1. Introduction
The high-speed railway (HSR) has gradually become one of the most preferred ways for people to travel, because of its convenience, flexibility, and high speed. To better meet passengers’ expectations of a high-quality experience and safe train operation control, the performance demand of communication systems is increasing [
1]. The development of creative communication network designs is essential for the rail transit sector. In the typical scenario of fifth-generation mobile communication technology (5G) [
2], the HSR scenario targets its high data rate, low delay, and low energy consumption. Under the 5G communication system [
3], HSR is designed to provide data transfer rates of 150 Mbps when a mobile speed of up to 500 km/h or higher.
However, HSR scenarios are typical scenarios with continuous wide-area coverage and high mobility [
4], so the characteristics of wireless channels are quite different from those in conventional scenarios. For example, due to the fast mobility and complex terrain [
5,
6], there are Doppler effects in the information transmission process, rapid changes in small-scale fading, and short coherence times. The channel is fast time-varying. These special characteristics make the design of the transmission algorithm of the system more challenging [
7]. In particular, the high-precision channel estimation is more difficult. Therefore, the research of channel estimation in HSR scenarios is an important and challenging technical field [
8].
Moreover, massive multiple-input multiple-output (MIMO) [
9,
10] systems are widely recognized as the foundational elements of 5G technology [
11]. Deploying large-scale antenna arrays at base stations (BS) can greatly improve network capacity and user experience. However, the massive MIMO itself is a technical problem for channel estimation, because it will increase computational complexity. Therefore, the way by which to design a channel estimation algorithm with low computational complexity and simultaneously fit its own architectural features is an issue for a 5G HSR communication system. Traditional channel estimation algorithms cannot effectively solve the above problems.
Generally, traditional channel estimation includes blind channel-estimation methods [
12] and pilot-assisted channel-estimation methods [
13]. For blind channel-estimation methods to count the correlation properties of the channel, a great deal of data is needed, which will lead to slow convergence and high complexity of the algorithm [
14]. In high-mobility environments, blind channel-estimation methods are generally considered infeasible. The reason is that blind channel-estimation methods need to keep the channel characteristics constant in the analysis, while in a high-mobility environment, such as HSR scenarios, the channel will change rapidly in a short time. The pilot-assisted estimation methods need to add auxiliary data to the transmitter, so it will occupy the sending resources of the transmitter. The pilot-assisted estimation methods are usually performed by using algorithms such as least square (LS) [
15] and linear minimum mean square error (LMMSE) to estimate the CSI in the frequency domain at the pilot frequency symbols [
16,
17,
18]. The channel frequency response (CFR), however, is often assumed by these approaches to fluctuate linearly. High-speed movement of the terminals will introduce a Doppler effect in HSR scenarios, which causes the CFR to change rapidly. At the same time, the Doppler effect will seriously affect the effectiveness of the estimation algorithm and lead to the degradation of the estimation performance. Therefore, in order to ensure extreme user experience (100 Mbit/s) and safe train operation control for the 5G HSR communication systems, channel-estimation technology that adapts to fast time-varying channels and massive MIMO systems should be paid more attention.
The development of deep learning (DL) technology has led to satisfactory results in the field of communication [
19]. It has shown excellent performace in signal detection [
20], channel coding [
21], signal classification [
22], and CSI feedback [
23]. Some researchers also apply DL to channel estimation. One type is the direct use of neural networks to learn the various characteristics of the channel and then estimate the complete CSI from the pilot sequence signal. In [
24], the approaches for massive MIMO systems forecast channels much more accurately than conventional channel-estimation algorithms. In [
25], a deep neural network-based online estimation method is adopted for dual selective fading channels. A channel-estimation method based on DL in the high mobile environment is proposed and the maximum pooling network is used to reduce the dimension of the parameters in [
26]. In [
27,
28], a neural network channel-estimation optimizer based on the MIMO-OFDM system to optimize the LS algorithm was proposed. The other type is to treat the CSI as an image and use image-processing techniques to recover the channel. In [
29], the idea of treating the channel matrix as a two-dimensional (2D) natural image and combining it with image-reconstruction techniques for channel estimation is proposed for the first time. In [
30], a wideband channel-estimation method based on a generation countermeasure network (GAN) is proposed. Furthermore, it is noted that the estimator based on GAN can lower the necessary pilot’s requirement without noticeably raising the error and necessary signal-to-noise-ratio (SNR). In [
31], conditional GAN (cGAN) is used as channel estimation, where the generator estimates the channel from the pilot signal received by the BS. Although the aforementioned research uses deep learning to address channel-estimation issues in a variety of communication systems, it does not adequately account for the effects of rapidly changing surroundings on large MIMO systems [
32].
Additionally, it is worth noting that environmental noise is a critical factor that can significantly impact the quality of channel estimation. Therefore, for denoising channel estimation algorithms, the pilot signals at the receivers before estimation can also improve the estimation quality [
33]. Due to the convolutional neural network (CNN)’s strong performance in image-recognition and processing tasks, more and more studies have applied CNN-based image denoising algorithms to design channel-estimation methods. In this kind of research, the receiver’s channel matrix and pilot matrix are frequently seen as images. More specifically, an image can be represented by a complex number of real and imaginary parts, respectively. In [
34], supervised learning is utilized in denoising CNN (DnCNN), which involves learning the residual noise from noisy channels. Then, to get residual noise, the channel generated from the rough estimate is fed into the trained DnCNN. Finally, the rough estimation channel is subtracted from the residual noise to obtain more accurate estimation results. Similar to how it was used to analyze the rough estimates of the channel to get a more precise estimation, DnCNN is also employed as the denoising network in [
35].
