1. Introduction
The progress and development of computer information systems and their indivisible connection to our lives have dramatically increased the motivation of attackers to target these systems [
1,
2]. Malicious software (malware) widely affects computer information systems in various ways, interrupting their normal operations, harming and removing files, programs, or services, and allowing illegitimate access to sensitive and private information.
In particular, malware disrupts regular user activity in computer systems by conducting undesired or harmful actions [
3]. According to the AV-Test Institute, the number of malware attacks on operating systems has increased by 722.505 million since 2022, compared to 13.365 million in 2008 [
4]. Many malware devices, such as ransomware, spyware, rootkits, worm, viruses, bots, botnets, Trojan horses, and other malware types, exist and target many parts of information systems, especially memory dump files. Memory dump aims to discover faults within working applications or programs.
Memory dump files regularly contain information on the final state of programs and applications. Memory areas and program status are considered points of interest for attackers to steal vital information such as passwords and encryption keys, causing a breach and a major threat to confidentiality, integrity, and authenticity [
5]. Manual detection methods of memory dump attacks are linked with limited capability due to low-accuracy rate and time-consuming issues, This can be developed by different machine learning systems, where training data is used to generate the most rapid and accurate evaluation possible [
6]. In contrast, a few machine learning techniques focus on speed, and others focus on precision and accuracy. Subsequently, it is crucial to select the most capable machine learning model for the memory dump context that can achieve the optimal model results [
7,
8].
Obfuscated malware [
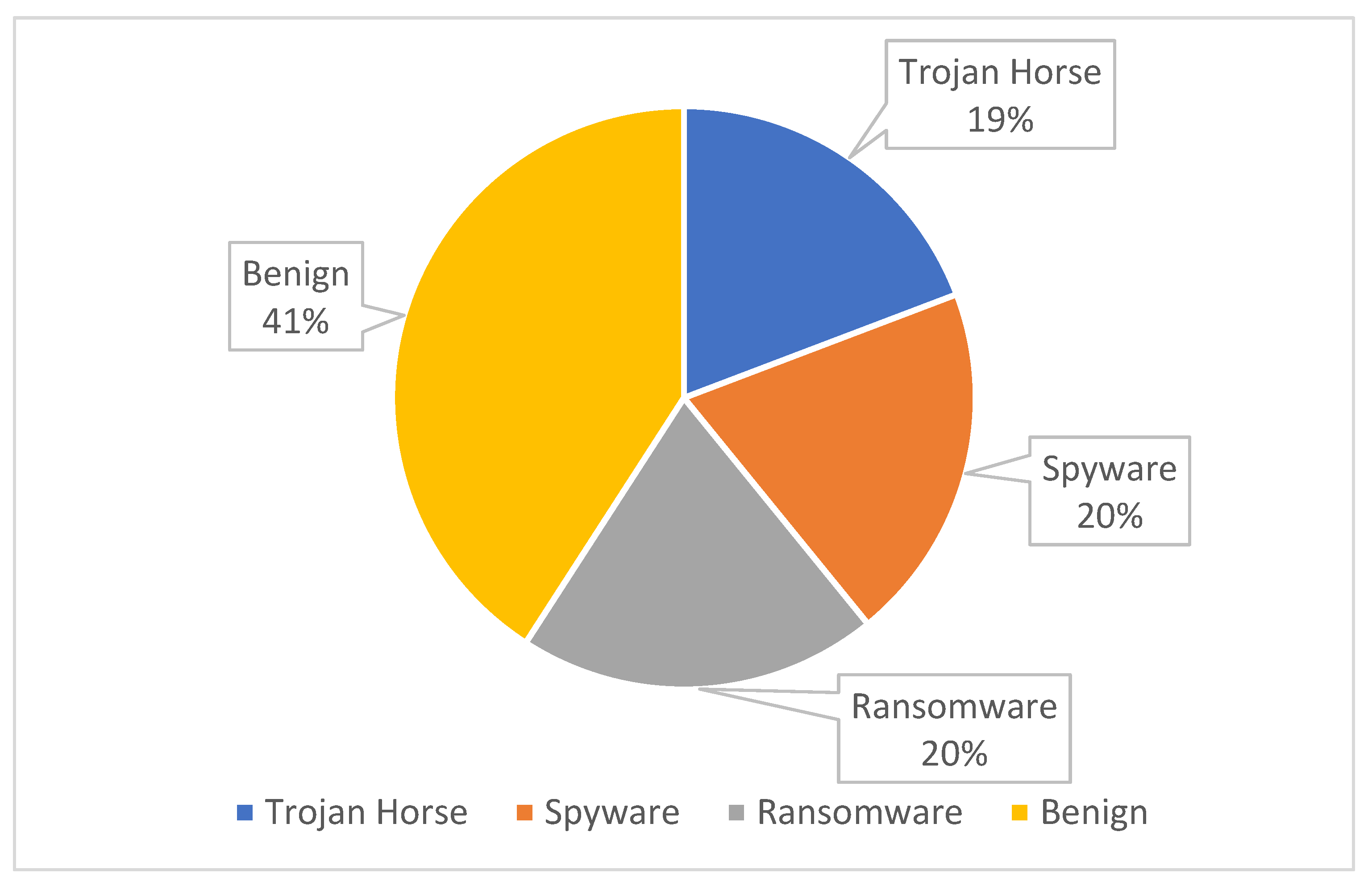
9] is malware that hides to avoid detection and extermination. In this research, we employed a dataset generated from an obfuscated malware dataset simulating real-world situations. “MalMemAnalysis2022” is a balanced dataset designed to test obfuscated malware detection methods through memory and is made up of spyware, ransomware, and Trojan malware. The structure of the “MalMemAnalysis2022” dataset is shown in
Figure 1.
