
Grasping Complex-Shaped and Thin Objects Using a Generative Grasping Convolutional Neural Network †

Abstract
:1. Introduction
- We created a new dataset of surgical tools composed of only complex-shaped and thin objects that are usually more difficult to grasp due to the challenging depth estimation resulting from their thinness;
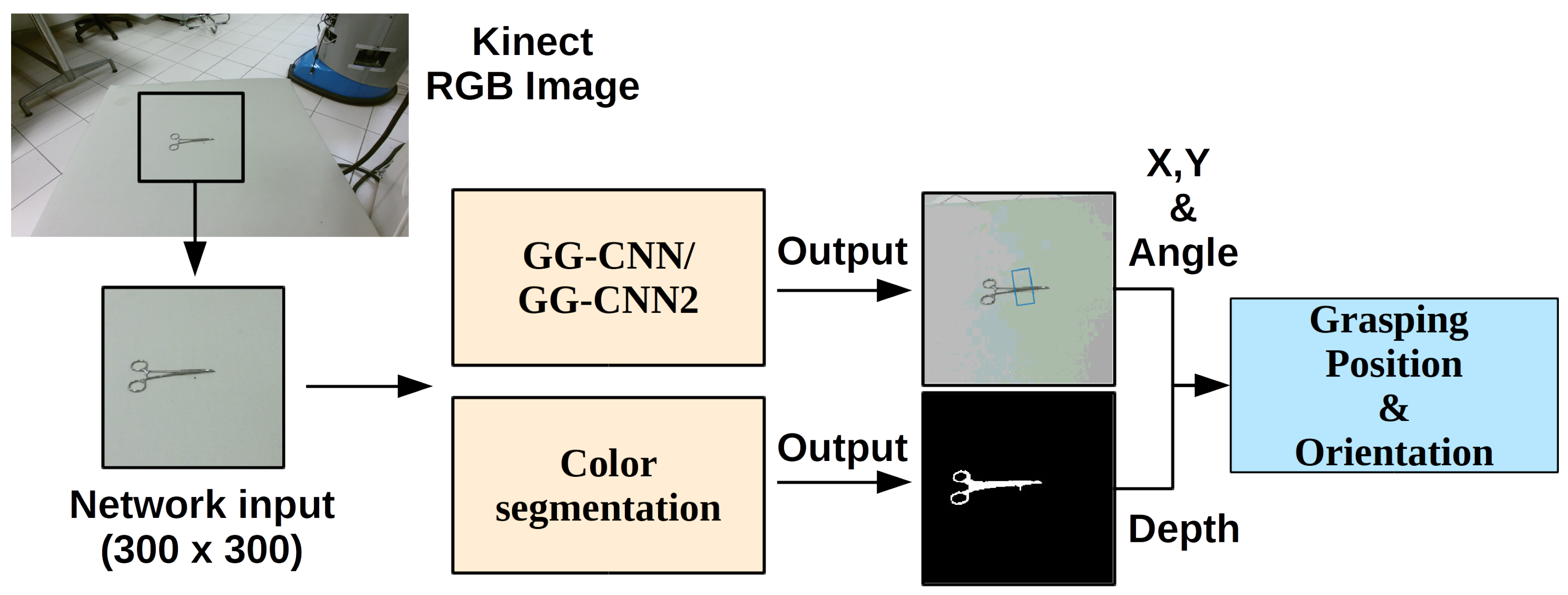
- We proposed an architecture for grasping complex-shaped and thin objects, such as surgical tools, using the GG-CNN/GG-CNN2 with a segmentation method that provides the depth of the surgical tools images;
- We compared the performance of the GG-CNN model with the dataset by applying different encoder–decoder models with GG-CNN/GGCNN2 structures and evaluating the models with the IOU.
- We conducted preliminary experiment tests for validating the GG-CNN architecture for grasping the surgical tools of seen and unseen in noncluttered or cluttered environments.
