1. Introduction
The detection of small objects has important implications for research and practical applications. There will be modest obstacles on the airport runway’s road pavement, such as cobblestones, screws, and nails. If these minute foreign objects on the runway can be precisely detected, major accidents can be avoided. In the field of automatic driving, it is vital that the vehicle’s vision sensor accurately detects small objects that could cause traffic accidents. In the field of industrial automation, tiny defects (such as burrs and fractures) visible on the surface of the material are detected using small object detection technology, thereby preventing larger financial losses. Finding microscopic lesions in medical image analysis is crucial for identifying early diseases and enhancing the effectiveness of therapy. In conclusion, small target detection technology has a multitude of application possibilities, application value, and significant implications for research across a wide spectrum of disciplines [
1,
2,
3,
4].
Due to the small proportion of small objects within image pixels and the absence of evident pixel characteristics, the detection of small objects remains a challenge in the field of object detection. First, the outline of small objects in the image is not distinct, making it challenging to train a neural network to differentiate between objects and backgrounds. Second, in the actual world, small objects, such as pedestrians, vehicles, birds, etc., are prone to congregate in the form of aggregations. Small objects of the same type are typically ignored by neural networks or confused with other objects, resulting in missed objects or erroneous alarms. In addition, large objects in the datasets are typically designated as positive samples, whereas the proportion of negative samples (small objects) is not particularly high. The sample imbalance can readily hinder the ability of one single threshold to differentiate between positive and negative samples, resulting in the loss of small objects [
4].
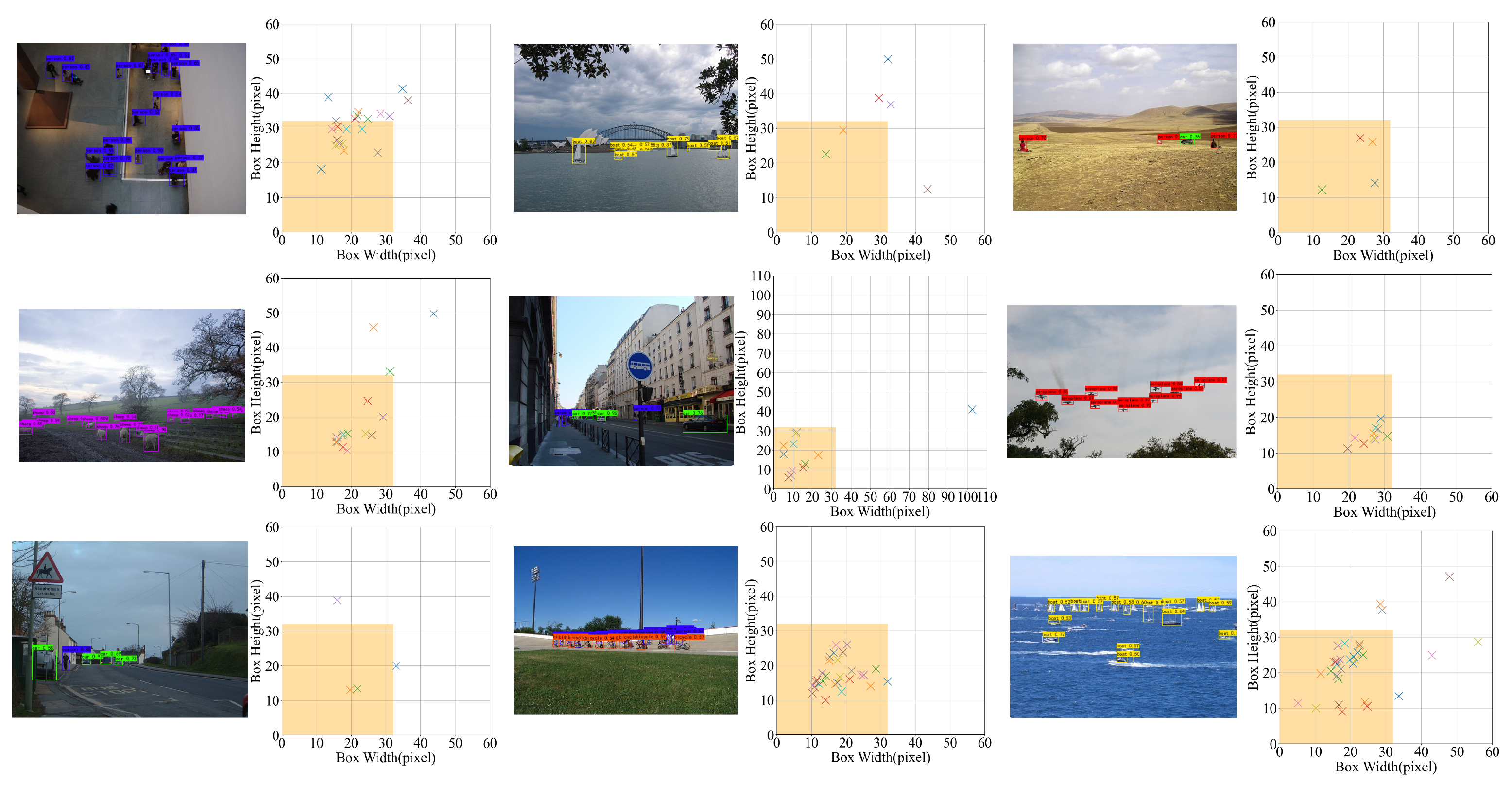
Since object detection is the starting point for more difficult tasks like semantic perception and object tracking, it is a major research area in the field of computer vision. In the field of computer vision, there are two types of definitions for minuscule objects based on the pixel size of the object in the image: relative scale and absolute scale definition. The relative scale specification for small objects is the ratio of pixels covered by the object to the total number of pixels in the image in the range of 0.08%∼0.58%. Objects with resolutions smaller than 32 × 32 from the Microsoft Common Objects in Context [
5] (MS-COCO) datasets are the most prevalent example of absolute scale. In this paper, the definition of absolute scale serves as the dividing line between minor objects.
