
Intelligent Approaches to Fault Detection and Diagnosis in District Heating: Current Trends, Challenges, and Opportunities
 , , , , and
, , , , and
Abstract
:1. Introduction
- We provide a comprehensive overview of state-of-the-art intelligent FDD in DH.
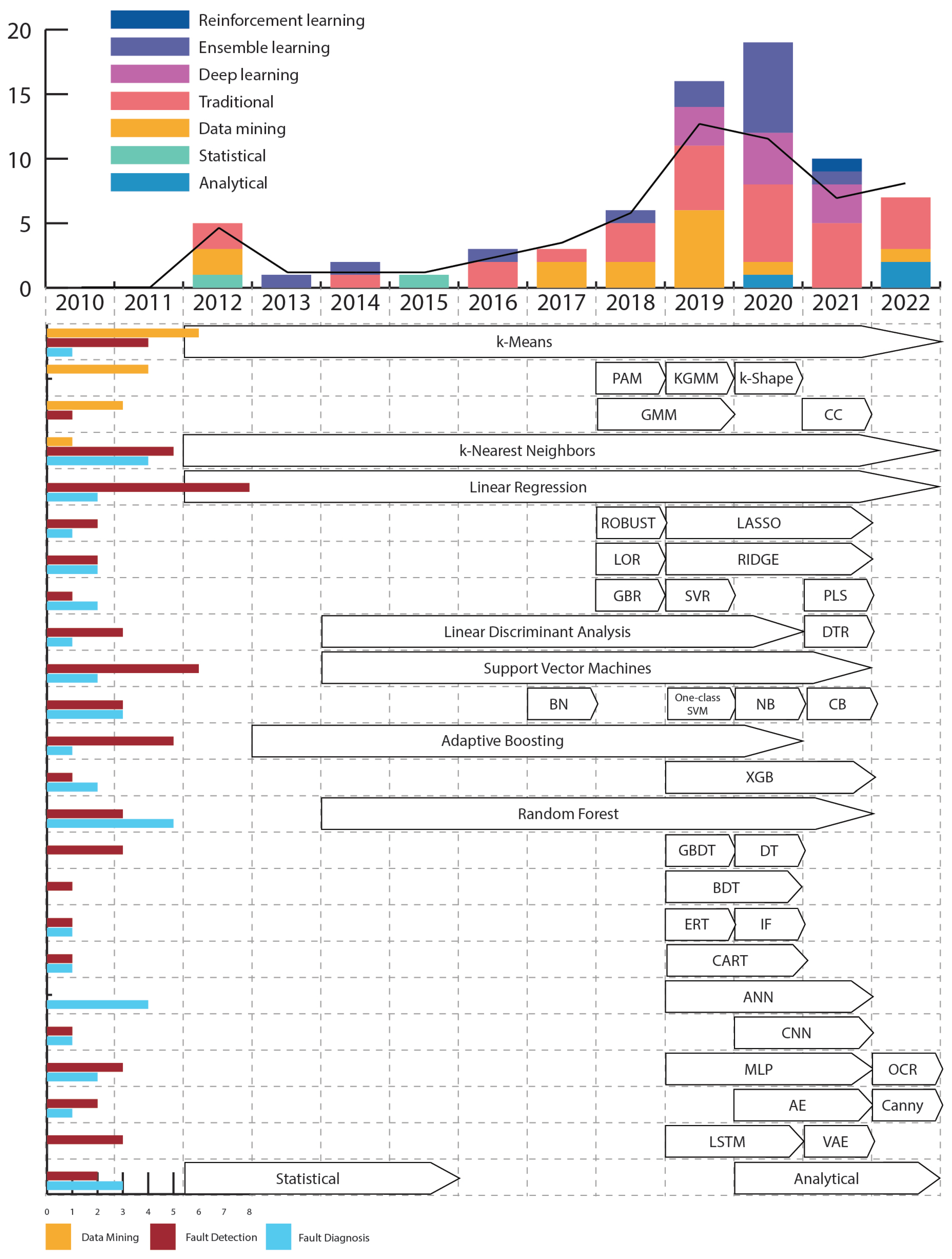
- We provide an elaborated overview in research papers based on fault detection, fault diagnosis or data mining, as well as current trends, as depicted in Figure 1.
- We provide an in-depth Strengths,Weaknesses, Opportunities, and Threats (SWOT) analysis to identify industry challenges, research gaps, and opportunities.
- We provide a clear list of research directions in the form of recommendations, and explain several advantages and disadvantages.
