1. Introduction
One of the most difficult duties for clinicians in many clinical departments (including Emergency, Internal Medicine, Cardiology and Intensive Care Unit, ICU) is the assessment of the intravascular volume status [
1]. Medical professionals actually use fluid infusion to boost cardiac output and tissue perfusion. The improper amount of fluids, however, might result in pulmonary edema, peripheral edema, or body cavity effusion [
2]. Typically, a central venous catheter (CVC) is used to invasively measure the intravascular volume condition [
3]. However, due to the potential difficulties brought on by an invasive procedure, this approach is not appropriate for all patient circumstances [
3,
4].
As ultrasound (US) is noninvasive, it causes no harm to the patient’s health, and it is inexpensive to acquire. Doctors frequently employ it for diagnostic and prognostic procedures [
5]. For example, US scans have been used to determine the condition of the intravascular volume [
6]. In US videos, specialists examine the diameter and collapsibility of inferior vena cava (IVC), which correlate with volume status [
7] and right atrial pressure [
8,
9]. However, this method is not standardized [
10]. In order to support the clinicians to obtain reliable findings, some automated methods have been introduced [
11,
12]. However, in our previous works [
12,
13,
14], some preliminary steps are required to start the algorithms: the user must choose the type of view to be examined (long or short axis view, i.e., with the probe either longitudinal or transverse to the IVC) and indicate where the vein is located. Then, the algorithms will start processing the US videos and the vein’s movement will be followed. The detection of IVC required by our algorithms introduces some subjectivity, which can be influenced by a number of conditions. The first is the doctor’s experience, as the position and shape of the vein might vary greatly from patient to patient. In addition, physicians handle the probe with one hand during the acquisition: thus, the indication of the IVC by a mouse managed by the other hand could be uncomfortable, reducing the accuracy of the selection of the parameters needed to begin the automatic analysis.
This study aims to introduce a deep learning algorithm to deal with the constraints imposed by user choices and turn our algorithms into completely automated software programs. We chose deep learning to detect IVC in US scans because it has produced impressive results in many image-recognition tasks [
15,
16,
17,
18]. Convolutional neural networks (CNNs) have been extensively used in a wide range of applications, including human pose estimation [
19], medical image analysis [
20,
21], and other computer vision tasks [
22]. Some applications on IVC investigation have also been proposed in the literature [
23,
24]. Recently, the time for classification required by this kind of model has reduced, making real-time application feasible in US video applications, where the frame rate is some tens per second. Specifically, the
You Only Look Once (YOLO) deep learning algorithm outperformed the R-CNN [
25] in terms of speed and provided good classification accuracy [
17]. This model is mainly adopted for object detection: it was able to identify more than 9000 different objects [
26]. Sporadically, it has been used to analyze medical US images [
27].
In this paper, we extend the range of applications of YOLO architecture to the identification of IVC positions in US video clips. We produced different datasets of manually segmented US frames to train and test different detectors. The datasets contain information on anatomy and tissue motion.
Knowledge of the anatomy of the blood vessels can be useful to distinguish between arteries and veins. Arteries are the blood vessels exiting from the heart and are subjected to high blood pressure. Veins are the blood vessels coming back to the heart; they are subjected to low internal pressure and rely on large compliance to ensure that the blood continues to flow even with a low pressure gradient. Both arteries and veins have three main layers. In order to cope with higher blood pressure, arteries have a thicker tunica media (i.e., the middle layer in the vessel wall) than veins, which are thinner and less elastic (i.e., more compliant). Thus, their shape can change more over time than arteries and is largely affected by the external pressure (in fact, the dynamics of the walls of blood vessels are driven by the transmural pressure, i.e., the internal minus the external pressure [
28]).
IVC exhibits large respirophasic movements, as it is attached to the diaphragm. It is a property which is quite specific of IVC, so it can be very useful to identify and discriminate it from other veins.
In conclusion, we created three datasets of manually delineated IVCs. In the first, we used a single frame, reflecting the anatomy of the tissues; in the second one, we considered the difference between two frames, focusing on information on tissue movements; finally, a linear combination of two frames was used for the third dataset, reflecting both anatomy and movement of the tissues. The classification performance of YOLO applied on the different datasets was assessed and discussed.