This paper aims to provide an enhanced memory dump detection model by increasing the model’s sensitivity, improving its ability to be generalizable, and improving its efficiency in detecting different types of memory malware, especially zero-day malware. The OCSVM classifier is utilized to identify any deviation from the normal memory dump file patterns. In addition, a technique of dimensionality reduction, PCA, is combined with the OCSVM training phase to achieve the desired goals.
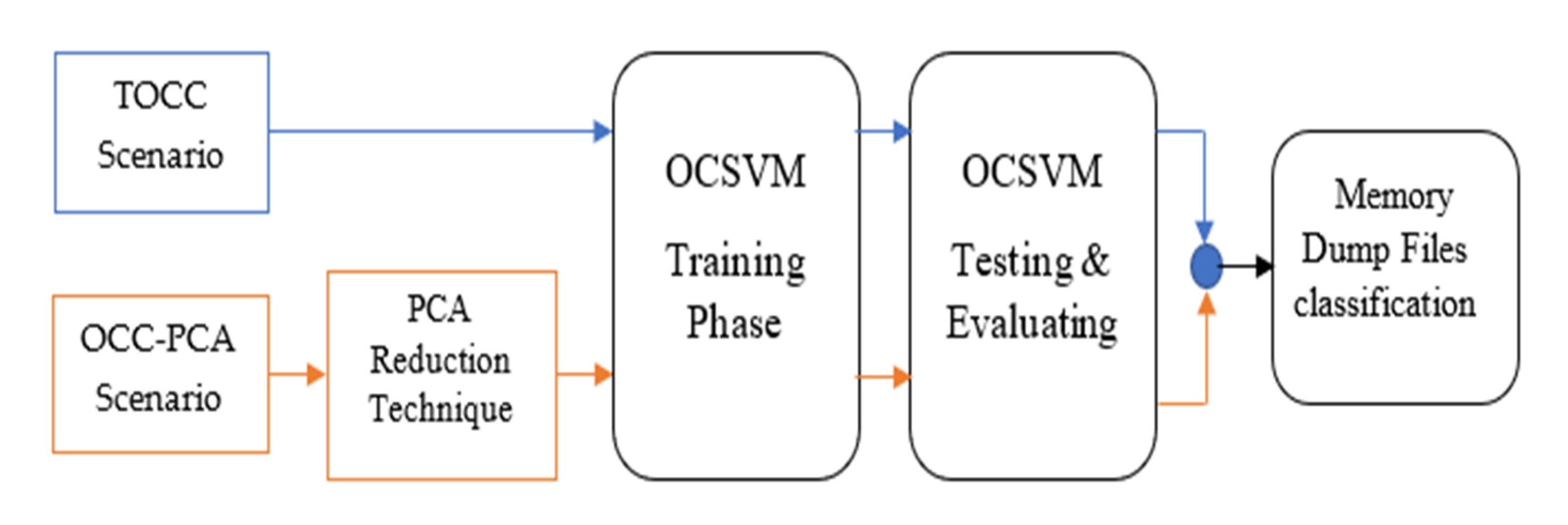
The “MalMemAnalysis2022” dataset [
7] is utilized in two scenarios, as illustrated in
Figure 2. The first scenario, known as TOCC, is to train an OCSVM classifier and evaluate its performance. The second scenario, OCC-PCA, is to reduce the dataset dimensionality using the PCA technique before training the OCSVM classifier. Several accuracy matrices have been used to evaluate the performance of both scenarios and to determine whether the PCA improved the standard OCSVM performance. The proposed OCSVM model achieved results and was compared with results reported in related studies for benchmarking and validation.
The remaining part of this paper is structured as follows:
Section 2 provides a background of memory dump attacks, the concept of novelty detection, the OCSVM, and PCA classifiers.
Section 3 demonstrates recent related work, whereas
Section 4 comprehensively describes the methodology.
Section 5 describes and analysis the evaluation results.
Section 6 is the conclusion.
3. Literature Reviews
Many researchers have employed different one-class classification techniques to detect novel attacks efficiently as soon as they occur. Consequently, most experimental attempts are combined with various enhancement techniques to improve the one-class classifier performance.
This section provides a comprehensive review of studies that adopted different class classification techniques. The focus was on how classifiers are employed, what attempts were used to enhance the performance, the utilized datasets, and what results were achieved.
Ref. [
16] proposed an anomaly-based and signature-based NIDS that overcame other systems in terms of reducing false alarm rates and detecting zero-day attacks. To build the NIDS, they presented two parallel subsystems, each utilizing OCSVM. The target class of the first OCSVM subsystem was the normal network packets to detect any outliers, while in the second OCSVM subsystem the target class was the attack packets to identify the known attacks. This research used the “KDDCUP-99” dataset for the training phase. Then the optimal features were selected using the Pigeon Inspired Optimizer (PIO) from the training sets. In the proposed methodology, the two subsystems were integrated in a parallel manner to judge each packet; in this way, false alarms were reduced, and detection rates were increased. For evaluation, “KDD CUP-99”, “NSL-KDD”, and “UNSW-NB15” datasets were used in the proposed NIDS testing phase. This research was carried out with the “KDD CUP-99” dataset: (99.7%) accuracy rate, (99.8%) DR, and (0.02%) FPR.
