4.1. Datasets
In this study, we used two public datasets, including CBIS-DDSM and INbreast [
16,
30]. CBIS-DDSM, which is a carefully curated subset of the DDSM dataset, contains breast mass and breast calcification mammograms. Regarding these two categories, there are two sets of beforehand partitioned datasets with pixel-level annotated labels. Our focus is the subset of mass mammograms. However, we found some mammograms are not well annotated as the sizes between mammograms and the labels are different. So, we manually excluded those mammograms and labels, both in the training set and the testing set.
After the patch extraction procedure, we then obtained mass patches (or positive patches) and breast tissue patches (called negative patches). However, the number of negative samples greatly outnumbered that of positive samples. To form a balanced training set for patch classification, we augmented the positive samples by eight times and randomly selected the same number of patches from the negative samples. The eight augmentation methods included flipping, rotation, contrast enhancement, etc. The details of the formed patch dataset are shown in
Table 1. After the patch extraction module, there are, in total, 20,747 patches and 1911 of them are positive samples, while the remaining are negative samples.
For the INbreast dataset, we used it for the overall performance evaluation of the proposed framework, and, therefore, no patches are extracted. While the INbreast dataset has 410 images in total, there are only 107 images containing masses, so we evaluated our framework on these 107 images instead.
4.2. Classification Results by Deep-Learning Models
In this study, we use
TP for True Positive,
TN for True Negative,
FP for False Positive (
FP), and
FN for False Negative (
FN). To quantify the performance of the deep-learning model for patch classification, we used various criteria including Area under the Curve (AUC) of the receiver operating characteristic curve, sensitivity, specificity, precision,
, and accuracy. AUC is another important evaluation metric to measure the overall performance of the classification model. Sensitivity can be expressed by
TP and
