
Dynamic Load Balancing in Stream Processing Pipelines Containing Stream-Static Joins


Abstract
:1. Introduction
- the location of the join—whether it is performed on workers with static or streaming data;
- the imbalance detection method—whether by counting streaming items or summing the processing load;
- whether the solution dynamically adapts to detected imbalances or not.
- We propose a novel solution that dynamically balances the processing load, and reduces the network load in the stream-static join. Our solution operates in different modes, depending on the location where the join is performed, and the method used to detect imbalance.
- To evaluate the effectiveness of our approach, we performed an experimental evaluation to measure throughput and latency, comparing our solution against competing approaches. By analyzing the results, we identify the best-performing modes of our approach, and we provide insights into the benefits of our solution.
2. Related Work
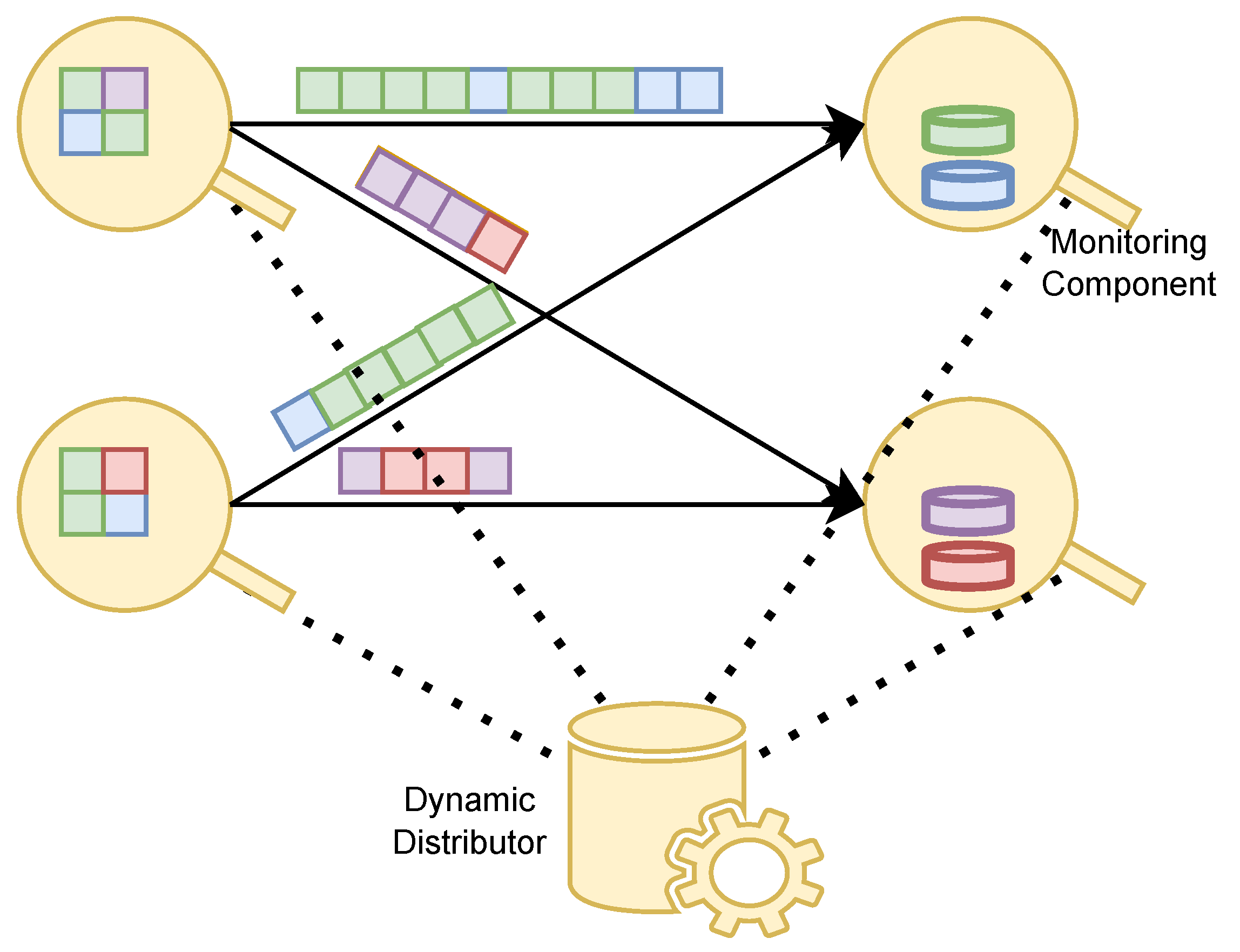
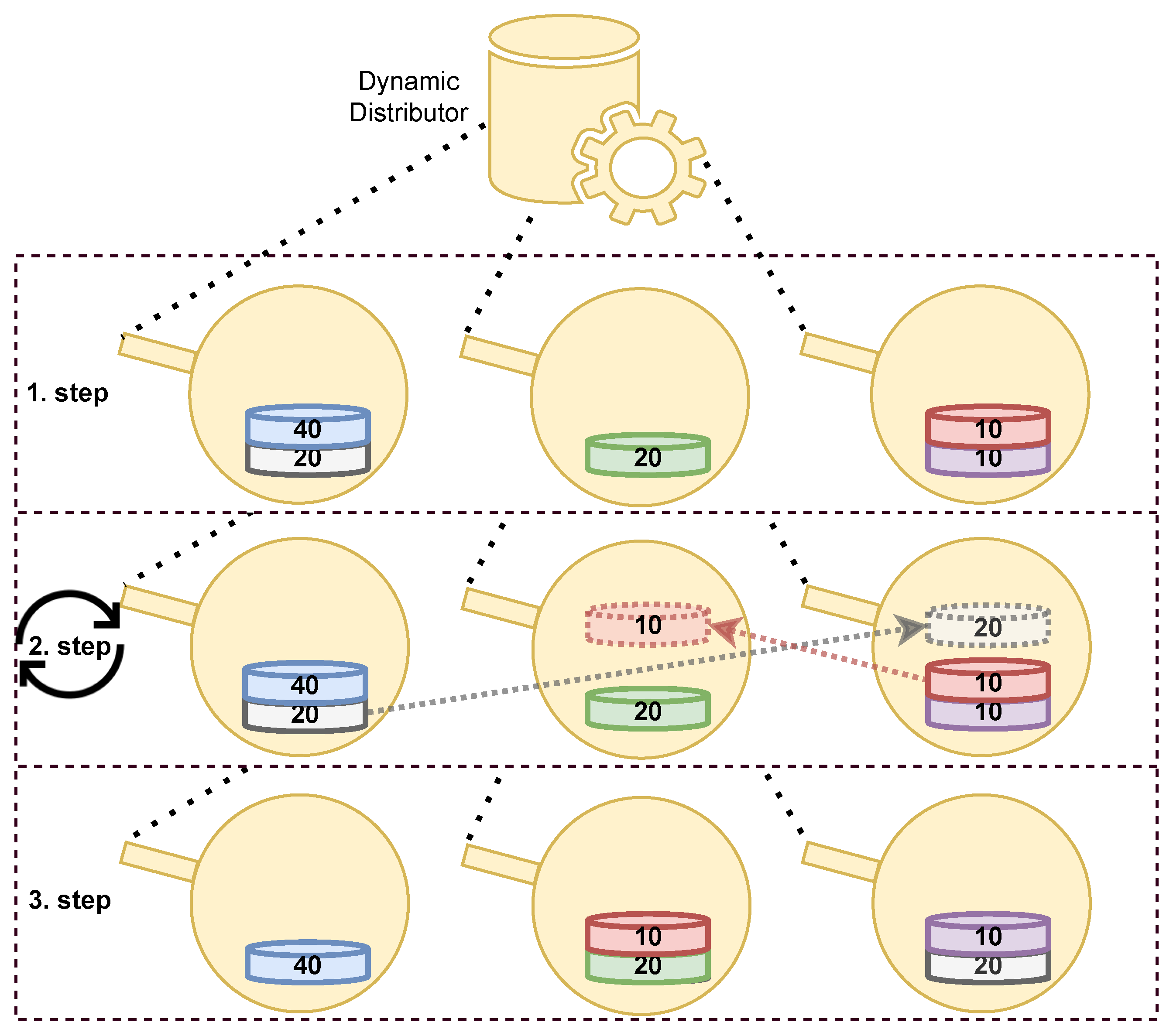
3. Dynamic Load Balancing
- monitoring load metrics in lines 2 and 3;
- load imbalance detection in lines 4 to 7;
- partition redistribution in line 8.
| Algorithm 1 Algorithm of Dynamic Distributor |
|
3.1. Monitoring Load Metrics
3.2. Load Imbalance Detection
- at least M items have been processed from the data stream;
- the redistribution has not been initiated during the last N periods of duration D;
- .
