
Clustering Algorithms for Enhanced Trustworthiness on High-Performance Edge-Computing Devices

{kind=link}
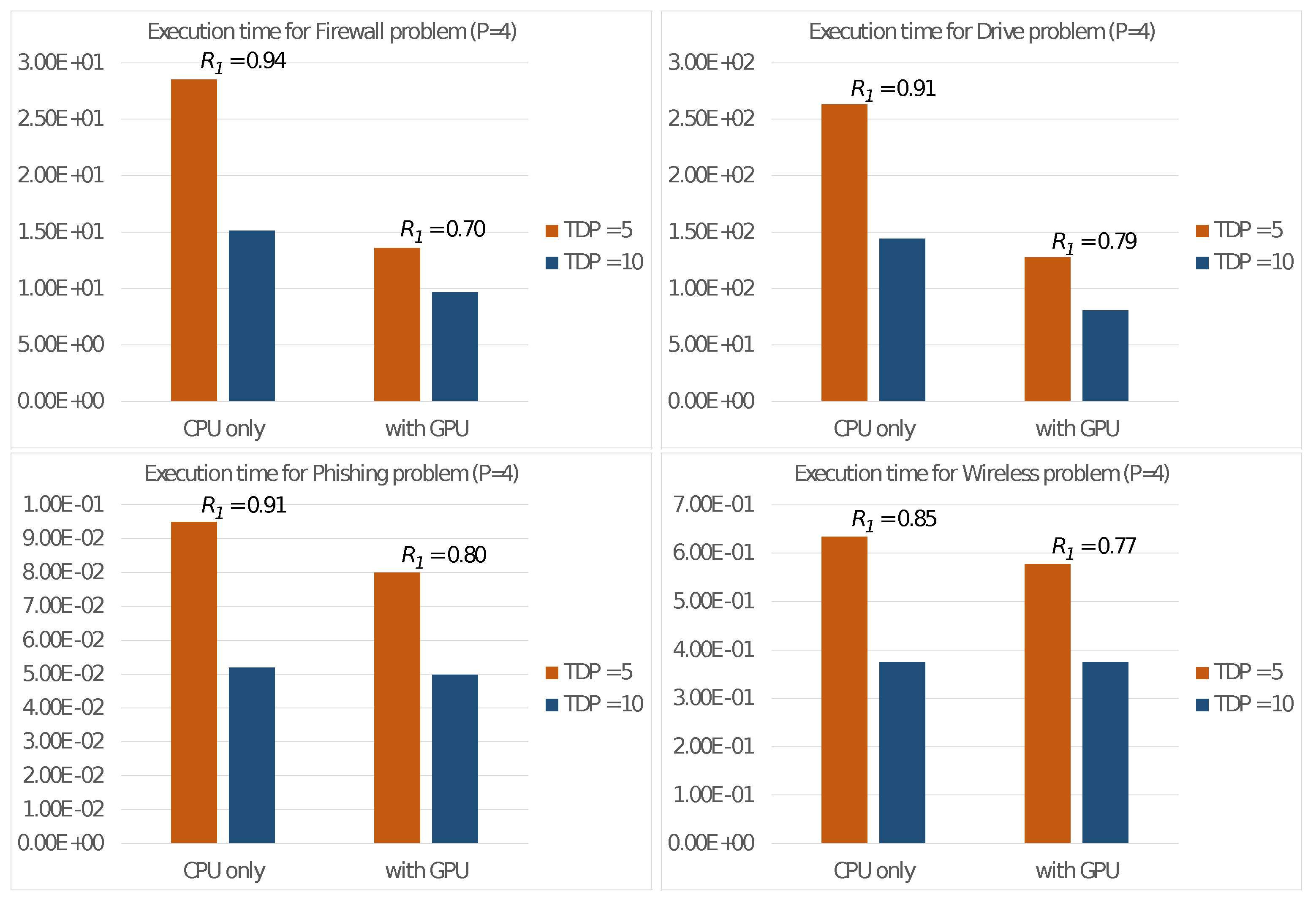{kind=link}
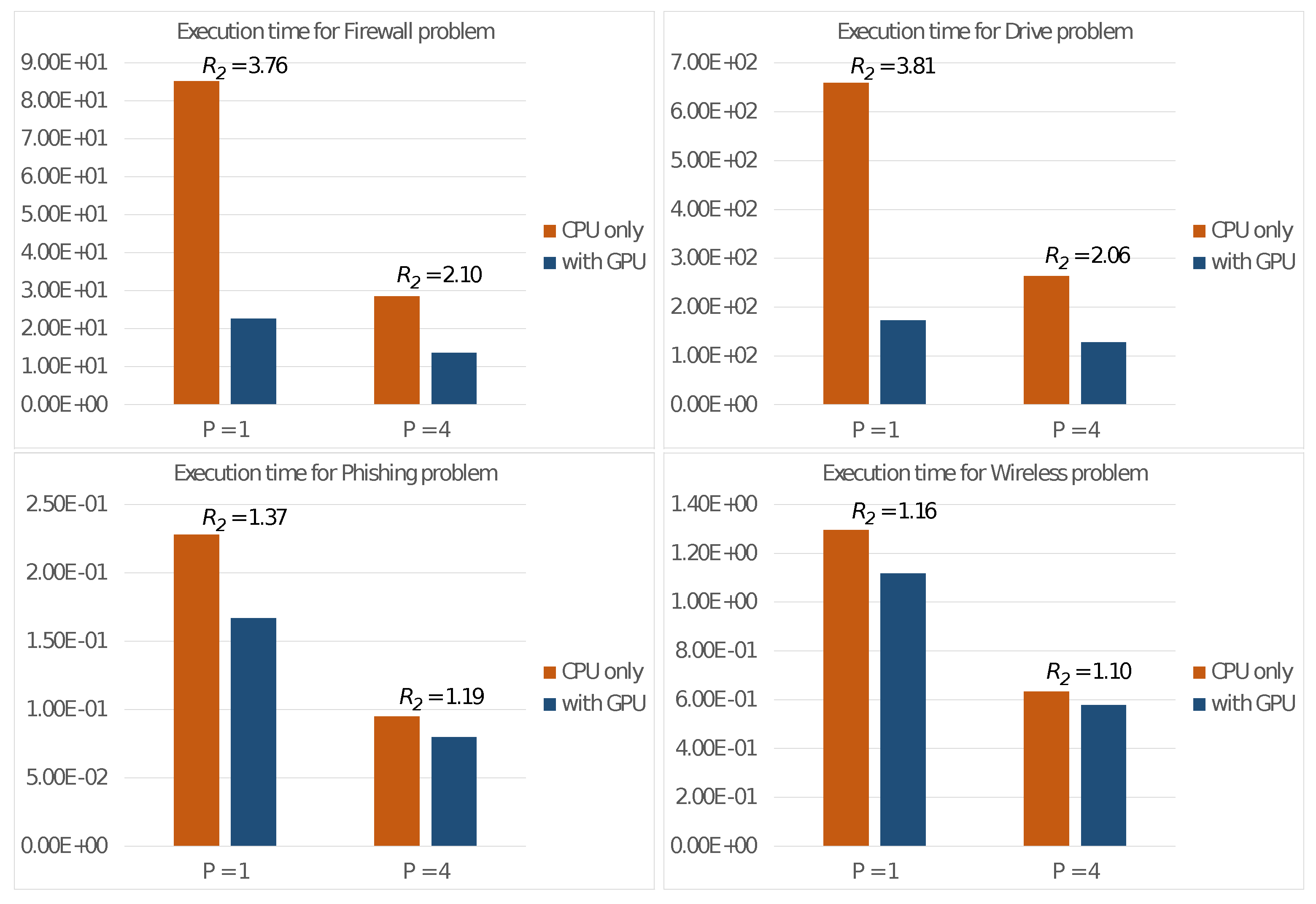{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Works
- The implementation of a hybrid strategy that leverages the multi-core CPU and GPU on the Nvidia Jetson Nano board concurrently, leading to a further reduction in execution time.
- The adoption of a more precise method for measuring energy consumption with a comparison to two other high-end GPU-based systems.
- A study about the possibility of using algorithms to improve the trustworthiness and security of the edge-computing environment.
