
A Management Method of Multi-Granularity Dimensions for Spatiotemporal Data
 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Dimension
2.1.1. Dimension Granularity
2.1.2. Dimension Granularity Fuzziness
Point
Segment
2.2. DGFQM
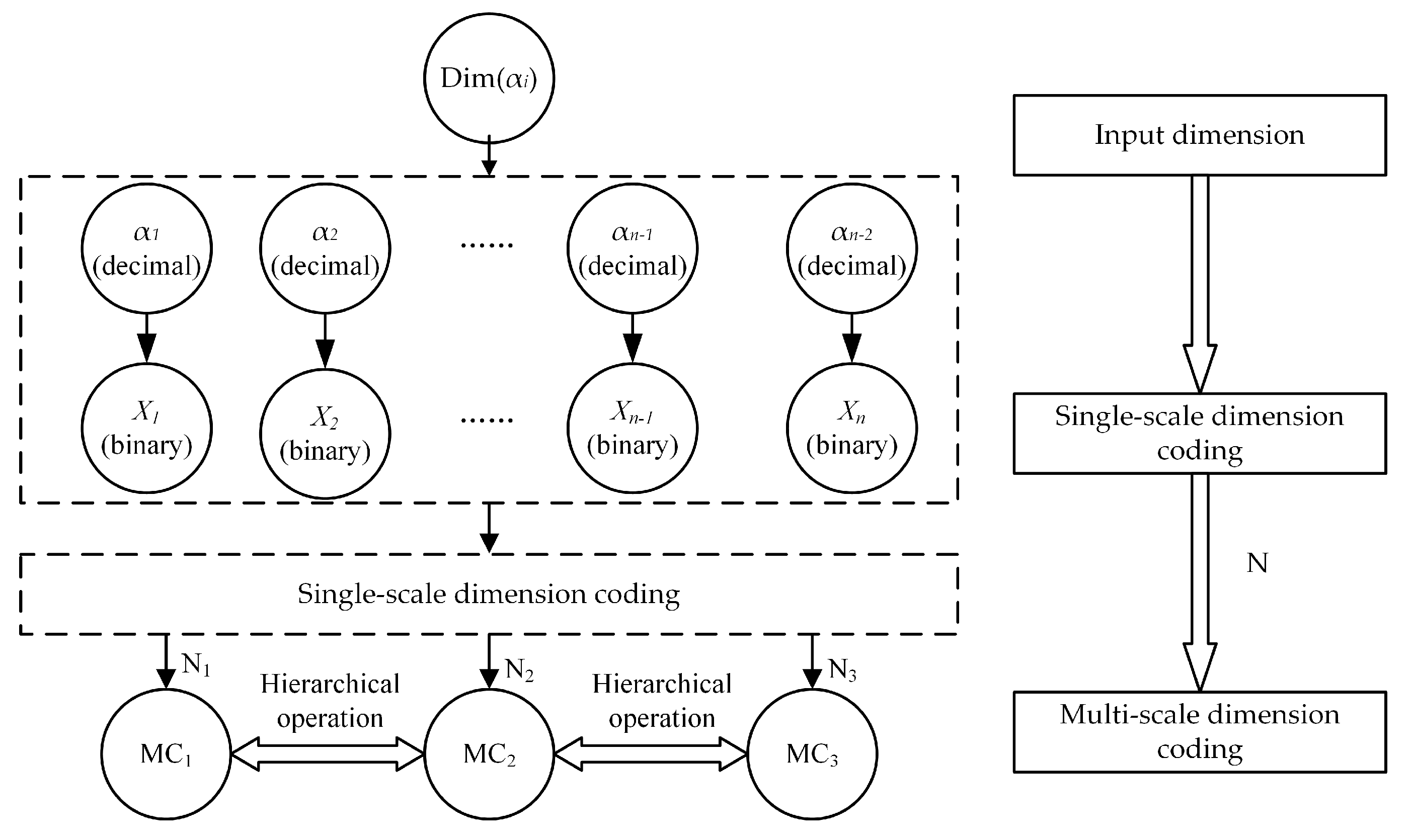
2.3. Dimension Coding Method
2.3.1. Multi-Scale Band Integer Coding
- The range of l8-pm is 0–1000, represented by a 10-bit binary, where 1000–1023 is a null value;
- The range of l7-nm is 0–1000, represented by a 10-bit binary number, where 1000–1023 is null;
- The range of l6-μm is 0–1000, represented by a 10-bit binary number, where 1000–1023 is null;
- The range of l5-mm is 0–10, represented by a 4-bit binary number, where 10–16 is null;
- The range of l4-cm is 0–1000, represented by a 4-bit binary number, where 10–16 is null;
- The range of l3-dm is 0–1000, represented by a 4-bit binary number, where 10–16 is null;
- The range of l2-m is 0–1000, represented by a 10-bit binary number, where 10–16 is null;
- l1-km is represented by a 12-bit binary number.