To enhance the channel estimation accuracy in the high-speed railway (HSR) environment of massive MIMO systems, we propose a N2N-cGAN channel-estimation algorithm that combines the WINNER II D2a channel model [
36] with image-denoising technology. In N2N-cGAN, both the denoising network and the generator network adopt the U-Net network structure, which can effectively capture and utilize the spatial dependencies in the input data to better meet the requirements of channel-estimation tasks. The discriminator uses a CNN and a patch architecture to distinguish between the input real channel information and the generated channel information. Specifically, we consider a predenoising channel estimation strategy for channel estimation. The channel-estimation process has two stages. In the first stage, the pilot signal is treated as an image, and a novel image denoising method, N2N [
37] is proposed. Unlike traditional denoising methods, N2N does not require an accurate noise model or a clean reference image. It achieves high-quality denoising by learning the general ability to remove noise from multiple noise samples during training, with strong robustness and versatility. In the second stage, we use cGAN to estimate the channel. Compared with other traditional methods, this cGAN-based channel-estimation method can better utilize the characteristics and structure of channel estimation data, thereby improving estimation accuracy. Due to the parallel nature of these two stages, the training speed can be significantly accelerated. The contributions of this paper can be summarized as follows.
The N2N algorithm does not need a noiseless signal as a training target. Moreover, the outcomes are more manageable because it is end-to-end training. Therefore, in order to reduce the error of channel estimation, the received pilot signal is denoised by using the N2N method before channel estimation.
The cGAN structure’s GAN loss improves the neural network’s optimization [
38], thereby enabling our channel-estimation method to perform well even in low SNR conditions.
Numerous simulation results demonstrate how our proposed algorithm may successfully lower the channel estimate error and improve system performance in HSR circumstances, even with very short pilot sequence sequences.
The rest of this paper is organized as follows:
Section 2 presents system and channel model.
Section 3 presents the proposed N2N-cGAN-based channel-estimation algorithm. Simulation results are provided in
Section 4, and conclusions are shown in
Section 5.
3. Channel Estimation Based on N2N-cGAN
This section introduces a channel-estimation approach based on N2N-cGAN. First, the main idea is briefly explained. The suggested N2N-cGAN algorithm’s framework is then further detailed. Finally, a network architecture is proposed.
3.1. The Main Idea
The N2N-cGAN algorithm mainly includes two steps: first, the pilot picture that the BS receives is denoised by using the N2N denoising algorithm. Then the pilot image after denoising is used to estimate the channel image based on cGAN network.
3.1.1. N2N Denoising
The relationship between noise and image can be divided into three forms:
a represents high-quality image,
b represents noisy image, and
n represents noise. Image denoising aims to eliminate the noise
n from the noisy image
that degrades the image quality. Traditional denoising algorithms usually train the CNN to model from noisy input image
b to clean output image
a. However, the N2N method is distinct from most denoising algorithms in this regard. The N2N algorithm simply needs clean images corresponding to noisy images with independent noise to compose training data and then trains CNN to learn how to map one noisy image to another. Obviously, N2N cannot completely learn the mapping connection between noisy pictures because noise
n and
are independent of one another. However, the neural network trained on this impossible task can obtain the same denoising effect as the neural network trained by the traditional denoising algorithm using clean images. Therefore, in this case, a clean image is unable to be obtained. N2N only needs a clean image corresponding to a noisy image with independent noise, the neural network training can produce good denoising effects. The N2N denoising algorithm’s optimization goal is
where
and
are different noisy images,
is a parameter
mapping function, and
is the loss function.
3.1.2. cGAN Network
The conventional GAN is an adversarial learning framework used to train a generative model, which involves a generator
and a discriminator
. To create extremely realistic pictures, the
is trained to produce samples that are similar to real data, while the
is trained to differentiate between the real and generated samples. The