FN as
Similarly, specificity can be denoted by
TN and
FP as
Precision,
, and accuracy can then be written as
In this research, we explored multiple state-of-the-art deep-learning models for the binary classification task. The models are VGG19, ResNet50, ResNet101, InceptioinV3, DenseNet201, and InceptionResnetv2. For a better understanding of these models, we listed the details of the deep models from three perspectives, including the number of the training parameters, the number of layers in total, and the number of connections between the layers, as can be seen in
Table 2.
We deployed the SPECTRE High-Performance Computing Facility at the University of Leicester for training as we were allowed access to a single GPU Tesla P100 PCI-E with a memory of 16 GB. The deep-learning framework is the deep-learning toolbox provided by Mathworks in Matlab 2019b. The parameters for training are shown in
Table 3, where SGDM stands for Stochastic Gradient Descent with Momentum. The maximum training epoch is 9 in order to alleviate the overfitting problem. The initial learning rate is
, which is the conventional setting. The minibatch size is 64, due to the size of the datasets used in this paper. The learning rate drop period and learning rate drop rate are 3 and 0.3, which are set via experience. The optimization method is SGDM, which is a common choice. The shuffle of the train set is each epoch to improve the performance.
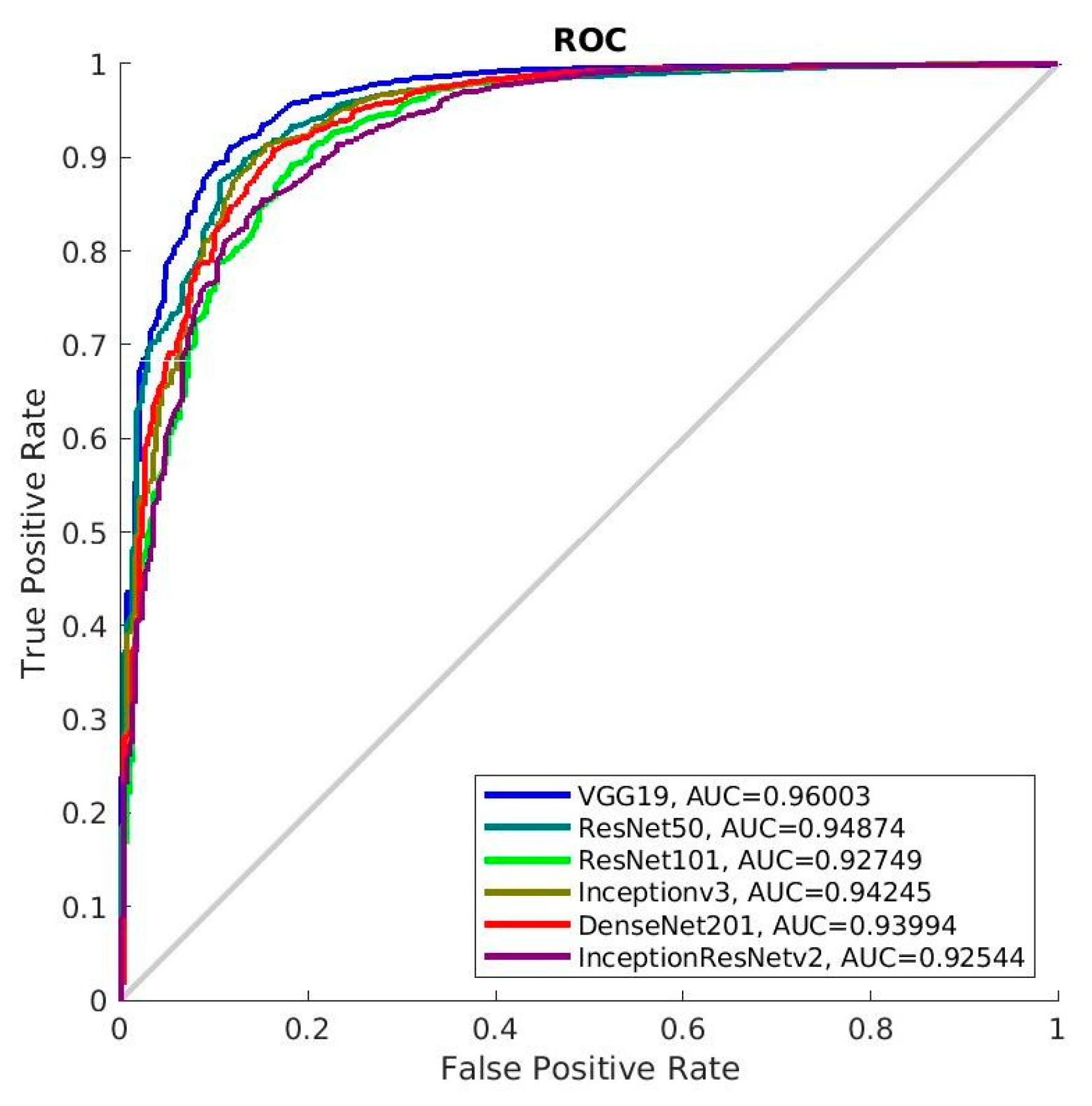
After training, we then tested the trained models with patches manually extracted from the testing set. To verify the effectiveness of data augmentation, we also evaluated the performance of the deep models that were only trained on the original training set, where the results can be seen in
Table 2, while the ROCs can be seen in
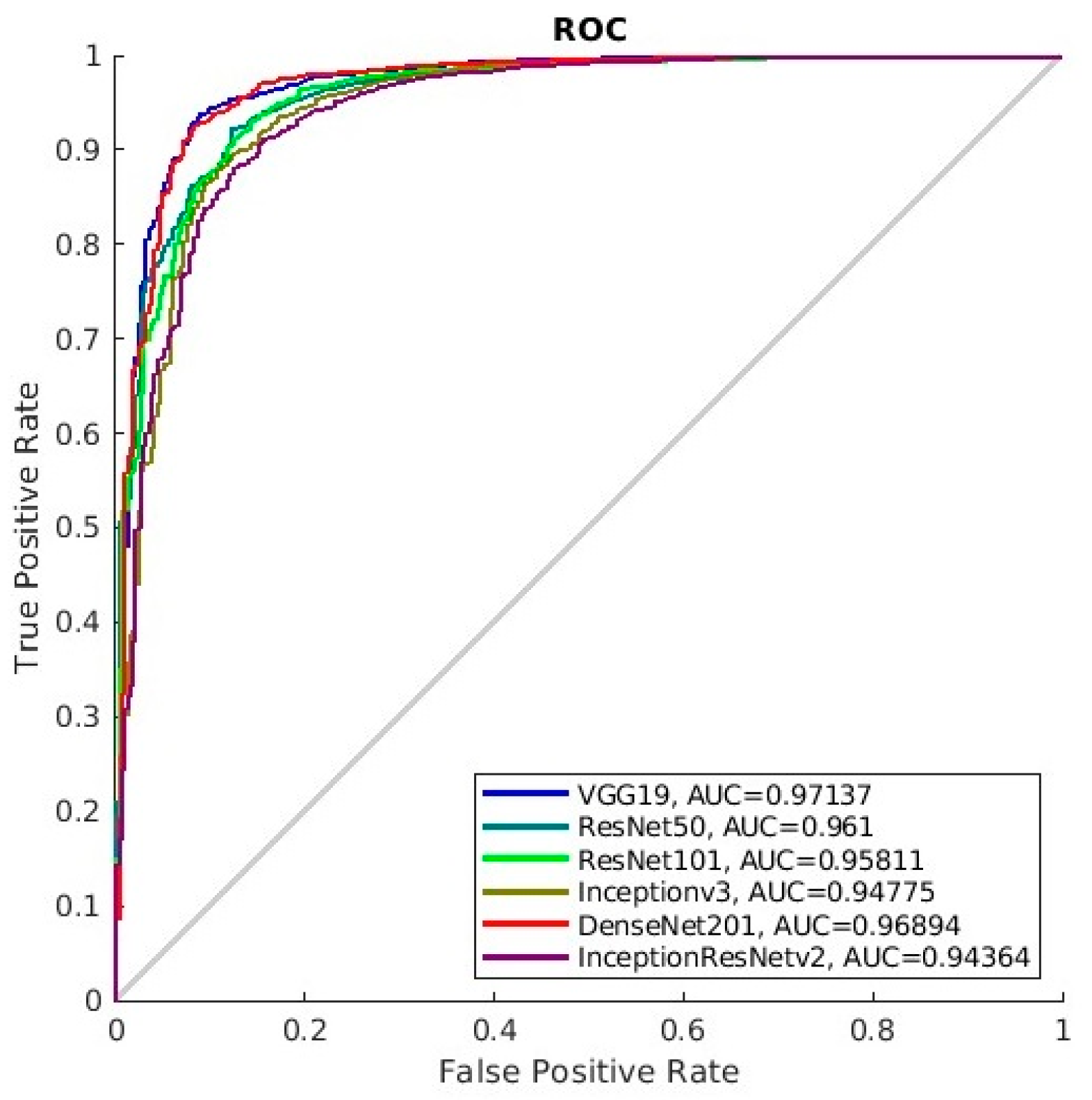
Figure 6. As can be seen from
Table 4 and
Figure 6, VGG19 turns out to be the best model as it provides the highest evaluation metrics and the AUC value. The reason behind this could attribute to the relatively large volume of VGG19 models, while the connection between the layers is straightforward. However, the precision and
