
Video Saliency Object Detection with Motion Quality Compensation

Abstract
:1. Introduction
2. Related Work
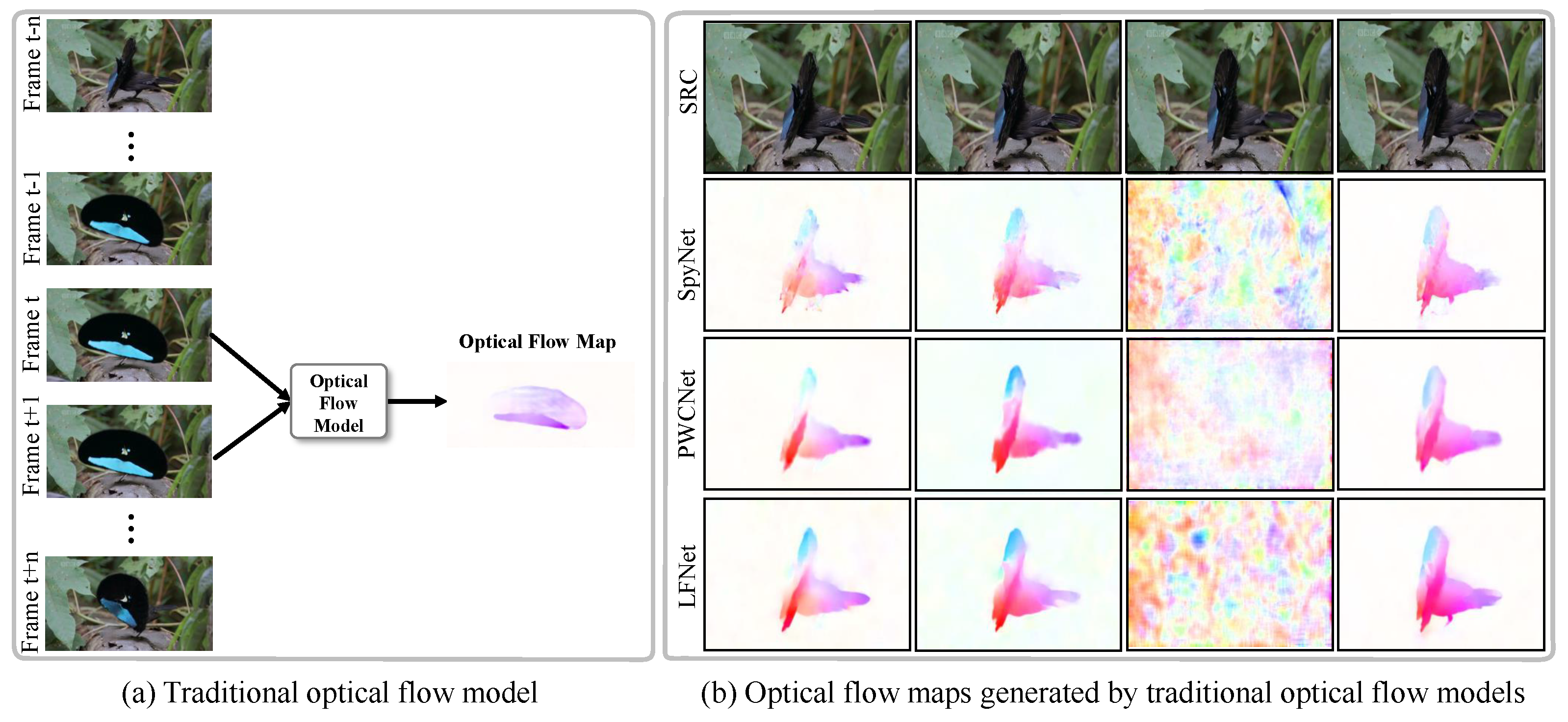
2.1. Traditional Optical Flow Model
2.2. Deep Learning-Based Optical Flow Model
2.3. Video Saliency Object Detection Using Optical Flow
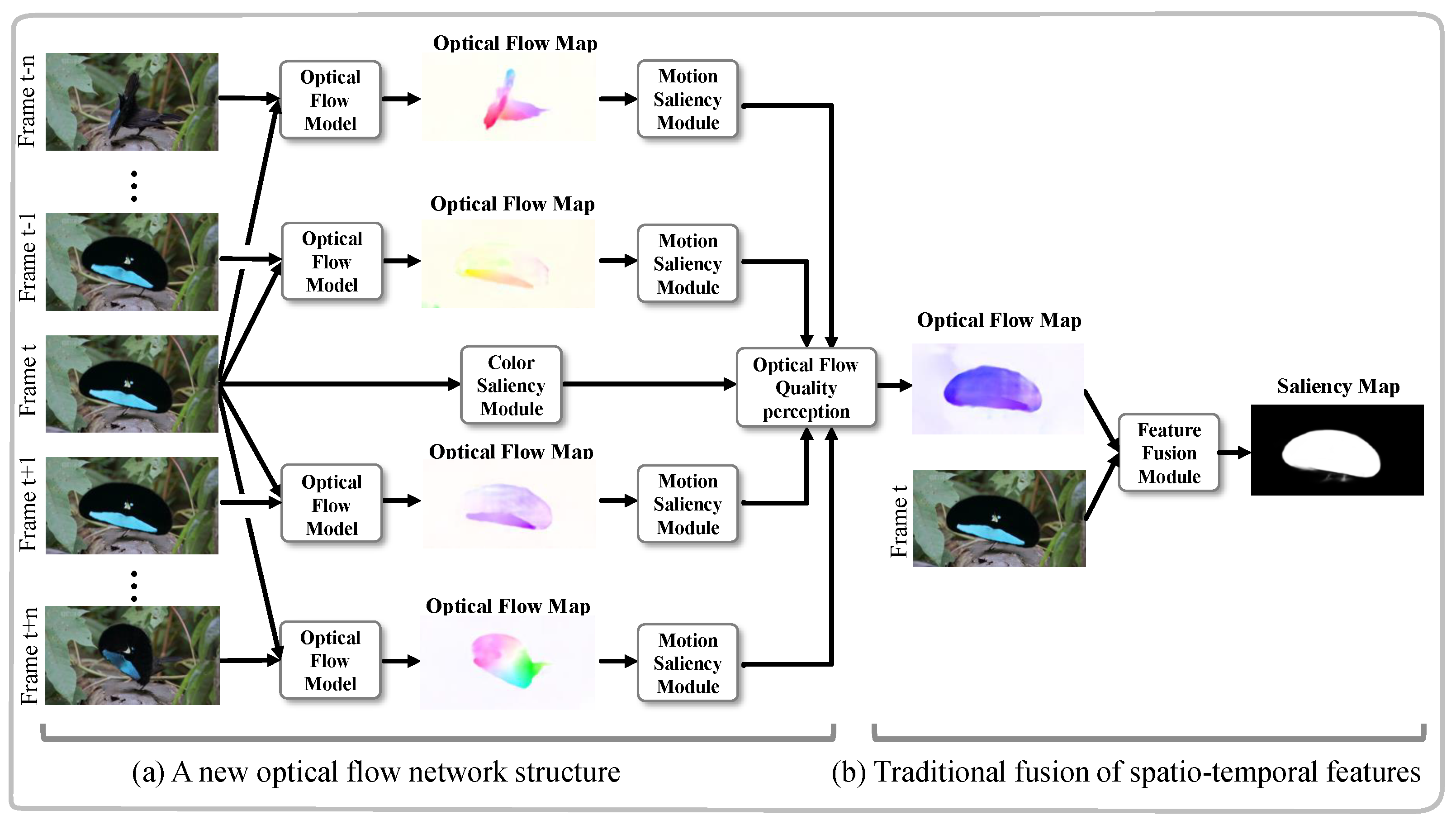
3. Method Overview
3.1. Existing Optical Flow Models
3.2. A Novel Optical Flow Model
3.2.1. Motion Saliency Module
3.2.2. Color Saliency Module
3.2.3. Enlarging the Optical Flow Perception Range
3.2.4. Optical Flow Quality Perception Module
4. Experiments
4.1. Datasets
4.2. Experimental Environment
4.3. Evaluation Metrics
5. Experimental Results Analysis
5.1. Ablation Experiment for the Parameter n
5.2. Validity Analysis of the Proposed Optical Flow Model
5.2.1. Quantitative Analysis
5.2.2. Comparison with Current Mainstream VSOD Models
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, C.; Li, Y.; Li, S.; Qin, H.; Hao, A. A novel bottom-up saliency detection method for video with dynamic background. IEEE Signal Process. Lett. 2017, 25, 154–158. [Google Scholar] [CrossRef]
- Chen, C.; Song, J.; Peng, C.; Wang, G.; Fang, Y. A novel video salient object detection method via semisupervised motion quality perception. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 2732–2745. [Google Scholar] [CrossRef]
- Chen, C.; Li, S.; Wang, Y.; Qin, H.; Hao, A. Video saliency detection via spatial-temporal fusion and low-rank coherency diffusion. IEEE Trans. Image Process. 2017, 26, 3156–3170. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Li, S.; Qin, H.; Hao, A. Structure-sensitive saliency detection via multilevel rank analysis in intrinsic feature space. IEEE Trans. Image Process. 2015, 24, 2303–2316. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Wang, G.; Peng, C. Structure-aware adaptive diffusion for video saliency detection. IEEE Access 2019, 7, 79770–79782. [Google Scholar] [CrossRef]
- Lin, L.; Yang, J.; Wang, Z.; Zhou, L.; Chen, W.; Xu, Y. Compressed Video Quality Index Based on Saliency-Aware Artifact Detection. Sensors 2021, 21, 6429. [Google Scholar] [CrossRef] [PubMed]
- Belloulata, K.; Belalia, A.; Zhu, S. Object-based stereo video compression using fractals and shape-adaptive DCT. AEU Int. J. Electron. Commun. 2014, 68, 687–697. [Google Scholar] [CrossRef]
- Kumar, A.; Kaur, A.; Kumar, M. Face detection techniques: A review. Artif. Intell. Rev. 2019, 52, 927–948. [Google Scholar] [CrossRef]