The authors of [
17] proposed using SIMCA and OCSVM models to identify impurities in cassava starch. Both models used a one-class classification technique. The SIMCA model used PCA instead of the OCSVM model, which used the OCSVM classifier. The evaluation results showed the two models’ accuracy rates, 78.8%, and 86.9%, respectively, in forecasting benign data. In the same respect, OC-SVM, WOC-SVM-DD, WOC-SVM (ND), and AWOC-SVM classifiers were implemented utilizing eight different datasets.
Preliminary results in ref. [
18] confirmed the viability and effectiveness of the WOC-SVM-DD classifier, which improved the weight calculation procedure, and addressed limited sample and high-dimension classification. Further experiments indicated the outstanding performance of OCSVM, 99.3% accuracy, utilizing the banknote authentication dataset.
In [
19], an HIDS model that combines the C5 and OC-SVM classifiers was developed and evaluated. The model was tested on the NSL-KDD and ADFA datasets. Three evaluation stages were conducted to reach high-accuracy results; in the last stage, OCSVM with an RBF kernel was applied using LIBSVM to achieve a detection accuracy of 76.4% for the ADFA dataset and 72.17% for the NSL-KDD dataset.
The authors of [
20] described a semi-supervised novelty identification technique based on OC-SVM for SMS spam detection. The researchers used a chi-squared feature selection algorithm, and only normal data were trained and had a 98% accuracy rate.
The authors of [
21] introduced an unsupervised deep learning strategy for IDS. NSL-KDD and UNSW-NB15 datasets were implemented, and the proposed CAE + OCSVM classifier was combined with a 1D CAE approach to a joint optimization framework. Convolutional auto-encoder and CNN methods were implemented to accomplish significant feature illustrations for both datasets. This method boosts OCSVM’s prediction accuracy to 91.58% with the NSL-KDD dataset and 94.28% with the UNSW-NB15 dataset.
In addition, in [
22], an anomaly-based NIDS that utilizes unsupervised methods to detect zero-day attacks was presented. Furthermore, unsupervised NIDS demonstrated their capacity to identify unidentified zero-day attacks provided that the malicious traffic diverges from legitimate traffic. The OCSVM produced the highest AUROC scores of 97% on the CIC-IDS-2017 dataset and 94% on the CSE-CIC-IDS-2018 dataset. At the same time, PCA achieved a good classification performance with the lowest recorded AUROC of 84% on the CSE-CIC-IDS-2018 dataset.
Moreover, in [
23], a cutting-edge NIDS model that used the OCSVM technique was developed and tested. The suggested approach relies on identifying regular traffic. An accuracy rate of 97.61% was achieved in an experiment using a recent honey network. Consequently, according to the experimental findings, OCSVM has 97.6% accuracy for predicted benign behavior.
In [
24], the authors proposed an unsupervised learning model memory augmented auto-encoder (MemAE); performance results of the model proposed were compared with OCSVM and AE models. All three models were trained on benign records and implemented using UNSW-NB15, NSL-KDD, and CICIDS 2017 datasets. The OCSVM model accuracy rate values were 94% on NSL-KDD, 81% on UNSW-NB15, and 76% on CICIDS 2017 datasets. Accordingly, MemAE was proposed as a solution to the over-generalization problem of auto-encoders.
Furthermore, in [
25], a unique method for exploiting PMU data to detect cyber-attacks on smart grids was proposed and built. It uses publicly accessible datasets on power system hacks and is based on semi-supervised anomaly identification. A performance comparison was carried out between four semi-supervised algorithms and four supervised algorithms. The four semi-supervised techniques were set up with PCA and a deep auto-encoder feature extraction approach. The OCSVM classifier had 84%, 85%, and 86% accuracy rates for all features, PCA, and DAE, respectively.
The authors of [
26] built an anomaly-based NIDS and then proposed an improvement to achieve a higher intrusion detection rate utilizing only the normal class of the KDD99 dataset. Basically, unsupervised training was conducted with an OCSVM algorithm. To obtain the best performance with minimal false alarms, they applied a nested approach to the OCSVM algorithm to find the optimum hyperparameter for it. The latter is called the “data-driven approach for intrusion detection using nested OCSVM.” The two approaches were evaluated, and the nested OCSVM approach achieved the best results: (12%) and (98.25%) for FP and accuracy rates, respectively.
A hybrid SAE-1SVM model was proposed by [
27], where the stack autoencoder and the OCSVM algorithm were merged. The authors aimed to construct an NIDS that detects DDoS attacks in software-defined networks (SDNs). The unsupervised anomaly detection approach was based on only the legitimate traffic flows represented in the CICIDS2017 dataset. First, feature dimensionality reduction was performed using the stack autoencoding algorithm. Second, the OCSVM algorithm was trained with the resulting low-dimensional feature set. The proposed model has proven its efficiency with real-time detection along with its effectiveness in detecting DDoS attacks with an accuracy rate of (99.35%), (99.97%) for the precession score, (98.28%) for the recall score, and (99.11%) for the F1 score.
