
Research on Detection and Recognition Technology of a Visible and Infrared Dim and Small Target Based on Deep Learning

Abstract
:1. Introduction
2. Related Work
3. Multi-Scale Fusion Super-Resolution Reconstruction Algorithm for UAV Detection
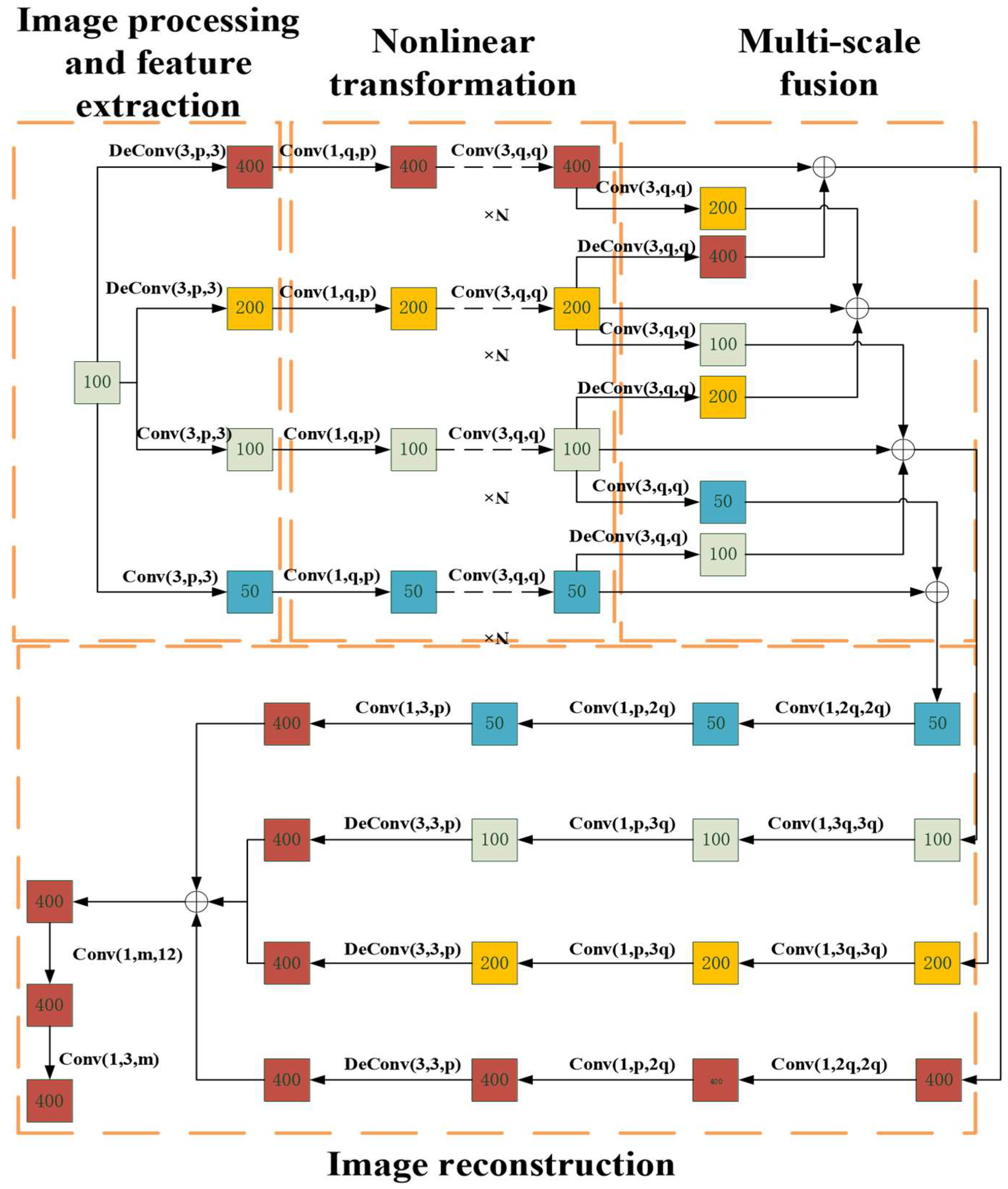
3.1. Principle Framework
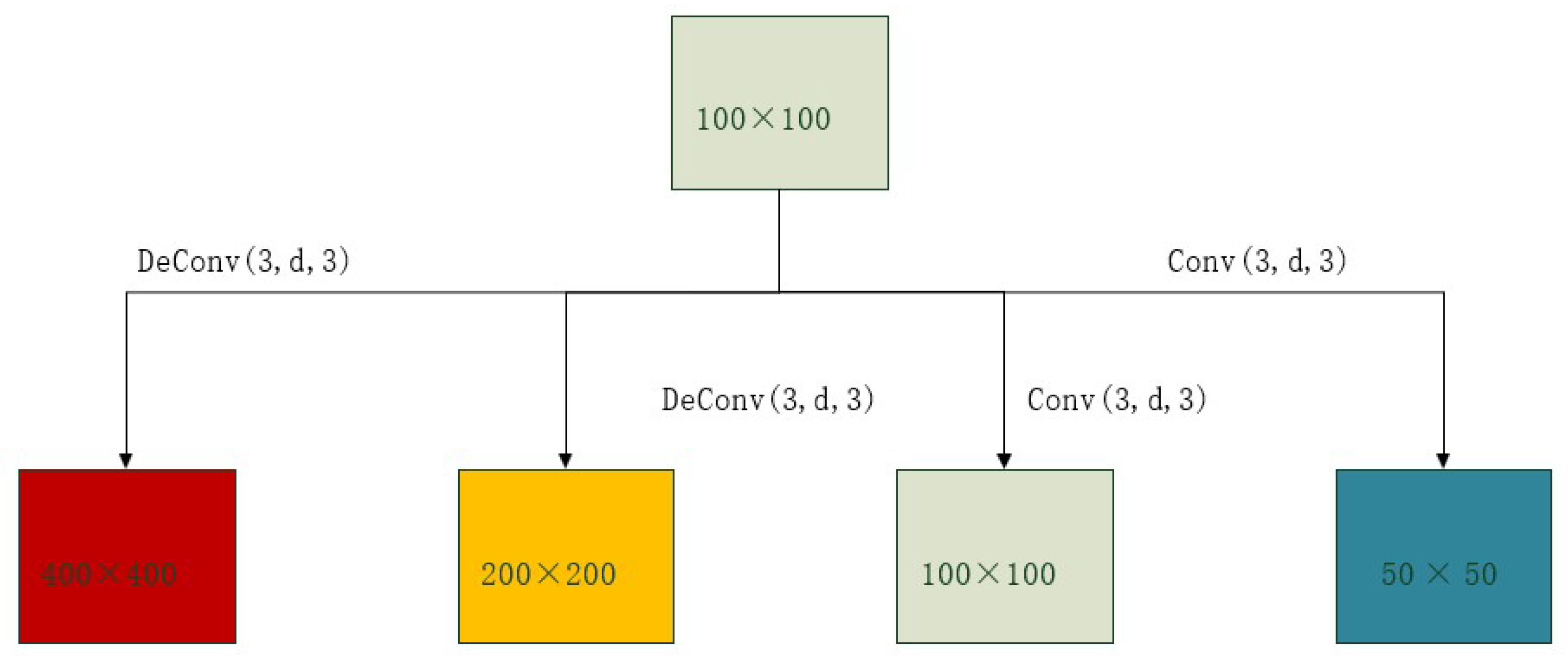
3.1.1. Feature Extraction
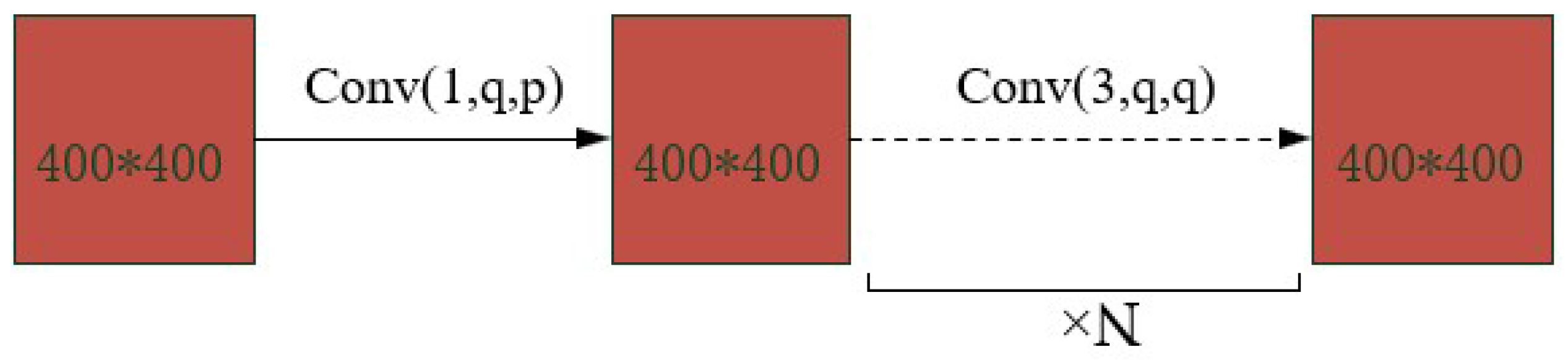
3.1.2. Nonlinear Transformations
