
Model and Data Integrated Transfer Learning for Unstructured Map Text Detection

Abstract
:1. Introduction
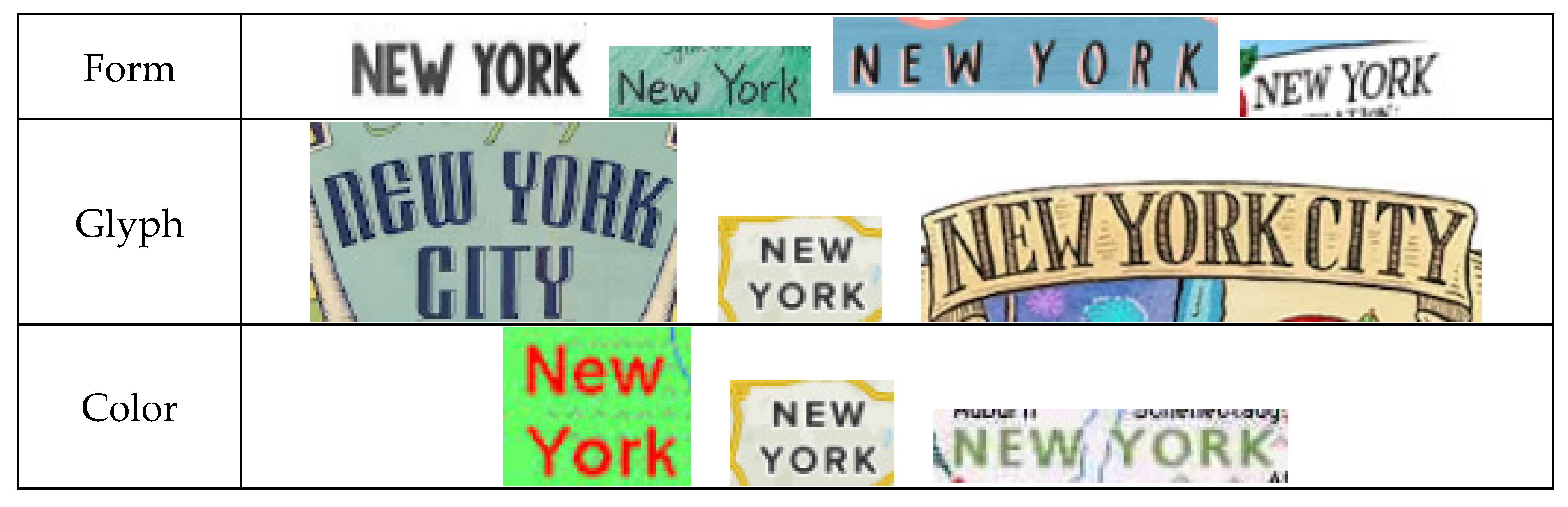
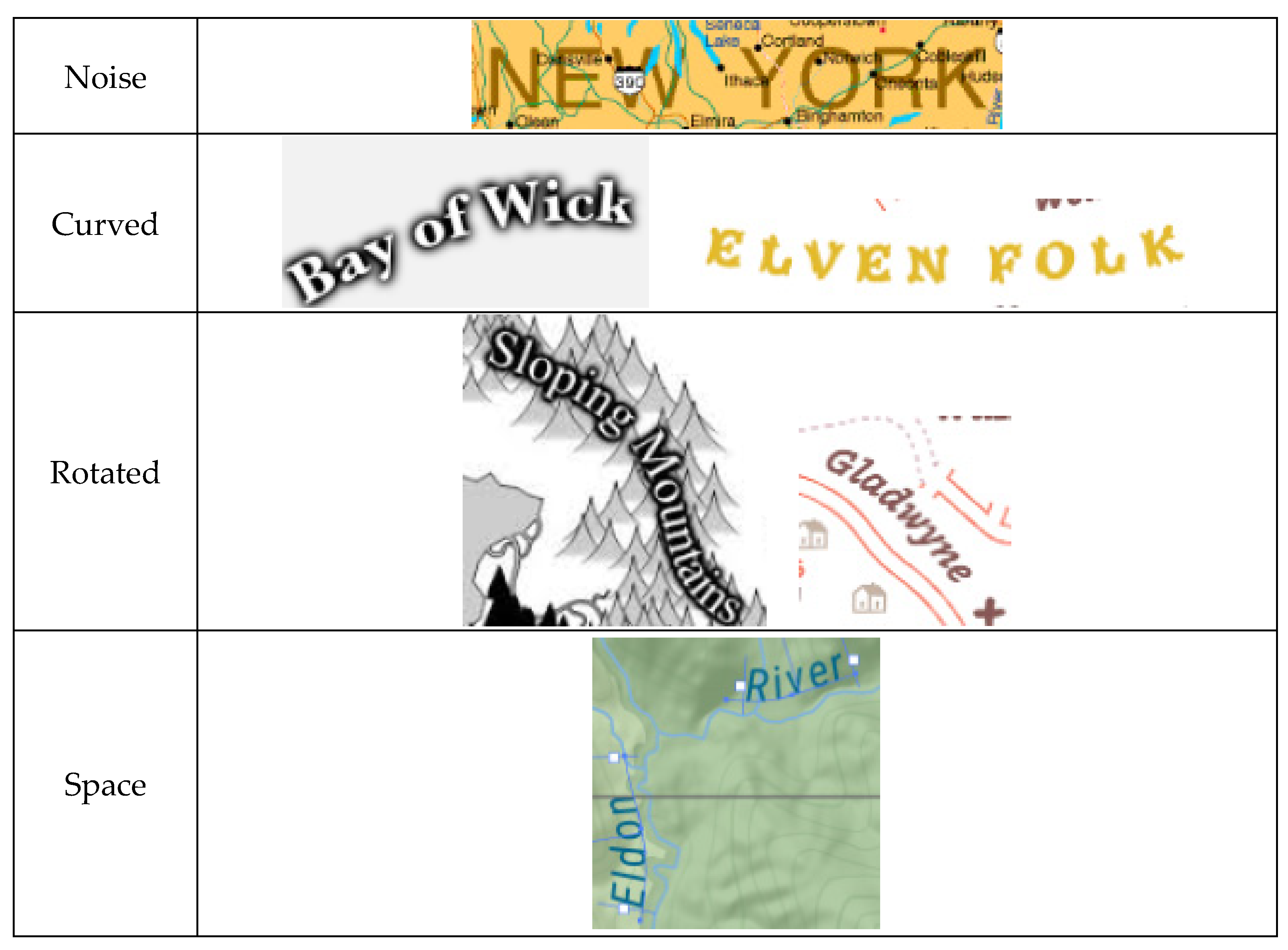
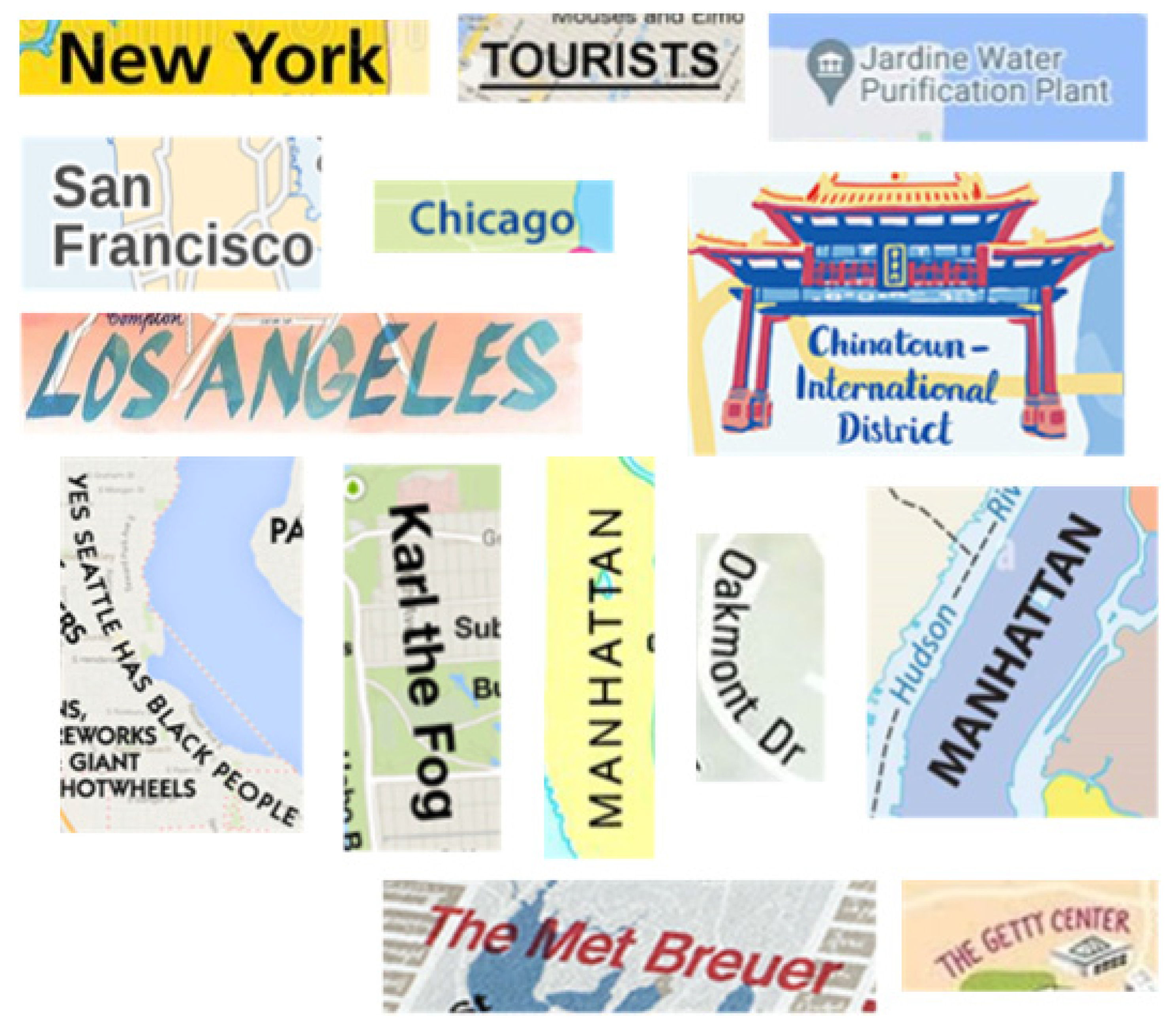
2. Unstructured Map Text from Volunteered Maps
3. Methodology
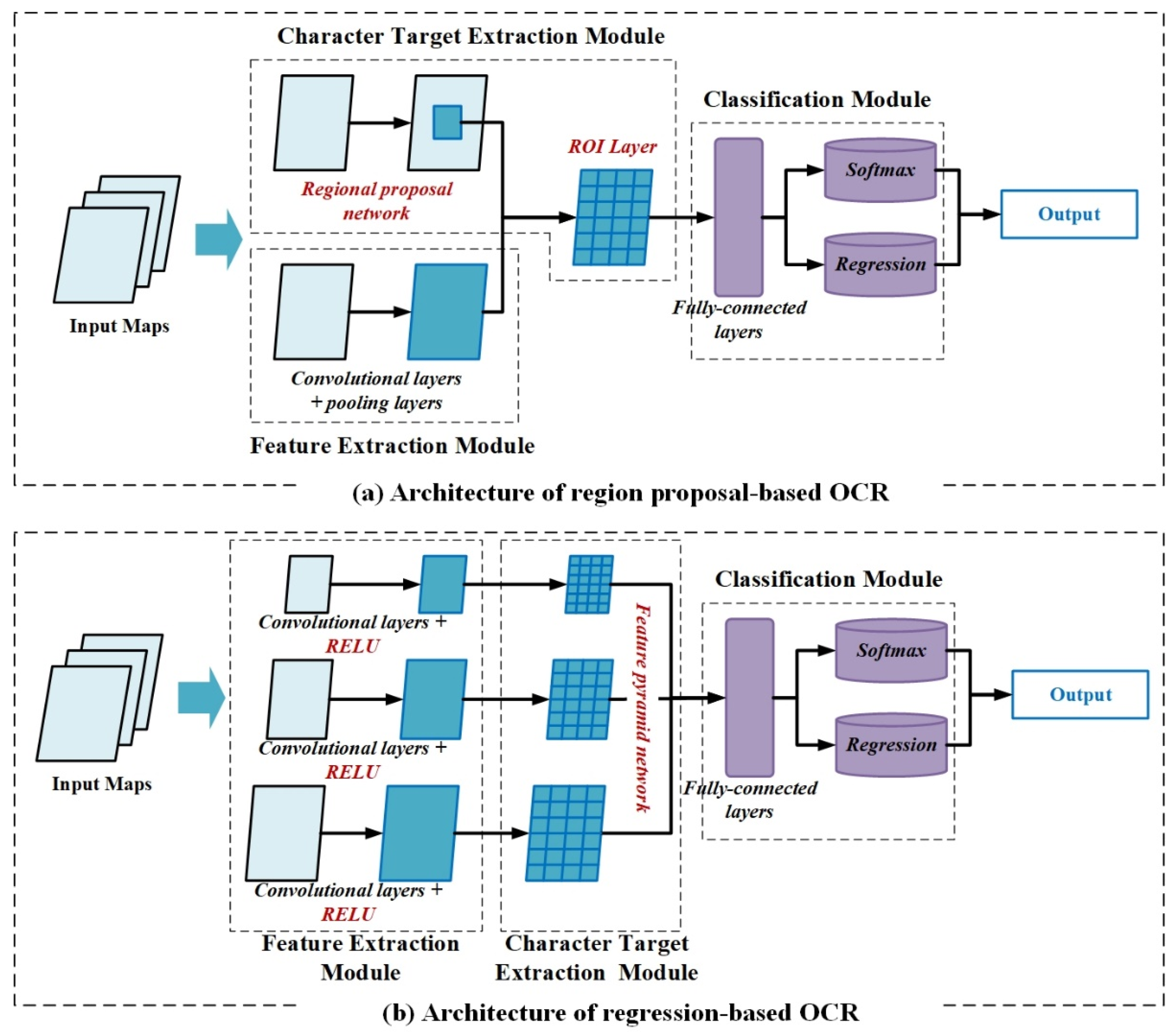
3.1. Basic Architecture of OCR-Powered CNN
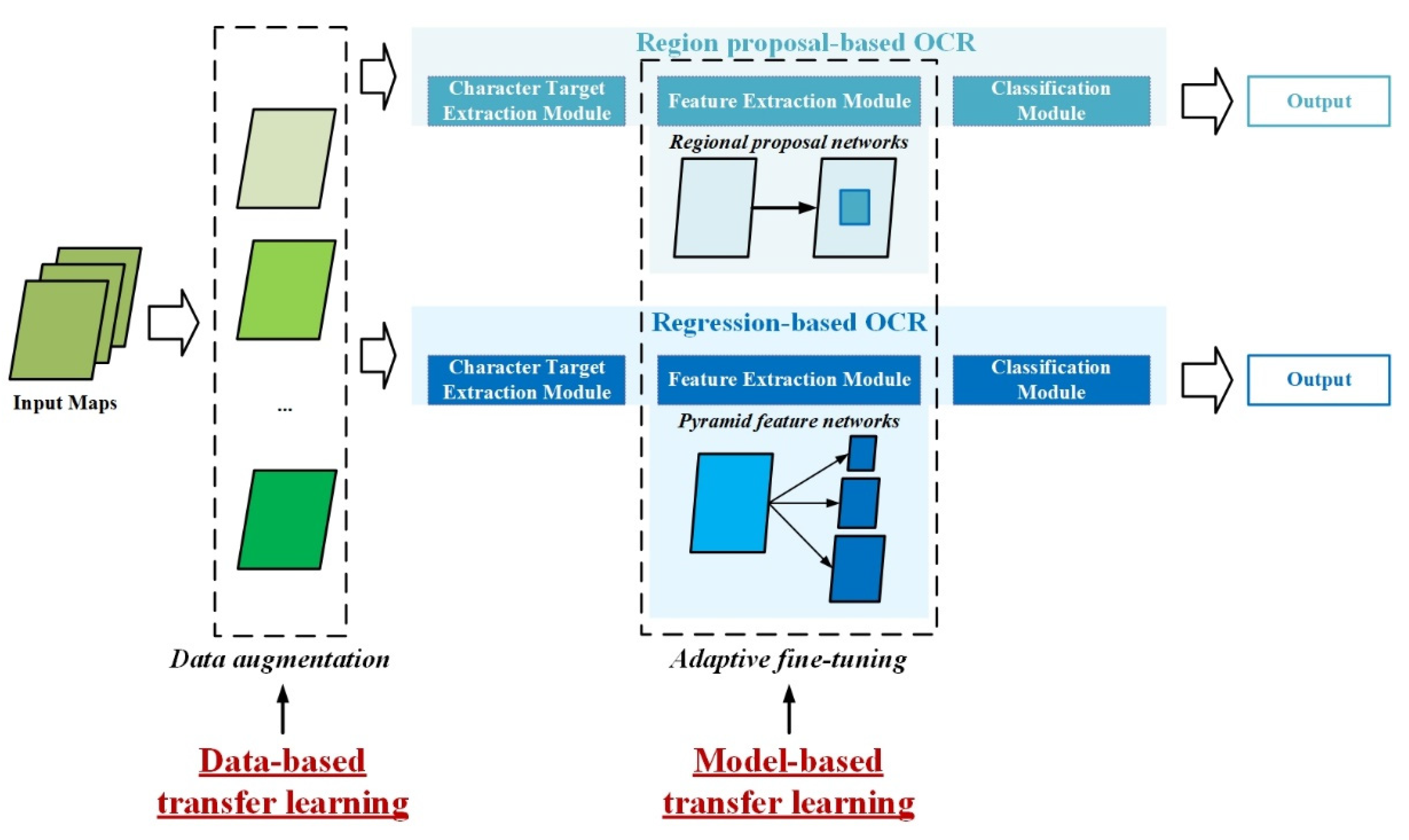
3.2. Model-Based and Data-Based Feature Transferring
- (1)
- Data augmentation for map text
- (2)
- Adaptive fine-tuning
4. Experiment
4.1. Classical OCR-Powered CNN
- (1)
- CTPN (Connectionist Text Proposal Network)
- (2)
- DRRG (Deep Relational Reasoning Graph Network)
- (3)
- EAST (Efficient and Accurate Scene Text Detector)
- (4)
- FCENet
- (5)
- DBNet (DB++)
- (6)
- PSENet
- (7)
- TextSnake
4.2. Dataset and Results
- (1)
- Dataset
- (2)
- Implementations
- CTPN: https://github.com/CrazySummerday/ctpn.pytorch (accessed on 7 February 2023)
- DRRG: https://github.com/GXYM/DRRG (accessed on 7 February 2023)
- EAST: https://github.com/songdejia/EAST (accessed on 7 February 2023)
- FCENet: https://github.com/tamerthamoqa/facenet-pytorch-glint360k (accessed on 7 February 2023)
- DBNet (DB++): https://github.com/WenmuZhou/DBNet.pytorch (accessed on 7 February 2023)
