1. Introduction
Convolutional neural networks (CNNs) have been widely studied and applied to various computational vision tasks such as image classification, target detection, and autonomous driving due to their excellent performance [
1,
2,
3]. For a long time, the mainstream line of thinking has been to improve the accuracy by increasing the network depth and complexity. However, it is difficult to implement deep networks with high computational density in embedded devices with limited computational resources, low power consumption, and high real-time characteristics. Therefore, lightweight convolutional neural network (CNN) design methods have attracted extensive research.
Network pruning and quantization were first proposed to reduce the computational complexity and resource consumption of deep networks. Subsequently, lightweight designs for the convolutional structure itself, such as depthwise separable convolution [
4] and group convolution, have been widely used. Compared to group convolution, DSC has higher efficiency due to fewer parameters and floating operations [
5], and is the most popular lightweight design method for CNN models to our knowledge.
DSC-based CNN models are being used extensively in mobile terminals, placing new demands on the power consumption and computing power of the platforms. GPUs offer excellent intensive computing performance and are often used to implement traditional convolutional accelerators. However, power consumption and volume limitations make it difficult to use GPU accelerators in embedded mobile devices. In addition, DSC is greatly different from the traditional standard convolution (STC) in terms of computational structure, and the performance of GPU-based accelerators for DSC cannot reach the theoretical value due to the high MAC/FLOPs ratio of DSC [
6]. The accelerators based on application-specific integrated circuits (ASICs) are designed for specific networks and offer higher processing efficiency and lower power consumption compared to GPU-based accelerators. However, the long design and iteration cycles of ASICs and the rapid iteration of network model updates make it difficult to take full advantageof ASICs. FPGAs have powerful parallel computing capabilities and can process multiple data streams simultaneously to achieve high throughput. In addition, FPGA-based accelerators have lower power consumption compared to GPU-based accelerators and shorter design cycles compared to ASIC-based accelerators. Therefore, FPGAs have attracted much attention in the implementation of various DSC-based lightweight CNN accelerators.
Limited on-chip resources and off-chip memory access bandwidth are the two major bottlenecks in implementing FPGA-based CNN accelerators. The key step in acceleration is to maximise the utilization of on-chip computing resources and off-chip access bandwidth, and reduce the utilization of on-chip memory resources. Pipelining is a common technique for accelerating algorithms in FPGAs, and DSC can also be accelerated by using pipelined hardware structures. Ref. [
7] proposes an FPGA-based DSC accelerator with all the layers working concurrently in a pipelined fashion to improve the system throughput and performance. However, only a small 10-layer DSC model was deployed on FPGAs in Ref. [
7]. In fact, DSC-based networks typically have extremely deep network depth and high complexity, such as MobilenetV2 which is a 54-layer network. When a deep DSC model is deployed by using a fully pipelined architecture, the computational resources consumed will be significantly higher. In response to this problem, partial pipeline structures are widely used. Ref. [
8] proposes to design a separate DWC engine in addition to the STC engine. By optimising the scheduling strategy, the two engines can operate efficiently in a pipelined fashion, and the engine size is planned according to the difference in computation volume between the different layers. However, since there are multiple engines in the accelerator, including the STC engine, DWC engine, pooling engine, and elementwise engine, when switching between different types of layers, it is not guaranteed that all engines work in parallel in a pipeline fashion, which will lead to some engines being idle. Ref. [
9] uses a single PWC accelerator and a DWC accelerator individually. The DWC accelerator can be pipelined after the PWC accelerator, or it can bypass the PWC convolution accelerator to match the DWC in MobileNets, reducing off-chip memory accesses and increasing inference speed. However, some engines will be idle when the computation does not satisfy the order in which the PWC layer is computed before the DWC layer, or when the PWC accelerator is bypassed. Other designs [
10,
11,
12,
13,
14] that use a partially pipelined architecture have similar engine idle problems, which reduce resource utilization. In contrast to the pipeline architecture is the single-engine architecture. The single-engine architecture was originally used in standard convolutional accelerators [
15], and some high-performance DSC accelerators [
6,
16,
17,
18,
19] also use this architecture. Ref. [
16] was the first to propose an FPGA acceleration framework for DSC, designing a computational engine with configurable modes and sizes to accommodate multiple operations, including DWC and PWC, as well as an in-channel multiplexed data caching approach that reduces off-chip memory bandwidth requirements, and finally implementing the MobileNetV2 network on an Arria10 Soc with an image classification speed of 266 FPS. However, it does not propose a solution for the first standard convolutional layer and the last fully connected layer, nor does it address how residual structures can be efficiently implemented in hardware.
In summary, existing FPGA-based DSC accelerator designs can be divided into three categories according to the strategy of using a pipelined structure. Accordingly, there are three different strategies for designing computational engines. They are (1) a fully discrete dedicated engine design strategy, which corresponds to a fully pipelined architecture. In this architecture, each computational layer has its own dedicated engine. However, the strategy is not suitable for deep DSC networks due to the large amount of computational resources consumed. (2) The second is a partially discrete dedicated engine design strategy, which corresponds to a partially pipelined architecture. The strategy focuses on the design of PWC and DWC dedicated compute engines, as well as other types of engines. Ideally, the individual engines would be able to perform parallel computations in a pipelined fashion to reduce off-chip accesses and improve accelerator performance. However, as the accelerators switch between different types of layers, the order of the layer inputs does not match the order in which the accelerators are expected, which inevitably leads to some compute engines being idle, thus reducing resource utilization. (3) Thirdly, we have single-engine architecture. Instead of designing dedicated engines for different types of layers, multiple computations are achieved by configuring the computational modes of a single engine, which has the advantage of making full use of computational resources. However, the performance of single-engine accelerators is usually limited by the bandwidth of off-chip memory access. In addition, as the calculation process of DSC is significantly different from standard convolution, using a traditional STC engine to calculate DSC will cause the engine to idle, resulting in a waste of processing elements.
The main contributions of this work are as follows.
- 1.
A scalable and highly reusable multiplication and accumulation engine (MAE) is proposed to solve the engine-idling problem caused by the separate dedicated engine architecture, and the MAE is compatible with different types of computation.
- 2.
An efficient convolution algorithm is proposed for DWC and PWC, respectively, to reduce the on-chip memory occupancy. Meanwhile, the two algorithms achieve layer fusion between PWC and DWC and improve off-chip memory access efficiency.
- 3.
An address-mapping method for off-chip access is proposed. This maximises bandwidth utilization and reduces latency when reading feature maps.
The remainder of this paper is organized as follows.
Section 2 briefly describes the CNN and depthwise separable convolution.
Section 3 presents the design of the proposed accelerator, including the detailed computational engine design and two methods for DSC acceleration.
Section 4 gives the results of the performance evaluation of the accelerator. Finally,
Section 5 summarizes the content of this article.