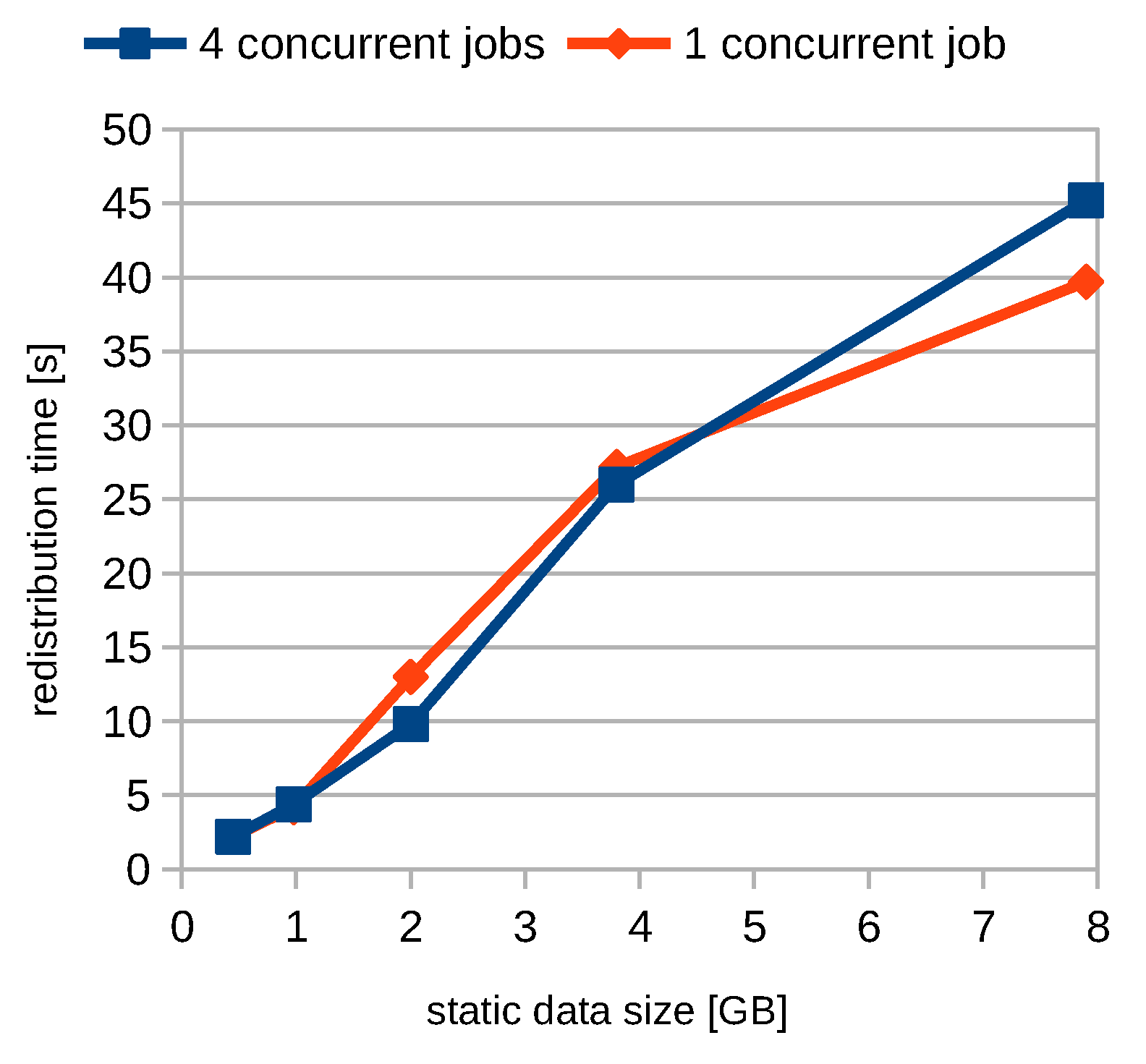
3.3. Partition Redistribution
4. Experimental Evaluation
4.1. Apache Spark
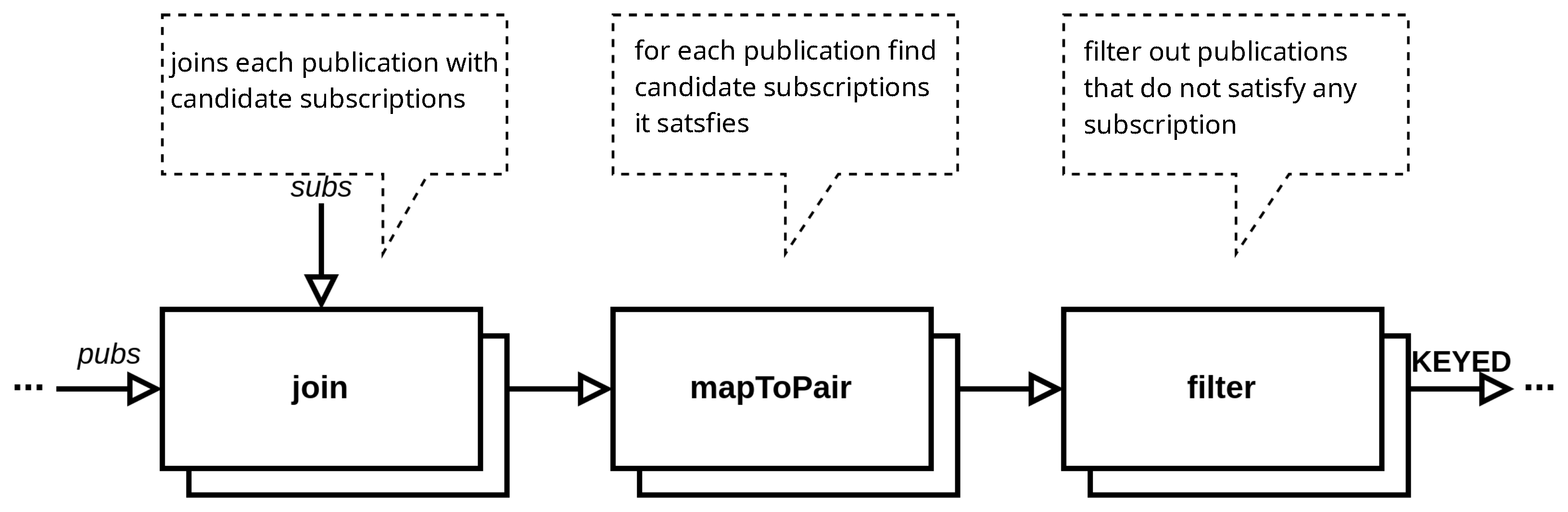
4.2. Evaluated Stream Processing Pipelines
4.3. Datasets
4.4. Experimental Setup
4.5. Evaluated Modes
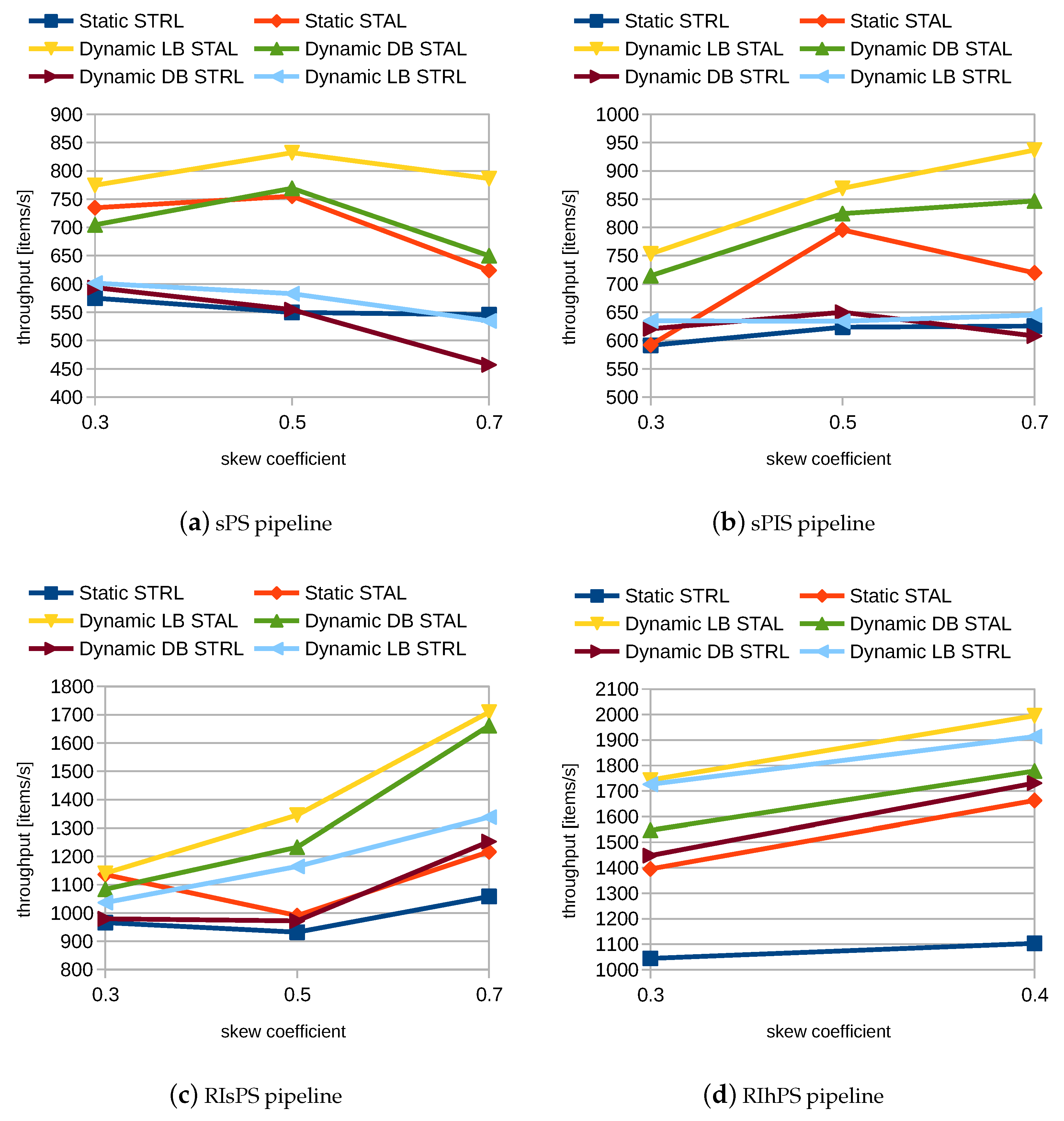
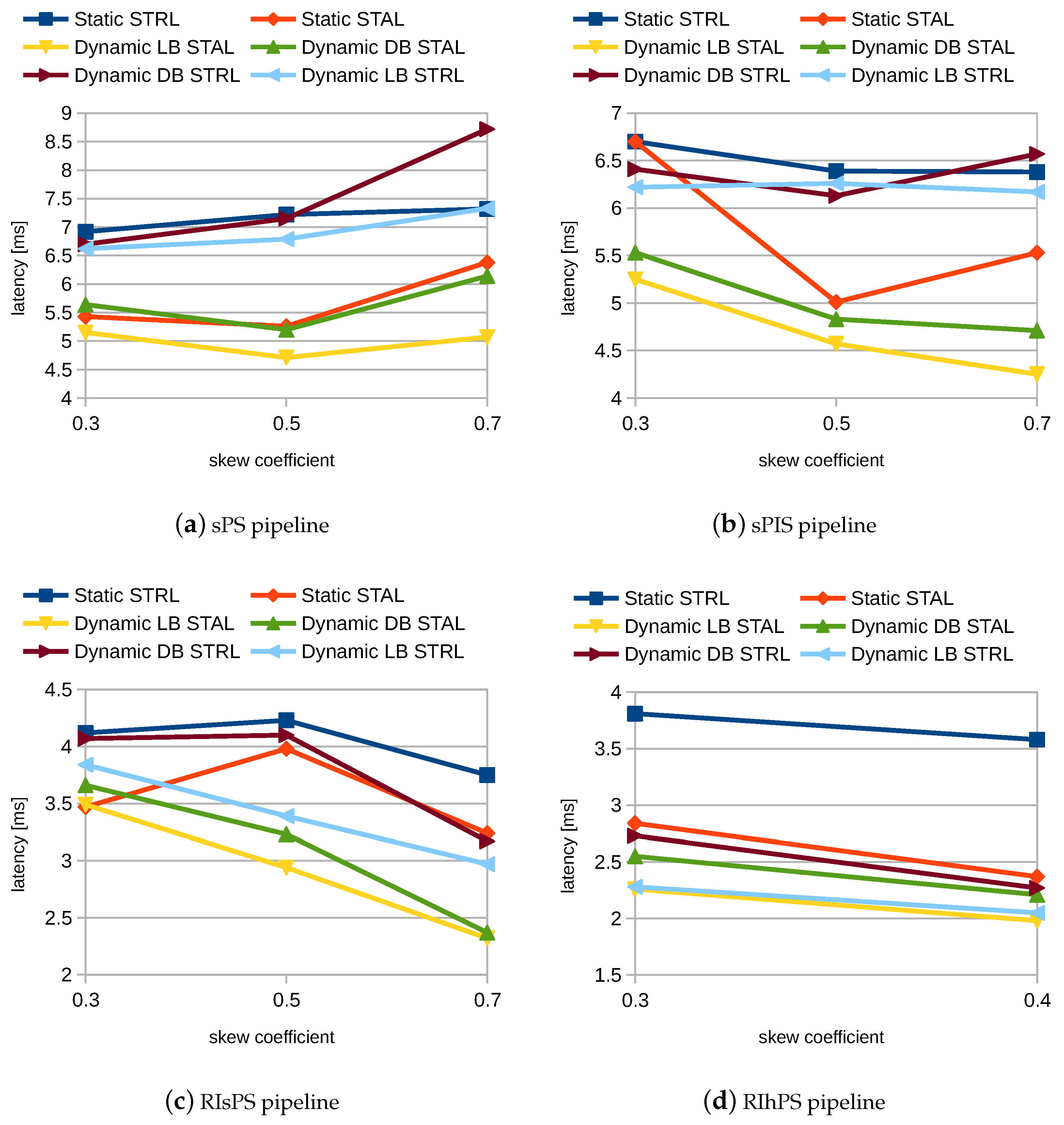
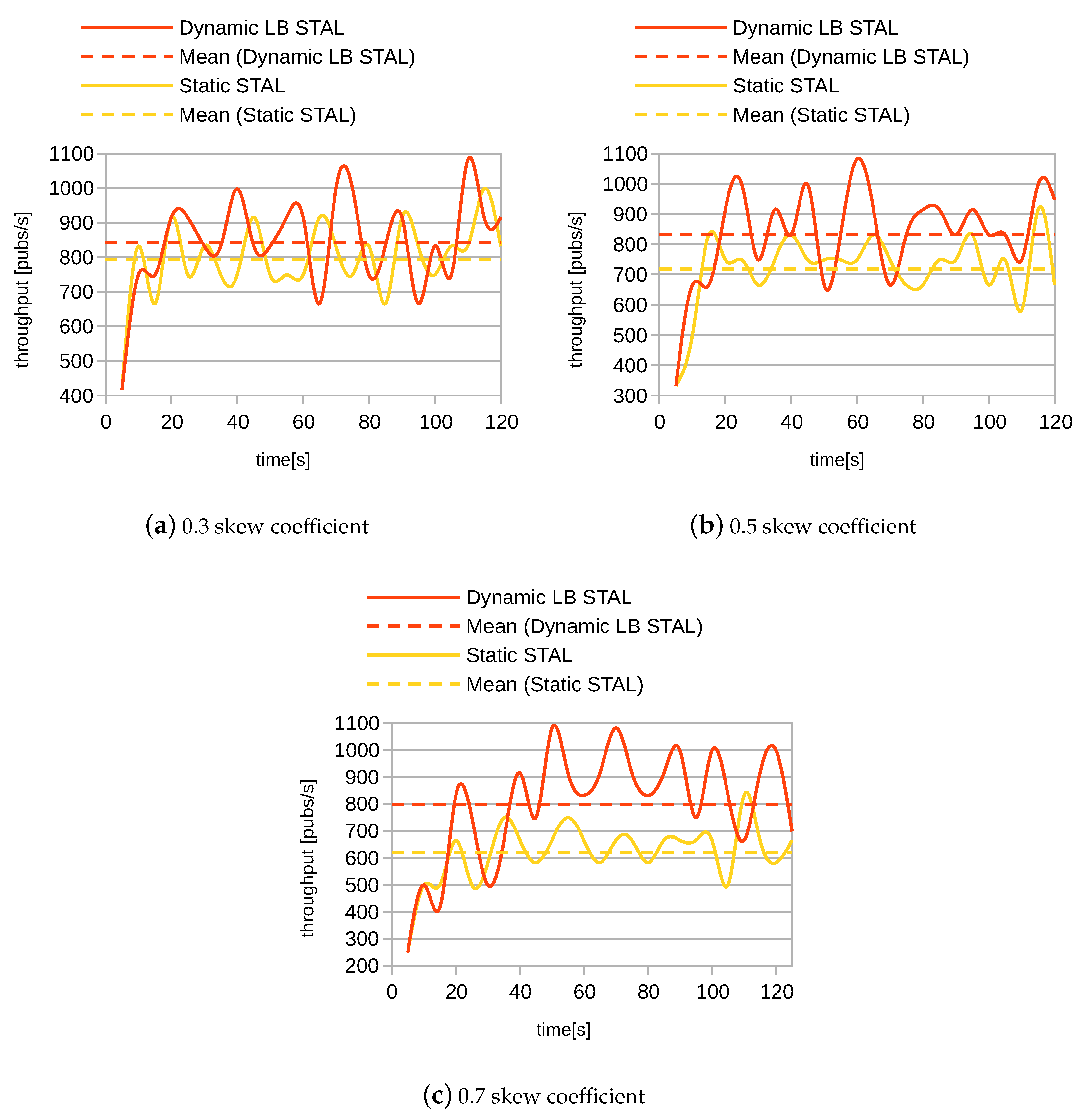
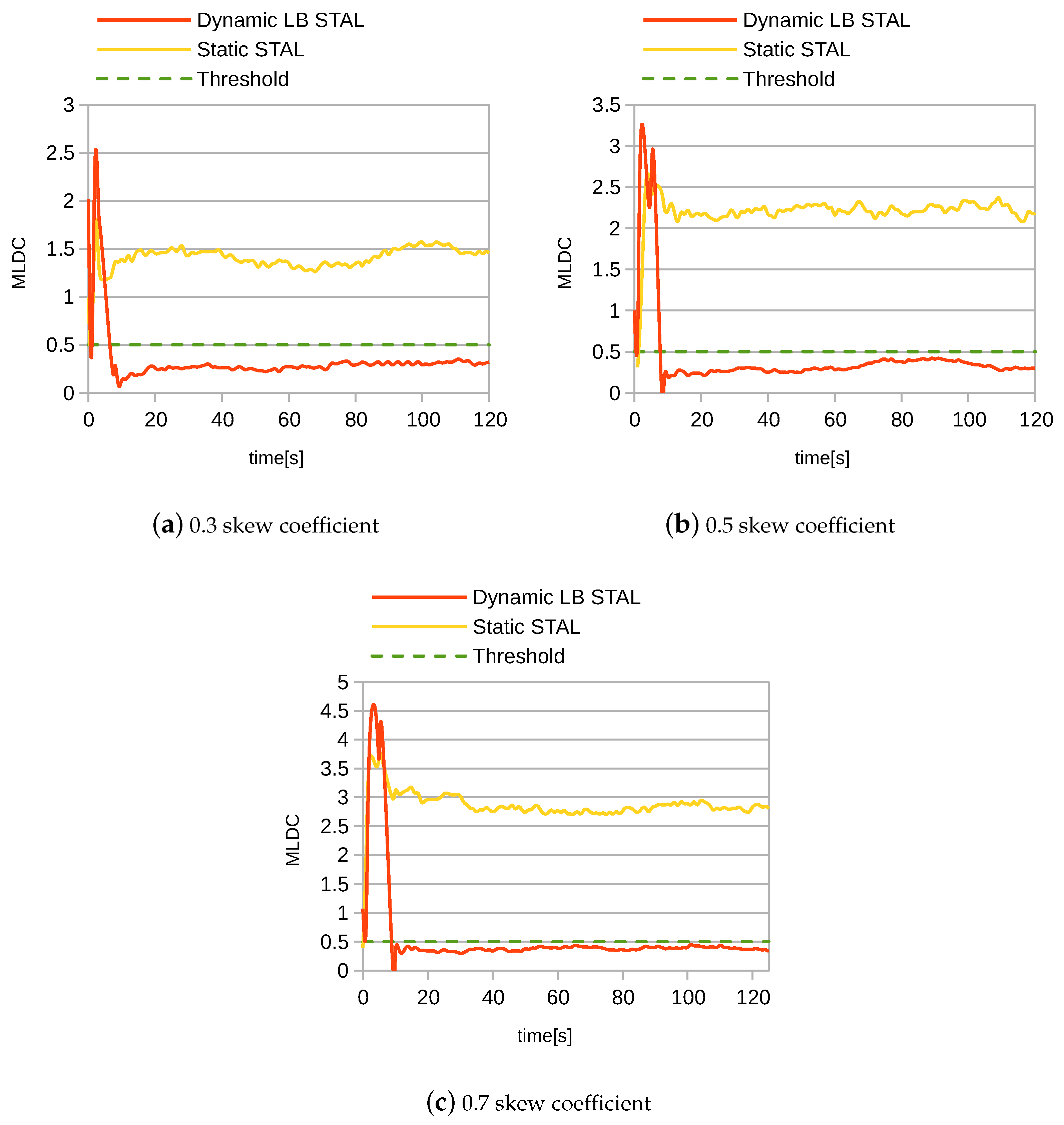
4.6. Experimental Results
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Golab, L.; Özsu, M.T. Issues in data stream management. ACM Sigmod Rec. 2003, 32, 5–14. [Google Scholar] [CrossRef]
- Carbone, P.; Katsifodimos, A.; Ewen, S.; Markl, V.; Haridi, S.; Tzoumas, K. Apache flink: Stream and batch processing in a single engine. Bull. IEEE Comput. Soc. Tech. Comm. Data Eng. 2015, 36, 28–38. [Google Scholar]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J.; et al. Apache spark: A unified engine for big data processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Iqbal, M.H.; Soomro, T.R. Big data analysis: Apache storm perspective. Int. J. Comput. Trends Technol. 2015, 19, 9–14. [Google Scholar] [CrossRef]
- Isah, H.; Abughofa, T.; Mahfuz, S.; Ajerla, D.; Zulkernine, F.; Khan, S. A Survey of Distributed Data Stream Processing Frameworks. IEEE Access 2019, 7, 154300–154316. [Google Scholar] [CrossRef]