Object detection algorithms based on deep learning typically consist of one or two stages. The primary difference between the two was whether or not the location of objects was inferred by a convolutional neural network branch operating alone. Region Convolutional Neural Network [
6] (R-CNN) and its improved algorithms [
7,
8] are exemplary of two-stage object detection techniques. This method generates a provisional prediction of the object location by first constructing a suggestion box for the object using a region proposal network. After modifying the boundary location of the region features derived by clipping the suggestion box, the object category is regressed. Common one-stage algorithms include You Only Look Once [
9,
10,
11] (YOLO) and its derivative series, as well as Single Shot MultiBox Detector [
12,
13] (SSD). The SSD employs the frame mechanism of Faster Region Convolutional Neural Network (FasterRCNN) as a reference among them in order to anticipate quickly and determine the object location with reasonable precision. After SSD incorporates a multi-scale feature layer for object detection, the subsequent YOLO derivative algorithm employs additional high-level properties of the backbone network to improve the detection capability of small objects.
We propose a one-stage algorithm for the detection of small objects based on YOLOv4. Through network structure and dataset augmentation, the proposed algorithm improves the precision and efficiency of small object detection. First, in terms of the algorithm network, we employ the MobileNetV3-Large [
14] as the backbone and the depthwise separable convolution and channel attention mechanisms to enhance the efficacy of feature extraction. Due to the shallow features’ smaller receptive fields, small objects can be detected more effectively. We have therefore increased the injection of shallow features in the scale fusion module and the depth of the feature layer. At the end part of the scale fusion module, a head for detecting small objects is also added. The spatial attention mechanism is used to increase the shallow network’s tendency to fixate on objects and to improve the efficiency of scale fusion. We use dilated convolution with hierarchical aggregation to improve the spatial structure information of the feature layer and eliminate the interference of background pixels on small objects.
In terms of datasets augmentation, in addition to introducing the Mixup [
15] and Mosaic [
11] methods, we also proposed the Consistent Mixed Cropping (CMC) method to improve the network’s ability to identify small objects and increase the diversity of small labels. In addition, we have counted the distribution of sample labels in PASCAL VOC [
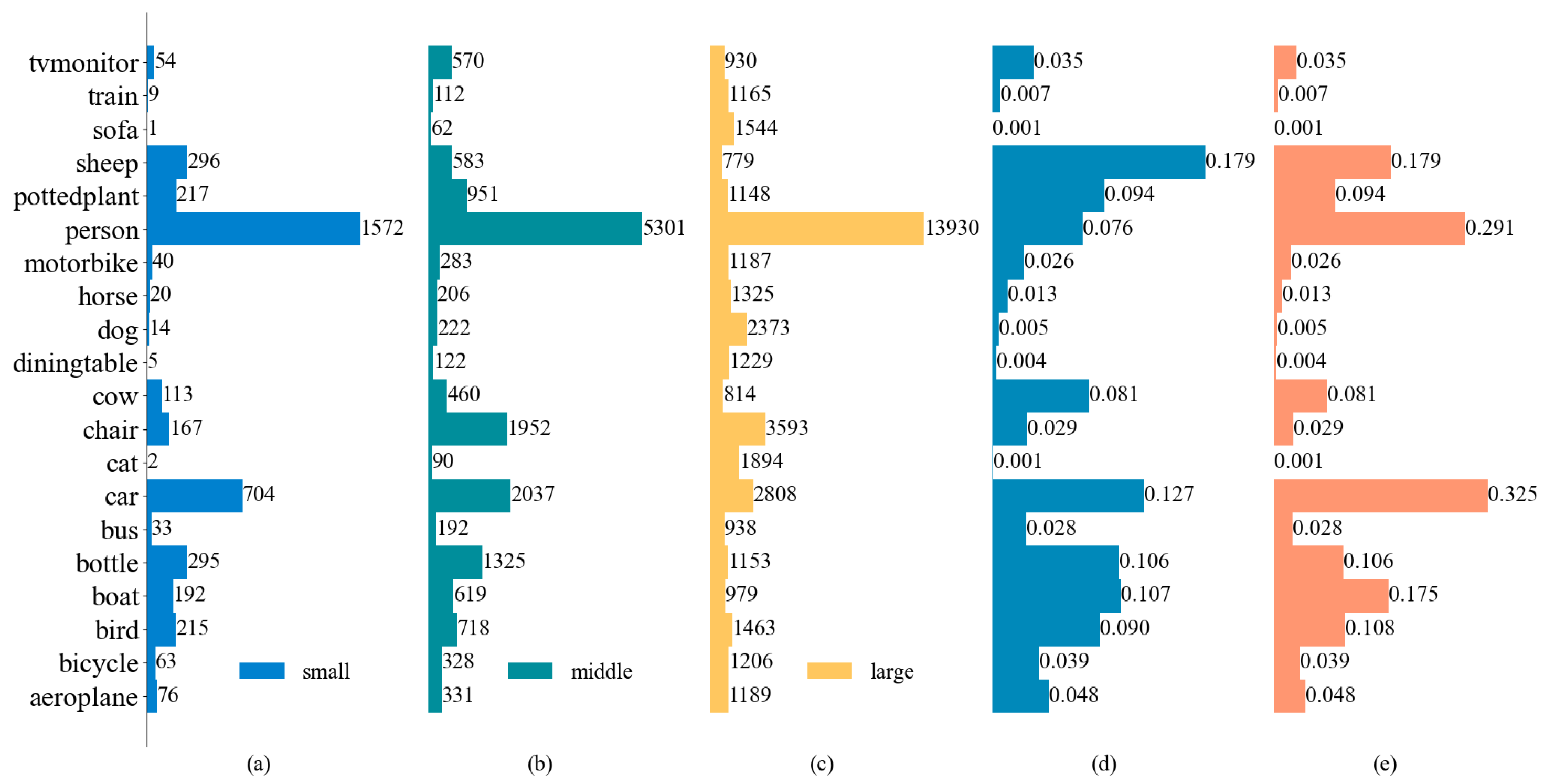
16] (PASCAL VOC represents Pattern Analysis, Statistical Modelling, and Computational Learning Visual Object Classes. Subsequently referred to as VOC) datasets and discover that the labels of a large object made up the majority in VOC datasets (small objects make up 3.5%). Large objectives are straightforward to identify as positive samples [
17]. In order to reduce the disparity between positive and negative samples, we added self-collected supplementary data to the training procedure to increase the number of small samples.