2. Background
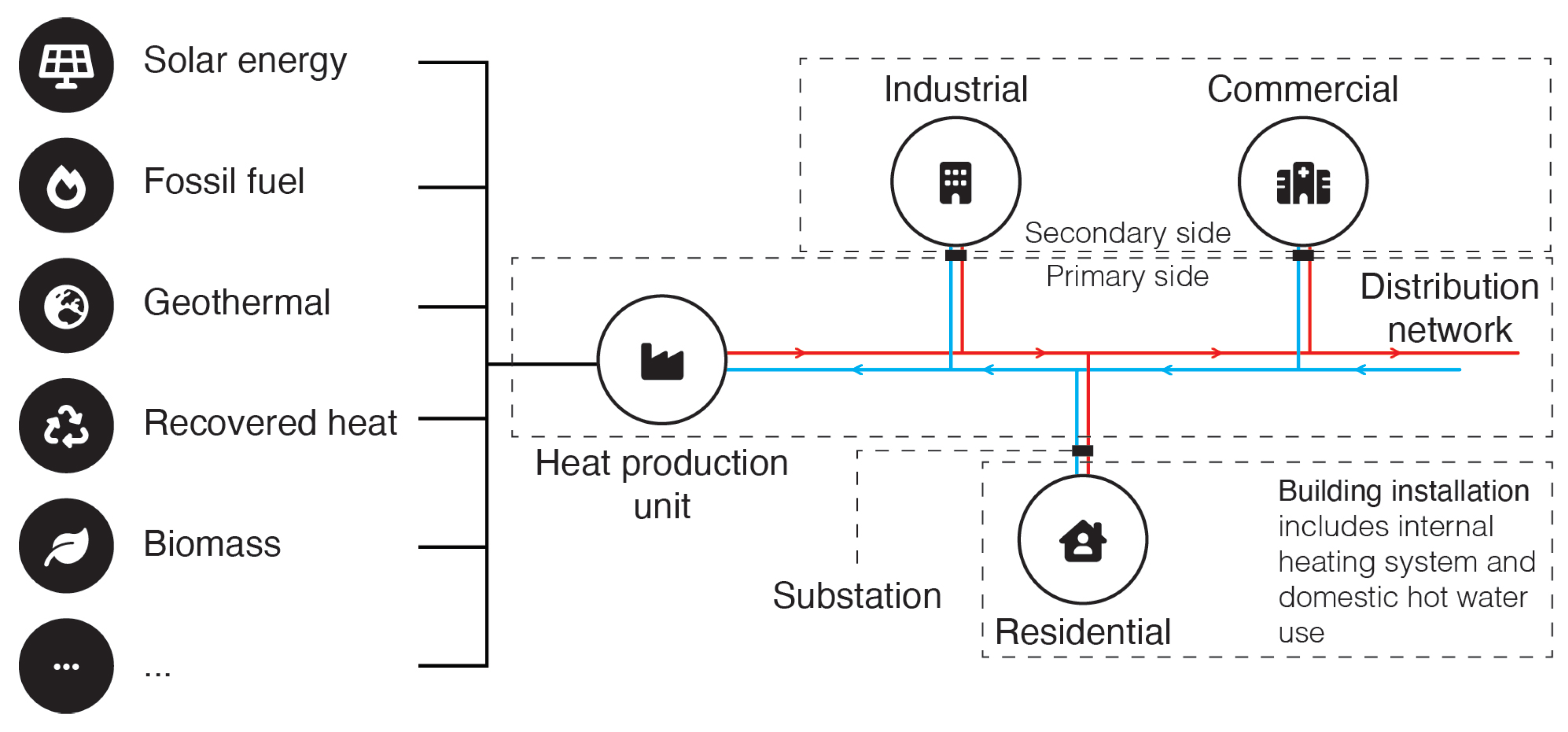
2.1. District Heating
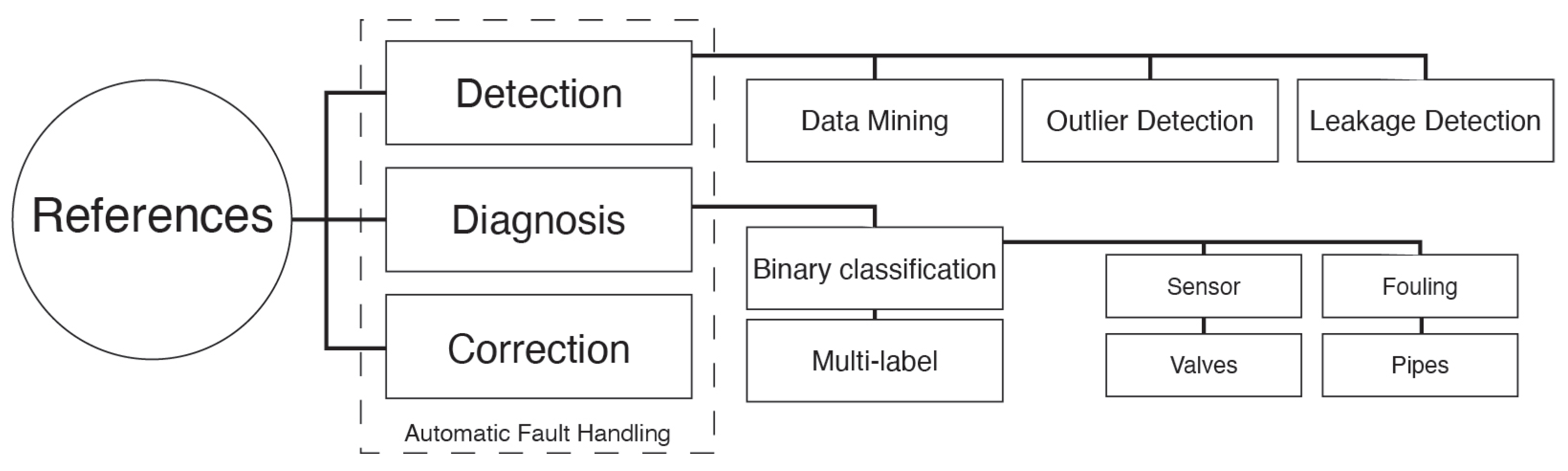
2.2. Automatic Fault Handling
2.3. Machine Learning
- (i)
- Supervised learning [11] (predictive) is concerned with learning mappings between inputs and outputs y given a labeled data set of input-output pairs, i.e., the output is a label that represents the class type of the inputs . Supervised learning can be divided into two types: classification and regression. Classification refers to classifying with discrete values as output, e.g., industrial or residential, i.e., classification attempts to predict class membership (assign a label). If the labels are numerical in a continuous range, it is called regression, i.e., regression attempts to predict numerical values, e.g., energy demand in the next 24 h. The algorithms fit a model to the labeled data set and can classify or predict new unseen data based on the independent variables as input. Some techniques in supervised learning include Linear Regression (LR), Support Vector Machines (SVM), Naive Bayes (NB), or Random Forests (RF).