- Livaja, I.; Pripužić, K.; Sovilj, S.; Vuković, M. A distributed geospatial publish/subscribe system on Apache Spark. Future Gener. Comput. Syst. 2022, 132, 282–298. [Google Scholar] [CrossRef]
- Irandoost, M.A.; Rahmani, A.M.; Setayeshi, S. MapReduce data skewness handling: A systematic literature review. Int. J. Parallel Program. 2019, 47, 907–950. [Google Scholar] [CrossRef]
- Ramakrishnan, S.R.; Swart, G.; Urmanov, A. Balancing reducer skew in MapReduce workloads using progressive sampling. In Proceedings of the Third ACM Symposium on Cloud Computing, San Jose, CA, USA, 14–17 October 2012; pp. 1–14. [Google Scholar]
- Chen, Q.; Yao, J.; Xiao, Z. Libra: Lightweight data skew mitigation in mapreduce. IEEE Trans. Parallel Distrib. Syst. 2014, 26, 2520–2533. [Google Scholar] [CrossRef]
- Dhawalia, P.; Kailasam, S.; Janakiram, D. Chisel++ handling partitioning skew in MapReduce framework using efficient range partitioning technique. In Proceedings of the Sixth International Workshop on Data Intensive Distributed Computing, Vancouver, BC, Canada, 23–27 June 2014; pp. 21–28. [Google Scholar]
- Gao, Y.; Zhang, Y.; Wang, H.; Li, J.; Gao, H. A distributed load balance algorithm of MapReduce for data quality detection. In Database Systems for Advanced Applications—DASFAA 2016 International Workshops: BDMS, BDQM, MoI, and SeCoP; Springer: Cham, Switzerland, 2016; pp. 294–306. [Google Scholar]