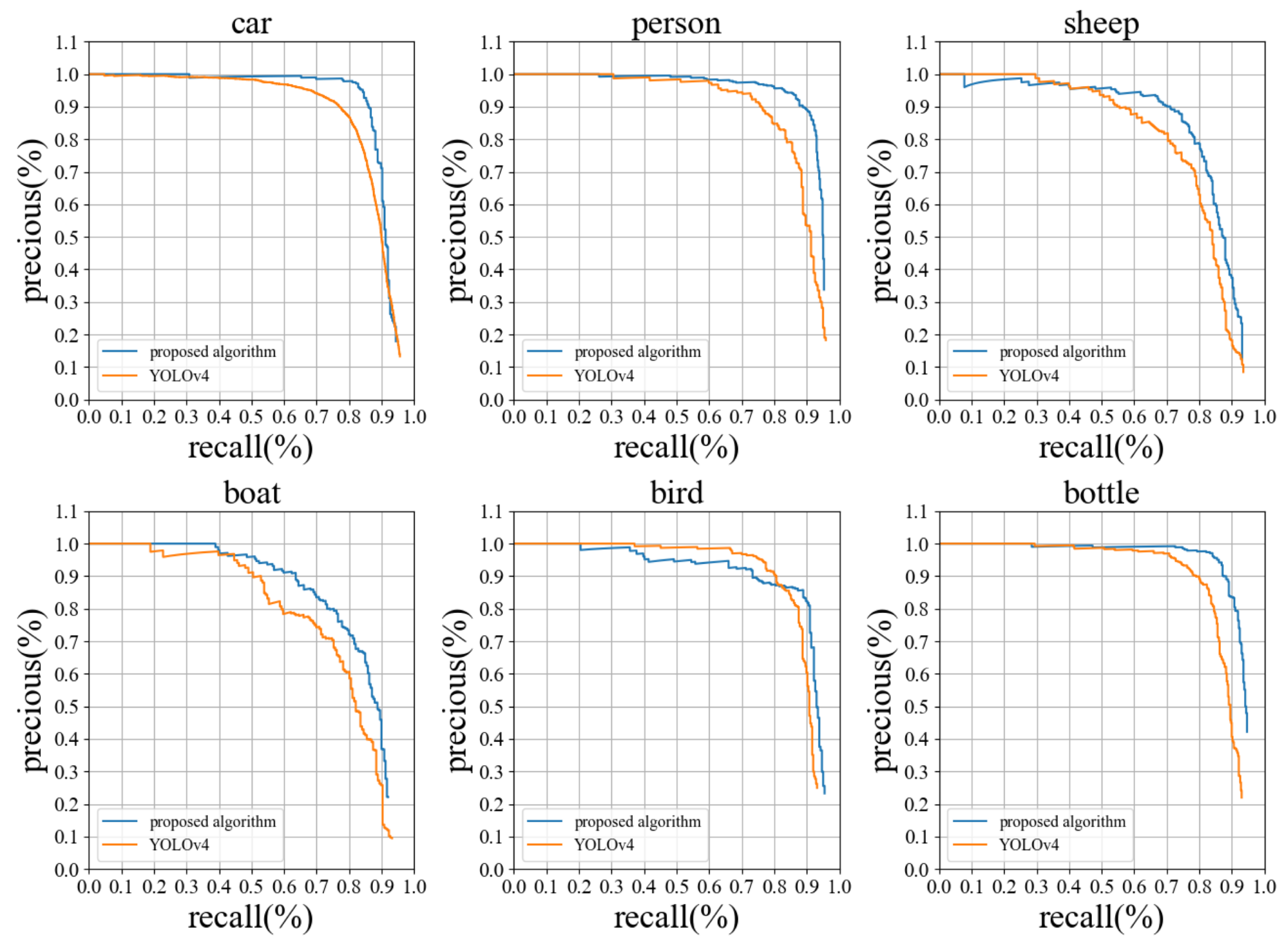
The proposed algorithm is trained on 64-Bit Extended (x86-64) platform and evaluated on embedded Advanced RISC Machine (ARM) platform. According to the test results, the Mean Average Precision (mAP) of the proposed algorithm is 4.6% greater than that of the original algorithm, YOLOv4. Among these, the Average Precision (AP) of the top six categories with small objects has been improved. Then, we administer inference tests using randomly selected test sets images. The visualization results reveal that the proposed algorithm is still capable of accurate recognition despite the difficulty of judging dense small object networks (the confidence level is close to 0.5). The algorithm has 76.4% fewer multiplier accumulators and 32.5% fewer network parameters than YOLOv4, respectively. It demonstrates that the proposed algorithm is less complex than the original algorithm. The convolutional neural network of proposed algorithms, YOLOv4 and YOLOv4-tiny, are then evaluated on the x86-64 and embedded ARM platform, respectively. The proposed algorithm’s average frame rate is comparable to YOLOv4-tiny.
The contributions in this paper are listed as follows:
By introducing an attention mechanism, enriching shallow scale features, and boosting context interaction, a novel lightweight small object detection algorithm based on a one-stage framework is proposed, which improves the accuracy and efficiency of small object detection;
We propose a new method for expanding the diversity of small samples in training data in order to increase the network’s ability to learn from small samples. Simultaneously, we utilize self-collected sample data to increase the number of small identifiers in the training data;
On the embedded ARM platform, the effectiveness of the proposed algorithm is evaluated on Neural Compute Stick (NCS2), and it can serve as a reference for future work.
