
Towards Convergence in Federated Learning via Non-IID Analysis in a Distributed Solar Energy Grid

Abstract
:1. Introduction
- This work defines the viable case-by-case scenarios of the locally collected non-IID dataset. It suggests a quantification scheme of the non-IID degree in a regression-based FL network with both local and global perspectives. To the best of my knowledge, this is the first study that covers the domain of local non-IID attributes in the FL regression task.
- This work suggests theoretical convergence analysis in FL regression optimization based on the quantitative degree of IID and non-IID attributes at the local training dataset, proposing a practical training approach to enhance the convergence rate of the global model.
- This work validates the suggested analysis through multiple experiments in the FL model with the distributed solar energy generation dataset in specific regions of South Korea within the period of January 2017 to August 2021 to empirically vindicate the usability and performance of the suggested FL regression and update periods in future applications in the Smart Grid system.
2. Related Works
3. FL Regression: Trained with Non-IID and IID
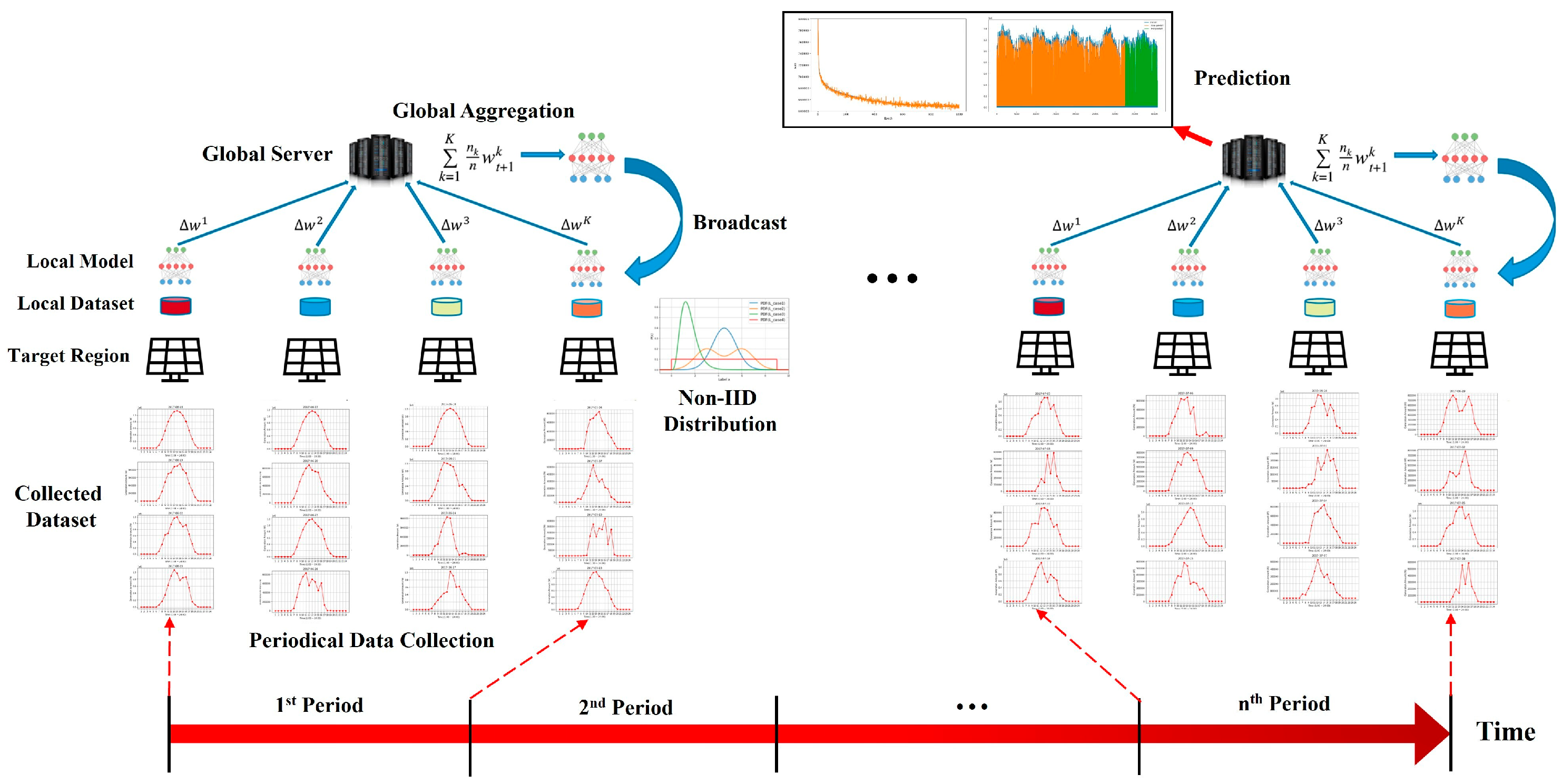
3.1. Federated Learning
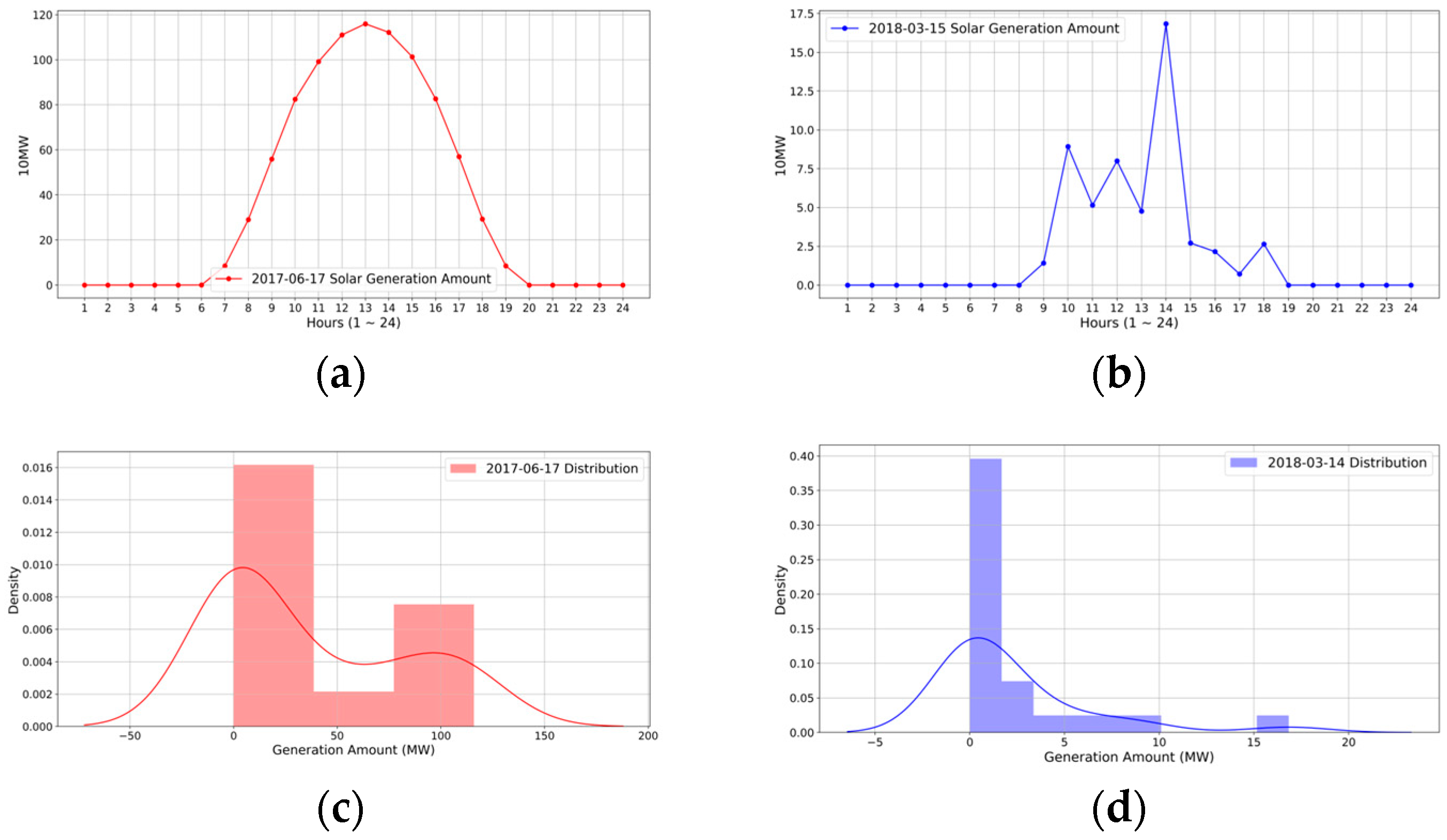
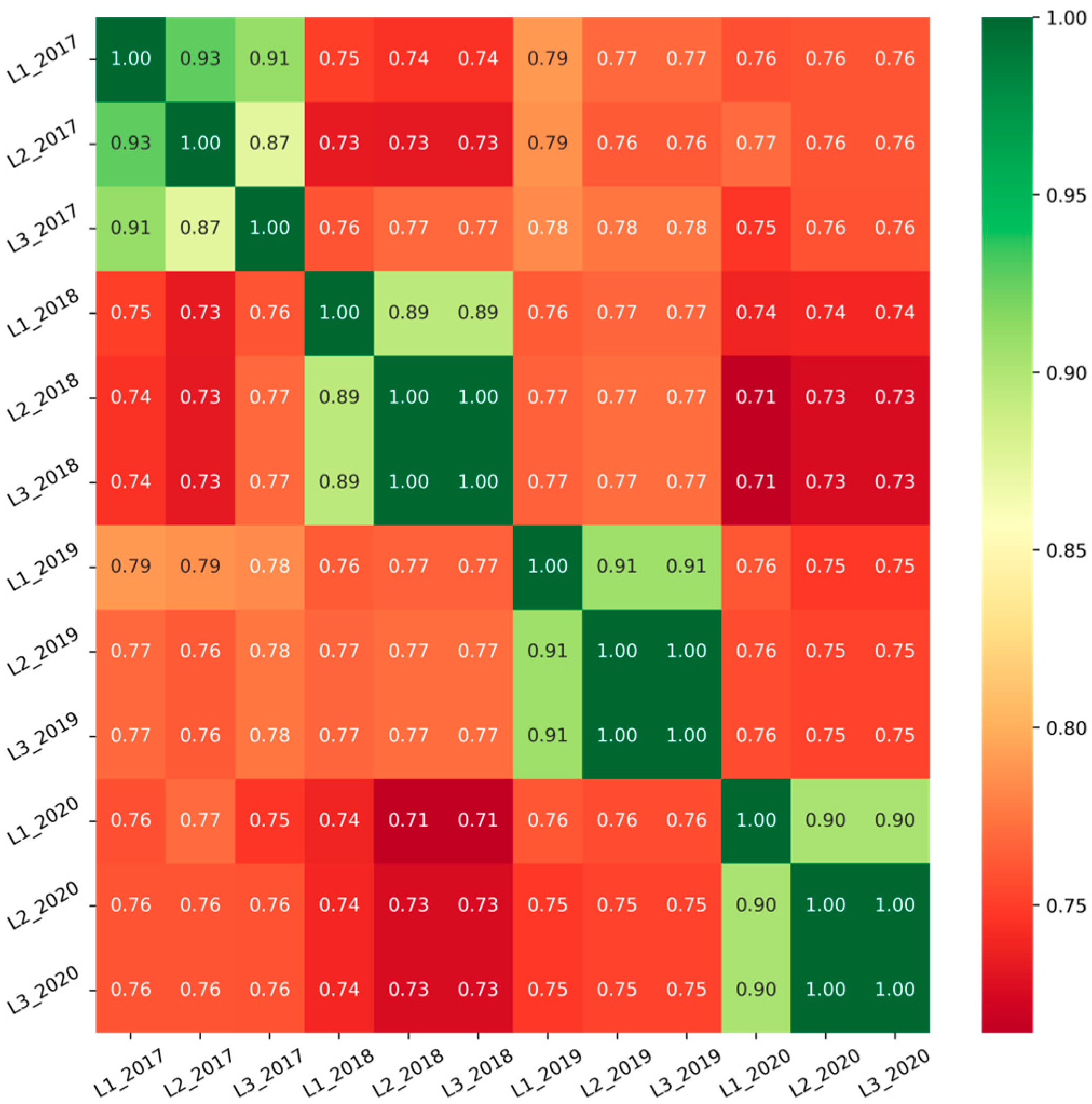
3.2. Non-IID Cases in Regression-Based FL