2. Materials and Methods
2.1. Manual Segmentation of US Frames
We enrolled 18 patients. The Ethics Committee of Mauriziano Hospital (Turin) approved the study (approval number 388/2020; experimental protocol identifier v.1, 1 June 2020), and informed consent was obtained according to the policies of the institutional review board. Anonymization was applied to protect patient data.
X-plane mode US videos of the IVC were obtained for each patient (GE Vivid E95; GE Healthcare, Vingmed Ultrasound, Horten, Norway). X-plane videos provide the user with two simultaneous views of the same target in perpendicular US planes. The videos were exported by means of a frame grabber (Vinmooog HDMI Video Capture; Shenzhen Yiminmin Trading Co., Ltd., Shenzhen, China), sampling at 30 Hz, connected to the video output of the US system and allowing data to be transferred to a PC. The frames had a resolution of 480 × 480 pixels. Custom software (implemented in Matlab, the Mathworks, Natick, Massachusetts, USA) was written to allow the manual segmentation of the frames. The algorithm allows the operator to perform the following actions:
Delineate the border of the vein with the mouse;
Select the pitch between two segmented frames (we set a pitch of 10 frames);
Analyze the video backwards if the vein is not visible at the beginning of the video, or set exactly the number of starting and ending frames when the vein is visible.
The operator had to set a single point to proceed to the next image if the IVC was not visible in a frame.
Two operators were involved in the segmentation of the US video frames using the above software. Two additional operators reviewed and cleaned the dataset, using a specific software (written in Matlab) to analyze the segmentation, find possible anomalies and correct them.
2.2. Datasets Creation
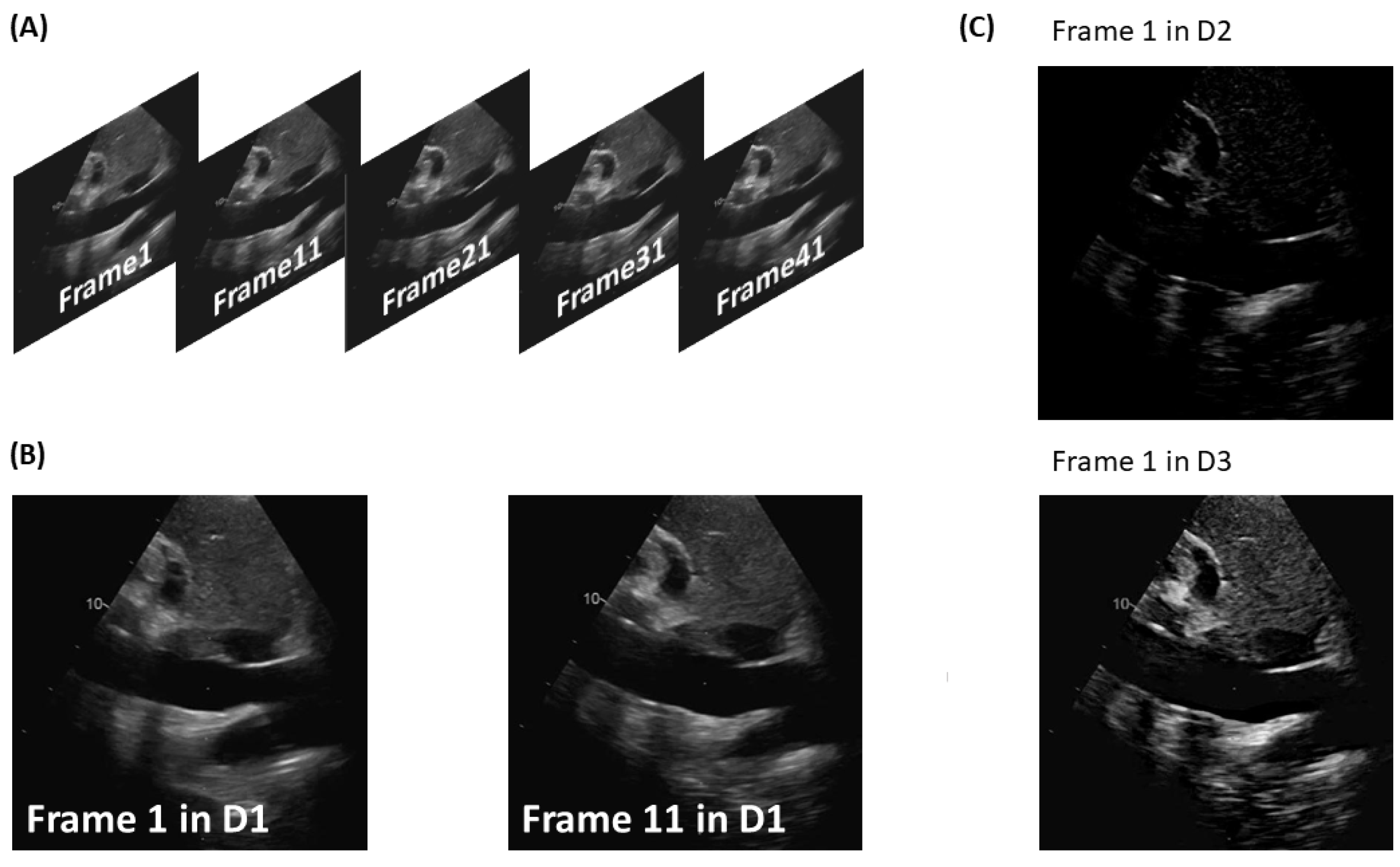
The original dataset D, consisting of 8334 segmented frames, was used to create three comparable datasets, referred to as D1, D2, and D3. These datasets were used to train and test our detection method. For each subject, consecutive pairs of images were considered, excluding frames that did not have a corresponding frame after a pitch of 10 frames. D1 was created by collecting all the frames. On the other hand, D2 and D3 were obtained by applying the following equation:
where
is the target frame on which to detect the IVC.
The frames of D2 were obtained by setting : in this way, information on the movement of tissues was obtained by calculating the difference between consecutive frames. The information obtained from this dataset is believed to be useful in identifying the IVC, as it exhibits significant respirophasic movements. D3 was generated using : both anatomy and movement information were captured, as each image is the sum of the target frame and the movement .