3. Proposed Algorithm
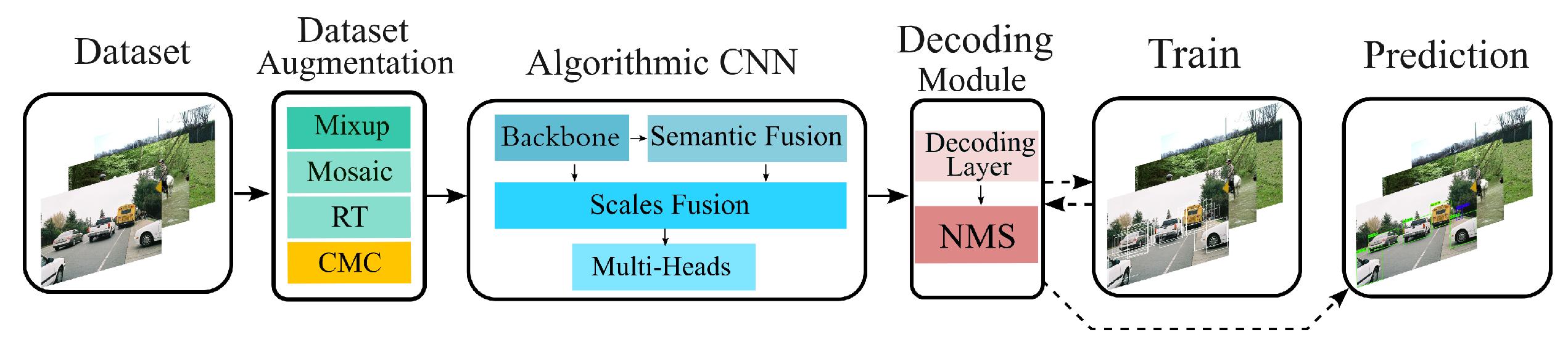
Figure 4 illustrates the division of our algorithm into the training and prediction operations. In order to increase the variety of samples in training datasets, we introduce a series of data augmentation methods (including Mixup [
15], Mosaic [
11], and Random Transformations (RT) of lighting and geometry) during the training phase. We also suggest a data augmentation method Consistent Mixed Cropping, which uses the prior knowledge of objects to strengthen the interaction between small sample labels and the background. In order to remedy the imbalance between positive and negative samples, which is detrimental to small object detection, we also increased the number of small labels in the sample image by self-collected samples.
The anchor mechanism and single-level object detection framework YOLOv4 are used as references by the algorithm network. Smaller receptive fields and higher resolution are correlated with shallow features in the deep learning network, which is advantageous for the detection of small objects. The shallow features also include a large number of parameter correlations, which makes the network model relatively complex and slows down inference. We make a trade-off between the proportion of shallow features and the speed of inference to resolve this issue. We take MobileNetV3-Large, a compact and effective backbone network. The decoding module’s task is to decode the characteristics produced by the algorithm network’s detection head and apply Non-Maximum Suppression (NMS) [