are really low due to the biased distribution of the breast mass patches and breast background tissue patches.
For comparison, we then measured the performance of deep-learning models trained on the augmented training set in terms of the mentioned metrics and listed the results in
Table 5. The receiver operating characteristic (ROC) curves and AUC are given in
Figure 7, where VGG19 turns out to be the best-performed classifier as it obtained the biggest AUC. As can be seen, InceptionV3 and InceptionResNetv2 performed best in terms of overall accuracy. However, it is likely these two deep models are suffering from overfitting as they obtained low sensitivity. Note that the testing dataset is biased, while the number of tissue background patches greatly outnumbered that of the mass patches. As a result, the AUC and the sensitivity are more important compared to other evaluation metrics. Instead, VGG19 has the highest sensitivity, though the overall accuracy is lower compared to that of the other models. Considering the overall performance of different models, we only use VGG19 as the deep-learning model for breast mass patch classification.
As aforementioned, for the classifiers for false positive reduction, we chose classifiers including SVM, BDT, and KNN. We used five cross-validations to evaluate the performance of these models while we partitioned the positive patches and negative patches evenly into each fold. We listed the results of the trained models in
Table 6, where
stands for the KNN model with
as the number of neighbors. Similarly,
in
stands for the number of the decision trees in the BDT model. For evaluation metrics, we simply take the three most representative metrics, including specificity, sensitivity, and accuracy, for consideration. As can be seen from the table,
showed highest averaged performance regarding the classification task, and we then took the
model that performed best amongst the trained models as the classifier for false positive reduction. While the average sensitivity of the trained
models is low, the
model with best performance, however, showed over 90% of sensitivity and is assumed to be suitable to be a false positive reduction model.
