
Mapping Topsoil Total Nitrogen Using Random Forest and Modified Regression Kriging in Agricultural Areas of Central China

 and
and
Abstract
:1. Introduction
2. Results
2.1. Descriptive Statistics of Soil Total Nitrogen Observations
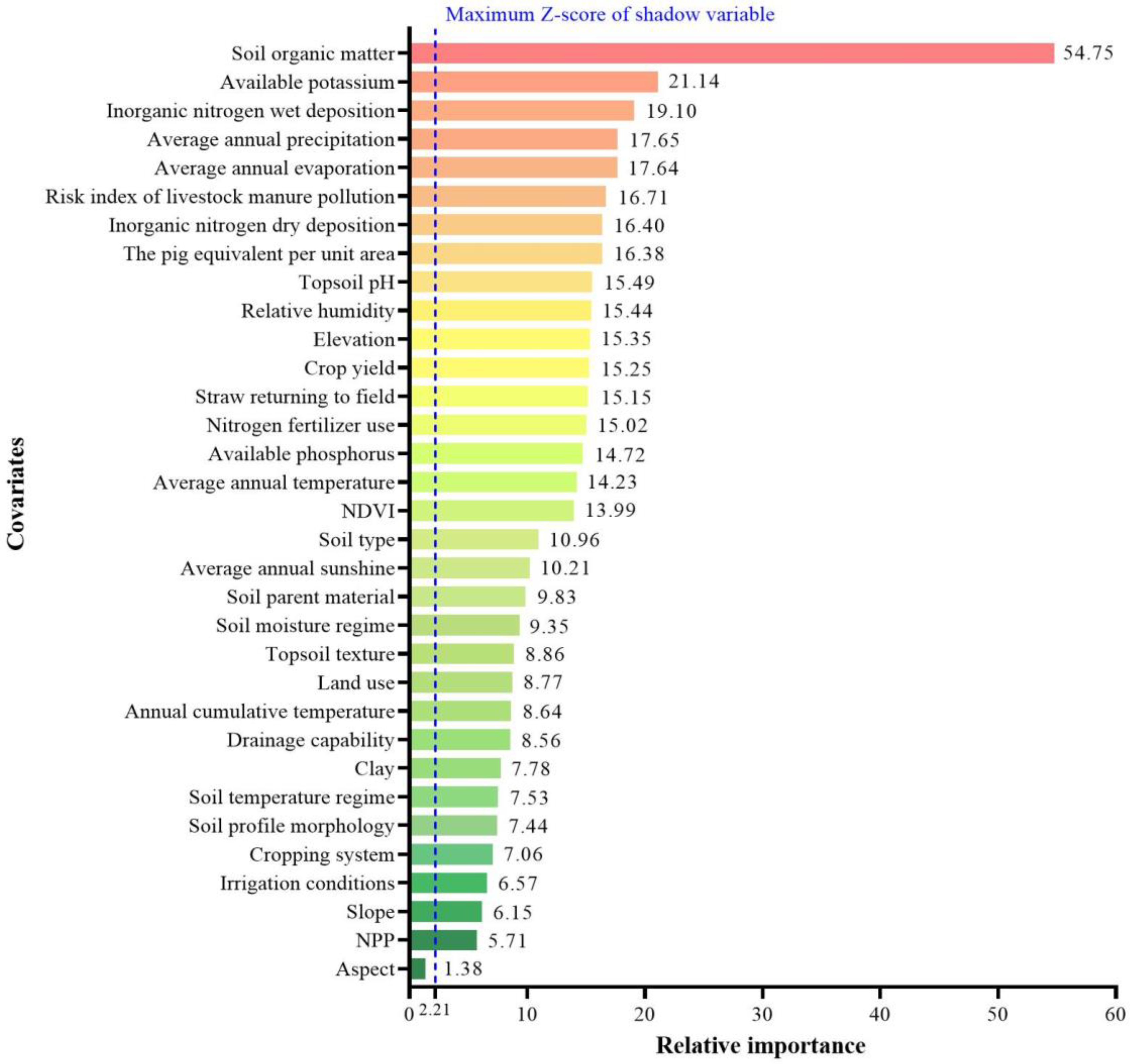
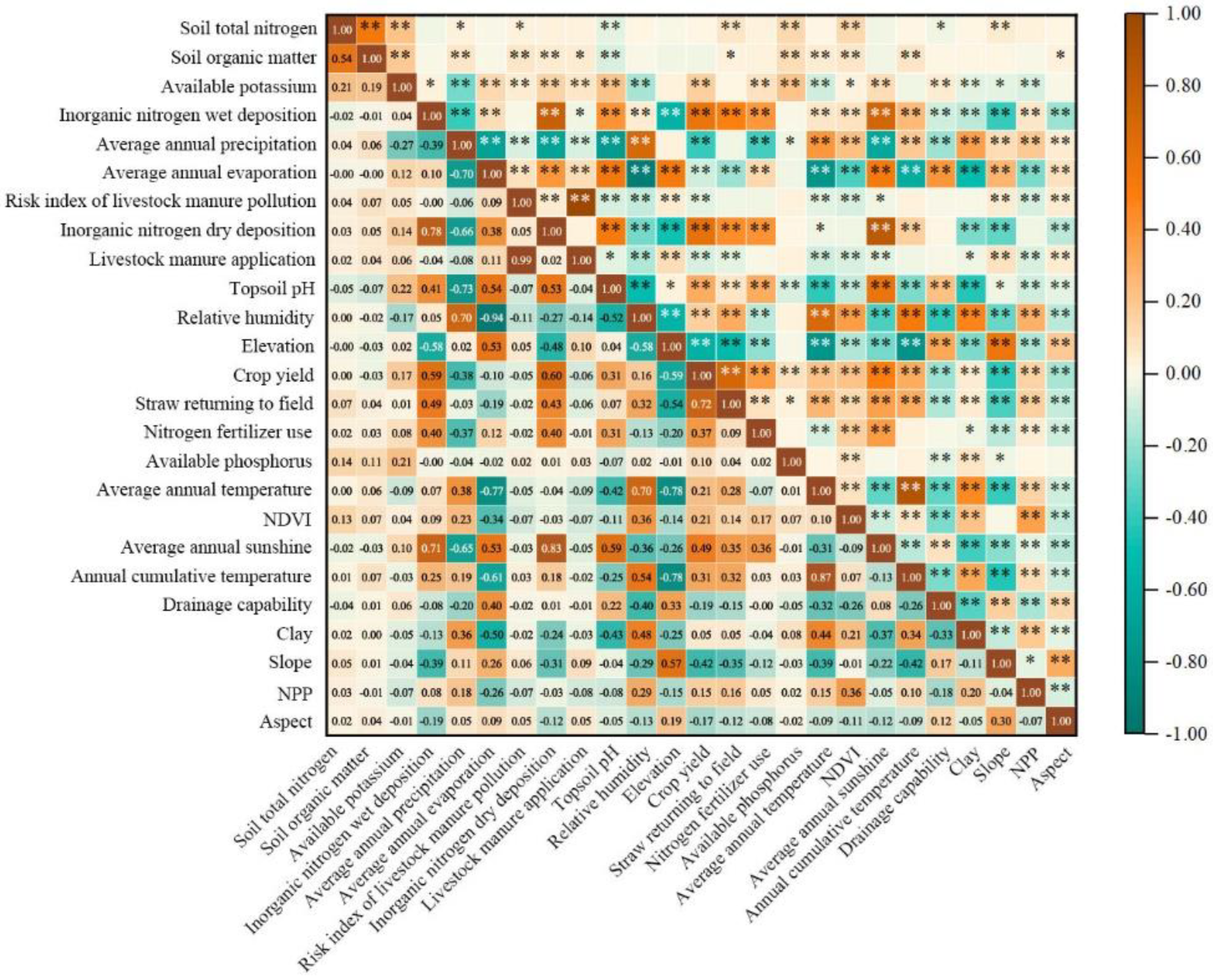
2.2. Relative Importance of Covariates
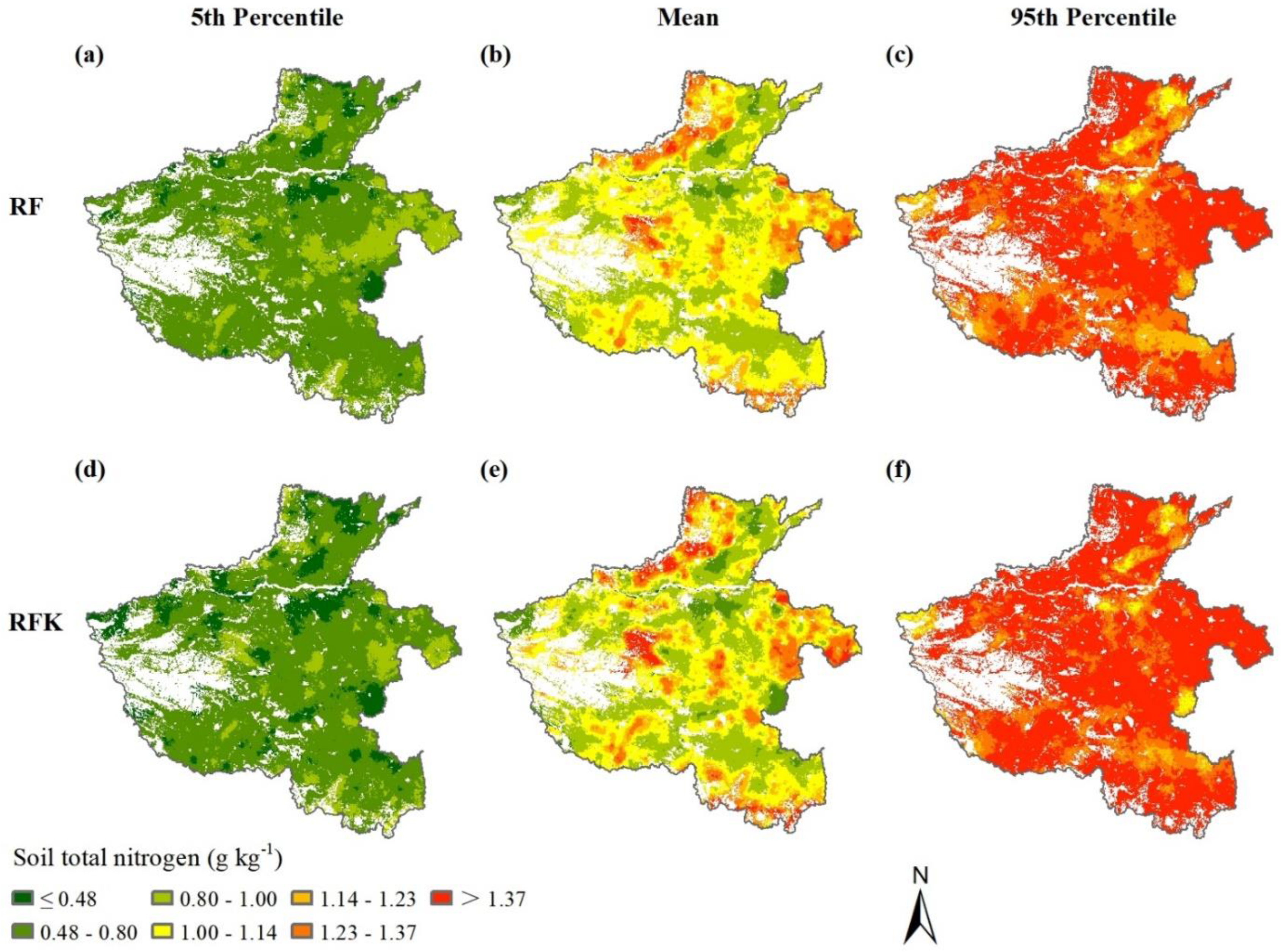
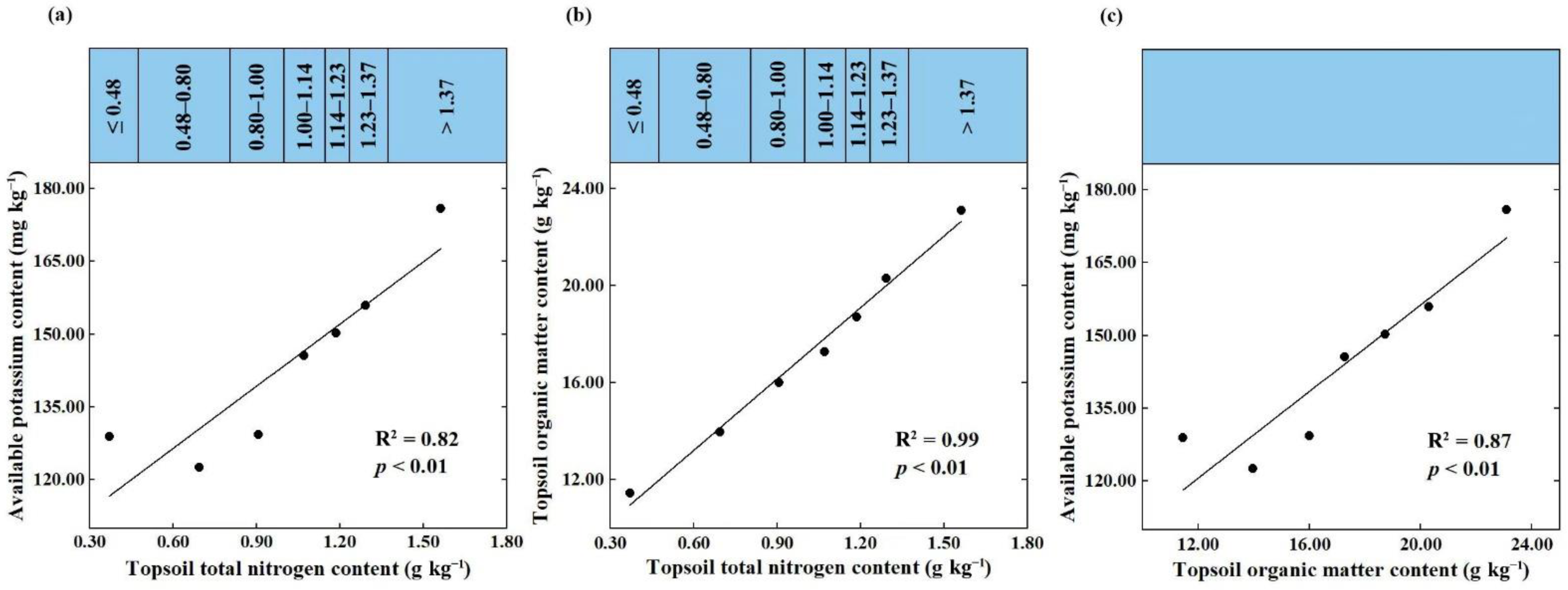
2.3. Spatial Distribution and Variability of Topsoil TN
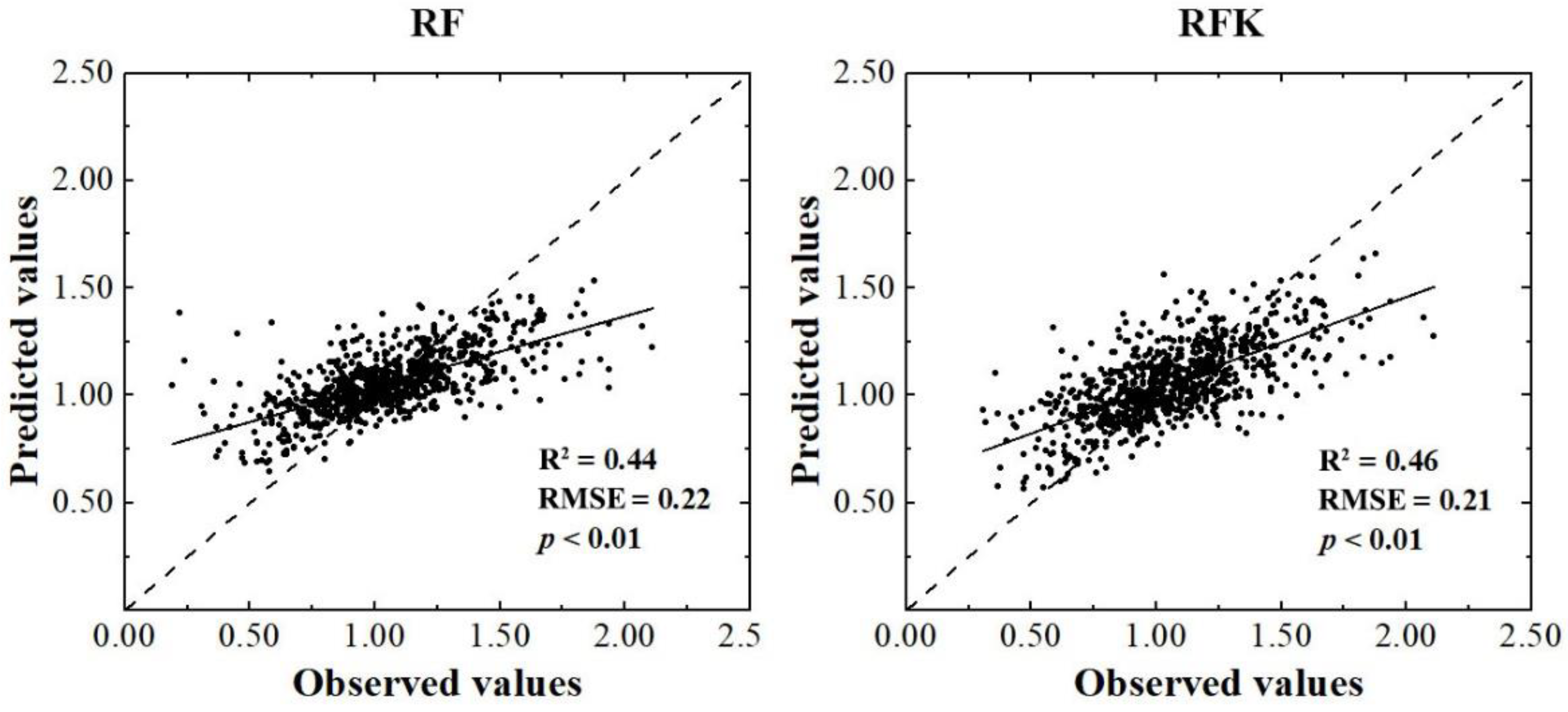
2.4. Comparison of Model Performance
3. Discussion
3.1. Covariate Contributions
3.2. Prediction Accuracy
3.3. Prediction Uncertainty
4. Materials and Methods
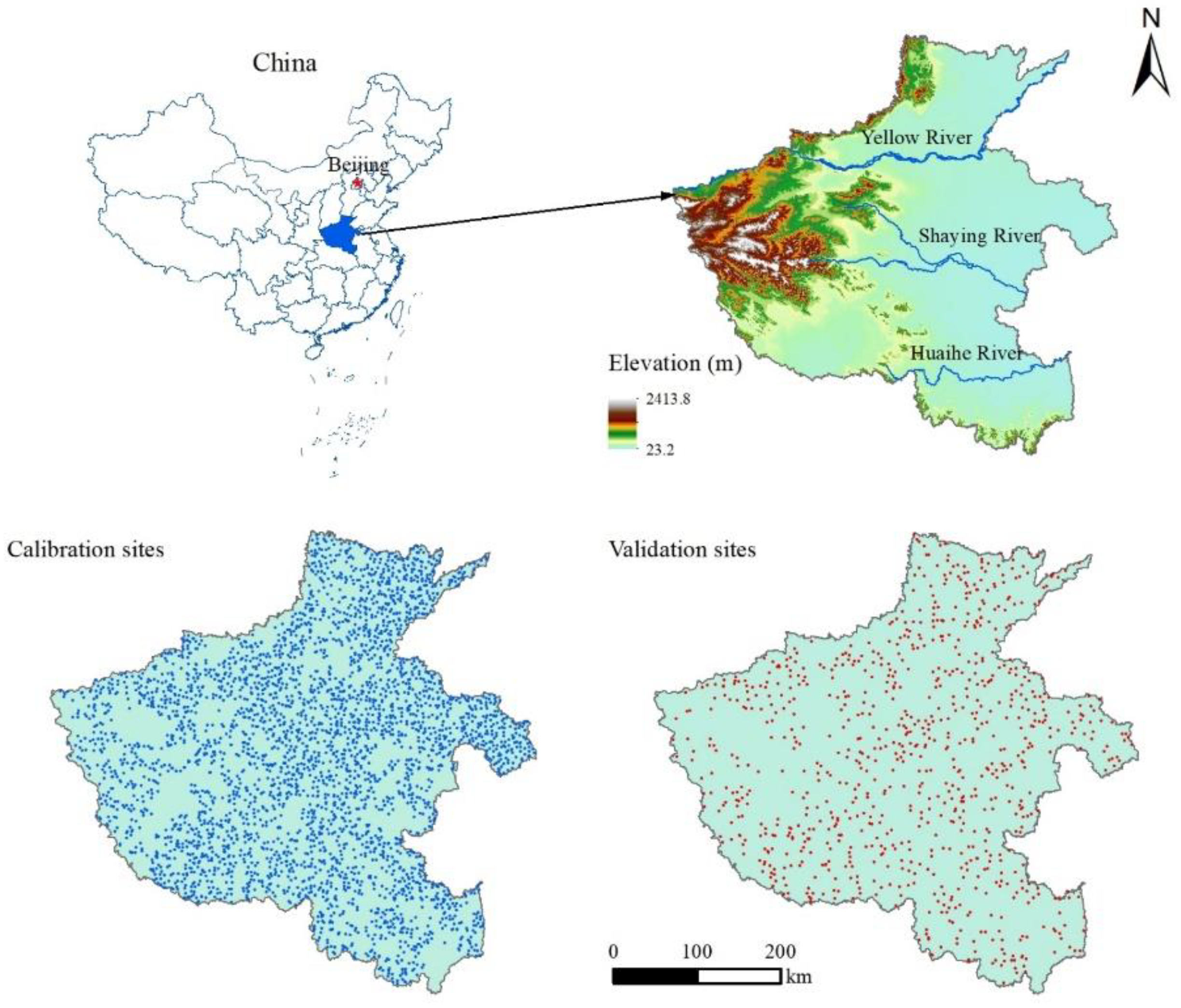
4.1. Study Area
4.2. Soil Sampling and Measurement
4.3. Covariates and Variable Selection
4.4. Predictive Models
4.5. Evaluation of Model Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bangroo, S.A.; Najar, G.R.; Achin, E.; Truong, P.N. Application of predictor variables in spatial quantification of soil organic carbon and total nitrogen using regression kriging in the North Kashmir forest Himalayas. Catena 2020, 193, 104632. [Google Scholar] [CrossRef]
- Zhang, H.; Shi, L.; Fu, S. Effects of nitrogen deposition and increased precipitation on soil phosphorus dynamics in a temperate forest. Geoderma 2020, 380, 114650. [Google Scholar] [CrossRef]
- Ma, J.; Cheng, J.; Wang, J.; Pan, R.; He, F.; Yan, L.; Xiao, J. Rapid detection of total nitrogen content in soil based on hyperspectral technology. Inf. Process. Agric. 2022, 9, 566–574. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, P.; Dai, S.; Han, Y. Analysis of non-point source nitrogen pollution in watersheds based on SWAT model. Ecol. Indic. 2022, 138, 108881. [Google Scholar] [CrossRef]
- Arabi, M.; Govindaraju, R.S.; Hantush, M.M.; Engel, B.A. Role of watershed subdivision on modeling the effectiveness of best management practices with SWAT. JAWRA J. Am. Water Resour. Assoc. 2006, 42, 513–528. [Google Scholar] [CrossRef]