3. Computing Environment
4. Materials and Methods
| Algorithm 1: Adaptive Clustering Algoritm |
(1) Initialize (2) repeat: (2.1) Increase (2.2) determine the cluster (2.3) define the new partition of clusters as in (3) (2.4) repeat: (2.4.1) for each cluster : update clusters info (2.4.2) for each : search the cluster such that the Euclidean distance is minimal (2.4.3) for each : move to until (the number of reassignment is negligible) (2.5) update the RMSSD until (the variation of RMSSD is negligible) |
| Refinement of Step 2.4.1 |
| (2.4.1-a) for each in parallel |
| (2.4.1-b) for each cluster : update clusters info |
| end parallel for |
| Refinement of Step 2.4.2 |
| (2.4.2-a) for each in parallel |
| search the cluster of belonging |
| end parallel for |
| ( 2.4.2-b) for each in parallel |
| for each : search the cluster of belonging |
| end parallel for |
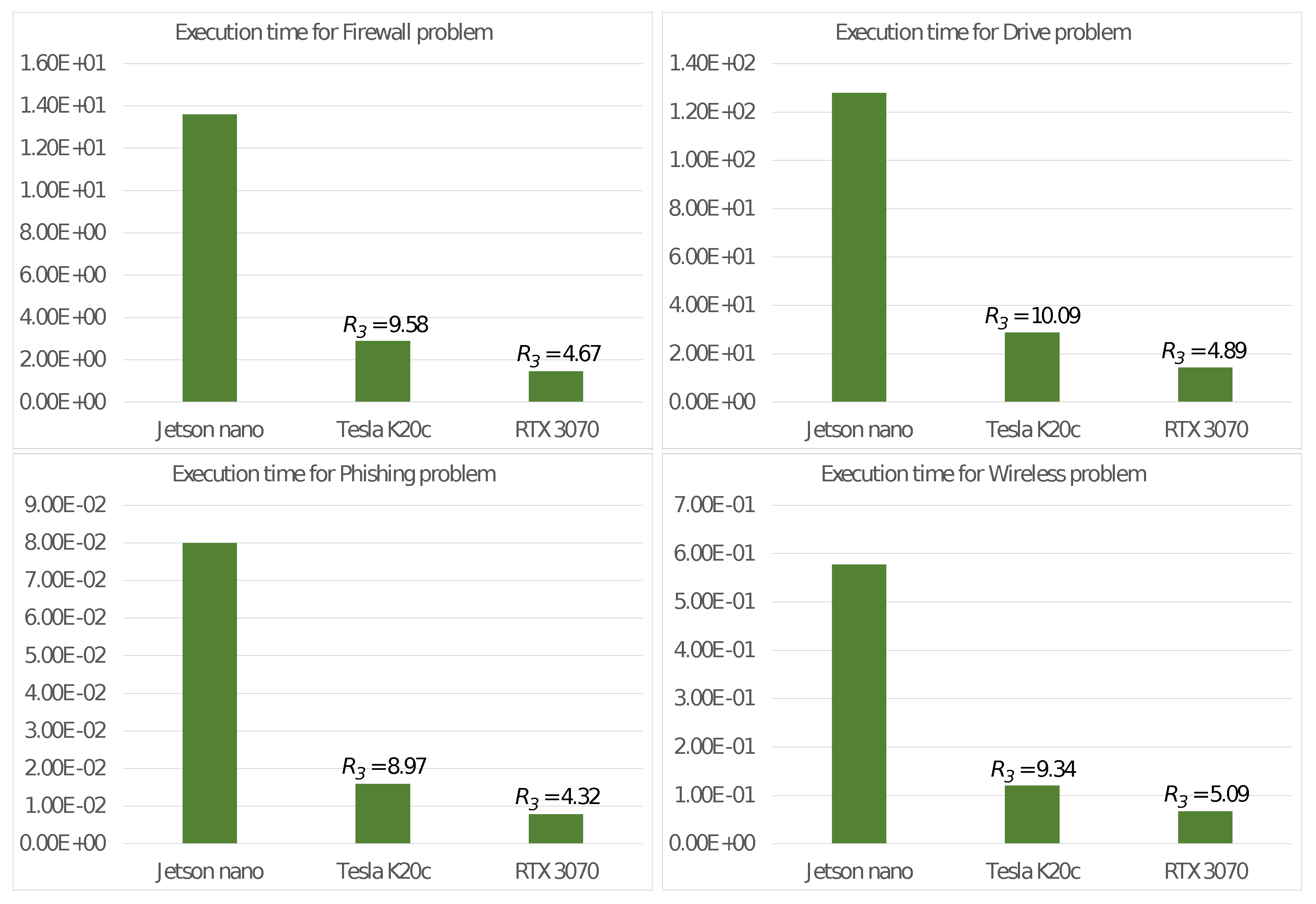
5. Experiments and Discussion
5.1. Design
- The Firewall dataset [33] comprises 65,532 elements, each representing an access on a firewall. These elements are characterized by numerical features and are to be classified into clusters.