4.3. Model Ablation on CBIS-DDSM Dataset
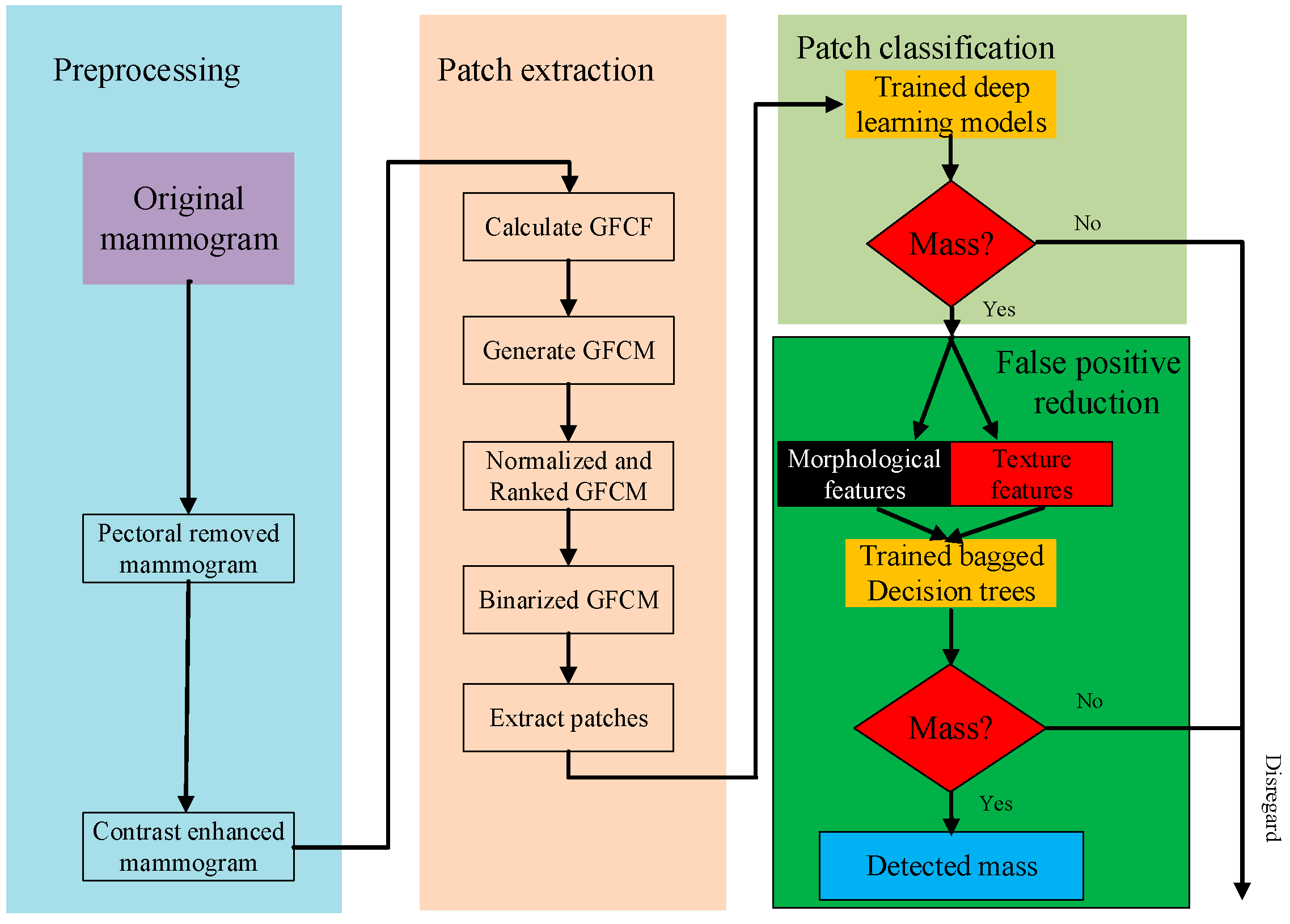
In this section, we will explore the key components that will lead to higher performance of the developed system. The detection capability of the system mainly relies on the performance of the trained deep-learning models, where VGG19 is chosen. The number of FPI generated by the system relies on the performance of the trained classifiers and NMS module, where the importance of the trained classifiers and NMS module needs to be verified via experiments. Furthermore, the overall detection performance of the proposed framework also relies on the following parameters:
The size of extracted patches, which can be denoted as width determines the scope of each patch and, therefore, directly determines the scale of the input; if the width is too small, the mass may not be totally included in the patch, and the performance of the deep-learning model may also be affected. A larger width of patches, however, means further bounding-box-refinement procedures are required as the mass can be found in a larger area. Consequently, we also need to explore the relationship between the overall performance of the proposed framework and the size for patch extraction.
The radius, , in the calculation of GFCF. , which can be interpreted as the size of filters in convolution, determines the number of neighborhood pixels that will be involved in the calculation of GFCF. A smaller may focus on small object-like features, while a larger increases the computational cost by a second order because the number of pixels for GFCF calculation is proportional to . Finally, we must specify an optimal for the trade-off between computational cost and the receptive field of GFCF.
, which determines the proportion of top GFCFs to be kept in GFCM’; a smaller may lead to a few numbers of connected components in GFCM’. As a result, some ROI regions could be missing when extracting ROI patches. However, if is too large, then connected components in GFCM’ may connect to each other and result in larger connected components, which makes it challenging to choose the proper patch width. So, we will explore the optimal value of that gives the best results on the testing set of CBIS-DDSM.