3. Design of Accelerator
3.1. Overall Architecture
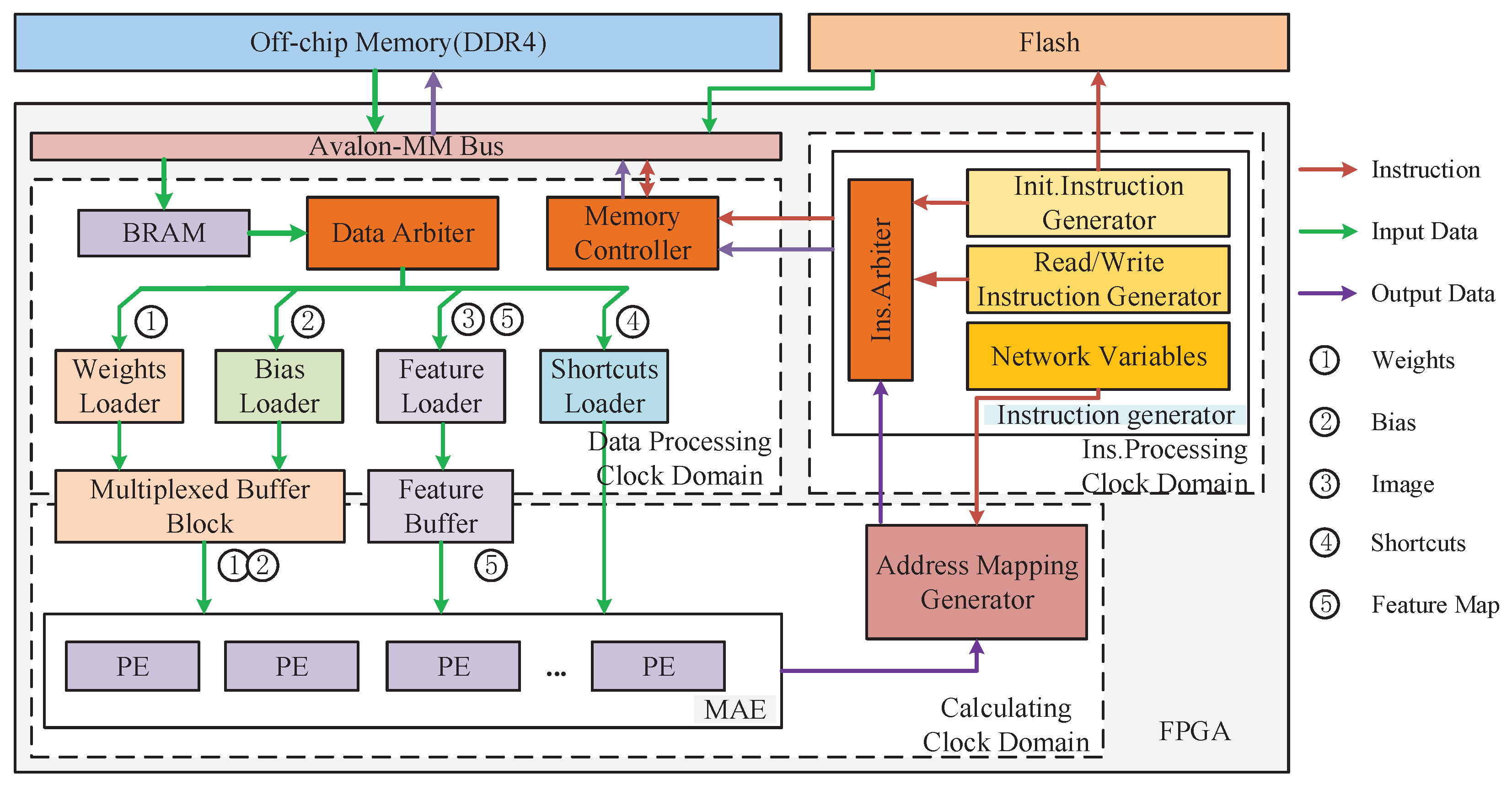
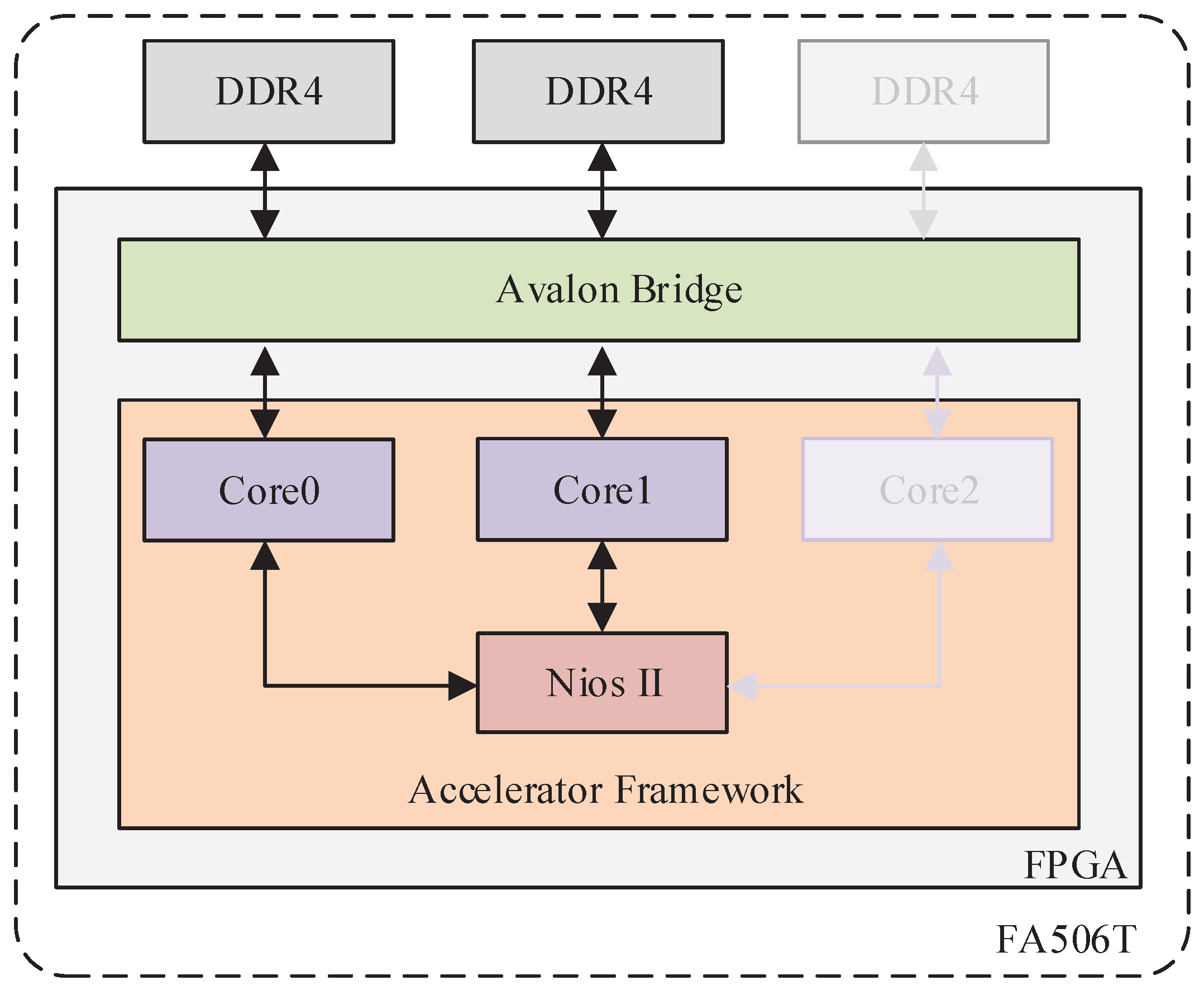
The overall architecture of the proposed accelerator is shown in
Figure 2, which details the main modules and the flow of instructions and data.
When the accelerator is started, the initialization instructions will first be generated by the Init Instruction Generator, and then the network weights and biases are read from external flash into on-chip memory. Simultaneously, the address mapping generator is initialized according to preset network variables. Then, the reading feature instruction is generated by the reading instruction generator, which acts on the memory controller. The latter sends a read instruction via the Avalon-MM bus to the off-chip memory, which returns the data after several clock cycles in a pipelined fashion. All read data is buffered in the BRAM and distributed to different buffers by the data arbiter. When the biases, weights, and input features are ready, convolution calculation is preformed by MAE, and the output features are written back to DDR4 via the address-mapping generator. Write feature instructions are generated by the write instruction generator and the write process is similar to the read process. Arbitration between different instructions is performed by the ins arbiter. For framework compatibility and portability considerations, the system is divided into three clock domains including the data processing clock domain, calculating clock domain, and instruction processing clock domain. The calculating clock domain is tuned to the performance of the hardware platform.
