
Metabolomic Profiling of Bipolar Disorder by 1H-NMR in Serbian Patients
 , , , , , and
, , , , , and
Abstract
:
1. Introduction
2. Materials and Methods
2.1. Sampling and Sample Preparation
2.2. NMR Analysis
2.3. Chemometrics
2.3.1. Software
2.3.2. Reading in Data
2.3.3. Peak Alignment
2.3.4. Data Pretreatment (Preprocessing)
2.3.5. Centering and Scaling
2.3.6. Cross-Validation (CV)
3. Results
3.1. Chemometrics
3.1.1. Exploratory Analysis
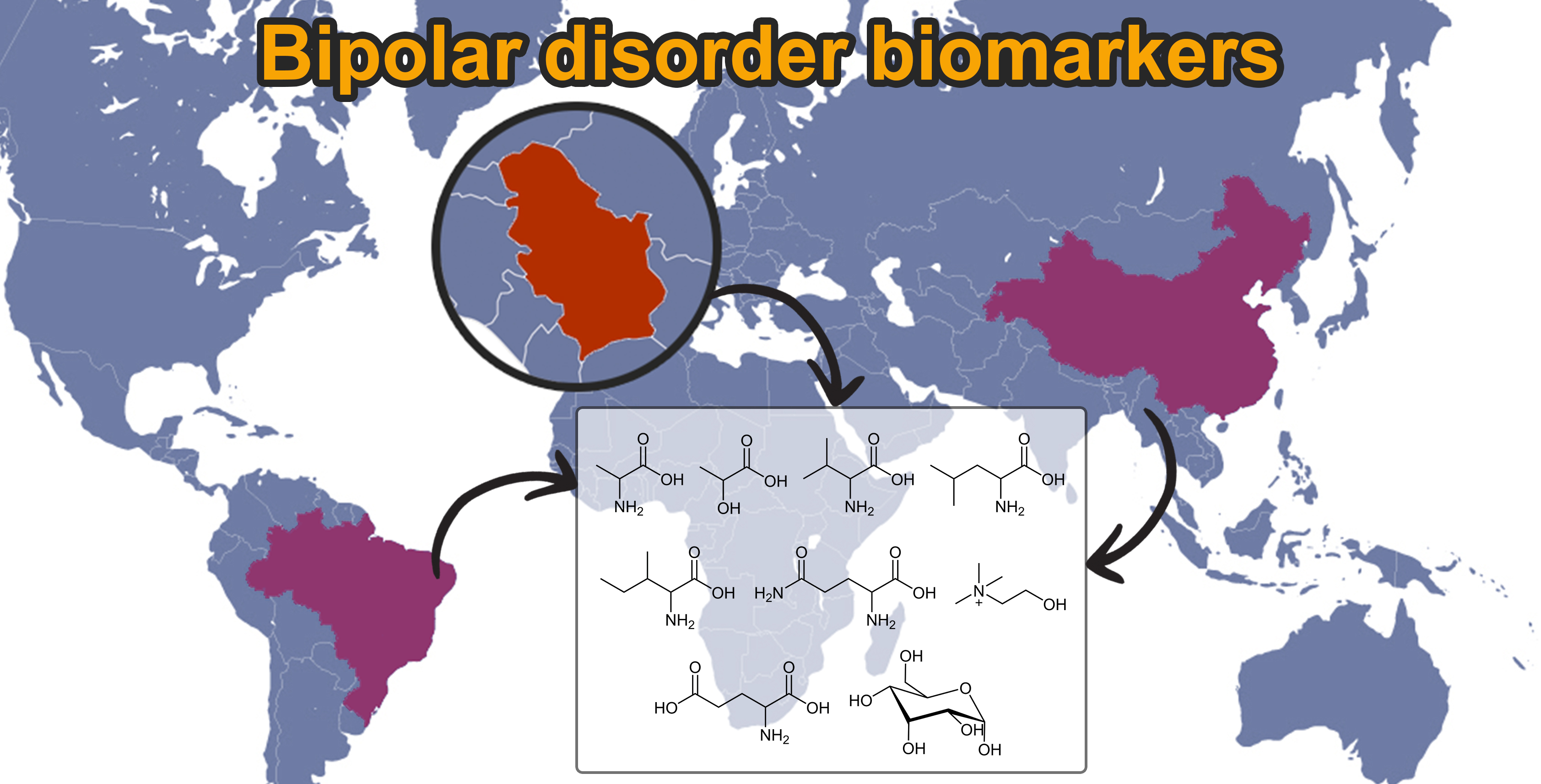
3.1.2. PCA Models
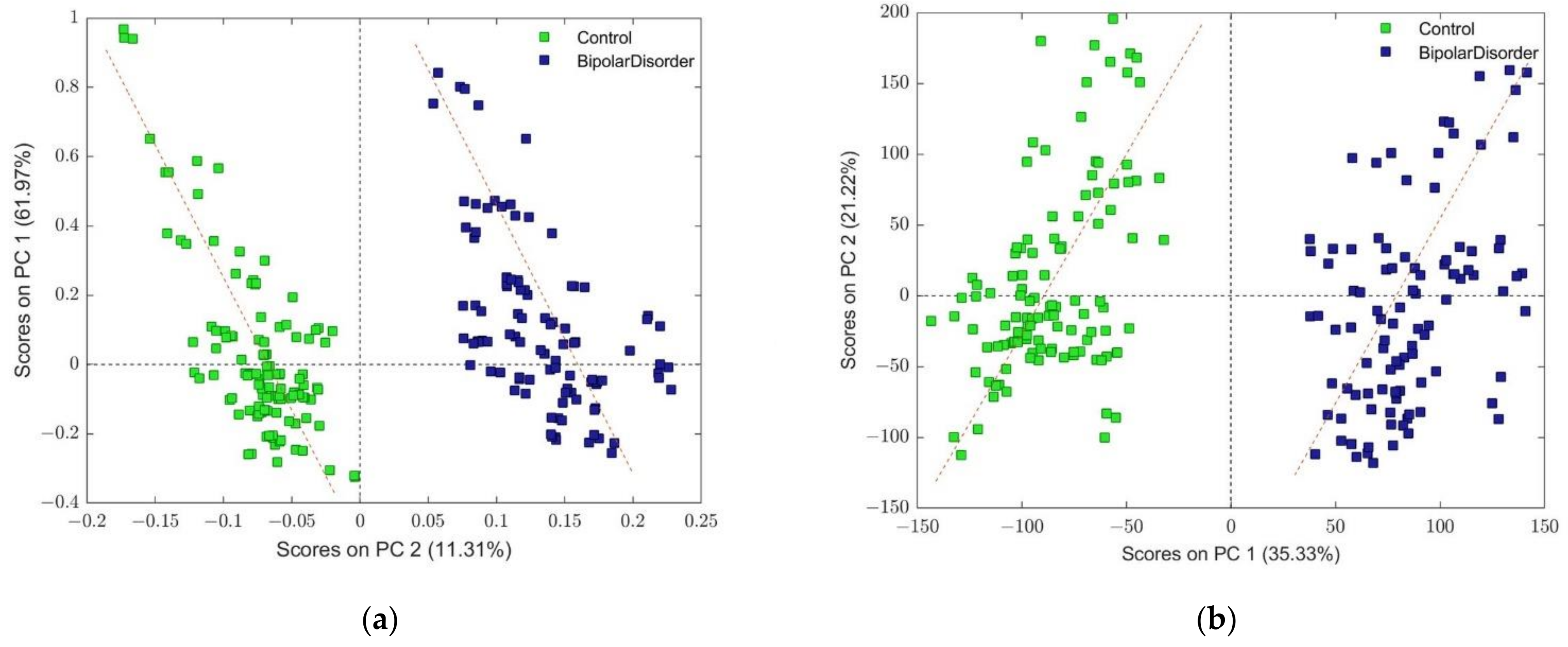
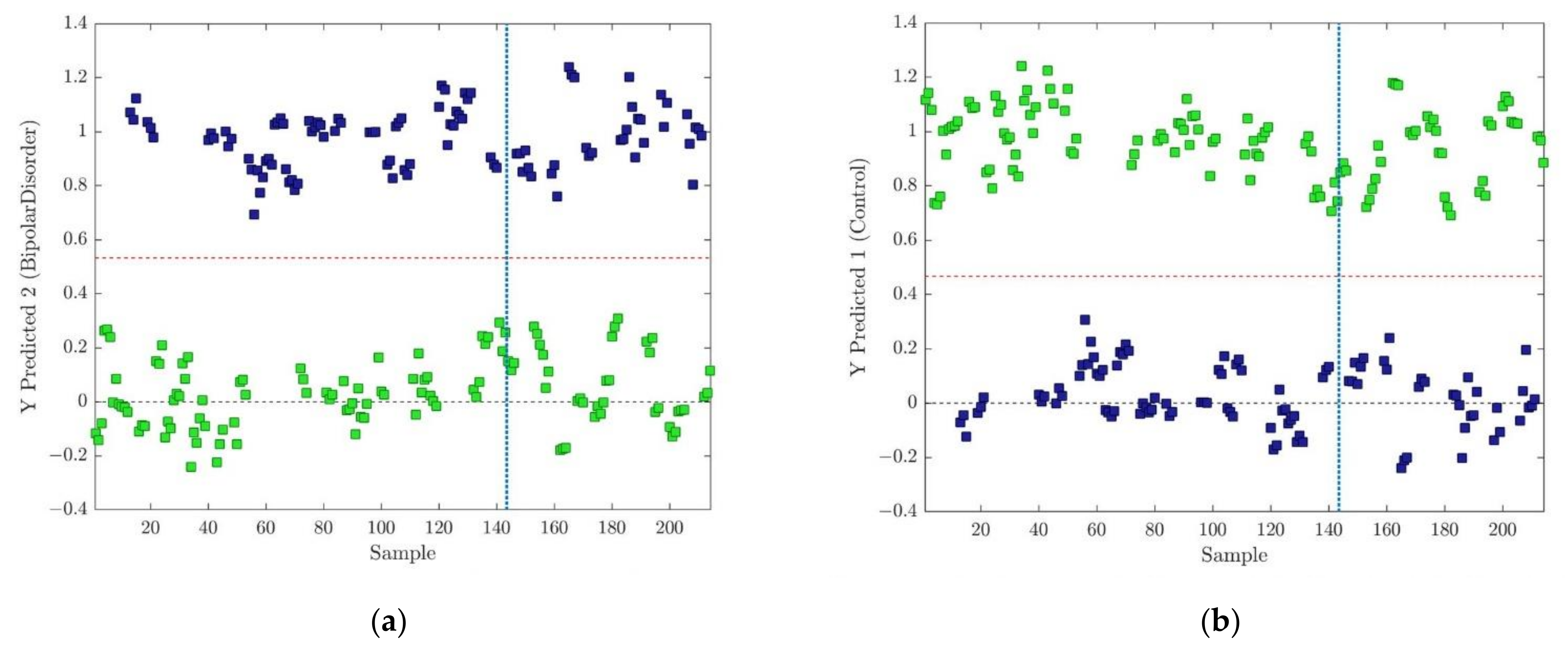
3.1.3. OPLS-DA Models
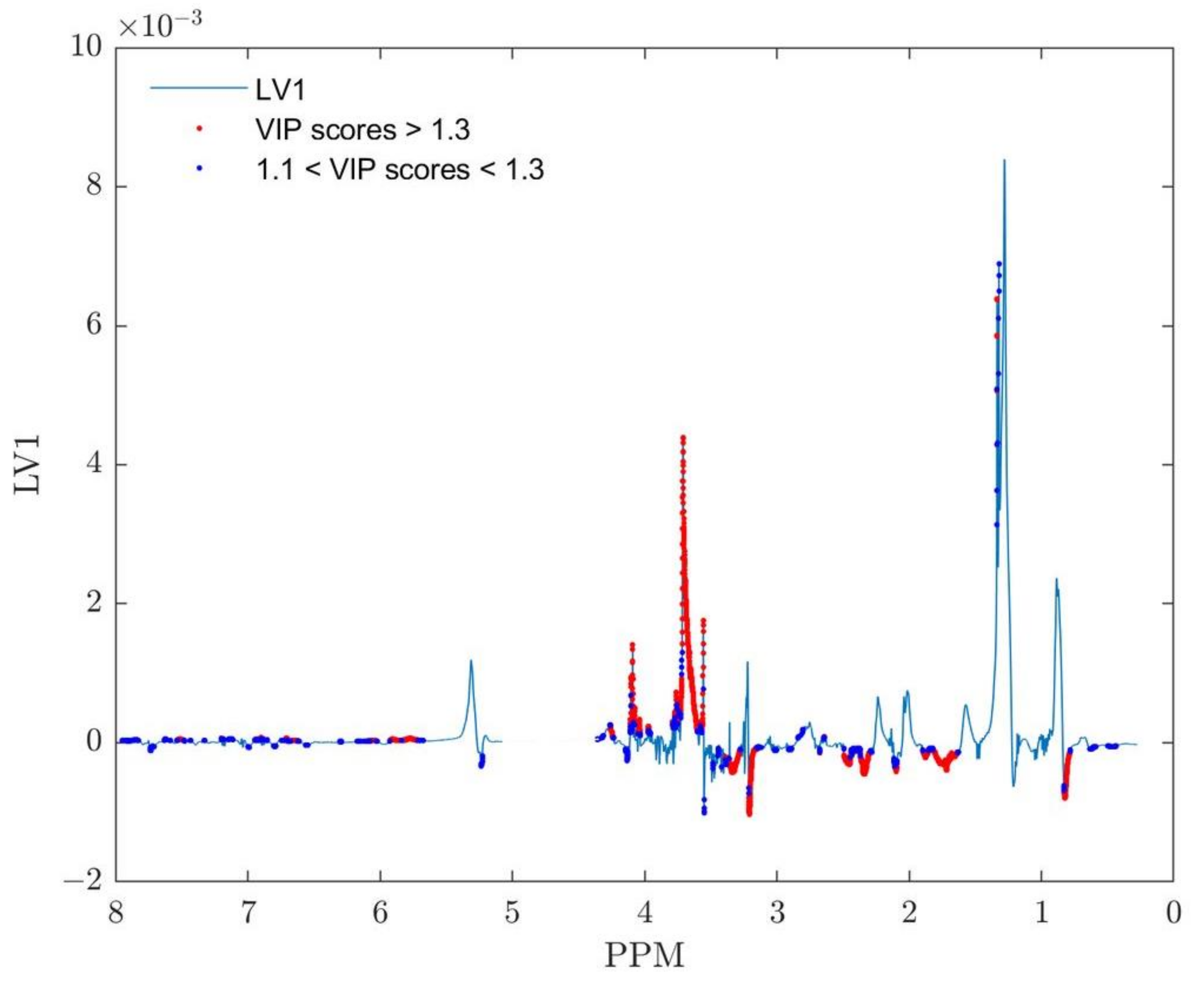
3.1.4. Variable Importance Signature
3.1.5. VIP Scores
3.2. NMR Analyses
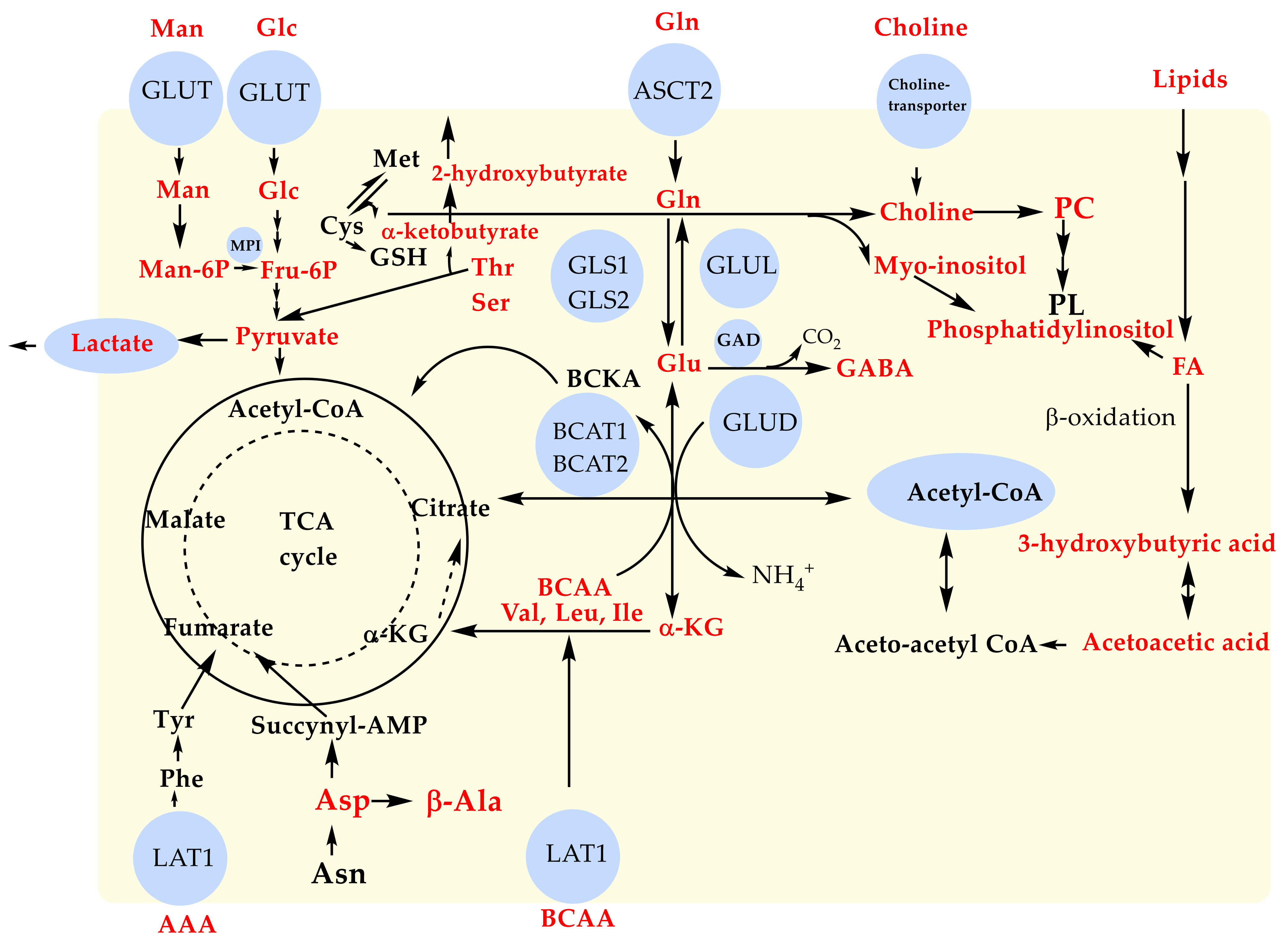
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Goodwin, F.K.; Jamison, K.R. Manic-Depressive Illness: Bipolar Disorders and Recurrent Depression; Oxford University Press: New York, NY, USA, 2007. [Google Scholar]
- Marohn, S. Natural Medicine Guide to Bipolar Disorder; Hampton Roads Publishing Company: Charlottesville, VA, USA, 2011. [Google Scholar]
- Nierenberg, A.A.; Kansky, C.; Brennan, B.P.; Shelton, R.C.; Perlis, R.; Iosifescu, D.V. Mitochondrial modulators for bipolar disorder: A pathophysiologically informed paradigm for new drug development. Aust. N. Z. J. Psychiatry 2013, 47, 26–42. [Google Scholar] [CrossRef] [PubMed]
- Phillips, M.L.; Kupfer, D.J. Bipolar disorder diagnosis: Challenges and future directions. Lancet 2013, 381, 1663–1671. [Google Scholar] [CrossRef] [PubMed]
- Müller-Oerlinghausen, B.; Berghöfer, A.; Bauer, M. Bipolar disorder. Lancet 2002, 359, 241–247. [Google Scholar] [CrossRef] [PubMed]