2. Related Works
Grasp Proposals Using Deep Learning Methods
3. Methods
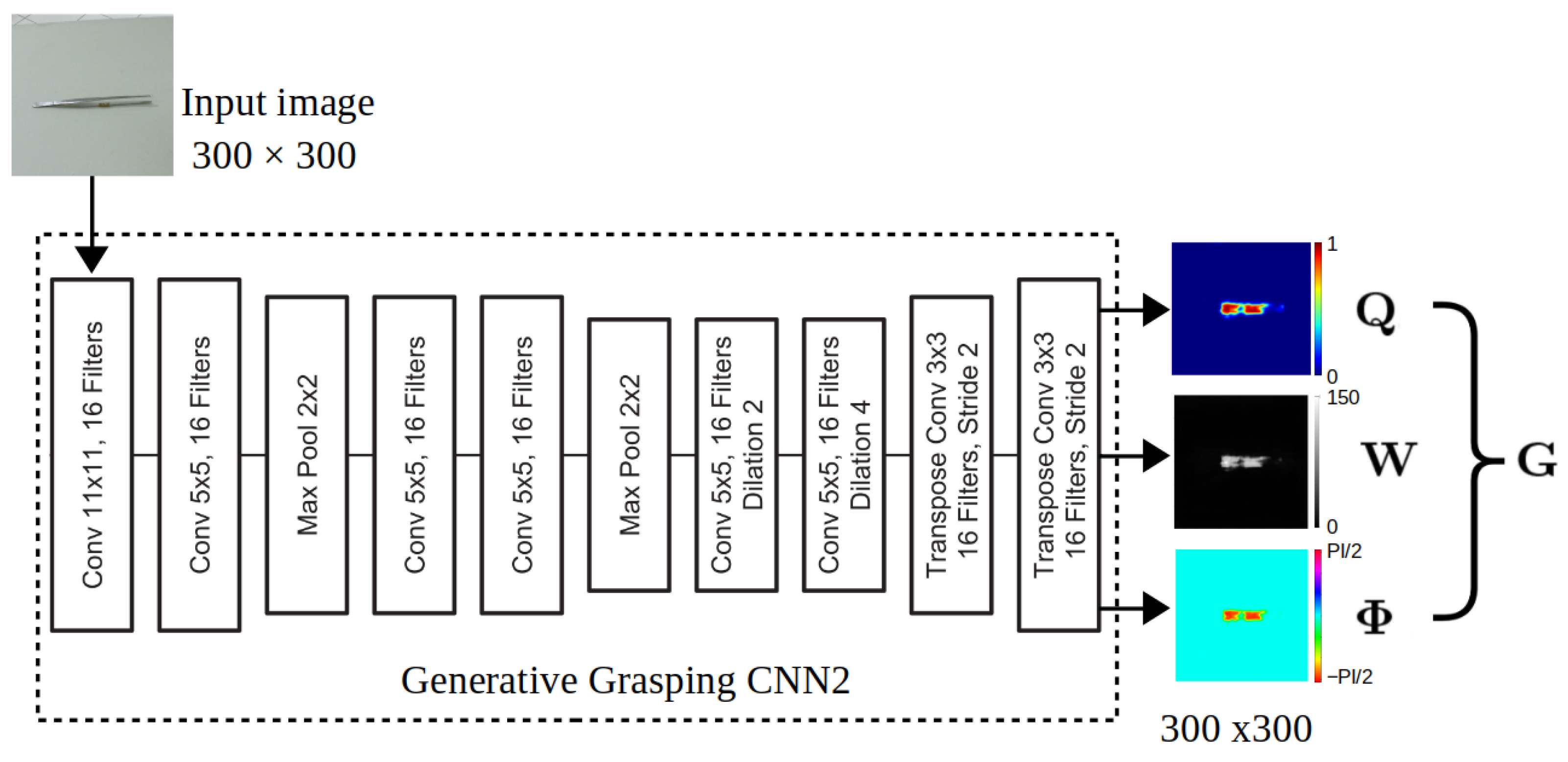
3.1. Grasping Generative Convolutional Neural Network
3.1.1. Contractive Networks
3.1.2. Denoising Networks
3.1.3. Sparse Networks
3.1.4. Variational Autoencoder (VAE) Networks
3.2. Proposed Approach
4. Experimental Setup
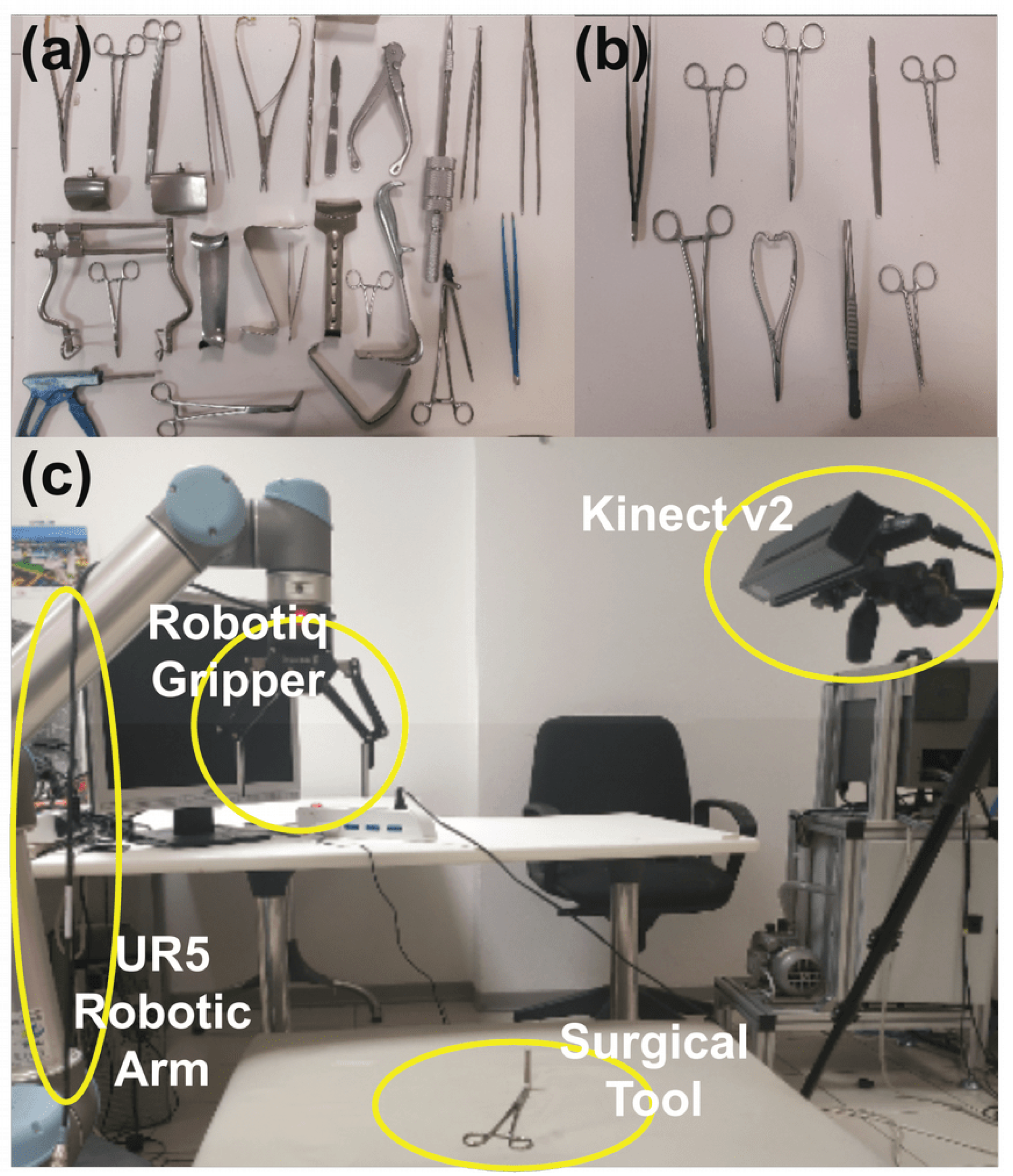
4.1. Datasets
4.2. Experimental Method
5. Experimental Results and Discussions
5.1. Quantitative Results
5.1.1. Network Evaluation
5.1.2. Grasping Single Tool
- Despite using a few variations in the training dataset, this model would still not adapt to novel objects due to limited variations in lighting conditions or other environmental factors.