3.2. The Scalable Multiplication and Accumulation Engine
To address the problem of low utilization of computational resources caused by idle engines during the running phrase, we propose a multiplexed scalable multiplication and accumulation engine that is compatible with multiple types of computation. In this section, the structure and variable parameters of the proposed calculation engine are explained in detail. In addition, the utilization of the engine for different calculations is analysed.
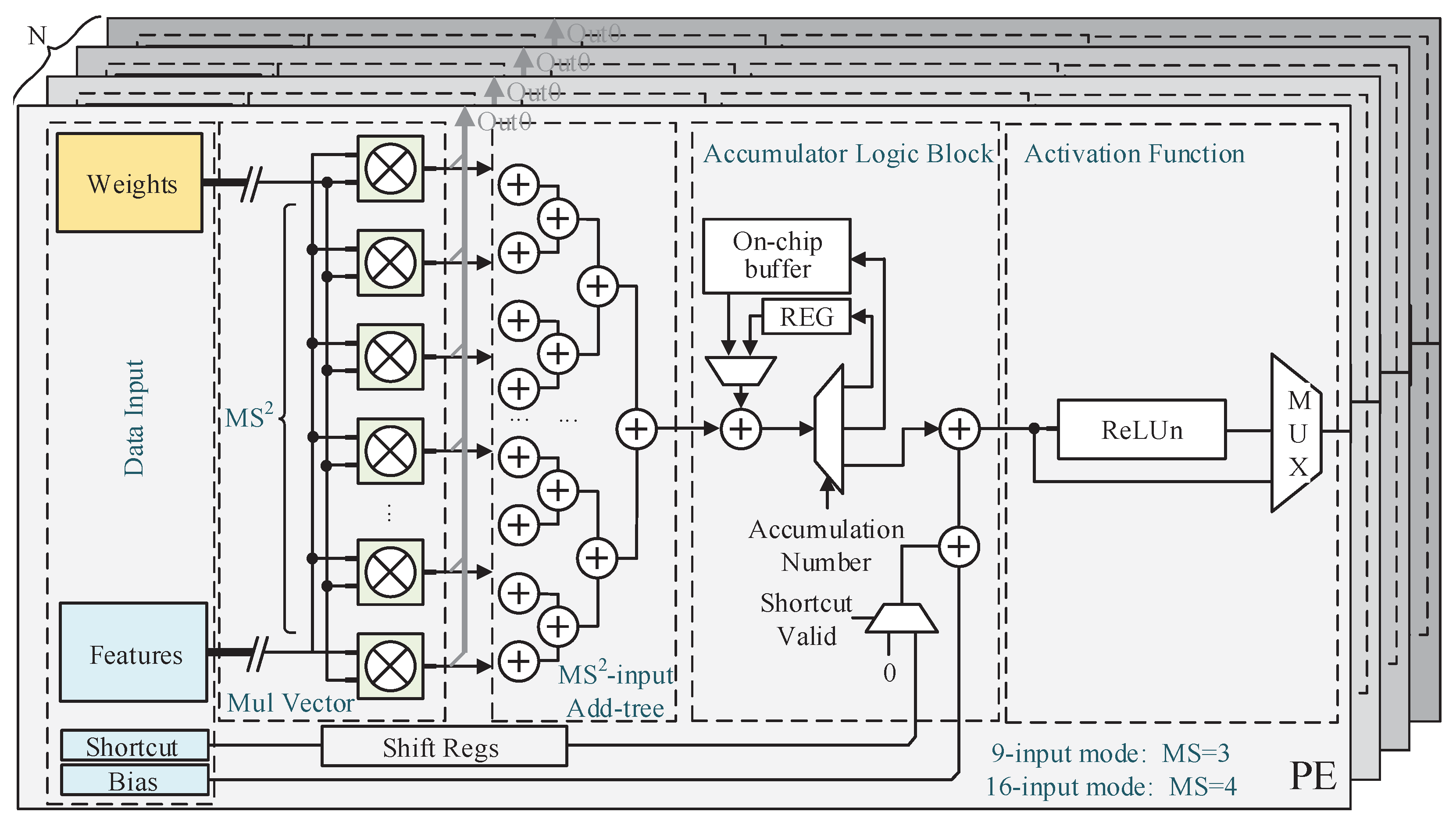
The block diagram of the proposed MAE with
N processing elements (PEs) is shown in
Figure 3. Each PE in the MAE contains a multiplication vector with
multipliers, an add tree with
inputs, an accumulator logic block, two adders for bias and residual summation, and a ReLUn (e.g., ReLU6) logic block.
N PEs are used in parallel in each MAE. The proposed MAE is scalable in size and can be adapted to various FPGA platforms with different amounts of resources by configuring
and
N. For
, two modes are available—
and
—and the default is
. Since 3 × 3 is a common convolution kernel size in CNNs, and for DSC-based CNNs (e.g., MobilenetV2), the number of channels of the feature map is usually an integer multiple of 16, the modes
and
are more friendly for PWC and DWC. A discussion of the utilization of the proposed MAE will follow below. In addition, resource utilization and accelerator performance can be easily balanced by adjusting the number of PEs, and the default is
.
The input of each PE consists of
weight feature pairs, an inverse residual, and a bias. Assume that the number of weight feature pairs required by a valid output of PE in a single convolution calculation is
M.
M is equal to
K ×
K for DWC and
for PWC. The accumulation number of the accumulator logic block is determined by
M and
and can be expressed as
where
represents the operation of rounding up. The accumulator logic block works continuously, and intermediate data is temporarily cached in REG or on-chip buffer as shown in
Figure 3. Compared to REG, the on-chip buffer requires more memory resources and can cache more data. Normally, the DWC calculation uses REG to accumulate directly, and part of the PWC is temporarily stored in the on-chip buffer, because the size
K of the DWC filter is usually fixed and relatively small, and the channel depth
of the PWC filter is a dynamic value and relatively large. For DWC with a fixed
K ×
K convolution kernel, the default accumulation number is
As for PWC,
is a dynamic variable that varies from layer to layer, and the preset accumulation number is
The sum of the shortcut and bias is strictly aligned with the time sequence output of the of the accumulator. In the layer without inverse residuals, the shortcuts are set to zero. The ReLUn logic block is implemented by two comparators. It is worth noting that ReLUn is placed at the end of each layer, while the inverse residual is placed before RelUn. The inverse residual is a spanning summation operation between layers. In terms of execution order, the inverse residual is usually executed after ReLUn, while in the proposed MAE the inverse residual summation is deployed before ReLUn. This is because in a number of DSC-based CNNs (e.g., MobileNetV3), ReLUn appears only within the bottleneck block, while the inverse residual summation appears after the output layer of the bottleneck block. Thus, ReLUn and inverse residual summation do not appear simultaneously. Therefore, the proposed MAE prioritises the residual summation to reduce the number of pipelines.