Looking at the literature reviews mentioned, obviously, the researchers who combined the OCSVM algorithm with a dimensionality reduction technique achieved higher accuracy rates. The core point is eliminating all features that are not necessary and focusing on the crucial features to produce more robust results. Therefore, this work uses a PCA classifier to extract vital features from every characteristic of the dataset and improve OCSVM performance. The achieved results reached a 99.4% accuracy rate.
Table 1 shows a comparison of the proposed approach with other related works.
4. Methodology
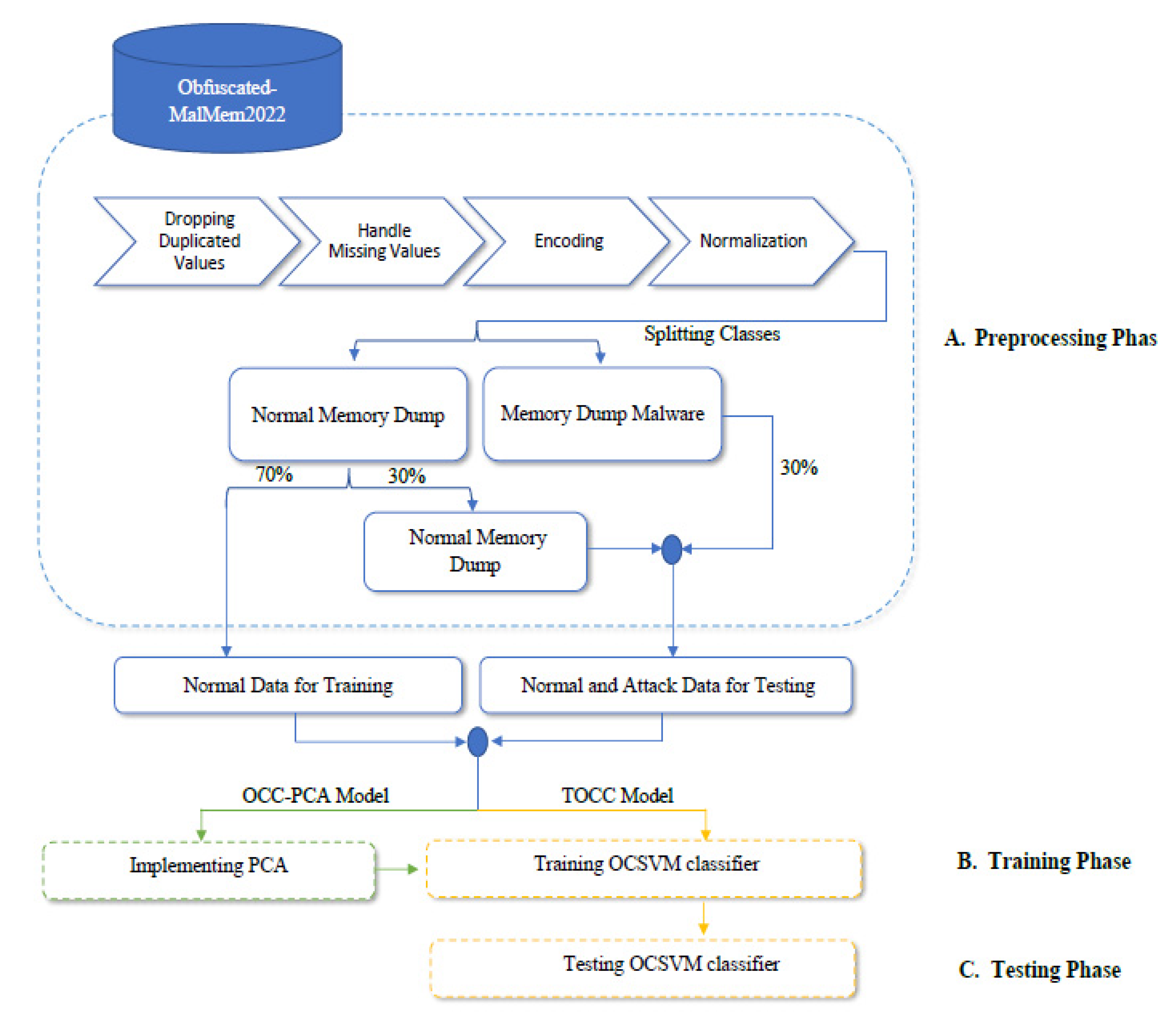
This section describes the study’s methodology and practice. Many phases were implemented to accomplish the desired goals and objectives. The pre-processing stage was applied to the dataset in five steps: partitioning the dataset, handling missing values, removing duplicate entries, and encoding. The OCC-PCA model utilized the PCA classifier on the dataset to minimize the number of features from 53 to 10 after the complete pre-processing phase. However, 53 features from a dataset were retained by the TOCC method. The OCSVM classifier was then implemented for two models using dataset training samples to train and learn. Two models will then be tested with the OCSVM classifier.
The MalMemAnalysis2022 dataset was created in 2022 to imitate real-world settings similar to malware seen in the real. Collecting malicious and benign dumps, the malMemAnalysis2022 dataset consists of 58,596 records, with 29,298 benign and 29,298 attack records, including 56 features and three main categories of memory dump malware (ransomware, spyware, and Trojan horse) [
7]. Many reasons for implementing this recent dataset are considered since it is a balanced binary classification dataset with a few missing values. In addition, we are among the earlier researchers to use this dataset. This methodology employs the Python programming language, and the OCSVM classifier is utilized to determine the experimental environment. After the testing step, the method offers information on the performance matrices used to assess the findings.