3.2.1. Non-IID Cases with a Structural View
- Case A. .
- Case B. in (5).
- Case C. .
3.2.2. Non-IID Cases in FL-Structural View
- Case 1. .
- Case 2. .
- Case 3. .
- Case 4. .
- Case 5. .
- Case 6. .
3.3. IID Dataset in FL Regression
4. Property and Performance Analysis of FL Regression
4.1. Dataset Analysis
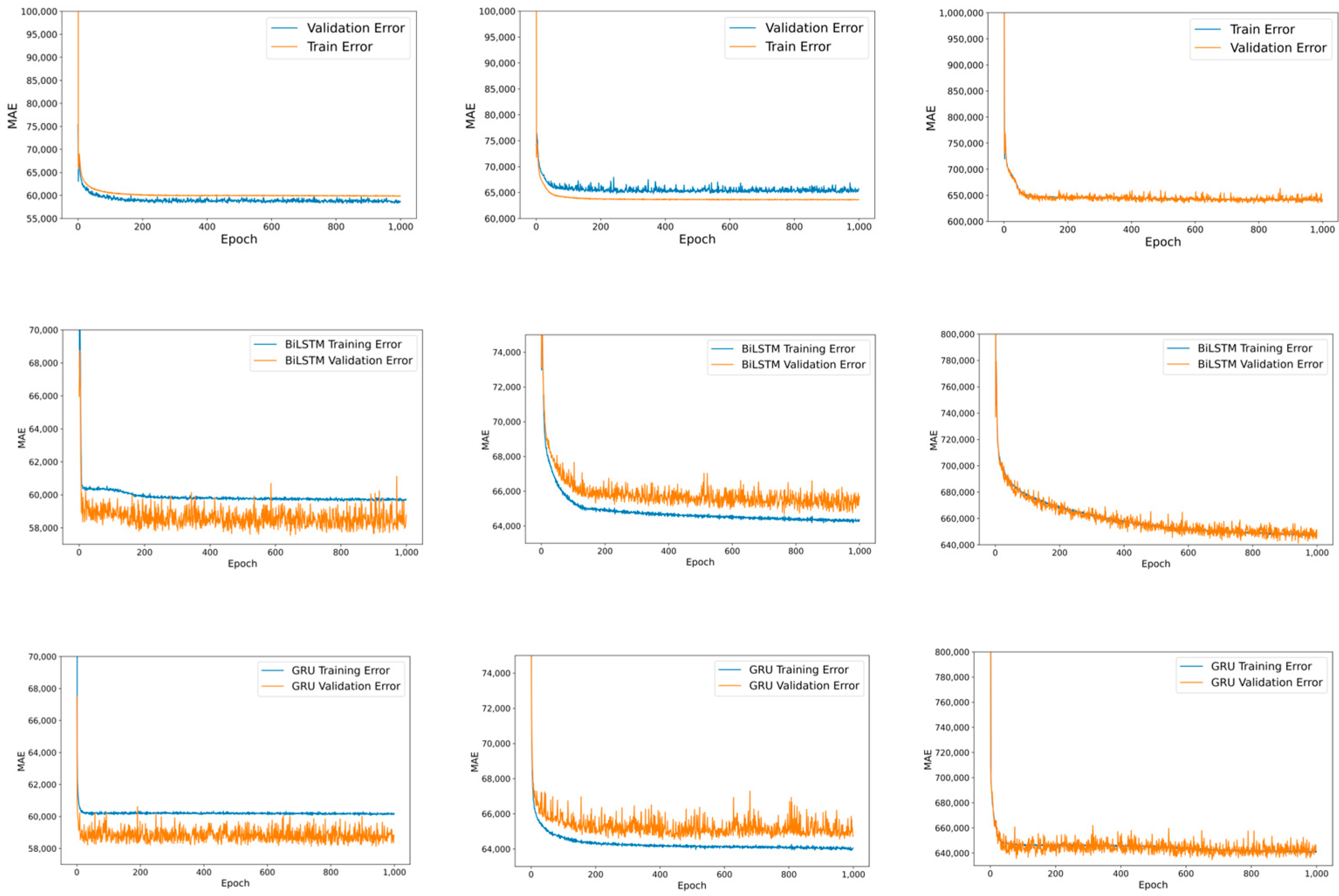
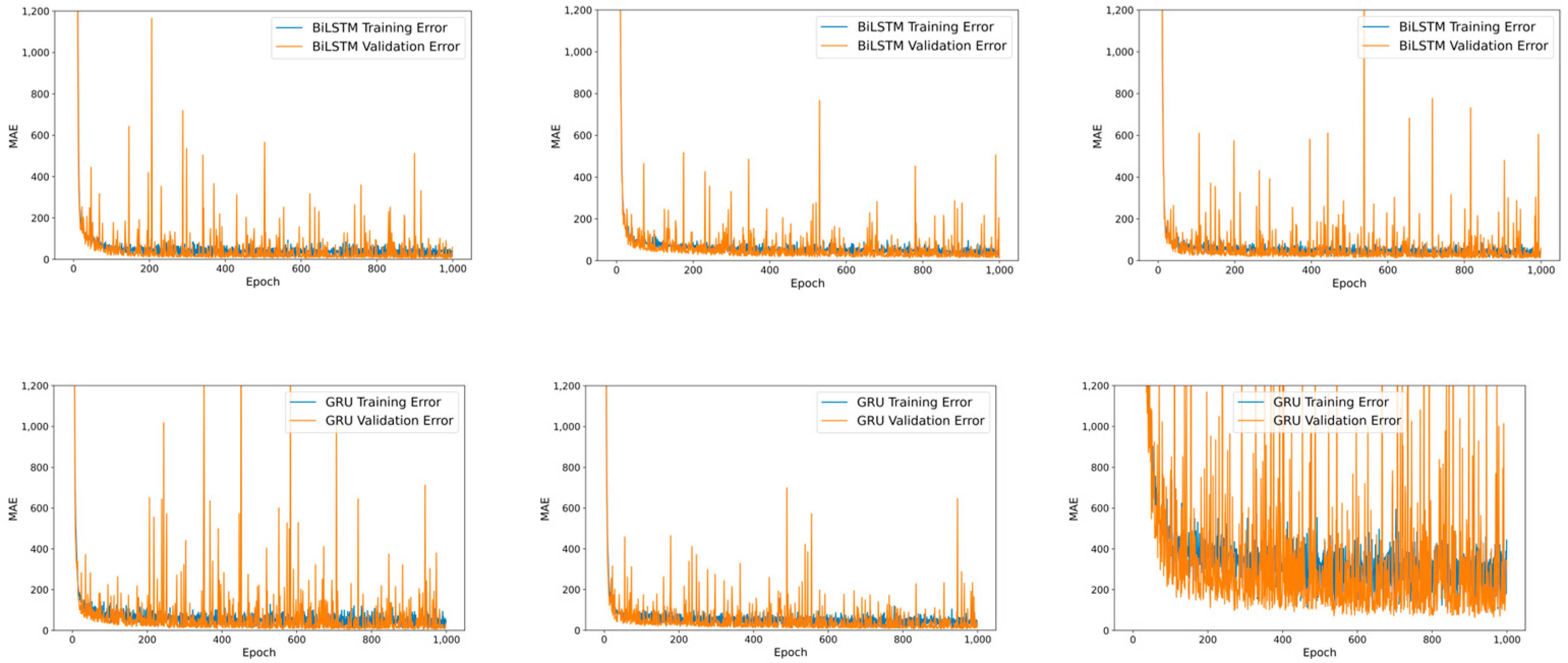
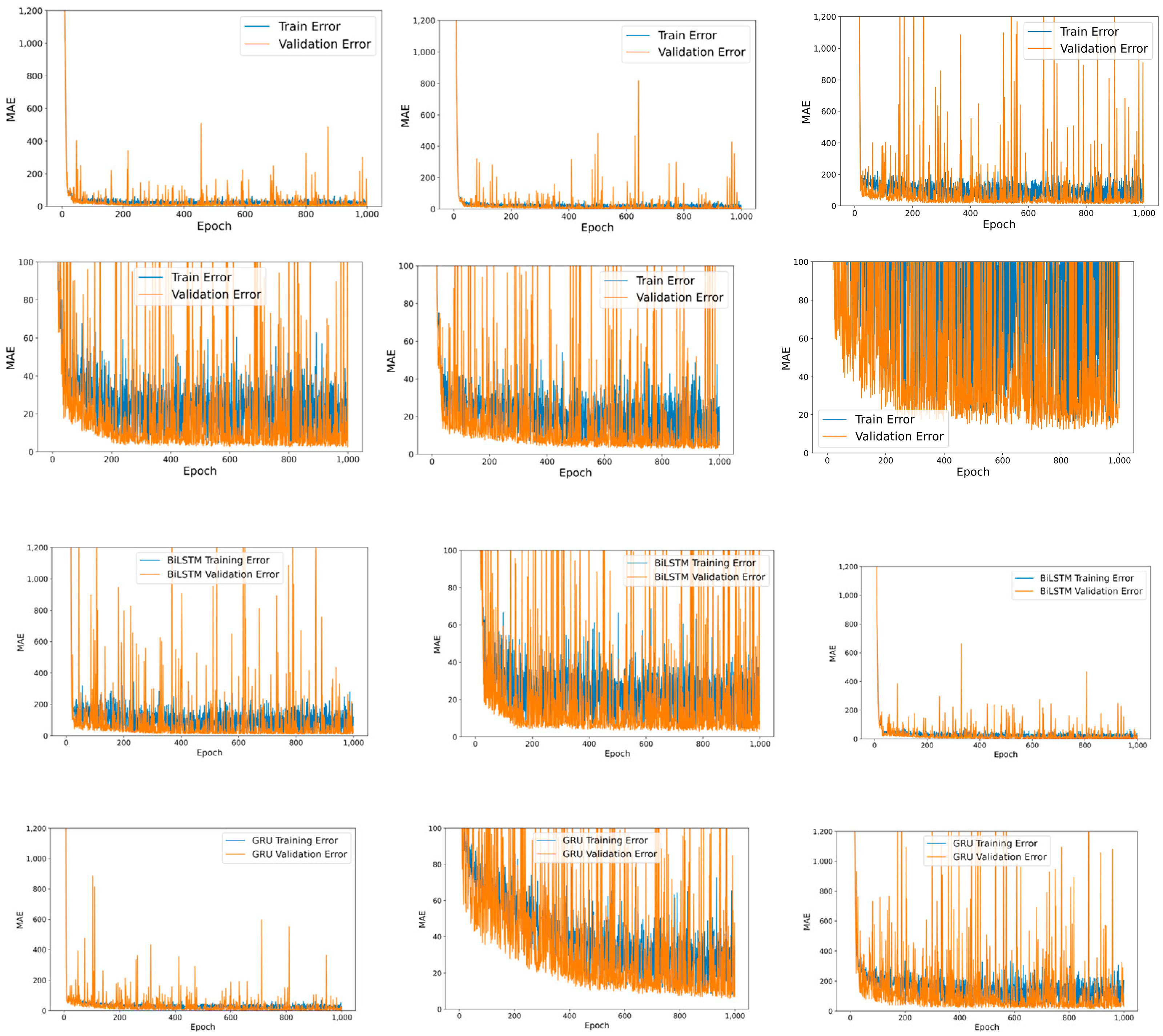
4.2. Training RNN-Based Models in Local Client
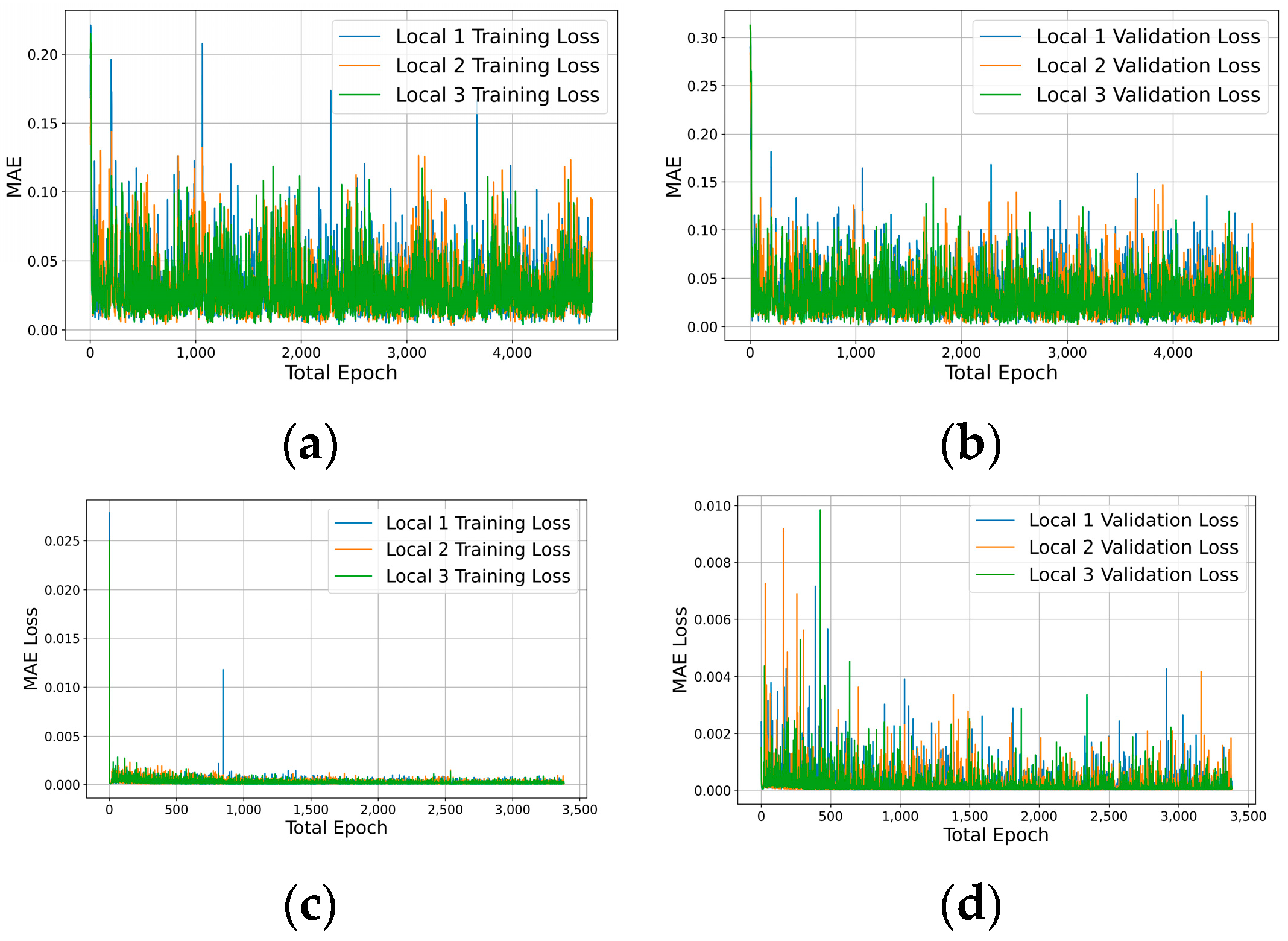
4.3. Merging Heterogeneous Local Models in FL
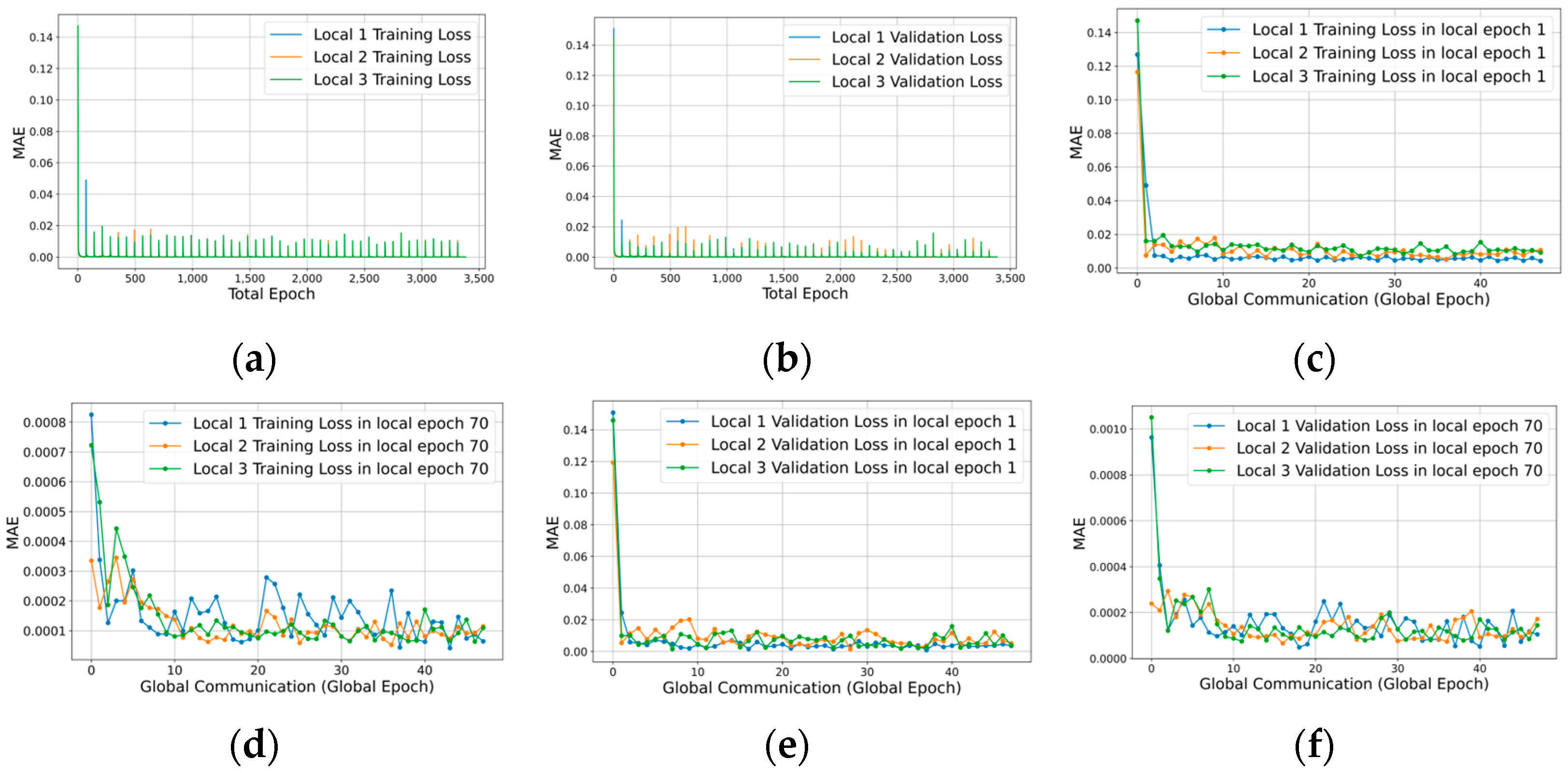
4.4. Federated Learning on Periodical Update
- Case . Daily update period, such that , and in (3).