- PSENet: https://github.com/youngguncho/PoseNet-Pytorch (accessed on 7 February 2023)
- TextSnake: https://github.com/princewang1994/TextSnake.pytorch (accessed on 7 February 2023)
- (3)
- Results and discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ballatore, A. Defacing the Map: Cartographic Vandalism in the Digital Commons. Cartogr. J. 2014, 51, 214–224. [Google Scholar] [CrossRef]
- Clarke, K.C.; Johnson, J.M.; Trainor, T. Contemporary American cartographic research: A review and prospective. Cartogr. Geogr. Inf. Sci. 2019, 46, 196–209. [Google Scholar] [CrossRef]
- Chiang, Y.Y.; Knoblock, C.A. Recognizing text in raster maps. Geoinformatica 2015, 19, 1–27. [Google Scholar] [CrossRef]
- Li, H.L.; Liu, J.; Zhou, X.R. Intelligent Map Reader: A Framework for Topographic Map Understanding with Deep Learning and Gazetteer. IEEE Access 2018, 6, 25363–25376. [Google Scholar] [CrossRef]
- Chiang, Y.; Duan, W.; Leyk, S.; Uhl, J.H.; Knoblock, C.A. Creating structured, linked geographic data from historical maps: Challenges and trends. In Using Historical Maps in Scientific Studies; Springer: Berlin/Heidelberg, Germany, 2020; pp. 37–63. [Google Scholar]
- Chiang, Y.Y.; Leyk, S.; Knoblock, C.A. A Survey of Digital Map Processing Techniques. ACM Comput. Surv. 2014, 47, 1–44. [Google Scholar] [CrossRef]