- Brietzke, E.; Rosa, A.R.; Pedrini, M.; Noto, M.N.; Kapczinski, F.; Scott, J. Challenges and developments in research of the early stages of bipolar disorder. Braz. J. Psychiatry 2016, 38, 329–337. [Google Scholar] [CrossRef]
- Kaddurah-Daouk, R.; Kristal, B.S.; Weinshilboum, R.M. Metabolomics: A global biochemical approach to drug response and disease. Annu. Rev. Pharmacol. Toxicol. 2008, 48, 653–683. [Google Scholar] [CrossRef]
- Johnson, C.; Ivanisevic, J.; Siuzdak, G. Metabolomics: Beyond biomarkers and towards mechanisms. Nat. Rev. Mol. Cell Biol. 2016, 17, 451–459. [Google Scholar] [CrossRef]
- Emwas, A.H.; Roy, R.; McKay, R.T.; Tenori, L.; Saccenti, E.; Gowda, G.A.N.; Raftery, D.; Alahmari, F.; Jaremko, L.; Jaremko, M.; et al. NMR spectroscopy for metabolomics research. Metabolites 2019, 9, 123. [Google Scholar] [CrossRef]
- Pontes, J.G.M.; Brasil, A.J.M.; Cruz, G.C.F.; de Souza, R.N.; Tasic, L. NMR-based metabolomics strategies: Plants, animals and humans. Anal. Methods 2017, 9, 1078. [Google Scholar] [CrossRef]
- Weckwerth, W. Metabolomics: Methods and Protocols; Humana Press: Viena, Austria, 2007; p. 293. [Google Scholar]
- Quinones, M.P.; Kaddurah-Daouk, R. Metabolomics tools for identifying biomarkers for neuropsychiatric diseases. Neurobiol. Dis. 2009, 35, 165–176. [Google Scholar] [CrossRef]
- Quintero Escobar, M.; Costa, T.B.B.C.; Martins, L.G.; Costa, S.S.; Van Helvoort Lengert, A.; Boldrini, E.; da Silva, S.R.M.; Lopes, L.F.; Vidal, D.O.; Krepischi, A.C.V.; et al. Insights in osteosarcoma by proton nuclear magnetic resonance serum metabonomics. Front. Oncol. 2020, 10, 506959. [Google Scholar] [CrossRef]