- Cong, R.; Lei, J.; Fu, H.; Cheng, M.M.; Lin, W.; Huang, Q. Review of visual saliency detection with comprehensive information. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 2941–2959. [Google Scholar] [CrossRef] [Green Version]
- Kong, Y.; Wang, Y.; Li, A.; Huang, Q. Self-sufficient feature enhancing networks for video salient object detection. IEEE Trans. Multimed. 2021, 25, 557–571. [Google Scholar] [CrossRef]
- Chen, C.; Li, S.; Qin, H.; Hao, A. Robust salient motion detection in non-stationary videos via novel integrated strategies of spatio-temporal coherency clues and low-rank analysis. Pattern Recognit. 2016, 52, 410–432. [Google Scholar] [CrossRef]
- Li, Y.; Li, S.; Chen, C.; Hao, A.; Qin, H. Accurate and robust video saliency detection via self-paced diffusion. IEEE Trans. Multimed. 2019, 22, 1153–1167. [Google Scholar] [CrossRef]
- Chen, C.; Wang, G.; Peng, C.; Fang, Y.; Zhang, D.; Qin, H. Exploring rich and efficient spatial temporal interactions for real-time video salient object detection. IEEE Trans. Image Process. 2021, 30, 3995–4007. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Sui, X.; Gu, G.; Chen, Q.; Cao, H. Infrared thermal imaging super-resolution via multiscale spatio-temporal feature fusion network. IEEE Sens. J. 2021, 21, 19176–19185. [Google Scholar] [CrossRef]
- Yao, Y.; Xu, M.; Choi, C.; Crandall, D.J.; Atkins, E.M.; Dariush, B. Egocentric vision-based future vehicle localization for intelligent driving assistance systems. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9711–9717. [Google Scholar]
- Qi, G.; Zhang, Y.; Wang, K.; Mazur, N.; Liu, Y.; Malaviya, D. Small object detection method based on adaptive spatial parallel convolution and fast multi-scale fusion. Remote Sens. 2022, 14, 420. [Google Scholar] [CrossRef]
- Kale, K.; Pawar, S.; Dhulekar, P. Moving object tracking using optical flow and motion vector estimation. In Proceedings of the 2015 4th International Conference on Reliability, Infocom Technologies and Optimization (ICRITO) (Trends and Future Directions), Noida, India, 2–4 September 2015; pp. 1–6. [Google Scholar]
- Yun, H.; Park, D. Efficient Object Detection Based on Masking Semantic Segmentation Region for Lightweight Embedded Processors. Sensors 2022, 22, 8890. [Google Scholar] [CrossRef] [PubMed]