- The Drive dataset [34] aims to detect defective components in a car. It comprises 58,509 electric drive signals described by numerical attributes. The signals are to be classified into different classes.
- The Phishing dataset [35] is related to the identification of phishing websites. It contains elements, each representing a website described through features. These websites are to be classified into clusters (phishing, legitimate or suspicious).
- The Wireless dataset [36] involves classifying 2.4 GHz radio signals based on their strengths in an indoor location. They are classified into locations based on features.
5.2. Experiments
- (TK20)
- utilizes a host CPU with a 4-core Intel Core i7-950 clocked at 3.07 GHz. The accompanying floating point accelerator is an Nvidia Tesla K20c GPU introduced in 2012, boasting 2496 CUDA cores with a clock speed of 0.706 GHz, a global memory capacity of 5 GBytes and a TDP of 225 Watts.
- (RTX)
- is based on a host CPU with an 8-core Intel Core i9-9900K running at a frequency of 3.6 GHz. The accelerator unit is the more recent Nvidia GeForce RTX 3070 GPU introduced in 2020, having 5888 CUDA cores operating at 1.75 GHz, 8 GBytes of global memory and a TDP of 220 Watts.
5.3. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Beckman, P.; Dongarra, J.; Ferrier, N.; Fox, G.; Moore, T.; Reed, D.; Beck, M. Harnessing the Computing Continuum for Programming Our World. In Fog Computing: Theory and Practice; Zomaya, A., Abbas, A., Khan, S., Eds.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2020. [Google Scholar]
- Cheptsov, A.; Koller, B.; Adami, D.; Davoli, F.; Mueller, S.; Meyer, N.; Lazzari, P.; Salon, S.; Watzl, J.; Schiffers, M.; et al. E-Infrastructure for Remote Instrumentation. Comput. Statd. Interfaces 2021, 34, 476–484. [Google Scholar] [CrossRef]
- Yu, W.; Liang, F.; He, X.; Hatcher, W.G.; Lu, C.; Lin, J.; Yang, X. A Survey on the Edge Computing for the Internet of Things. IEEE Access 2018, 6, 6900–6919. [Google Scholar] [CrossRef]
- di Luccio, D.; Riccio, A.; Galletti, A.; Laccetti, G.; Lapegna, M.; Marcellino, L.; Kosta, S.; Montella, R. Coastal Marine Data Crowdsourcing Using the Internet of Floating Things: Improving the Results of a Water Quality Model. IEEE Access 2020, 8, 101209–101223. [Google Scholar] [CrossRef]
- Romano, D.; Lapegna, M.; Mele, V.; Laccetti, G. Designing a GPU-parallel algorithm for raw SAR data compression: A focus on parallel performance estimation. Future Gener. Comput. Syst. 2020, 112, 695–708. [Google Scholar] [CrossRef]
- Lapegna, M.; Stranieri, S. DClu: A Direction-Based Clustering Algorithm for VANETs Management. In Innovative Mobile and Internet Services in Ubiquitous Computing, Proceedings of the 15th International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing (IMIS-2021), Asan, Republic of Korea, 1–3 July 2021; Lecture Notes in Networks and Systems; Springer Nature: Cham, Switzerland, 2022; Volume 279, pp. 253–262. [Google Scholar]
- Balzano, W.; Lapegna, M.; Stranieri, S.; Vitale, F. Competitive-blockchain-based parking system with fairness constraints. Soft Comput. 2022, 26, 4151–4162. [Google Scholar] [CrossRef]
- Deng, S.; Zhao, H.; Fang, W.; Yin, J.; Dustdar, S.; Zomaya, A.Y. Edge Intelligence: The Confluence of Edge Computing and Artificial Intelligence. IEEE Internet Things J. 2020, 7, 7457–7469. [Google Scholar] [CrossRef] [Green Version]
