

MFSR: Light Field Images Spatial Super Resolution Model Integrated with Multiple Features

Abstract
:1. Introduction
2. Related Works
3. Methods
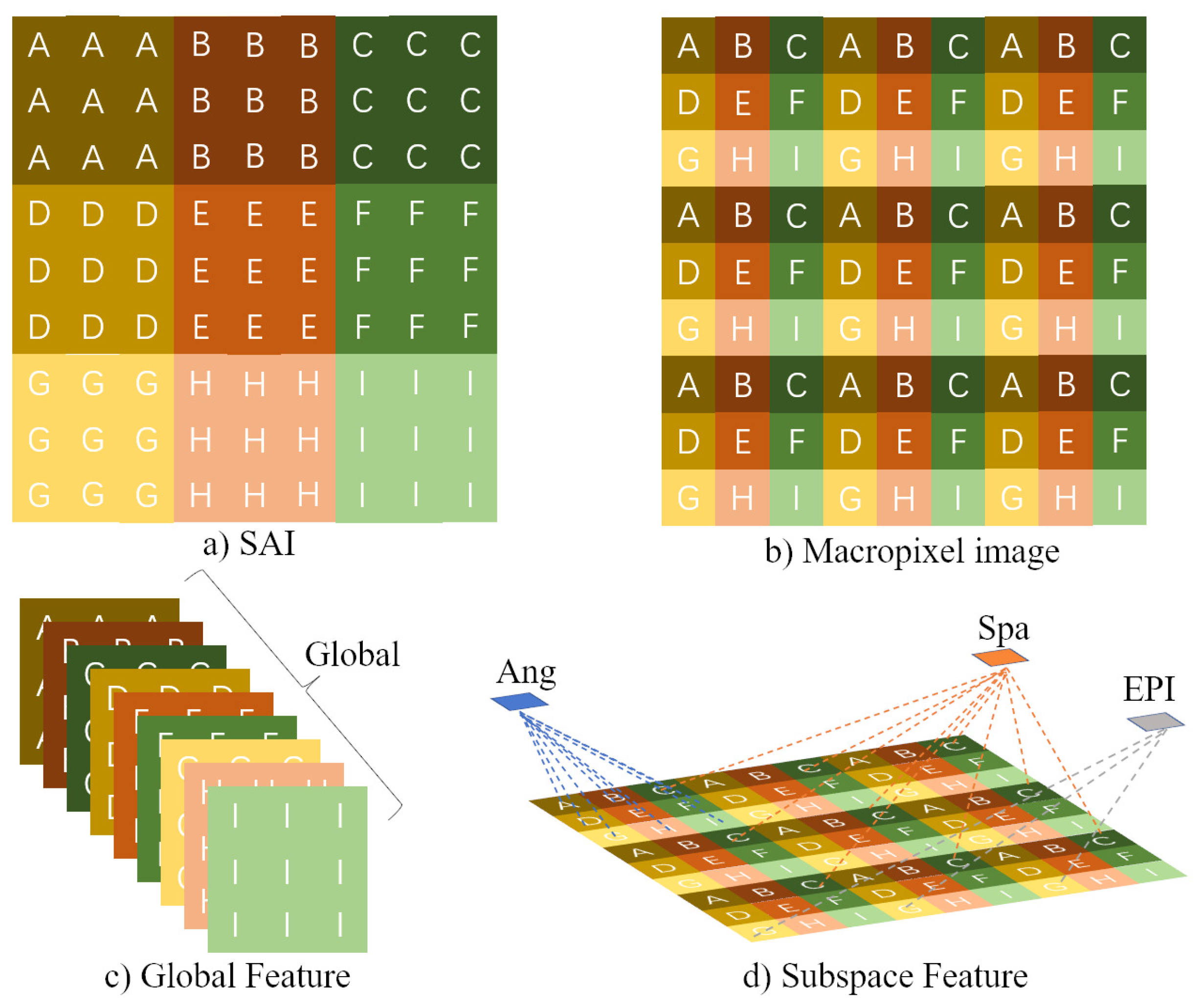
3.1. Light Field Representation
3.2. Network Design
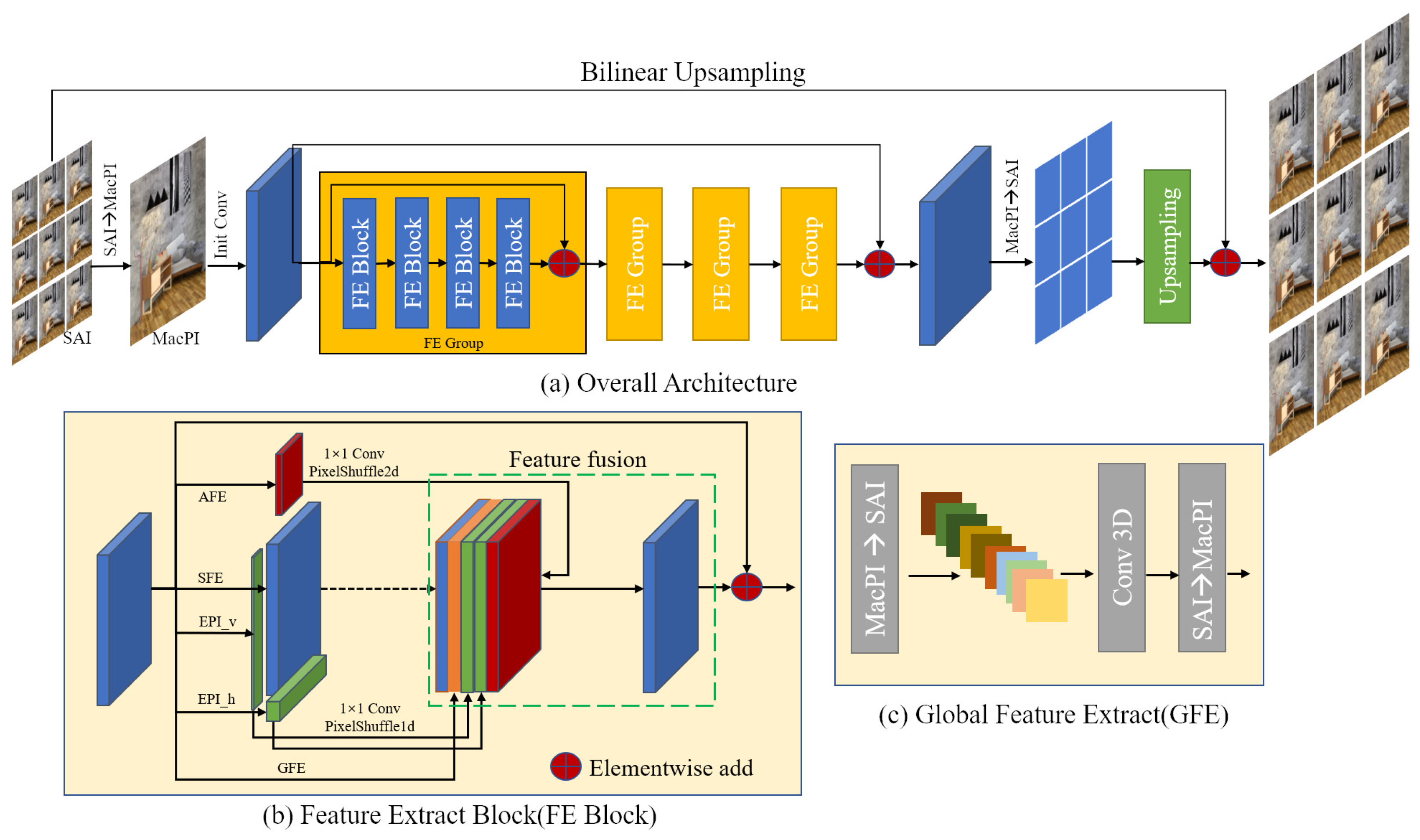
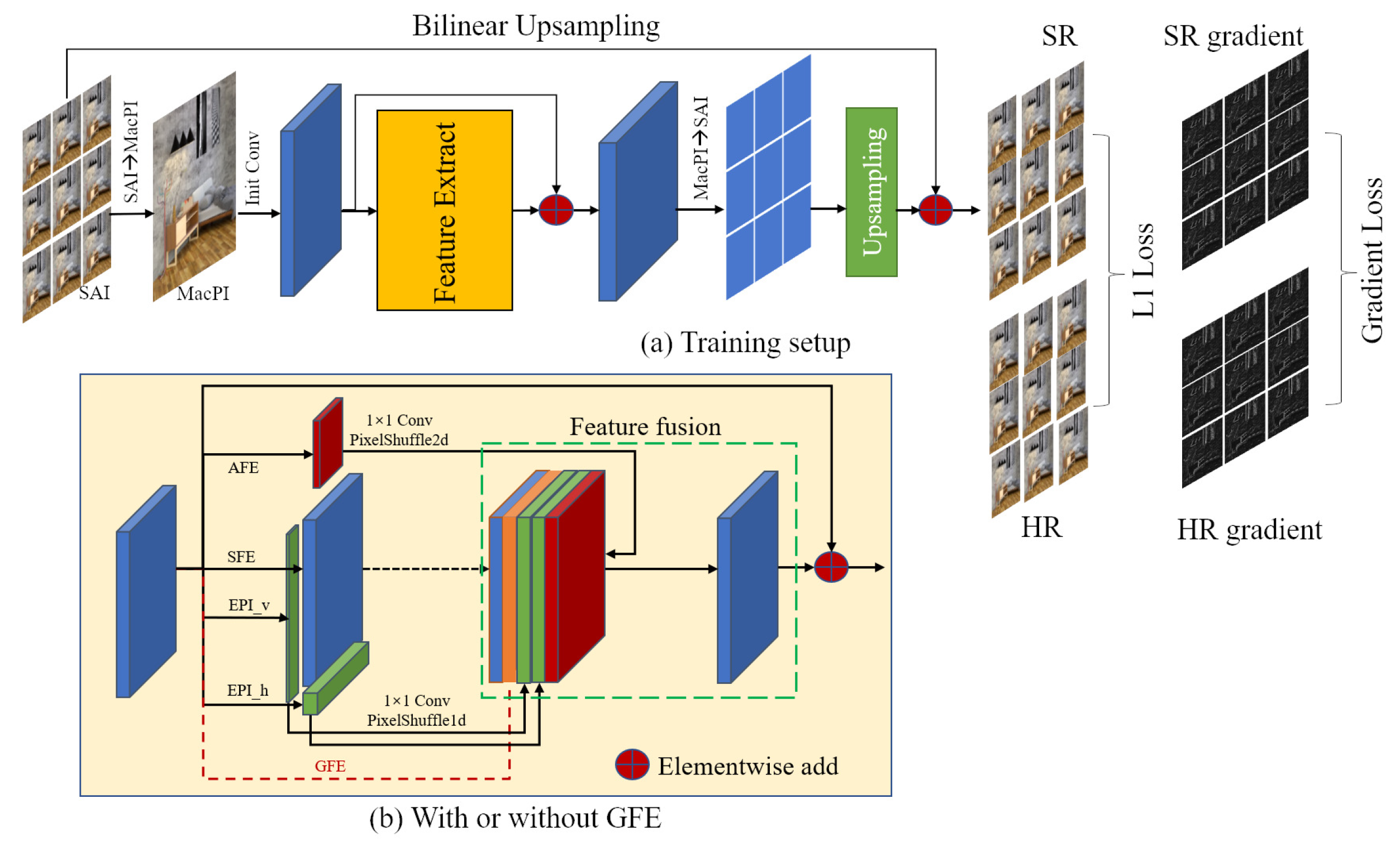
3.2.1. Network Structure
3.2.2. Loss Function
4. Experiments
4.1. Datasets and Implementation Details
4.2. Ablation Study
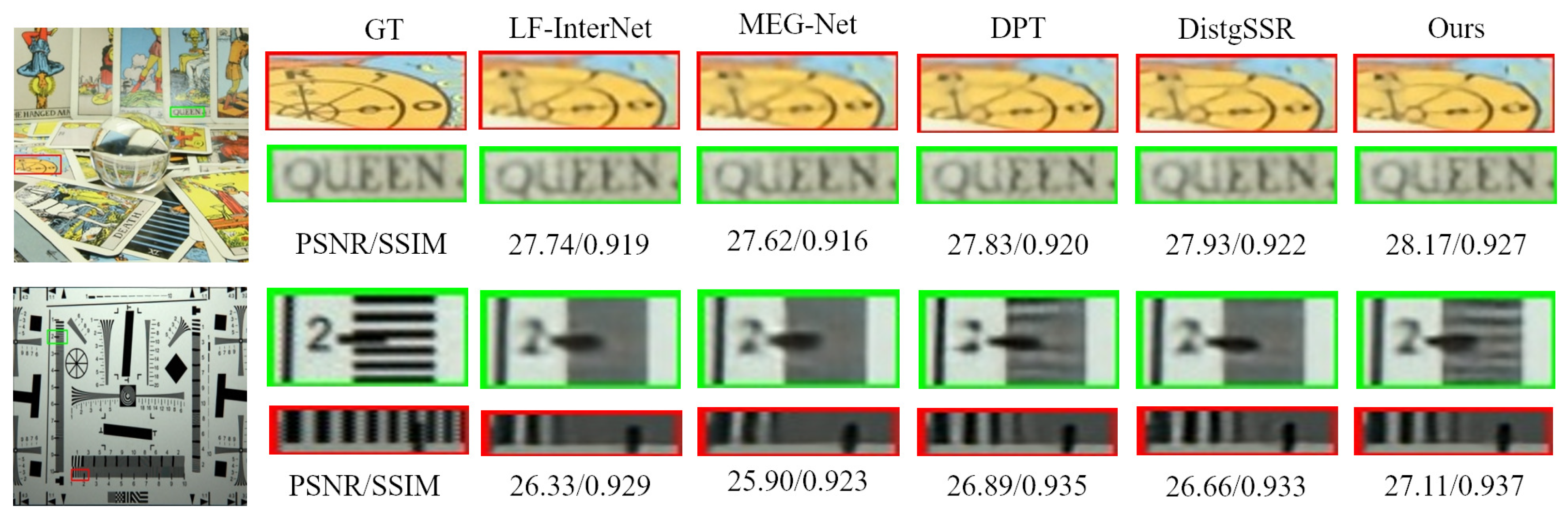
4.3. Experimental Results on the Light Field Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, Y.; Yang, J.; Guo, Y.; Xiao, C.; An, W. Selective light field refocusing for camera arrays using bokeh rendering and superresolution. IEEE Signal Process. Lett. 2018, 26, 204–208. [Google Scholar] [CrossRef]
- Bishop, T.E.; Favaro, P. The light field camera: Extended depth of field, aliasing, and superresolution. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 972–986. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.-C.; Efros, A.A.; Ramamoorthi, R. Depth estimation with occlusion modeling using light-field cameras. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2170–2181. [Google Scholar] [CrossRef] [PubMed]
- Park, I.K.; Lee, K.M. Robust light field depth estimation using occlusion-noise aware data costs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2484–2497. [Google Scholar]
- Zhou, M.; Ding, Y.; Ji, Y.; Young, S.S.; Yu, J.; Ye, J. Shape and reflectance reconstruction using concentric multi-spectral light field. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1594–1605. [Google Scholar] [CrossRef] [PubMed]
