
An Improved Vision Transformer Network with a Residual Convolution Block for Bamboo Resource Image Identification
 ,
,
Abstract
:1. Introduction
2. Experiment and Methods
2.1. Bamboo Resources
2.2. Methods
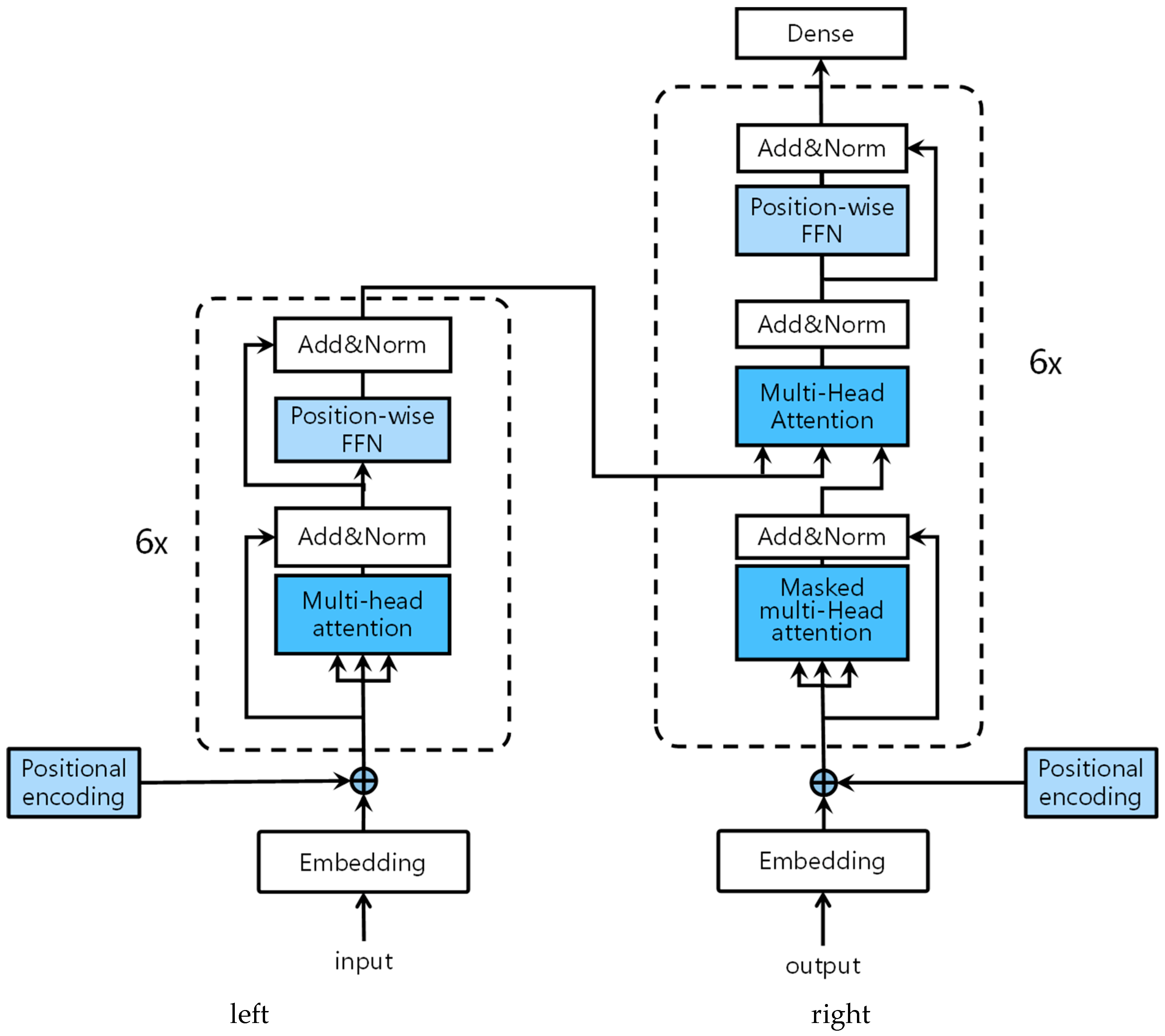
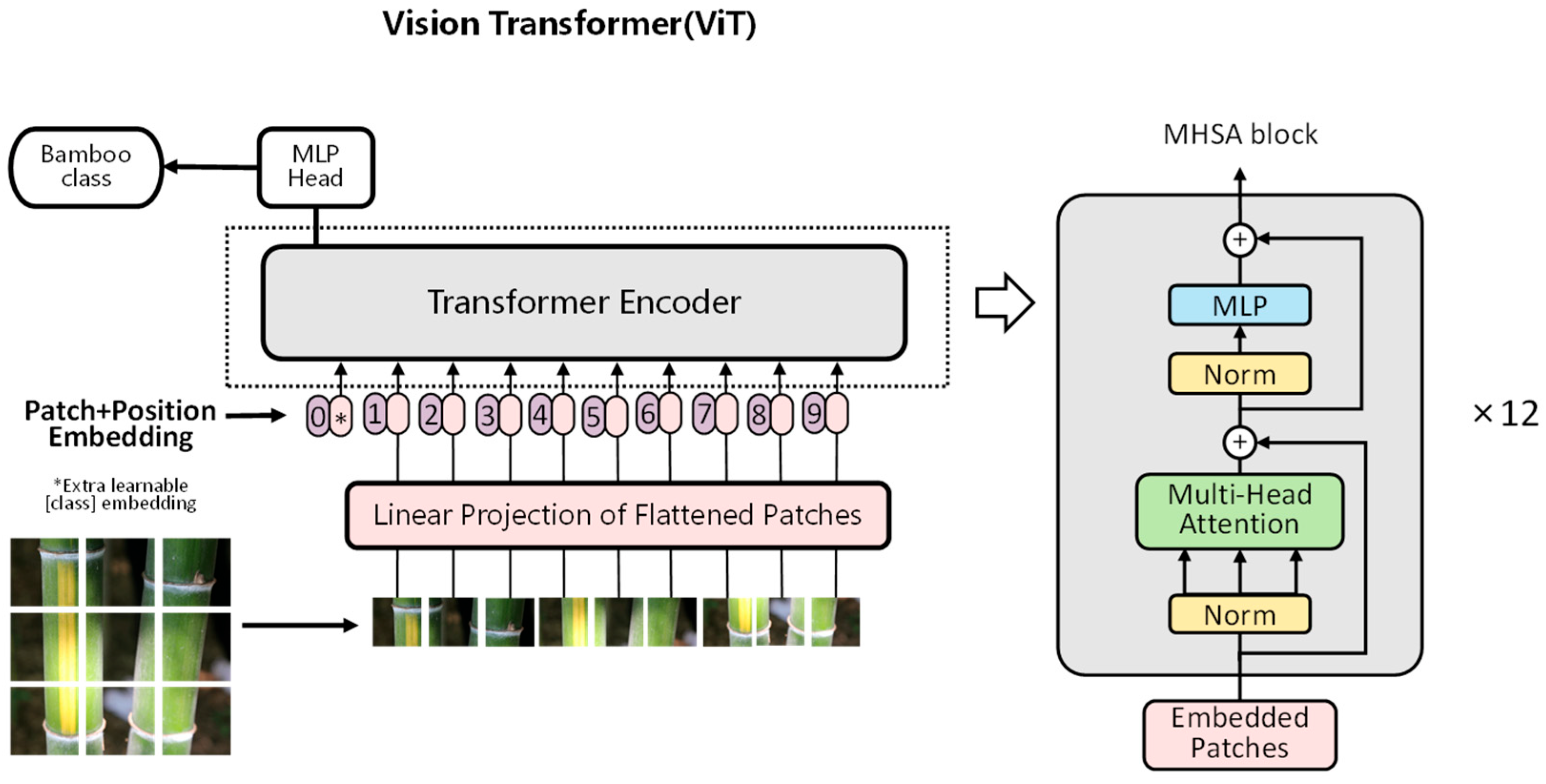
