
Generating Gridded Gross Domestic Product Data for China Using Geographically Weighted Ensemble Learning
Abstract
:1. Introduction
2. Study Area and Data
2.1. Study Area
2.2. Data
2.2.1. County-Level Statistical GDP Data
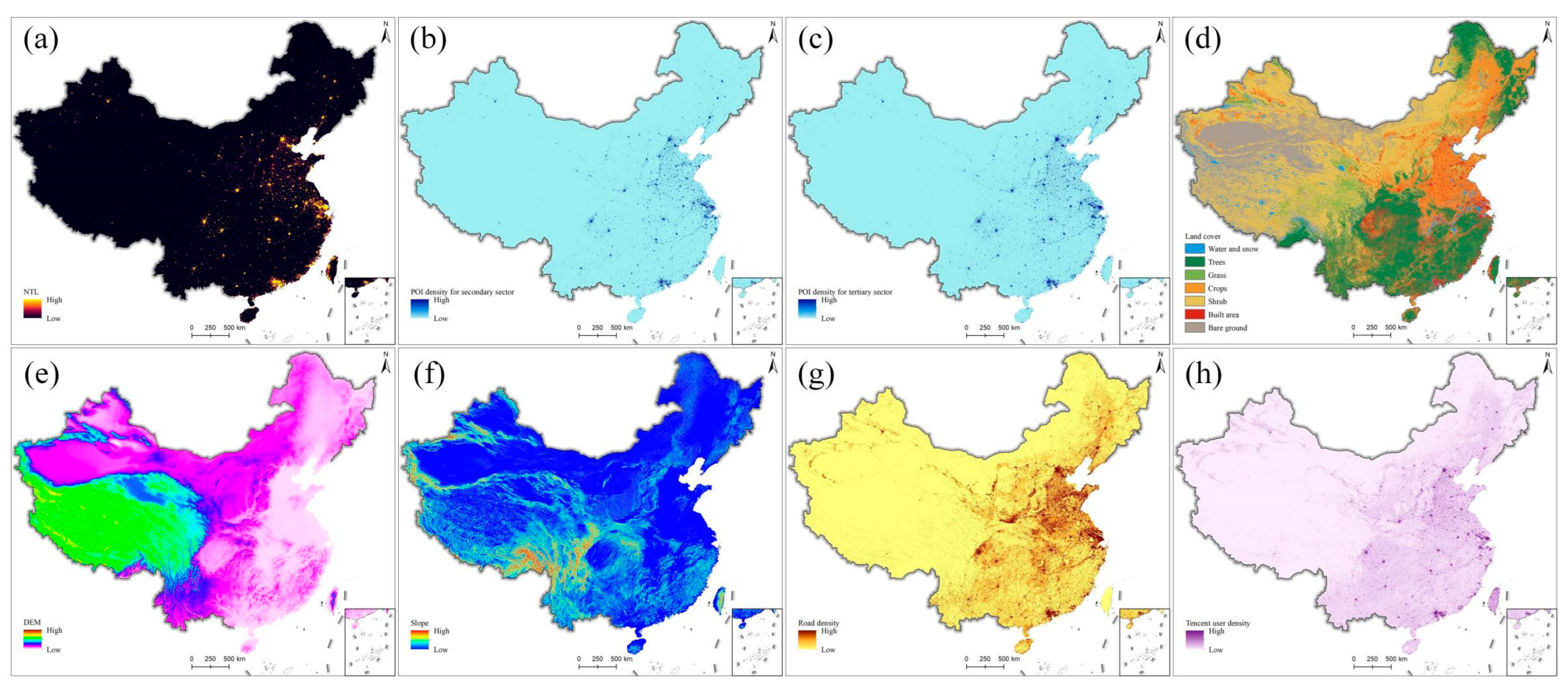
2.2.2. Gridded Auxiliary Data
3. Methodology
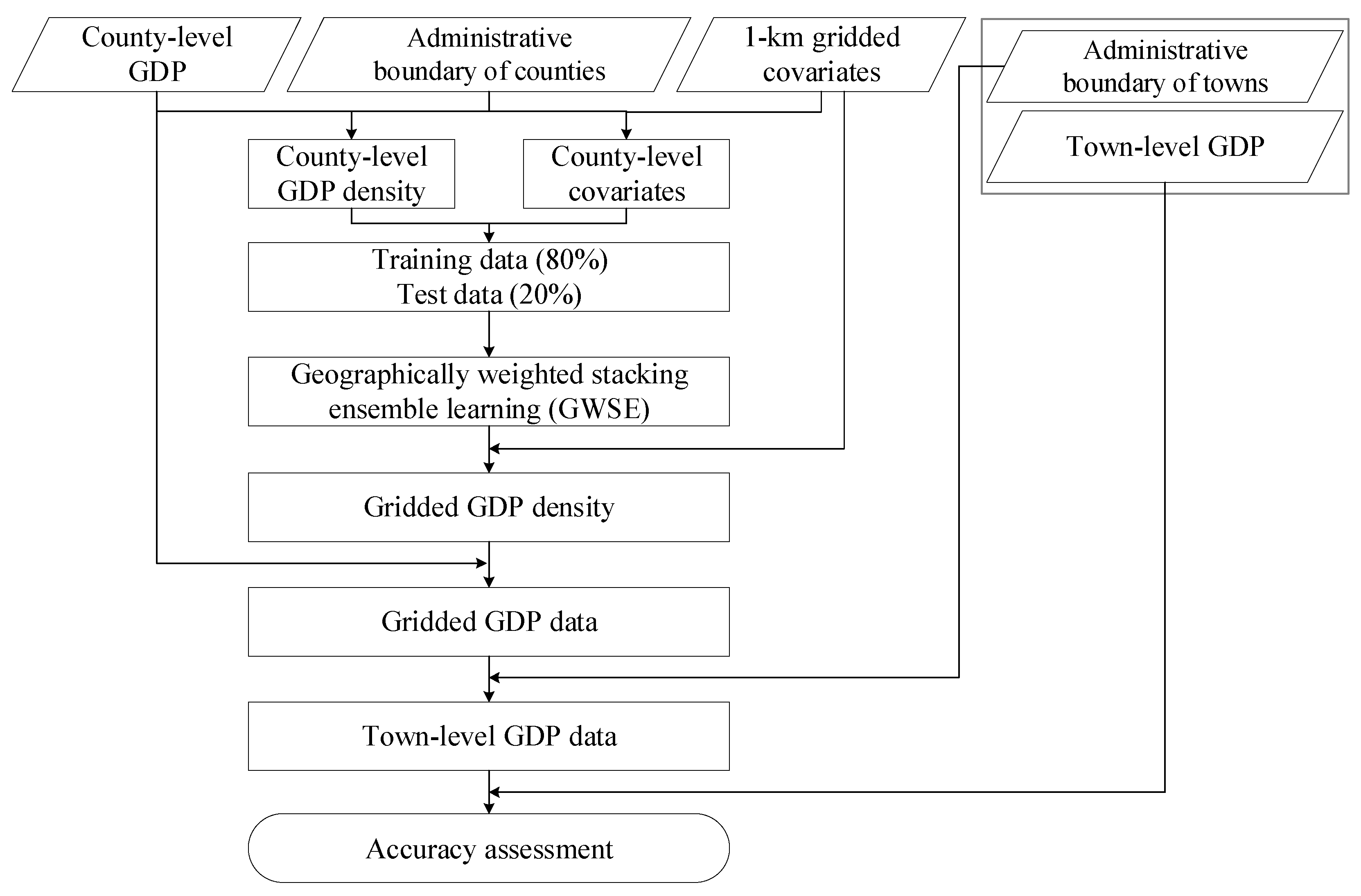
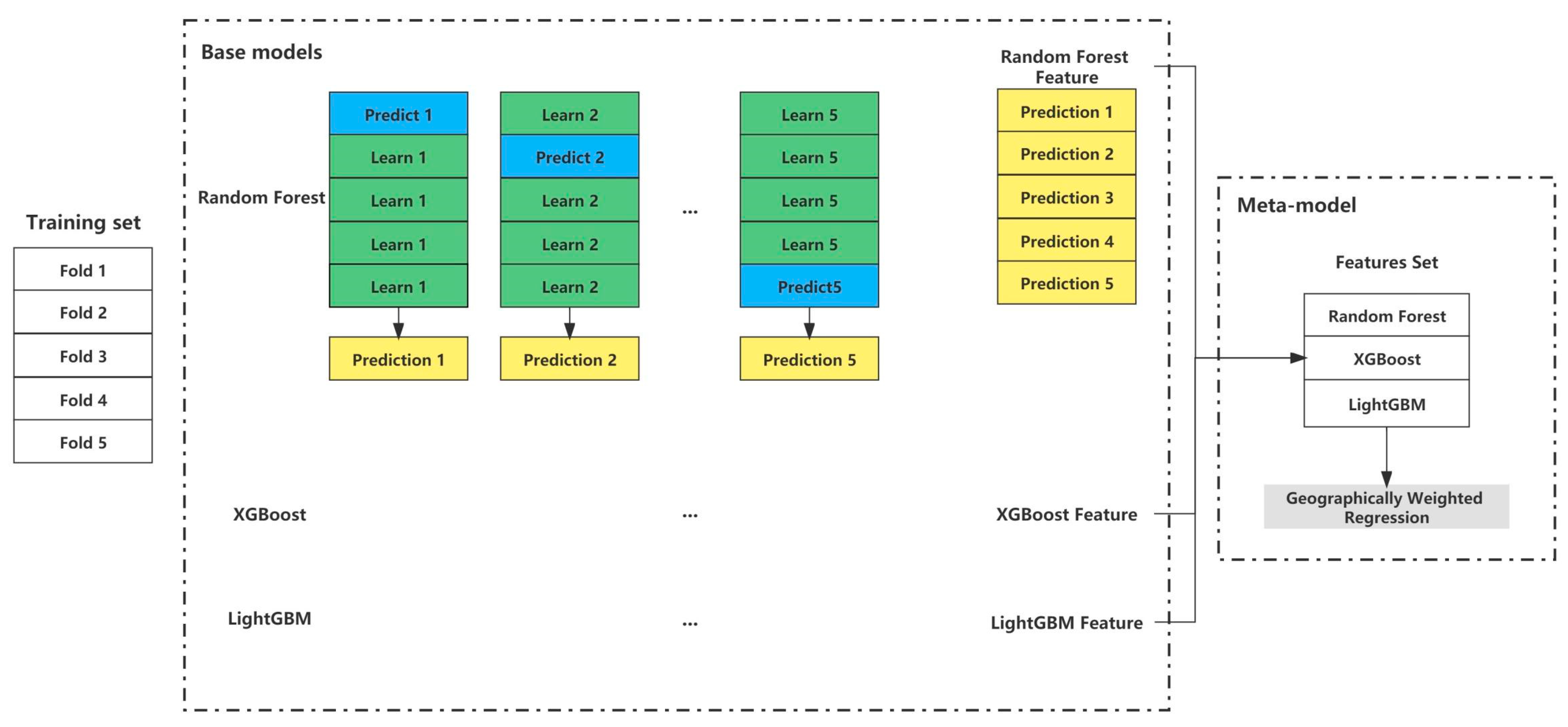
3.1. Procedure of GDP Downscaling
- (1)
- The county-level GDP data in Figure 1 and 1 km covariates in Table 1 were preprocessed. The Albers equal-area conic projection was adopted as the coordinate system of the GDP data and covariates. The county-level covariates were also calculated using the mean of covariates within each county and were combined with county-level GDP data for subsequent training.