- Guerrero, A.; De Neve, S.; Mouazen, A.M. Chapter One—Current sensor technologies for in situ and on-line measurement of soil nitrogen for variable rate fertilization: A review. In Advances in Agronomy; Sparks, D.L., Ed.; Academic Press: Cambridge, MA, USA, 2021; Volume 168, pp. 1–38. [Google Scholar]
- Li, J.; Chen, L.; Fu, B.; Zhang, S.; Li, G. Spatial and temporal variation characteristics of non-point source N in surface water in Yuqiao reservoir basin. J. Geosci. 2019, 22, 238–242. [Google Scholar]
- Liao, K.; Lv, L.; Lai, X.; Zhu, Q. Toward a framework for the multimodel ensemble prediction of soil nitrogen losses. Ecol. Model. 2021, 456, 109675. [Google Scholar] [CrossRef]
- Potarzycki, J. Effect of magnesium or zinc supplementation at the background of nitrogen rate on nitrogen management by maize canopy cultivated in monoculture. Plant Soil Environ. 2011, 57, 19–25. [Google Scholar] [CrossRef] [Green Version]
- Post, W.M.; Pastor, J.; Zinke, P.J.; Stangenberger, A.G. Global patterns of soil nitrogen storage. Nature 2021, 317, 613–616. [Google Scholar] [CrossRef]
- Komolafe, A.A.; Olorunfemi, I.E.; Oloruntoba, C.; Akinluyi, F.O. Spatial prediction of soil nutrients from soil, topography and environmental attributes in the northern part of Ekiti State, Nigeria. Remote Sens. Appl. Soc. Environ. 2021, 21, 100450. [Google Scholar] [CrossRef]
- Ma, D.; Zhang, H.; Song, X.; Xing, S.; Fan, M.; Heiling, M.; Liu, L.; Zhang, L.; Mao, Y. Estimating soil organic carbon and nitrogen stock based on high-resolution soil databases in a subtropical agricultural area of China. Soil Tillage Res. 2022, 219, 105321. [Google Scholar] [CrossRef]
- Zhang, Z.; Hao, M.; Li, Y.; Shao, Z.; Yu, Q.; He, Y.; Gao, P.; Xu, J.; Dun, X. Effects of vegetation and terrain changes on spatial heterogeneity of soil C–N–P in the coastal zone protected forests at northern China. J. Environ. Manag. 2022, 317, 115472. [Google Scholar] [CrossRef] [PubMed]
- Abebe, G.; Tsunekawa, A.; Haregeweyn, N.; Takeshi, T.; Wondie, M.; Adgo, E.; Masunaga, T.; Tsubo, M.; Ebabu, K.; Berihun, M.L.; et al. Effects of land use and topographic position on soil organic carbon and Total nitrogen stocks in different agro-ecosystems of the upper Blue Nile Basin. Sustainability 2020, 12, 2425. [Google Scholar] [CrossRef] [Green Version]