is updated based on the feedback from the
, and the discriminator is updated based on the difference between real and generated data. However, the
is trained to map random noise to the real data distribution, which can introduce instability and randomness in the generated samples. Therefore, cGAN was proposed. In order to establish the mapping between conditional input and real data, it introduced a conditional variable
y. Specifically, in order to direct the data creation process, cGAN incorporates condition variable
y in the modeling of the
and the
. In
, the input to the generator is formed by combining the noise variable
z with the conditional information
y. In the
, the input is the combination of real data
x and conditional information
y or the generated data
output by the generator.
estimates the probability that its input
is a real one, given the dataset. A definition of the cGAN’s objective function is
It is possible to produce data based on the new inputs of z and y after the trained is acquired.
3.2. N2N-cGAN-Based Channel Estimation
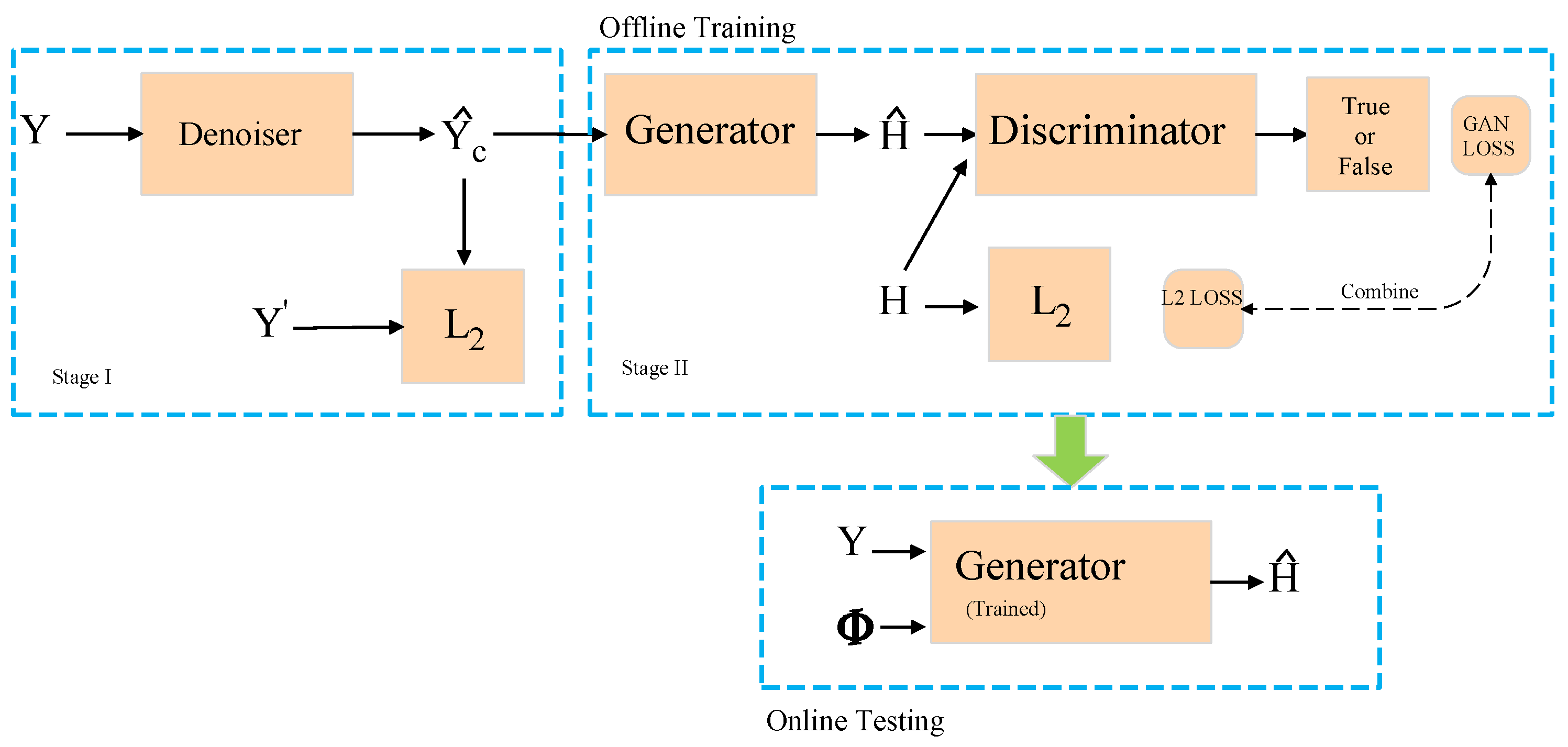
According to
Figure 3, the N2N-cGAN channel-estimation process consists of two stages. Stage I sees the denoising device apply the N2N algorithm (i.e., training only using the noisy pilot image.). Since our training dataset contains a portion of the real channel, we can construct a clean pilot signal at the receiver side by using Equation (
16). In each round of training for the denoising device, we randomly select a clean pilot image from the training dataset, after which the clean pilot picture is separately sampled, and two AWGNs of equal size are then added. Different signal-to-noise ratios (SNRs) might contribute to the noise power, which can be added to the pilot image to form two noisy pilot images
Y and
. In the actual scenarios, the pilot signal can also be sent many times in a coherent time. The pilot signals received by the BS can be regarded as multiple independent noisy versions from the same clean pilot. With two noisy images,
Y is input to the denoiser to obtain
, where
denotes the denoiser with parameter
. In the training process, we have employed the
loss function, which is expressed as
In the N2N algorithm, a CNN trained with an L2 loss function can learn the mapping relationship from a noisy image to a noise-free image and reconstruct a clear image. Specifically, L2 loss measures the difference between the CNN output and the target, and the process of minimizing L2 loss is essentially minimizing the difference. From a formulaic point of view, the L2 loss function has a square term, which can effectively penalize the difference between the CNN output and the target, thus helping to remove noise. Compared with L1 loss, L2 loss is smoother and continuous, so it can better deal with image-denoising problems. Using L2 loss function in N2N algorithm can help CNN learn to minimize pixel-level differences between images and realize image denoising and clear image reconstruction.
Finally, the denoiser is trained by using the Adam algorithm [
40]. When the training is completed, the denoising device is employed to process the noisy pilot image in the test dataset, which outputs the corresponding denoising results.
In stage II, we use cGAN for estimation. The
generates the estimating channel by using the
, while
distinguishes between the real channel and the one generated by the
. During each training iteration, a
is randomly selected from the training dataset to serve as the input to
. The output of
with parameters
, denoted as
, is then obtained. Then, the discriminator
with the input parameters of channel
H and
generating
as
is generated, and the discriminator’s output is used to determine whether the input channel image is genuine or produced by the generator. After training is finished, the generator takes the denoised pilot from stage I and produces the estimation results for the relevant channel. Finally, the two components of the cGAN’s objective function are as follows,
where cGAN objective function is a minimax game problem with conditional probability. It can be expressed as
When using
loss, the resulting picture is represented as follows to ensure that it matches the original image in pixels:
The procedure of the proposed N2N-cGAN channel-estimation algorithm is summarized in Algorithm 1.
In this paper, during training, stages I and stages II can be trained separately in parallel. During deployment, the received pilot signal at the BS is input to the denoiser, and the output of the denoiser is then fed to the generator, which generates an estimated channel image. Finally, the estimated channel is obtained by converting the channel image to complex values.