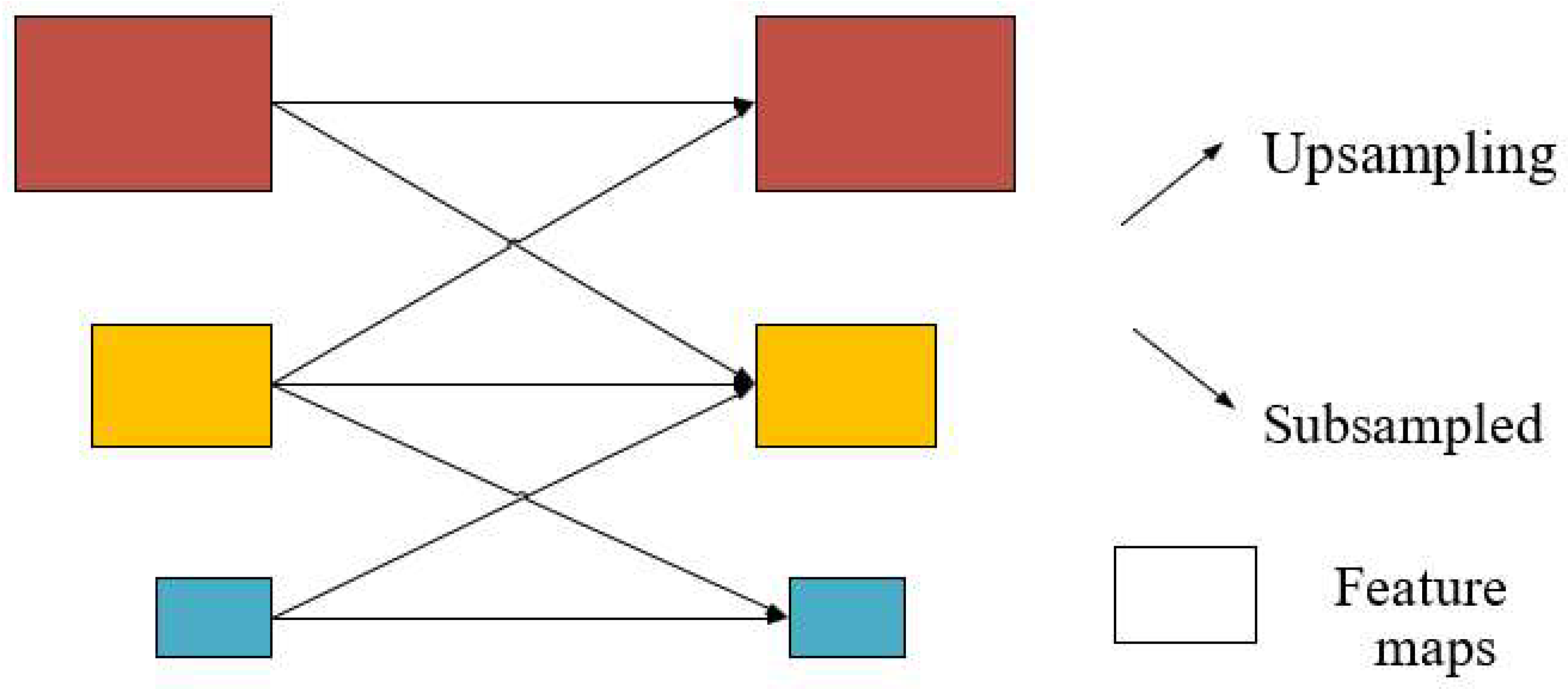
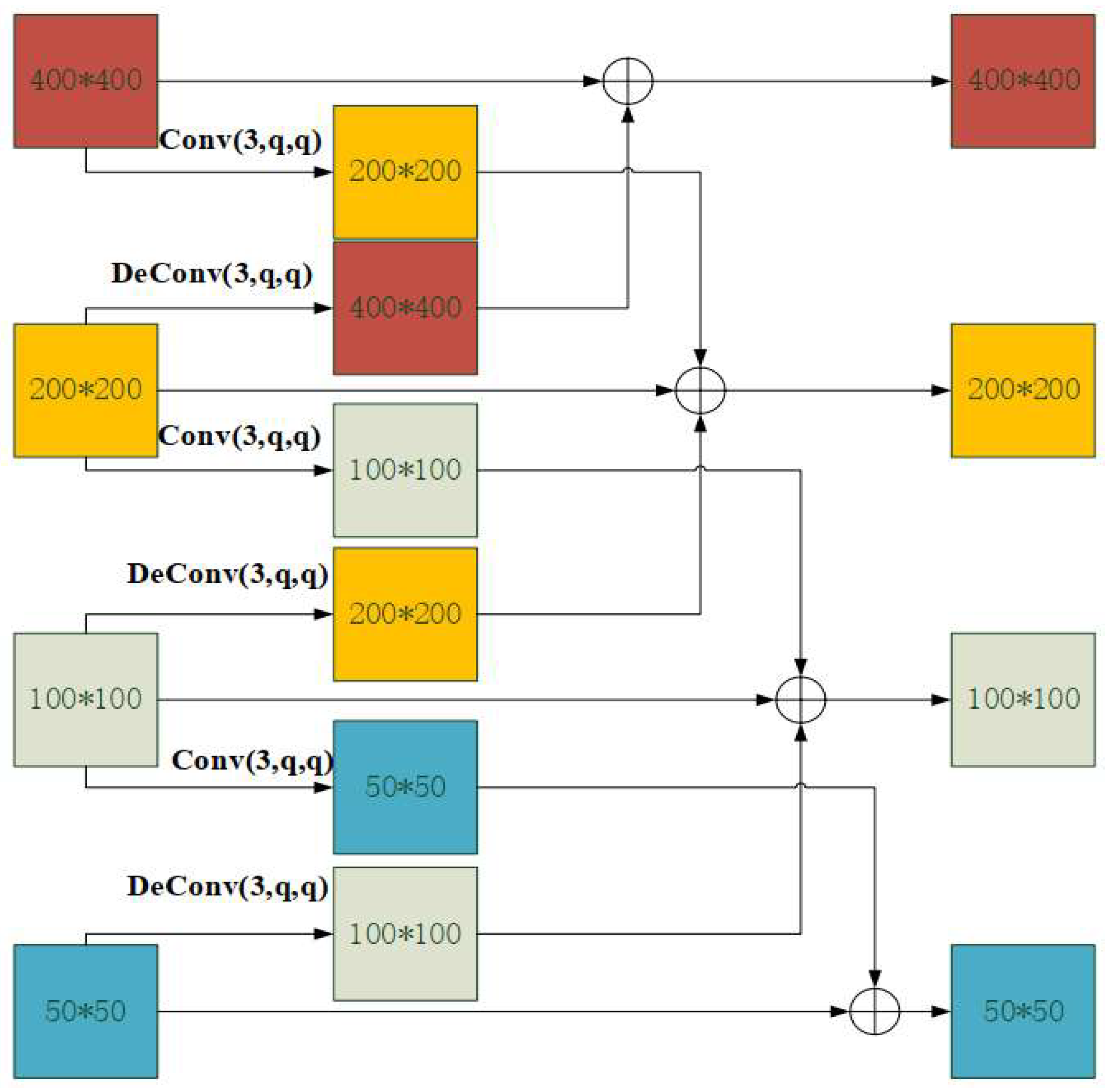
3.1.3. Multi-Scale Fusion
3.1.4. Image Reconstruction
3.2. Simulation Training and Results
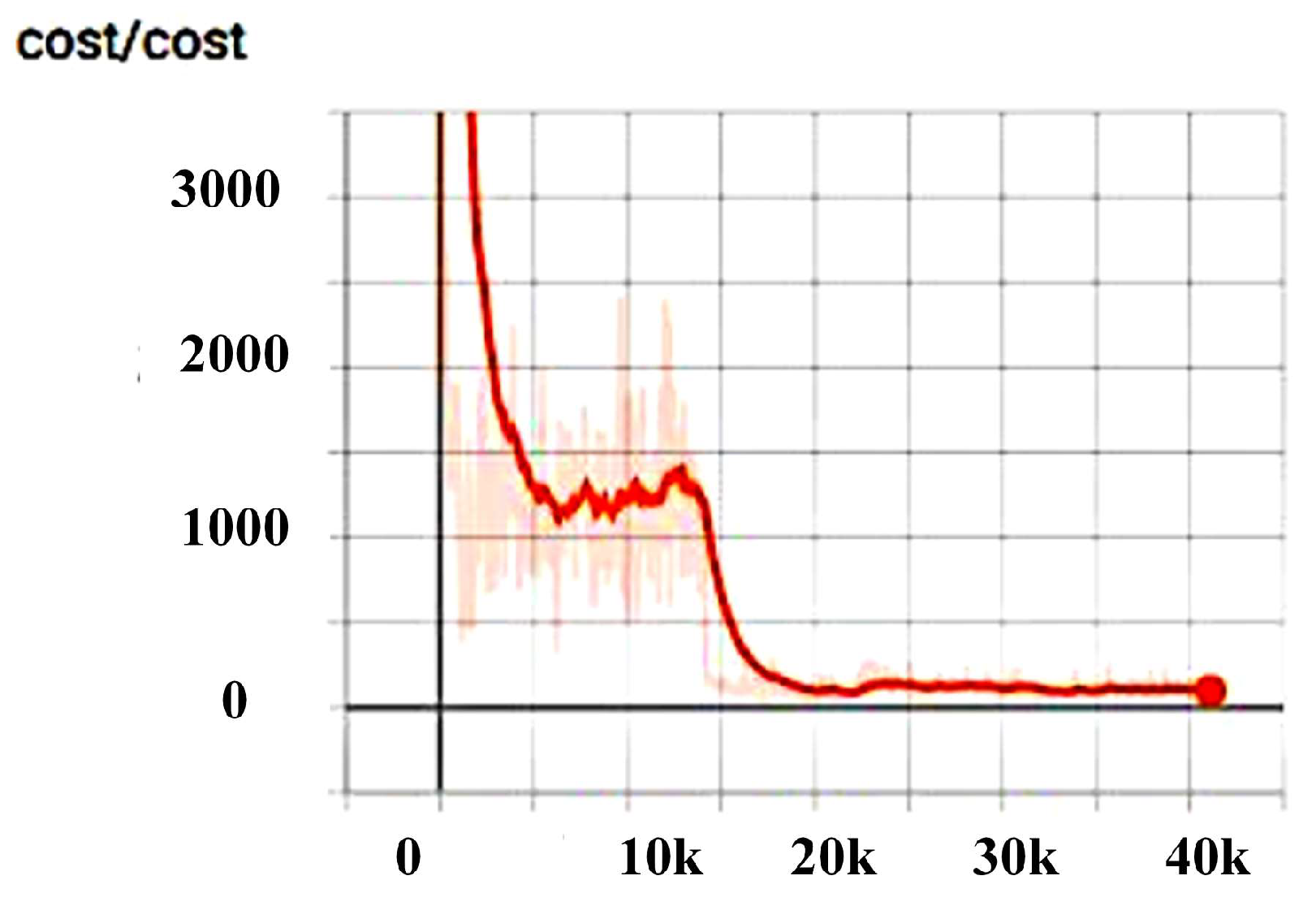
3.2.1. Model Training
3.2.2. Experimental Results
4. Analysis of Experimental Results
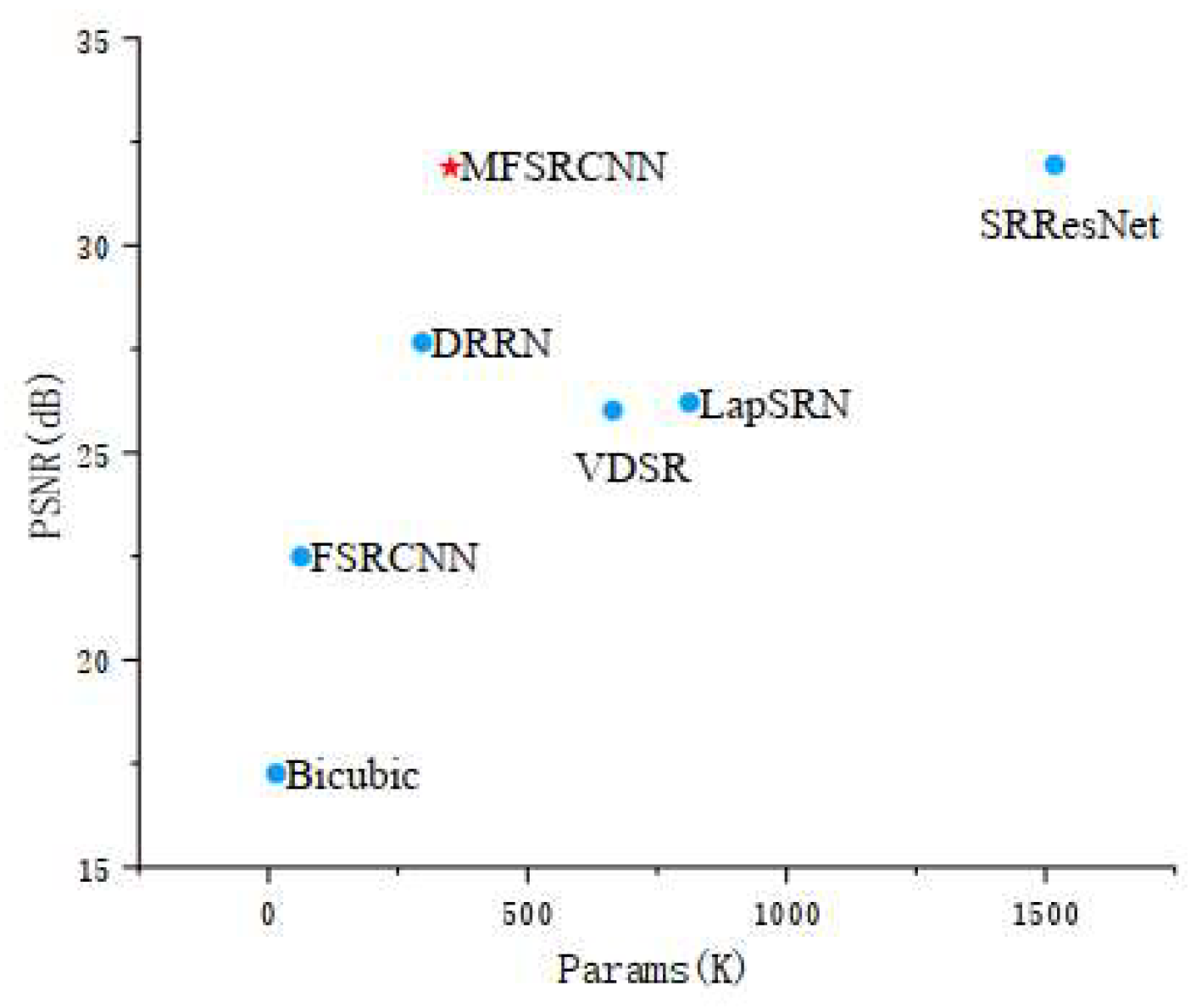
4.1. Comparative Analysis of Models
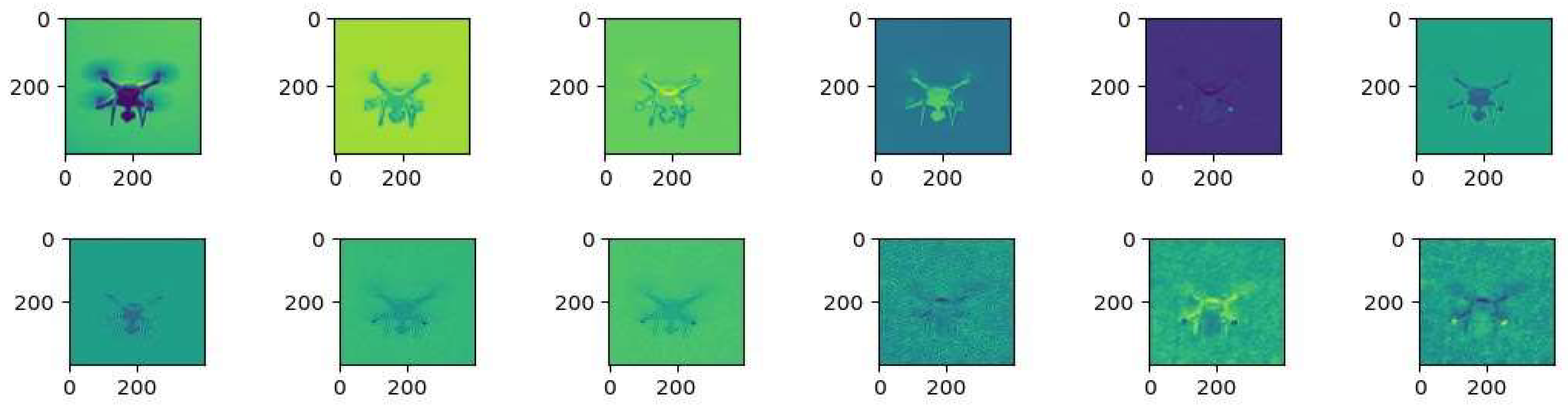