- Onwuka, B.; Mang, B. Effects of soil temperature on some soil properties and plant growth. Adv. Plants Agric. Res. 2018, 8, 34–37. [Google Scholar] [CrossRef]
- Dai, L.; Ge, J.; Wang, L.; Zhang, Q.; Liang, T.; Bolan, N.; Lischeid, G.; Rinklebe, J. Influence of soil properties, topography, and land cover on soil organic carbon and total nitrogen concentration: A case study in Qinghai-Tibet plateau based on random forest regression and structural equation modeling. Sci. Total Environ. 2022, 821, 153440. [Google Scholar] [CrossRef]
- Sadayappan, K.; Kerins, D.; Shen, C.; Li, L. Nitrate concentrations predominantly driven by human, climate, and soil properties in US rivers. Water Res. 2022, 226, 119295. [Google Scholar] [CrossRef]
- Wang, Y.; Xiao, Z.; Aurangzeib, M.; Zhang, X.; Zhang, S. Effects of freeze-thaw cycles on the spatial distribution of soil total nitrogen using a geographically weighted regression kriging method. Sci. Total Environ. 2021, 763, 142993. [Google Scholar] [CrossRef]
- Zhou, T.; Geng, Y.; Chen, J.; Pan, J.; Haase, D.; Lausch, A. High-resolution digital mapping of soil organic carbon and soil total nitrogen using DEM derivatives, Sentinel-1 and Sentinel-2 data based on machine learning algorithms. Sci. Total Environ. 2020, 729, 138244. [Google Scholar] [CrossRef]
- Mulder, V.L.; de Bruin, S.; Schaepman, M.E.; Mayr, T.R. The use of remote sensing in soil and terrain mapping—A review. Geoderma 2011, 162, 1–19. [Google Scholar] [CrossRef]
- Kalambukattu, J.G.; Kumar, S.; Raj, R.A. Digital soil mapping in a Himalayan watershed using remote sensing and terrain parameters employing artificial neural network model. Environ. Earth Sci. 2018, 77, 203.201–203.214. [Google Scholar] [CrossRef]
- Arrouays, D.; Poggio, L.; Salazar Guerrero, O.A.; Mulder, V.L. Digital soil mapping and GlobalSoilMap. Main advances and ways forward. Geoderma Reg. 2020, 21, e00265. [Google Scholar] [CrossRef]
- Padarian, J.; Minasny, B.; Mcbratney, A.B. Using deep learning for digital soil mapping. Soil 2019, 5, 79–89. [Google Scholar] [CrossRef] [Green Version]