2.2.1. Vision Transformer
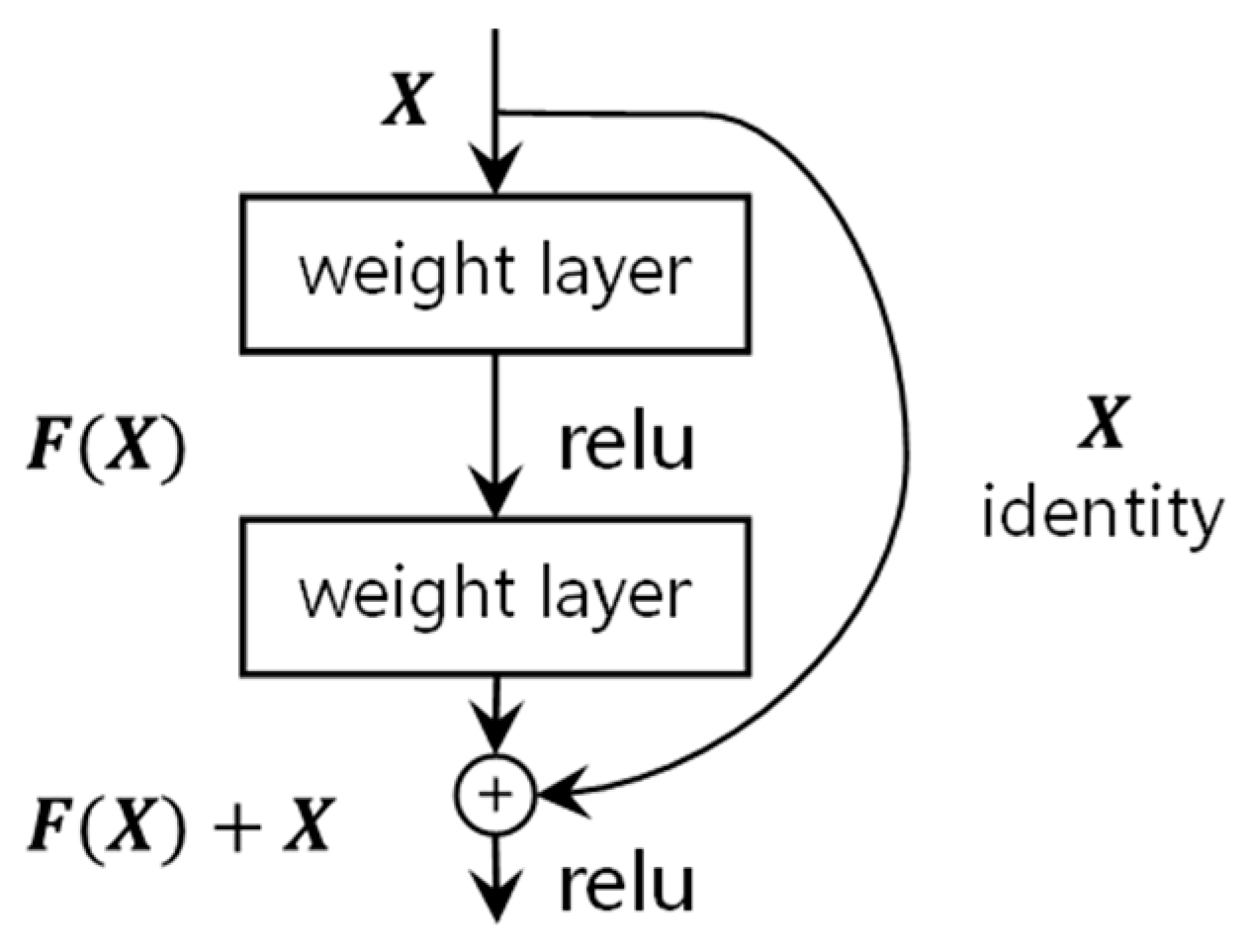
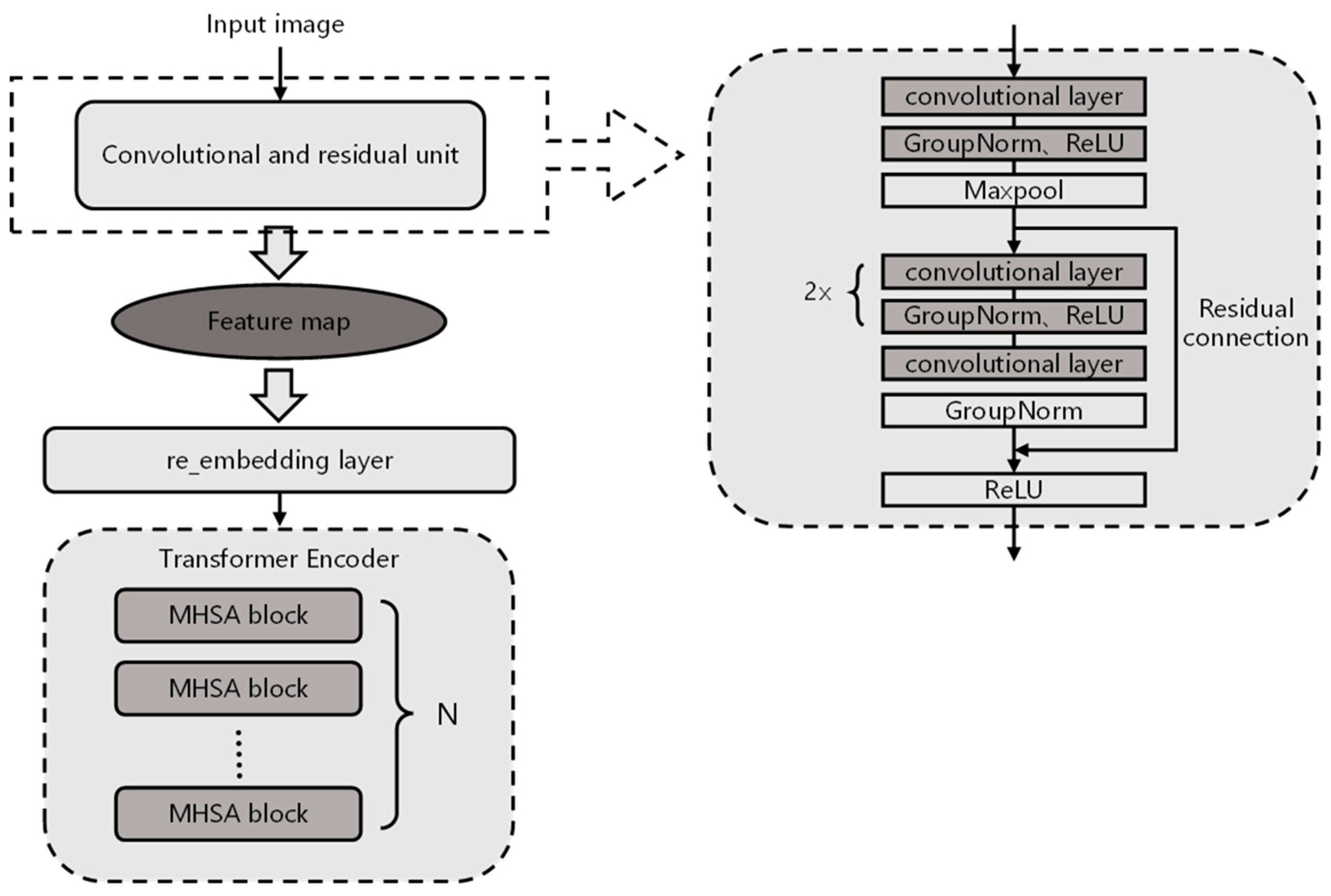