- Quintero Escobar, M.; Maschietto, M.; Krepischi, A.C.V.; Avramovic, N.; Tasic, L. Insights into the Chemical Biology of Childhood Embryonal Solid Tumors by NMR-Based Metabolomics. Biomolecules 2019, 9, 843. [Google Scholar] [CrossRef]
- Stanisic, D.; Martins, L.G.; Tasic, L. Nuclear Magnetic Resonance Spectroscopy in Analyses of Biological Samples. In Tools and Trends in Bioanalytical Chemistry; Kubota: Zurich, Switzerland, 2022; pp. 203–221. [Google Scholar]
- Takis, P.G.; Ghini, V.; Tenori, L.; Turano, P.; Luchinat, C. Uniqueness of the NMR approach to metabolomics. TrAC Trends Anal. Chem. 2019, 120, 115300. [Google Scholar] [CrossRef]
- Le Guennec, A.; Giraudeau, P.; Caldarelli, S. Evaluation of fast 2D NMR for metabolomics. Anal. Chem. 2014, 86, 5946–5954. [Google Scholar] [CrossRef]
- Zhang, A.; Sun, H.; Wang, X. Serum metabolomics as a novel diagnostic approach for disease: A systematic review. Anal. Bioanal. Chem. 2012, 404, 1239–1245. [Google Scholar] [CrossRef]
- Yoshimi, N.; Futamura, T.; Bergen, S.E.; Iwayama, Y.; Ishima, T.; Sellgren, C.; Ekman, C.J.; Jakobsson, J.; Pålsson, E.; Kakumoto, K.; et al. Cerebrospinal fluid metabolomics identifies a key role of isocitrate dehydrogenase in bipolar disorder: Evidence in support of mitochondrial dysfunction hypothesis. Mol. Psychiatry 2016, 21, 1504–1510. [Google Scholar] [CrossRef]
- Lan, M.J.; McLoughlin, G.A.; Griffin, J.L.; Tsang, T.M.; Huang, J.T.; Yuan, P.; Manji, H.; Holmes, E.; Bahn, S. Metabonomic analysis identifies molecular changes associated with the pathophysiology and drug treatment of bipolar disorder. Mol. Psychiatry 2009, 14, 269–279. [Google Scholar] [CrossRef]