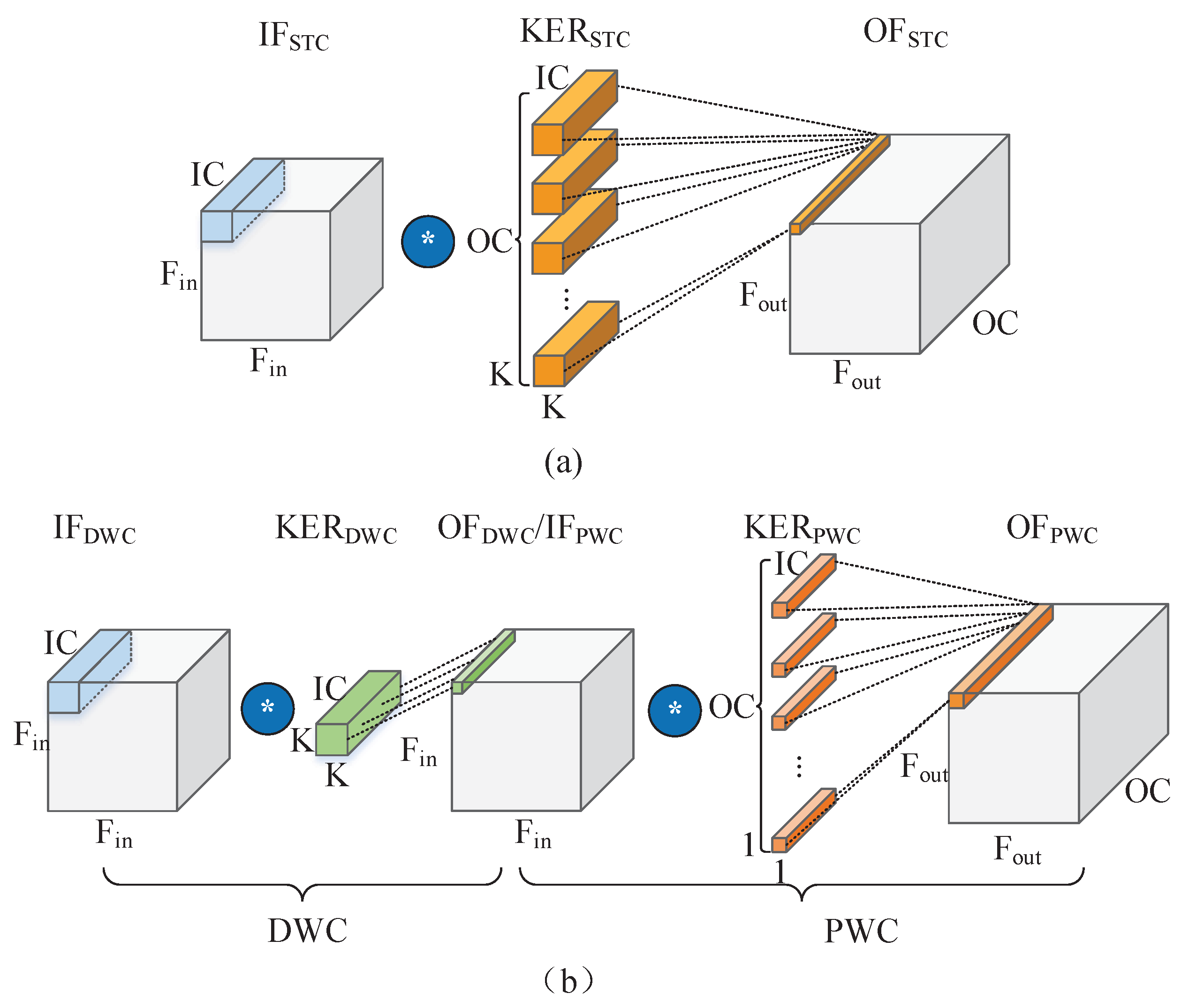
The different types of computation are prenormalised to DWC and PWC before the computation starts. The STC filter of size
is replaced by the PWC filter of size
. Like STC, the FCL and GPL layers are also suitable to deployment as a PWC layer. The role of the softmax layer is to assign class labels based on probabilities. Since class labels are assigned by sorting the FCL output, which is less computationally intensive, softmax is not deployed on the accelerator. Note that if necessary, softmax can be implemented quickly on a Nios II processor. Batch normalization can be merged into the weight and bias of the convolution layer, which is a common method [
27,
28]. In addition, the inverse residual, which can be called a shortcut, should also be merged into the bias because it always lags the convolution calculation.
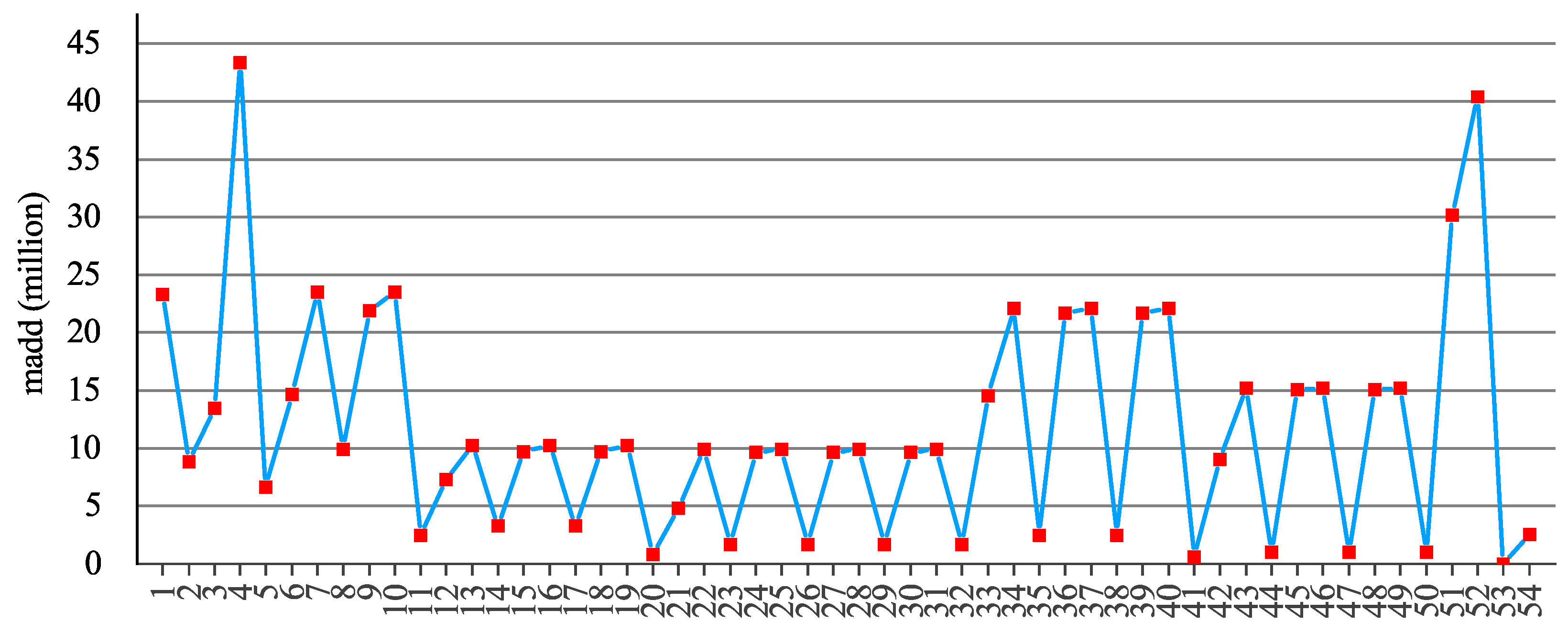
We analyze the scalable parameters
and
N by calculating the MAE utilization. In the proposed MAE, the multipliers and adders are approximately equal in number, and the PE utilization for convolution (e.g., DWC or PWC) can be represented by the valid multiplication load percentage. For the MAE to work properly, a zero-fill complement to PE is required for layers where the total number of multiplications is not an integer multiple of
, and the zero-fill multiplication is referred to as an invalid multiplication load. If the stride is 1, the MAE utilization for DWC and PWC with the convolution order proposed in
Section 3.3 can be expressed as
According to Equations (
12) and (
13), both
and
are independent of the size of the input feature map.
is related to
and
K, and
reaches its maximum value when
is an integer multiple of
N and
is an integer multiple of
.
is determined by
and
, and the MAE utilization for PWC is highest when
is an integer multiple of
and
is an integer multiple of
N. We determined the default values of
and
N by analyzing
,
and
K of MobilenetV1, MobilenetV2, and MobilenetV3.