- (ii)
- Unsupervised learning [10] (descriptive) is the technique of discovering underlying structures in data. Unsupervised learning can help identify essential (statistical) characteristics and patterns within the data without human intervention. It is a crucial paradigm in DMKD. Unsupervised learning is ideal for explanatory data analysis, outlier detection, and image or pattern recognition. Consequently, unsupervised learning can also be used for data pre-processing, e.g., dimensional reduction techniques such as Principle Component Analysis (PCA). Some techniques in unsupervised learning include k-Means (kM), Gaussian Mixture Model (GMM), or Linear Discriminant Analysis (LDA).
- (iii)
- Reinforcement learning [12] is the technique where an agent learns in a particular environment through exploration and exploitation. The agent performs specific actions that lead to a reward or punishment, aiming to maximize the reward. An agent should perform actions known to produce a high reward; however, the agent has to learn such actions by trial and error. That is, the algorithm rewards the agent for reinforcing the preferred behavior. The model continues to learn until it converges or achieves its stopping criteria. A well-known technique in reinforcement learning is Q-learning, which has a broad set of application areas such as self-driving or gaming AI.
- (iv)
- Deep learning [13] applies to any of the paradigms mentioned above in case one or more of the employed regressors or classifiers is a Deep Neural Network (DNN). Deep refers to using a neural network consisting of three or more layers. DNN can handle unstructured data sets, such as texts or images. Recently, deep learning has made a significant impact in text and image generation[14,15]. Also, DNN can automate feature extraction, such as Convolutional Neural Network (CNN), which reduces the need for human interventions; a side effect is that reasoning about model behavior becomes significantly more complicated, as the models are incredibly complex (black box models). However, an upcoming field, called explainable AI, tries to mitigate this problem. Explainable AI refers to the ability of complex models, such as in deep learning, to explain their reasoning or decision-making process such that it can be understood by humans, i.e., it can provide a transparent and understandable explanation for how a model arrived at its output or recommendation. A brief overview is given in [16]. Some techniques in deep learning include Multilayer Perceptron (MLP), CNN, or Long short-Term Memory (LSTM).
- (v)
- Semi-supervised learning [17], as the name indicates, provides hybrid solutions combining supervised and unsupervised learning techniques. It can use smaller labeled data sets to classify or extract patterns from larger unlabeled data sets. Compared to a traditional classifier, semi-supervised learning can reduce the size of the original labeled data set by 66%, at the cost of five times as many unlabeled data [18]. Semi-supervised learning is beneficial in scenarios where unlabeled data is abundant, but labeled data is expensive—typical in most engineering scenarios. Compared to the preceding paradigms, semi-supervised learning is less explored. Some techniques include MixMatch [19], label propagation [20], or self-training [21].
- (vi)
- Transfer learning [22] is a technique where a model trained for one task (source domain) is reused, e.g., as a starting point, in a second but related task (target domain). Unlike semi-supervised learning, where the model exploits the abundance of unlabeled data, transfer learning exploits the models available in similar domains. A subcategory of transfer learning is domain adaptation [23], which mainly focuses on using labeled data in one or more similar domains—assuming the domains shares class labels. It is similar to supervised learning, where the goal is to find a mapping based on training data, and the model predicts test data assumed to be from the same data distribution as the training data. In domain adaption, the training data comes from a particular domain with a large set of labeled data. The model can predict in another similar domain under the same assumptions as supervised learning—test data is from the same distribution as the training data. Transfer learning and domain adaption can be helpful in DH as it reduces the need for labeled data, which is currently scarce in DH.
3. Related Work
4. Method
5. District Heating Data Collection
6. Current Intelligent Techniques for FDD
6.1. Fault Detection
6.1.1. Data Mining and Knowledge Discovery
6.1.2. Outlier Detection
6.1.3. Leakage Detection
6.2. Fault Diagnosis
6.2.1. Sensor Failure
6.2.2. Fouling
6.2.3. Valves
6.2.4. Pipes
6.2.5. Multi-Label Classification
7. Discussion
7.1. Strengths
7.2. Threats
7.3. Weaknesses
7.4. Opportunities
8. Conclusions
- Transfer learning.
- Domain adaption.
- Semi-supervised learning.
- Hybrid models.
- Data-centric approaches.
- Improving (labeled) data quality.
- Quantifying district heating definitions.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DH | District Heating |
| CHP | Combined Heat and Power |
| DHW | Domestic Hot Water system |
| FDD | Fault Detection and Diagnosis |
| 4GDH | 4th generation district heating |
| 5GDH | 5th generation district heating |
| DMKD | Data Mining and Knowledge Discovery |
| AI | Artificial Intelligence |
| ML | Machine Learning |
| HOM | Higher Order Mining |
| EDA | Exploratory Data Analysis |
| GMM | Gaussian Mixture Model |
| KGMM | Kernel Gaussian Mixture Model |
| SVM | Support Vector Machines |
| kNN | k-Nearest Neighbor |
| kM | k-Means |
| kS | k-Shape |
| PAM | Partitioning Around Medoids |
| MIA | Mean Index Adequacy |
| CDI | Cluster Dispersion Indicator |
| SI | Silhouette Index |
| DBI | Davies-Bouldin Index |
| BIC | Bayesian Information Criterion |
| PCC | Pearson Correlation Coefficient |
| CC | Conformal Clustering |
| MST | Minimum Spanning Tree |
| TPOT | Tree-based Pipeline Optimization Tool |
| AHC | Agglomerative Hierarchical Clustering |
| LSTM | Long short-Term Memory |
| ANN | Artificial Neural Network |
| CNN | Convolutional Neural Network |
| DNN | Deep Neural Network |
| GAN | Generative Adviserial Networks |
| MLP | Multilayer Perceptron |
| GBDT | Gradient Boosted Decision Tree |
| BDT | Binary Decision Tree |
| DT | Decision Tree |
| DTR | Decision Tree Regression |
| CB | Contextual Bandit |
| NB | Naive Bayes |
| RUSBT | RUS Boosted Trees |
| XGBoost | Extreme Gradient Boosting |
| RF | Random Forests |
| IF | Isolation Forests |
| AB | Adaptive Boosting |
| ERT | Extremely Random Tree |
| LDA | Linear Discriminant Analysis |
| PCA | Principle Component Analysis |
| BN | Bayesian Network |
| ARIMA | Auto Regressive Integrated Moving Average |
| LinUCB | Linear Upper Confidence Bound |
| CART | Classification and Regression Tree |
| AE | Auto Encoder |
| VAE | Variational Auto Encoder |
| LR | Linear Regression |
| RR | Robust Regression |
| LOR | Logistic Regression |
| RFR | Random Forest Regression |
| AR | auto Regression |
| LASSO | Lasso Regression |
| RIDGE | Ridge Regression |
| GBR | Gradient Boosting Regression |
| PLS | Partial Least Squares Regression |
| SVR | Support Vector Regression |
| OLS | Ordinary Least Squares |
| COC | Continuous Operation Control |
| NSB | Night Setback Control |
| TCO5 | Time Clock Operation (during five workdays) |
| TCO7 | Time Clock Operation (during seven workdays) |
| HVAC | heating, ventilation, and air conditioning |
| OCR | Optical Character Recognition |
| SC | Saliency computation |
| SHAP | Shapely Additive Explanations |
| EM | Expectation Maximization |
References
- United Nations. Growing World Population. Available online: https://www.un.org/en/global-issues/population (accessed on 2 August 2022).