- Chen, J.J.; Zhou, C.J.; Liu, Z.; Fu, Y.Y.; Zheng, P.; Yang, D.Y.; Li, Q.; Mu, J.; Wei, Y.D.; Zhou, J.J.; et al. Divergent urinary metabolic phenotypes between major depressive disorder and bipolar disorder identified by a combined GC-MS and NMR Spectroscopic Metabonomic Approach. J. Proteome Res. 2015, 14, 3382–3389. [Google Scholar] [CrossRef]
- Xu, X.J.; Zheng, P.; Ren, G.P.; Liu, M.L.; Mu, J.; Guo, J.; Cao, D.; Liu, Z.; Meng, H.Q.; Xie, P. 2,4-Dihydroxypyrimidine is a potential urinary metabolite biomarker for diagnosing bipolar disorder. Mol. Biosyst. 2014, 10, 813–819. [Google Scholar] [CrossRef]
- Chen, J.J.; Liu, Z.; Fan, S.; Yang, D.-Y.; Zheng, P.; Shao, W.-H.; Qi, Z.; Xu, X.; Li, Q.; Mu, J.; et al. Combined application of NMR- and GC-MS-based metabonomics yields a superior urinary biomarker panel for bipolar disorder. Sci. Rep. 2014, 4, 5855. [Google Scholar] [CrossRef]
- Sethi, S.; Pedrini, M.; Rizzo, L.B.; Zeni-Graiff, M.; Dal Mas, C.; Cassinelli, A.C.; Noto, M.N.; Asevedo, E.; Cordeiro, Q.; Pontes, J.G.M.; et al. 1H-NMR, 1H-NMR T2-edited, and 2D-NMR in bipolar disorder metabolic profiling. Int. J. Bipolar Disord. 2017, 5, 23–32. [Google Scholar] [CrossRef]
- Tasic, L.; Larcerda, A.L.T.; Pontes, J.G.M.; da Costa, T.B.B.C.; Nani, J.V.; Martins, L.G.; Santos, L.A.; Nunes, M.F.Q.; Adelino, M.P.M.; Pedrini, M.; et al. Peripheral biomarkers allow differential diagnosis between schizophrenia and bipolar disorder. J. Psychiatr. Res. 2019, 119, 67–75. [Google Scholar] [CrossRef] [PubMed]
- Sussulini, A.; Prando, A.; Maretto, D.A.; Poppi, R.J.; Tasic, L.; Muller Banzato, C.E.; Arruda, M.A.Z. Metabolic profiling of human blood serum from treated patients with bipolar disorder employing 1H NMR spectroscopy and chemometrics. Anal. Chem. 2009, 81, 9755–9763. [Google Scholar] [CrossRef]