- Alperovich, A.; Johannsen, O.; Strecke, M.; Goldluecke, B. Light field intrinsics with a deep encoder-decoder network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9145–9154. [Google Scholar]
- Wang, Y.; Wu, T.; Yang, J.; Wang, L.; An, W.; Guo, Y. Deoccnet: Learning to see through foreground occlusions in light fields. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 118–127. [Google Scholar]
- Li, Y.; Yang, W.; Xu, Z.; Chen, Z.; Shi, Z.; Zhang, Y.; Huang, L. Mask4d: 4d convolution network for light field occlusion removal. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2480–2484. [Google Scholar]
- Zhang, S.; Chang, S.; Lin, Y. End-to-end light field spatial super-resolution network using multiple epipolar geometry. IEEE Trans. Image Process. 2021, 30, 5956–5968. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Lin, Y.; Sheng, H. Residual networks for light field image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11046–11055. [Google Scholar]
- Wang, Y.; Wang, L.; Wu, G.; Yang, J.; An, W.; Yu, J.; Guo, Y. Disentangling light fields for super-resolution and disparity estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 425–443. [Google Scholar] [CrossRef] [PubMed]
- Jiang, L.; Dai, B.; Wu, W.; Loy, C.C. Focal frequency loss for image reconstruction and synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 13919–13929. [Google Scholar]
- Wang, S.; Zhou, T.; Lu, Y.; Di, H. Detail-preserving transformer for light field image super-resolution. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; pp. 2522–2530. [Google Scholar]