- Miao, Q.G.; Liu, T.G.; Song, J.F.; Gong, M.G.; Yang, Y. Guided Superpixel Method for Topographic Map Processing. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6265–6279. [Google Scholar] [CrossRef]
- Long, S.B.; He, X.; Yao, C. Scene Text Detection and Recognition: The Deep Learning Era. Int. J. Comput. Vis. 2021, 129, 161–184. [Google Scholar] [CrossRef]
- Chiang, Y.Y.; Leyk, S.; Nazari, N.H.; Moghaddam, S.; Tan, T.X. Assessing the impact of graphical quality on automatic text recognition in digital maps. Comput. Geosci. 2016, 93, 21–35. [Google Scholar] [CrossRef]
- Liu, T.E.; Xu, P.F.; Zhang, S.H. A review of recent advances in scanned topographic map processing. Neurocomputing 2019, 328, 75–87. [Google Scholar] [CrossRef]
- Armstrong, M.P. Active symbolism: Toward a new theoretical paradigm for statistical cartography. Cartogr. Geogr. Inf. Sci. 2019, 46, 72–81. [Google Scholar] [CrossRef]
- He, Y.F.; Sheng, Y.H.; Jing, Y.Q.; Yin, Y.; Hasnain, A. Uncorrelated Geo-Text Inhibition Method Based on Voronoi K-Order and Spatial Correlations in Web Maps. ISPRS Int. J. Geo.-Inf. 2020, 9, 381. [Google Scholar] [CrossRef]
- Uhl, J.H.; Leyk, S.; Chiang, Y.Y.; Duan, W.W.; Knoblock, C.A. Automated Extraction of Human Settlement Patterns from Historical Topographic Map Series Using Weakly Supervised Convolutional Neural Networks. IEEE Access 2020, 8, 6978–6996. [Google Scholar] [CrossRef]