- (2)
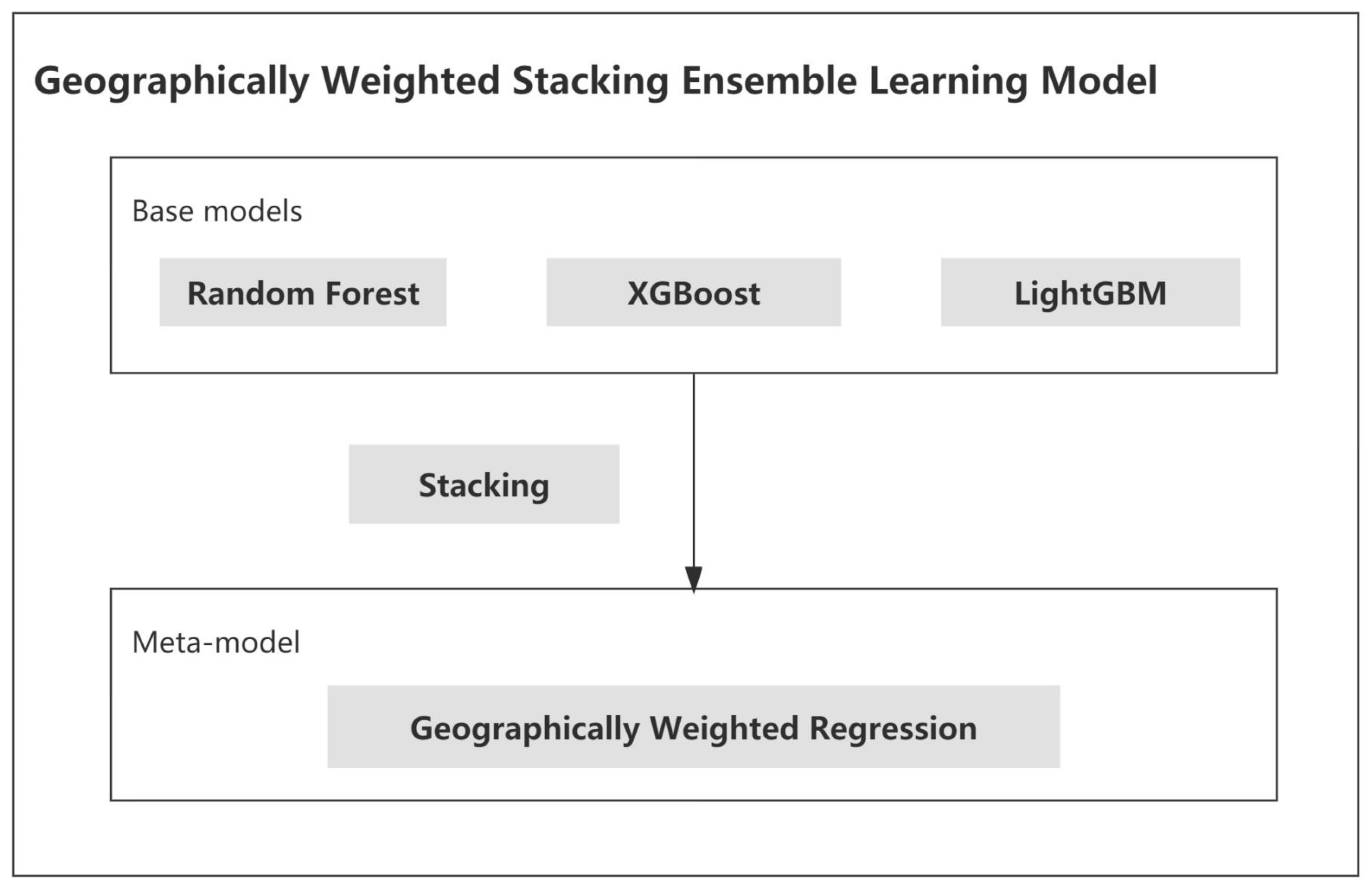
- GWSE was built and trained to estimate gridded GDP density. Random forest, XGBoost, and LightGBM were employed as base models, and the longitude and latitude were considered as covariates in the three models to account for spatial homogeneity. To consider spatial heterogeneity, GWSE replaced linear regression with GWR to locally fuse the predictions of the three base models in stacking ensemble learning. As each GDP sector has different spatial distribution and related covariates [10,23,27,28,42], three GWSE models were trained for each GDP sector to estimate the gridded GDP density of each GDP sector. The county-level GDP data and county-level covariates were divided into training data and test data. Training data accounted for 80% of all county-level data in training GWSE for each GDP sector. The best-trained GWSE was selected for each GDP sector after 10 iterations.