3.3. Network Architecture
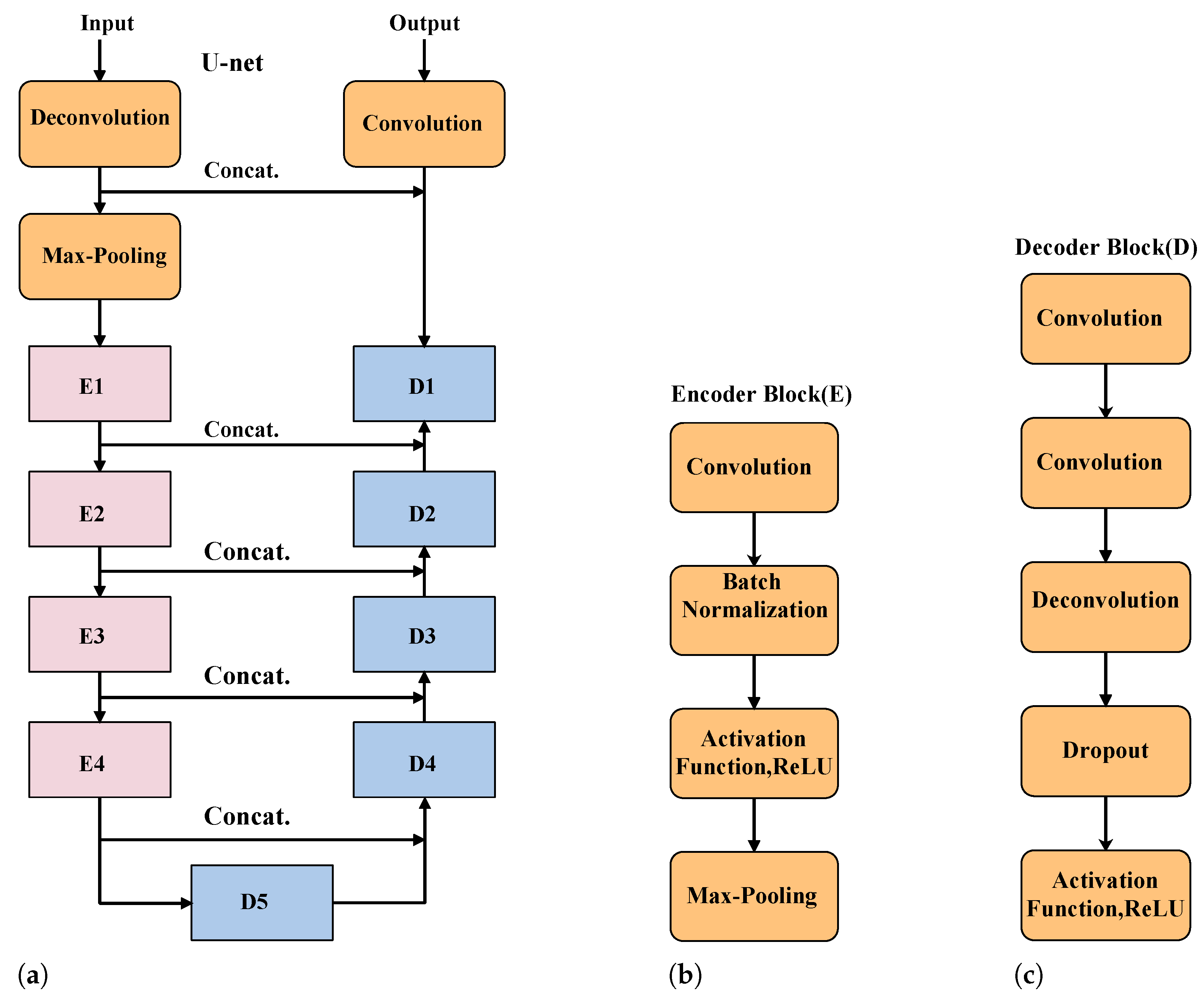
In N2N-cGAN algorithm, both the denoising network and the generative network use the U-Net framework. U-Net is a CNN designed for semantic image segmentation. The structure of U-Net can be divided into downsampling and upsampling. Both of them use the encoder and decoder as well as the jump connection topology, which allows for more precise segmentation on fewer training images. U-Net is symmetrical. The expansion path on the right side of the network is symmetrical with the contraction path on the left to restore the size of the picture, while the contraction path on the left is used to capture context information. The output feature map of the encoder corresponding layer is copied, cut, and deconvoluted for feature fusion through jump connection, The output feature mapping of the corresponding layer of the encoder is copied, cut, and deconvoluted, and the feature fusion is carried out through the jump connection, and then the upsampling operation is carried out. During the upsampling process, U-Net employs many feature channels, which can improve the quality of the output and the accuracy of the segmentation.
| Algorithm 1 N2N-cGAN-Based Channel Estimation |
Require:,H.
Ensure:.
1: for number of training iterations do
2: Construct sample of (16)
3: Construct two samples of Y and (17)
4: Obtain with Y.
5: Update the by the loss function (20).
6:
end for
7: Extract the trained .
8: Get the clean pilot: .
Require: .
Ensure: .
9: for number of training iterations do
10: Sample minibatch of data and data H.
11: Train and alternately by (21) and (22) with and H.
12: end for
13: Obtain the trained generator network .
14: Get the channel estimation:. |
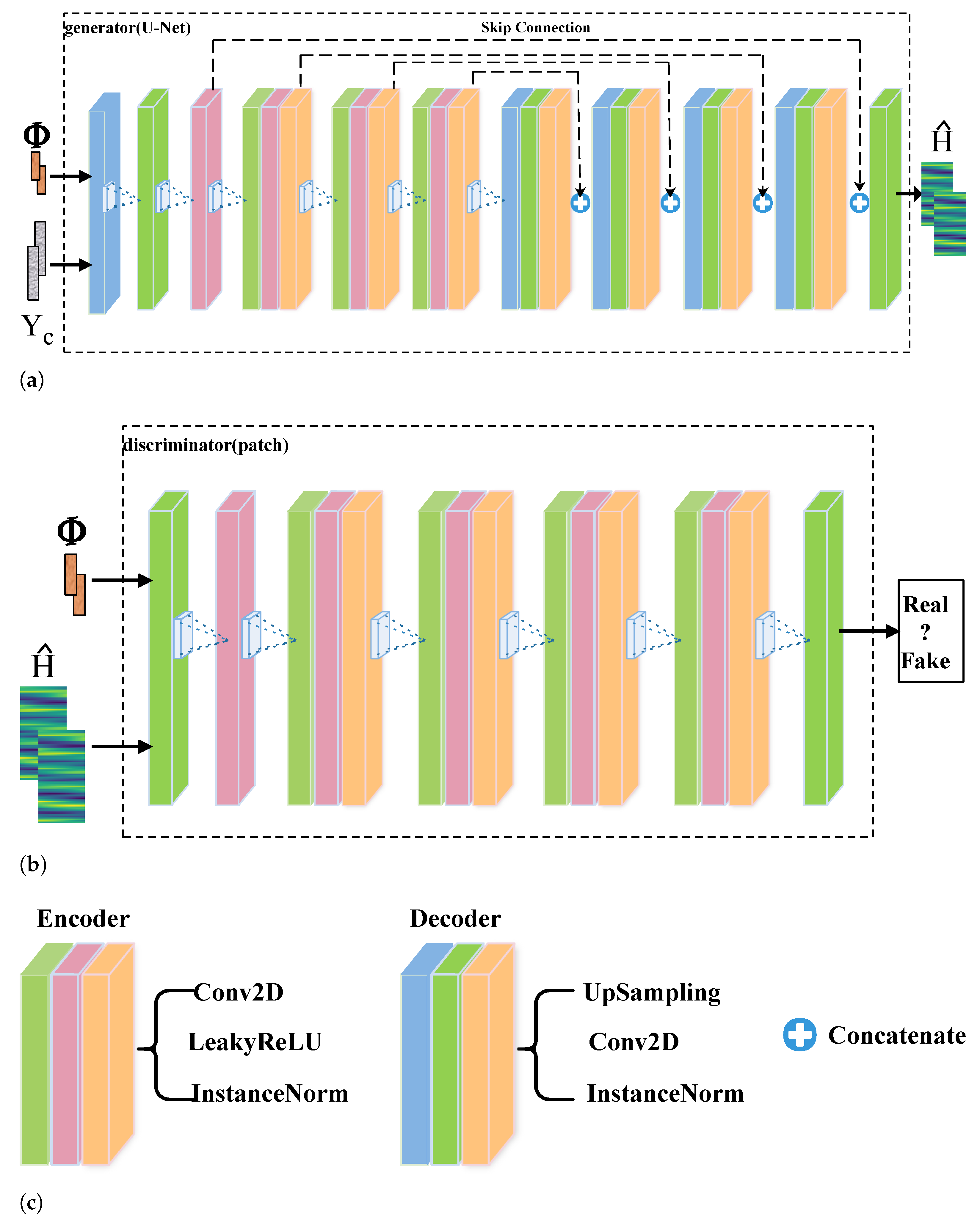
Figure 4a shows the architecture of the denoising network. The input image resolution is
. We first use a deconvolution to change the shape to adapt to the convolution operation. The next encoder consists of four submodules, each of which contains a convolution layer, a batch normalization layer, and each submodule has a downsampling layer realized by max-pooling as shown in
Figure 4b. After this processing, the image size becomes
. The information flow enters the decoder on the right side. The decoder also includes five submodules. Each submodule is composed of two convolution layers and a dropout layer, and each submodule has an upper sampling layer realized by deconvolution as shown in
Figure 4c. The resolution is improved by upsampling operation. Finally, the output image has the same resolution as the input image in the convolution process. The jump connection connects the upsampling result with the output of the submodule of the encoder, whose connection part has the same resolution, and takes it as the input of the next submodule in the decoder.