- Bao, F.; Chen, I.; Chang, M.; Cho, J. Hierarchical Trust Management for Wireless Sensor Networks and its Applications to Trust-Based Routing and Intrusion Detection. IEEE Trans. Netw. Serv. Manag. 2012, 9, 169–183. [Google Scholar] [CrossRef]
- Kammoun, N.; Abassi, R.; Guemara, S. Towards a New Clustering Algorithm based on Trust Management and Edge Computing for IoT. In Proceedings of the 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 1570–1575. [Google Scholar]
- Dongarra, J.; Gannon, D.; Fox, G.; Kennedy, K. The Impact of Multi-core on Computational Science Software. CTWatch Q. 2007, 3, 1–10. [Google Scholar]
- Wang, T.; Wang, P.; Cai, S.; Ma, Y.; Liu, A.; Xie, M. A Unified Trustworthy Environment Establishment Based on Edge Computing in Industrial IoT. IEEE Trans. Ind. Inf. 2020, 16, 6083–6091. [Google Scholar] [CrossRef]
- Sun, Y.; Ochiai, H.; Esaki, H. Decentralized Deep Learning for Multi-Access Edge Computing: A Survey on Communication Efficiency and Trustworthiness. IEEE Trans. Artif. Intell. 2022, 3, 963–972. [Google Scholar] [CrossRef]
- Wang, T.; Qiu, L.; Sangaiah, A.K.; Liu, A.; Bhuiyan, M.Z.A.; Ma, Y. Edge-Computing-Based Trustworthy Data Collection Model in the Internet of Things. IEEE Internet Things J. 2020, 7, 4218–4227. [Google Scholar] [CrossRef]
- Li, E.; Zhou, Z.; Chen, X. Edge intelligence: On-demand deep learning model co-inference with device-edge synergy. In Proceedings of the 2018 Workshop on Mobile Edge Communications, MECOMM@SIGCOMM 2018, Budapest, Hungary, 20 August 2018; pp. 31–36. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Lee, J.; Eshraghian, J.K.; Cho, K.; Eshraghian, K. Adaptive precision CNN accelerator using radix-x parallel-connected memristor crossbars. arXiv 2019, arXiv:1906.09395. [Google Scholar]
- Sze, V.; Chen, Y.; Yang, T.; Emer, J.S. Efficient processing of deep neural networks: A tutorial and survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef] [Green Version]
- Lapegna, M.; Mele, V.; Romano, D. An Adaptive Strategy for Dynamic Data Clustering with the K-Means Algorithm. In Parallel Processing and Applied Mathematics, Proceedings of the PPAM 2019, Bialystok, Poland, 8–11 September 2019; Wyrzykowski, R., Deelman, E., Dongarra, J., Karczewski, K., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12044, pp. 101–110. [Google Scholar]
- Laccetti, G.; Lapegna, M.; Mele, V.; Romano, D.; Szustak, L. Performance enhancement of a dynamic K-means algorithm through a parallel adaptive strategy on multi-core CPUs. J. Parallel Distrib. Comput. 2020, 145, 34–41. [Google Scholar] [CrossRef]
- Lapegna, M.; Balzano, W.; Meyer, N.; Romano, D. Clustering Algorithms on Low-Power and High-Performance Devices for Edge Computing Environments. Sensors 2021, 21, 5395. [Google Scholar] [CrossRef]
- Laccetti, G.; Lapegna, M.; Montella, R. Toward a high-performance clustering algorithm for securing edge computing environments. In Proceedings of the 2022 22nd IEEE International Symposium on Cluster, Cloud and Internet Computing (CCGrid), Taormina, Italy, 16–19 May 2022; pp. 820–825. [Google Scholar]
- Nvidia Jetson Nano Documentation. Available online: https://developer.nvidia.com/embedded/jetson-nano-developer-kit (accessed on 12 February 2023).