- This model may struggle with objects that have complex geometries or are occluded, as it relies on a simple geometric grasping position.
- Improving the training dataset by incorporating more diverse object shapes, textures, and sizes.
- Using other types of sensors, such as tactile or additional information, provides the model with more information for grasping [55].
5.2. Qualitative Results
5.2.1. Grasping Multiple Tools
5.2.2. Failure Grasping Examples
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| GG-CNN | Generative Grasping Convolutional Neural Network |
| IOU | Intersection Over Union |
| ORANGE | ORientation AtteNtive Grasp synthEsis |
| GR-ConvNet | Generative Residual Convolutional Neural Network |
| AWGN | Additive White Gaussian Noise |
| VAE | Variational Autoencoder |
| UR | Universal Robot |
References
- Morrison, D.; Corke, P.; Leitner, J. Closing the Loop for Robotic Grasping: A Real-time, Generative Grasp Synthesis Approach. In Proceedings of the Robotics: Science and Systems (RSS), Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar]
- Morrison, D.; Corke, P.; Leitner, J. Learning robust, real-time, reactive robotic grasping. Int. J. Robot. Res. 2020, 39, 183–201. [Google Scholar] [CrossRef]
- Bohg, J.; Morales, A.; Asfour, T.; Kragic, D. Data-driven grasp synthesis—A survey. IEEE Trans. Robot. 2013, 30, 289–309. [Google Scholar] [CrossRef] [Green Version]
- Sahbani, A.; El-Khoury, S.; Bidaud, P. An overview of 3D object grasp synthesis algorithms. Robot. Auton. Syst. 2012, 60, 326–336. [Google Scholar] [CrossRef] [Green Version]
- Mousavian, A.; Eppner, C.; Fox, D. 6-Dof graspnet: Variational grasp generation for object manipulation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2901–2910. [Google Scholar]
- Murali, A.; Mousavian, A.; Eppner, C.; Paxton, C.; Fox, D. 6-Dof grasping for target-driven object manipulation in clutter. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 6232–6238. [Google Scholar]
- Depierre, A.; Dellandréa, E.; Chen, L. Jacquard: A large scale dataset for robotic grasp detection. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 3511–3516. [Google Scholar]
- Detry, R.; Başeski, E.; Krüger, N.; Popović, M.; Touati, Y.; Piater, J. Autonomous Learning of Object-Specific Grasp Affordance Densities. 2009. Available online: https://iis.uibk.ac.at/public/papers/Detry-2009-SLHR.pdf (accessed on 15 January 2023).
