3.1.1. Estimation of
We start by finding a way to estimate the drift parameter
. First, Equation (
8) is transformed to a regression form. To this end, we introduce several additional variables. The first,
, is defined as
Let
be a series of ratios between consecutive prices of assets,
for
. Taking the above definitions into consideration, Equation (
8) can be rewritten as:
Now, let us divide both sides of this equation by
, as
is known, and at this stage, we consider
to be known too. Let us now introduce another two new variables,
as
and
as
Inserting them into Equation (
13) gives
The last expression has the form of a linear regression with
explained by
. We want to treat it with the Bayesian regression framework. To this end, we first collect all the discretised values of
and
into
n-element column vectors—
and
, respectively,
where the prime symbol is used for the transpose.
Assuming a prior distribution for
to be normal with mean
and standard deviation
, it follows from the Bayesian regression general results
O’Hagan and Kendall (
1994) that the posterior distribution for
is also normal with precision (inverse of variance)
, which can be calculated as
Here,
is the precision of the prior distribution, i.e.,
. The mean
of the posterior distribution is of the following form
where
is a classical ordinary-least-square (OLS) estimator of
, i.e.,
Hence, we can sample the realisations of
as follows:
where
i indicates the
i-th sample from the posterior distribution, which has been found for
. Having a realisation of
in form of
, we can quickly turn it into a realisation of the
parameter itself by a simple transform, inverse to Equation (
11)
3.1.2. Estimation of , , and
In order to estimate the parameters related to the volatility process, i.e.,
,
, and
, we conduct a similar exercise but this time using the volatility process. Let us first rewrite Equation (
9) as
Now, let us introduce two new parameters,
and
From Equations (
24)–(
26), we obtain
In a fashion similar to the equation for the stock price, we can rewrite this last expression as
Introducing the following vectors,
allows us to rewrite the original volatility equation in form of a linear regression
where
and
Using the formulas for Bayesian regression and assuming a multivariate (two- dimensional) normal prior for
with a mean vector
and a precision matrix
, we obtain the conjugate posterior distribution that is also multivariate normal with a precision matrix given by
and mean vector given by
where again
is a standard OLS estimator of
,
We can then use this posterior distribution of
for sampling
It is worth noting that the realisation of
appears in Equation (
39); however, we have not defined it yet. This is because the distribution of
is dependent on
, and the distribution of
is dependent on
. Hence, we suggest taking the realisation of
from the previous iteration here (which is indicated by the
subscript). We address the order of performing calculations in more detail later in this article.
Obtaining realisations of the actual parameters is very easy; one simply needs to inverse the equations defining
and
:
and
where
and
are, respectively, the first and the second component of the
vector.
The most common approach for estimating
is assuming the inverse-gamma prior distribution for
. If the parameters of the prior distribution are
and
, then the conjugate posterior distribution is also inverse gamma
where
and
3.1.3. Estimation of
For the estimation of
, we follow an approach presented in
Jacquier et al. (
2004). We first define the residuals for the stock price equation.
and for the volatility equation,
By calculating those residuals, we try to retrieve the error terms from Equations (
1) and (2),
and
, respectively, as we know they are tied with each other by a relationship given by Equation (
10). Taking this fact into consideration, we end up with the following equation
We now introduce two new variables, traditionally called
and
. It is not difficult to deduce that the relationship between
and the newly-introduced variables
and
is
Then, Equation (
47) becomes
which is again a linear regression of
on
. Thus, we can use the exact same estimation scheme as in case of the previously described regressions. We first collect the values of
and
in two
n-element vectors:
Then we appose both vectors, forming them into an
n-by-2 matrix:
Next, we define a 2-by-2 matrix
as
If we assume a normal prior for
with mean
and precision
, the posterior distribution for
is also normal with the mean
given by
and the precision
equal to
where
,
, and
are the elements of the matrix
on positions
,
, and
respectively.
Assuming the inverse gamma prior with parameters
and
for
, the conjugate posterior distribution is also the inverse gamma with parameters
and
Thus, sampling from the posterior distribution of
can be summarised as
while when it comes to sampling from
it is
To obtain
, we simply make use of Equation (
48).
3.1.4. Estimation of —Particle Filtering
For all the estimation procedures shown in the previous sections, we assumed
to be known. However, in practice, the volatility is not a directly observable quantity, it is “hidden” in the process of prices, to which we have access. Hence, we need a way to extract the volatility from the price process, and the particle filtering methodology is extremely useful for that purpose. Here, we only sketch the outline of the particle filtering logic, namely the SIR algorithm, which we utilise to obtain the volatility estimator. For a more in-depth review of particle filtering, we suggest the works of
Johannes et al. (
2009) and
Doucet and Johansen (
2009). Here, we follow a procedure similar to the one presented in
Christoffersen et al. (
2007).
We start by fixing the number of particles
N. In each moment of time
, we produce
N particles, which represent various possible values of the volatility at that point in time. By averaging out all of those particles, we obtain an estimate of the true volatility
. The process of creating the particles is as follows: at the time
, we create
N initial particles, all with the initial value of the volatility, which we assume to be the long-term average
. Denoting each of the particles by
, for
, we have
For any subsequent moment of time, except the last one
, we define three sequences of size
N.