2.2.2. Residual Vision Transformer Algorithm
2.2.3. Quantitative Evaluation Indicators
3. Results and Discussion
3.1. Bamboo Resource Images Dataset Analysis
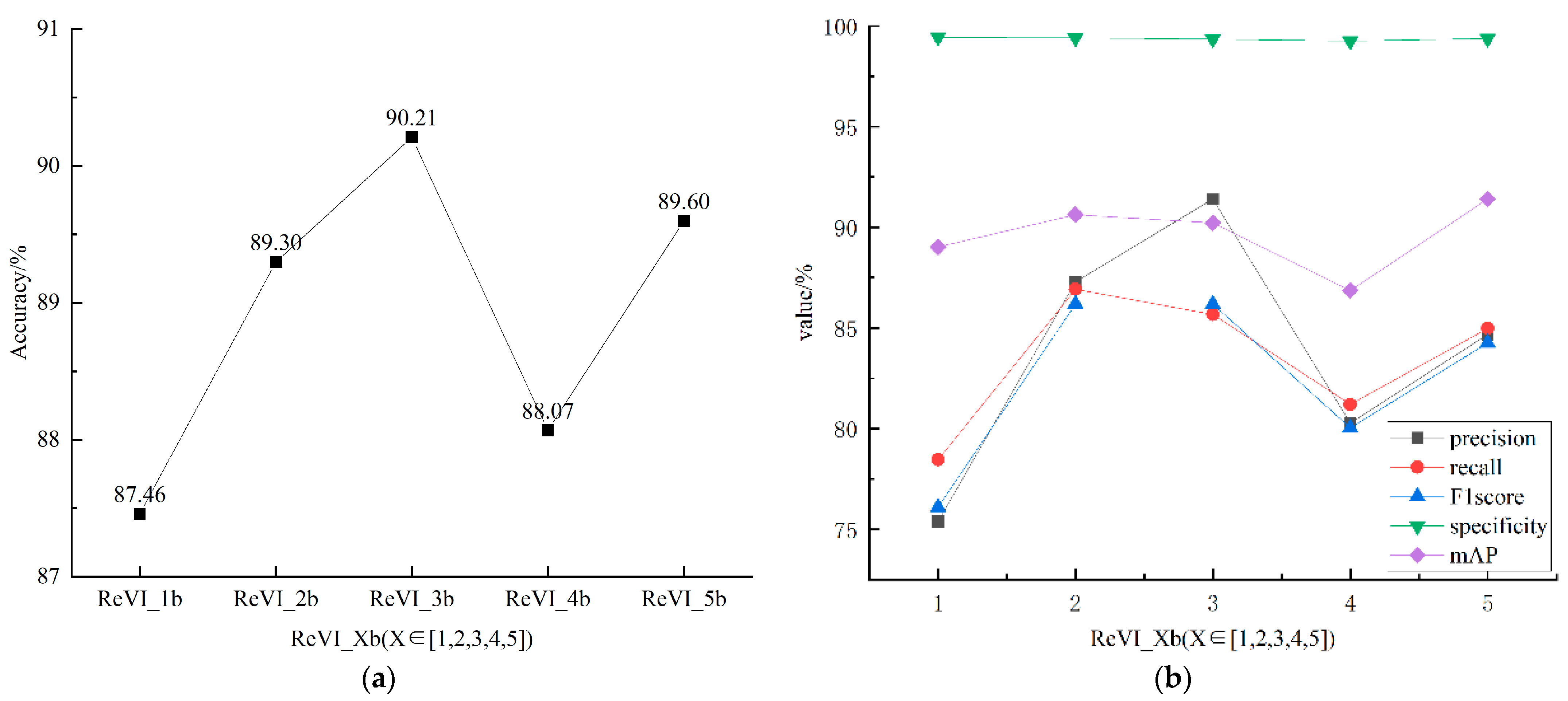