- Goldfeder, C.; Allen, P.K.; Lackner, C.; Pelossof, R. Grasp planning via decomposition trees. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Rome, Italy, 10–14 April 2007; pp. 4679–4684. [Google Scholar]
- Miller, A.T.; Knoop, S.; Christensen, H.I.; Allen, P.K. Automatic grasp planning using shape primitives. In Proceedings of the 2003 IEEE International Conference on Robotics and Automation (Cat. No. 03CH37422), Taipei, Taiwan, 14–19 September 2003; Volume 2, pp. 1824–1829. [Google Scholar]
- Saxena, A.; Driemeyer, J.; Ng, A.Y. Robotic grasping of novel objects using vision. Int. J. Robot. Res. 2008, 27, 157–173. [Google Scholar] [CrossRef] [Green Version]
- El-Khoury, S.; Sahbani, A. Handling objects by their handles. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008. number POST_TALK. [Google Scholar]
- Mahler, J.; Matl, M.; Liu, X.; Li, A.; Gealy, D.; Goldberg, K. Dex-net 3.0: Computing robust robot vacuum suction grasp targets in point clouds using a new analytic model and deep learning. arXiv 2017, arXiv:1709.06670. [Google Scholar]
- Zhang, Z.; Zhou, C.; Koike, Y.; Li, J. Single RGB Image 6D Object Grasping System Using Pixel-Wise Voting Network. Micromachines 2022, 13, 293. [Google Scholar] [CrossRef]
- Bicchi, A.; Kumar, V. Robotic grasping and contact: A review. In Proceedings of the Proceedings 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation. Symposia Proceedings (Cat. No. 00CH37065), San Francisco, CA, USA, 24–28 April 2000; Volume 1, pp. 348–353. [Google Scholar]
- Prattichizzo, D.; Trinkle, J.C.; Siciliano, B.; Khatib, O. Springer handbook of robotics. In Grasping; Springer: Berlin/Heidelberg, Germany, 2008; pp. 671–700. [Google Scholar]
- Rubert, C.; Kappler, D.; Morales, A.; Schaal, S.; Bohg, J. On the relevance of grasp metrics for predicting grasp success. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 265–272. [Google Scholar]
- Balasubramanian, R.; Xu, L.; Brook, P.D.; Smith, J.R.; Matsuoka, Y. Physical human interactive guidance: Identifying grasping principles from human-planned grasps. Hum. Hand Inspir. Robot. Hand Dev. 2014, 28, 899–910. [Google Scholar]
- Weisz, J.; Allen, P.K. Pose error robust grasping from contact wrench space metrics. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 557–562. [Google Scholar]
- Ciocarlie, M.; Hsiao, K.; Jones, E.G.; Chitta, S.; Rusu, R.B.; Şucan, I.A. Towards reliable grasping and manipulation in household environments. In Experimental Robotics; Springer: Berlin/Heidelberg, Germany, 2014; pp. 241–252. [Google Scholar]
- Herzog, A.; Pastor, P.; Kalakrishnan, M.; Righetti, L.; Asfour, T.; Schaal, S. Template-based learning of grasp selection. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 2379–2384. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Morrison, D.; Corke, P.; Leitner, J. EGAD! An Evolved Grasping Analysis Dataset for diversity and reproducibility in robotic manipulation. IEEE Robot. Autom. Lett. 2020, 5, 4368–4375. [Google Scholar] [CrossRef]
- Yu, H.; Lai, Q.; Liang, Y.; Wang, Y.; Xiong, R. A Cascaded Deep Learning Framework for Real-time and Robust Grasp Planning. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; pp. 1380–1386. [Google Scholar]
- Wang, S.; Jiang, X.; Zhao, J.; Wang, X.; Zhou, W.; Liu, Y. Efficient fully convolution neural network for generating pixel wise robotic grasps with high resolution images. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; pp. 474–480. [Google Scholar]