The discriminator network uses CNN. As shown in
Figure 5b. Instead of acting as a discriminator to discriminate true from false by mapping the input to a single scalar output, the input is mapped to the receptive field via a patch discriminator [
41], with each element indicating whether the input block is true or not. The front-end part of the discriminator consists of a convolutional layer, a LeakyReLU activation layer, and four encoder blocks. Each convolutional layer consists of 512 4 × 4 sized filters. We use the full connected layer in the last layer instead of the convolutional layer to obtain the receptive field. The final output of the discriminator is then produced by averaging all the answers from the receptive field.
4. Numerical Results and Analysis
In this section, we use simulations to evaluate the performance of the N2N-cGAN algorithm and compare it with other approaches. Reference [
31] has demonstrated through experiments that cGAN outperforms U-Net and CNN in terms of accuracy for channel estimation directly from noisy pilots. The work also considers the case where the length of the pilot sequence is smaller than the number of transmitting antennae, but the scenario considered in this paper is more complex, making the comparison results more informative. This paper mainly examines the performance of the N2N-cGAN and cGAN estimation methods compared to traditional channel-estimation algorithms LS and MMSE from three aspects. First, simulation parameters are set, and the standard for channel-estimation performance is established. Then we compare the performance of the proposed algorithms from different SNRs and different numbers of antennae deployed at the BS. Finally, we also compare the computational costs of different algorithms.
4.1. Simulation Dataset
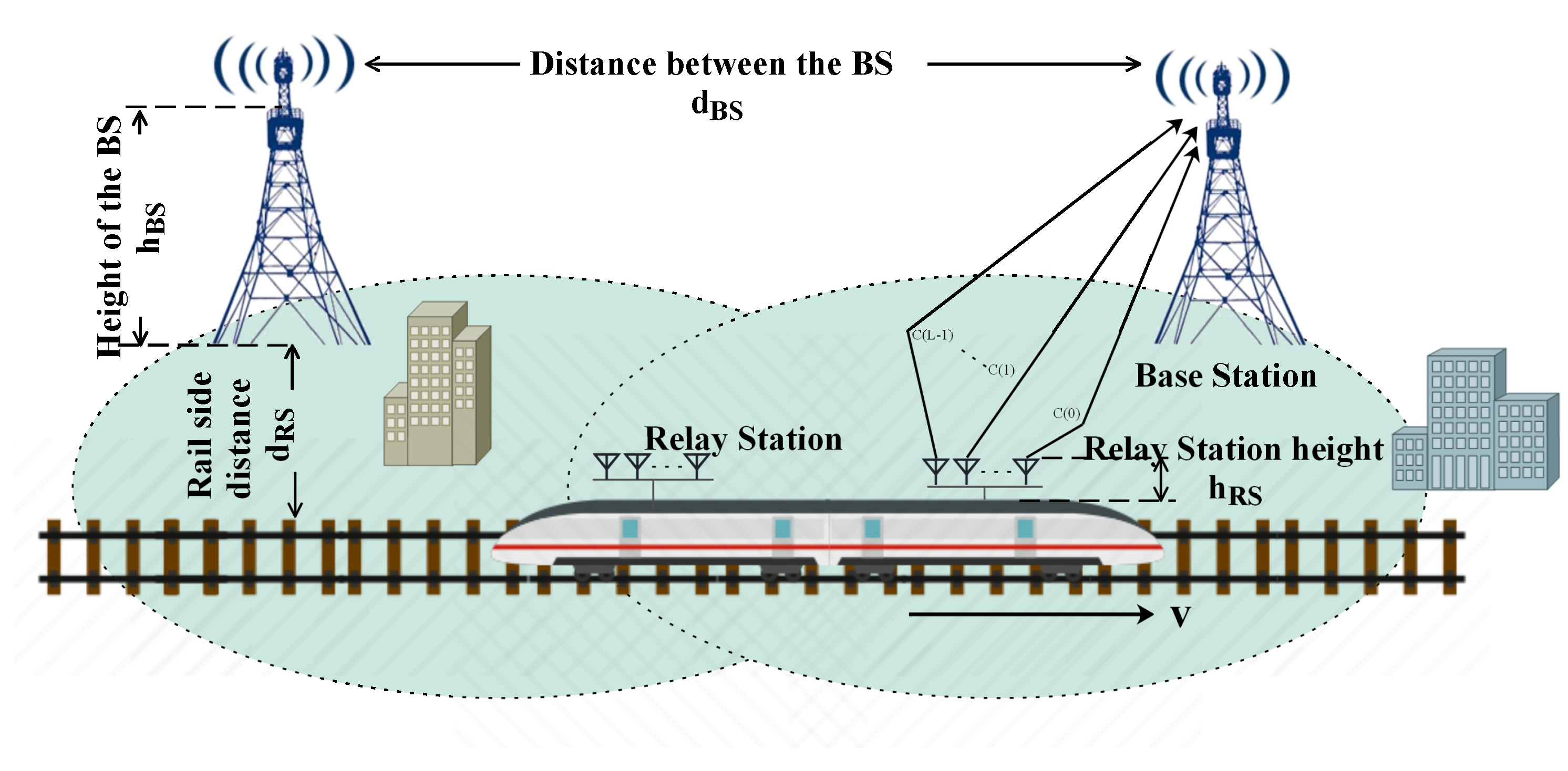
In our study, simulation data is produced by using the WINNER II D2a channel model. It is a scenario model for mobile devices, its network coverage, antenna configuration, and moving speed are all suitable for the HSR scenario described in this paper. Its channel parameters ( RMS, path loss, etc.) are derived from the calculations in
Section 2. Therefore, this channel model will be used in this paper to complete the simulation under the high-speed rail channel. The scene layout measured by WINNER II D2a includes the following. The RS is atop the moving train, whereas the BS is 50 m from the rail, that is
m. The link between the BS and the moving RS is basically considered to be LOS. The height of the BS is
m. The height of the RS on the top of the train is
m. The train speed is
km/h.