- Single-scale band integer coding calculation: SC is calculated according to Formula (7);
- 2.
- Multi-scale band integer coding calculation: according to Formulas (8)–(10), the multi-scale band integer coding mc is obtained by using the level N;
2.3.2. MBIC Related Operations
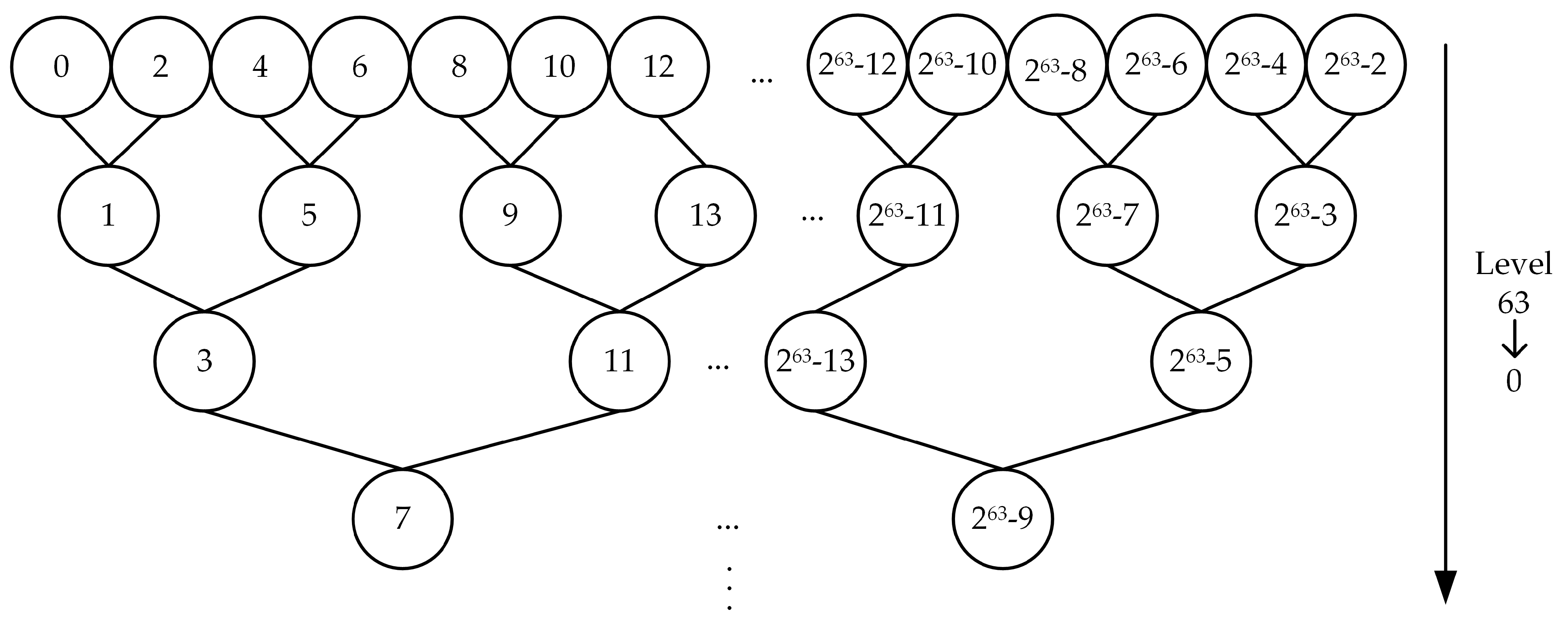
Level Calculation
- If MC is an even number, its level N is 63;
- If MC is an odd number, first, calculate how much the high-order bits in front of the binary of MC − 1 and MC + 1 are the same, i.e., Mid = (MC − 1) ^ (MC + 1). Secondly, the level is calculated by calculating how many consecutive zeros are on the left side of the binary of Mid. MBIC is represented by a 64-bit integer and can use the bifurcation method to efficiently obtain level information. The branch method judges how many 0 are on the left of the 64-bit integer according to the method of dichotomy.
Level Relationship Calculation
- Child coding set: Given a multi-scale band integer encoding MC, the corresponding level is N. The integer encoding MC′ of the calculated level N′ () is the child coding set. Let the interval of the child coding set be [C1, C2], where C1, C2 are calculated as Formulas (11) and (12):
- 2.
- Parent coding set: Let the MC level be N, and the parent encoding level is N′. The integer MC′ of the calculated level N′ () is the parent coding set. According to Formulas (13) and (14), the parent coding set of MC is obtained from N − 1 to 0 through loop variable N′:
2.3.3. The Association Method between MBIC and Band
- Rule 1: The maximum level Nmax of MBIC is not larger than the maximum level Nmax′ of the start and end point of the band.