9,
10,
11] to the prediction frame. We include a header for recognizing small objects in the decoding module using the YOLOv4 approach as a model.
3.1. Overview of Algorithmic Convolutional Neural Network
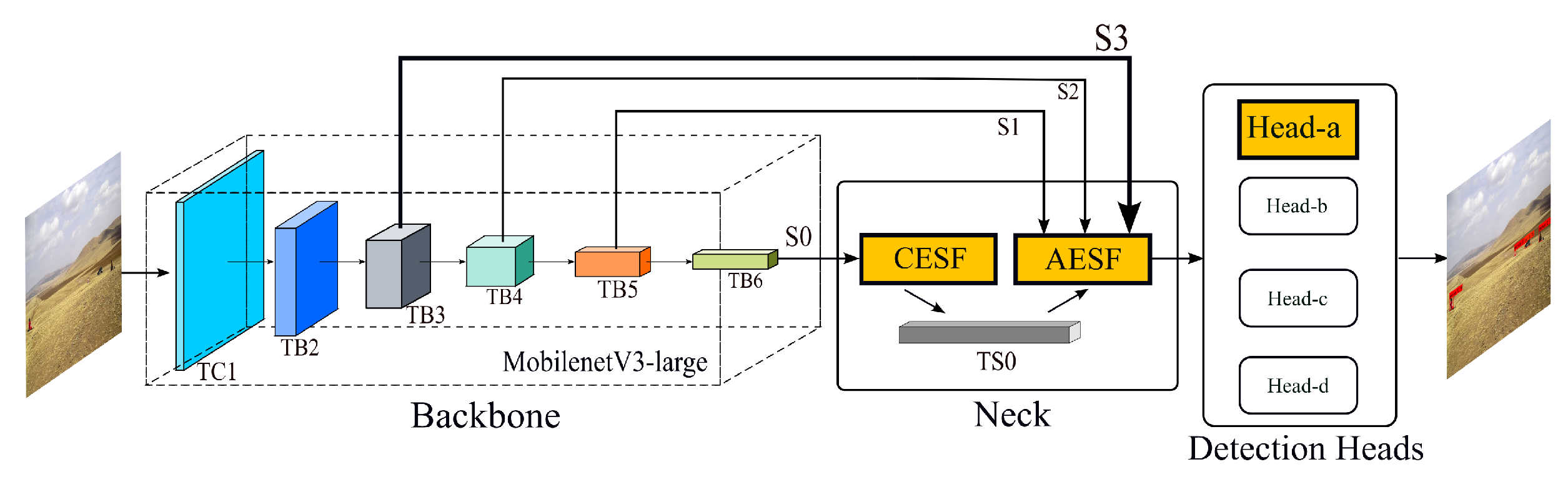
Based on the one-stage framework, the algorithmic convolutional neural network is shown in
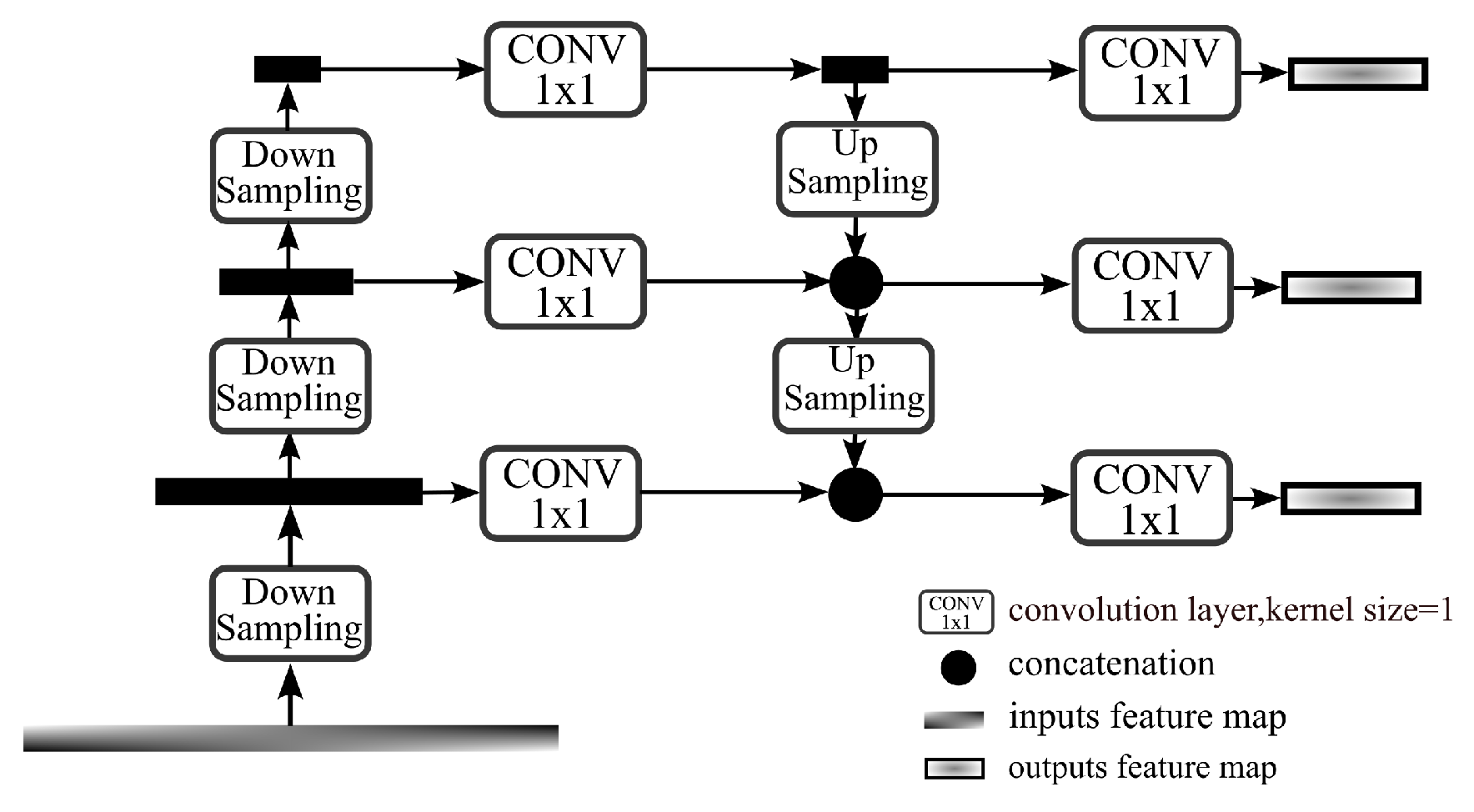
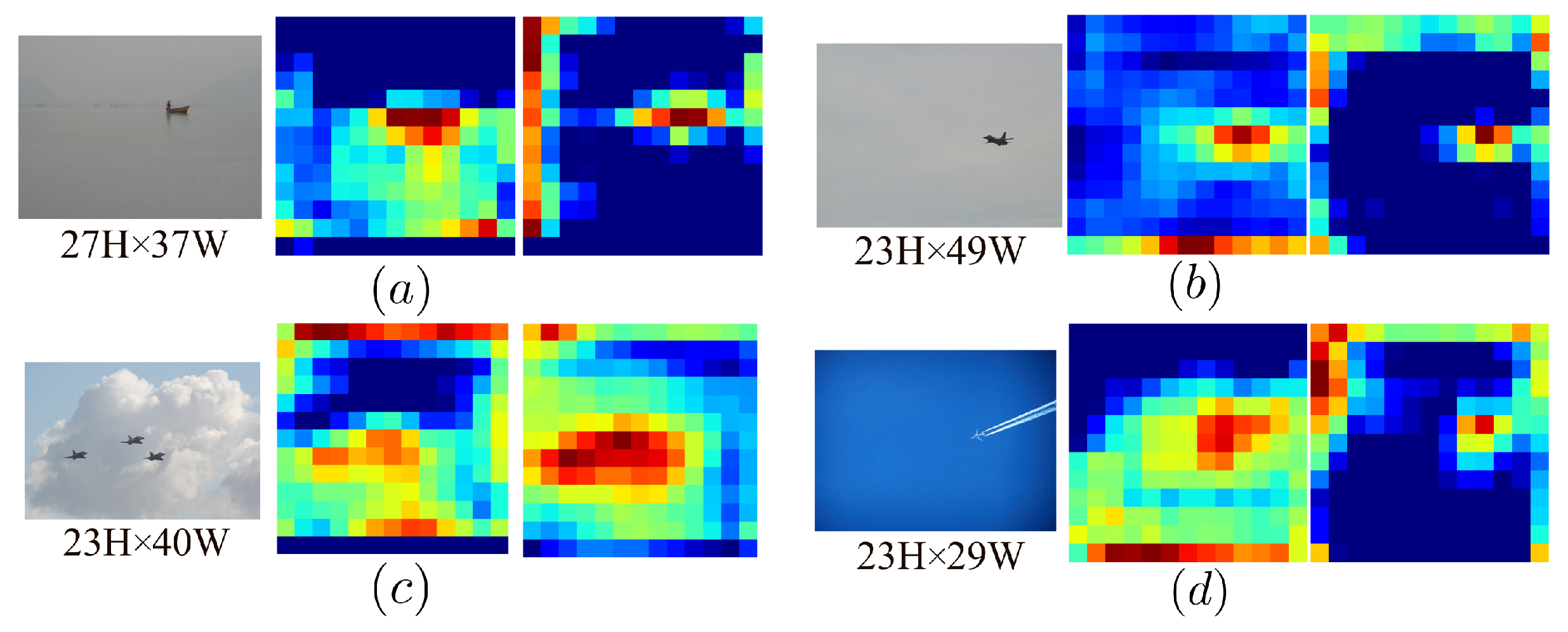
Figure 5. To enhance the capacity to detect small objects, we add a low-level feature injection in the scale fusion part to improve the expression of shallow features in the scale features. Additionally, a detection head made to look for small objects is also included. Context-Enhanced Semantic Fusion (CESF) module and Attention-Enhanced Scale Fusion (AESF) module are included in the neck portion. Blind coverage of small object features may come from pooling deep semantic features. We also believe that keeping a wider receiving field and more organized information about context features in the feature map is helpful for lowering the noise floor around weak objects. As a result, we use hierarchical aggregation instead of spatial pyramid pooling in the semantic context fusion section. In the scale fusion part, we apply the attention enhancement mechanism at the spatial and channel levels to the feature map of each scale. So that the network has the ability to adaptively adjust the weight for the small object response area and improve the recognition accuracy of small objects.