- Myung, J.; Shim, J.; Yeon, J.; Lee, S.G. Handling data skew in join algorithms using MapReduce. Expert Syst. Appl. 2016, 51, 286–299. [Google Scholar] [CrossRef]
- Liroz-Gistau, M.; Akbarinia, R.; Agrawal, D.; Valduriez, P. FP-Hadoop: Efficient processing of skewed MapReduce jobs. Inf. Syst. 2016, 60, 69–84. [Google Scholar] [CrossRef] [Green Version]
- Shah, M.A.; Hellerstein, J.M.; Chandrasekaran, S.; Franklin, M.J. Flux: An adaptive partitioning operator for continuous query systems. In Proceedings of the 19th International Conference on Data Engineering (Cat. No. 03CH37405), Bangalore, India, 5–8 March 2003; pp. 25–36. [Google Scholar]
- Zhao, X.; Zhang, J.; Qin, X. k NN-DP: Handling Data Skewness in kNN Joins Using MapReduce. IEEE Trans. Parallel Distrib. Syst. 2017, 29, 600–613. [Google Scholar] [CrossRef]
- Gavagsaz, E.; Rezaee, A.; Haj Seyyed Javadi, H. Load balancing in join algorithms for skewed data in MapReduce systems. J. Supercomput. 2019, 75, 228–254. [Google Scholar] [CrossRef]
- DeWitt, D.J.; Naughton, J.F.; Schneider, D.A.; Seshadri, S. Practical Skew Handling in Parallel Joins. In Proceedings of the 18th International Conference on Very Large Data Bases Madison, Vancouver, BC, Canada, 23–27 August 1992; pp. 27–44. [Google Scholar]