Table 1 displays the other specific simulation parameters.
According to these parameters, the channel vector between each user and the antenna array are generated. The user sends the derivative symbols as , These symbols are freely combined to form a sequence of U derivatives, which generate the derivative matrix of U × .
Through the channel model, the 10,000 real channel dataset is obtained. The z-score standardized method was used to process the dataset. The mean value of the processed dataset is 0 and the standard deviation is 1, which is more suitable for model training. Then, to produce clean pilots, we combine the normalized actual channel data with the Formula (16). The noise-containing pilots are obtained by adding independent Gaussian white noise under a given SNR. Consequently, a clear pilot dataset and a noisy pilot dataset are thus obtained. Finally, we reduce the three datasets’ complicated data into two-channel picture data, and use the holdout method in the divided dataset. It is divided into a training set and a test set according to the ratio of 4:1.
At the simulation stage, the Gaussian white noise under the SNR of dB to 10 dB is superposed by the clean signal to generate multiple noise-containing signals. Since the noisy signals all come from the same clean signal, the initial training data of the denoising model are freely combined by them. In the second stage, the cGAN takes the clean signal as input directly, with the actual channel data serving as the training data for the generator model. The two training stages can be conducted concurrently in this manner. The denoiser, generator, and discriminator are employed with the Adam optimizer with learning rates of , , and , respectively, to train the proposed N2N-cGAN model. As a comparison of the end-to-end cGAN method, we use noisy pilot data as the generator input, while real channel data serves as the generator learning object.
4.2. Evaluation Criteria
In the simulation, we quantify the variance between the estimated channel
and the real channel
H by using the normalized mean square error (NMSE) as the evaluation standard. This is expressed as
where the matrix norm computation is shown by the symbol
and
obtains values of expectation. To facilitate the observation of simulation results, we calculate
to convert NMSE into dB form.
4.3. Performance Evaluation
First,
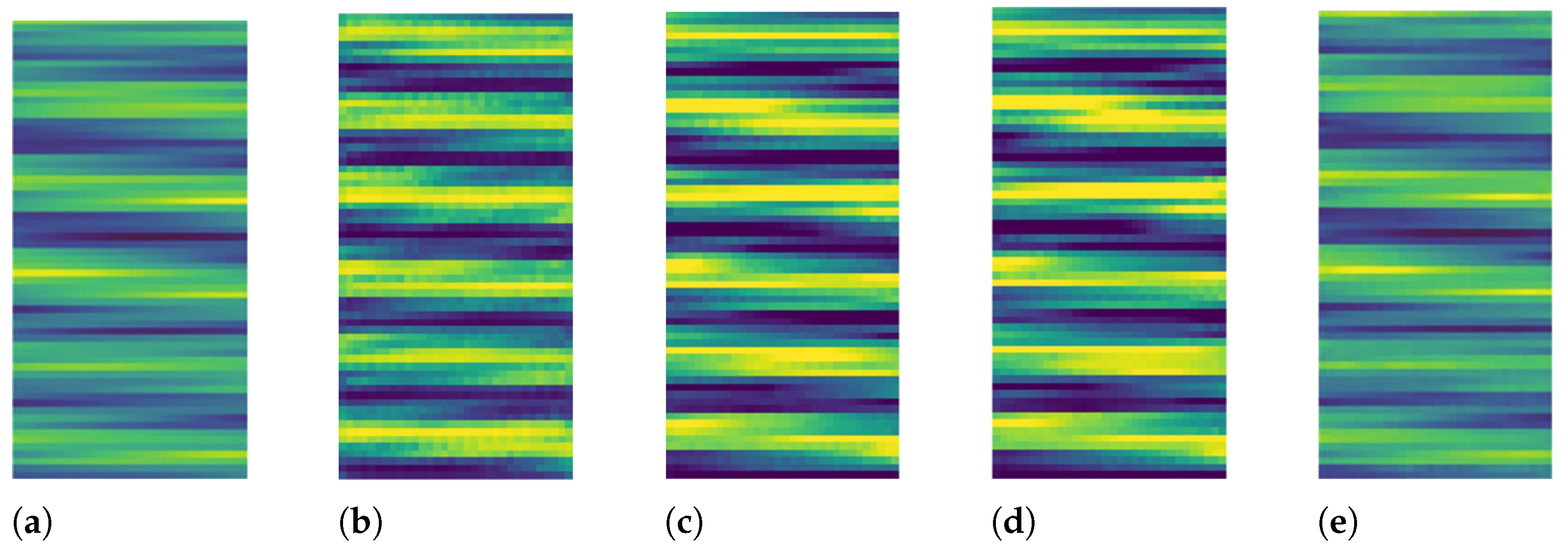
Figure 6 shows the display of channel estimate results by using various methodologies. We visualize the estimated and real channels as graphics in pseudocolor images.