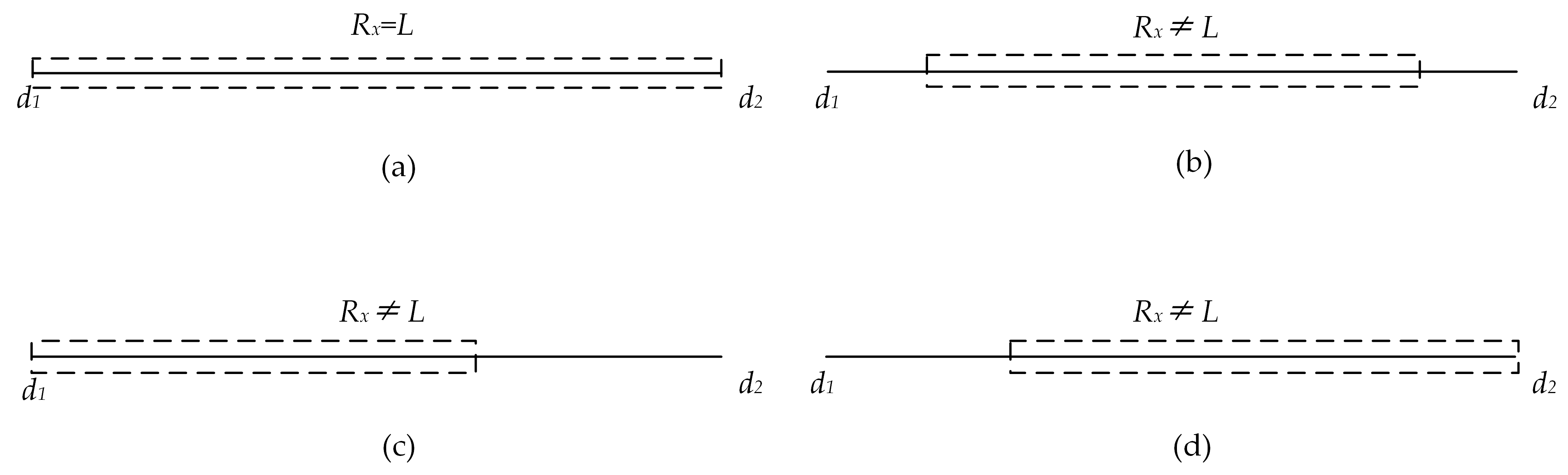
- Rule 2: First, the bands are padded with fine-grained to coarse-grained integer encoding, then the bands are padded with coarse-grained to fine-grained integer encoding until the band interval is filled. The specific filling method is shown in Figure 6, where L represents the band, and A, B, C, and D represent multi-scale integer coding at different levels.
- Convert the start and end point of the bands to the same granularity.
- 2.
- Gradually divide and determine its level scope.
- Case 1: If li−1 = lj−1, calculate the band length l, i.e., l = lj − li + 1, and convert l to the sum of the power of 2, where the maximum value in the addend corresponds to the level of is Nmin;
- Case 2: If li−1 ≠ lj−1, calculate the band length l, l = maxj−li + 1, where maxj is the maximum value of the j-th component, for example, if j = 6, then maxj = 1000. Then convert l to the sum of the power of 2, where the maximum value in the addend corresponds to the level of is Nmin;
- 3.
- Accurate filling step by step.
- Step 1: Calculate the corresponding level of b1 and b2, N1 = 33, N2 = 33;
- Step 2: According to the components of b1 and b2, it is divided into 5 grades (29~33, 25~29, 21~25, 11~21, 0~11); It is only necessary to calculate the band length l at the (29~33) grade, l = 4 mm, the level corresponding to 4 mm is Nmin = 27, Nmax = 33;
- Step 3: The level corresponding to l5 = 1 mm is N = 33, N > Nmin, and the multi-scale integer coding is obtained: MC1= 59,551,923,803,521,023 (N = 33), MC2= 59,551,927,024,746,495 (N = 32), MC3= 59,551,930,245,971,967 (N = 33);
3. Results
3.1. DGFQM
3.1.1. The DGFQM Based on String Coding
- Perform string encoding on the query interval [t1, t2] to obtain the string interval [s1, s2];
- Decode the strings s1 and s2 to attain levels N1, N2;
- Parse the string s1, and then obtain the parent data set Cf1 of s1 by coding;
- Parse s2, and then obtain the child set Cs2 of s2 through string coding;
- Obtain query results through set operations and query statements;
3.1.2. The DGFQM Based on MTSIC
- According to the multi-scale time segment integer encoding method, the integer coding MTC1 and MTC2 of t1 and t2 were obtained, so the integer coding interval was Cb = [MTC1, MTC2];
- Calculate the level of MTC1 and MTC2, and obtain the corresponding levels N1 and N2 through level operations;
- The parent data sets Cf1 and Cf2 are obtained through the contained relationship operation, and the missing fuzzy data set C1 is obtained according to Formula (15);
- 4.
- The child data sets Cs1 and Cs2 of MTC1 and MTC2 were obtained by using the containment relationship operation, and then the missing precise data set C2 was obtained according to the following Formula (16);
- 5.