, the number of patches with top scores. When testing the trained models, it is likely that these models performed poorly on the testing set. So, we chose the top patches to keep as many mass patches as possible in the beginning. Another reason why we did not choose a fixed threshold value is that the predictive scores for patches generated through our proposed patch extraction method may fall below the threshold value as the breast tissues are complicated. However, the choice of should be careful as a larger tends to increase FPI, while a smaller tends to reduce the detection accuracy. The impact of will be shown in the experimental part.
We first checked the performance of the patch extraction module via GFCM under different configurations of these parameters and listed both patch extraction results and detection results in
Table 7.
The value of Rate in the NMS algorithm is 0.5 by default. We consider it a successful extraction of the patches if the mass patches have been included in all the patches generated from a mammogram. Specifically, for the detection results here, we simply deployed the NMS algorithm without applying the false positive reduction as we aimed at preparing coarse detection results for false positive reduction. The accuracy in the table here and after indicates the rate between the number of detected numbers and the number of real breast masses, while the FPI is the average number of false positives in each image.
To begin with, we set the , , and to be 30, 0.08, and 15, respectively, while varying width is from 129 to 199. As can be seen, the patch extraction rate increases along with the width, which means a larger width contributes to better performance of patch extraction. In addition, the detection performance benefited from the width as high accuracy, and lower FPI is seen when the width increases. We then increased , , and to 60, 0.15, and 15, respectively. As can be seen, the patch extraction rate reaches 1, which means the module indeed benefited from the increase of these parameters. However, the overall detection performance becomes even worse because the FPI increased significantly while the overall accuracy decreased slightly. The reason behind this is that the larger values of , , and lead to more generated patches. We then increase the to 20 to evaluate the impact of the on the detection performance. As a result, the FPI increases while leaving the same accuracy. Therefore, should be no more than 15. Nevertheless, we will explore more about the parameter setting in the later experiment.
We then tested the detection system with a false positive module but without no NMS. Given the fact that
performed best among all classifiers, we then took the trained
with the best performance as the classifier. The detection results can be seen in