The simulated data was generated with an SNR of 0 dB and a pilot sequence length of 8. The resulting estimated channel matrix
and the real components of the actual channel matrix
H are presented as pseudocolor images. The color values correspond to the data values in the channel matrix. As we can see from
Figure 6a–e, the visual images obtained by the LS estimation algorithm, MMSE estimation algorithm, and cGAN estimation algorithm are very different from that of the real channel. However, the N2N-cGAN-generated channel picture closely resembles the real channel. This indicates that the N2N-cGAN method generates channel details well. That is, results from the N2N-cGAN channel estimate can be more realistic.
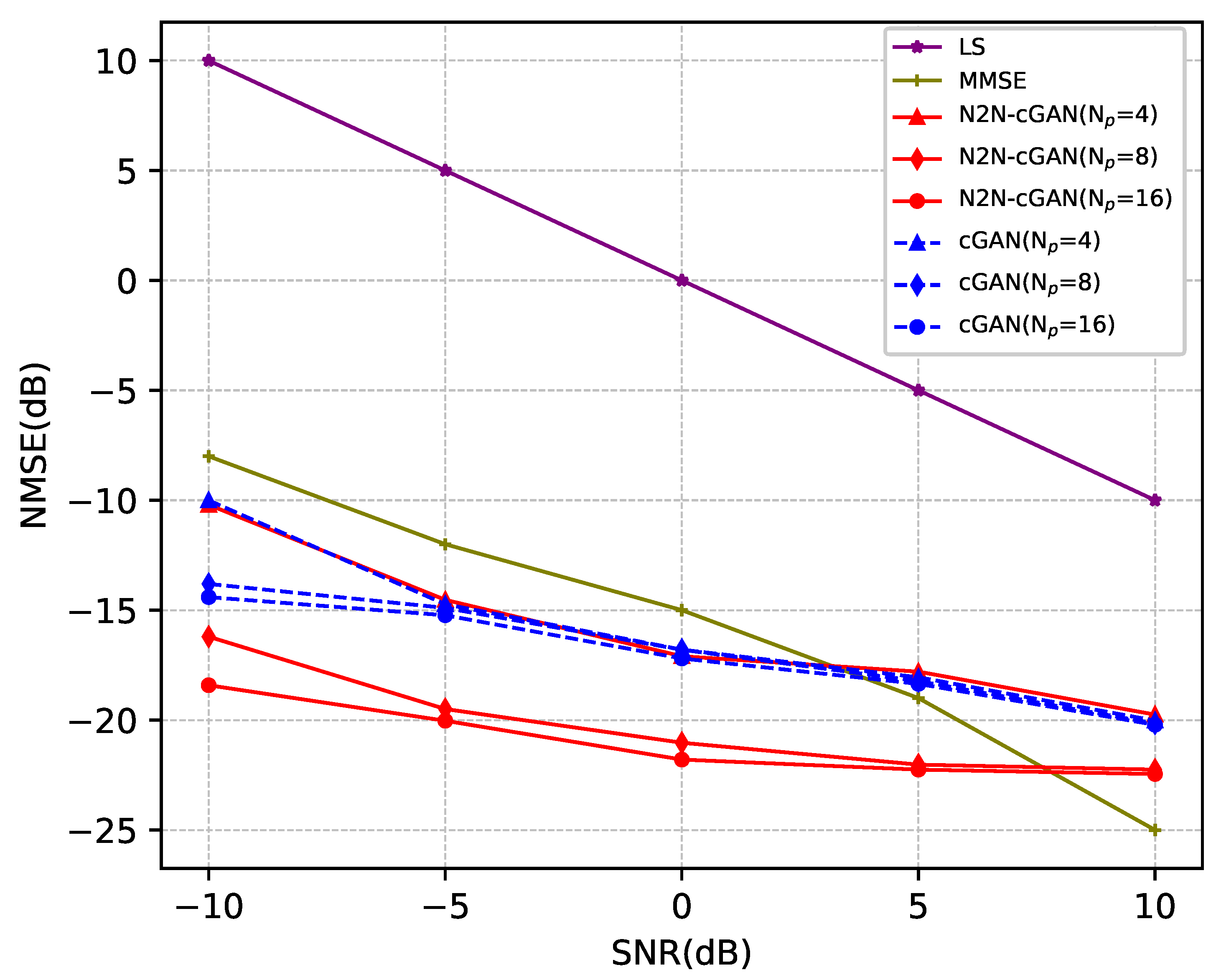
Figure 7 illustrates the comparison of NMSE performance between N2N-cGAN and cGAN algorithms, as well as conventional LS and MMSE algorithms, under different SNRs.
It shows the MMSE values obtained by the four channel-estimation methods in the process of SNR changing from
dB to 10 dB. N2N-cGAN and cGAN use pilot sequences to estimate channels with lengths of 4, 8, and 16 respectively. The comparative analysis of estimated errors between the N2N-cGAN and cGAN demonstrates that, irrespective of the variation in SNR and pilot sequence length, the N2N-cGAN outperformed the cGAN in terms of estimated error. Notably, the estimated error of N2N-cGAN is much smaller than that of cGAN when the pilot length is 8 or 16 and the SNR is low. Additionally,
Figure 7 shows that when the duration of the pilot sequence reduces, the estimation errors of both techniques increase, and the change in performance of N2N-cGAN is relatively more obvious, and the performance of N2N-cGAN at the pilot sequence of the length of 4 is comparable to that of cGAN at a pilot sequence of length 16. N2N-cGAN is overall better than cGAN. It is mainly because the first stage denoising network in N2N-cGAN removes the noise from the noisy pilot as much as possible, which makes the second stage channel estimation approximate for a noise-free estimation. In contrast, cGAN directly uses noisy pilots to estimate the channel, which makes cGAN learn the change of noise. However, the noise is independent and unpredictable, so the estimation error of cGAN will be greater than that of N2N-cGAN, which is more obvious in the case of low SNR. Lastly,
Figure 7 demonstrates that the classic LS approach performs the worst. In the event of high SNR, the performance of the MMSE method can outperform N2N-cGAN, but it is not even superior to the cGAN estimation method at low SNR.