- United Nations. Urbanization. Available online: https://www.un.org/development/desa/en/news/population/2018-revision-of-world-urbanization-prospects.html (accessed on 2 August 2022).
- Ferrari, L.; Morgione, S.; Rutz, D.; Mergner, R.; Doračić, B.; Hummelshøj, R.M.; Grimm, S.; Kazagic, A.; Merzic, A.; Krasatsenka, A.; et al. A comprehensive framework for District Energy systems upgrade. Energy Rep. 2021, 7, 359–367. [Google Scholar] [CrossRef]
- European Commission. 2050 Long-Term Strategy. Available online: https://ec.europa.eu/clima/eu-action/climate-strategies-targets/2050-long-term-strategy_en (accessed on 9 January 2022).
- Månsson, S.; Davidsson, K.; Lauenburg, P.; Thern, M. Automated statistical methods for fault detection in district heating customer installations. Energies 2018, 12, 113. [Google Scholar] [CrossRef] [Green Version]
- Gadd, H.; Werner, S. Fault detection in district heating substations. Appl. Energy 2015, 157, 51–59. [Google Scholar] [CrossRef] [Green Version]
- ∅stergaard, D.S.; Smith, K.M.; Tunzi, M.; Svendsen, S. Low-temperature operation of heating systems to enable 4th generation district heating: A review. Energy 2022, 248, 123529. [Google Scholar] [CrossRef]
- International Energy Agency (IEA). District Heating. Available online: https://www.iea.org/reports/district-heating (accessed on 20 January 2023).
- Sorknæs, P.; ∅stergaard, P.A.; Thellufsen, J.Z.; Lund, H.; Nielsen, S.; Djørup, S.; Sperling, K. The benefits of 4th generation district heating in a 100% renewable energy system. Energy 2020, 213, 119030. [Google Scholar] [CrossRef]
- Flach, P. Machine Learning: The Art and Science of Algorithms That Make Sense of Data; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- McClarren, R.G. Machine Learning for Engineers; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT press: Cambridge, MA, USA, 2018. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: London, UK, 2016. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Nakano, R.; Hilton, J.; Balaji, S.; Wu, J.; Ouyang, L.; Kim, C.; Hesse, C.; Jain, S.; Kosaraju, V.; Saunders, W.; et al. WebGPT: Browser-assisted question-answering with human feedback. arXiv 2021, arXiv:2112.09332. [Google Scholar]
- Holzinger, A.; Saranti, A.; Molnar, C.; Biecek, P.; Samek, W. Explainable AI methods-a brief overview. In Proceedings of the xxAI-Beyond Explainable AI: International Workshop on Extending Explainable AI Beyond Deep Models and Classifiers, Vienna, Austria, 18 July 2020; Revised and Extended Papers; Springer: Berlin/Heidelberg, Germany, 2022; pp. 13–38. [Google Scholar]
- Chapelle, O.; Scholkopf, B.; Zien, A. Semi-Supervised Learning; The MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Morgan Kaufmann: Burlington, MA, USA, 2011. [Google Scholar]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C. MixMatch: A Holistic Approach to Semi-Supervised Learning. arXiv 2019, arXiv:1905.02249. [Google Scholar]
- Iscen, A.; Tolias, G.; Avrithis, Y.; Chum, O. Label Propagation for Deep Semi-supervised Learning. arXiv 2019, arXiv:1904.04717. [Google Scholar]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-training with Noisy Student improves ImageNet classification. arXiv 2019, arXiv:1911.04252. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. (CSUR) 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, T.; Zhang, X.; Zhang, C. Artificial intelligence-based fault detection and diagnosis methods for building energy systems: Advantages, challenges and the future. Renew. Sustain. Energy Rev. 2019, 109, 85–101. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, C.; Zhang, Y.; Wang, Z.; Li, J. A review of data mining technologies in building energy systems: Load prediction, pattern identification, fault detection and diagnosis. Energy Built Environ. 2020, 1, 149–164. [Google Scholar] [CrossRef]
- Mbiydzenyuy, G.; Nowaczyk, S.; Knutsson, H.; Vanhoudt, D.; Brage, J.; Calikus, E. Opportunities for machine learning in district heating. Appl. Sci. 2021, 11, 6112. [Google Scholar] [CrossRef]
- Buffa, S.; Fouladfar, M.H.; Franchini, G.; Lozano Gabarre, I.; Andrés Chicote, M. Advanced control and fault detection strategies for district heating and cooling systems—A review. Appl. Sci. 2021, 11, 455. [Google Scholar] [CrossRef]
- Zhou, S.; O’Neill, Z.; O’Neill, C. A review of leakage detection methods for district heating networks. Appl. Therm. Eng. 2018, 137, 567–574. [Google Scholar] [CrossRef]
- Wohlin, C. Guidelines for snowballing in systematic literature studies and a replication in software engineering. In Proceedings of the 18th international Conference on Evaluation and Assessment in Software Engineering, London, UK, 13–14 May 2014; pp. 1–10. [Google Scholar]
- Calikus, E.; Nowaczyk, S.; Sant’Anna, A.; Gadd, H.; Werner, S. A data-driven approach for discovering heat load patterns in district heating. Appl. Energy 2019, 252, 113409. [Google Scholar] [CrossRef]
- Sun, W.; Cheng, D.; Peng, W. Anomaly Detection Analysis for District Heating Apartments. J. Appl. Sci. Eng. 2018, 21, 33–44. [Google Scholar]