3.3. Two Efficient Convolution Algorithms
Reducing on-chip memory and improving off-chip memory access efficiency are two other focuses of this paper in addition to improving the engine utilization. In this section, we first analyse the on-chip memory resources required for four common DSC computation sequences based on the minimum cache and access cells shown in
Figure 4. Subsequently, an efficient convolution algorithm is designed for DWC and PWC, respectively, under the condition of minimising on-chip memory to improve the PWC layer writing DDR4 efficiency and reduce the latency of reading feature maps.
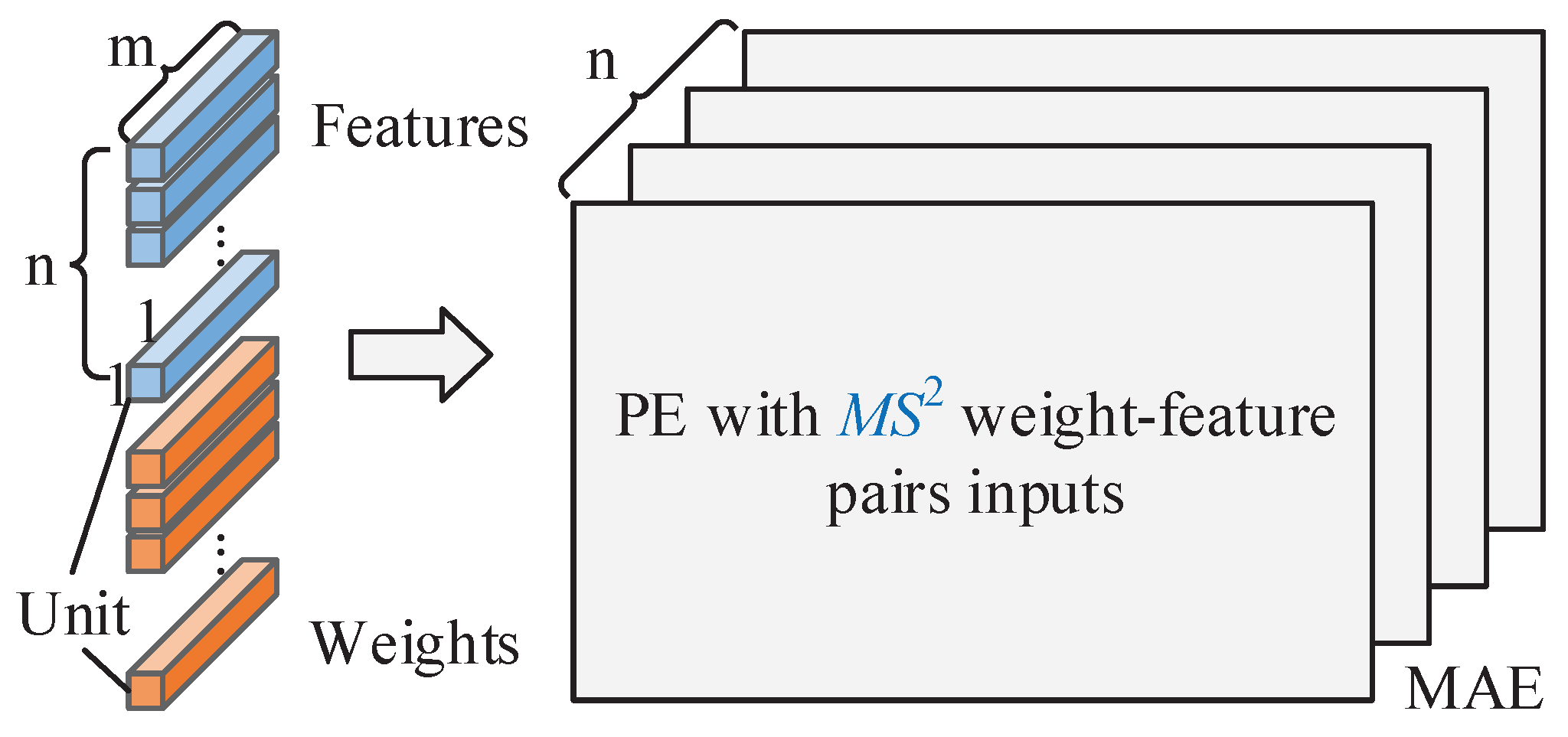
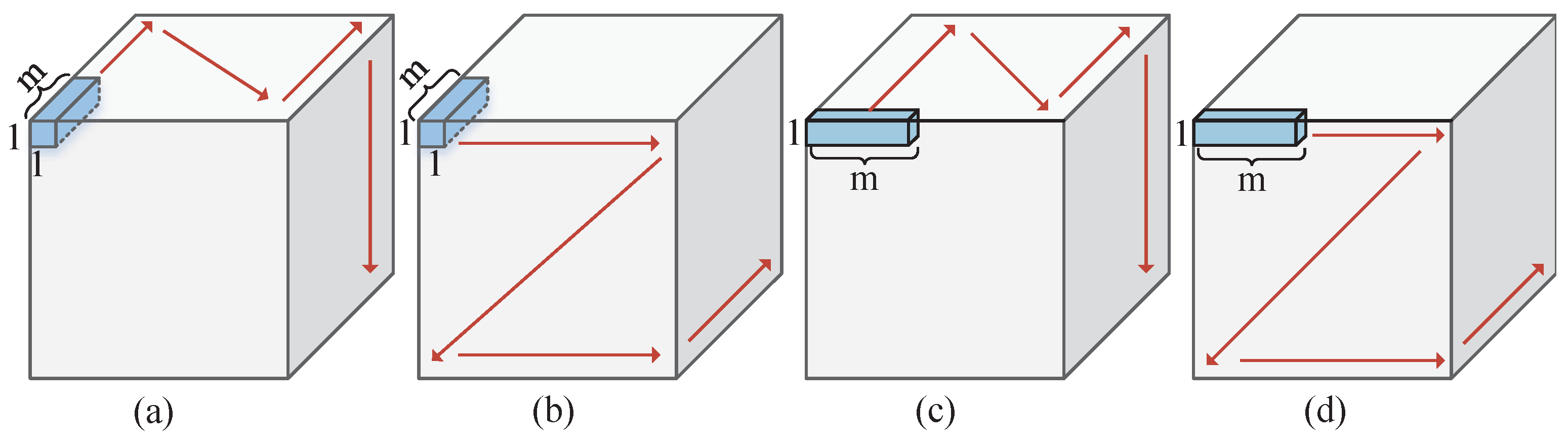
Assume that the minimum cache and access unit for feature maps and weights contains
m data, and
n units are filled into
n PEs in parallel, as shown in
Figure 4. Furthermore, the unit consisting of
m interchannel data is called a pointwise unit (PU), as shown in
Figure 5a,b, while the unit containing
m intrachannel data is called a depthwise unit (DU), as shown in
Figure 5c,d. Similarly, the interchannel first loop order is called pointwise loop (PL), as represented by the red arrows in
Figure 5a,c, and the intrachannel first loop order is called depthwise loop (DL), as represented by the red arrows in
Figure 5b,d.