- Case . Monthly period, such that , and in (3).
- Case . Yearly period, such that , and in (3).
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
Notations
| Notation | Definition | Notation | Definition |
| Global model | Local epoch | ||
| Set of global parameters | Global epoch | ||
| Tensor shape of parameters | Number of local epoch | ||
| 2d vector of weights and bias | Number of global epoch | ||
| Local client index () | Loss function of input | ||
| ’s parameter index () | Set of hidden units | ||
| Constant | Layer, Layer index | ||
| Dataset | Error term | ||
| Required number of i | Loss space with dimensions | ||
| Distribution of input | Learning rate | ||
| Kullback Leibler divergence of | Ideal benchmark dataset | ||
| Local model | Time unit s: sec, h: hour | ||
| Standard deviation of the input | Set of feature; | ||
| Average of the input | Input | ||
| sampling rate per second | Ground truth | ||
| multivariate function | Sejong-si | ||
| multivariate function | Youngnam-gun | ||
| Yansan-si |
References
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Artificial Intelligence and Statistics; PMLR: Cambridge, MA, USA, 2017; pp. 1273–1282. [Google Scholar]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the convergence of fedavg on non-iid data. arXiv 2019, arXiv:1907.02189. [Google Scholar]
- Gadekallu, T.R. Federated Learning for Big Data: A Survey on Opportunities, Applications, and Future Directions. arXiv 2021, arXiv:2110.04160. [Google Scholar]
- Zhan, Y.; Zhang, J.; Hong, Z.; Wu, L.; Li, P.; Guo, S. A Survey of Incentive Mechanism Design for Federated Learning. IEEE Trans. Emerg. Top. Comput. 2021, 10, 1035–1044. [Google Scholar] [CrossRef]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.; Suresh, A.T. Scaffold: Stochastic controlled averaging for federated learning. In International Conference on Machine Learning; PMLR: Cambridge, MA, USA, 2020; pp. 5132–5143. [Google Scholar]
- Korea Public Data Portal. Available online: https://www.data.go.kr/data/15003553/fileData.do (accessed on 21 December 2022).