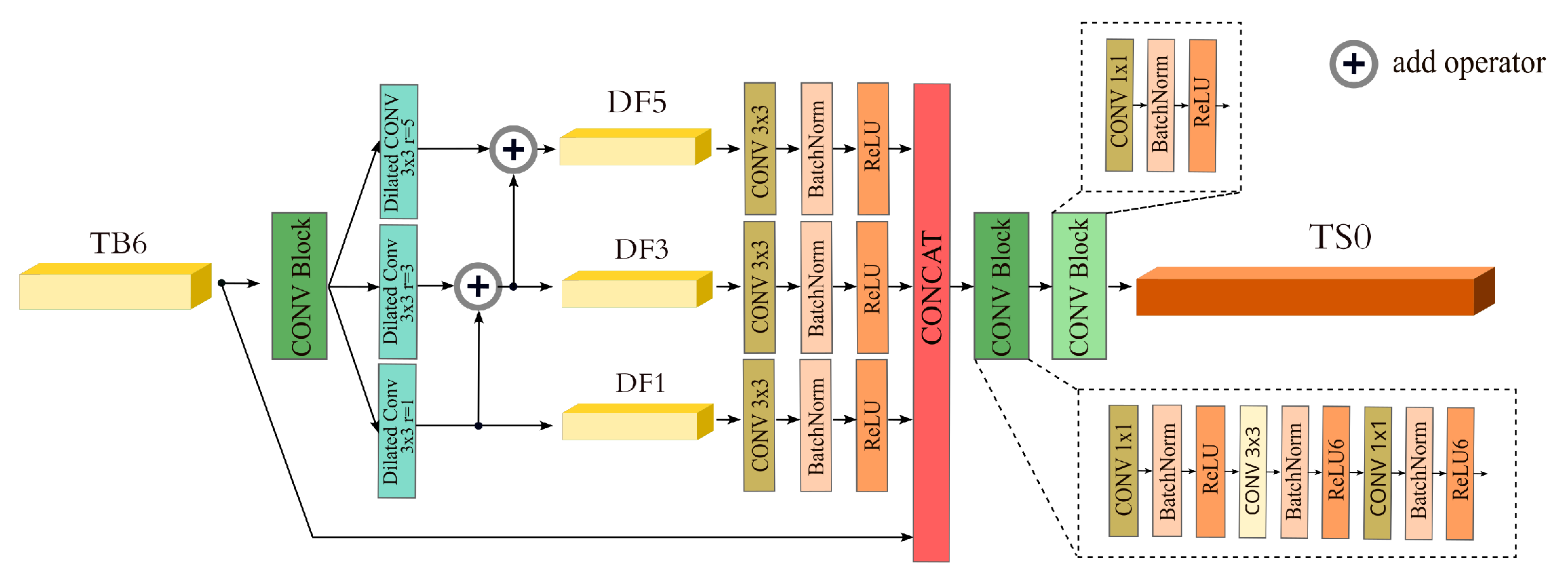
3.2. Efficient Context Enhanced Semantic Fusion
The SPP [
20] module in the YOLOv4 algorithm used a pooling layer to distill feature output, which might lead to the loss of fine-grained information, making semantic features unable to fully express small objects. In order to solve this, we design the context semantic fusion module Context Fusion Module (CFM) to replace the SPP network in the original network, using the concept from reference [
27]. In order to accomplish context semantic fusion, CFM employs dilated convolutions with various expansion rates. This method effectively mines spatial structure features by capturing more spatial location information about the input feature layer while expanding its receptive field. The improved network can better identify background pixels and improves the recognition ability of small objects.
The architecture of the CFM module is shown in
Figure 6. For the input
feature, the channel is adjusted by convolution blocks, and then the receptive field is expanded by three expansion convolutions with ratios of 1, 3, and 5. For the chessboard effect caused by dilated convolution, we use Hierarchical Feature Fusion (HFF) [
28] structure to suppress it by hierarchical fusion. The expansion volume is then integrated into features
,
, and
. The 3 × 3 convolution blocks are used to smooth the above features. The feature maps of three levels are stacked by tensor splicing for fusion, and two convolution blocks are used for feature concentration and channel adjustment to finally obtain the semantic fusion feature
.
3.3. Attention Enhanced Spatial Scales Fusion
The convolutional neural network contains less semantic information than the shallow feature map, but the object location was still very accurate. The minute object features progressively became unnoticeable despite the deep feature map’s semantic information being relatively dense. Shallow features were commonly used for small object recognition, which makes it necessary to incorporate the semantic information of deep features.