- Xiangjie, G.; Jiao, J.; Zhiyong, Z.; Yuting, M.; Peng, W.; Yaqin, B.; Yan, R. Metabolomic biomarkers related to non-suicidal self-injury in patients with bipolar disorder. BMC Psychiatry 2022, 22, 491–505. [Google Scholar]
- Ren, Y.; Bao, S.; Jia, Y.; Sun, X.L.; Cao, X.X.; Bai, X.Y.; Tian, J.S.; Yang, H. Metabolic profiling in Bipolar Disorder patients during depressive episodes. Front. Psychiatry 2020, 11, 569612. [Google Scholar] [CrossRef] [PubMed]
- Yoshimi, N.; Futamura, T.; Kakumoto, K.; Salehi, A.M.; Sellgren, C.M.; Holmén-Larsson, J.; Jakobsson, J.; Pålsson, E.; Landén, M.; Hashimoto, K. Blood metabolomics analysis identifies abnormalities in the citric acid cycle, urea cycle, and amino acid metabolism in bipolar disorder. BBA Clin. 2016, 5, 151–158. [Google Scholar] [CrossRef]
- Burghardt, K.J.; Evans, S.J.; Wiese, K.M.; Ellingrod, V.L. An untargeted metabolomics analysis of antipsychotic use in bipolar disorder. Clin. Transl. Sci. 2015, 8, 432–440. [Google Scholar] [CrossRef]
- MathWorks. MathWorks Announces Release 2019a of MATLAB and Simulink. MATLAB. The MathWorks Inc., 2019. Available online: https://www.mathworks.com/products/statistics.html (accessed on 22 March 2022).
- Castañar, L.; Poggetto, G.D.; Colbourne, A.A.; Morris, G.A.; Nilsson, M. The GNAT: A new tool for processing NMR data. Magn. Reson. Chem. 2018, 56, 546–558. [Google Scholar] [CrossRef]
- Savorani, F.; Tomasi, G.; Engelsen, S.B. icoshift: A versatile tool for the rapid alignment of 1D NMR spectra. J. Magn. Reson. 2010, 202, 190–202. [Google Scholar] [CrossRef]
- PLS_Toolbox. Software. 2020. Available online: http://www.eigenvector.com (accessed on 20 March 2023).