- Kittler, J. On the accuracy of the sobel edge detector. Image Vis. Comput. 1983, 1, 37–42. [Google Scholar] [CrossRef]
- Honauer, K.; Johannsen, O.; Kondermann, D.; Goldluecke, B. A dataset and evaluation methodology for depth estimation on 4d light fields. In Proceedings of the Computer Vision–ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Berlin/Heidelberg, Germany, 2017; pp. 19–34. [Google Scholar]
- Rerabek, M.; Ebrahimi, T. New light field image dataset. In Proceedings of the 8th International Conference on Quality of Multimedia Experience (QoMEX), Lisbon, Portugal, 6–8 June 2016. [Google Scholar]
- Liang, C.-K.; Ramamoorthi, R. A light transport framework for lenslet light field cameras. ACM Trans. Graph. (TOG) 2015, 34, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Alain, M.; Smolic, A. Light field super-resolution via lfbm5d sparse coding. In Proceedings of the 2018 25th IEEE international conference on image processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2501–2505. [Google Scholar]
- Wanner, S.; Goldluecke, B. Variational light field analysis for disparity estimation and super-resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 606–619. [Google Scholar]
- Mitra, K.; Veeraraghavan, A. Light field denoising, light field superresolution and stereo camera based refocussing using a gmm light field patch prior. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Washington, DC, USA, 16–21 June 2012; pp. 22–28. [Google Scholar]