- Obtain query results through set operations and query statements;
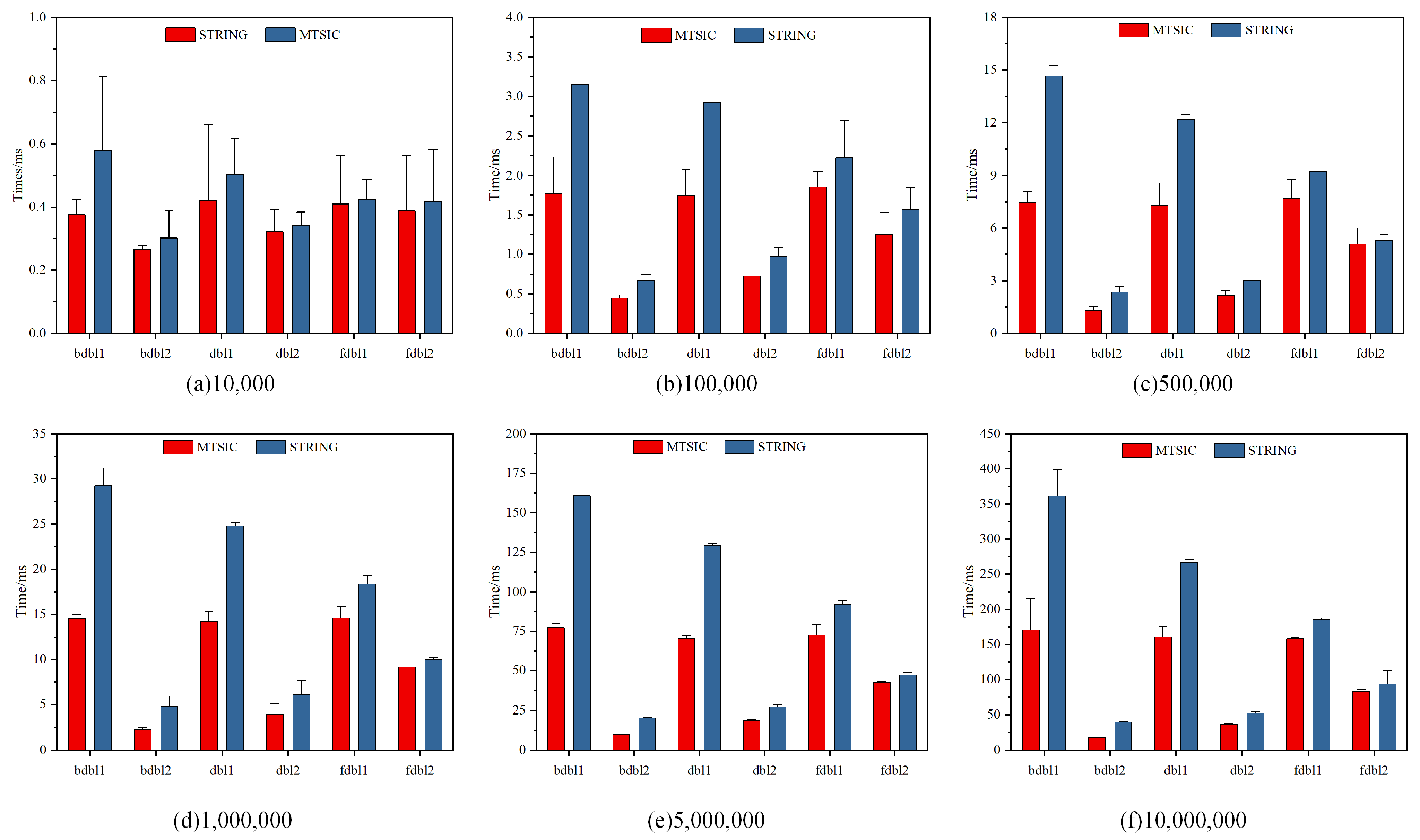
3.2. The Influence of the Proportion of Different Time Scales on Retrieval Efficiency
- Randomly generate n time data (year, month, day, hour, minute, second, millisecond, microsecond) according to equal and unequal proportions. The non-proportional data is generated in the way of 1: 2: 4: 8: 16: 32: 64: 128, which will generate a combination of factorials of 8, so we divided the scales into fine scales (hour, minute, second, millisecond, microsecond) and coarse scales (year, month, day). The specific design is shown in Table 3.
- Establish a B-tree index. Perform string encoding and MTSIC on time data, and then build B-trees, respectively.
- Dimension granularity fuzzy query. According to Section 3.1, we performed the DGFQM on string coding and MTSIC, respectively, and counted the results.