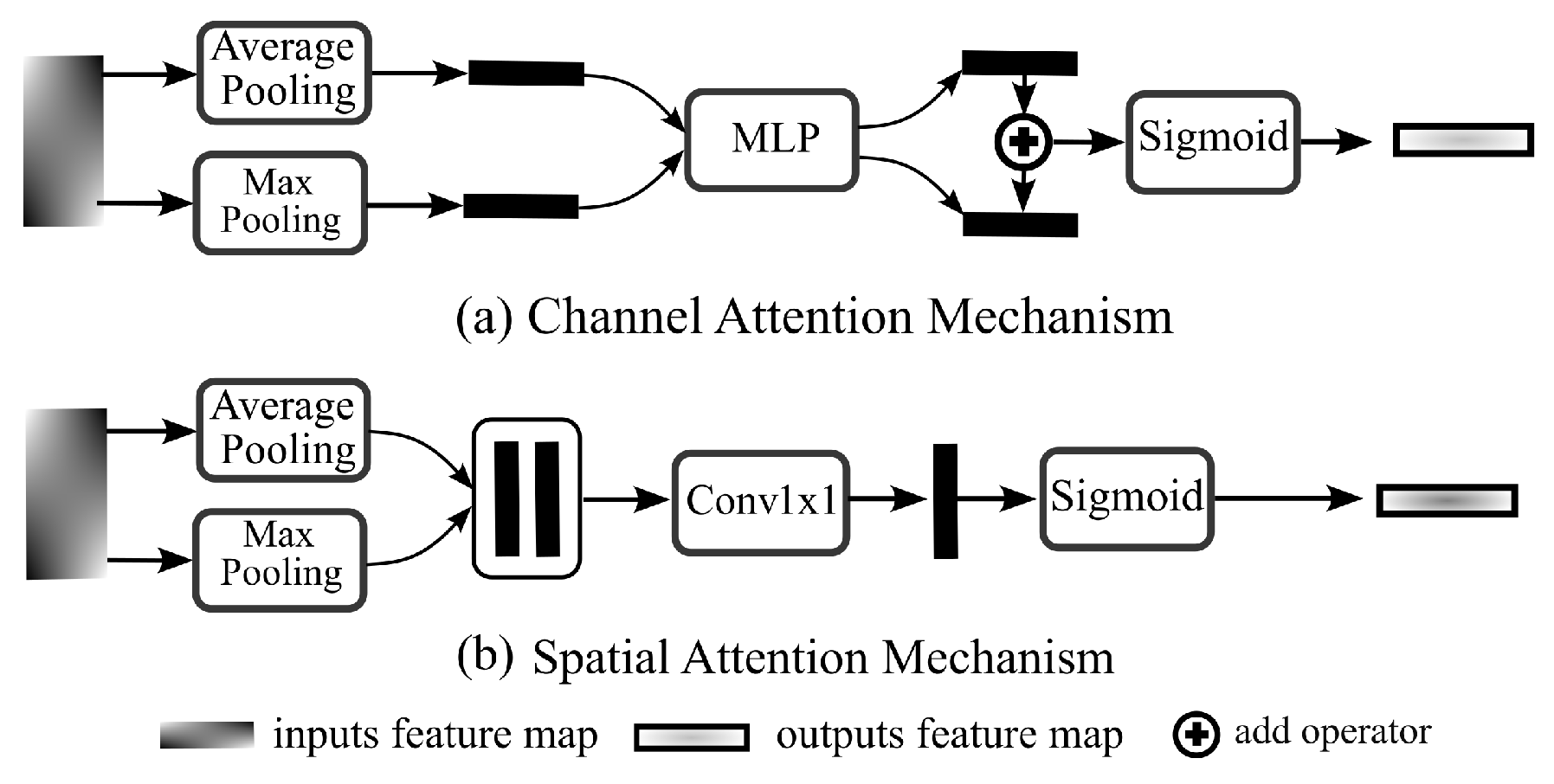
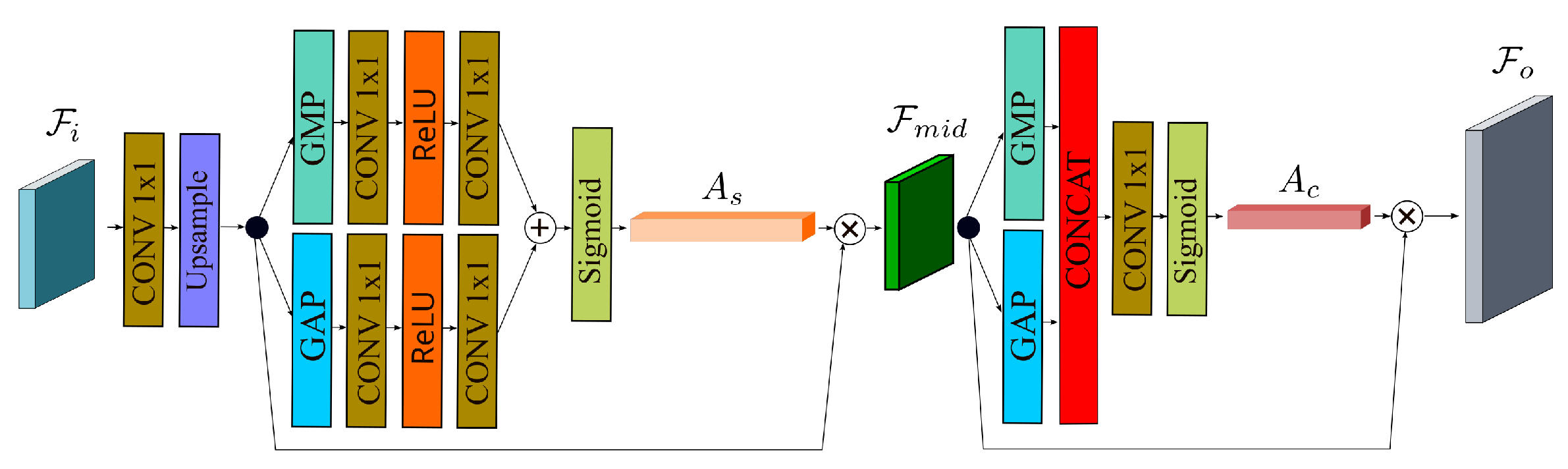
In order to boost semantic feature fusion’s effectiveness, we apply the spatial and channel attention method [
22] to the scale feature layer, on the basis of a multi-path aggregation network, to enhance the recognition capability of small objects. We specifically deepen the hierarchical structure of scale features by injecting a shallower feature map into the spatial scale fusion module. The effectiveness of the merging of shallow feature maps and high-level semantic maps is simultaneously improved by the employment of the attention mechanism. We proposed the Spatial Scale Attention Module (S2AM) to improve the emphasis on shallow features and the capacity to recognize small objects by adaptively adjusting the weight of space and channels in the process of scale fusion.
Figure 7 displays the entire spatial scale fusion module organization.
The archiecture of Spatial Scale Attention Module is shown in
Figure 8. The adaptive guiding features are aggregated in key directions by the scale attention module in the spatial scale fusion module, which cascades through the attention modules at the two levels of space and channel. The global maximum pooling and the global average pooling are executed, respectively, for the input feature
. Two × 1 convolutions are used to tweak the resulting feature layer before sigmoid activation is used to create the channel attention tensor. By aggregating with the feature layer
, the output feature layer
is created. The two output features are then tensor layered after
is pooled globally to large and globally to average along the spatial direction of each layer of channels. The spatial attention tensor is obtained after the stacking features have been modified and turned on by the channel, and the output feature
is obtained following the aggregation with
. In order to increase the effectiveness of fusion with underlying semantic features, SAM modules have enhanced the features of each scale with spatial attention and channel attention. After attention improvement, the feature picture is sampled using bilinear interpolation and then combined with the top feature.