- (3)
- Gridded GDP data was predicted using trained GWSE models. According to previous GDP downscaling studies [2,9,10,23,24], the trained GDP downscaling models on administrative-level data were directly used to estimate the gridded GDP data. Using 1 km gridded covariates as inputs, each trained GWSE model on county-level data was employed to forecast the 1 km gridded GDP density of each GDP sector. The predicted gridded GDP density was adjusted to generate gridded GDP data for each sector, and the sum of the three adjusted gridded GDP data was computed as the total gridded GDP data.
- (4)
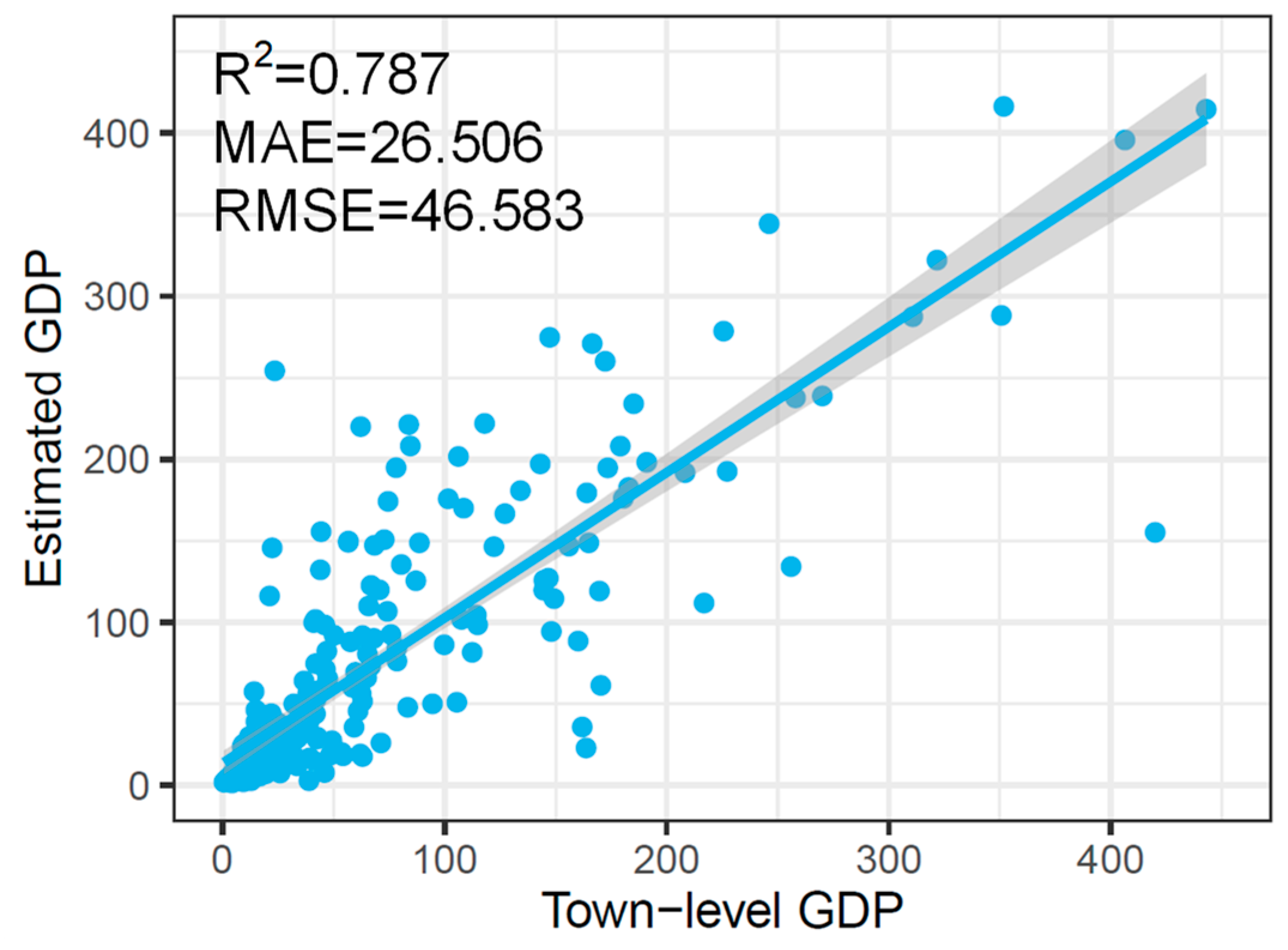
- The accuracy of the gridded GDP data was evaluated. Statistical town-level GDP data from the yearbook were adopted as ground truth data to evaluate the corresponding town-level GDP data aggregated from the estimated gridded GDP data to further evaluate the performance of GWSE.