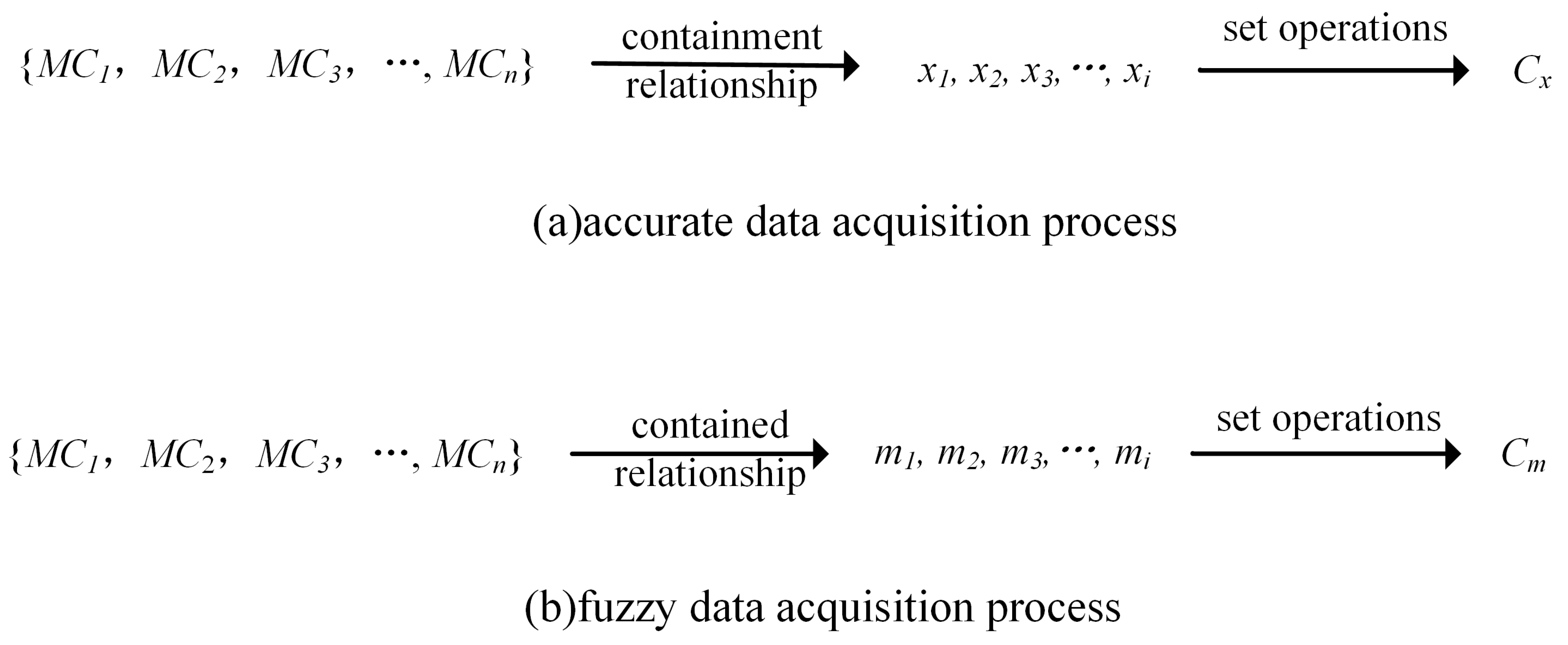
3.3. Comparing the Retrieval Efficiency of MBIC and String Encoding
- Perform string coding on the query interval [b1, b2] to obtain the string interval [s1, s2];
- Attain the exact data set Cx in the query interval. Let the storage fields be field1 and field2, respectively, and obtain the exact data set Cx according to Formula (17);
- 3.
- Obtain the fuzzy data set Cm in the query interval. Obtain the fuzzy data set Cm according to the Formula (18);
- 4.