3.4. Data Augmentation
We introduce some effective data augmentation methods, such as Mixup [
15], Mosaic [
11], and random transformation, to increase the input datasets in order to increase the learning effectiveness of the network. In order to improve training performance, the network has to learn more features connected to samples.
Figure 9 displays the sample case after data augmentation. The amplified samples with category labels created after stacking the first four samples using the Mixup method are shown in the figure’s first column. The mixed image created by utilizing the Mosaic augmentation approach is displayed in the second column. The sample produced after the affine transformation, illumination transformation, and scaling operation is represented by the third column. A popular data augmentation technique in deep learning networks is Mixup. By proportionally combining two pairs of sample data from the same category, it creates new samples. Another quick and efficient form of data augmentation is Mosaic. To splice and synthesize a new sample, it employs four genuine frames from different samples. Following normalization, it is the same as learning four samples simultaneously while enhancing the variety of the sample backdrop. To increase the diversity of the input samples, lighting, and geometric alteration are also applied.
We also suggest the Consistent Mixed Cropping (CMC) method (
Figure 9c) to increase the effectiveness of learning minor goals. Consistent Mixed Cropping is inspired by Mixup. But instead of haphazardly chopping and splicing samples, we attach the object to its matching background in accordance with the object’s meaning. To enhance the shape of small objects, we scale and geometrically transform the object once more. We believe that using the incorrect hybrid splicing technique could cause misunderstanding in online learning. For instance, finding small objects at sea has a much higher likelihood than detecting a ship or a bird. These prior details will lower the likelihood of network inference errors.
5. Deployment Test and Discussion
In order to increase the precision and effectiveness of small object recognition, we propose an attention-enhanced lightweight small object detection algorithm based on the single-stage framework. In the training experiment section, the accuracy of the trained model’s recognition of tiny objects is primarily evaluated. In light of the model’s accuracy test results, the ablation experiment, and the visual small object prediction results, it is evident that the proposed algorithm can enhance the accuracy of small object recognition.
In this section, we deploy the model on the x86-64 platform to evaluate the inference efficiency of the proposed algorithm. As an extension test, we also deploy the model on embedded ARM platform to evaluate the inference efficiency of the proposed algorithm.
5.1. Deployment Environment
The x86-64 platform hardware environment used in the deployment test is the laptop with Intel I7-8750H Central Processing Unit (CPU) and Nvidia Rtx1050Ti Graphics Processing Unit (GPU). The embedded ARM platform(as shown in
Figure 15) employs Raspberry4B which has a 4-cores Cortex-A72 processor and the second generation of Neural Network Stick (NCS2). The NCS2 is an artificial intelligence device that features a high-performance, low-power AI processor. It is specifically designed for deep learning inference and can be used to run neural networks on edge devices such as drones, smartphones, and other compute nodes. The device is capable of running advanced models quickly and efficiently, making it suitable for applications such as image classification, object detection, face recognition, and more. Additionally, it provides an API for easy integration with existing software solutions. We utilize OpenVINO [
35] framework to create a deployment environment for embedded platform that serves as a model. Simultaneously, the proposed algorithm model is quantized and compressed in accordance with NCS2 usage requirements. To facilitate comparative testing, we select YOLOv4 and its lightweight model YOLOv4-tiny as references. All of the reference models are from the Intel Open Model Zoo depository [
35].
5.2. Inference Efficiency
In the deployment tests, we gather a total of 50 sample images containing moderately sized objects from the test sets in order to determine the time required for network inference. According to the results in x86-64 platform in
Table 4, we find that the average inference time of the proposed algorithm network is 51.8% less than the original framework YOLOv4 and 12.3% more than YOLOv4-tiny. Using the Torchstat utility of Pytorch, we then analyzed the computational complexity of algorithms and the quantity of the model parameters. We find that the number of Multiply–Accumulate Operations (MAdds) in the proposed algorithm’s model is 87.9% less than that of YOLOv4 and similar to YOLOv4-tiny (5.8% higher than YOLOv4-tiny). The proposed algorithm model has 76% fewer parameters than YOLOv4 and 1.6 times as many as YOLOv4-tiny. The proposed algorithm model has an average single frame inference time of 29.2 ms, which is 51.8% less than YOLOv4 and 12.3% more than YOLOv4-tiny. The comparison between computational complexity and average frame rate demonstrates that the proposed algorithm has superior inference efficiency.
In order to evaluate the inference efficacy of the model on the embedded ARM platform, we quantified and compressed the model of the proposed algorithm into FP16 format according to the hardware requirements of NCS2. In addition, the inference efficacy of the model on the GPU and CPU hardware has also been tested using the OpenVINO framework as a point of comparison. The test results are shown in
Table 5.
Comparing the FPS data in
Table 4 and
Table 5, the quantized algorithm model inference using VPU on the embedded ARM platform is 80.9% lower than that of using CPU on the x86-64 platform. By contrasting the FPS results of the standard YOLOv4 and YOLOv4-tiny models, we find a similar result. The FPS of the YOLOv4 and YOLOv4-tiny models decreased by 96.9% and 85.4%, respectively, under the same comparison conditions. The inference performance of the proposed algorithm model using the OpenVINO framework is inferior to that of the Pytorch framework, and the model acceleration effect of NCS2 is insignificant. Subsequently, we meticulously analyzed the time consumption of each component of Latency. Based on the qualitative analysis of the Latency results in
Table 5, we discover that the three models in the comparative test consumed the most time during forward propagation of the network under various hardware environments. In three hardware environments, the inference time of the proposed algorithm is comparable to the YOLOv4-tiny model provided by the Open Model Zoo of Intel. The inference time of the proposed algorithm model and lightweight model utilizing VPU for inference on the ARM platform is 91.7% and 91.2% less than that of YOLOv4, respectively.
Based on previous analysis and test data in
Table 5, we discovered that, for the same model in the OpenVINO framework, the inference performance of NCS2 is typically slower than that of CPU and GPU. The inference acceleration impact of VPU on neural network models is not immediately apparent. We investigate the possibility that FP16-formatted model data of NCS2 is irreconcilable with the 64-bit instruction set in the embedded ARM environment. Next, we will attempt to replace the 32-bit instruction set and investigate the effect of multiple NCS2s accelerating simultaneously. Additionally, the lightweight model provides more performance benefits on embedded ARM platform. The visualization of the embedded ARM deployment experiments are as shown in
Figure 16.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}