- Hu, Y.J.; Gui, Z.P.; Wang, J.M.; Li, M.X. Enriching the metadata of map images: A deep learning approach with GIS-based data augmentation. Int. J. Geogr. Inf. Sci. 2022, 36, 799–821. [Google Scholar] [CrossRef]
- Ory, J.; Christophe, S.; Fabrikant, S.I.; Bucher, B. How Do Map Readers Recognize a Topographic Mapping Style? Cartogr. J. 2015, 52, 193–203. [Google Scholar] [CrossRef]
- Zhou, X. GeoAI-Enhanced Techniques to Support Geographical Knowledge Discovery from Big Geospatial Data. Ph.D. Thesis, Arizona State University , Tempe, AZ, USA, 2019. [Google Scholar]
- Zhuang, F.Z.; Qi, Z.Y.; Duan, K.Y.; Xi, D.B.; Zhu, Y.C.; Zhu, H.S.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Zhou, X.; Li, D.; Xue, Y.; Wan, Y.; Shao, Z. Intelligent Map Image Recognition and Understanding: Representative Features, Methodology and Prospects. Geomat. Inf. Sci. Wuhan Univ. 2022, 47, 641–650. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Tian, Z.; Huang, W.L.; He, T.; He, P.; Qiao, Y. Detecting Text in Natural Image with Connectionist Text Proposal Network. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Volume 9912, pp. 56–72. [Google Scholar]