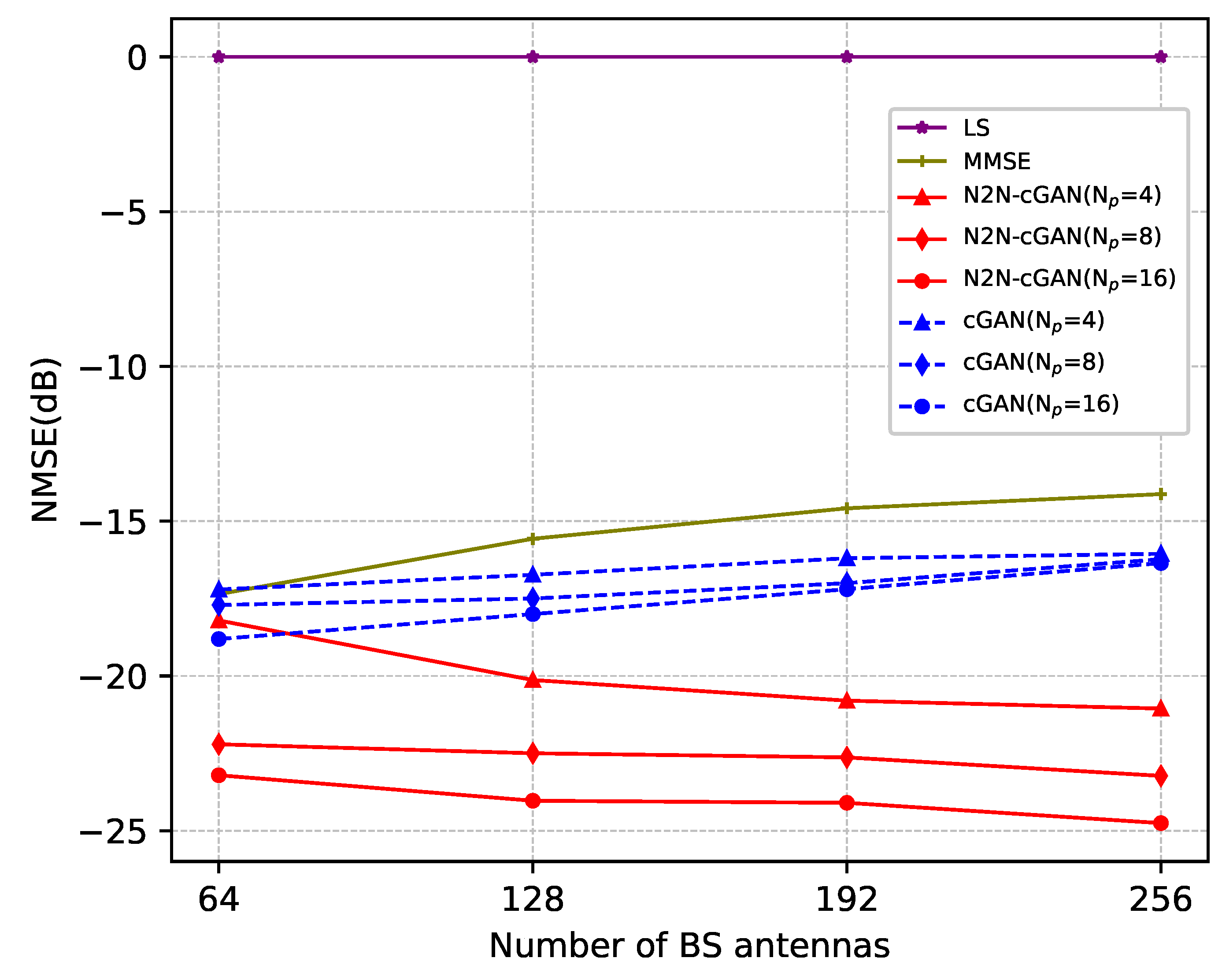
Next, We analyze the NMSE performance of LS, MMSE, cGAN, and N2N-cGAN in different scenarios where the number of antennae deployed in the BS varies. The SNR is 0 dB in this simulation. The corresponding simulation results are presented in
Figure 8. It demonstrates that the N2N-cGAN estimation approach exhibits superior performance compared to the cGAN approach, as the estimation error decreases with the increase of the number of antennae. The size of the channel matrix will expand as the number of BS antennae rises. The use of cGAN for estimation results in a complex estimated target, which increases the learning difficulty and consequently leads to reduced performance. For N2N-cGAN, the performance of the second stage is almost not affected due to the noise-free estimation. The denoising of the first stage learns better denoising methods because of the introduction of more noise information, so the performance of N2N-cGAN improves with the increase of antenna numbers.
Figure 8 illustrates that the performance of the MMSE approach deteriorates as the number of antennae increases, while the estimation error of the conventional LS method remains relatively constant. As the pilot sequence length increases from 4 to 8, the performance improvement of N2N-cGAN is more significant, which can be shown from the simulation. However, when the length is further increased from 8 to 16, the performance gain of N2N-cGAN is less significant.
4.4. Complexity Analysis
Table 2 presents the results. The computational complexity of the four channel-estimation algorithms, LS, MMSE, cGAN, and N2N-cGAN, are measured in terms of the number of complex multiplications. In the table,
and
represent the number of receiving and transmitting antennae respectively, and
N represents the number of subcarriers.
Among the channel-estimation algorithms, the LS algorithm exhibits the lowest computational complexity. The MMSE has the highest computational complexity due to matrix inversion. The N2N-cGAN algorithm exhibits low computational complexity, as it only involves matrix multiplication and addition, and does not require matrix inversion operations. Online complexity is less difficult than traditional MMSE complexity. Additionally, because the neural network may be constructed in parallel, the approach can shorten the algorithm’s execution time. The complexity of the online implementation phase of the algorithm is low, because the trained model can be used immediately for channel estimation without large computational overhead.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}