- Tureczek, A.M.; Nielsen, P.S.; Madsen, H.; Brun, A. Clustering district heat exchange stations using smart meter consumption data. Energy Build. 2019, 182, 144–158. [Google Scholar] [CrossRef]
- Frederiksen, S. and Werner, S. District Heating and Cooling; Studentlitteratur: Lund, Sweden, 2013. [Google Scholar]
- Brés, A.; Johansson, C.; Geyer, R.; Leoni, P.; Sjögren, J. Coupled building and system simulations for detection and diagnosis of high district heating return temperatures. In Proceedings of the Conference: Building Simulation: 16th Conference of IBPSA, Rome, Italy, 2–4 September 2019. [Google Scholar]
- Månsson, S.; Kallioniemi, P.O.J.; Thern, M.; Van Oevelen, T.; Sernhed, K. Faults in district heating customer installations and ways to approach them: Experiences from Swedish utilities. Energy 2019, 180, 163–174. [Google Scholar] [CrossRef]
- Månsson, S.; Benzi, I.L.; Thern, M.; Salenbien, R.; Sernhed, K.; Kallioniemi, P.O.J. A taxonomy for labeling deviations in district heating customer data. Smart Energy 2021, 2, 100020. [Google Scholar] [CrossRef]
- Månsson, S.; Thern, M.; Johansson Kallioniemi, P.O.; Sernhed, K. A fault handling process for faults in district heating customer installations. Energies 2021, 14, 3169. [Google Scholar] [CrossRef]
- Leoni, P.; Geyer, R.; Schmidt, R.R. Developing innovative business models for reducing return temperatures in district heating systems: Approach and first results. Energy 2020, 195, 116963. [Google Scholar] [CrossRef]
- Gianniou, P.; Liu, X.; Heller, A.; Nielsen, P.S.; Rode, C. Clustering-based analysis for residential district heating data. Energy Convers. Manag. 2018, 165, 840–850. [Google Scholar] [CrossRef]
- Ma, Z.; Yan, R.; Nord, N. A variation focused cluster analysis strategy to identify typical daily heating load profiles of higher education buildings. Energy 2017, 134, 90–102. [Google Scholar] [CrossRef] [Green Version]
- Lu, Y.; Tian, Z.; Peng, P.; Niu, J.; Li, W.; Zhang, H. GMM clustering for heating load patterns in-depth identification and prediction model accuracy improvement of district heating system. Energy Build. 2019, 190, 49–60. [Google Scholar] [CrossRef]
- Flath, C.; Nicolay, D.; Conte, T.; van Dinther, C.; Filipova-Neumann, L. Cluster analysis of smart metering data. Bus. Inf. Syst. Eng. 2012, 4, 31–39. [Google Scholar] [CrossRef]
- Ramos, S.; Vale, Z. Data Mining techniques to support the classification of MV electricity customers. In Proceedings of the 2008 IEEE Power and Energy Society General Meeting-Conversion and Delivery of Electrical Energy in the 21st Century, Pittsburgh, PA, USA, 20–24 July 2008; pp. 1–7. [Google Scholar]
- Hong, Y.; Yoon, S. Holistic Operational Signatures for an energy-efficient district heating substation in buildings. Energy 2022, 250, 123798. [Google Scholar] [CrossRef]
- Lu, Y.; Tian, Z.; Peng, P.; Niu, J.; Dai, J. Identification and evaluation of operation regulation strategies in district heating substations based on an unsupervised data mining method. Energy Build. 2019, 202, 109324. [Google Scholar] [CrossRef]
- Xue, P.; Zhou, Z.; Fang, X.; Chen, X.; Liu, L.; Liu, Y.; Liu, J. Fault detection and operation optimization in district heating substations based on data mining techniques. Appl. Energy 2017, 205, 926–940. [Google Scholar] [CrossRef]
- Abghari, S.; Boeva, V.; Brage, J.; Johansson, C. District heating substation behaviour modelling for annotating the performance. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Würzburg, Germany, 16–20 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 3–11. [Google Scholar]
- Abghari, S.; Boeva, V.; Brage, J.; Johansson, C.; Grahn, H.; Lavesson, N. Higher order mining for monitoring district heating substations. In Proceedings of the 2019 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Washington, DC, USA, 5–8 October 2019; pp. 382–391. [Google Scholar]
- Abghari, S.; Boeva, V.; Brage, J.; Grahn, H. A higher order mining approach for the analysis of real-world datasets. Energies 2020, 13, 5781. [Google Scholar] [CrossRef]
- Roddick, J.F.; Spiliopoulou, M.; Lister, D.; Ceglar, A. Higher order mining. ACM SIGKDD Explor. Newsl. 2008, 10, 5–17. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Mortazavi-Asl, B.; Pinto, H.; Chen, Q.; Dayal, U.; Hsu, M. Prefixspan: Mining sequential patterns efficiently by prefix-projected pattern growth. In Proceedings of the 17th International Conference on Data Engineering, Heidelberg, Germany, 2–6 April 2001; pp. 215–224. [Google Scholar]
- Frey, B.J.; Dueck, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Boeva, V.; Tsiporkova, E.; Kostadinova, E. Analysis of multiple DNA microarray datasets. In Springer Handbook of Bio-/Neuroinformatics; Springer: Berlin/Heidelberg, Germany, 2014; pp. 223–234. [Google Scholar]
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Kruskal, J.B. On the shortest spanning subtree of a graph and the traveling salesman problem. Proc. Am. Math. Soc. 1956, 7, 48–50. [Google Scholar] [CrossRef]