- Zhang, S.; Zhu, X.; Hou, J.; Liu, C.; Yang, C.; Wang, H.; Yin, X. Deep Relational Reasoning Graph Network for Arbitrary Shape Text Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 9696–9705. [Google Scholar]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. EAST: An Efficient and Accurate Scene Text Detector. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2642–2651. [Google Scholar]
- Zhu, Y.; Chen, J.; Liang, L.; Kuang, Z.; Jin, L.; Zhang, W. Fourier Contour Embedding for Arbitrary-Shaped Text Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3122–3130. [Google Scholar]
- Aroudi, A.; Braun, S. DBnet: Doa-Driven Beamforming Network for end-to-end Reverberant Sound Source Separation. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP–2021), Toronto, ON, Canada, 6–11 June 2021; pp. 211–215. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Hou, W.; Lu, T.; Yu, G.; Shao, S. Shape Robust Text Detection with Progressive Scale Expansion Network. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019; pp. 9328–9337. [Google Scholar]
- Long, S.; Ruan, J.; Zhang, W.; He, X.; Wu, W.; Yao, C. Textsnake: A flexible representation for detecting text of arbitrary shapes. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 20–36. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Benchmark Dataset | Links | Used by OCR Models |
|---|---|---|
| ICDAR 2013 | https://rrc.cvc.uab.es/?ch=2&com=downloads (accessed on 7 February 2023) | CTPN |
| ICDAR 2015 | https://rrc.cvc.uab.es/?ch=4&com=downloads (accessed on 7 February 2023) | CPTN, EAST, FCENet, DB++, TextSnake |
| CTW1500 | https://ctwdataset.github.io/downloads.html (accessed on 7 February 2023) | DRRG, FCENet, DB++, TextSnake |
| MSRA-TD500 | http://www.iapr-tc11.org/mediawiki/index.php/MSRA_Text_Detection_500_Database_%28MSRA-TD500%29 (accessed on 7 February 2023) | DRRG, EAST, DB++, TextSnake |
| Total-Text | https://drive.google.com/file/d/1bC68CzsSVTusZVvOkk7imSZSbgD1MqK2/view?usp=sharing (accessed on 7 February 2023) | DRRG, FCENet, DB++, TextSnake |
| Synth Text | https://www.robots.ox.ac.uk/~vgg/data/scenetext/ (accessed on 7 February 2023) | TextSnake |
| COCO-Text | https://bgshih.github.io/cocotext/ (accessed on 7 February 2023) | EAST |
| MLT-2017 | https://rrc.cvc.uab.es/?ch=8&com=downloads (accessed on 7 February 2023) | DB++ |
| MLT-2019 | https://rrc.cvc.uab.es/?ch=15&com=downloads (accessed on 7 February 2023) | DB++ |
| Map | CTPN | DRRG | EAST | FCENet | DB++ | PSENet | TextSnake |
|---|---|---|---|---|---|---|---|
| 1 | 0.6904 | 0.8095 | 0.6547 | 0.6667 | 0.8095 | 0.8095 | 0.9285 |
| 1+ | 0.7381 | 0.8333 | 0.7023 | 0.6904 | 0.8333 | 0.8333 | 0.9404 |
| 2 | 0.8571 | 0.8214 | 0.8214 | 0.9642 | 0.9285 | 0.9642 | 1 |