- Zhang, X.; Chen, H.; Hu, F. Back Propagation Grouping: Load Balancing at Global Scale When Sources Are Skewed. In Proceedings of the 2017 IEEE International Conference on Services Computing (SCC), Honolulu, HI, USA, 25–30 June 2017; pp. 426–433. [Google Scholar]
- Nasir, M.A.U.; Morales, G.D.F.; Garcia-Soriano, D.; Kourtellis, N.; Serafini, M. The power of both choices: Practical load balancing for distributed stream processing engines. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Republic of Korea, 13–17 April 2015; pp. 137–148. [Google Scholar]
- Lv, W.; Tang, Z.; Li, K.; Li, K. An Adaptive Partition Method for Handling Skew in Spark Applications. In Proceedings of the 2018 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Guangzhou, China, 8–12 October 2018; pp. 1063–1070. [Google Scholar]
- Cardellini, V.; Nardelli, M.; Luzi, D. Elastic stateful stream processing in storm. In Proceedings of the 2016 International Conference on High Performance Computing & Simulation (HPCS), Innsbruck, Austria, 18–22 July 2016; pp. 583–590. [Google Scholar]
- Tang, Z.; Zhang, X.; Li, K.; Li, K. An intermediate data placement algorithm for load balancing in spark computing environment. Future Gener. Comput. Syst. 2018, 78, 287–301. [Google Scholar] [CrossRef]
- Liu, G.; Zhu, X.; Wang, J.; Guo, D.; Bao, W.; Guo, H. SP-Partitioner: A novel partition method to handle intermediate data skew in spark streaming. Future Gener. Comput. Syst. 2018, 86, 1054–1063. [Google Scholar] [CrossRef]