Figure 3 depicts the methodology of the two proposed approaches.
4.1. Dataset Pre-Processing Phase
The dataset goes through various processes in this phase to remove noise and then adapt it to the chosen ML methods, as mentioned in
Figure 3.
4.1.1. Dropping Duplicate Values
All duplicate rows with missing values were dropped. This stage eliminates duplicate features in the dataset for two approaches by removing the redundant feature column. The first column feature, known as “category,” with the type “object,” was dropped. Another two columns named “handles. nport” and “svcscan.interactive_process_services” were dropped since they have zero numbers; the dataset, after removing three columns, has 53 features; the last column, formerly known as a “class” with the type “object” was renamed “label”.
4.1.2. Handle Missing Values
The dataset’s missing values and duplicated rows are dealt with in two approaches at this level. Depending on their implications, missing values were adjusted by eliminating entire rows or replacing them with appropriate values as median [
28].
4.1.3. Encoding Dataset
To be acceptable for the two approaches, 0 and 1 numbers define all benign attacks.
4.1.4. Value Normalization
The dataset’s independent values are not fairly distributed; all values are set closely together to normalize with the classifier for the best accuracy and measurement performance matrices.
4.1.5. Dataset Partitioned
After completing all the previous steps in the pre-processing phase, all duplicate rows, duplicate features, and missing values are dealt with by eliminating, dropping, or replacing. The dataset after that was divided into 28,796 records for memory dump malware and 29,231 for benign records. To prepare the OCSVM classifier to be trained and tested, the dataset depends on more samples for the training phase to make the model more generalizable. Malware records are divided into 30%, with 8770 records utilized for the testing phase, while the remaining 70%, with 20,026 records, remain inactive. Benign records were split into 70%, with 20,461 records for training the classifier, and 30%, with 8770 records, for the testing phase.
Table 2 depicts the number of records in the training and testing phase.
4.2. Training Phase
After completing dataset pre-processing, the OCSVM classifier was set to depend on benign records for each model to train the classifier. Twenty-nine thousand two hundred thirty-one benign records of the dataset were split into two halves; 70% of benign records were to be utilized for the training classifier on both models, while 30% were to be utilized for the testing phase, as mentioned in
Figure 3. On another side, the experimental setup of two models was implemented in a 64-bit Windows 11 pro computer with 12 GB RAM and 1.80 GHz CPU; the ML models were implemented using Python 3.8, and SPYDER 4.2.5 provide libraries, Panda, Scikit-learn, and Numpy.
Table 3 depicts the experimental setup for other related works.
4.2.1. The OCC-PCA Approach
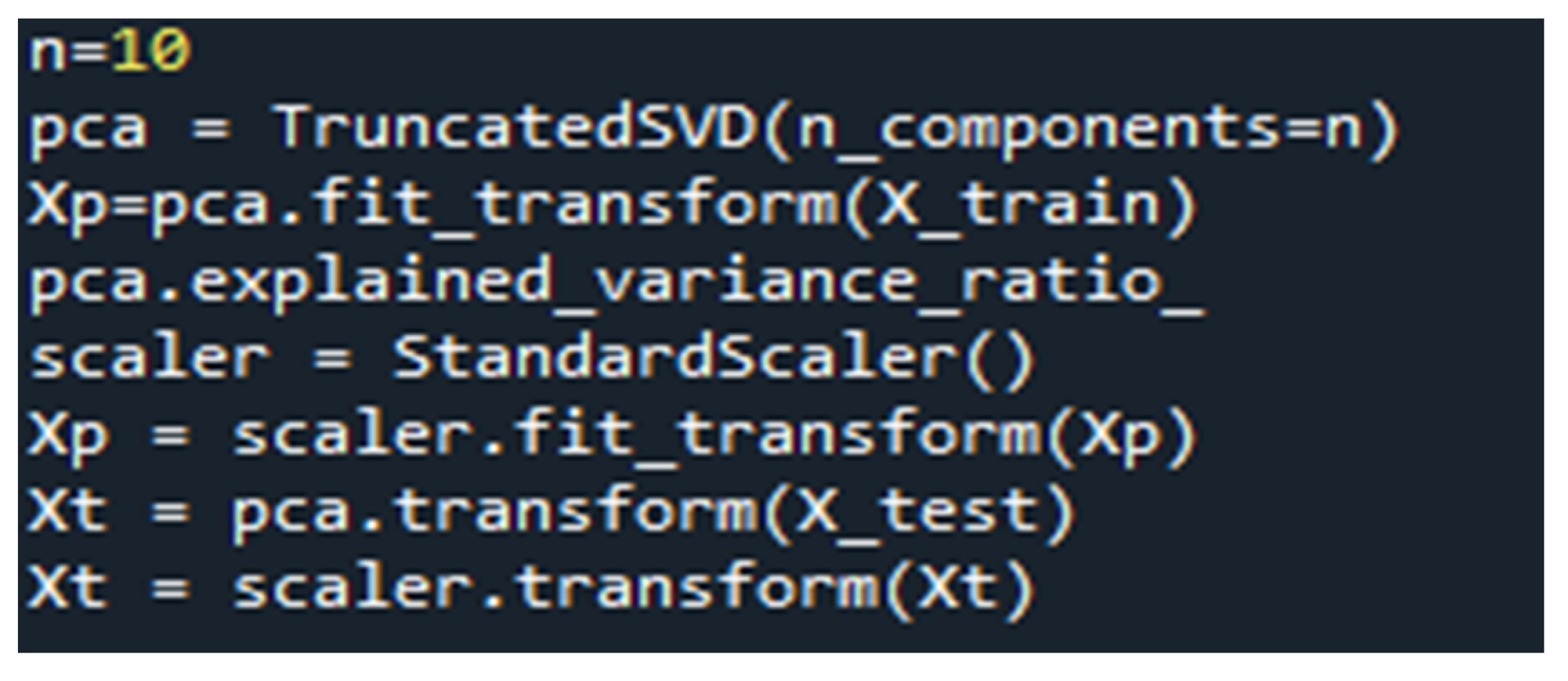
Automated dimensional reduction is implemented by utilizing a PCA classifier to select ten features (n = 10) out of 53 feature selections from the dataset where “n” is the number of feature extractions; then, the OCSVM classifier is trained on 20,461 benign records. To select the best n value that suits the number of available features, an experiment with n = 30, as in [
25,
29], is conducted. Furthermore, in an attempt to decrease the time consumed, another experiment is conducted with n = 10. The python code for implementing the PCA is shown in
Figure 4.