Figure 1 shows two frames from each augmented dataset.
2.3. Cross-Validation
Different YOLO models (v4 [
29] and v4 tiny [
30], described below) were first explored on the entire dataset, fixing the training set as the first 70% of the frames selected from each subject and the test as the last 30%. The best model (in terms of performance and computational cost) was then selected and more deeply tested by cross-validation, separating the subjects used for training and testing. Specifically, to validate the results, we used k-fold (
k = 3) where the subject’s frames were divided into
k groups. However, a simple equipartion of the subjects could not be performed since each recorded video consisted of a variable number of frames. From a computational complexity theory perspective, this is an
-hard problem since it involves a
k-partition [
31]. Thus, an optimization algorithm was designed to maintain a similar number of frames that equally divided the subjects between the folds. The pseudocode of the optimization method is shown in Algorithm 1, with
set to
. The maximum difference in frames between the three folds was 32. We performed training and testing in
k iterations, leaving one fold for testing and training the model on the other two folds in each step. The performance parameters obtained from each iteration were averaged.
| Algorithm 1: An n-dimensional array (where n is the number of subjects) containing integer numbers (indicating the number of frames from each subject) is subdivided into k groups ( used for training and one for testing) with n multiple of k, by minimizing the differences of the sum of the numbers in each group (i.e., their available frames) |
![Electronics 12 01725 i001]() |
2.4. Deep Learning Model
We applied a deep learning model called YOLO, which stands for “You Only Look Once”. It is a recently introduced object detection algorithm, popular in computer vision and for real-time applications [
32]. Given the already remarkable first results, the subsequent tuning over the years has allowed the development of new versions of this deep learning model with exceptional localization efficiency and speed. Some more specific details are given below on YOLO and on YOLO v4, which is the version that we used in this work, both in its original form and in its tiny counterpart.
2.4.1. YOLO
Object detection algorithms aim at identifying the exact location of specific elements in images or videos. Recently, robotics, self-driving cars and automation technologies require accuracy as well as speed. Deformable component models (DPM) assess each filter applied to the picture at a different scale using a classifier. This method showed good accuracy performance [
33]; it requires specific software and hardware optimization to analyze videos in real-time [
34].