3.2. Preparing GDP and Auxiliary Data
3.3. Building GWSE
3.3.1. Base Models
3.3.2. Meta Model
3.3.3. Stacking
3.4. GDP Downscaling
3.5. Accuracy Assessment Metrics
4. Results
4.1. Model Performance and Comparison
4.2. Gridded GDP Maps
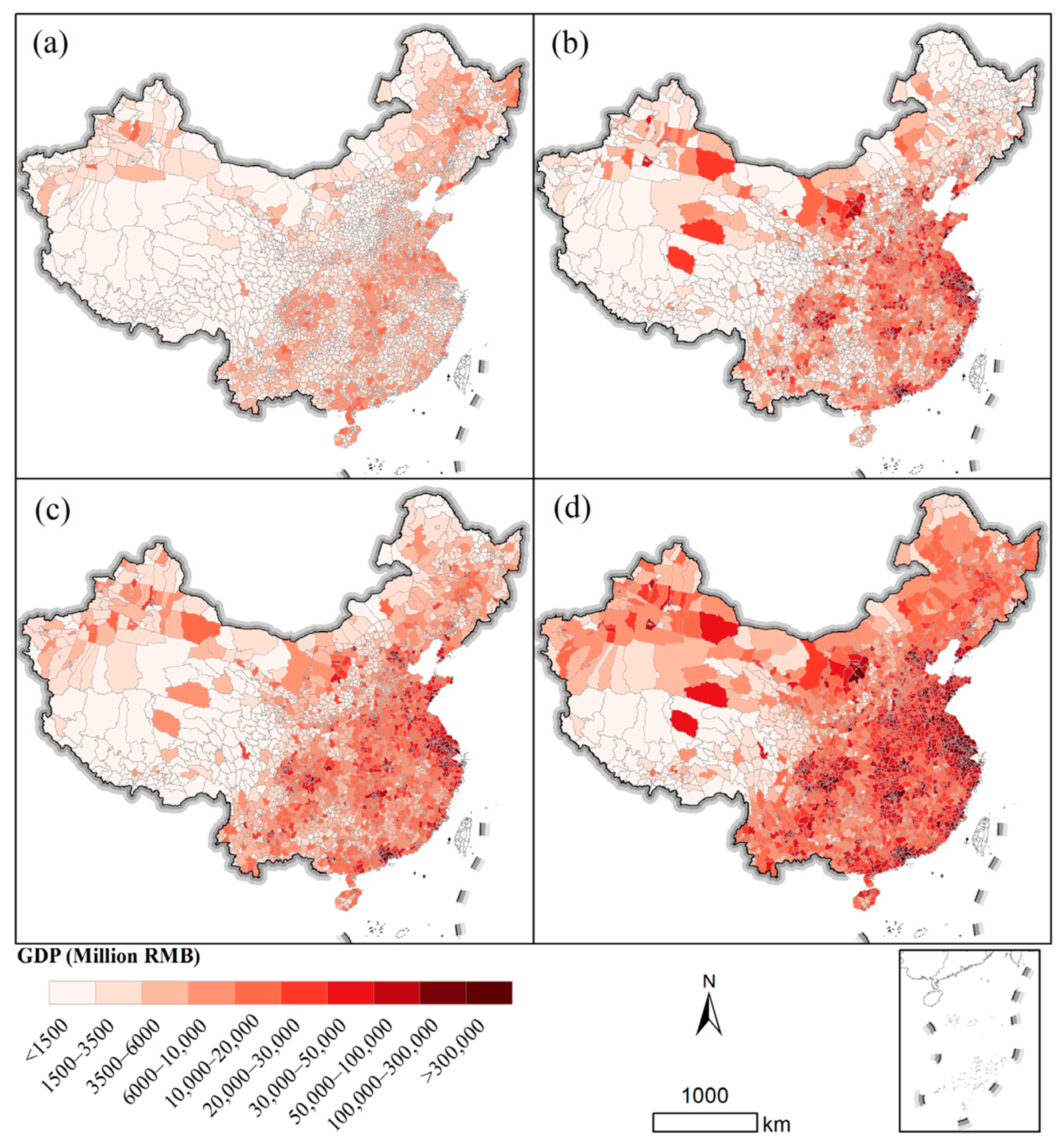
4.2.1. Gridded GDP Map of China for the Primary Sector
4.2.2. Gridded GDP Map of China for the Secondary Sector
4.2.3. Gridded GDP Map of China for the Tertiary Sector
4.3. Accuracy Assessment
5. Discussion
5.1. Difference in Performance of GDP Sectors
5.2. Scale Uncertainty in Estimating Gridded GDP Density
5.3. Advantages and Disadvantages
5.4. Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Geiger, T. Continuous national gross domestic product (gdp) time series for 195 countries: Past observations (1850–2005) harmonized with future projections according to the shared socio-economic pathways (2006–2100). Earth Syst. Sci. Data 2018, 10, 847–856. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Li, S.; Gao, F.; Wang, F.; Lin, J.; Tan, Z. Evaluating the performance of lbsm data to estimate the gross domestic product of china at multiple scales: A comparison with npp-viirs nighttime light data. J. Clean. Prod. 2021, 328, 129558. [Google Scholar] [CrossRef]
- Kummu, M.; Taka, M.; Guillaume, J.H.A. Gridded global datasets for gross domestic product and human development index over 1990–2015. Sci. Data 2018, 5, 180004. [Google Scholar] [CrossRef] [Green Version]
- Nadim, F.; Kjekstad, O.; Peduzzi, P.; Herold, C.; Jaedicke, C. Global landslide and avalanche hotspots. Landslides 2006, 3, 159–173. [Google Scholar] [CrossRef]
- Sun, J.; Di, L.; Sun, Z.; Wang, J.; Wu, Y. Estimation of gdp using deep learning with npp-viirs imagery and land cover data at the county level in conus. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1400–1415. [Google Scholar] [CrossRef]
- Sutton, P.C.; Costanza, R. Global estimates of market and non-market values derived from nighttime satellite imagery, land cover, and ecosystem service valuation. Ecol. Econ. 2002, 41, 509–527. [Google Scholar] [CrossRef]
- Yao, J.; Zhang, X.; Luo, W.; Liu, C.; Ren, L. Applications of stacking/blending ensemble learning approaches for evaluating flash flood susceptibility. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102932. [Google Scholar] [CrossRef]
- Yi, J.; Du, Y.; Liang, F.; Tu, W.; Qi, W.; Ge, Y. Mapping human’s digital footprints on the tibetan plateau from multi-source geospatial big data. Sci. Total Environ. 2019, 711, 134540. [Google Scholar] [CrossRef]
- Zhao, N.; Liu, Y.; Cao, G.; Samson, E.L.; Zhang, J. Forecasting china’s gdp at the pixel level using nighttime lights time series and population images. GIScience Remote Sens. 2017, 54, 407–425. [Google Scholar] [CrossRef]
- Chen, Q.; Ye, T.; Zhao, N.; Ding, M.; Ouyang, Z.; Jia, P.; Yue, W.; Yang, X. Mapping china’s regional economic activity by integrating points-of-interest and remote sensing data with random forest. Environ. Plan. B Urban Anal. City Sci. 2020, 48, 1876–1894. [Google Scholar] [CrossRef]
- Wang, X.; Sutton, P.C.; Qi, B. Global mapping of gdp at 1 km2 using viirs nighttime satellite imagery. ISPRS Int. J. Geo-Inf. 2019, 8, 580. [Google Scholar] [CrossRef] [Green Version]
- Lloyd, C.T.; Sorichetta, A.; Tatem, A. High resolution global gridded data for use in population studies. Sci. Data 2017, 4, 170001. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Doll, C.N.; Muller, J.-P.; Elvidge, C.D. Night-time imagery as a tool for global mapping of socioeconomic parameters and greenhouse gas emissions. AMBIO J. Hum. Environ. 2000, 29, 157–162. [Google Scholar] [CrossRef]