- Zeraatpisheh, M.; Jafari, A.; Bagheri Bodaghabadi, M.; Ayoubi, S.; Taghizadeh-Mehrjardi, R.; Toomanian, N.; Kerry, R.; Xu, M. Conventional and digital soil mapping in Iran: Past, present, and future. Catena 2020, 188, 104424. [Google Scholar] [CrossRef]
- Heung, B.; Ho, H.C.; Zhang, J.; Knudby, A.; Bulmer, C.E.; Schmidt, M.G. An overview and comparison of machine-learning techniques for classification purposes in digital soil mapping. Geoderma 2016, 265, 62–77. [Google Scholar] [CrossRef]
- Keskin, H.; Grunwald, S. Regression kriging as a workhorse in the digital soil mapper’s toolbox. Geoderma 2018, 326, 22–41. [Google Scholar] [CrossRef]
- Mirchooli, F.; Kiani-Harchegani, M.; Khaledi Darvishan, A.; Falahatkar, S.; Sadeghi, S.H. Spatial distribution dependency of soil organic carbon content to important environmental variables. Ecol. Indic. 2020, 116, 106473. [Google Scholar] [CrossRef]
- Tajik, S.; Ayoubi, S.; Zeraatpisheh, M. Digital mapping of soil organic carbon using ensemble learning model in Mollisols of Hyrcanian forests, northern Iran. Geoderma Reg. 2020, 20, e00256. [Google Scholar] [CrossRef]
- Gomes, L.C.; Faria, R.M.; de Souza, E.; Veloso, G.V.; Schaefer, C.E.G.R.; Filho, E.I.F. Modelling and mapping soil organic carbon stocks in Brazil. Geoderma 2019, 340, 337–350. [Google Scholar] [CrossRef]
- Hengl, T.; Heuvelink, G.B.; Kempen, B.; Leenaars, J.G.; Walsh, M.G.; Shepherd, K.D.; Sila, A.; MacMillan, R.A.; Mendes de Jesus, J.; Tamene, L. Mapping soil properties of Africa at 250 m resolution: Random forests significantly improve current predictions. PLoS ONE 2015, 10, e0125814. [Google Scholar] [CrossRef]
- Khaledian, Y.; Miller, B.A. Selecting appropriate machine learning methods for digital soil mapping. Appl. Math. Model. 2020, 81, 401–418. [Google Scholar] [CrossRef]
- Silatsa, F.B.T.; Yemefack, M.; Tabi, F.O.; Heuvelink, G.B.M.; Leenaars, J.G.B. Assessing countrywide soil organic carbon stock using hybrid machine learning modelling and legacy soil data in Cameroon. Geoderma 2020, 367, 114260. [Google Scholar] [CrossRef]
- Wang, S.; Jin, X.; Adhikari, K.; Li, W.; Yu, M.; Bian, Z.; Wang, Q. Mapping total soil nitrogen from a site in northeastern China. Catena 2018, 166, 134–146. [Google Scholar] [CrossRef]