- Mahajan, M.; Bhattacharjee, T.; Krishnan, A.; Shukla, P.; Nandi, G. Semi-supervised Grasp Detection by Representation Learning in a Vector Quantized Latent Space. arXiv 2020, arXiv:2001.08477. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Gkanatsios, N.; Chalvatzaki, G.; Maragos, P.; Peters, J. Orientation Attentive Robot Grasp Synthesis. arXiv 2020, arXiv:2006.05123. [Google Scholar]
- Kumra, S.; Joshi, S.; Sahin, F. Antipodal Robotic Grasping using Generative Residual Convolutional Neural Network. arXiv 2019, arXiv:1909.04810. [Google Scholar]
- Sayour, M.H.; Kozhaya, S.E.; Saab, S.S. Autonomous robotic manipulation: Real-time, deep-learning approach for grasping of unknown objects. J. Robot. 2022, 2022, 2585656. [Google Scholar] [CrossRef]
- Xu, R.; Chu, F.J.; Vela, P.A. Gknet: Grasp keypoint network for grasp candidates detection. Int. J. Robot. Res. 2022, 41, 361–389. [Google Scholar] [CrossRef]
- Alliegro, A.; Rudorfer, M.; Frattin, F.; Leonardis, A.; Tommasi, T. End-to-end learning to grasp via sampling from object point clouds. IEEE Robot. Autom. Lett. 2022, 7, 9865–9872. [Google Scholar] [CrossRef]
- Redmon, J.; Angelova, A. Real-time grasp detection using convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1316–1322. [Google Scholar]
- Kumra, S.; Kanan, C. Robotic grasp detection using deep convolutional neural networks. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 769–776. [Google Scholar]
- Park, D.; Chun, S.Y. Classification based grasp detection using spatial transformer network. arXiv 2018, arXiv:1803.01356. [Google Scholar]
- Jiang, Y.; Moseson, S.; Saxena, A. Efficient grasping from rgbd images: Learning using a new rectangle representation. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3304–3311. [Google Scholar]
- Lenz, I.; Lee, H.; Saxena, A. Deep learning for detecting robotic grasps. Int. J. Robot. Res. 2015, 34, 705–724. [Google Scholar] [CrossRef] [Green Version]
- Gu, S.; Rigazio, L. Towards deep neural network architectures robust to adversarial examples. arXiv 2014, arXiv:1412.5068. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.M. A review of image denoising algorithms, with a new one. Multiscale Model. Simul. 2005, 4, 490–530. [Google Scholar] [CrossRef]
- Awad, A. Denoising images corrupted with impulse, Gaussian, or a mixture of impulse and Gaussian noise. Eng. Sci. Technol. Int. J. 2019, 22, 746–753. [Google Scholar] [CrossRef]
- Ling, B.W.K.; Ho, C.Y.F.; Dai, Q.; Reiss, J.D. Reduction of quantization noise via periodic code for oversampled input signals and the corresponding optimal code design. Digit. Signal Process. 2014, 24, 209–222. [Google Scholar] [CrossRef]
- Rajagopal, A.; Hamilton, R.B.; Scalzo, F. Noise reduction in intracranial pressure signal using causal shape manifolds. Biomed. Signal Process. Control. 2016, 28, 19–26. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ilesanmi, A.E.; Idowu, O.P.; Chaumrattanakul, U.; Makhanov, S.S. Multiscale hybrid algorithm for pre-processing of ultrasound images. Biomed. Signal Process. Control. 2021, 66, 102396. [Google Scholar] [CrossRef]
- Liu, B.; Wang, M.; Foroosh, H.; Tappen, M.; Pensky, M. Sparse convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 806–814. [Google Scholar]
- An, J.; Cho, S. Variational autoencoder based anomaly detection using reconstruction probability. Spec. Lect. IE 2015, 2, 1–18. [Google Scholar]
- Coleman, D.; Sucan, I.; Chitta, S.; Correll, N. Reducing the barrier to entry of complex robotic software: A moveit! case study. arXiv 2014, arXiv:1404.3785. [Google Scholar]