- Kiluk, S. Algorithmic acquisition of diagnostic patterns in district heating billing system. Appl. Energy 2012, 91, 146–155. [Google Scholar] [CrossRef]
- Kiluk, S. Diagnostic information system dynamics in the evaluation of machine learning algorithms for the supervision of energy efficiency of district heating-supplied buildings. Energy Convers. Manag. 2017, 150, 904–913. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, C.; Shen, W. A deep learning approach for heating and cooling equipment monitoring. In Proceedings of the 2019 IEEE 15th International Conference on Automation Science and Engineering (CASE), Vancouver, BC, Canada, 22–26 August 2019; pp. 228–234. [Google Scholar]
- Calikus, E.; Nowaczyk, S.; Sant’Anna, A.; Byttner, S. Ranking abnormal substations by power signature dispersion. Energy Procedia 2018, 149, 345–353. [Google Scholar] [CrossRef]
- Farouq, S.; Byttner, S.; Bouguelia, M.R.; Gadd, H. A conformal anomaly detection based industrial fleet monitoring framework: A case study in district heating. Expert Syst. Appl. 2022, 201, 116864. [Google Scholar] [CrossRef]
- Farouq, S.; Byttner, S.; Bouguelia, M.R.; Gadd, H. Mondrian conformal anomaly detection for fault sequence identification in heterogeneous fleets. Neurocomputing 2021, 462, 591–606. [Google Scholar] [CrossRef]
- Farouq, S.; Byttner, S.; Bouguelia, M.R.; Nord, N.; Gadd, H. Large-scale monitoring of operationally diverse district heating substations: A reference-group based approach. Eng. Appl. Artif. Intell. 2020, 90, 103492. [Google Scholar] [CrossRef]
- Yeh, C.C.M.; Zhu, Y.; Ulanova, L.; Begum, N.; Ding, Y.; Dau, H.A.; Zimmerman, Z.; Silva, D.F.; Mueen, A.; Keogh, E. Time series joins, motifs, discords and shapelets: A unifying view that exploits the matrix profile. Data Min. Knowl. Discov. 2018, 32, 83–123. [Google Scholar] [CrossRef]
- Wang, P.; Poovendran, P.; Manokaran, K.B. Fault detection and control in integrated energy system using machine learning. Sustain. Energy Technol. Assess. 2021, 47, 101366. [Google Scholar] [CrossRef]
- Zhang, F.; Fleyeh, H. Anomaly detection of heat energy usage in district heating substations using LSTM based variational autoencoder combined with physical model. In Proceedings of the 2020 15th IEEE Conference on Industrial Electronics and Applications (ICIEA), Kristiansand, Norway, 9–13 November 2020; pp. 153–158. [Google Scholar]
- Pałasz, P.; Przysowa, R. Using Different ML Algorithms and Hyperparameter Optimization to Predict Heat Meters’ Failures. Appl. Sci. 2019, 9, 3719. [Google Scholar] [CrossRef] [Green Version]
- Lee, T.; Yoon, S.; Won, K. Delta-T-based operational signatures for operation pattern and fault diagnosis of building energy systems. Energy Build. 2022, 257, 111769. [Google Scholar] [CrossRef]
- Theusch, F.; Klein, P.; Bergmann, R.; Wilke, W.; Bock, W.; Weber, A. Fault detection and condition monitoring in district heating using smart meter data. PHM Soc. Eur. Conf. 2021, 6, 11. [Google Scholar]
- Al Koussa, J.; Månsson, S. Fault detection in district heating substations: A cluster-based and an instance-based approach. In Proceedings of the CLIMA 2022 Conference, Rotterdam, The Netherlands, 22–25 May 2022. [Google Scholar]
- Sandin, F.; Gustafsson, J.; Delsing, J.; Eklund, R. Basic methods for automated fault detection and energy data validation in existing district heating systems. In International Symposium on District Heating and Cooling: 03/09/2012-04/09/2012; District Energy Development Center: Copenhagen, Denmark, 2012. [Google Scholar]
- Johansson, C.; Wernstedt, F. N-dimensional fault detection and operational analysis with performance metrics. In Proceedings of the 13th International Symposium on District Heating and Cooling, Copenhagen, Denmark, 3–4 September 2012. [Google Scholar]
- Shen, Y.; Chen, J.; Fu, Q.; Wu, H.; Wang, Y.; Lu, Y. Detection of district heating pipe network leakage fault using UCB arm selection method. Buildings 2021, 11, 275. [Google Scholar] [CrossRef]
- Guan, H.; Xiao, T.; Luo, W.; Gu, J.; He, R.; Xu, P. Automatic fault diagnosis algorithm for hot water pipes based on infrared thermal images. Build. Environ. 2022, 218, 109111. [Google Scholar] [CrossRef]
- Pierl, D.; Vahldiek, K.; Geißler, J.; Rüger, B.; Michels, K.; Klawonn, F.; Nürnberger, A. Online model-and data-based leakage localization in district heating networks-Impact of random measurement errors. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 2331–2338. [Google Scholar]
- Xue, P.; Jiang, Y.; Zhou, Z.; Chen, X.; Fang, X.; Liu, J. Machine learning-based leakage fault detection for district heating networks. Energy Build. 2020, 223, 110161. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, X.; Zhong, Y.; Zhang, L. Thermal anomaly detection based on saliency computation for district heating system. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 681–684. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Hossain, K.; Villebro, F.; Forchhammer, S. UAV image analysis for leakage detection in district heating systems using machine learning. Pattern Recognit. Lett. 2020, 140, 158–164. [Google Scholar] [CrossRef]