- Bishop, T.E.; Zanetti, S.; Favaro, P. Light field superresolution. In Proceedings of the 2009 IEEE International Conference on Computational Photography (ICCP), San Francisco, CA, USA, 16–17 April 2009; pp. 1–9. [Google Scholar]
- Cho, D.; Lee, M.; Kim, S.; Tai, Y.W. Modeling the calibration pipeline of the lytro camera for high quality light-field image reconstruction. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3280–3287. [Google Scholar]
- Rossi, M.; Frossard, P. Geometry-consistent light field super-resolution via graph-based regularization. IEEE Trans. Image Process. 2018, 27, 4207–4218. [Google Scholar]
- Farrugia, R.A.; Galea, C.; Guillemot, C. Super resolution of light field images using linear subspace projection of patch-volumes. IEEE J. Sel. Top. Signal Process. 2017, 11, 1058–1071. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 184–199. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 1646–1654. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Yoon, Y.; Jeon, H.G.; Yoo, D.; Lee, J.Y.; So Kweon, I. Learning a deep convolutional network for light-field image super-resolution. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 24–32. [Google Scholar]
- Jin, J.; Hou, J.; Chen, J.; Kwong, S. Light field spatial super-resolution via deep combinatorial geometry embedding and structural consistency regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2260–2269. [Google Scholar]
- Wang, Y.; Wang, L.; Yang, J.; An, W.; Yu, J.; Guo, Y. Spatial-angular interaction for light field image super-resolution. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 290–308. [Google Scholar]