The results of the two experiments are shown in
Table 4. The results illustrate that setting n to 10 is the best for achieving a higher accuracy rate and lower consumption time.
4.2.2. The TOCC Approach
This approach was trained using the identical 20,461 benign records without utilizing any dimensional reduction techniques and dealt with 53 features from the dataset after the pre-processing phase to train the OCSVM classifier.
4.3. Testing Phase
Testing the OCSVM classifier for both novelty-class techniques follows the completion of OCSVM classifier training for two approaches. The OCC-PCA and TOCC models use 8770 benign and 8770 malware records, totaling 30% benign and 30% malware records, respectively. A total of 17,540 data were employed. The result demonstrates the prediction error for the final model and the suggested model’s generalizability, as mentioned in
Figure 4.
5. Analysis and Evaluation of the Results
In the evaluation phase, confusion matrix variables consist of four variables, detecting benign records correctly as true negative (TN), correctly detecting attack records as true positive (TP), incorrectly recognizing benign records as false positive (FP), and incorrectly recognizing attack records as false negative (FN) [
30]. This was developed by comparing actual label values to predicted label values in the testing phase and measuring performance matrices for both models. Recall value is a way to measure how many predicted positives were TPs. There is an inverse relationship between sensitivity/recall and FN alarm rates [
31]. The authors mentioned that the model that produces no FN alarms has a recall score of 1. The proposed model seeks to reduce the false negative rates (FNRs) by obtaining the highest possible sensitivity. The recall score shown in Equation (1) indicates the sensitivity of the classifying model [