is a series of independent standard normal random variables
The series
contains residuals from the stock price process, where the past values of volatility are replaced by the values of the particles from the previous time step
Finally, the series
, which incorporates the possible dependency between the stock process and the volatility particles, is
Having all that, the candidates for the new particles
are created as follows
Each candidate for a particle is evaluated based on how probable it is that such a value of the volatility would generate the return that was actually observed. The measure of this probability
is a value of a normal distribution PDF function designed specifically for this purpose
1,
To be able to treat the values of the proposed measure along with the values of particles as a proper probability distribution on its own, we normalise them, so that their sum is equal to 1,
Now, we combine the particles with their respective probabilities, forming two-element vectors
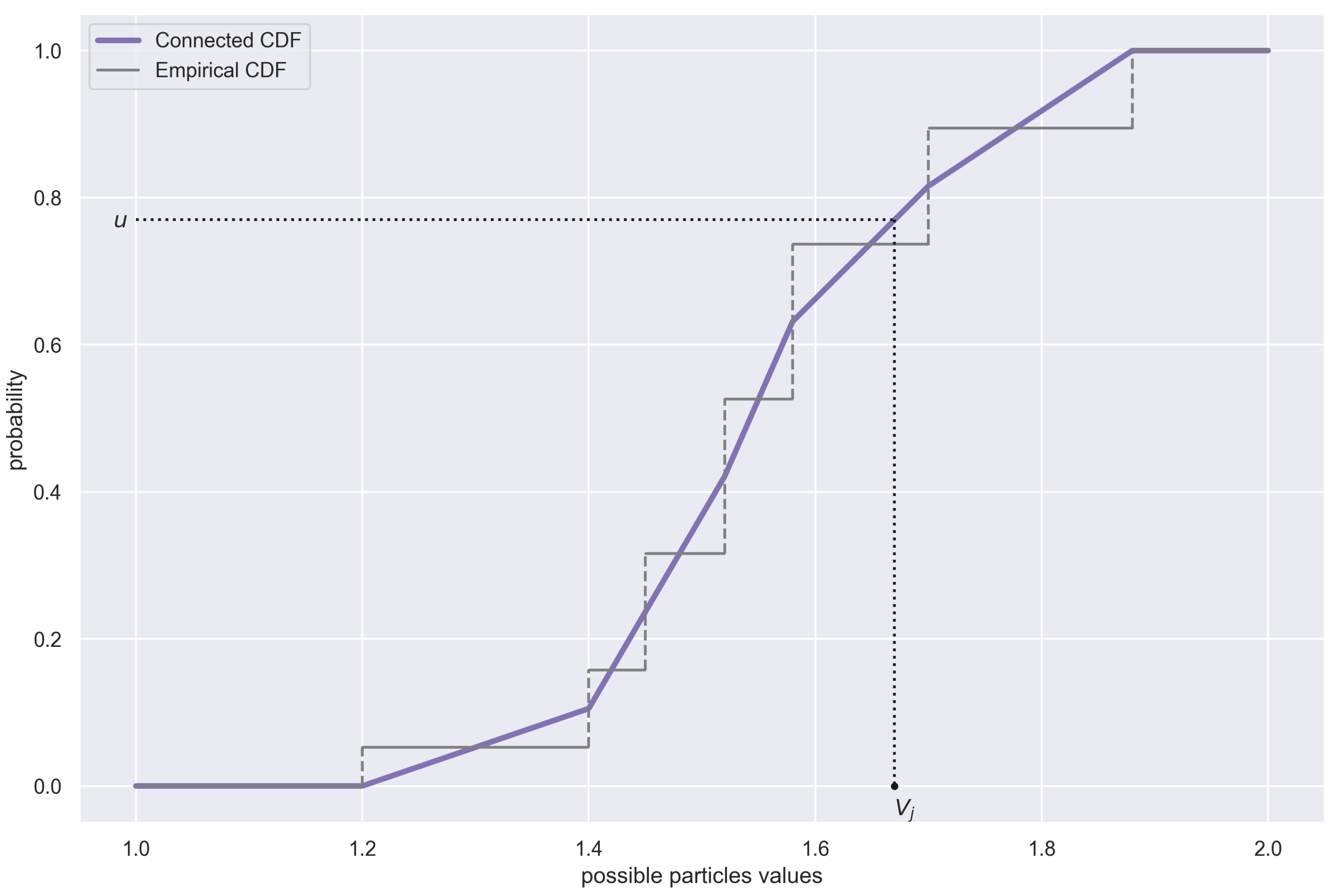
We now want to sample from the probability distribution described by to obtain the true “refined” particles. Most sources suggest drawing from it, treating it as a multinomial distribution. However, this makes all the “refined” particles have the same values as the “raw” ones, with just the proportions changed (the same “raw” particle can be drawn several times, if it has a higher probability than the others). To address this problem, we conduct the sampling in a different way. We first need to sort the values of particles in ascending order. Mathematically speaking, we create another sequence and call it , ensuring that the following conditions are all met:
The particle with the smallest value is the first in the new sequence, i.e.,
The particle with the largest value is the last in the new sequence, i.e.,
For any
, we have
We also want to keep track of the probabilities of our sorted particles; so, we order the probabilities in the same way, by defining another probability sequence
,
This step is necessary to ensure that each element of the sorted sequence of particle values
still has an original normalised probability
assigned to it. This is why it was necessary to pair up the particles and their normalised probabilities into two-element vectors, under Equation (
67). These pairs now help us approximate a continuous distribution, from which we can sample the refined particles. The “extreme” particles,
and
, will become the edges of the support of this new continuous distribution. The CDF function is given by the formula below (the time labels have been dropped for the sake of legibility, as all the variables are evaluated at
):
The formula might seem overwhelming, but there is a very easy-to-follow interpretation behind it (see
Figure 1). The new “refined” particles can be generated by drawing from the distribution given by
; the simplest way to do so is to use the inverse transform sampling.
After following the described procedure for each
, we can specify the actual estimate of the volatility process as the mean of the “refined” particles.
For , we can simply assume , which should not have any tangible negative impact on any procedure using the estimate for a sufficiently dense time discretisation grid.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