4.2. Analysis of Super-Resolution Reconstruction Effect
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 9627–9636. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 2918–2928. [Google Scholar]
- Wei, S.; Kang, J.U. Optical flow optical coherence tomography for determining accurate velocity fields. Opt. Express. 2020, 28, 25502. [Google Scholar] [CrossRef] [PubMed]
- Xue, Q.; Zhu, Y.; Wang, J. Joint Distribution Estimation and Navie Bayes Classification Under Local Differential Privacy. IEEE Trans. Emerg. Top. Comput. 2021, 9, 2053–2063. [Google Scholar] [CrossRef]
- Li, L.; Wei, Y.; Zhang, Y. The development of anti-UAV technical equipment of the U.S. armed forces. Aerosp. Electron. Warf. 2017, 33, 60–64. [Google Scholar]
- Hao, J.; Luo, S.; Pan, L. Computer-aided intelligent design using deep multi-objective cooperative optimization algorithm. Future Gener. Comput. Syst. 2021, 124, 49–53. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Tern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–27 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning Spatial Fusion for Single-Shot Object Detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934,. [Google Scholar]
- Ghose, D.; Desai, S.M.; Bhattacharya, S.; Chakraborty, D.; Fiterau, M.; Rahman, T. Pedestrian Detection in Thermal Images using Saliency Maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 1–10. [Google Scholar]
- Xu, L.; Lu, G.; Liu, S.; Xiu, C.L. Research on Infrared Target Recognition Method Based on Improved CNN. Fire Control. Command. Control. 2020, 45, 136–141. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Wang, K.; Li, S.; Niu, S.; Zhang, K. RISTDnet: Robust Infrared Small Target Detection Network. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar]
- Wang, K.; Li, S.; Niu, S.; Zhao, Y.; Zheng, H.; Zhang, W. Detection of Infrared Small Targets Using Feature Fusion Convolutional Network. IEEE Access 2019, 7, 146081–146092. [Google Scholar] [CrossRef]
- Xie, J.; Li, F.; Wei, H. Enhanced single—shot multi—frame detector method for aerial infrared target detection. J. Opt. 2019, 39, 223–231. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. pp. 5693–5703.