- Berg, A.; Ahlberg, J. Classification of leakage detections acquired by airborne thermography of district heating networks. In Proceedings of the 2014 8th IAPR Workshop on Pattern Reconition in Remote Sensing, Stockholm, Sweden, 24 August 2014; pp. 1–4. [Google Scholar]
- Friman, O.; Follo, P.; Ahlberg, J.; Sjökvist, S. Methods for large-scale monitoring of district heating systems using airborne thermography. IEEE Trans. Geosci. Remote. Sens. 2013, 52, 5175–5182. [Google Scholar] [CrossRef] [Green Version]
- Berg, A.; Ahlberg, J.; Felsberg, M. Enhanced analysis of thermographic images for monitoring of district heat pipe networks. Pattern Recognit. Lett. 2016, 83, 215–223. [Google Scholar] [CrossRef] [Green Version]
- Zimmerman, N.; Dahlquist, E.; Kyprianidis, K. Towards on-line fault detection and diagnostics in district heating systems. Energy Procedia 2017, 105, 1960–1966. [Google Scholar] [CrossRef]
- Aláiz-Moretón, H.; Castejón-Limas, M.; Casteleiro-Roca, J.L.; Jove, E.; Fernández Robles, L.; Calvo-Rolle, J.L. A fault detection system for a geothermal heat exchanger sensor based on intelligent techniques. Sensors 2019, 19, 2740. [Google Scholar] [CrossRef] [Green Version]
- Månsson, S.; Kallioniemi, P.O.J.; Sernhed, K.; Thern, M. A machine learning approach to fault detection in district heating substations. Energy Procedia 2018, 149, 226–235. [Google Scholar] [CrossRef]
- Guelpa, E.; Verda, V. Automatic fouling detection in district heating substations: Methodology and tests. Appl. Energy 2020, 258, 114059. [Google Scholar] [CrossRef]
- Cadei, L.; Corneo, A.; Milana, D.; Loffreno, D.; Lancia, L.; Montini, M.; Rossi, G.; Purlalli, E.; Fier, P.; Carducci, F. Advanced Analytics for Predictive Maintenance with Limited Data: Exploring the Fouling Problem in Heat Exchanging Equipment. In Proceedings of the Abu Dhabi International Petroleum Exhibition & Conference, Abu Dhabi, United Arab Emirates, 31 October–3 November 2019. [Google Scholar]
- Kim, R.; Hong, Y.; Choi, Y.; Yoon, S. System-level fouling detection of district heating substations using virtual-sensor-assisted building automation system. Energy 2021, 227, 120515. [Google Scholar] [CrossRef]
- Park, S.; Moon, J.; Hwang, E. Explainable anomaly detection for district heating based on shapley additive explanations. In Proceedings of the 2020 International Conference on Data Mining Workshops (ICDMW), Virtual, 17–20 November 2020; pp. 762–765. [Google Scholar]
- Langroudi, P.P.; Weidlich, I.; Hay, S. Backward simulation of temperature changes of District Heating networks for enabling loading history in predictive maintenance. Energy Rep. 2021, 7, 119–127. [Google Scholar] [CrossRef]
- Bahlawan, H.; Ferraro, N.; Gambarotta, A.; Losi, E.; Manservigi, L.; Morini, M.; Saletti, C.; Spina, P.R.; Venturini, M. Detection and identification of faults in a District Heating Network. Energy Convers. Manag. 2022, 266, 115837. [Google Scholar] [CrossRef]
- Manservigi, L.; Bahlawan, H.; Losi, E.; Morini, M.; Spina, P.R.; Venturini, M. A diagnostic approach for fault detection and identification in district heating networks. Energy 2022, 251, 123988. [Google Scholar] [CrossRef]
- Bode, G.; Thul, S.; Baranski, M.; Müller, D. Real-world application of machine-learning-based fault detection trained with experimental data. Energy 2020, 198, 117323. [Google Scholar] [CrossRef]
- Li, M.; Deng, W.; Xiahou, K.; Ji, T.; Wu, Q. A data-driven method for fault detection and isolation of the integrated energy-based district heating system. IEEE Access 2020, 8, 23787–23801. [Google Scholar] [CrossRef]
- Choi, Y.; Yoon, S. Autoencoder-driven fault detection and diagnosis in building automation systems: Residual-based and latent space-based approaches. Build. Environ. 2021, 203, 108066. [Google Scholar] [CrossRef]
- Gokhale, G.; Claessens, B.; Develder, C. Physics informed neural networks for control oriented thermal modeling of buildings. Appl. Energy 2022, 314, 118852. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Hinneburg, A.; Keim, D.A. On the surprising behavior of distance metrics in high dimensional space. In International Conference on Database Theory; Springer: Berlin/Heidelberg, Germany, 2001; pp. 420–434. [Google Scholar]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Bond-Taylor, S.; Leach, A.; Long, Y.; Willcocks, C.G. Deep generative modelling: A comparative review of VAEs, GANs, normalizing flows, energy-based and autoregressive models. arXiv 2021, arXiv:2103.04922. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Inclusion | Exclusion |
|---|---|
| Available in electronic form | Duplicates |
| Peer-reviewed journal and conference papers | Non-relevant title or abstract |
| Written in English | Non-indexed studies |
| Addresses FDD in DH | Research thesis |