Table 8.
As can be seen from the above table, the overall performance of the detection system has been greatly improved thanks to the false positive reduction module. By introducing the module, more breast mass patches have been correctly recognized while more breast tissue patches are wrongly recognized as a breast mass, which leads to the increase of FPI. When we fixed , , and to be 60, 0.15, and 20, we found that a larger width tends to contribute to higher detection accuracy. We then fixed the width, , and to be 149, 0.15, and 20 but varied from 40 to 60. The accuracy remains unchanged, but a small leads to a higher FPI. Considering this, a large is preferable. However, a too large will increase the overall computational cost. Therefore, we choose in the later experiment. When varying and fixing other parameters, we found that the connected components tend to connect when is larger than 0.15 because more pixels are introduced. So, we only tested the varied values, not beyond 0.15. From the table above, the accuracy and the FPI seem to increase when increases. We finally tested the model with different values of and the conclusion is that FPI increases when increases as more patches are considered in the mass patch classification stage. The accuracy, however, only reaches the highest when optimal is chosen. Based on previous experiments, we then set , , and to be 60, 0.15, and 15 while varying the width from 149 to 199 in a later experiment. The reason why we vary the width is that a smaller width tends to provide more accurate location information of the detected masses.
Finally, we tested the detection model with trained
and NMS. The detection results can be seen in
Table 9. Note that
Rate is the only parameter that should be determined for the NMS algorithm, and we then vary it from 0.5 to 0.7. As can be seen, the FPI under different situations has been greatly reduced compared to the models without NMS. Moreover, the models with trained
and NMS showed higher detection accuracy compared to the accuracy of the models with only NMS, while they have close values of FPI. Therefore, we believe the previous experiments showed the effectiveness of each module in the developed system. Some detection results can be seen in
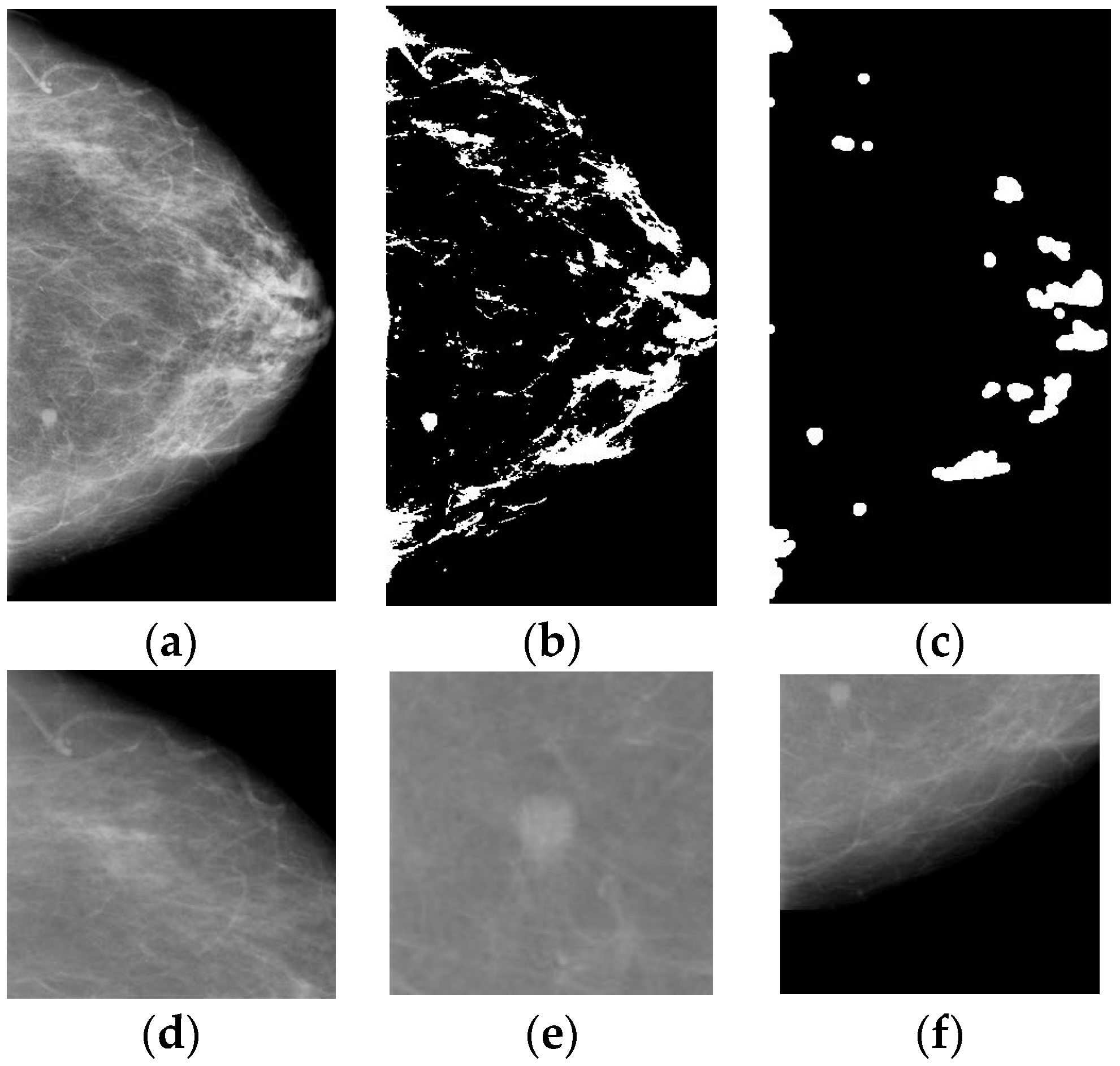
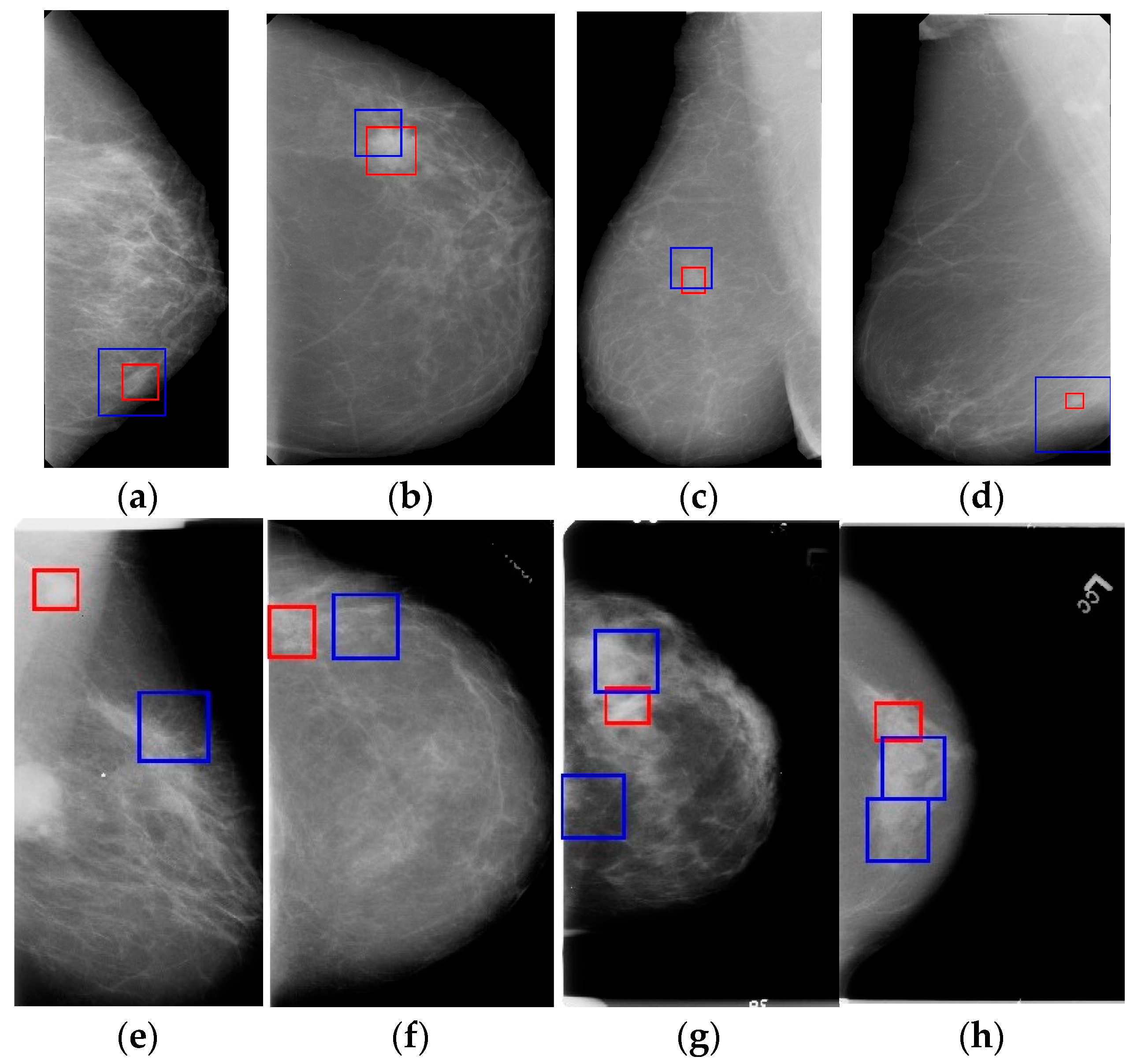
Figure 8.
Figure 8a–d are successful detection examples, where we can see that the breast masses have been detected without FPIs. One deficiency of the proposed method is the failure of detection of breast mass within the pectoral muscle, as can be seen in
Figure 8a. Furthermore, the complexity of the breast tissues, especially the breast mass-like tissue, posed a great threat to the detection of the proposed method, which can be seen from