- Keskin, H.; Grunwald, S.; Harris, W.G. Digital mapping of soil carbon fractions with machine learning. Geoderma 2019, 339, 40–58. [Google Scholar] [CrossRef]
- Odeh, I.O.A.; McBratney, A.B.; Chittleborough, D.J. Further results on prediction of soil properties from terrain attributes: Heterotopic cokriging and regression-kriging. Geoderma 1995, 67, 215–226. [Google Scholar] [CrossRef]
- Szatmári, G.; Pirkó, B.; Koós, S.; Laborczi, A.; Bakacsi, Z.; Szabó, J.; Pásztor, L. Spatio-temporal assessment of topsoil organic carbon stock change in Hungary. Soil Tillage Res. 2019, 195, 104410. [Google Scholar] [CrossRef]
- Takoutsing, B.; Heuvelink, G.B.M. Comparing the prediction performance, uncertainty quantification and extrapolation potential of regression kriging and random forest while accounting for soil measurement errors. Geoderma 2022, 428, 116192. [Google Scholar] [CrossRef]
- Pouladi, N.; Møller, A.B.; Tabatabai, S.; Greve, M.H. Mapping soil organic matter contents at field level with Cubist, Random Forest and kriging. Geoderma 2019, 342, 85–92. [Google Scholar] [CrossRef]
- Rial, M.; Martínez Cortizas, A.; Rodríguez-Lado, L. Understanding the spatial distribution of factors controlling topsoil organic carbon content in European soils. Sci. Total Environ. 2017, 609, 1411–1422. [Google Scholar] [CrossRef]
- Vaysse, K.; Lagacherie, P. Using quantile regression forest to estimate uncertainty of digital soil mapping products. Geoderma 2017, 291, 55–64. [Google Scholar] [CrossRef]
- Boubehziz, S.; Khanchoul, K.; Benslama, M.; Benslama, A.; Marchetti, A.; Francaviglia, R.; Piccini, C. Predictive mapping of soil organic carbon in Northeast Algeria. Catena 2020, 190, 104539. [Google Scholar] [CrossRef]
- Sindayihebura, A.; Ottoy, S.; Dondeyne, S.; Van Meirvenne, M.; Van Orshoven, J. Comparing digital soil mapping techniques for organic carbon and clay content: Case study in Burundi’s central plateaus. Catena 2017, 156, 161–175. [Google Scholar] [CrossRef]
- Xu, Y.; Smith, S.E.; Grunwald, S.; Abd-Elrahman, A.; Wani, S.P.; Nair, V.D. Estimating soil total nitrogen in smallholder farm settings using remote sensing spectral indices and regression kriging. Catena 2018, 163, 111–122. [Google Scholar] [CrossRef] [Green Version]