- Obtain query results through set sum operation;
- According to the association method between MBIC and band, the corresponding MBIC set B= {MC1, MC2,..., MCn} is obtained;
- Attain the exact data set Cx in the query interval. Obtain the child interval xi of the i-th code in B by including relational operation, i.e., B(i) and repeat the operation until all codes in B are traversed. The specific process was shown in Figure 10a:
- Attain fuzzy data set Cm of query interval. Obtain the parent interval mi of the i-th code in B by including relational operation, i.e., B(i) and repeat the operation until all codes in B are traversed. The specific process was shown in Figure 10b;
- Obtain query results through set operations;
3.4. Discussion
4. Conclusions
4.1. DGFQM
4.2. Multi-Scale Integer Coding
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, Y.; Chen, Z.-x.; Yu, T.; Huang, X.-z.; Gu, X.-f. Agricultural remote sensing big data: Management and applications. J. Integr. Agric. 2018, 17, 1915–1931. [Google Scholar] [CrossRef]
- Saralioglu, E.; Gungor, O. Crowdsourcing in Remote Sensing: A Review of Applications and Future Directions. IEEE Geosci. Remote Sens. Mag. 2020, 8, 89–110. [Google Scholar] [CrossRef]
- Clifford, L. Big data: How do your data grow? Nature 2008, 455, 28–29. [Google Scholar]
- Spitzbart, B.D.; Lynch, H.J.; Turilli, M.; Jha, S. ICEBERG: Imagery Cyber-infrastructure and Extensible Building blocks to Enhance Research in the Geosciences. (A Research Programmer’s Perspective). In Practice and Experience in Advanced Research Computing; ACM: New York, NY, USA, 2020. [Google Scholar]
- Hidalgo, C. Why Information Grows; Penguin UK: London, UK, 2015. [Google Scholar]
- Balsa-Barreiro, J.; Menendez, M.; Morales, A.J. Scale, context, and heterogeneity: The complexity of the social space. Sci. Rep. 2022, 12, 9037. [Google Scholar] [CrossRef] [PubMed]
- Alessandretti, L.; Aslak, U.; Lehmann, S. The scales of human mobility. Nature 2020, 587, 402–407. [Google Scholar] [CrossRef] [PubMed]
- Ren, H.; Zhao, L.; Zhang, A.; Song, L.; Liao, Y.; Lu, W.; Cui, C. Early forecasting of the potential risk zones of COVID-19 in China’s megacities. Sci. Total Environ. 2020, 729, 138995. [Google Scholar] [CrossRef]
- Sugg, M.M.; Spaulding, T.J.; Lane, S.J.; Runkle, J.D.; Harden, S.R.; Hege, A.; Iyer, L.S. Mapping community-level determinants of COVID-19 transmission in nursing homes: A multi-scale approach. Sci. Total Environ. 2021, 752, 141946. [Google Scholar] [CrossRef]
- Ben, J.; Li, Y.; Zhou, C.; Wang, R.; Du, L. Algebraic encoding scheme for aperture 3 hexagonal discrete global grid system. Science China. Earth Sci. 2018, 61, 215–227. [Google Scholar]
- Li, Q.; Chen, X.; Tong, X.; Zhang, X.; Cheng, C. An Information Fusion Model between GeoSOT Grid and Global Hexagonal Equal Area Grid. ISPRS Int. J. Geo-Inf. 2022, 11, 265. [Google Scholar] [CrossRef]
- Guo, N.; Xiong, W.; Wu, Y.; Chen, L.; Jing, N. A Geographic Meshing and Coding Method Based on Adaptive Hilbert-Geohash. IEEE Access 2019, 7, 39815–39825. [Google Scholar] [CrossRef]
- Cao, B.; Feng, H.; Liang, J.; Li, X. Hilbert Curve and Cassandra Based Indexing and Storing Approach for Large-Scale Spatiotemporal Data. Geomat. Inf. Sci. Wuhan Univ. 2021, 46, 620–629. [Google Scholar]
- Zhai, W.; Chen, B.; Tong, X.; Cheng, C. Research on Continuity of Multi-Scale Space-Filling Curves. Acta Sci. Nat. Univ. Pekin. 2018, 54, 331–335. [Google Scholar]
- Huang, K.; Li, G.; Wang, J. Rapid retrieval strategy for massive remote sensing metadata based on GeoHash coding. Remote Sens. Lett. 2019, 10, 111–119. [Google Scholar] [CrossRef]
- Lei, Y.; Tong, X.; Zhang, Y.; Qiu, C.; Wu, X.; Lai, G.; Li, H.; Guo, C.; Zhang, Y. Global multi-scale grid integer coding and spatial indexing: A novel approach for big earth observation data. ISPRS J. Photogramm. 2020, 163, 202–213. [Google Scholar] [CrossRef]
