
Thangka Sketch Colorization Based on Multi-Level Adaptive-Instance-Normalized Color Fusion and Skip Connection Attention


Abstract
:1. Introduction
- We propose a multi-level color fusion module multi-level adaptive-instance-normalized color fusion (MACF), which can accurately fuse color features with sketch features and generate high-quality colorization works.
- We propose a skip connection attention (SCA) module for accurately distinguishing semantic information consisting of dense lines.
- For the first time, we present a framework applicable to the Thangka sketches colorization, and we also constructed a new Thangka dataset (5081 images).
2. Related Work
2.1. Automatic Sketch Colorization
2.2. User Prompt Based Colorization
2.3. Reference-Based Sketch Image Colorization
3. Methodology
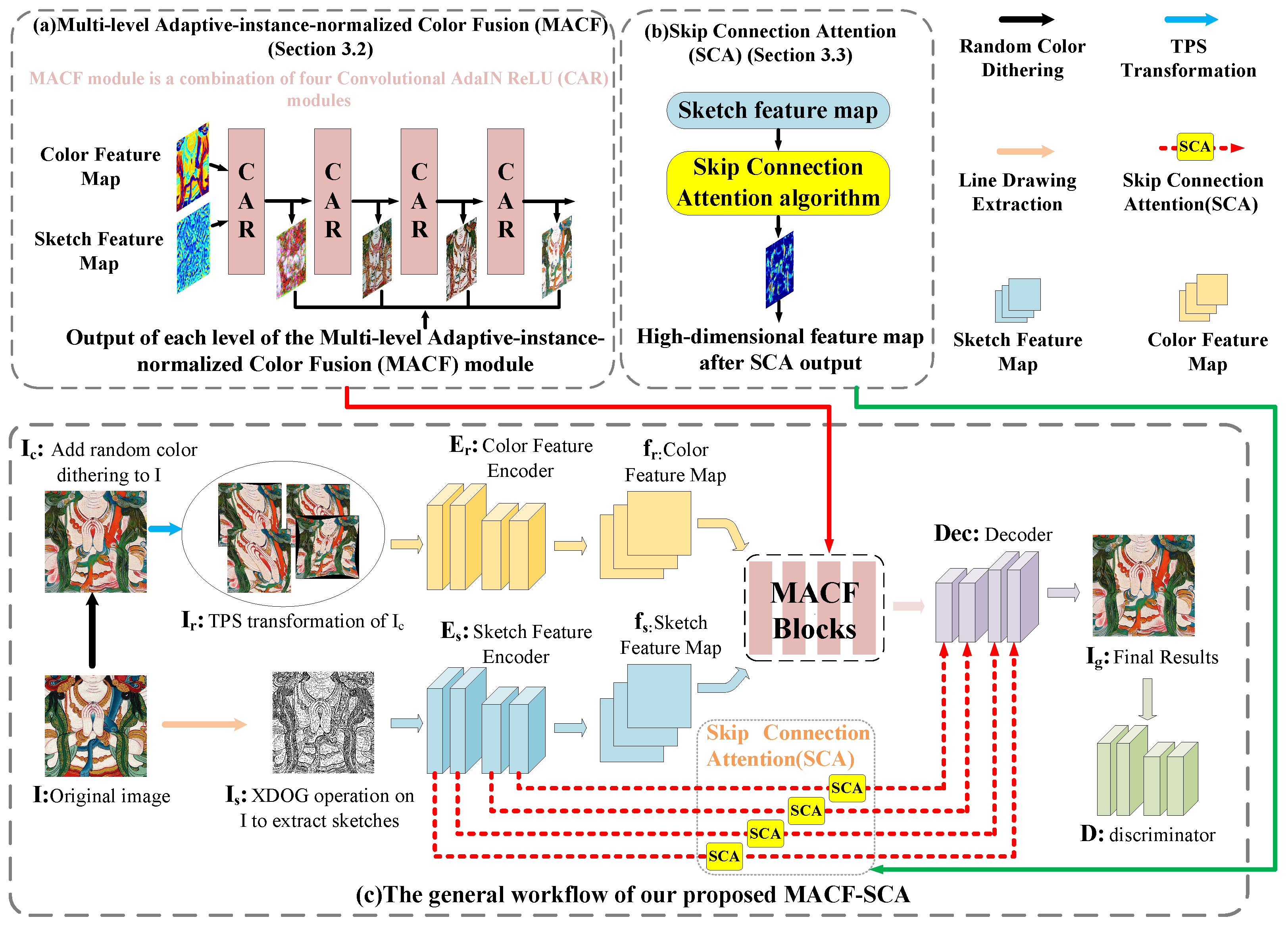
3.1. Overall Workflow
3.2. Self-Enhanced Self-Referential Learning
3.3. Multi-Level Adaptive-Instance-Normalized Color Fusion (MACF)
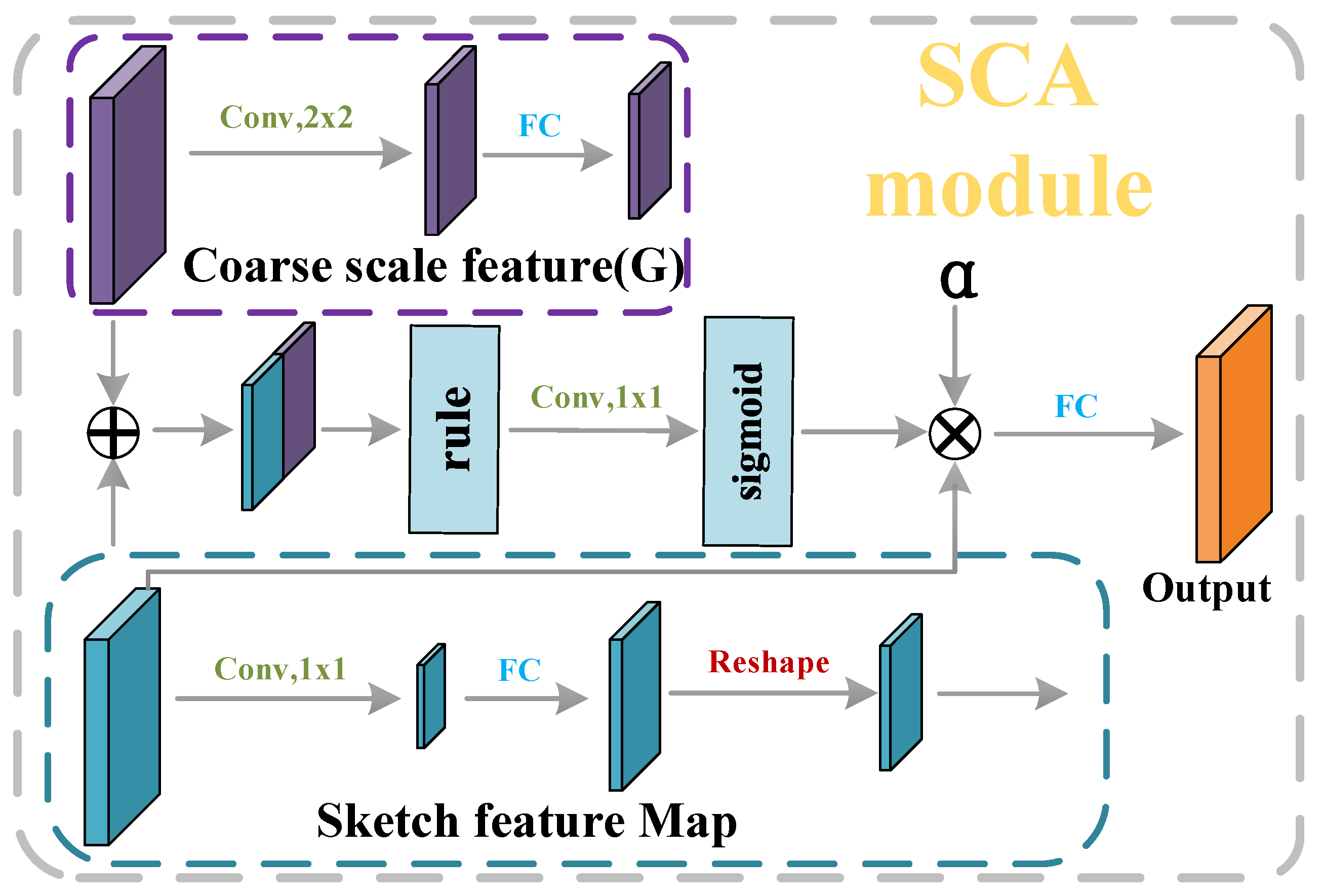
3.4. Skip Connection Attention (SCA)
3.5. Loss Function
4. Experimental Results and Analysis
4.1. Dataset
4.2. Implementation Details
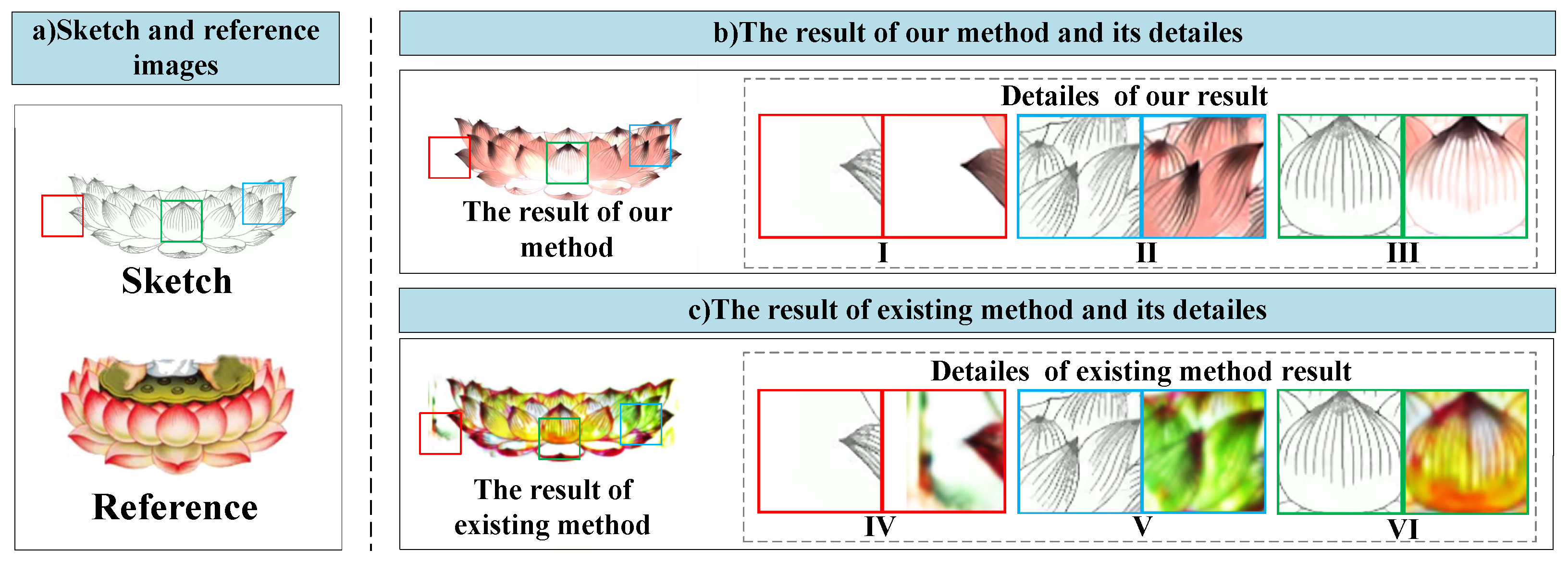
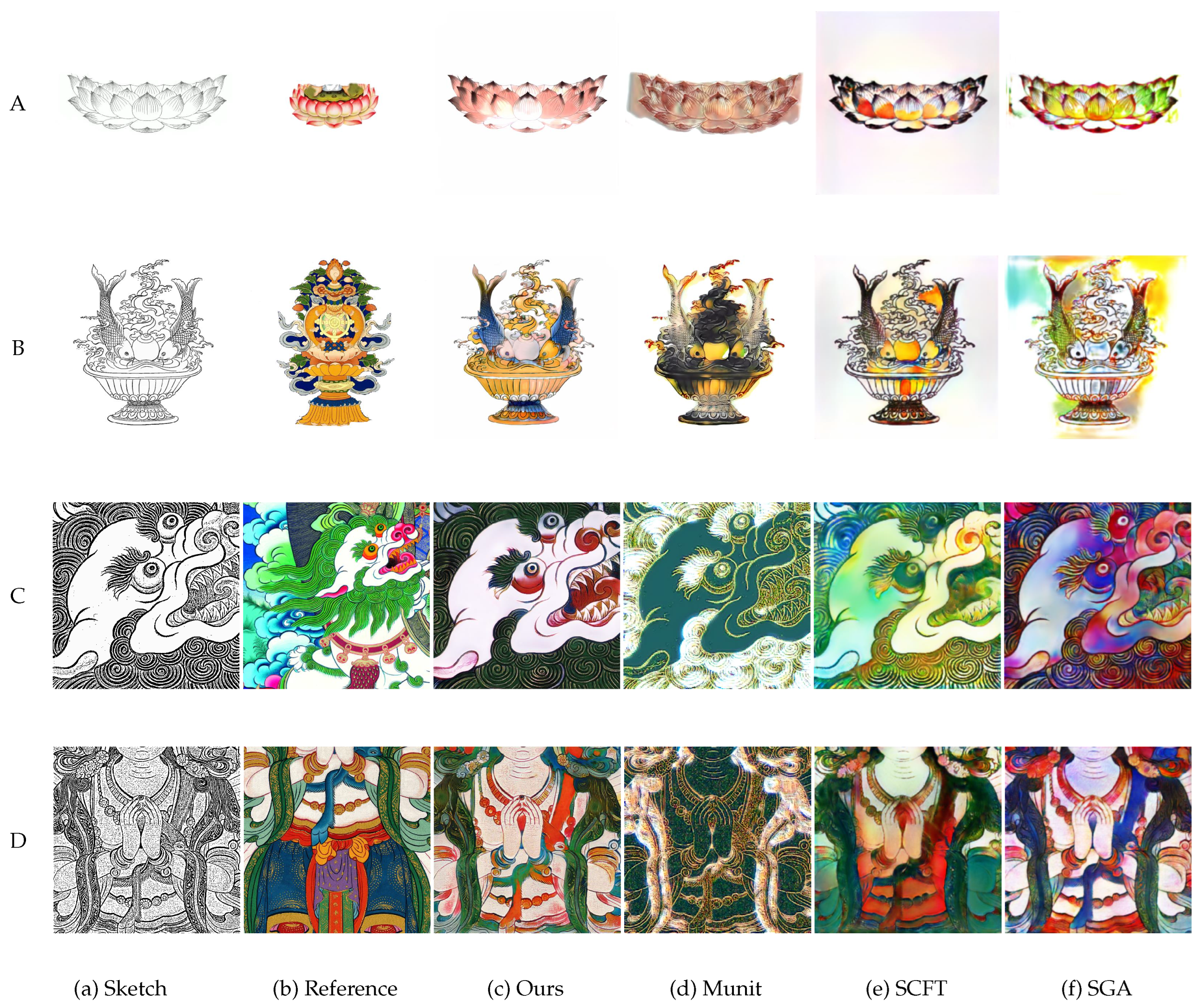
4.3. Qualitative Evaluation
4.4. Quantitative Evaluation
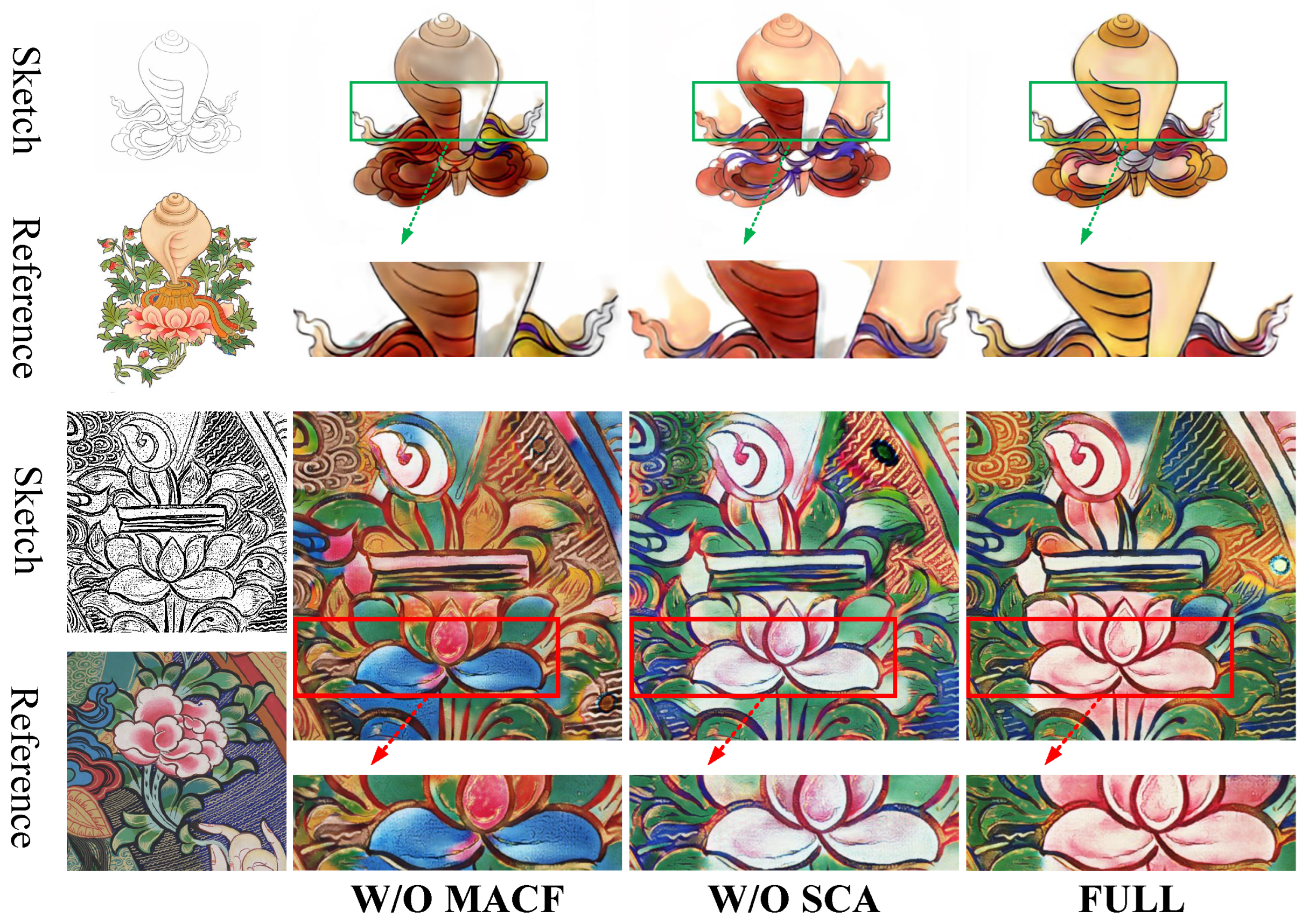