- Chou, T.; Abraham, J. Load Balancing in Distributed Systems. IEEE Trans. Softw. Eng. 1982, SE-8, 401–412. [Google Scholar] [CrossRef]
- Jiang, Y.C.; Jiang, J. A multi-agent coordination model for the variation of underlying network topology. Expert Syst. Appl. 2005, 29, 372–382. [Google Scholar] [CrossRef]
- Jiang, Y. A survey of task allocation and load balancing in distributed systems. IEEE Trans. Parallel Distrib. Syst. 2015, 27, 585–599. [Google Scholar] [CrossRef]
- Khan, A.; Attique, M.; Kim, Y. iStore: Towards the optimization of federation file systems. IEEE Access 2019, 7, 65652–65666. [Google Scholar] [CrossRef]
- Madsen, K.G.S.; Zhou, Y.; Cao, J. Integrative dynamic reconfiguration in a parallel stream processing engine. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017; pp. 227–230. [Google Scholar]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster computing with working sets. HotCloud 2010, 10, 95. [Google Scholar]
- Vavilapalli, V.K.; Murthy, A.C.; Douglas, C.; Agarwal, S.; Konar, M.; Evans, R.; Graves, T.; Lowe, J.; Shah, H.; Seth, S.; et al. Apache Hadoop YARN: Yet another resource negotiator. In Proceedings of the SoCC: ACM Symposium on Cloud Computing, Santa Clara, CA, USA, 1–3 October 2013; pp. 1–16. [Google Scholar]
- UK Car Accidents 2005–2015. 2021. Available online: https://www.kaggle.com/silicon99/dft-accident-data/ (accessed on 25 February 2021).