- Wei, S.G.; Yang, L.; Chen, Z.; Liu, Z.F. Motion detection based on optical flow and self-adaptive threshold segmentation. Procedia Eng. 2011, 15, 3471–3476. [Google Scholar] [CrossRef] [Green Version]
- Domingues, J.; Azpúrua, H.; Freitas, G.; Pessin, G. Localization of mobile robots through optical flow and sensor fusion in mining environments. In Proceedings of the 2022 Latin American Robotics Symposium (LARS), 2022 Brazilian Symposium on Robotics (SBR), and 2022 Workshop on Robotics in Education (WRE), Sao Paulo, Brazil, 18–21 October 2022; pp. 1–6. [Google Scholar]
- Sui, X.; Li, S.; Geng, X.; Wu, Y.; Xu, X.; Liu, Y.; Goh, R.; Zhu, H. Craft: Cross-attentional flow transformer for robust optical flow. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 July 2022; pp. 17602–17611. [Google Scholar]
- Xu, H.; Zhang, J.; Cai, J.; Rezatofighi, H.; Tao, D. Gmflow: Learning optical flow via global matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 July 2022; pp. 8121–8130. [Google Scholar]
- Ranjan, A.; Black, M.J. Optical flow estimation using a spatial pyramid network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4161–4170. [Google Scholar]
- Sun, D.; Yang, X.; Liu, M.Y.; Kautz, J. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 July 2018; pp. 8934–8943. [Google Scholar]
- Hui, T.W.; Tang, X.; Loy, C.C. Liteflownet: A lightweight convolutional neural network for optical flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 July 2018; pp. 8981–8989. [Google Scholar]
- Chen, C.; Wang, H.; Fang, Y.; Peng, C. A novel long-term iterative mining scheme for video salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7662–7676. [Google Scholar] [CrossRef]
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the IJCAI’81: 7th International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981; Volume 2, pp. 674–679. [Google Scholar]
- Wulff, J.; Black, M.J. Efficient sparse-to-dense optical flow estimation using a learned basis and layers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 120–130. [Google Scholar]
- Revaud, J.; Weinzaepfel, P.; Harchaoui, Z.; Schmid, C. Epicflow: Edge-preserving interpolation of correspondences for optical flow. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1164–1172. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. Flownet: Learning optical flow with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 2758–2766. [Google Scholar]