- Ribeiro, E.; Uhl, A.; Wimmer, G.; Häfner, M. Exploring Deep Learning and Transfer Learning for Colonic Polyp Classification. Comput. Math. Methods Med. 2016, 2016, 6584725. [Google Scholar] [CrossRef] [PubMed] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Params | PSNR | SSIM |
|---|---|---|---|
| Bicubic | 15 K | 17.2557 | 0.6607 |
| FSRCNN | 63 K | 22.4835 | 0.7503 |
| VDSR | 665 K | 26.0151 | 0.7698 |
| LapSRN | 813 K | 26.2043 | 0.7726 |
| DRRN | 297 K | 27.6547 | 0.7789 |
| SRResNet | 1 518 K | 31.9431 | 0.7974 |
| MFSRCNN | 406 K | 31.8800 | 0.7961 |
| Serial Number | Before | After | Ascension | Serial Number | Before | After | Ascension | Serial Number | Before | After | Ascension |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.82 | 0.86 | 4.88% | 11 | 0.7 | 0.73 | 4.29% | 21 | 0.85 | 0.91 | 7.06% |
| 2 | 0.95 | 0.97 | 2.11% | 12 | 0.62 | 0.67 | 8.06% | 22 | 0.72 | 0.68 | −5.56% |
| 3 | 0.76 | 0.79 | 3.95% | 13 | 0.73 | 0.78 | 6.85% | 23 | 0.5 | 0.52 | 4.00% |
| 4 | 0.86 | 0.9 | 4.65% | 14 | 0.63 | 0.69 | 9.52% | 24 | 0.56 | 0.65 | 16.07% |
| 5 | 0.63 | 0.65 | 3.17% | 15 | 0.68 | 0.77 | 13.24% | 25 | 0.96 | 0.97 | 1.04% |
| 6 | 0 | 0 | 0.00% | 16 | 0.93 | 0.95 | 2.15% | 26 | 0.96 | 0.98 | 2.08% |
| 7 | 0.71 | 0.77 | 8.45% | 17 | 0.67 | 0.98 | 46.27% | 27 | 0.75 | 0.91 | 21.33% |
| 8 | 0.91 | 0.92 | 1.09% | 18 | 0.8 | 0.84 | 5.00% | 28 | 0.97 | 0.99 | 2.06% |
| 9 | 0.93 | 0.94 | 1.08% | 19 | 0.83 | 0.83 | 0.00% | 29 | 0 | 0.41 | ∞ |
| 10 | 0.45 | 0.48 | 6.67% | 20 | 0.61 | 0.73 | 19.67% | 30 | 0.88 | 0.97 | 10.23% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, Y.; Li, Y.; Li, Z. Research on Detection and Recognition Technology of a Visible and Infrared Dim and Small Target Based on Deep Learning. Electronics 2023, 12, 1732. https://doi.org/10.3390/electronics12071732
Dong Y, Li Y, Li Z. Research on Detection and Recognition Technology of a Visible and Infrared Dim and Small Target Based on Deep Learning. Electronics. 2023; 12(7):1732. https://doi.org/10.3390/electronics12071732
Chicago/Turabian StyleDong, Yuxing, Yan Li, and Zhen Li. 2023. "Research on Detection and Recognition Technology of a Visible and Infrared Dim and Small Target Based on Deep Learning" Electronics 12, no. 7: 1732. https://doi.org/10.3390/electronics12071732