- Wang, Y.; Yang, J.; Wang, L.; Ying, X.; Wu, T.; An, W.; Guo, Y. Light field image super-resolution using deformable convolution. IEEE Trans. Image Process. 2020, 30, 1057–1071. [Google Scholar]
- Youssef, A. Image downsampling and upsampling methods. Natl. Inst. Stand. Technol. 1999, 10, 57–61. [Google Scholar]
- Niklaus, S.; Mai, L.; Liu, F. Video frame interpolation via adaptive separable convolution. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 261–270. [Google Scholar]
- Wanner, S.; Meister, S.; Goldluecke, B. Datasets and benchmarks for densely sampled 4d light fields. In Proceedings of the VMV, Bayreuth, Germany, 10–12 October 2013; pp. 225–226. [Google Scholar]
- Le Pendu, M.; Jiang, X.; Guillemot, C. Light field inpainting propagation via low rank matrix completion. IEEE Trans. Image Process. 2018, 27, 1981–1993. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vaish, V.; Adams, A. The (new) stanford light field archive. In Computer Graphics Laboratory; Stanford University: Stanford, CA, USA, 2008; Volume 6, p. 7. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | HCI_NEW | Stanford_Gantry | EPFL | INRIA_Lytro | HCI_OLD | Total |
|---|---|---|---|---|---|---|
| Train | 20 | 9 | 70 | 35 | 10 | 144 |
| Test | 4 | 2 | 10 | 5 | 2 | 23 |
| Global Feature | HCI_new | Stanford_Gantry | EPFL | INRIA_Lytro | HCI_old | Average |
|---|---|---|---|---|---|---|
| w | 31.11 | 30.891 | 28.711 | 30.836 | 37.198 | 31.749 |
| w/o | 31.239 | 31.223 | 28.943 | 30.959 | 37.48 | 31.968 |