- You, S. A Cyber-secure Framework for Power Grids Based on Federated Learning. Eng. Arch. 2020. [Google Scholar] [CrossRef]
- Massaoudi, M.; Abu-Rub, H.; Refaat, S.S.; Chihi, I.; Oueslati, F.S. Deep Learning in Smart Grid Technology: A Review of Recent Advancements and Future Prospects. IEEE Access 2021, 9, 54558–54578. [Google Scholar] [CrossRef]
- Taik, A.; Nour, B.; Cherkaoui, S. Empowering Prosumer Communities in Smart Grid with Wireless Communications and Federated Edge Learning. IEEE Wirel. Commun. 2021, 28, 26–33. [Google Scholar] [CrossRef]
- Zhai, S.; Jin, X.; Wei, L.; Luo, H.; Cao, M. Dynamic Federated Learning for Gmec With Time-Varying Wireless Link. IEEE Access 2021, 9, 10400–10412. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, X.; Shen, X.; Sun, H. A federated learning framework for smart grids: Securing power traces in collaborative learning. arXiv 2021, arXiv:2103.11870. [Google Scholar]
- Wen, M.; Xie, R.; Lu, K.; Wang, L.; Zhang, K. FedDetect: A Novel Privacy-Preserving Federated Learning Framework for Energy Theft Detection in Smart Grid. IEEE Internet Things J. 2021, 9, 6069–6080. [Google Scholar] [CrossRef]
- Zhao, L.; Li, J.; Li, Q.; Li, F. A Federated Learning Framework for Detecting False Data Injection Attacks in Solar Farms. IEEE Trans. Power Electron. 2021, 37, 2496–2501. [Google Scholar] [CrossRef]
- Li, D.; Luo, Z.; Cao, B. Blockchain-based federated learning methodologies in smart environments. Clust. Comput. 2021, 25, 2585–2599. [Google Scholar] [CrossRef]
- Al-Quraan, M.; Khan, A.; Centeno, A.; Zoha, A.; Imran, M.A.; Mohjazi, L. FedTrees: A Novel Computation-Communication Efficient Federated Learning Framework Investigated in Smart Grids. arXiv 2022, arXiv:2210.00060. [Google Scholar]
- Wang, Y.; Bennani, I.L.; Liu, X.; Sun, M.; Zhou, Y. Electricity consumer characteristics identification: A federated learning approach. IEEE Trans. Smart Grid 2021, 12, 3637–3647. [Google Scholar] [CrossRef]
- Zhao, Y.; Xiao, W.; Shuai, L.; Luo, J.; Yao, S.; Zhang, M. A Differential Privacy-enhanced Federated Learning Method for Short-Term Household Load Forecasting in Smart Grid. In Proceedings of the 2021 7th International Conference on Computer and Communications (ICCC), Chengdu, China, 10–13 December 2021; pp. 1399–1404. [Google Scholar] [CrossRef]
- Fernandez, J.D.; Menci, S.P.; Lee, C.; Fridgen, G. Secure Federated Learning for Residential Short Term Load Forecasting. arXiv 2021, arXiv:2111.09248. [Google Scholar]
- Zhou, X.; Feng, J.; Wang, J.; Pan, J. Privacy-preserving household load forecasting based on non-intrusive load monitoring: A federated deep learning approach. PeerJ Comput. Sci. 2022, 8, e1049. [Google Scholar] [CrossRef] [PubMed]
- Savi, M.; Fabrizio, O. Short-term energy consumption forecasting at the edge: A federated learning approach. IEEE Access 2021, 9, 95949–95969. [Google Scholar] [CrossRef]
- Taik, A.; Cherkaoui, S. Electrical Load Forecasting Using Edge Computing and Federated Learning. In Proceedings of the ICC 2020–2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, C.; Jiang, C.; Han, Z. Deep Reinforcement Learning Assisted Federated Learning Algorithm for Data Management of IIoT. IEEE Trans. Ind. Inform. 2021, 17, 8475–8484. [Google Scholar] [CrossRef]
- Saputra, Y.M.; Hoang, D.T.; Nguyen, D.N.; Dutkiewicz, E.; Mueck, M.D.; Srikanteswara, S. Energy Demand Prediction with Federated Learning for Electric Vehicle Networks. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Huang, X.; Li, P.; Yu, R.; Wu, Y.; Xie, K.; Xie, S. Fedparking: A federated learning based parking space estimation with parked vehicle assisted edge com-puting. IEEE Trans. Veh. Technol. 2021, 70, 9355–9368. [Google Scholar] [CrossRef]
- Zhang, Y.; Tang, G.; Huang, Q.; Wang, Y.; Wu, K.; Yu, K.; Shao, X. FedNILM: Applying Federated Learning to nilm Applications at the Edge. In IEEE Transactions on Green Communications and Networking; IEEE: Piscataway Township, NJ, USA, 2022; p. 1. [Google Scholar] [CrossRef]