The anchor box [
35] strategy was used to reduce the computational cost necessary to achieve classification, speeding up the detection. Using a CNN, YOLO divides the input image into a grid of cells and predicts a border box and the probability that it contains the target to be detected. One convolutional network is performed on the image by YOLO, and model confidence is used to threshold the resulting detections. YOLO combines detection and classification into the following loss function [
17]
where (
x,
y) are the coordinates, (
w,
h) are the width and height of the boundary boxes,
= 5 and
= 0.5 are two parameters set to reduce the instability during training (caused by the high probability that a boundary box does not contain the target object),
represents the presence of the object in the cell
i (where the image is divided into a grid of
cells),
denotes that the
jth boundary box in the
ith cell is responsible for that prediction (
B is the number of bounding boxes within each cell),
denotes the confidence score of the box
j in the cell
i, and
refers to conditional class probabilities for class
c in cell
i. This method enables the deep learning system to achieve outstanding accuracy and amazing classification speed [
17].
2.4.2. YOLO v4
The architecture of YOLO v4 [
29] can be divided into three parts: head, neck, and backbone. Inside these three structural elements, a collection of new methods, called
the bag of freebies and
the bag of specials, were introduced. The bag of freebies is a set of methods that increase the training cost (e.g., data augmentation) but improves the learning of data by the model. The bag of specials contains different plugins and post-processing modules that only increase the inference cost by a small amount but can drastically improve the accuracy of the object detector, e.g., the Mish activation function. We trained YOLO v4 to identify the view of the US scan (among long and short axis) and to detect the IVC in the US frames in our datasets.
2.4.3. YOLO v4 Tiny
The YOLO v4 model is compacted into the YOLO v4 tiny [
30]. Compared to the full model, in the tiny version there are fewer anchor boxes for prediction and only two YOLO layers as opposed to three. Furthermore, 29 convolutional layers are used instead of 137. The architecture is simplified and the number of parameters to be trained is decreased, which improves recognition time performance at the expense of accuracy. Usually, embedded and mobile devices employ this approach [
36].
2.5. Performance Evaluation Methods
To evaluate the performance of our object detection method, the primary metric used was the mean average precision (
). This was achieved by comparing the predicted area produced by the algorithm, represented by a rectangular region, to the ground truth using the intersection over union (IoU) metric:
By setting a threshold of 50% for the IoU, we differentiated between True Positive (TP) and False Positive (FP) predictions based on whether the IoU was above or below the threshold, respectively. When the IVC was not detected, a False Negative (FN) was identified. Precision and recall were then calculated as:
The average precision (
) was computed for each class as the area under the curve defined by the precision–recall relationship:
The was then obtained as the average of the individual values.
In addition, the F1 score was calculated to assess the detection performance:
The performance in terms of processing time was measured as frames per second (FPS), calculated as:
4. Discussion
Reducing operator dependency is very important in US imaging. Our group introduced different methods to process US videos of IVC [
13,
14] supporting standardization and improving repeatability of measurements [
37]. Some preliminary applications have been obtained [
7,
8,
9,
38,
39]. However, our algorithms require a preliminary interaction with the user, so that our techniques can be considered semi-automated and results still depend on the operator’s settings. Moreover, if the operator loses sight of the vein during an acquisition, the measurement should stop and the process should come back to the beginning.
In this paper, we focus on automatizing the detection of the IVC, in order to free the operator from the preliminary procedure and to allow the possibility of IVC recovering in case of problems. Moreover, the either long or short axis view is identified, thus allowing the operator to even change it during the acquisition (by rotating the probe of 90°), without needing to stop the inspection.
We trained different deep learning object detection models, based on YOLO architecture, to identify the IVC in a US video. This is aimed at replacing the first user interaction in our previous segmentation software. Thus, we assume that the operator is interested on IVC detection and is able to point the probe toward the correct tissues: the behavior of our software when applied to US scans of other tissues was not tested, as it is not of interest.
As reported in the Results section, we achieved fairly good IVC detection performance. This work paves the way for a new fully automated IVC detection and edge tracking tool, once integrated with algorithms that delineate the vein either in long or in short axis view. We considered both single frames (showing tissue anatomy) and other two augmented datasets, to highlight different characteristics of IVC. Specifically, in the first dataset, the features that the CNN layers can extract from the images are mostly correlated with the anatomy of the tissues and the geometry of the vein. The second dataset highlights the movements of the tissues, thus providing information on compliance and flexibility of the IVC walls, related to the collapsibility of the vein, together with the respirophasic movement. The last dataset includes a combination of the previous vein characteristics: in fact the geometry of the vein is visible, but at the same time there is additional information about its collapsibility and movement.