- Gan, D.G.; Ma, C.; Wu, J. Data Clustering: Theory, Algorithms, and Applications; ASA-SIAM Series on Statistics and Applied Probability; SIAM: Philadelphia, PA, USA; ASA: Alexandria, VA, USA, 2007. [Google Scholar]
- Halkidi, M.; Batistakis, Y.; Vazirgiannis, M. On clustering validation techniques. Journ. Intell. Inf. Syst. 2001, 17, 107–145. [Google Scholar] [CrossRef]
- Laccetti, G.; Lapegna, M.; Mele, V.; Montella, R. An adaptive algorithm for high-dimensional integrals on heterogeneous CPU-GPU systems. Concurr. Comput. Pract. Exp. 2019, 31, e4945. [Google Scholar] [CrossRef]
- Thompson, J.F. A survey of dynamically-adaptive grids in the numerical solution of partial differential equations. Appl. Numer. Math. 1985, 1, 3–27. [Google Scholar] [CrossRef]
- Haase, W.; Misegades, K.; Naar, M. Adaptive grids in numerical fluid dynamics. Numer. Methods Fluids 1985, 5, 515–528. [Google Scholar] [CrossRef]
- The Top 500 List. Available online: https://www.top500.org (accessed on 12 February 2023).
- Junior, F.M.R.; Kamienski, C.A. A Survey on Trustworthiness for the Internet of Things. IEEE Access 2021, 9, 42493–42514. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository. In Science; School of Information and Computer, University of California: Irvine, CA, USA, 2019; Available online: http://archive.ics.uci.edu/ml (accessed on 12 February 2023).
- Ertam, F.; Kaya, M. Classification of firewall log files with multiclass support vector machine. In Proceedings of the sixth International Symposium on Digital Forensic and Security (ISDFS), Antalya, Turkey, 22–25 March 2018; pp. 1–4. [Google Scholar]
- Paschke, F.; Bayer, C.; Bator, M.; Mönks, U.; Dicks, A.; Enge-Rosenblatt, O.; Lohweg, V. Sensorlose Zustandsüberwachung an Synchronmotoren. In Proceedings of the Workshop Computational Intelligence, Dortmund, Germany, 5–6 December 2013; Volume 46, pp. 211–225. [Google Scholar]
- Abdelhamid, N.; Ayesh, A.; Thabtah, F. Phishing detection based Associative Classification data mining. Expert Syst. Appl. 2014, 41, 5948–5959. [Google Scholar] [CrossRef]
- AlHajri, M.I.; Ali, N.T.; Shubair, R.M. Classification of Indoor Environments for IoT Applications: A Machine Learning Approach. IEEE Antennas Wirel. Propag. Lett. 2018, 17, 2164–2168. [Google Scholar]
- Tahoori, M.B.; Pedram, M. Energy-Efficient Computing; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Ouyang, Y.; Liu, X.; Luo, J.; Zhao, Y. Characterizing Energy Efficiency and Performance of Parallel Workloads on Multicore Systems. IEEE Trans. Comput. 2018, 62, 1506–1520. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lapegna, M.; Mele, V.; Romano, D. Clustering Algorithms for Enhanced Trustworthiness on High-Performance Edge-Computing Devices. Electronics 2023, 12, 1689. https://doi.org/10.3390/electronics12071689
Lapegna M, Mele V, Romano D. Clustering Algorithms for Enhanced Trustworthiness on High-Performance Edge-Computing Devices. Electronics. 2023; 12(7):1689. https://doi.org/10.3390/electronics12071689
Chicago/Turabian StyleLapegna, Marco, Valeria Mele, and Diego Romano. 2023. "Clustering Algorithms for Enhanced Trustworthiness on High-Performance Edge-Computing Devices" Electronics 12, no. 7: 1689. https://doi.org/10.3390/electronics12071689