| Published between 2010 and 2022 |
| Feature | Notation | Unit |
|---|---|---|
| Primary supply temperature | °C | |
| Primary return temperature | °C | |
| Volume flow | mh | |
| Accumulated volume | V | m |
| Accumulated energy | Q | J |
| References | Methodologies | Distance Metrics | Validation Metrics |
|---|---|---|---|
| Tureczek et al. [34] | kM | Euclidean distance | MIA, CDI, DBI and SI |
| Gianniou et al. [41] | kM | K-Spectral Centroid | BIC, SI |
| Hong et al. [46] | kM | Euclidean distance | DBI |
| Flath et al. [44] | kM | Euclidean distance | DBI |
| Xue et al. [48] | kM, PAM | Euclidean distance | DBI |
| Ma et al. [42] | PAM | Pearson Correlation Coefficient-based dissimilarity | Dunn Index |
| Calikus et al. [32] | kS | Dynamic Time Warping | SI |
| Kiluk [58] | kNN | Chebyshev distance | |
| Lu et al. [43] | GMM | Probability distribution | BIC, Mean Absolute Percentage Error and PCC |
| Lu et al. [47] | GMM | Probability distribution | BIC |
| Sun et al. [33] | kM, GMM, KGMM | Euclidean distance, Probability distribution | Minimum Sum of Squared error |
| Abghari et al. [49,50,51] | Affinity, Consensus | Levenshtein distance | SI, Adjusted Rand score |
| References | Methodologies | Categories |
|---|---|---|
| Wang et al. [60] | LASSO | Regression |
| Wang et al. [60] | SVR | Regression |
| Månsson et al. [5], Theusch et al. [70], Calikus et al. [61], Wang et al. [66], Sandin et al. [72], Johansson and Wernstedt [73] | LR | Regression |
| Calikus et al. [61] | RR | Regression |
| Al Koussa and Månsson [71] | TPOT | Geometric |
| Wang et al. [66], Palasz and Przysowa [68] | SVM | Geometric |
| Theusch et al. [70], Farouq et al. [62,63,64] | kNN | Geometric |
| Lee et al. [69], Theusch et al. [70], Sandin et al. [72] | kM | Geometric |
| Farouq et al. [63] | CC | Geometric |
| Sandin et al. [72] | Limit-checking | Geometric |
| Palasz and Przysowa [68] | GBDT | Logical |
| Brès et al. [36] | BDT | Logical |
| Brès et al. [36] | CART | Logical |
| Farouq et al. [64] | IF | Logical |
| Wang et al. [60], Palasz and Przysowa [68] | MLP | Deep learning |
| Wang et al. [60], Zhang and Fleyeh [67] | LSTM | Deep learning |
| Zhang and Fleyeh [67] | AE | Deep learning |
| Zhang and Fleyeh [67] | VAE | Deep learning |
| Johansson and Wernstedt [73] | Visualisation | Statistical |
| Gadd and Werner [6] | Manual analysis | Statistical |
| References | Methodologies | Categories | Data | DH Segment |
|---|---|---|---|---|
| Chen et al. [74] | CB, RIDGE | Reinforcement learning | Leakage simulations | Primary |
| Pierl et al. [76] | SVM, NB, RUSBT, AB | Traditional learning | Leakage simulations | Primary |
| Xue et al. [77] | XGBoost | Traditional learning | Leakage simulations | Primary |
| Guan et al. [75] | LR, OCR, Canny | Computer vision | Infrared thermal imagery | Secondary |
| Xu et al. [78] | SC | Computer vision | Airborne thermal imagery | Primary |
| Berg et al. [81] | LDA, SVM, AB, RF | Computer vision | Airborne thermal imagery | Primary |
| Berg et al. [83] | LDA, SVM, AB, RF | Computer vision | Airborne thermal imagery | Primary |
| Friman et al. [82] | AB | Computer vision | Airborne thermal imagery | Primary |
| Hossain et al. [80] | CNN, LOR, LDA, SVM, NB, kNN, DT, RF, AB | Computer vision, Deep learning | Airborne thermal imagery | Primary |
| References | Methodologies | Diagnosis |
|---|---|---|
| Zimmerman et al. [84] | BN | Sensor failure |
| Aláiz-Moretón et al. [85] | RF, XGBoost, ERT, AB, kNN, ANN | Sensor failure |
| Månsson et al. [86] | GBR, TPOT | Sensor failure |
| Guelpa et al. [87] | Analytical | Fouling |
| Cadei et al. [88] | ARIMA, RIDGE, one-class SVM | Fouling |
| Kim et al. [89] | kM, MLP | Fouling |
| Park et al. [90] | RF | Valves |
| Langroudi et al. [91] | LR, DTR, RIDGE, kNN, PLS, SVM, RF, LASSO, XGBoost, ANN | Pipes |
| Bahlawan et al. [92] | Analytical | Pipes |
| Manservigi et al. [93] | Analytical | Pipes |
| Bode et al. [94] | LR, kNN, CART, RF, NB, SVM, ANN | Multi-label |
| Choi et al. [96] | AE, MLP | Multi-label |
| Li et al. [95] | kNN, RF, ANN, CNN | Multi-label |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
van Dreven, J.; Boeva, V.; Abghari, S.; Grahn, H.; Al Koussa, J.; Motoasca, E. Intelligent Approaches to Fault Detection and Diagnosis in District Heating: Current Trends, Challenges, and Opportunities. Electronics 2023, 12, 1448. https://doi.org/10.3390/electronics12061448
van Dreven J, Boeva V, Abghari S, Grahn H, Al Koussa J, Motoasca E. Intelligent Approaches to Fault Detection and Diagnosis in District Heating: Current Trends, Challenges, and Opportunities. Electronics. 2023; 12(6):1448. https://doi.org/10.3390/electronics12061448
Chicago/Turabian Stylevan Dreven, Jonne, Veselka Boeva, Shahrooz Abghari, Håkan Grahn, Jad Al Koussa, and Emilia Motoasca. 2023. "Intelligent Approaches to Fault Detection and Diagnosis in District Heating: Current Trends, Challenges, and Opportunities" Electronics 12, no. 6: 1448. https://doi.org/10.3390/electronics12061448