Figure 8f–h.
4.4. Detection Results on INbreast
Without any adaptation of the proposed framework, we directly evaluated our framework on 107 mammograms from the INbreast dataset that contains at least one mass per mammogram. We fixed the
width,
, and
, but varied
and the results based on the models without false positive reduction but with NMS are shown in
Table 10. By default, we set the
Rate in the NMS algorithm to 0.5.
As can be seen from
Table 10, the overall performance of the proposed framework reaches the best one when the
width is 149,
is 60,
is 0.15, and
is 10. Especially, the FPI is much lower compared to the results on the testing set of CBIS-DDSM. The reason could be that the resolutions of mammograms from the INbreast dataset are higher than that of the mammograms from CBIS-DDSM. With the increase of
, the accuracy seems to be saturated while the FPI increases, which indicates that
should be carefully chosen instead of setting it as large as possible. Additionally, the results further show the robustness and effectiveness of our GFNet framework. Note that deep-learning models and the bagged decision trees were only trained with the training set of CBIS-DDSM while no further fine-tuning process is applied to INbreast.
We then examine the performance of GFNet with false positive reduction via trained
but without NMS on INbreast, and the detection results can be seen in
Table 11. As can be seen, the attached false positive reduction module helps to boost the detection performance. However, the FPI also increases compared to the FPI produced by the previous models with only NMS, which shows the effectiveness of the NMS module. The best model obtained is the one with the
width = 149,
= 60,
= 0.15, and
= 10 which achieved an accuracy of 0.99 at 1.37 FPI. However, if we look at the lowest value of FPI but with acceptable accuracy, the model with the
width = 149,
= 60,
= 0.15, and
= 5 becomes the best one.
Finally, we tested the full version of GFNet with false positives and NMS on INbreast and concluded the results in
Table 12. Based on previous experiments, we found that the detection accuracy on INbreast is much higher than that of the accuracy on CBIS-DDSM. We, therefore, propose to vary
from 5 to 15. To evaluate the values of
Rate to the overall detection performance on INbreast, we varied the
Rate from 0.5 to 0.7. As can be seen from
Table 11, the overall detection accuracy increases along with the increase in the
Rate. However, the FPI increases as well when the
Rate increases. Finally, the model with the
width = 149,
= 60,
= 0.15,
= 5, and
Rate = 0.5 gives the lowest FPI, while the model with the
width = 149,
= 60,
= 0.15,
= 10, and
Rate = 0.5 gives the highest detection accuracy of 0.99 at FPI of 0.97.