- Simić, K.; Todorović, N.; Trifunović, S.; Miladinović, Z.; Gavrilović, A.; Jovanović, S.; Avramović, N.; Gođevac, D.; Vujisić, L.; Tešević, V.; et al. NMR Metabolomics in Serum Fingerprinting of Schizophrenia Patients in a Serbian Cohort. Metabolites 2022, 12, 707–723. [Google Scholar] [CrossRef]
- Sousa, S.A.A.; Magalhães, A.; Ferreira, M.M.C. Optimized bucketing for NMR spectra: Three case studies. Chemom. Intell. Lab. Syst. 2013, 122, 93–102. [Google Scholar] [CrossRef]
- Cloarec, O.; Dumas, M.E.; Trygg, J.; Craig, A.; Barton, R.H.; Lindon, J.C.; Nicholson, J.K.; Holmes, E. Evaluation of the Orthogonal Projection on Latent Structure Model Limitations Caused by Chemical Shift Variability and Improved Visualization of Biomarker Changes in 1H NMR Spectroscopic Metabonomic Studies. Anal. Chem. 2005, 77, 517–526. [Google Scholar] [CrossRef]
- Dieterle, F.; Ross, A.; Schlotterbeck, G.; Senn, H. Probabilistic Quotient Normalization as Robust Method to Account for Dilution of Complex Biological Mixtures. Application in 1H NMR Metabonomics. Anal. Chem. 2006, 78, 4281–4290. [Google Scholar] [CrossRef]
- Molugaram, K.; Rao, G.S. Chapter 1—An Overview of Statistical Applications. In Statistical Techniques for Transportation Engineering; Molugaram, K., Rao, G.S., Eds.; Butterworth-Heinemann: Oxford, UK, 2017; pp. 1–23. [Google Scholar]
- Cloarec, O.; Dumas, M.-E.; Craig, A.; Barton, R.H.; Trygg, J.; Hudson, J.; Blancher, C.; Gauguier, D.; Lindon, J.C.; Holmes, E.; et al. Statistical Total Correlation Spectroscopy: An Exploratory Approach for Latent Biomarker Identification from Metabolic 1H NMR Data Sets. Anal. Chem. 2005, 77, 1282–1289. [Google Scholar] [CrossRef]
- Wiklund, S.; Johansson, E.; Sjöström, L.; Mellerowicz, E.J.; Edlund, U.; Shockcor, J.P.; Gottfries, J.; Moritz, T.; Trygg, J. Visualization of GC/TOF-MS-Based Metabolomics Data for Identification of Biochemically Interesting Compounds Using OPLS Class Models. Anal. Chem. 2008, 80, 115–122. [Google Scholar] [CrossRef]
- Ballabio, D.; Consonni, V. Classification tools in chemistry. Part 1: Linear models. PLS-DA. Anal. Methods 2013, 5, 3790–3798. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principal Component Analysis, Softcover. Reprint of the Hardcover, 2nd ed.; Springer Science and Business Media, LLC: New York, NY, USA, 2010; p. 518. [Google Scholar]
- Bro, R.; Smilde, A.K. Principal component analysis. Anal. Methods 2014, 6, 2812–2831. [Google Scholar] [CrossRef]
- Abdi, H. Factor Rotations in Factor Analyses. In Encyclopedia for Research Methods for the Social Sciences; Lewis-Beck, M., Bryman, A., Futimg, T., Eds.; Sage Publications: Thousand Oaks, CA, USA, 2003; pp. 978–982. [Google Scholar]
- Abdi, H.; Williams, L.J. Principal component analysis: Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Kaiser, H.F. The varimax criterion for analytic rotation in factor analysis. Psychometrika 1958, 23, 87–200. [Google Scholar] [CrossRef]
- PLS-DS—Eigenvector Research Documentation Wiki. Available online: https://wiki.eigenvector.com/index.php?title=Plsda (accessed on 28 September 2022).
- Eriksson, L.; Byrne, T.; Johansson, E.; Trygg, J.; Vikström, C. Multi- and Megavariate Data Analysis Basic Principles and Applications, 1st ed.; Umetrics Academy: Malmö, Sweden, 2013. [Google Scholar]
- Pérez, N.F.; Ferré, J.; Boqué, R. Calculation of the reliability of classification in discriminant partial least-squares binary classification. Chemom. Intell. Lab. Syst. 2009, 95, 122–128. [Google Scholar] [CrossRef]
- Galindo-Prieto, B.; Eriksson, L.; Trygg, J. Variable influence on projection (VIP) for orthogonal projections to latent structures (OPLS). J. Chemom. 2014, 28, 623–632. [Google Scholar] [CrossRef]
- Chong, G.I.; Jun, C.H. Performance of some variable selection methods when multicollinearity is present. Chemom. Intell. Lab. Syst. 2005, 78, 103–112. [Google Scholar] [CrossRef]
- Xu, K.; Wang, M.; Zhou, W.; Pu, J.; Wang, H.; Xie, P. Chronic D-ribose and D-mannose overload induce depressive/anxiety-like behavior and spatial memory impairment in mice. Transl. Psychiatry 2021, 11, 90. [Google Scholar] [CrossRef] [PubMed]