| Gradient Loss | HCI_NEW | Stanford_Gantry | EPFL | INRIA_Lytro | HCI_OLD | Average |
|---|---|---|---|---|---|---|
| w | 31.239 | 31.223 | 28.943 | 30.959 | 37.48 | 31.968 |
| w/o | 31.278 | 31.338 | 28.92 | 30.966 | 37.388 | 31.978 |
| Methods | Scale | HCI_new | Stanford_Granty | EPFL | INRIA_Lytro | HCI_old |
|---|---|---|---|---|---|---|
| Bicubic | ×2 | 31.887/0.9356 | 31.063/0.9498 | 29.740/0.9376 | 31.331/0.9577 | 37.686/0.9785 |
| EDSR [28] | ×2 | 34.828/0.9592 | 36.296/0.9818 | 33.089/0.9629 | 34.985/0.9764 | 41.014/0.9874 |
| RCAN [29] | ×2 | 35.022/0.9603 | 36.670/0.9831 | 33.159/0.9634 | 35.046/0.9769 | 41.125/0.9875 |
| resLF [10] | ×2 | 36.685/0.9739 | 38.354/0.9904 | 33.617/0.9706 | 35.395/0.9804 | 43.422/0.9932 |
| LF-ATO [31] | ×2 | 37.244/0.9767 | 39.636/0.9929 | 34.272/0.9757 | 36.170/0.9842 | 44.205/0.9942 |
| LF_InterNet [32] | ×2 | 37.319/0.9772 | 38.838/0.9917 | 34.298/0.9762 | 36.108/0.9847 | 44.534/0.9945 |
| LF-DFnet [33] | ×2 | 37.418/0.9773 | 39.427/0.9926 | 34.513/0.9755 | 36.416/0.9840 | 44.198/0.9941 |
| MEG-Net [9] | ×2 | 37.424/0.9777 | 38.767/0.9915 | 34.312/0.9773 | 36.103/0.9849 | 44.097/0.9942 |
| DPT [13] | ×2 | 37.355/0.9771 | 39.429/0.9926 | 34.490/0.9758 | 36.409/0.9843 | 44.302/0.9943 |
| DistgSSR [11] | ×2 | 37.838/0.9791 | 40.341/0.9940 | 34.306/0.9773 | 36.247/0.9853 | 44.826/0.9948 |
| MFSR | ×2 | 37.964/0.9943 | 40.560/0.9943 | 34.859/0.9791 | 36.518/0.9861 | 44.699/0.9947 |
| Bicubic | ×4 | 27.715/0.8517 | 26.087/0.8452 | 25.264/0.8324 | 26.952/0.8867 | 32.576/0.9344 |
| EDSR [28] | ×4 | 29.591/0.8869 | 28.703/0.9072 | 27.833/0.8854 | 29.656/0.9257 | 35.176/0.9536 |