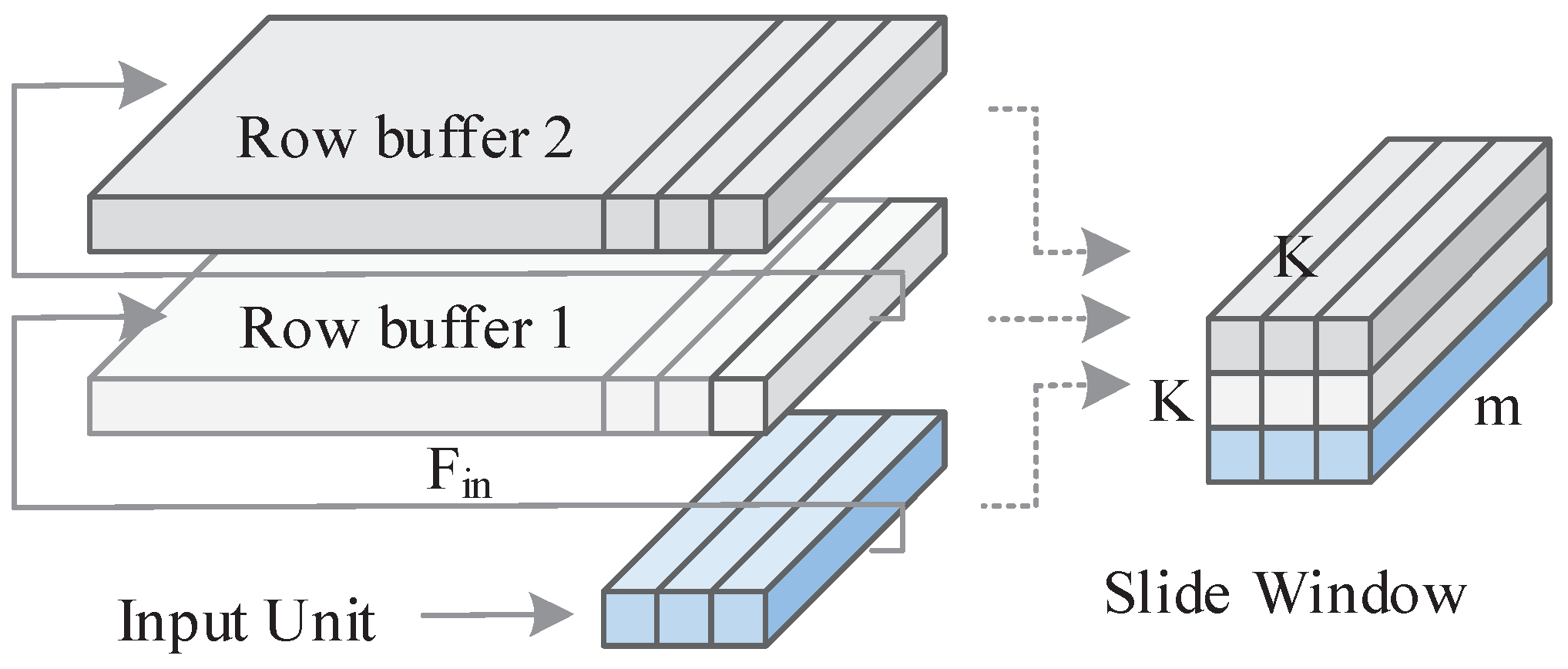
The cached data mainly includes input feature maps and weights, and compared to the former the latter is less and occupies a smaller cache, so the input feature map cache size is mainly considered. In order to avoid frequent updating of the weight buffer, both DWC and PWC multiplex the weight data. The DWC features of different input channels are filled into respective PEs, while the PWC features of different input channels are filled into the same PE. Take DWC with PUDL convolution order, as shown in
Figure 5b, as an example. We use the structure shown in
Figure 6 to perform the sliding window operation. The minium cache size of input features before starting convolution calculation is
where
Q is the quantified bit width. Similarly, the cache size of DWC and PWC with the various convolution orders are calculated, and the results are shown in
Table 1. Compared to
and
,
m,
n and
K are usually taken as smaller values. Thus, by analyzing
Table 1, it is clear that for DWC, the PUDL convolution order requires the smallest buffer size. For PWC, the PUDL convolution order requires the same buffer size as PUPL and is smaller than the other two orders. However, the PWC calculation with PUDL order requires additional resource to store intermediate results and a more complex control strategy compared to with PUPL order. Therefore, in terms of the minimum preconvolution feature cache size, PUPL is the most efficient convolution order for PWC. In summary, the use of the PUDL order to calculate DWC, along with the PUPL order to calculate PWC, can minimize the preconvolution feature cache size.
