2022. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| KPI | Scores | |||||
|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | |
| Onboard applicability | Not applicable | Network of regenerative satellites | Regenerative Upper layers (CU–RAN) | Regenerative Lower layers (DU–RAN) | Regenerative PHY layer (RU–RAN) | DTP/RF/ Antenna Interface |
| AI Gain | No gain | Human intervention reduction | The previous score + OPEX reduction | The previous score + QoS gain | The previous score + processing time reduction | The previous score + performance gain |
| Complexity | Unfeasible | Extensive payload changes required | Computational level + memory-intensive + power and time constraints | Computational level + memory-intensive + power constraints | Computational level + memory-intensive | Computational level |
| Scenario | Input | Output | Total Scores |
|---|---|---|---|
| Interference Detection | Baseband digital signal | Binary detection flag | 13 |
| FEC in Regenerative Payload | Modulated or demodulated codeword | Corrected codeword | 10 |
| Link Adaptation/ ACM Optimization | SNR time series | Predicted SNR/ModCod | 9 |
| Flexible Payload | Demand Information | Configuration of the RF | 11 |
| Antenna Beamforming | User locations within antenna FOV | Beamforming parameters | 12 |
| Device | Provider | Core Units | |
|---|---|---|---|
| CPU | On-Chip Accelerator | ||
| Myriad Family | Intel | 2× Leon 4 RISC | Image/Video PA |
| SHAVE | |||
| Jetson Nano | NVIDIA | 4× ARM Cortex-A57MP | 128-CUDA Maxwell |
| Jetson TX2 Family | NVIDIA | 2× Denver ARM64b | 256-CUDA Pascall |
| 4× ARM Cortex-A57MP | |||
| Jetson Xavier NX Family | NVIDIA | 6× Carmel ARM64b | 384-CUDA Volta |
| 2× NVDLA | |||
| 2× PVA | |||
| 48 Tensor | |||
| Jetson AGX Xavier Family | NVIDIA | 8× Carmel ARM64b | 512-CUDA Volta |
| 2× NVDLA | |||
| 2× PVA | |||
| 64 Tensor | |||
| Jetson Orin NX Family | NVIDIA | 6×/8× ARM64b Cortex-A78AE | 1024-CUDA Ampere |
| 1×/2× NVDLAv2 | |||
| 1× PVAv2 | |||
| 32 Tensor | |||
| Jetson AGX Orin Family | NVIDIA | 8×/12× ARM64b Cortex-A78AE | 1792/2048-CUDA Ampere |
| 2× NVDLAv2 | |||
| 1× PVAv2 | |||
| 56/64 Tensor | |||
| Cloud AI 100 Family | Qualcomm | Snapdragon 865 MP | Cloud AI 100 |
| Kryo 585 CPU | |||
| Instinct MI200 Family | AMD | CDNA2 | 6656/14,080 Stream Proc. |
| 104/220 Core Units | |||
| Versal AI Edge Family | XILINX | 2× Cortex-A72 | 8-304 AI Engines |
| 2× Cortex-R5F2 | 90-1312 DSP Eng | ||
| 43k-1139k System Logic Cells | |||
| Device | Computer Capacity in Operations | Power Cons. (W) | ||
|---|---|---|---|---|
| I8 (Ops) | FP16 (FLOPs) | FP32 (FLOPs) | ||
| Myriad Family | NR | NR | NR | 1∼2 |
| Jetson Nano | NR | 512 G | NR | 5–10 |
| Jetson TX2 Family | NR | x | NR | 7.5–20 |
| Jetson Xavier NX Family | 21T | x | NR | 10–20 |
| Jetson AGX Xavier Family | 30–32 T | 10 T | NR | 10–40 |
| Jetson Orin NX Family | 70–100 T Sparse | x | x | 10–25 |
| 35–50 T Dense | ||||
| 20 T Sparse | ||||
| Jetson GX Orin Family | 108–170 T Sparse | 54–85 T | 3.3–5.3 T | 15–60 |
| 92–105 T Sparse | 6.7–10.6 T | |||
| Cloud AI 100 Family | 70–400 T | 35–200 T | x | 15–75 |
| Instinct MI200 Family | 181–383 T | 181–383 T | 45.3–95.7 T (Matrix) | 300–560 |
| 22.6–45.9 T | ||||
| Versal AI Edge Family | 5–202 T | NR | 0.4–16.6 T | 6–75 |
| 0.6–9.1 T | 0.1–2.1 T | |||
| 1–17 T | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ortiz, F.; Monzon Baeza, V.; Garces-Socarras, L.M.; Vásquez-Peralvo, J.A.; Gonzalez, J.L.; Fontanesi, G.; Lagunas, E.; Querol, J.; Chatzinotas, S. Onboard Processing in Satellite Communications Using AI Accelerators. Aerospace 2023, 10, 101. https://doi.org/10.3390/aerospace10020101
Ortiz F, Monzon Baeza V, Garces-Socarras LM, Vásquez-Peralvo JA, Gonzalez JL, Fontanesi G, Lagunas E, Querol J, Chatzinotas S. Onboard Processing in Satellite Communications Using AI Accelerators. Aerospace. 2023; 10(2):101. https://doi.org/10.3390/aerospace10020101
Chicago/Turabian StyleOrtiz, Flor, Victor Monzon Baeza, Luis M. Garces-Socarras, Juan A. Vásquez-Peralvo, Jorge L. Gonzalez, Gianluca Fontanesi, Eva Lagunas, Jorge Querol, and Symeon Chatzinotas. 2023. "Onboard Processing in Satellite Communications Using AI Accelerators" Aerospace 10, no. 2: 101. https://doi.org/10.3390/aerospace10020101