- Elvidge, C.D.; Baugh, K.E.; Kihn, E.A.; Kroehl, H.W.; Davis, E.R.; Davis, C.W. Relation between satellite observed visible-near infrared emissions, population, economic activity and electric power consumption. Int. J. Remote Sens. 1997, 18, 1373–1379. [Google Scholar] [CrossRef]
- Zhang, R.; Chen, Y.; Zhang, X.; Ma, Q.; Ren, L. Mapping homogeneous regions for flash floods using machine learning: A case study in jiangxi province, china. Int. J. Appl. Earth Obs. Geoinf. 2022, 108, 102717. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, X.; Gao, S.; Gong, L.; Kang, C.; Zhi, Y.; Chi, G.; Shi, L. Social sensing: A new approach to understanding our socioeconomic environments. Ann. Assoc. Am. Geogr. 2015, 105, 512–530. [Google Scholar] [CrossRef]
- Chen, Y.; Shi, K.; Ge, Y.; Zhou, Y.n. Spatiotemporal remote sensing image fusion using multiscale two-stream convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Chen, Y.; Li, Y.; Wu, G.; Zhang, F.; Zhu, K.; Xia, Z.; Chen, Y. Exploring spatiotemporal accessibility of urban fire services using real-time travel time. Int. J. Environ. Res. Public Health 2021, 18, 4200. [Google Scholar] [CrossRef]
- Chen, Y.; Ge, Y.; Chen, Y.; Jin, Y.; An, R. Subpixel land cover mapping using multiscale spatial dependence. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5097–5106. [Google Scholar] [CrossRef]
- Chen, Y.; Ge, Y.; Heuvelink, G.B.M.; An, R.; Chen, Y. Object-based superresolution land cover mapping from remotely sensed imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 328–340. [Google Scholar] [CrossRef]
- Chen, Y.; Ge, Y.; An, R.; Chen, Y. Super-resolution mapping of impervious surfaces from remotely sensed imagery with points-of-interest. Remote Sens. 2018, 10, 242. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Zhou, Y.n.; Ge, Y.; An, R.; Chen, Y. Enhancing land cover mapping through integration of pixel-based and object-based classifications from remotely sensed imagery. Remote Sens. 2018, 10, 77. [Google Scholar] [CrossRef] [Green Version]
- Chen, Q.; Hou, X.; Zhang, X.; Ma, C. Improved gdp spatialization approach by combining land-use data and night-time light data: A case study in china’s continental coastal area. Int. J. Remote Sens. 2016, 37, 4610–4622. [Google Scholar] [CrossRef] [Green Version]
- Murakami, D.; Yamagata, Y. Estimation of gridded population and gdp scenarios with spatially explicit statistical downscaling. Sustainability 2019, 11, 2106. [Google Scholar] [CrossRef] [Green Version]
- Zhao, M.; Cheng, W.; Zhou, C.; Li, M.; Wang, N.; Liu, Q. Gdp spatialization and economic differences in south china based on npp-viirs nighttime light imagery. Remote Sens. 2017, 9, 673. [Google Scholar] [CrossRef] [Green Version]
- Liang, H.; Guo, Z.; Wu, J.; Chen, Z. Gdp spatialization in ningbo city based on npp/viirs night-time light and auxiliary data using random forest regression. Adv. Space Res. 2020, 65, 481–493. [Google Scholar] [CrossRef]
- Chen, Y.; Wu, G.; Ge, Y.; Xu, Z. Mapping gridded gross domestic product distribution of china using deep learning with multiple geospatial big data. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens 2022, 15, 1791–1802. [Google Scholar] [CrossRef]
- Ustaoglu, E.; Bovkır, R.; Aydınoglu, A.C. Spatial distribution of gdp based on integrated nps-viirs nighttime light and modis evi data: A case study of turkey. Environ. Dev. Sustain. 2021, 23, 10309–10343. [Google Scholar] [CrossRef]
- Dong, X.; Yu, Z.; Cao, W.; Shi, Y.; Ma, Q. A survey on ensemble learning. Front. Comput. Sci. 2020, 14, 241–258. [Google Scholar] [CrossRef]