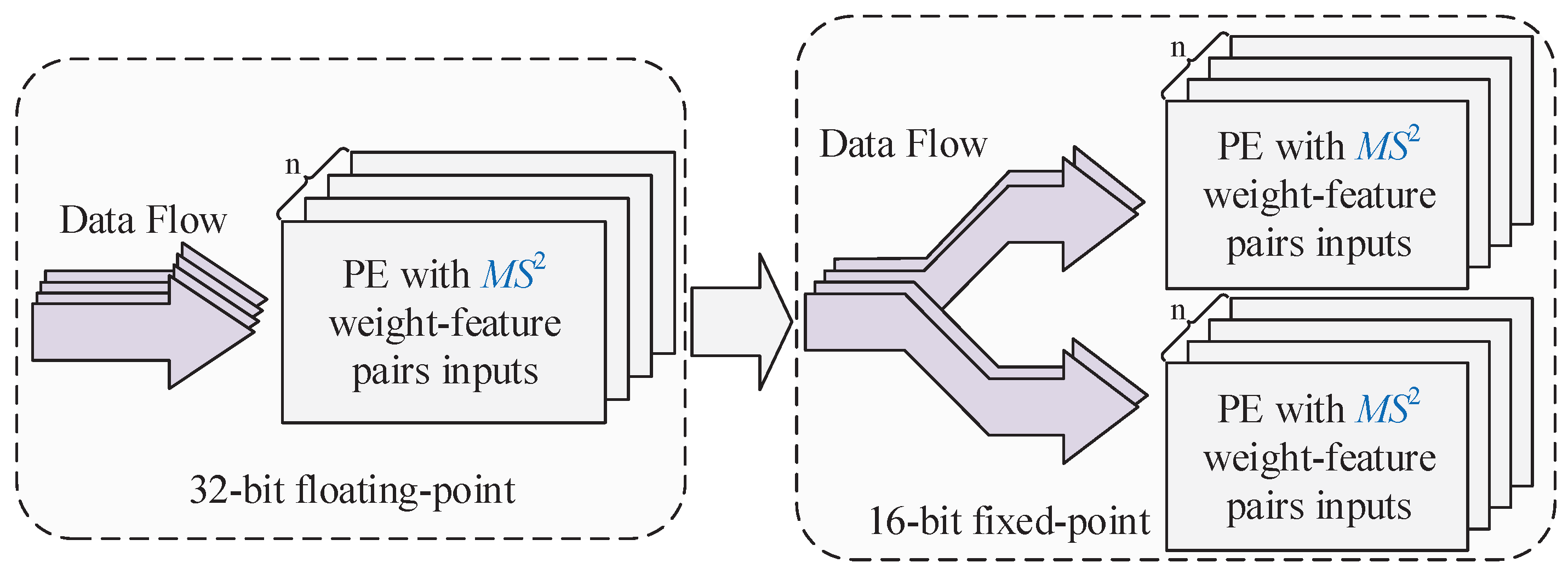
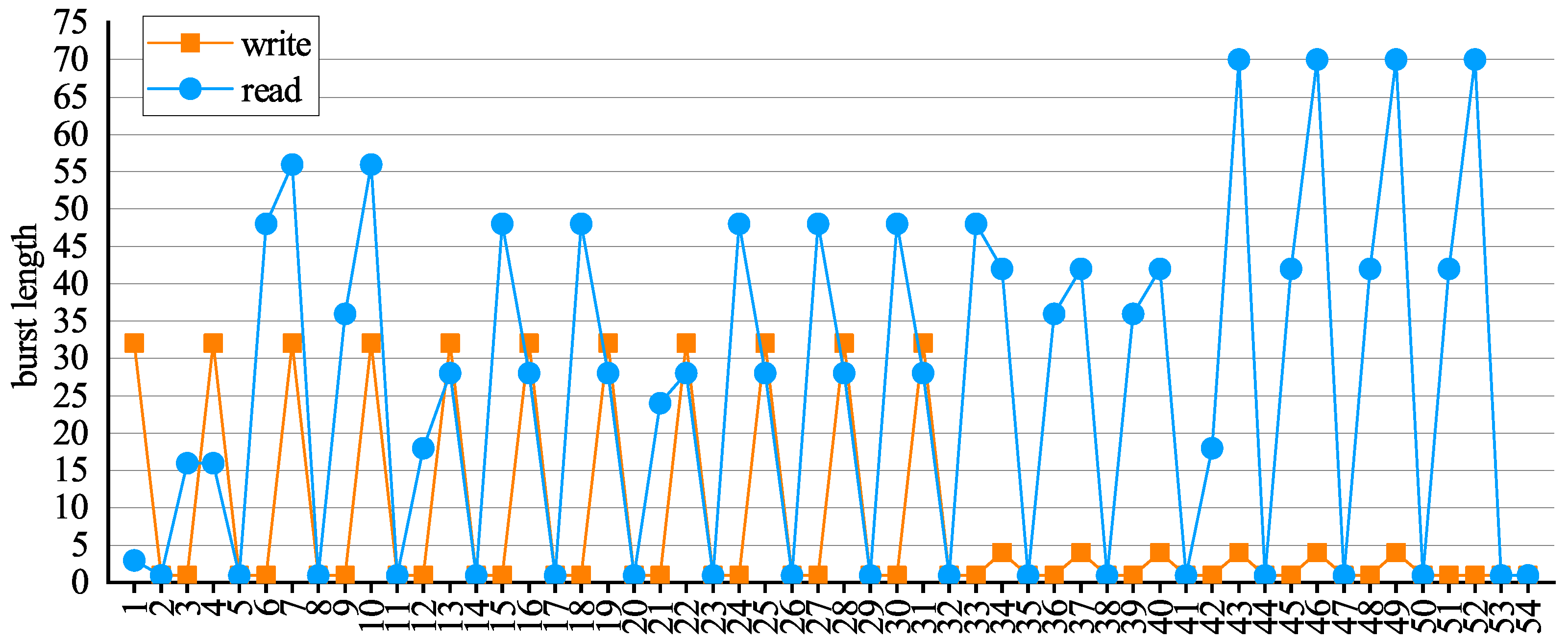
In addition, although the use of the above two convolution orders can effectively reduce on-chip memory, the proposed MAE using a unified architecture requires a large number of off-chip memory accesses [
5], which can negatively impact the overall performance of the accelerator. On the other hand, with the advancement of semiconductor processes and architecture design, the data transfer rate of double data rate SDRAM has reached a considerable level. Sequential reads or writes make efficient use of DDR4 bandwidth, whereas random reads or writes can negatively affect the use of DDR4 bandwidth. We found that the DSC accelerator can only access the DDR4 with a relatively small burst length in most cases because the output order of the feature map of the previous layer is different from the input order of the feature map of the next layer. Therefore, by designing the convolution order to achieve partial fusion between PWC and DWC, the burst length of DDR4 accesses can be improved, which in turn improves the overall performance of the proposed DSC accelerator. Based on the above analysis, we designed an efficient convolution order for DWC and PWC, respectively.
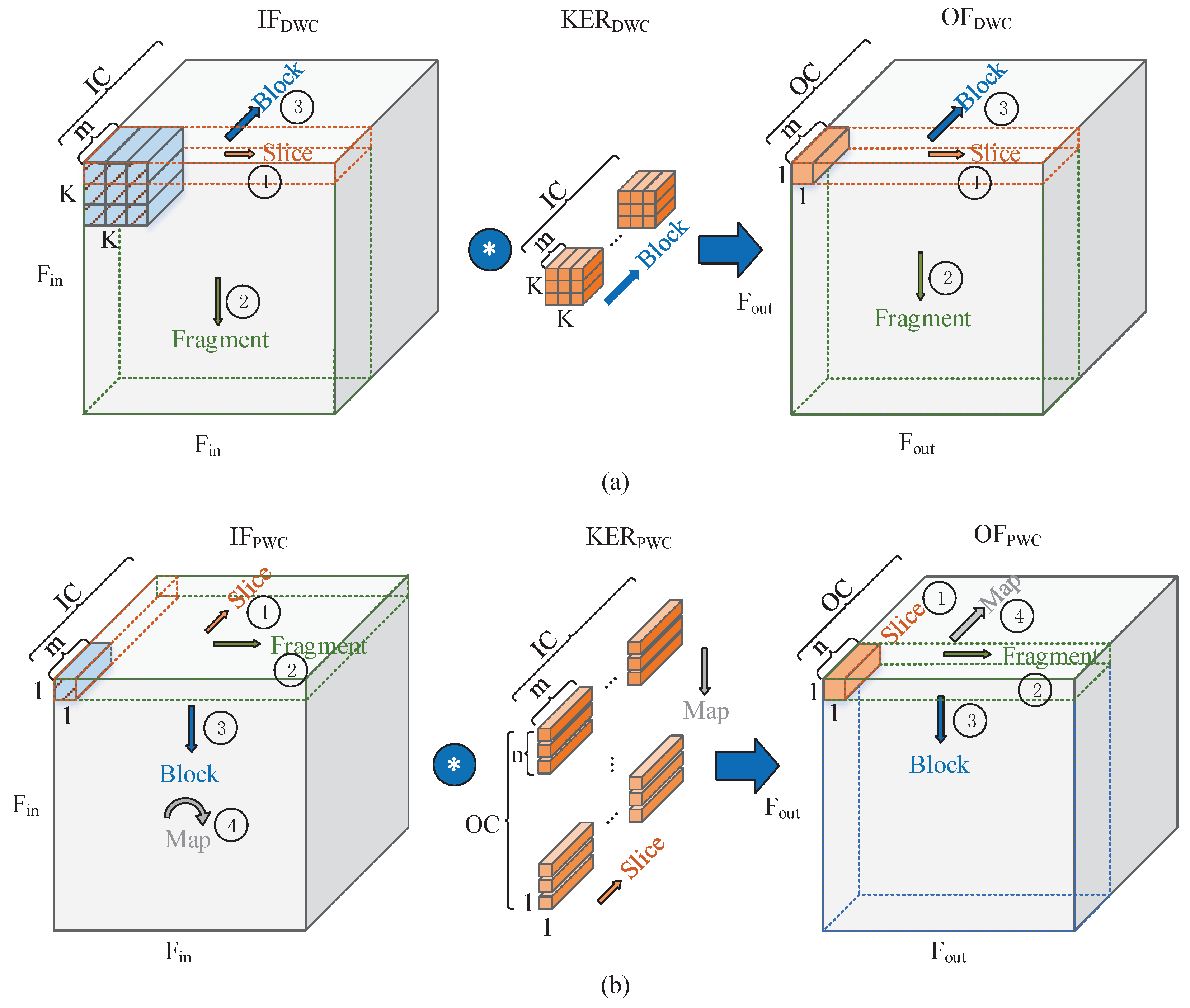
Figure 7 shows the diagram of the two proposed efficient convolution orders, which can achieve partial fusion of PWC and DWC. For presentation purposes, the input feature maps are divided into
,
,
, and
based on the minimum cache and access unit, which is shown in
Figure 4.