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, W.; Qian, J.; Lu, X. Research outline and progress of digital protection on thangka. In Advanced Topics in Multimedia Research; IntechOpen: London, UK, 2012; p. 67. [Google Scholar]
- Lee, J.; Kim, E.; Lee, Y.; Kim, D.; Chang, J.; Choo, J. Reference-based sketch image colorization using augmented-self reference and dense semantic correspondence. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5801–5810. [Google Scholar]
- Li, Z.; Geng, Z.; Kang, Z.; Chen, W.; Yang, Y. Eliminating Gradient Conflict in Reference-based Line-Art Colorization. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Part XVII. pp. 579–596. [Google Scholar]
- Zhang, L.; Ji, Y.; Lin, X.; Liu, C. Style transfer for anime sketches with enhanced residual u-net and auxiliary classifier gan. In Proceedings of the 2017 4th IAPR Asian Conference on Pattern Recognition (ACPR), Nanjing, China, 26–29 November 2017; pp. 506–511. [Google Scholar]
- Liu, Y.; Qin, Z.; Wan, T.; Luo, Z. Auto-painter: Cartoon image generation from sketch by using conditional Wasserstein generative adversarial networks. Neurocomputing 2018, 311, 78–87. [Google Scholar] [CrossRef]
- Frans, K. Outline colorization through tandem adversarial networks. arXiv 2017, arXiv:1704.08834. [Google Scholar]
- Zhang, G.; Qu, M.; Jin, Y.; Song, Q. Colorization for anime sketches with cycle-consistent adversarial network. Int. J. Perform. Eng. 2019, 15, 910. [Google Scholar] [CrossRef]