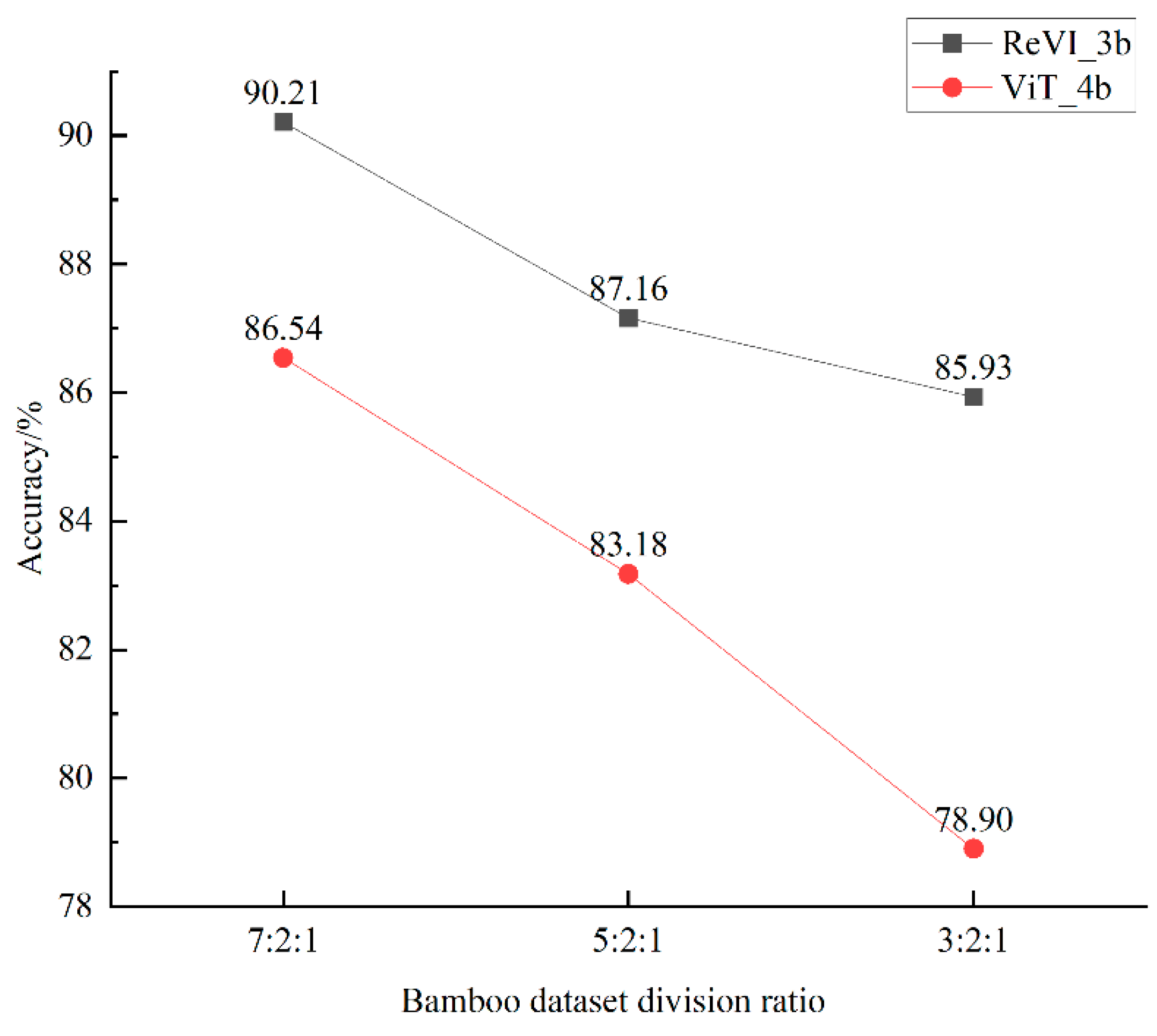
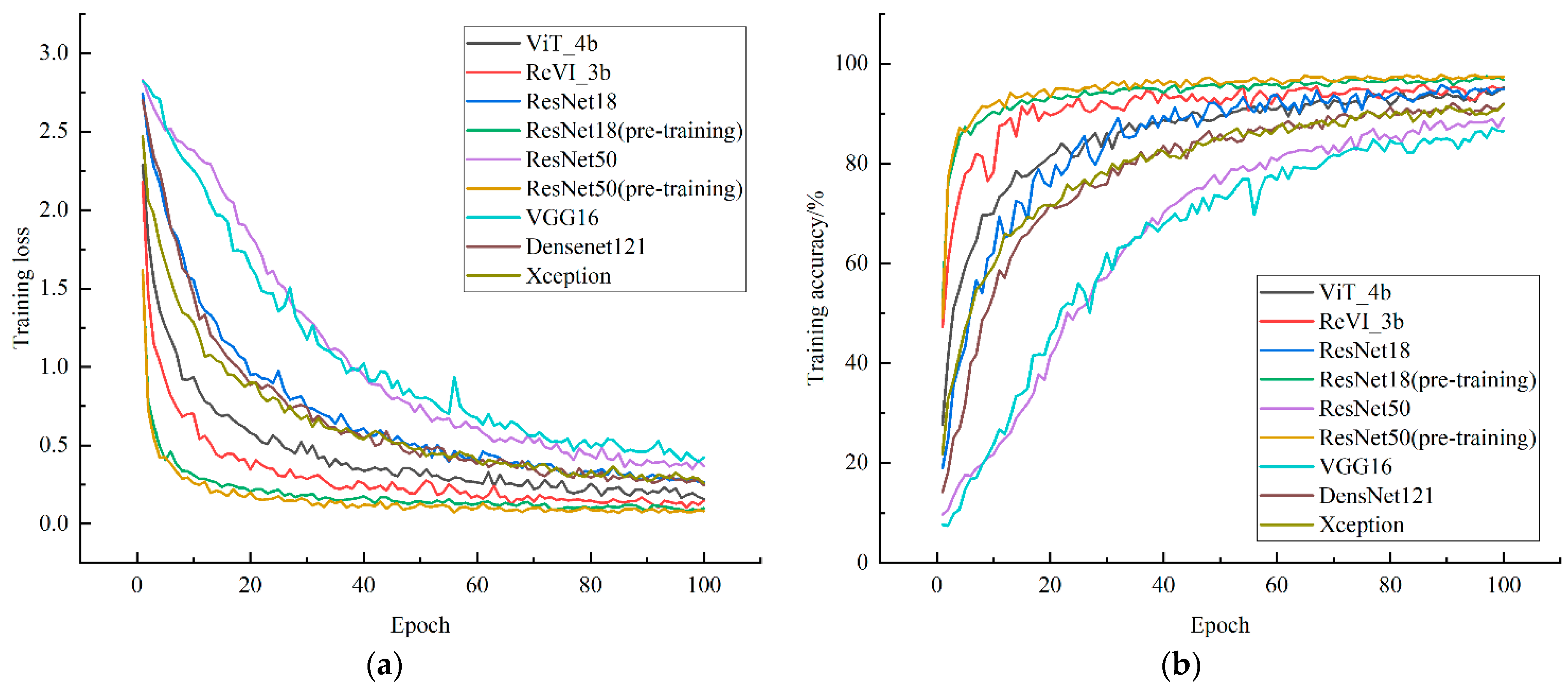