uses the order of PUDL for the computation, and the detailed algorithm is shown in Algorithm 1. The input features and weights are stored in the multiplexed buffer block and feature buffer, respectively, as shown in
Figure 2. By default,
m is equal to
n. The
m data in each PU are filled into
n PEs separately, and the calculation starts when each PE is filled with
data. If
is not divisible by
, when
is less than
, zero is filled to make up the inputs, and when
is greater than
, the calculation is split into multiple times.
| Algorithm 1: DWC calculation with PUDL convolution order. |
![Electronics 12 01571 i001]() |
Similarly,
uses the order of PUPL for the calculation, and the Algorithm 2 shows the details.
weights are first stored in the multiplexed buffer block. When the feature buffer is fully filled with
m input features which come from the same PU, the PU is copied
n times to form
weight feature pairs with the preprepared weights, and the weight feature pairs are then filled with
n PEs. The
m data which from the same PU are filled into the same PE, and the inputs are supplemented to
by a similar way as
. When
is greater than
, the calculation is split into multiple times.
| Algorithm 2: PWC calculation with PUPL convolution order. |
![Electronics 12 01571 i002]() |
Moreover, the output order of of is the same as the input order of of . Therefore, the output of can be written to consecutive DDR4 memory cells with a large burst length. This approach reduces the latency of DDR4 accesses and improves the performance of the proposed accelerator.
3.4. Address-Mapping Method
Although the off-chip memory access efficiency is improved by designing the and convolution orders, it is still limited by the reading burst length when switching from the to the layer. In this section, we first analyse the reasons for the constrained read burst length of the layer, and then propose an address-mapping method for the output feature map in off-chip memory to maximize bandwidth utilization when reading the features of layer.
As mentioned earlier, the reason for the low DDR4 access efficiency when switching from to is that the output order of the former is different from the input order of the latter. If the output features are written directly to off-chip memory in the default output order, there are two scenarios when reading the input features required by from external memory.
Input features are read into the accelerator from off-chip memory at large burst lengths from contiguous addresses, where the data is contiguous but must be heavily cached on-chip because the data order does not match the expected input order of the .
Input features are read into the accelerator from discrete external memory cells at a small burst length, where the data order matches the desired computational order of the but the off-chip memory access is inefficient.
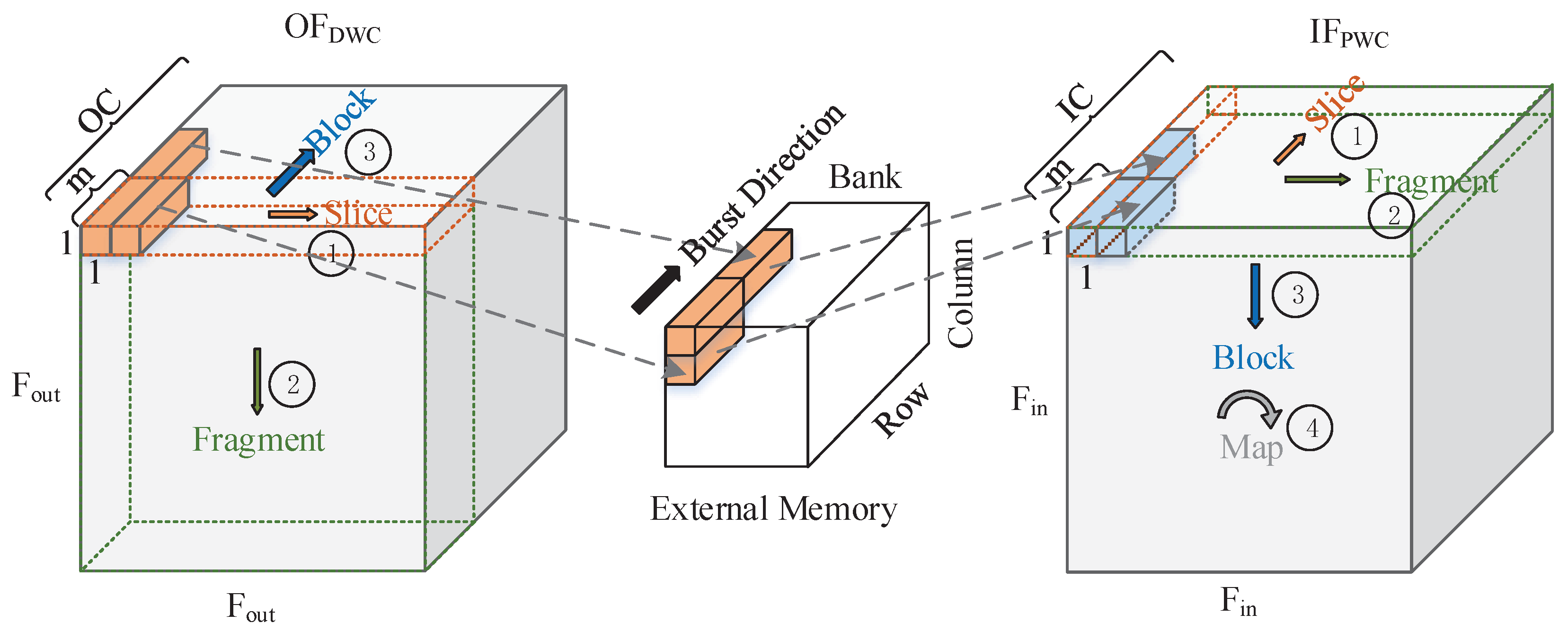
Neither of above two scenarios can achieve a balance between on-chip memory and off-chip memory access efficiency. Considering that when accelerating DSC, the same output feature map is only written to DDR4 once, while the same input feature map needs to be read out of DDR4 one or more times, the bandwidth gain from read optimization of the feature map data is greater than that from write optimization. Therefore, the address mapping method is designed to allow external memory to be read in efficient sequential bursts without requiring large amounts of on-chip memory resources. As shown in
Figure 8, the DWC outputs features in the order of PUDL, while the next layer of PWC reads features in the order of PUPL. Usually, the output features of
are by default stored in continuous external memory cells along the burst direction, while in the proposed method they are stored in discrete cells according to precalculated addresses, while ensuring that the input features of
can be accessed in the expected input order at large burst lengths. Assuming that the minimum cache and access unit still consists of
m data and the counts in the three dimensions of
are
,
and
, the offset address of each
output unit is expressed as
The address-mapping method above describes the relationship between the feature output order and the offset address of each
output unit. At the stage of writing back to off-chip memory, the final address must be calculated based on the stored base address of the current layer, and the final address can be expressed as
where
is the base address of the current layer. The number of off-chip memory addresses occupied by each feature matrix is equal to the total number of units contained in the features of that layer. Therefore, the base address of each layer can be calculated by accumulating layer by layer, and can be quickly obtained by looking up the table.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}