- Liu, P.; King, I.; Lyu, M.R.; Xu, J. Ddflow: Learning optical flow with unlabeled data distillation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8770–8777. [Google Scholar]
- Ding, M.; Wang, Z.; Zhou, B.; Shi, J.; Lu, Z.; Luo, P. Every frame counts: Joint learning of video segmentation and optical flow. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10713–10720. [Google Scholar]
- Li, H.; Chen, G.; Li, G.; Yu, Y. Motion guided attention for video salient object detection. In Proceedings of the IEEE/CVF international conference on computer vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7274–7283. [Google Scholar]
- Zhou, T.; Li, J.; Wang, S.; Tao, R.; Shen, J. Matnet: Motion-attentive transition network for zero-shot video object segmentation. IEEE Trans. Image Process. 2020, 29, 8326–8338. [Google Scholar] [CrossRef]
- Ren, S.; Han, C.; Yang, X.; Han, G.; He, S. Tenet: Triple excitation network for video salient object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 212–228. [Google Scholar]
- Chen, C.; Li, S.; Qin, H.; Pan, Z.; Yang, G. Bilevel feature learning for video saliency detection. IEEE Trans. Multimed. 2018, 20, 3324–3336. [Google Scholar] [CrossRef]
- Khan, S.D.; Bandini, S.; Basalamah, S.; Vizzari, G. Analyzing crowd behavior in naturalistic conditions: Identifying sources and sinks and characterizing main flows. Neurocomputing 2016, 177, 543–563. [Google Scholar] [CrossRef] [Green Version]
- Cheng, M.M.; Mitra, N.J.; Huang, X.; Torr, P.H.; Hu, S.M. Global contrast based salient region detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 569–582. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Su, L.; Huang, Q. Cascaded partial decoder for fast and accurate salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2019; pp. 3907–3916. [Google Scholar]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4548–4557. [Google Scholar]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Perazzi, F.; Krähenbühl, P.; Pritch, Y.; Hornung, A. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 733–740. [Google Scholar]
- Perazzi, F.; Pont-Tuset, J.; McWilliams, B.; Van Gool, L.; Gross, M.; Sorkine-Hornung, A. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 724–732. [Google Scholar]
- Li, F.; Kim, T.; Humayun, A.; Tsai, D.; Rehg, J.M. Video segmentation by tracking many figure-ground segments. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 1–8 December 2013; pp. 2192–2199. [Google Scholar]