- Fairbanks, K.D. An analysis of Ext4 for digital forensics. Digit. Invest. 2012, 9, S118–S130. [Google Scholar] [CrossRef]
- Brumm, B. Beginning Oracle SQL for Oracle Database 18c: From Novice to Professional: Beginning Oracle SQL for Oracle Database 18c: From Novice to Professional; Apress: New York, NY, USA, 2019. [Google Scholar]
- Zhu, L.; Su, X.; Tai, X. A High-Dimensional Indexing Model for Multi-Source Remote Sensing Big Data. Remote Sens. 2021, 13, 1314. [Google Scholar] [CrossRef]
- Wu, H.; Cheng, H.; Zheng, J.; Qi, K.; Yang, H.; Li, X. RS-ODMS: An Online Distributed Management and Service Framework for Remote Sensing Data. Geomat. Inf. Sci. Wuhan Univ. 2020, 45, 11. [Google Scholar]
- Xu, C.; Du, X.; Yan, Z.; Fan, X. ScienceEarth: A Big Data Platform for Remote Sensing Data Processing. Remote Sens. 2020, 12, 607. [Google Scholar] [CrossRef] [Green Version]
- Isomura, A.; Iida, Y.; Naito, I.; Nakamura, T. Axispot: A Distributed Spatiotemporal Data Management System for Digital Twins of Moving Objects. IEEE Softw. 2022, 39, 33–38. [Google Scholar] [CrossRef]
- Akakba, A.; Filali, A. Object-Relational Modelling and Establishment of a Generic Database for the Management and Monitoring of Urban Planning Permissions in the City of El-Eulma (Algeria). J. Settl. Spat. Plan. 2017, 8, 139–146. [Google Scholar] [CrossRef]
- Zheng, Y.; Liu, J.; Li, J.; Xu, Y.; Pei, Y. Design of Fine Management System for Civil Aviation Airspace Resources Based on Spatiotemporal Grid Model. In Proceedings of the 2019 IEEE 1st International Conference on Civil Aviation Safety and Information Technology (ICCASIT), Kunming, China, 17–19 October 2019. [Google Scholar]
- Tong, X.; Wang, R.; Wang, L.; Lai, G.; Ding, L. An Efficient Integer Coding and Computing Method for Multiscale Time Segment. Acta Geod. Et Cartogr. Sin. 2016, 45, 66–76. [Google Scholar]
- Zadeh, A.L. Fuzzy sets versus probability. Proc. IEEE 1980, 68, 421. [Google Scholar] [CrossRef]
- Deng, L.; Liang, Z.; Zhang, Y. A Fuzzy Temporal Model and Query Language for FTER Databases. In Proceedings of the 2008 Eighth International Conference on Intelligent Systems Design and Applications, Kaohsuing, Taiwan, 26–28 November 2008; Volume 3, pp. 77–82. [Google Scholar]
- Ďuračiová, R.; Faixová Chalachanová, J. Fuzzy Spatio-Temporal Querying the PostgreSQL/PostGIS Database for Multiple Criteria Decision Making. In Dynamics in GIscience; Springer: Cham, Switzerland, 2018; pp. 81–97. [Google Scholar]
- Liu, Y.; Wu, H.; Wang, S.; Chen, X.; Kimball, J.S.; Zhang, C.; Gao, H.; Guo, P. Evaluation of trophic state for inland waters through combining Forel-Ule Index and inherent optical properties. Sci. Total Environ. 2022, 820, 153316. [Google Scholar] [CrossRef]
- Duan, M.; Duan, L. High Spatial Resolution Remote Sensing Data Classification Method Based on Spectrum Sharing. Sci. Program. 2021, 2021, 4356957. [Google Scholar] [CrossRef]
- Fan, L.; Li, T.; Yuan, Y.; Katabi, D. In-Home Daily-Life Captioning Using Radio Signals. arXiv 2020, arXiv:2008.10966. [Google Scholar]
- Fan, L.; Li, T.; Fang, R.; Hristov, R.; Yuan, Y.; Katabi, D. Learning Longterm Representations for Person Re-Identification Using Radio Signals. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, DC, USA, 13–19 June 2020. [Google Scholar]
- Yonemoto, N.; Kohmura, A.; Futatsumori, S.; Morioka, K.; Makita, Y. Passive Radio Imaging of Hybrid Radar System for Security Inspections. In Proceedings of the 2020 17th European Radar Conference (EuRAD), Utrecht, The Netherlands, 10–15 January 2021; pp. 378–381. [Google Scholar]
- Zhang, L.; Wang, S.; Liu, H.; Lin, Y.; Zhu, M.; Gao, L.; Tong, Q. From Spectrum to Temporal Spectrum—Research on Change Detection of Remote Sensing Time Series. Geomat. Inf. Sci. Wuhan Univ. 2021, 46, 18. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