4.1. Comparison of Detection Performance
Analyzing the result, we can assume that the additional information extracted from augmented datasets gives both YOLO algorithms additional knowledge to identify the IVC. Indeed, IVC shows large respirophasic motions and wall deformations, so augmenting the information considering tissue movements is reasonably important. In particular, for the YOLO v4 model there is a great performance gain in the identification of IVC in both longitudinal and transverse views: in fact, the average precision increases by 20% comparing the D1 dataset and the augmented dataset D3 (including both information on IVC anatomy and movements). The mean IoU increases by around 24% when comparing outcomes when using either D1 or D3. The model trained with D2 reached intermediate performances with respect to those based on D1 and D3, both in terms of IoU and mAP.
The detection performance of YOLO v4 tiny follows the trend of the YOLO v4 model, with an increase of mAP and IoU over the datasets. Even though the two models had different architectural designs, their performances over D3 were very comparable. However, the performances of the tiny version were generally superior, suggesting the full YOLO v4 model was too complicated (and sometimes overfitted the training data). As YOLO tiny showed equivalent performances and much lower computational cost in the comparison with YOLO v4, we selected it for further validation. Specifically, we used a k-fold cross-validation test, in which the subjects considered for the training were not used for the test. This is an application more similar to the natural conditions of use of our algorithm. The results confirm the accuracy improvement between the dataset D1 and D3. Moreover, the performances are fairly good and quite similar to those obtained by the first investigation, in which frames from the same subjects were used for training and test.
In general, the best performances were obtained with dataset 3: this means that the combination of information on IVC anatomy/geometry and movements/border displacement over time allows the model to identify better the region where the vein is located.
4.2. Time Performance
Our research team has developed segmentation algorithms [
12,
13,
14] that are designed to analyze US videos in real-time with low computational cost, once they are optimized and compiled (which is currently underway). Hence, the IVC detection algorithm also needs to be speedy, in order to be integrated in a tool feasible for applications.
The frame rate of US imaging is determined by the duration required to scan the area of interest. This scanning time, in turn, is influenced by three factors: the depth, line density, and pulse rate of each scan line [
40]. Typically, we use US videos that are captured at a frame rate of around 30 FPS. The frame rate analysis by our YOLO models is promising: it can process videos in real-time, with minimal delay. For example, the YOLO tiny could provide the output with a delay which is less than the sampling period with both the hardware architectures that we tested (indicated in
Table 1). When incorporating a pipeline that uses two frames to capture IVC dynamics, an additional delay is introduced due to the augmented frames being sampled with a 10-pitch (which corresponds to one third of a second, with a frame rate of 30 Hz); after this delay, the estimation provided by our YOLO model can be real time for all subsequent frames. Notice that by using a circular buffer keeping the last 10 frames available, this delay is removed in applications such as IVC retrieval, which is useful when the operator loses sight of the vein due to a fast movement or an artefact. Thus, we are confident that our detection method could be valuable for future integration into a fully automated IVC tracking software. Still considering the good performances and low computational cost of YOLO v4 tiny, apps for embedded and mobile devices could also be feasible.
5. Conclusions
A real-time IVC detection algorithm for US videos is introduced using YOLO v4 network. The model performance was evaluated on a vast dataset of manually segmented US images, and two augmented datasets were created to provide additional information to our detection algorithm. Our findings confirm that incorporating information on IVC movements is crucial to enhance detection performance. The performances of YOLO v4 algorithm and of its tiny version were very similar in preliminary tests on the entire dataset, thus leaning toward preferring the latter, which has a much lower computational cost. The YOLO tiny was then further investigated, by a cross-validation which included different subjects for training and test, obtaining again good performances.
In the future, we plan to integrate IVC detection with our edge tracking algorithms to create fully automated methods. The automation of IVC detection, tracking, and segmentation can reduce the subjectivity of the interpretation of US scans. Additionally, these tools will assist novices, paramedical staff, and nursing in acquiring good US videos and making useful assessments of IVC dynamics.


 ,
, 




{kind=link}
{kind=link}
{kind=link}