| 2+ | 0.9285 | 0.8571 | 0.8928 | 1 | 0.9642 | 0.9642 | 1 |
| 3 | 0.5357 | 0.7589 | 0.4642 | 0.2946 | 0.6964 | 0.7589 | 0.6517 |
| 3+ | 0.5714 | 0.7589 | 0.5 | 0.2946 | 0.7053 | 0.7767 | 0.6607 |
| 4 | 0.6315 | 0.7368 | 0.7105 | 0.728 | 0.7894 | 0.6842 | 0.8859 |
| 4+ | 0.6929 | 0.7543 | 0.7543 | 0.7456 | 0.7982 | 0.7192 | 0.9035 |
| 5 | 0.4869 | 0.8869 | 0.7217 | 0.8173 | 0.8260 | 0.9043 | 0.9304 |
| 5+ | 0.5391 | 0.9826 | 0.8 | 0.8782 | 0.8695 | 0.9304 | 0.9478 |
| 6 | 0.4302 | 0.7325 | 0.5465 | 0.3604 | 0.6511 | 0.6395 | 0.5697 |
| 6+ | 0.4767 | 0.7441 | 0.5930 | 0.4069 | 0.6860 | 0.6627 | 0.5697 |
| 7 | 0.7619 | 0.7142 | 0.7619 | 0.4761 | 0.7142 | 0.8571 | 0.9047 |
| 7+ | 0.8571 | 0.8095 | 0.8095 | 0.523 | 0.7619 | 1 | 0.9047 |
| 8 | 0.6769 | 0.8461 | 0.7692 | 0.8 | 0.8615 | 0.8769 | 0.9384 |
| 8+ | 0.7538 | 0.9076 | 0.8153 | 0.8461 | 0.9230 | 0.9076 | 0.9692 |
| 9 | 0.7457 | 0.7288 | 0.8135 | 0.8305 | 0.8474 | 0.8474 | 0.7796 |
| 9+ | 0.8644 | 0.8305 | 0.8813 | 0.8813 | 0.8983 | 0.8983 | 0.7966 |
| 10 | 0.4363 | 0.8787 | 0.8484 | 0.8848 | 0.8303 | 0.9393 | 0.8182 |
| 10+ | 0.4848 | 0.9151 | 0.8666 | 0.9030 | 0.8484 | 0.9636 | 0.8181 |
| 11 | 0.6019 | 0.9029 | 0.3398 | 0.5048 | 0.6213 | 0.8932 | 0.9514 |
| 11+ | 0.6699 | 0.9708 | 0.3592 | 0.5242 | 0.6310 | 0.9320 | 0.9611 |