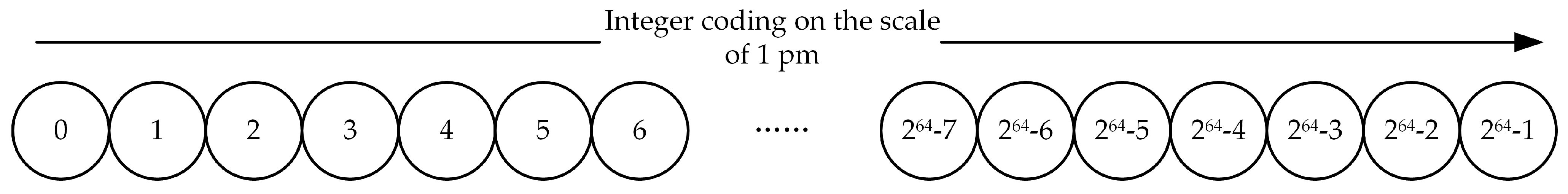{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level | Scale | Level | Scale | Level | Scale | Level | Scale |
|---|---|---|---|---|---|---|---|
| 63 | 1 pm | 47 | 64 | 31 | 4 | 15 | 64 |
| 62 | 2 | 46 | 128 | 30 | 8 | 14 | 128 |
| 61 | 4 | 45 | 256 | 29 | 1 cm | 13 | 256 |
| 60 | 8 | 44 | 512 | 28 | 2 | 12 | 512 |
| 59 | 16 | 43 | 1 μm | 27 | 4 | 11 | 1 km |
| 58 | 32 | 42 | 2 | 26 | 8 | 10 | 2 |
| 57 | 64 | 41 | 4 | 25 | 1 dm | 9 | 4 |
| 56 | 128 | 40 | 8 | 24 | 2 | 8 | 8 |
| 55 | 256 | 39 | 16 | 23 | 4 | 7 | 16 |
| 54 | 512 | 38 | 32 | 22 | 8 | 6 | 32 |
| 53 | 1 nm | 37 | 64 | 21 | 1 m | 5 | 64 |
| 52 | 2 | 36 | 128 | 20 | 2 | 4 | 128 |
| 51 | 4 | 35 | 256 | 19 | 4 | 3 | 256 |
| 50 | 8 | 34 | 512 | 18 | 8 | 2 | 512 |
| 49 | 16 | 33 | 1 mm | 17 | 16 | 1 | 1024 |
| 48 | 32 | 32 | 2 | 16 | 32 | 0 | 2048 |
| Partial Results of Granular Fuzzy Queries | Partial Results of an Intersect Query | Partially Missing Data for Intersecting Queries |
|---|---|---|
| ‘2014’ ‘2014-11’ ‘2014-11-15’ ‘2014-11-15T00:08:08.216495’ ‘2014-11-15T01:25’ ‘2014-11-15T01:59:09.074094’ ‘2014-11-15T03:08:31.252138’ ‘2015-02-15T00:10:09.460989’ ‘2015-02-15T00:21:15.373’ | ‘2014-11-15’ ‘2014-11-15T00:08:08.216495’ ‘2014-11-15T01:25’ ‘2014-11-15T01:59:09.074094’ ‘2014-11-15T03:08:31.252138’ | ‘2014’ ‘2014-11’ ‘2015-02-15T00:10:09.460989’ ‘2015-02-15T00:21:15.373’ |
| Proportional Way | Representation Symbols | Proportional Design |
|---|---|---|
| y: m: d: h: m: s: ms: μs | dbl (equal proportion) | 1: 1: 1: 1: 1: 1: 1: 1 |
| bdbl (unequal proportion) | 1: 2: 4: 8: 16: 32: 64: 128 | |
| fdbl (unequal proportion) | 128: 64: 32: 16: 8: 4: 2: 1 |
| Storage Method | Method Description | Example |
|---|---|---|
| string | Use two fields to store bands | “6-626-4-5-1”–“6-626-4-5-4” |
| MBIC | Store bands with a column of integer | The multi-scale integer encoding of “6-626-4-5-1”–“6-626-4-5-4” is: 59,551,923,803,521,023, 59,551,927,024,746,495, 59,551,930,245,971,967 |
| Query Interval | MBIC | String Coding | |
|---|---|---|---|
| query1 | 4,003,612~4,003,619 mm | 36,058,524,635,103,231 36,058,531,077,554,175 36,058,537,520,005,119 | “04-003-6-1-2”–“04-003-6-1-9” |
| query2 | 400,362~400,367 cm | 36,058,586,912,129,023 36,058,689,991,344,127 | “04-003-6-2”–“04-003-6-7” |
| query3 | 40,032~40,039 dm | 36,056,834,565,472,255 36,058,483,832,913,919 36,060,133,100,355,583 | “04-003-2”–“04-003-9” |
| query4 | 2004~2060 m | 18,067,175,067,615,231 18,119,951,625,748,479 18,225,504,742,014,975 18,366,242,230,370,303 18,471,795,346,636,799 18,524,571,904,770,047 18,546,562,137,325,567 | “02-004”–“02-060” |
| query5 | 4003~4230 m | 36,059,583,344,541,695 36,072,777,484,075,007 36,081,573,577,097,215 36,134,350,135,230,463 36,239,903,251,496,959 36,451,009,484,029,951 36,873,221,949,095,935 37,436,171,902,517,247 37,858,384,367,583,231 38,016,714,041,982,975 38,056,296,460,582,911 | “04-003”–“04-230” |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, W.; Liu, W.; Tong, X.; Wang, J.; Peng, F.; Tian, Y.; Zhu, J. A Management Method of Multi-Granularity Dimensions for Spatiotemporal Data. ISPRS Int. J. Geo-Inf. 2023, 12, 148. https://doi.org/10.3390/ijgi12040148
Cao W, Liu W, Tong X, Wang J, Peng F, Tian Y, Zhu J. A Management Method of Multi-Granularity Dimensions for Spatiotemporal Data. ISPRS International Journal of Geo-Information. 2023; 12(4):148. https://doi.org/10.3390/ijgi12040148
Chicago/Turabian StyleCao, Wen, Wenhao Liu, Xiaochong Tong, Jianfei Wang, Feilin Peng, Yuzhen Tian, and Jingwen Zhu. 2023. "A Management Method of Multi-Granularity Dimensions for Spatiotemporal Data" ISPRS International Journal of Geo-Information 12, no. 4: 148. https://doi.org/10.3390/ijgi12040148