- Mahajan, M.; Bhattacharjee, T.; Krishnan, A.; Shukla, P.; Nandi, G.C. Robotic grasp detection by learning representation in a vector quantized manifold. In Proceedings of the 2020 International Conference on Signal Processing and Communications (SPCOM), Bangalore, India, 19–24 July 2020; pp. 1–5. [Google Scholar]
- Feng, K.; Wei, W.; Yu, Q.; Liu, Q. Grasping Prediction Algorithm Based on Full Convolutional Neural Network. J. Phys. Conf. Ser. 2021, 1754, 012214. [Google Scholar] [CrossRef]
- Zhang, C.; Zheng, L.; Pan, S. Suction Grasping Detection for Items Sorting in Warehouse Logistics using Deep Convolutional Neural Networks. In Proceedings of the 2022 IEEE International Conference on Networking, Sensing and Control (ICNSC), Shanghai, China, 15–18 December 2022; pp. 1–6. [Google Scholar]
- Navarro, R. Learning to Grasp 3D Objects Using Deep Convolutional Neural Networks. Ph.D. Thesis, University of Groningen, Groningen, The Netherlands, 2020. [Google Scholar]
- Shukla, P.; Kushwaha, V.; Nandi, G.C. Development of a robust cascaded architecture for intelligent robot grasping using limited labelled data. arXiv 2021, arXiv:2112.03001. [Google Scholar]
- Kim, J.; Cauli, N.; Vicente, P.; Damas, B.; Bernardino, A.; Santos-Victor, J.; Cavallo, F. Cleaning tasks knowledge transfer between heterogeneous robots: A deep learning approach. J. Intell. Robot. Syst. 2020, 98, 191–205. [Google Scholar] [CrossRef] [Green Version]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain randomization for transferring deep neural networks from simulation to the real world. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 23–30. [Google Scholar]
- Maus, P.; Kim, J.; Nocentini, O.; Bashir, M.Z.; Cavallo, F. The Impact of Data Augmentation on Tactile-Based Object Classification Using Deep Learning Approach. IEEE Sensors J. 2022, 22, 14574–14583. [Google Scholar] [CrossRef]
- Zeng, A.; Song, S.; Yu, K.T.; Donlon, E.; Hogan, F.R.; Bauza, M.; Ma, D.; Taylor, O.; Liu, M.; Romo, E.; et al. Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1–8. [Google Scholar]
- Kim, J.; Mishra, A.K.; Radi, L.; Bashir, M.Z.; Nocentini, O.; Cavallo, F. SurgGrip: A compliant 3D printed gripper for vision-based grasping of surgical thin instruments. Meccanica 2022, 1–16. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Batch size | 8 |
| Epochs | 100 |
| Batches per epochs | 1000 |
| Val-batches | 250 |
| Optimizer | Adam |
| Learning rate | 0.001 |
| Loss function | MSE |
| Network | IOU (Max 1) |
|---|---|
| GG-CNN | 0.79 |
| GG-CNN2 | 0.88 |
| Contractive-GG-CNN | 0.78 |
| Contractive-GG-CNN2 | 0.98 |
| Denoising-GG-CNN | 0.41 |
| Denoising-GG-CNN2 | 0.90 |
| Sparse-GG-CNN | 0.73 |
| Sparse-GG-CNN2 | 0.96 |
| VAE-GG-CNN | 0.18 |
| VAE-GG-CNN2 | 0.26 |
| Dataset | Surgical | Cornell | Daily | Jacquard | Restaurant | |
|---|---|---|---|---|---|---|
| Models | ||||||
| GGCNN | 66.36% | 85.39% [48], 88% [49], 91% [1] | 91.45% [50] | 94.14% [51] | ||
| GGCNN2 | 90% | 95.5% [52] | 94% [2] | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Nocentini, O.; Bashir, M.Z.; Cavallo, F. Grasping Complex-Shaped and Thin Objects Using a Generative Grasping Convolutional Neural Network. Robotics 2023, 12, 41. https://doi.org/10.3390/robotics12020041
Kim J, Nocentini O, Bashir MZ, Cavallo F. Grasping Complex-Shaped and Thin Objects Using a Generative Grasping Convolutional Neural Network. Robotics. 2023; 12(2):41. https://doi.org/10.3390/robotics12020041
Chicago/Turabian StyleKim, Jaeseok, Olivia Nocentini, Muhammad Zain Bashir, and Filippo Cavallo. 2023. "Grasping Complex-Shaped and Thin Objects Using a Generative Grasping Convolutional Neural Network" Robotics 12, no. 2: 41. https://doi.org/10.3390/robotics12020041