| 12 | 0.9583 | 1 | 0.8541 | 0.9167 | 1 | 0.9792 | 0.9792 |
| 12+ | 1 | 1 | 0.875 | 0.9167 | 1 | 0.9792 | 0.9792 |
| 13 | 0.9411 | 0.9558 | 0.9705 | 0.9705 | 0.9852 | 1 | 1 |
| 13+ | 0.9852 | 1 | 1 | 0.9852 | 0.9852 | 1 | 1 |
| 14 | 0.6379 | 0.7931 | 0.6896 | 0.5689 | 0.8965 | 0.7413 | 0.8275 |
| 14+ | 0.6896 | 0.8620 | 0.7068 | 0.5689 | 0.9482 | 0.7931 | 0.8275 |
| 15 | 0.9629 | 0.9629 | 0.9629 | 0.8889 | 0.9629 | 1 | 0.9629 |
| 15+ | 0.9629 | 0.9629 | 0.9629 | 0.8888 | 0.9629 | 1 | 0.9629 |
| avg * | 0.7731 | 0.9179 | 0.8157 | 0.8071 | 0.8907 | 0.9086 | 0.9205 |
| avg+ * | 0.8056 | 0.9388 | 0.8396 | 0.8313 | 0.9048 | 0.9154 | 0.9221 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhai, Y.; Zhou, X.; Li, H. Model and Data Integrated Transfer Learning for Unstructured Map Text Detection. ISPRS Int. J. Geo-Inf. 2023, 12, 106. https://doi.org/10.3390/ijgi12030106
Zhai Y, Zhou X, Li H. Model and Data Integrated Transfer Learning for Unstructured Map Text Detection. ISPRS International Journal of Geo-Information. 2023; 12(3):106. https://doi.org/10.3390/ijgi12030106
Chicago/Turabian StyleZhai, Yanrui, Xiran Zhou, and Honghao Li. 2023. "Model and Data Integrated Transfer Learning for Unstructured Map Text Detection" ISPRS International Journal of Geo-Information 12, no. 3: 106. https://doi.org/10.3390/ijgi12030106