- Maes, M.; Verkerk, R.; Vandoolaeghe, E.; Lin, A.; Scharpé, S. Serum levels of excitatory amino acids, serine, glycine, histidine, threonine, taurine, alanine and arginine in treatment-resistant depression: Modulation by treatment with antidepressants and prediction of clinical responsivity. Acta Psychiatr. Scand. 1998, 97, 302–308. [Google Scholar] [CrossRef] [PubMed]
- Hashimoto, K.; Fukushima, T.; Shimizu, E.; Komatsu, N.; Watanabe, H.; Shinoda, N.; Nakazato, M.; Kumakiri, C.; Okada, S.I.; Hasegawa, H.; et al. Decreased serum levels of D-serine in patients with schizophrenia: Evidence in support of the N-methyl-D-aspartate receptor hypofunction hypothesis of schizophrenia. Arch. Gen. Psychiatry 2003, 60, 572–576. [Google Scholar] [CrossRef]
- Yamada, K.; Ohnishi, T.; Hashimoto, K.; Ohba, H.; Iwayama-Shigeno, Y.; Toyoshima, M.; Okuno, A.; Takao, H.; Toyota, T.; Minabe, Y.; et al. Identification of multiple serine racemase (SRR) mRNA isoforms and genetic analyses of SRR and DAO in schizophrenia and d -serine levels. Biol. Psychiatry 2005, 57, 1493–1503. [Google Scholar] [CrossRef]
- Li, X.; Xu, Z.; Lu, X.; Yang, X.; Yin, P.; Kong, H.; Yu, Y.; Xu, G. Comprehensive two-dimensional gas chromatography/time-of-flight mass spectrometry for metabonomics: Biomarker discovery for diabetes mellitus. Anal. Chim. Acta 2009, 633, 257–262. [Google Scholar] [CrossRef]
- Siegel, G.; Albers, R.W.; Brady, S.; Price, D.L. (Eds.) Basic Neurochemistry: Molecular, Cellular, and Medical Aspects, 2nd ed.; Academic Press: London, UK, 2006. [Google Scholar]
- Pålsson, E.; Jakobsson, J.; Södersten, K.; Fujita, Y.; Sellgren, C.; Ekman, C.J.; Ågren, H.; Hashimoto, K.; Landén, M. Markers of glutamate signaling in cerebrospinal fluid and serum from patients with bipolar disorder and healthy controls. Eur. Neuropsychopharmacol. 2015, 25, 133–140. [Google Scholar] [CrossRef]
- Hsu, J.H.; Chien, I.C.; Lin, C.H. Increased risk of hyperlipidemia in patients with bipolar disorder: A population-based study. Gen. Hosp. Psychiatry 2015, 37, 294–298. [Google Scholar] [CrossRef]
- Holeček, M. Branched-chain amino acids in health and disease: Metabolism, alterations in blood plasma, and as supplements. Nutr. Metab. 2018, 15, 33. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Patients | Control Group | |
|---|---|---|
| Number of samples | 33 | 39 |
| Age in years | 20–74 | 23–60 |
| Sex (male/female) | 14/19 | 27/12 |
| BMI (Body mass index) | 18.5–35.5 | 22.2–33.2 |
| Smoker/non-smoker | 22/11 | 19/20 |
| No | Metabolites/Biomarkers | TOCSY Correlations (δH, ppm) | JRES ((δH (ppm), Multiplicity, J (Hz)) | HSQC (δH/δc (ppm)) |
|---|---|---|---|---|
| 1 | Lactate/lactic acid | 4.10; 1.31 | CH3: 1.31, d, 6.98; CH: 4.10 q, 7.0 | 1.32/22.79, 4.098/71.25 |
| 2 | Threonine | 1.31; 3.56; 4.24 | CH3: 1.32, d, overlapped with lactate; CH: 3.56 d, 5.0; CH2: 4.23 dd, 4.9, 6.6, overlapped with acylglycerol | 1.34/22.54, 3.55/63.42, 4.24 |
| 3 | Leucine | 0.95; 1.71; 3.71 | CH3: 0.94, d, 6.24; CH3: 0.95, d, 6.24 | 0.94/23.41, 0.95/24.72, 1.71/42.70, 3.71 |
| 4 | Valine | 0.98; 1.03; 2.27; 3.62 | CH3: 0.97, d, 7.00; CH3: 1.03, d, 7.00; CH: 3.59 d, 4.39 | 0.97/19.26, 1.02/20.6, 2.27, 3.59/63.27 |
| 5 | Glutamine | 2.12; 2.44; 3.74 | CH2: 2.12 m; CH2: 2.44 m | 2.12/29.27, 2.43/33.61, 3.74/57.11 |
| 6 | Glutamate/glutamic acid | 2.05; 2.35; 3.75 | CH2: 2.04, m and 2.11 m | 2.0/29.68, 2.34/36.28, 3.74/57.11 |
| 7 | Citrate/citric acid | 2.51; 2.68 | CH2: 2.51 d, 16.0; CH2: 2.68 d, 16.0 | - |
| 8 | Aspartate/aspartic acid | 2.68; 2.80; 3.88 | CH2: 2.66, dd, 8.8, 17.5 and 2.80, dd 3.8, 17.4 | 3.80/54.56 |
| 9 | Alanine | 1.46; 3.77 | CH3: 1.46, d, 7.26 | 3.76/53.21 |
| 10 | 3-Hydroxybutyric acid | 1.19; 2.34; 4.12 | CH3: 1.19 d, 6.4; CH2: 2.40, dd, 7.2, 14.4 and 2.29 dd, 6.4, 14.4 | - |
| 11 | Gamma-aminobutyric acid | 1.9; 3.03 | CH2: 3.04, t, 7.6 | - |
| 12 | Choline | 3.50; 4.05 | CH2: 4.05 m | 4.05/58.35 |
| 13 | Glucose (α + β) | 3.40; 3.52; 3.7; 3.75; 5.10; 5.22 | CH-4: 3.40 m; CH-2: 3.52 dd, 3.7, 9.7; CH-3: 3.70 m (overlapped); CH2-6: 3.75 dd, 5.1, 12.0 and 3.83 m; CH-5: 3.82 m; CH-1: 5.22 d, 3.9 | - |
| 14 | Arginine | 4.07; 4.27; 5.20 | 3.23 t, 6.6; 1.70, m and 1.64, m | - |
| 15 | Lysine | 1.70; 1.89; 3.03; 3.74 | 1.91 m | - |
| 16 | 2-Hydroxybutyric acid | - | CH3: 0.88, t, 7.50; CH2: 1.70, m and 1.64, m or arginine | - |