- Wu, T.; Zhang, W.; Jiao, X.; Guo, W.; Alhaj Hamoud, Y. Evaluation of stacking and blending ensemble learning methods for estimating daily reference evapotranspiration. Comput. Electron. Agric. 2021, 184, 106039. [Google Scholar] [CrossRef]
- Cheng, J.; Sun, J.; Yao, K.; Xu, M.; Wang, S.; Fu, L. Hyperspectral technique combined with stacking and blending ensemble learning method for detection of cadmium content in oilseed rape leaves. J. Sci. Food Agric. 2022, 103, 2690–2699. [Google Scholar] [CrossRef] [PubMed]
- Džeroski, S.; Ženko, B. Is combining classifiers with stacking better than selecting the best one? Mach. Learn. 2004, 54, 255–273. [Google Scholar] [CrossRef] [Green Version]
- Oshan, T.M.; Li, Z.; Kang, W.; Wolf, L.J.; Fotheringham, A.S. Mgwr: A python implementation of multiscale geographically weighted regression for investigating process spatial heterogeneity and scale. ISPRS Int. J. Geo-Inf. 2019, 8, 269. [Google Scholar] [CrossRef] [Green Version]
- Song, Y. Geographically optimal similarity. Math. Geosci. 2022, 1–26. [Google Scholar] [CrossRef]
- Georganos, S.; Grippa, T.; Niang Gadiaga, A.; Linard, C.; Lennert, M.; Vanhuysse, S.; Mboga, N.; Wolff, E.; Kalogirou, S. Geographical random forests: A spatial extension of the random forest algorithm to address spatial heterogeneity in remote sensing and population modelling. Geocarto Int. 2021, 36, 121–136. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Wu, G.; Chen, Y.; Xia, Z. Spatial location optimization of fire stations with traffic status and urban functional areas. Appl. Spat. Anal. Policy 2023, 1–18. [Google Scholar] [CrossRef]
- Fotheringham, A.; Brunsdon, C.; Charlton, M. Geographically Weighted Regression: The Analysis of Spatially Varying Relationships; Wiley: Chichester, UK; Hoboken, NJ, USA, 2002. [Google Scholar]
- Chen, Y.; Ruojing, Z.; Ge, Y.; Yan, J.; Zelong, X. Downscaling census data for gridded population mapping with geographically weighted area-to-point regression kriging. IEEE Access 2019, 7, 149132–149141. [Google Scholar] [CrossRef]
- Goodchild, M.F. The validity and usefulness of laws in geographic information science and geography. Ann. Assoc. Am. Geogr. 2004, 94, 300–303. [Google Scholar] [CrossRef] [Green Version]
- Elvidge, C.D.; Zhizhin, M.; Ghosh, T.; Hsu, F.-C.; Taneja, J. Annual time series of global viirs nighttime lights derived from monthly averages: 2012 to 2019. Remote Sens. 2021, 13, 922. [Google Scholar] [CrossRef]
- Karra, K.; Kontgis, C.; Statman-Weil, Z.; Mazzariello, J.C.; Mathis, M.; Brumby, S.P. Global land use/land cover with sentinel 2 and deep learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4704–4707. [Google Scholar]
- Thomas, T.S.; You, L.; Wood-Sichra, U.; Ru, Y.; Blankespoor, B.; Kalvelagen, E.M.F. Generating Gridded Agricultural Gross Domestic Product for Brazil: A Comparison of Methodologies; The World Bank: Washington, DC, USA, 2019. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Lu, B.; Hu, Y.; Yang, D.; Liu, Y.; Liao, L.; Yin, Z.; Xia, T.; Dong, Z.; Harris, P.; Brunsdon, C.; et al. Gwmodels: A software for geographically weighted models. SoftwareX 2023, 21, 101291. [Google Scholar] [CrossRef]
- Ge, Y.; Jin, Y.; Stein, A.; Chen, Y.; Wang, J.; Wang, J.; Cheng, Q.; Bai, H.; Liu, M.; Atkinson, P.M. Principles and methods of scaling geospatial earth science data. Earth-Sci. Rev. 2019, 197, 102897. [Google Scholar] [CrossRef]
- Wheeler, D.C. Diagnostic tools and a remedial method for collinearity in geographically weighted regression. Environ. Plan. A 2007, 39, 2464–2481. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Auxiliary Data Variable | Description | Data Source | Time | Use in Sectors |