- Seo, C.W.; Seo, Y. Seg2pix: Few shot training line art colorization with segmented image data. Appl. Sci. 2021, 11, 1464. [Google Scholar] [CrossRef]
- Furusawa, C.; Kitaoka, S.; Li, M.; Odagiri, Y. Generative Probabilistic Image Colorization. arXiv 2021, arXiv:2109.14518. [Google Scholar]
- Yan, C.; Chung, J.J.Y.; Kiheon, Y.; Gingold, Y.; Adar, E.; Hong, S.R. FlatMagic: Improving Flat Colorization through AI-Driven Design for Digital Comic Professionals. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022; pp. 1–17. [Google Scholar]
- Liu, G.; Chen, X.; Hu, Y. Anime sketch coloring with swish-gated residual U-net. In Proceedings of the Computational Intelligence and Intelligent Systems: 10th International Symposium, ISICA 2018, Jiujiang, China, 13–14 October 2018; Revised Selected Papers 10. pp. 190–204. [Google Scholar]
- Huang, Y.C.; Tung, Y.S.; Chen, J.C.; Wang, S.W.; Wu, J.L. An adaptive edge detection based colorization algorithm and its applications. In Proceedings of the 13th Annual ACM International Conference on Multimedia, Singapore, 6–11 November 2005; pp. 351–354. [Google Scholar]
- Levin, A.; Lischinski, D.; Weiss, Y. Colorization Using Optimization. Available online: https://www.researchgate.net/publication/2896183_Colorization_using_Optimization (accessed on 4 March 2023).