- Arrouays, D.; Grundy, M.G.; Hartemink, A.E.; Hempel, J.W.; Heuvelink, G.B.M.; Hong, S.Y.; Lagacherie, P.; Lelyk, G.; McBratney, A.B.; McKenzie, N.J.; et al. Chapter Three—GlobalSoilMap: Toward a Fine-Resolution Global Grid of Soil Properties. In Advances in Agronomy; Sparks, D.L., Ed.; Academic Press: Cambridge, MA, USA, 2014; Volume 125, pp. 93–134. [Google Scholar]
- Malone, B.P.; McBratney, A.B.; Minasny, B. Empirical estimates of uncertainty for mapping continuous depth functions of soil attributes. Geoderma 2011, 160, 614–626. [Google Scholar] [CrossRef]
- Deng, X.; Chen, X.; Ma, W.; Ren, Z.; Zhang, M.; Grieneisen, M.L.; Long, W.; Ni, Z.; Zhan, Y.; Lv, X. Baseline map of organic carbon stock in farmland topsoil in East China. Agric. Ecosyst. Environ. 2018, 254, 213–223. [Google Scholar] [CrossRef]
- Deng, X.; Ma, W.; Ren, Z.; Zhang, M.; Grieneisen, M.L.; Chen, X.; Fei, X.; Qin, F.; Zhan, Y.; Lv, X. Spatial and temporal trends of soil total nitrogen and C/N ratio for croplands of East China. Geoderma 2020, 361, 114035. [Google Scholar] [CrossRef]
- Li, X.; Shang, B.; Wang, D.; Wang, Z.; Wen, X.; Kang, Y. Mapping soil organic carbon and total nitrogen in croplands of the Corn Belt of Northeast China based on geographically weighted regression kriging model. Comput. Geosci. 2020, 135, 104392. [Google Scholar] [CrossRef]
- Wang, S.; Zhuang, Q.; Wang, Q.; Jin, X.; Han, C. Mapping stocks of soil organic carbon and soil total nitrogen in Liaoning Province of China. Geoderma 2017, 305, 250–263. [Google Scholar] [CrossRef]
- Wang, S.; Adhikari, K.; Wang, Q.; Jin, X.; Li, H. Role of environmental variables in the spatial distribution of soil carbon (C), nitrogen (N), and C:N ratio from the northeastern coastal agroecosystems in China. Ecol. Indic. 2018, 84, 263–272. [Google Scholar] [CrossRef]
- Aula, L.; Macnack, N.; Omara, P.; Mullock, J.; Raun, W. Effect of Fertilizer Nitrogen (N) on Soil Organic Carbon, Total N, and Soil pH in Long-Term Continuous Winter Wheat (Triticum Aestivum L.). Commun. Soil Sci. Plant Anal. 2016, 47, 863–874. [Google Scholar] [CrossRef]