- Hudson, N.; Hossain, J.; Hosseinzadeh, M.; Khamfroush, H.; Rahnamay-Naeini, M.; Ghani, N. A Framework for Edge Intelligent Smart Distribution Grids via Federated Learning. In Proceedings of the 2021 International Conference on Computer Communications and Networks (ICCCN), Athens, Greece, 19–22 July 2021; pp. 1–9. [Google Scholar] [CrossRef]
- Nightingale, J.S.; Wang, Y.; Zobiri, F.; Mustafa, M.A. Effect of Clustering in Federated Learning on Non-IID Electricity Consumption Prediction. In Proceedings of the 2022 IEEE PES Innovative Smart Grid Technologies Conference Europe (ISGT-Europe), Novi Sad, Serbia, 10–12 October 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Briggs, C.; Fan, Z.; Andras, P. Federated learning for short-term residential energy demand forecasting. arXiv 2021, arXiv:2105.13325. [Google Scholar]
- Yan, G.; Hao, W.; Jian, L. Seizing Critical Learning Periods in Federated Learning. In Proceedings of the AAAI Conference on Artificial Intelligence; AAAI Press: Palo Alto, CA, USA, 2022. [Google Scholar]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Blockchain Empowered Asynchronous Federated Learning for Secure Data Sharing in Internet of Vehicles. IEEE Trans. Veh. Technol. 2020, 69, 4298–4311. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Xiong, Z.; Miao, C.; Niyato, D.; Yang, Q.; Leung, C.; Poor, H.V. Hierarchical Incentive Mechanism Design for Federated Machine Learning in Mobile Networks. IEEE Internet Things J. 2020, 7, 9575–9588. [Google Scholar] [CrossRef]
- Lee, H.; Liu, Y.; Kim, D.; Li, Y. Robust Convergence in Federated Learning through Label-wise Clustering. arXiv 2021, arXiv:2112.14244. [Google Scholar]
- Zhou, T.; Konukoglu, E. FedFA: Federated Feature Augmentation. arXiv 2023, arXiv:2301.12995. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2017 | 1.60 ± 0.85 | 1.55 ± 1.03 | 1.86 ± 0.90 |
| 2018 | 1.66 ± 0.95 | 1.60 ± 0.99 | 1.86 ± 0.91 |
| 2019 | 1.57 ± 0.88 | 1.60 ± 0.99 | 1.83 ± 0.91 |
| 2020 | 1.71 ± 0.75 | 1.61 ± 1.00 | 1.97 ± 0.86 |
| August 2021 | 1.87 ± 0.87 | 1.64 ± 0.97 | 1.98 ± 0.86 |
| Overall | 1.67 ± 0.87 | 1.60 ± 1.00 | 1.89 ± 0.89 |
| Experiment 1 | ||||||
| Local 1 | Local 2 | Local 3 | ||||
| Train | Val | Train | Val | Train | Val | |
| LSTM | 60,298.26 | 58,202.96 | 64,383.79 | 62,592.67 | 662,806.25 | 635,606.56 |
| GRU | 60,169.04 | 58,801.27 | 64,059.05 | 64,715.78 | 640,914.86 | 641,708.94 |
| BiLSTM | 59,735.69 | 58,777.66 | 64,374.08 | 65,708.52 | 646,646.01 | 651,371.92 |
| Experiment 2 | ||||||
| Local 1 | Local 2 | Local 3 | ||||
| Train | Val | Train | Val | Train | Val | |
| LSTM | 39.41 | 9.66 | 93.16 | 71.93 | 374.10 | 75.47 |
| GRU | 47.73 | 36.67 | 30.86 | 27.75 | 443.16 | 310.01 |
| BiLSTM | 41.74 | 58.56 | 35.78 | 12.73 | 56.57 | 59.75 |
| Experiment 3 | ||||||
| Local 1 | Local 2 | Local 3 | ||||
| Train | Val | Train | Val | Train | Val | |
| LSTM | 21.56 | 1.28 | 27.41 | 12.20 | 159.37 | 27.50 |
| GRU | 29.86 | 19.76 | 32.15 | 6.80 | 204.22 | 30.82 |
| BiLSTM | 22.43 | 1.81 | 14.13 | 8.16 | 119.58 | 16.97 |
| Local 1 | Local 2 | Local 3 | |
|---|---|---|---|
| FedAvg () | 472,308.44 | 516,164.47 | 1,334,568.25 |
| FedAvg () | 183,788.52 | 220,938.30 | 1,605,387.38 |
| FedAvg () | 11,498.82 | 30,333.07 | 1,790,837.25 |
| FedAvg () | 228,898.06 | 201,307.98 | 2,012,914.50 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, H. Towards Convergence in Federated Learning via Non-IID Analysis in a Distributed Solar Energy Grid. Electronics 2023, 12, 1580. https://doi.org/10.3390/electronics12071580
Lee H. Towards Convergence in Federated Learning via Non-IID Analysis in a Distributed Solar Energy Grid. Electronics. 2023; 12(7):1580. https://doi.org/10.3390/electronics12071580
Chicago/Turabian StyleLee, Hyeongok. 2023. "Towards Convergence in Federated Learning via Non-IID Analysis in a Distributed Solar Energy Grid" Electronics 12, no. 7: 1580. https://doi.org/10.3390/electronics12071580