Some detection examples can be seen in
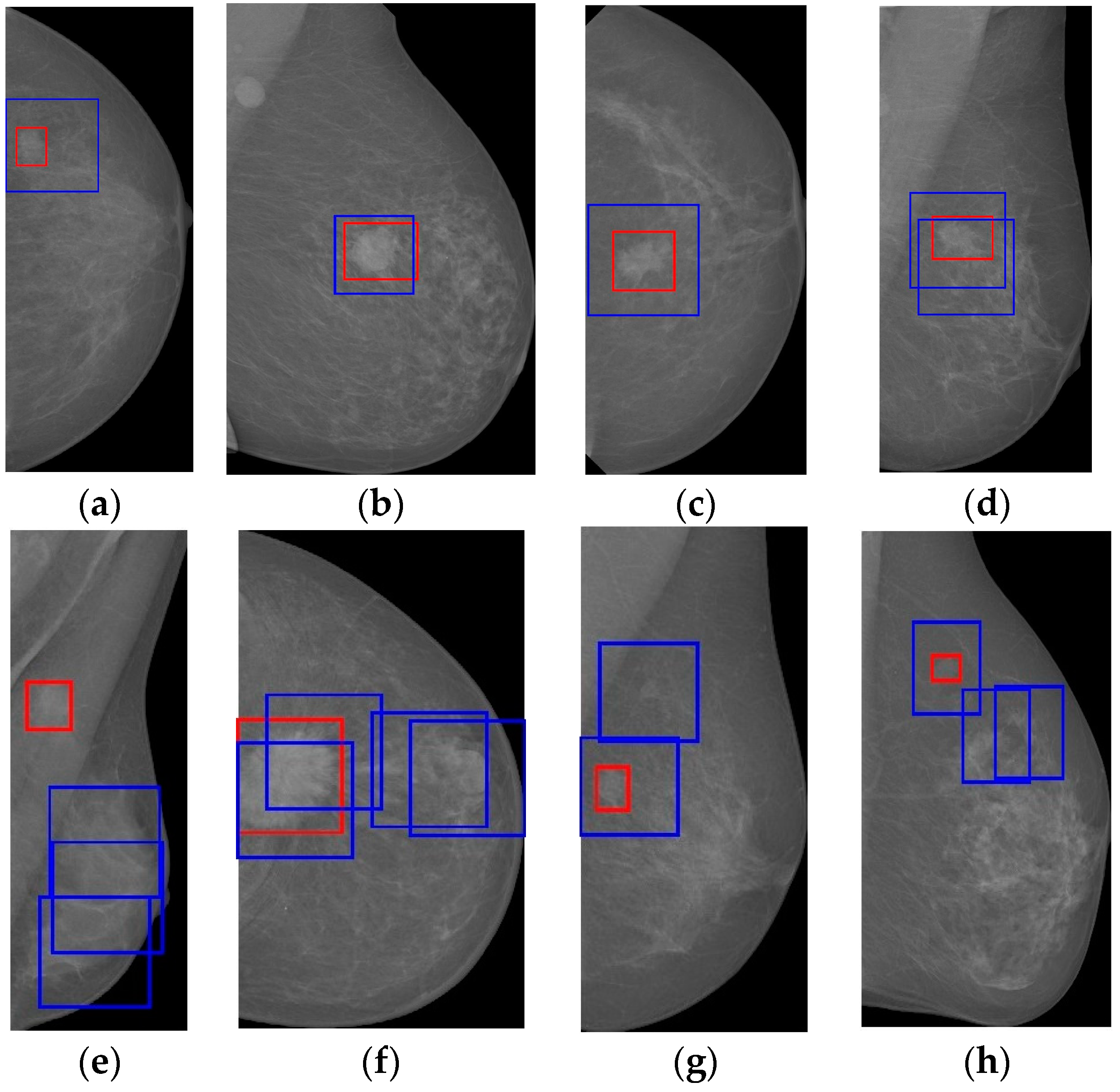
Figure 9, where true breast masses are detected at a lower cost of FPIs.
Figure 9a–d are successful detection results without FPIs, which shows the effectiveness of the proposed detection method.
Figure 9e–h are detection results with FPIs. The mass in the pectoral muscle is removed along with the removal of the pectoral muscle, and that is why the image in
Figure 9e will have multiple FPIs but no truly detected masses. Besides the true masses in the mammograms, there are also mass-like tissues that confuse the detection system, which we can tell from
Figure 9f–h.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}