- Sun, X.-L.; Minasny, B.; Wu, Y.-J.; Wang, H.-L.; Fan, X.-H.; Zhang, G.-L. Soil organic carbon content increase in the east and south of China is accompanied by soil acidification. Sci. Total Environ. 2023, 857, 159253. [Google Scholar] [CrossRef]
- Wu, Z.; Sun, X.; Sun, Y.; Yan, J.; Zhao, Y.; Chen, J. Soil acidification and factors controlling topsoil pH shift of cropland in central China from 2008 to 2018. Geoderma 2022, 408, 115586. [Google Scholar] [CrossRef]
- Zhang, X.; Guo, J.; Vogt, R.D.; Mulder, J.; Wang, Y.; Qian, C.; Wang, J.; Zhang, X. Soil acidification as an additional driver to organic carbon accumulation in major Chinese croplands. Geoderma 2020, 366, 114234. [Google Scholar] [CrossRef]
- Liu, Y.; Gao, P.; Zhang, L.Y.; Niu, X.; Wang, B. Spatial heterogeneity distribution of soil total nitrogen and total phosphorus in the Yaoxiang watershed in a hilly area of northern China based on geographic information system and geostatistics. Ecol. Evol. 2016, 6, 6807–6816. [Google Scholar] [CrossRef] [PubMed]
- Wadoux, A.M.J.C. Using deep learning for multivariate mapping of soil with quantified uncertainty. Geoderma 2019, 351, 59–70. [Google Scholar] [CrossRef] [Green Version]
- Costa, E.M.; Tassinari, W.d.S.; Pinheiro, H.S.K.; Beutler, S.J.; dos Anjos, L.H.C. Mapping Soil Organic Carbon and Organic Matter Fractions by Geographically Weighted Regression. J. Environ. Qual. 2018, 47, 718–725. [Google Scholar] [CrossRef]
- Wang, K.; Zhang, C.; Li, W. Predictive mapping of soil total nitrogen at a regional scale: A comparison between geographically weighted regression and cokriging. Appl. Geogr. 2013, 42, 73–85. [Google Scholar] [CrossRef]
- Zhu, Q.; Lin, H.S. Comparing Ordinary Kriging and Regression Kriging for Soil Properties in Contrasting Landscapes. Pedosphere 2010, 20, 594–606. [Google Scholar] [CrossRef]
- Kuhn, M.; Wing, J.; Weston, S.; Williams, A.; Keefer, C.; Engelhardt, A.; Cooper, T.; Mayer, Z.; Kenkel, B.; Team, R.C. Package ‘caret’. R J. 2020, 223. [Google Scholar]
- Team, R.C. A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020; Available online: http://www.R-project.Org (accessed on 28 November 2022).