- Wang, W.; Shen, J.; Shao, L. Consistent video saliency using local gradient flow optimization and global refinement. IEEE Trans. Image Process. 2015, 24, 4185–4196. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fan, D.P.; Wang, W.; Cheng, M.M.; Shen, J. Shifting more attention to video salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2019; pp. 8554–8564. [Google Scholar]
- Li, J.; Xia, C.; Chen, X. A benchmark dataset and saliency-guided stacked autoencoders for video-based salient object detection. IEEE Trans. Image Process. 2017, 27, 349–364. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, X.; Gao, H.; Yu, L.; Yang, D.; Zhang, J. Quality-Driven Dual-Branch Feature Integration Network for Video Salient Object Detection. Electronics 2023, 12, 680. [Google Scholar] [CrossRef]
- Liu, Z.y.; Liu, J.w. Part-aware attention correctness for video salient object detection. Eng. Appl. Artif. Intell. 2023, 119, 105733. [Google Scholar] [CrossRef]
- Zhang, M.; Liu, J.; Wang, Y.; Piao, Y.; Yao, S.; Ji, W.; Li, J.; Lu, H.; Luo, Z. Dynamic context-sensitive filtering network for video salient object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, USA, 10–17 October 2021; pp. 1553–1563. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, L.; Wang, Z.; Liu, Y.; Cheng, M.M.; Lu, S.P. Pyramid constrained self-attention network for fast video salient object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10869–10876. [Google Scholar]
- Chen, C.; Wang, G.; Peng, C.; Zhang, X.; Qin, H. Improved robust video saliency detection based on long-term spatial-temporal information. IEEE Trans. Image Process. 2019, 29, 1090–1100. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Metrics | ||||
|---|---|---|---|---|---|
| maxF | 0.787 | 0.798 | 0.790 | 0.789 | |
| Davis [43] | SM | 0.844 | 0.855 | 0.848 | 0.846 |
| MAE | 0.049 | 0.044 | 0.048 | 0.047 | |
| maxF | 0.648 | 0.699 | 0.701 | 0.695 | |
| Segtrack-v2 [44] | SM | 0.760 | 0.791 | 0.795 | 0.790 |
| MAE | 0.054 | 0.045 | 0.043 | 0.047 | |
| maxF | 0.624 | 0.734 | 0.722 | 0.725 | |
| Visal [45] | SM | 0.736 | 0.796 | 0.786 | 0.790 |
| MAE | 0.079 | 0.066 | 0.070 | 0.069 |
| Dataset | Davis [43] | Segtrack-v2 [44] | Visal [45] | DAVSOD [46] | VOS [47] | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metrics | maxF | S-M | MAE | maxF | S-M | MAE | maxF | S-M | MAE | maxF | S-M | MAE | maxF | S-M | MAE |