- Ci, Y.; Ma, X.; Wang, Z.; Li, H.; Luo, Z. User-guided deep anime line art colorization with conditional adversarial networks. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1536–1544. [Google Scholar]
- Zhang, L.; Li, C.; Wong, T.T.; Ji, Y.; Liu, C. Two-stage sketch colorization. ACM Trans. Graph. (TOG) 2018, 37, 1–14. [Google Scholar] [CrossRef]
- Yuan, M.; Simo-Serra, E. Line art colorization with concatenated spatial attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3946–3950. [Google Scholar]
- Zhang, L.; Li, C.; Simo-Serra, E.; Ji, Y.; Wong, T.T.; Liu, C. User-guided line art flat filling with split filling mechanism. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9889–9898. [Google Scholar]
- Sato, K.; Matsui, Y.; Yamasaki, T.; Aizawa, K. Reference-based manga colorization by graph correspondence using quadratic programming. In Proceedings of the SIGGRAPH Asia 2014 Technical Briefs, Shenzhen, China, 3–6 December 2014; pp. 1–4. [Google Scholar]
- Huang, J.; Liao, J.; Kwong, S. Semantic example guided image-to-image translation. IEEE Trans. Multimed. 2020, 23, 1654–1665. [Google Scholar] [CrossRef]
- Huang, X.; Liu, M.Y.; Belongie, S.; Kautz, J. Multimodal unsupervised image-to-image translation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 172–189. [Google Scholar]
- Winnemöller, H.; Kyprianidis, J.E.; Olsen, S.C. XDoG: An eXtended difference-of-Gaussians compendium including advanced image stylization. Comput. Graph. 2012, 36, 740–753. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Chui, H.; Rangarajan, A. A new algorithm for non-rigid point matching. In Proceedings of the Proceedings IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2000 (Cat. No. PR00662), Hilton Head, SC, USA, 15 June 2000; Volume 2, pp. 44–51. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. In Proceedings of the Medical Imaging with Deep Learning, Amsterdam, The Netherlands, 4–6 July 2018. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Huber, P.J. Robust estimation of a location parameter. In Breakthroughs in Statistics: Methodology and Distribution; Springer: Berlin/Heidelberg, Germany, 1992; pp. 492–518. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kim, H.; Jhoo, H.Y.; Park, E.; Yoo, S. Tag2pix: Line art colorization using text tag with secat and changing loss. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 9056–9065. [Google Scholar]
- Branwen, G.; Gokaslan, A. Danbooru2019: A Large-Scale Crowdsourced and Tagged Anime Illustration Dataset. Available online: https://www.gwern.net/Danbooru2019 (accessed on 13 January 2020).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Bynagari, N.B. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. Asian J. Appl. Sci. Eng. 2019, 8, 25–34. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Danbooru 2019 | Thangka | ||||
|---|---|---|---|---|---|---|
| FID↓ | SSIM↑ | PSNR↑ | FID↓ | SSIM↑ | PSNR↑ | |
| Munit [20] | 58.38 | 0.68 | 13.83 | 168.89 | 0.19 | 9.09 |
| SCFT [2] | 45.60 | 0.80 | 16.23 | 183.65 | 0.48 | 13.26 |
| SGA [3] | 24.28 | 0.79 | 16.18 | 110.79 | 0.43 | 11.92 |
| Ours | 16.13 | 0.82 | 16.53 | 51.35 | 0.54 | 12.87 |
| Method | Danbooru 2019 | Thangka | ||||
|---|---|---|---|---|---|---|
| FID↓ | SSIM↑ | PSNR↑ | FID↓ | SSIM↑ | PSNR↑ | |
| W/O MACF | 21.35 | 0.79 | 14.42 | 66.05 | 0.51 | 12.30 |
| W/O SCA | 18.40 | 0.78 | 15.88 | 60.79 | 0.50 | 12.41 |
| FULL | 16.13 | 0.82 | 16.53 | 51.35 | 0.54 | 12.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Fang, J.; Jia, Y.; Ji, L.; Chen, X.; Wang, N. Thangka Sketch Colorization Based on Multi-Level Adaptive-Instance-Normalized Color Fusion and Skip Connection Attention. Electronics 2023, 12, 1745. https://doi.org/10.3390/electronics12071745
Li H, Fang J, Jia Y, Ji L, Chen X, Wang N. Thangka Sketch Colorization Based on Multi-Level Adaptive-Instance-Normalized Color Fusion and Skip Connection Attention. Electronics. 2023; 12(7):1745. https://doi.org/10.3390/electronics12071745
Chicago/Turabian StyleLi, Hang, Jie Fang, Ying Jia, Liqi Ji, Xin Chen, and Nianyi Wang. 2023. "Thangka Sketch Colorization Based on Multi-Level Adaptive-Instance-Normalized Color Fusion and Skip Connection Attention" Electronics 12, no. 7: 1745. https://doi.org/10.3390/electronics12071745