32].
Furthermore, it aims to increase the true negative rates (TNRs) by obtaining the highest possible specificity measured by Equation (2).
The precision value can measure the actual positive results; in other words, it measures the true positive rates (TPRs) among all projected positive results. Equation (3) represents the precision value [
33].
Precision and recall are both used to measure the F1 value. Equation (4) represents the F1 measure.
The percentage of accurately predicted events from all predicted events, whether positive or negative, is measured by accuracy value. Equation (5) represents the accuracy value [
33].
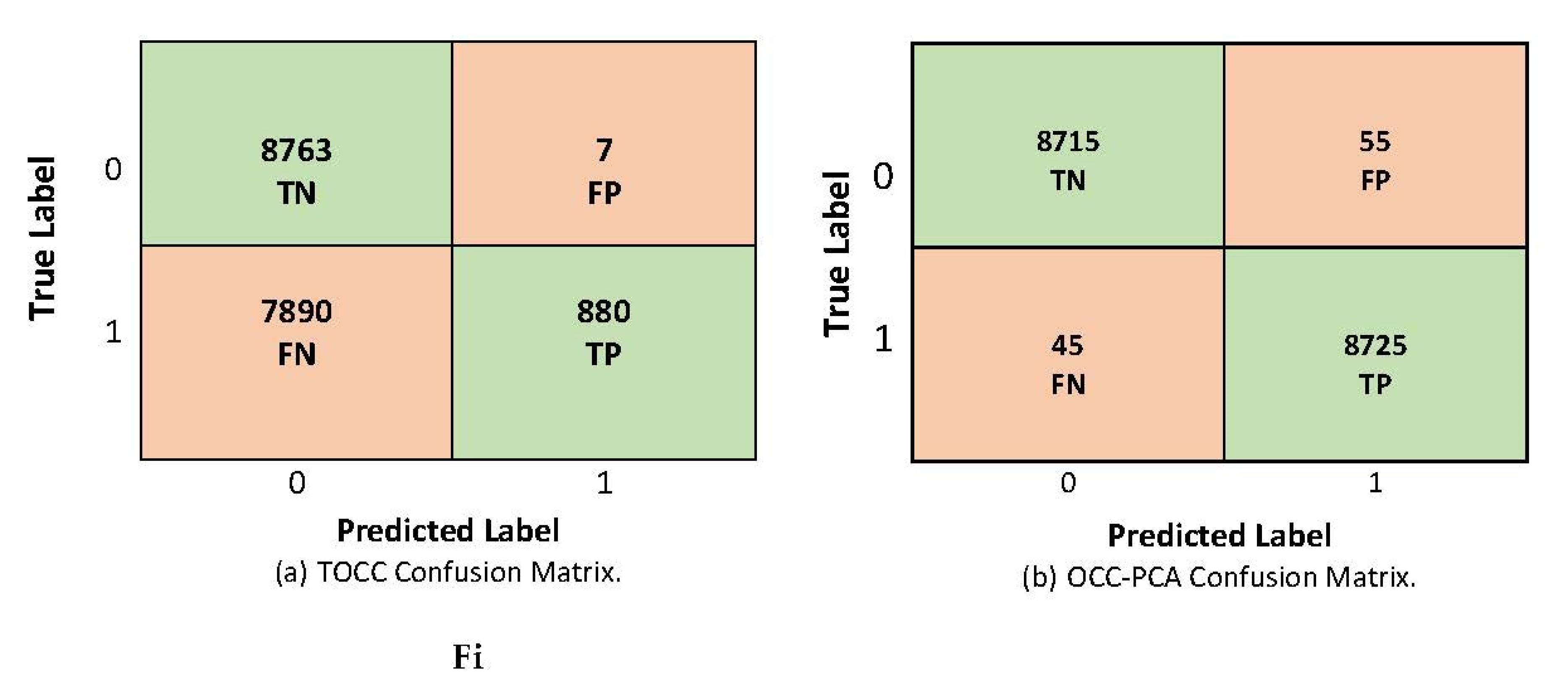
The findings of the evaluation phase, shown in
Figure 5a, reveal that the TOCC approach achieved 880 TP samples and 8763 TN samples, while there were seven FP and 7890 FN samples. The TOCC approach achieved high FN rates; consequently, it suffers low sensitivity (recall score of 55%). Furthermore, it achieves low specificity (TNR rate of 53%), as shown in
Table 5.
At the same time, the OCC-PCA approach achieved 8725 TP samples and 8715 TN samples, while there were 55 FP samples and 45 FN samples, as shown in
Figure 5b. With this model, the OCSVM could accurately predict normal and abnormal behavior. Utilizing the PCA enhanced the model performance results, as shown in
Table 5, and increased the sensitivity and specificity to 99% and 99.4%, respectively. Increasing the model sensitivity indicates its ability to detect any deviation of the target class, consequently increasing its ability to be generalized and to detect zero-day attacks.
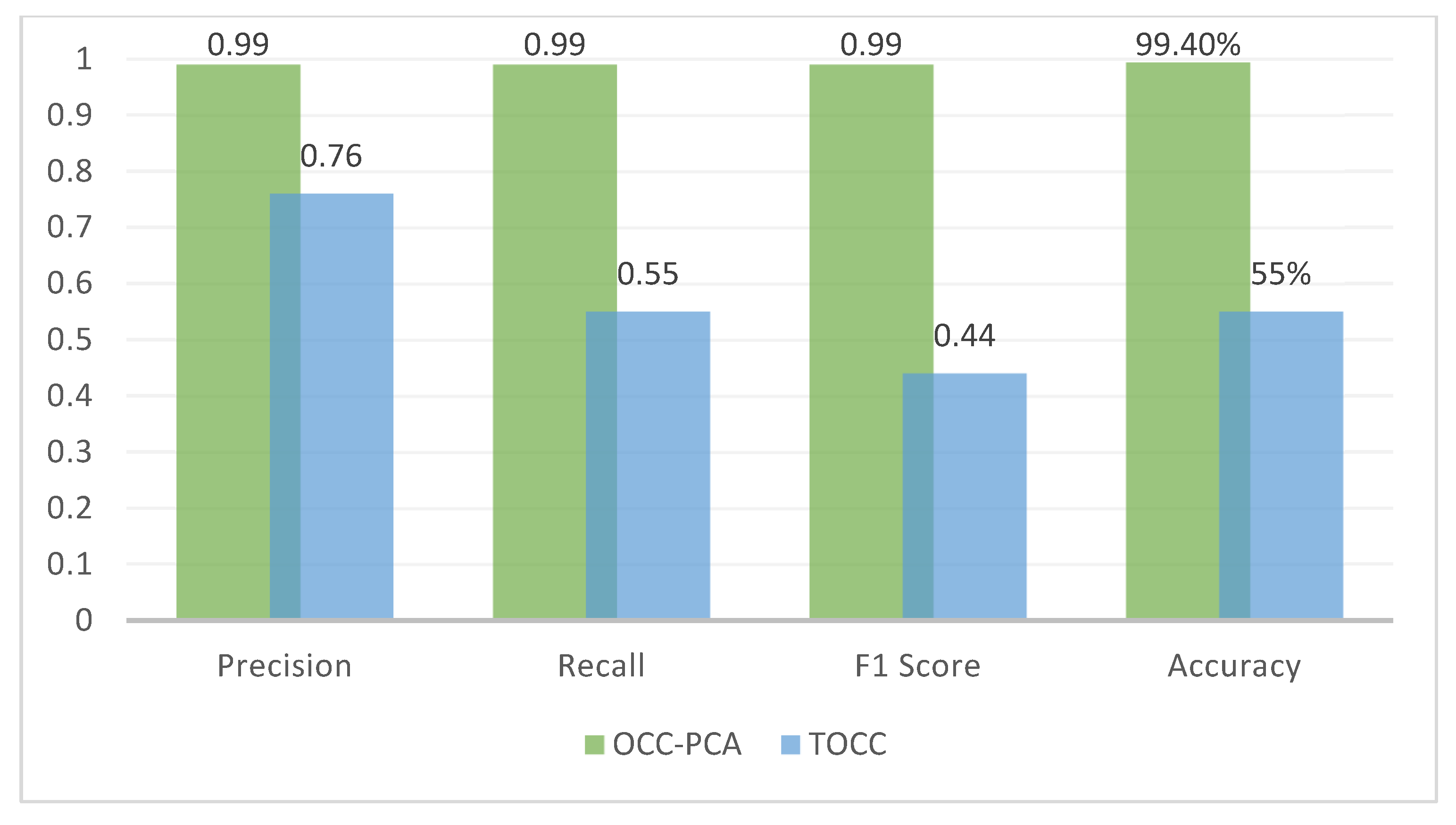
The performance matrices of the evaluation phase reveal that the OCC-PCA model achieved 99%, 99%, 99%, 99.4%, and 99.4% in precision, recall/sensitivity, F1, TNR/specificity, and accuracy, respectively.