- Xiong, X.; Grunwald, S.; Myers, D.B.; Kim, J.; Harris, W.G.; Comerford, N.B. Holistic environmental soil-landscape modeling of soil organic carbon. Environ. Model. Softw. 2014, 57, 202–215. [Google Scholar] [CrossRef]
- Kursa, M.B.; Rudnicki, W.R. Feature Selection with the Boruta Package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Biau, G.; Scornet, E. A random forest guided tour. TEST 2016, 25, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Lopes, M.E. Estimating the algorithmic variance of randomized ensembles via the bootstrap. Ann. Stat. 2019, 47, 1025+1088–1112. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Package ‘randomForest’: Breiman and Cutler’s Random Forests for Classification and Regression; CRAN Software: Whitehouse Station, NJ, USA, 2018. [Google Scholar]
- Mitran, T.; Mishra, U.; Lal, R.; Ravisankar, T.; Sreenivas, K. Spatial distribution of soil carbon stocks in a semi-arid region of India. Geoderma Reg. 2018, 15, e00192. [Google Scholar] [CrossRef]
- Meinshausen, N. Quantile regression forests. J. Mach. Learn. Res. 2006, 7, 983–999. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Simple Size (n) | Mean (g kg−1) | Maximum (g kg−1) | Minimum (g kg−1) | SD 1 (g kg−1) | CV 2 (%) | Kurtosis | Skewness | |
|---|---|---|---|---|---|---|---|---|
| Entire set | 4337 | 1.06 | 2.11 | 0.16 | 0.28 | 27.00 | 0.64 | 0.36 |
| Calibration set | 3470 | 1.06 | 2.09 | 0.16 | 0.28 | 27.00 | 0.63 | 0.36 |
| Validation set | 867 | 1.06 | 2.11 | 0.19 | 0.28 | 27.00 | 0.69 | 0.34 |
| Variogram | Model | Nugget | Sill | Nugget/Sill (%) | R2 | RSS 1 | Range (km) |
|---|---|---|---|---|---|---|---|
| RF residuals | Exponential | 0.0018 | 0.0447 | 4.02 | 0.345 | 9.325 × 10−4 | 2670 |
| Inside | Outside | ||
|---|---|---|---|
| <5% | >95% | ||
| RF | 92.40 | 3.60 | 4.00 |
| RFK | 98.21 | 0.49 | 1.30 |
| Categories | Covariates | Data Source | Resolution/Scale |
|---|---|---|---|
| Nitrogen sources | Nitrogen fertilizer use | Field investigation during the soil sampling campaign | 30 m |
| Nitrogen wet deposition | National Science and Technology Infrastructure (http://rs.cern.ac.cn/index.jsp) | 1000 m | |
| Nitrogen dry deposition | National Science and Technology Infrastructure (http://rs.cern.ac.cn/index.jsp) | 10,000 m | |
| The pig equivalent per unit area | Field investigation during the soil sampling campaign | 30 m | |
| Straw returning to field | Field investigation during the soil sampling campaign | 30 m | |
| Soil properties | Soil organic matter Available phosphorus | Henan Provincial Database for Cropland Quality Evaluation Henan Provincial Database for Cropland Quality Evaluation | 1:200,000 1:200,000 |
| Available potassium | Henan Provincial Database for Cropland Quality Evaluation | 1:200,000 | |
| Topsoil pH | Henan Provincial Database for Cropland Quality Evaluation | 1:200,000 | |
| Soil type | Henan Provincial Database for Cropland Quality Evaluation | 1:200,000 | |
| Soil parent material | Henan Provincial Database for Cropland Quality Evaluation | 1:200,000 | |
| Soil profile morphology | Henan Provincial Database for Cropland Quality Evaluation | 1:200,000 | |
| Topsoil texture | Henan Provincial Database for Cropland Quality Evaluation | 1:200,000 | |
| Soil temperature regime | Soil Series of China, Volume Henan, 2019 | 1:200,000 | |
| Soil moisture regime | Soil Series of China, Volume Henan, 2019 | 1:200,000 | |
| Clay content | Henan Provincial Database for Cropland Quality Evaluation | 1:200,000 | |
| Terrain attributes | Elevation | ASTER GDEM V3 30 m DEM (http://www.tuxingis.com/resource/aster_v3.html) | 30 m |
| Slope | Derived from ASTER GDEM V3 30 m DEM | 30 m | |
| Aspect | Derived from ASTER GDEM V3 30 m DEM | 30 m | |
| Climate characteristics | Average annual temperature | National Meteorological Science Data Center (https://data.cma.cn/data/cdcdetail/dataCode/A.0012.0001.S011.html) | 30 m |
| Average annual precipitation | National Meteorological Science Data Center (https://data.cma.cn/data/cdcdetail/dataCode/A.0012.0001.S011.html) | 30 m | |
| Average annual evaporation | National Meteorological Science Data Center (https://data.cma.cn/data/cdcdetail/dataCode/A.0012.0001.S011.html) | 30 m | |
| Relative humidity | National Meteorological Science Data Center (https://data.cma.cn/data/cdcdetail/dataCode/A.0012.0001.S011.html) | 30 m | |
| Average annual sunshine | National Meteorological Science Data Center (https://data.cma.cn/data/cdcdetail/dataCode/A.0012.0001.S011.html) | 30 m | |
| Annual cumulative temperature | National Meteorological Science Data Center (https://data.cma.cn/data/cdcdetail/dataCode/A.0012.0001.S011.html) | 30 m | |
| Organism features | NDVI | China Resource and Environmental Science and Data Centre (http://www.resdc.cn.) | 1000 m |
| NPP | China Resource and Environmental Science and Data Centre (http://www.resdc.cn.) | 1000 m | |
| Crop yield | Henan Provincial Database for Cropland Quality Evaluation | 1:200,000 | |
| Management practices | Land use | Henan Provincial Database for Cropland Quality Evaluation | 1:200,000 |
| Cropping system | Henan Provincial Database for Cropland Quality Evaluation | 1:200,000 | |
| Irrigation condition | Henan Provincial Database for Cropland Quality Evaluation | 1:200,000 | |
| Drainage capability | Henan Provincial Database for Cropland Quality Evaluation | 1:200,000 | |
| Risk index of livestock manure pollution | Field investigation during the soil sampling campaign | 30 m |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Wu, Z.; Sun, X.; Yan, J.; Sun, Y.; Liu, P.; Chen, J. Mapping Topsoil Total Nitrogen Using Random Forest and Modified Regression Kriging in Agricultural Areas of Central China. Plants 2023, 12, 1464. https://doi.org/10.3390/plants12071464
Zhang L, Wu Z, Sun X, Yan J, Sun Y, Liu P, Chen J. Mapping Topsoil Total Nitrogen Using Random Forest and Modified Regression Kriging in Agricultural Areas of Central China. Plants. 2023; 12(7):1464. https://doi.org/10.3390/plants12071464
Chicago/Turabian StyleZhang, Liyuan, Zhenfu Wu, Xiaomei Sun, Junying Yan, Yueqi Sun, Peijia Liu, and Jie Chen. 2023. "Mapping Topsoil Total Nitrogen Using Random Forest and Modified Regression Kriging in Agricultural Areas of Central China" Plants 12, no. 7: 1464. https://doi.org/10.3390/plants12071464