- Pope, A. GB Postcode Area, Sector, District, [Dataset]. University of Edinburgh. 2017. Available online: https://doi.org/10.7488/ds/1947 (accessed on 20 February 2021).
- Kassab, A.; Liang, S.; Gao, Y. Real-time notification and improved situational awareness in fire emergencies using geospatial-based publish/subscribe. Int. J. Appl. Earth. Obs. Geoinf. 2010, 12, 431–438. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Parameter | Value |
|---|---|---|
| lower threshold of | ||
| M | number of processed items from the data stream | 1000 |
| N | number of periods to wait | 3 |
| D | period duration | 10 s |
| minimal improvement of |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marić, J.; Pripužić, K.; Antonić, M.; Škvorc, D. Dynamic Load Balancing in Stream Processing Pipelines Containing Stream-Static Joins. Electronics 2023, 12, 1613. https://doi.org/10.3390/electronics12071613
Marić J, Pripužić K, Antonić M, Škvorc D. Dynamic Load Balancing in Stream Processing Pipelines Containing Stream-Static Joins. Electronics. 2023; 12(7):1613. https://doi.org/10.3390/electronics12071613
Chicago/Turabian StyleMarić, Josip, Krešimir Pripužić, Martina Antonić, and Dejan Škvorc. 2023. "Dynamic Load Balancing in Stream Processing Pipelines Containing Stream-Static Joins" Electronics 12, no. 7: 1613. https://doi.org/10.3390/electronics12071613