In this model, the results illustrate that concentrating on significant features enhances the algorithm’s accuracy and predictability with respect to identifying benign behavior from malicious behavior. Apart from its accuracy, the algorithm’s sensitivity in identifying and detecting normal behaviors can be enhanced and developed using the PCA algorithm. On another side, the TOCC model achieved 76%, 55%, 44%, 53%, and 55% precision, recall/sensitivity, F1, TNR/specificity, and accuracy, respectively. These properties contain information that is not necessarily useful in the training and testing of the algorithm. As a result, the TOCC model demonstrates that the OCSVM algorithm interacts negatively when the number of features is significant. In contrast to the OCC-PCA model, which uses the PCA algorithm to remove unnecessary features, the OCSVM algorithm appears to affect the results in anticipating normal behaviors when improving those predictions and concentrating on the necessary traits.
In conclusion, the PCA excluded the redundant and irrelevant features and selected the most relevant ones that increased the model’s sensitivity and specificity. Moreover, memory malware usually suffers from high FP due to the inaccuracies caused by benign software bugs. The concept of merging the one-class classification with the PCA reduction techniques improved the model’s detection results and reduced the FPs.
Table 5 depicts the comparison between OCC-PCA and TOCC models. Noticeably, the TOCC approach consumed more time than the OCC-PCA in the testing phase.
The authors of [
17,
23] employed the PCA classifier; their findings were less than those in this study. That may be attributed to the chosen dataset’s unsuitability. Refs. [
26,
27] utilized different dimensionality reduction techniques and achieved lower results than the proposed model’s results. The dataset’s suitability to the chosen algorithm and the suitable number of extracted features are factors for a successful performance. Although [
16] achieved a better accuracy rate than the currently achieved rate, the proposed model is characterized by utilizing a modern dataset that keeps pace with modern attacks.
Table 6 compares the OCC-PCA model with other existing and published related work.
The hierarchical approach adopted in this study had a crucial role in the OCC-PCA model’s ability to achieve a greater accuracy rate. The OCC-PCA and TOCC models were chosen following training, testing, and comparing the accuracy results by implementing the OCSVM classifier to assess both models. The authors then modified the variables in the OCC-PCA model from n = 10 to n = 30 and reevaluated the model to see if the variable modification improved the model results. The suggested model was then compared to the models of earlier research. One further factor that enhanced the performance of the proposed model was that OCSVM could have a better accuracy rate when dataset features extracted automation via the PCA classifier and utilized current, balanced datasets with a high augmentation of pre-proccing datasets. The variation in the PCA algorithms used on various datasets in prior research and the diversity in the OCSVM algorithms used on various models, as described in
Table 1 and
Table 6, shows that the model we have presented may provide the best outcomes based on the findings.
As a result, the OCC-PCA approach and the nature of the OCSVM classifier in dealing with a low number of feature selections can be considered enhancements for detecting any attack. That can be seen as a mainly unknown attack or, using its other name, a zero-day attack. The accuracy rate of the OCC-PCA approach was achieved at 99.4%, and all performance matrices such as recall, precision, TPR, and F1 were achieved at 99%. Thus, PCA relies on eliminating all features that are not necessary and concentrating effort on the crucial features that produce more robust results, which helped us achieve better results. At the same time, the TOCC approach performed poorly, with an accuracy rate of 55%, and caused exceedingly low sensitivity to recognize normal behavior during the test phase. In the future, after detecting normal flow, we suggest stepping over to the next layer by determining what kind each attack is by utilizing multi-class classification in different datasets.
Figure 6 depicts the comparison between TOCC and OCC-PCA results.
6. Conclusions
This paper has developed a one-class classification (OCSVM) by integrating it with Principal Component Analysis (PCA), a dimensionality reduction technique. This integrated solution focuses on accurately detecting memory dump malware; even novel ones were considered. PCA was used to improve the sensitivity, specificity, and ability to generalize. To efficiently detect any deviation from the normal memory dump file patterns, the OCSVM classifier was utilized.
An intensive evaluation methodology was implemented based on a recently published dataset known as “MalMemAnalysis2022” to compare the performance of the standard OCSVM classifier with the proposed OSCVM with dimensionality reduction technique, PCA (OCC-PCA). The OCC-PCA model achieves a 99.4% accuracy rate, 99.3% TNR, and 99% for F1, recall, and precision scores, compared to the limited low performance of the standard model. Hence, an OCSVM classifier with a PCA classifier is recommended to identify benign behaviors.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}