|---|---|---|---|---|
| NTL | VIIRS night-time light data | VIIRS NTL image (https://eogdata.mines.edu/nighttime_light/annual/v20/, accessed on 1 January 2022.) | 2020 | GDP2 and GDP3 |
| POI density for GDP2 | Number of POIs within each grid related to GDP2 | AutoNavi Maps (https://amap.com/, accessed on 31 December 2020.) | 2020 | GDP2 |
| POI density for GDP3 | Number of POIs within each grid related to GDP3 | GDP3 | ||
| Water | Water and snow/ice proportion. | Esri 10-m global land cover data (https://www.arcgis.com/apps/instant/media/index.html?appid=fc92d38533d440078f17678ebc20e8e2, accessed on 27 December 2021.) | 2020 | GDP1 |
| Tree | Tree proportion | GDP1 | ||
| Grass | Grass and flooded vegetation proportion | GDP1 | ||
| Crops | Crop land proportion | GDP1 | ||
| Scrub/shrub | Scrub and shrub proportion | GDP1 | ||
| Bare ground | Bare ground proportion | GDP1 | ||
| Built area | Built area proportion | GDP2 and GDP3 | ||
| DEM | Digital elevation of each grid | ALOS World 3D-30 m (AW3D30) (https://www.eorc.jaxa.jp/ALOS/en/aw3d30/data/index.htm, accessed on 1 July 2022.) | - | GDP1 |
| Slope | Slope of each grid | GDP1 | ||
| Road density | Road length within each grid | AutoNavi Maps (https://amap.com/, accessed on 31 December 2020.) | 2020 | GDP2 and GDP3 |
| Tencent user density | Average positioning density of Tencent users | Tencent user positioning data (https://heat.qq.com/, accessed on 12 June 2019.) | 2019 | GDP2 and GDP3 |
| Percentage of GDP1 | Percentage of the primary sector in total GDP | The 2021 yearbook of China (https://data.cnki.net/Yearbook/Single/N2022040099, accessed on 13 April 2022.) | 2020 | GDP1 |
| Percentage of GDP2 | Percentage of the secondary sector in total GDP | GDP2 | ||
| Percentage of GDP3 | Percentage of the tertiary sector in total GDP | GDP3 | ||
| Longitude | Longitude of the grid center | Centroid of grids | - | All three sectors |
| Latitude | Latitude of the grid center | All three sectors |
| Model | R2 | MAE | RMSE | |
|---|---|---|---|---|
| GDP1 | Random forest | 0.857 | 0.367 | 0.531 |
| XGBoost | 0.851 | 1.404 | 1.889 | |
| LightGBM | 0.865 | 1.476 | 1.998 | |
| Stacking (LR) | 0.892 | 0.345 | 0.497 | |
| Stacking (GWR) | 0.894 | 0.348 | 0.502 | |
| GDP2 | Random forest | 0.963 | 0.296 | 0.402 |
| XGBoost | 0.963 | 0.291 | 0.394 | |
| LightGBM | 0.968 | 0.263 | 0.367 | |
| Stacking (LR) | 0.975 | 0.256 | 0.345 | |
| Stacking (GWR) | 0.976 | 0.253 | 0.329 | |
| GDP3 | Random forest | 0.965 | 0.266 | 0.378 |
| XGBoost | 0.964 | 0.283 | 0.380 | |
| LightGBM | 0.967 | 0.274 | 0.403 | |
| Stacking (LR) | 0.975 | 0.253 | 0.330 | |
| Stacking (GWR) | 0.976 | 0.243 | 0.322 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Wang, Y.; Sun, G.; Chen, Y.; Ma, Q.; Zhang, X. Generating Gridded Gross Domestic Product Data for China Using Geographically Weighted Ensemble Learning. ISPRS Int. J. Geo-Inf. 2023, 12, 123. https://doi.org/10.3390/ijgi12030123
Xu Z, Wang Y, Sun G, Chen Y, Ma Q, Zhang X. Generating Gridded Gross Domestic Product Data for China Using Geographically Weighted Ensemble Learning. ISPRS International Journal of Geo-Information. 2023; 12(3):123. https://doi.org/10.3390/ijgi12030123
Chicago/Turabian StyleXu, Zekun, Yu Wang, Guihou Sun, Yuehong Chen, Qiang Ma, and Xiaoxiang Zhang. 2023. "Generating Gridded Gross Domestic Product Data for China Using Geographically Weighted Ensemble Learning" ISPRS International Journal of Geo-Information 12, no. 3: 123. https://doi.org/10.3390/ijgi12030123