| Ours | 0.798 | 0.855 | 0.044 | 0.699 | 0.791 | 0.045 | 0.734 | 0.796 | 0.066 | 0.798 | 0.855 | 0.044 | 0.699 | 0.791 | 0.045 |
| CRAFT [21] | 0.795 | 0.850 | 0.044 | 0.695 | 0.789 | 0.048 | 0.731 | 0.793 | 0.069 | 0.793 | 0.848 | 0.046 | 0.695 | 0.688 | 0.048 |
| GMFlow [22] | 0.792 | 0.847 | 0.046 | 0.690 | 0.787 | 0.050 | 0.730 | 0.792 | 0.071 | 0.790 | 0.842 | 0.048 | 0.691 | 0.685 | 0.049 |
| PWCNet [24] | 0.787 | 0.844 | 0.049 | 0.648 | 0.760 | 0.054 | 0.624 | 0.736 | 0.079 | 0.450 | 0.613 | 0.148 | 0.405 | 0.566 | 0.167 |
| SpyNet [23] | 0.727 | 0.801 | 0.065 | 0.596 | 0.733 | 0.078 | 0.659 | 0.762 | 0.092 | 0.382 | 0.574 | 0.182 | 0.403 | 0.562 | 0.188 |
| LFNet [25] | 0.781 | 0.843 | 0.049 | 0.656 | 0.766 | 0.059 | 0.674 | 0.764 | 0.081 | 0.408 | 0.592 | 0.168 | 0.380 | 0.551 | 0.189 |
| Dataset | Davis [43] | B | Visal [45] | DAVSOD [46] | VOS [47] |
|---|---|---|---|---|---|
| Ours | 11 | 9 | 8 | 20 | 35 |
| CRAFT [21] | 9 | 7 | 6 | 15 | 26 |
| GMFlow [22] | 9 | 8 | 7 | 16 | 28 |
| SpyNet [23] | 8 | 6 | 5 | 16 | 28 |
| PWCNet [24] | 9 | 7 | 6 | 15 | 27 |
| LFNet [25] | 10 | 8 | 7 | 17 | 28 |
| Dataset | Davis [43] | Segtrack-v2 [44] | Visal [45] | DAVSOD [46] | VOS [47] |
|---|---|---|---|---|---|
| Ours | 24 | 12 | 11 | 89 | 476 |
| CRAFT [21] | 20 | 9 | 8 | 78 | 356 |
| GMFlow [22] | 21 | 9 | 8 | 77 | 351 |
| SpyNet [23] | 21 | 10 | 8 | 79 | 360 |
| PWCNet [24] | 18 | 9 | 6 | 54 | 350 |
| LFNet [25] | 19 | 10 | 9 | 61 | 345 |
| Dataset | Davis [43] | Segtrack-v2 [44] | Visal [45] | DAVSOD [46] | VOS [47] | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metrics | maxF | S-M | MAE | maxF | S-M | MAE | maxF | S-M | MAE | maxF | S-M | MAE | maxF | S-M | MAE |
| +Ours | 0.914 | 0.924 | 0.014 | 0.881 | 0.910 | 0.013 | 0.955 | 0.948 | 0.011 | 0.735 | 0.799 | 0.060 | 0.832 | 0.852 | 0.058 |
| +CRAFT [21] | 0.913 | 0.923 | 0.015 | 0.877 | 0.907 | 0.015 | 0.952 | 0.946 | 0.013 | 0.727 | 0.795 | 0.063 | 0.811 | 0.845 | 0.063 |
| +GMFlow [22] | 0.912 | 0.922 | 0.016 | 0.879 | 0.908 | 0.014 | 0.953 | 0.947 | 0.012 | 0.729 | 0.797 | 0.063 | 0.815 | 0.849 | 0.060 |
| +PWCNet [24] | 0.913 | 0.924 | 0.015 | 0.875 | 0.905 | 0.015 | 0.950 | 0.945 | 0.012 | 0.723 | 0.794 | 0.064 | 0.801 | 0.841 | 0.067 |
| +SpyNet [23] | 0.910 | 0.922 | 0.015 | 0.861 | 0.899 | 0.016 | 0.953 | 0.948 | 0.012 | 0.717 | 0.790 | 0.065 | 0.787 | 0.832 | 0.069 |
| +LFNet [25] | 0.910 | 0.920 | 0.016 | 0.869 | 0.899 | 0.015 | 0.951 | 0.946 | 0.012 | 0.723 | 0.795 | 0.065 | 0.795 | 0.835 | 0.071 |