| 17 | Isoleucine | - | CH3: 0.92, t, 7.4; CH3: 0.99, d, 7.0; 3.65 d, 4.04 | - |
| 18 | Serin | - | CH2: 3.97, dd, 3.8, 12.2 and 3.92, dd 5.7, 12.2; CH: 3.82 overlapped | 3.95/62.94, 3.81/59.2 |
| 19 | Mannose | - | CH: 3.55 t, 9.4; CH: 3.79 m; CH: 3.84 dd, 2.2, 4.0; CH: 3.95 m; CH: 5.17, d1.4 | - |
| 20 | Glycerol | - | CH2: 3.64 and 3.55 m; CH: 3.70 m (overlapped) | 3.63 and 3.55/65.31 |
| 21 | Tyrosine | 6.88; 7.18 | CH: 3.96, dd, 5.0, 8.1 or phenylalanine; Ar: 6.88 and 7.18 | 3.95/58.78, Ar: 6.88/118.6, 7.18/133.4 |
| 22 | Phenylalanine | 7.30; 7.36; 7.42 | Ar: 7.30 m, 7.37 m, 7.41 m | Ar: 7.31/132.01, 7.40/131.80 |
| No | Metabolites/Biomarkers | Serbian Serum Samples | Brazilian Serum Samples | Chines Serum Samples | References |
|---|---|---|---|---|---|
| 1 | Lactate/lactic acid | + | + | + | [24,25,26,27] |
| 2 | Threonine | + | − | − | - |
| 3 | Leucine | + | + | + | [24,25,27] |
| 4 | Valine | + | + | + | [24,25,26,27] |
| 5 | Glutamine | + | + | + | [24,25,26,27] |
| 6 | Glutamate/glutamic acid | + | + | + | [24,25,26,27] |
| 7 | Citrate/citric acid | + | − | + | [27] |
| 8 | Aspartate/aspartic acid | + | − | − | - |
| 9 | Asparagine | − | + | − | [26] |
| 10 | Alanine | + | + | + | [24,25,26,27] |
| 11 | 3-Hydroxybutyric acid | + | − | + | [27] |
| 12 | Gamma-aminobutyric acid | + | − | − | - |
| 13 | Choline | + | + | + | [24,26,27] |
| 14 | Glucose | + | + | + | [24,27] |
| 15 | Arginine | + | + | − | [26] |
| 16 | Lysine | + | + | − | [26] |
| 17 | 2-Hydroxybutyric acid | + | − | − | - |
| 18 | Isoleucine | + | + | + | [25,27] |
| 19 | Serin | + | − | − | - |
| 20 | Mannose | + | − | − | - |
| 21 | Glycine | − | + | − | [25] |
| 22 | Glycerol | + | − | + | [27] |
| 23 | Tyrosine | + | + | − | [25] |
| 24 | Phenylalanine | + | + | − | [25] |
| 25 | N-Acetyl-aspartyl-glutamic acid | − | + | − | [24,25] |
| 26 | N-Acetyl-phenylalanine | − | + | − | [24] |
| 27 | Ethanol | − | + | − | [25] |
| 28 | α-ketoglutaric acid | − | + | − | [24] |
| 29 | Lipoamide | − | + | − | [24,26] |
| 30 | Myo-inositol | − | + | + | [24,25,26,27] |
| 31 | Lipids | − | + | − | [24,25,26] |
| 32 | Proline | − | + | − | [24,26] |
| 33 | Glycoprotein lipids | − | + | − | [26] |
| 34 | Acetate | − | + | + | [26,27] |
| 35 | α-ketoisovaleric acid | − | + | − | [24] |
| 36 | Acetoacetate | − | − | + | [27] |
| 37 | Methionine | − | − | + | [27] |
| 38 | Guanidinoacetate | − | − | + | [27] |
| 39 | Uracil | − | − | + | [27] |
| 40 | Histidine | − | + | + | [25,27] |
| 41 | Taurine | − | − | + | [27] |
| 42 | Betaine | − | − | + | [27] |
| 43 | Acetone | − | − | + | [27] |
| 44 | 2,3-diphospho-D-glyceric acid | − | + | − | [25] |
| 45 | monoethyl malonate | − | + | − | [25] |
| 46 | 6-hydroxydopamine | − | + | − | [25] |
| 47 | Acetyl-choline | − | + | + | [25,27] |
| 48 | Fatty acids | − | + | − | [25] |
| 49 | Creatine | − | + | + | [24,25,27] |
| 50 | N-acetyl glycoproteins | − | − | + | [27] |
| 51 | O-acetyl glycoproteins | − | − | + | [27] |
| 52 | Pantothenate | − | − | + | [27] |
| 53 | Dimethylglycine | − | − | + | [27] |
| 54 | Citrulline | − | − | + | [27] |
| 55 | Ascorbate | − | − | + | [27] |
| 56 | HDL | − | − | + | [27] |
| 56 | Pyruvic acid | − | − | + | [27] |
| 58 | Oxidized GSH | − | − | + | [27] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Simić, K.; Miladinović, Z.; Todorović, N.; Trifunović, S.; Avramović, N.; Gavrilović, A.; Jovanović, S.; Gođevac, D.; Vujisić, L.; Tešević, V.; et al. Metabolomic Profiling of Bipolar Disorder by 1H-NMR in Serbian Patients. Metabolites 2023, 13, 607. https://doi.org/10.3390/metabo13050607
Simić K, Miladinović Z, Todorović N, Trifunović S, Avramović N, Gavrilović A, Jovanović S, Gođevac D, Vujisić L, Tešević V, et al. Metabolomic Profiling of Bipolar Disorder by 1H-NMR in Serbian Patients. Metabolites. 2023; 13(5):607. https://doi.org/10.3390/metabo13050607
Chicago/Turabian StyleSimić, Katarina, Zoran Miladinović, Nina Todorović, Snežana Trifunović, Nataša Avramović, Aleksandra Gavrilović, Silvana Jovanović, Dejan Gođevac, Ljubodrag Vujisić, Vele Tešević, and et al. 2023. "Metabolomic Profiling of Bipolar Disorder by 1H-NMR in Serbian Patients" Metabolites 13, no. 5: 607. https://doi.org/10.3390/metabo13050607