| RCAN [29] | ×4 | 29.694/0.8886 | 29.021/0.9131 | 27.907/0.8863 | 29.805/0.9276 | 35.359/0.9548 |
| resLF [10] | ×4 | 30.723/0.9107 | 30.191/0.9372 | 28.260/0.9035 | 30.338/0.9412 | 36.705/0.9682 |
| LF-ATO [31] | ×4 | 30.880/0.9135 | 30.607/0.9430 | 28.514/0.9115 | 30.711/0.9484 | 36.999/0.9699 |
| LF_InterNet [32] | ×4 | 30.998/0.9166 | 30.537/0.9432 | 28.737/0.9143 | 30.701/0.9485 | 37.101/0.9714 |
| LF-DFnet [33] | ×4 | 31.136/0.9177 | 31.035/0.9481 | 28.685/0.9141 | 30.770/0.9497 | 37.175/0.9711 |
| MEG-Net [9] | ×4 | 30.882/0.9146 | 30.437/0.9415 | 28.538/0.9107 | 30.542/0.9463 | 36.861/0.9696 |
| DPT [13] | ×4 | 31.028/0.9161 | 30.770/0.9451 | 28.604/0.9142 | 30.681/0.9486 | 37.098/0.9706 |
| DistgSSR [11] | ×4 | 31.110/0.9175 | 30.891/0.9466 | 28.711/0.9149 | 30.836/0.9492 | 37.198/0.9715 |
| MFSR | ×4 | 31.327/0.9207 | 31.262/0.9506 | 28.985/0.9183 | 31.024/0.9515 | 37.519/0.9729 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, J.; Wang, H. MFSR: Light Field Images Spatial Super Resolution Model Integrated with Multiple Features. Electronics 2023, 12, 1480. https://doi.org/10.3390/electronics12061480
Zhou J, Wang H. MFSR: Light Field Images Spatial Super Resolution Model Integrated with Multiple Features. Electronics. 2023; 12(6):1480. https://doi.org/10.3390/electronics12061480
Chicago/Turabian StyleZhou, Jianfei, and Hongbing Wang. 2023. "MFSR: Light Field Images Spatial Super Resolution Model Integrated with Multiple Features" Electronics 12, no. 6: 1480. https://doi.org/10.3390/electronics12061480