| Paltform | LIMS | +Ours | +CRAFT | +GMFlow | +PWCNet | +SpyNET | +LFNet |
|---|---|---|---|---|---|---|---|
| GTX1080Ti | 23 f/s | 24 f/s | 22f/s | 23f/s | 23 f/s | 23 f/s | 22 f/s |
| Dataset | Davis [43] | Segtrack-v2 [44] | Visal [45] | DAVSOD [46] | VOS [47] | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metrics | maxF | S-M | MAE | maxF | S-M | MAE | maxF | S-M | MAE | maxF | S-M | MAE | maxF | S-M | MAE |
| QDFINet [48] | 0.912 | 0.918 | 0.018 | 0.834 | 0.883 | 0.015 | 0.952 | 0.946 | 0.012 | 0.705 | 0.773 | 0.069 | - | - | - |
| PAC [49] | 0.904 | 0.912 | 0.016 | 0.880 | 0.908 | 0.020 | 0.953 | 0.948 | 0.011 | 0.732 | 0.798 | 0.060 | 0.830 | 0.849 | 0.061 |
| DCFNet [50] | 0.900 | 0.914 | 0.016 | 0.839 | 0.883 | 0.015 | 0.953 | 0.952 | 0.010 | 0.791 | 0.846 | 0.060 | 0.660 | 0.741 | 0.074 |
| MQP [2] | 0.904 | 0.916 | 0.018 | 0.841 | 0.882 | 0.018 | 0.939 | 0.942 | 0.016 | 0.703 | 0.770 | 0.075 | 0.768 | 0.828 | 0.069 |
| TENet [35] | 0.881 | 0.905 | 0.017 | 0.810 | 0.868 | 0.025 | 0.949 | 0.949 | 0.012 | 0.697 | 0.779 | 0.070 | 0.781 | 0.845 | 0.052 |
| U2Net [51] | 0.839 | 0.876 | 0.027 | 0.775 | 0.843 | 0.042 | 0.958 | 0.952 | 0.011 | 0.620 | 0.728 | 0.103 | 0.748 | 0.815 | 0.076 |
| PCSA [52] | 0.880 | 0.902 | 0.022 | 0.810 | 0.865 | 0.025 | 0.940 | 0.946 | 0.017 | 0.655 | 0.741 | 0.086 | 0.747 | 0.827 | 0.065 |
| LSTI [53] | 0.850 | 0.876 | 0.034 | 0.858 | 0.870 | 0.025 | 0.905 | 0.916 | 0.033 | 0.585 | 0.695 | 0.106 | 0.649 | 0.695 | 0.115 |
| LIMS [26] | 0.911 | 0.922 | 0.016 | 0.899 | 0.921 | 0.013 | 0.953 | 0.947 | 0.011 | 0.725 | 0.792 | 0.064 | 0.822 | 0.844 | 0.060 |
| +Ours | 0.914 | 0.924 | 0.014 | 0.881 | 0.910 | 0.013 | 0.955 | 0.948 | 0.011 | 0.735 | 0.799 | 0.060 | 0.832 | 0.852 | 0.058 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Chen, C.; Li, L.; Peng, C. Video Saliency Object Detection with Motion Quality Compensation. Electronics 2023, 12, 1618. https://doi.org/10.3390/electronics12071618
Wang H, Chen C, Li L, Peng C. Video Saliency Object Detection with Motion Quality Compensation. Electronics. 2023; 12(7):1618. https://doi.org/10.3390/electronics12071618
Chicago/Turabian StyleWang, Hengsen, Chenglizhao Chen, Linfeng Li, and Chong Peng. 2023. "Video Saliency Object Detection with Motion Quality Compensation" Electronics 12, no. 7: 1618. https://doi.org/10.3390/electronics12071618