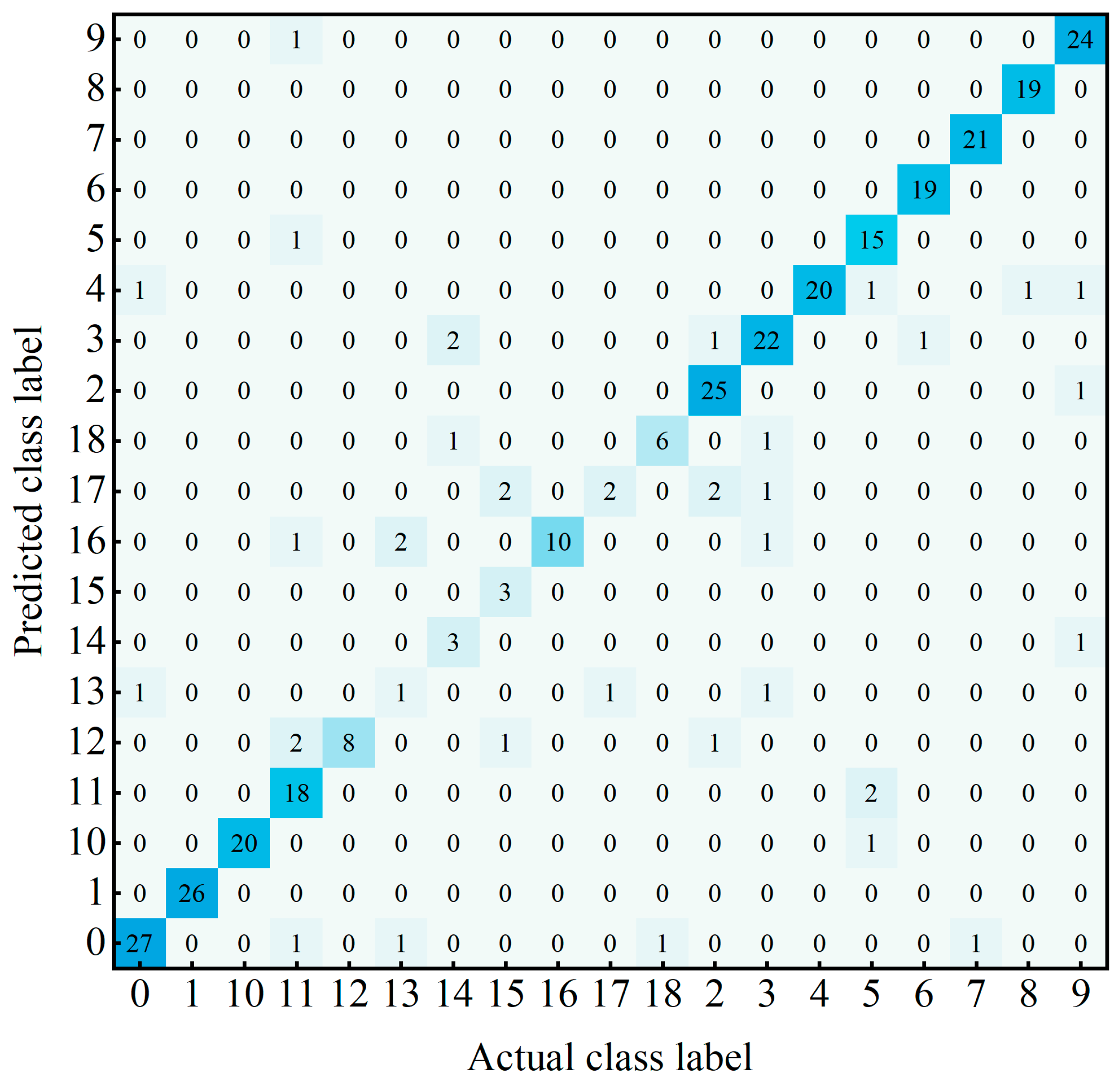
3.2. Analyzing the Performance of ReVI on Bamboo Datasets
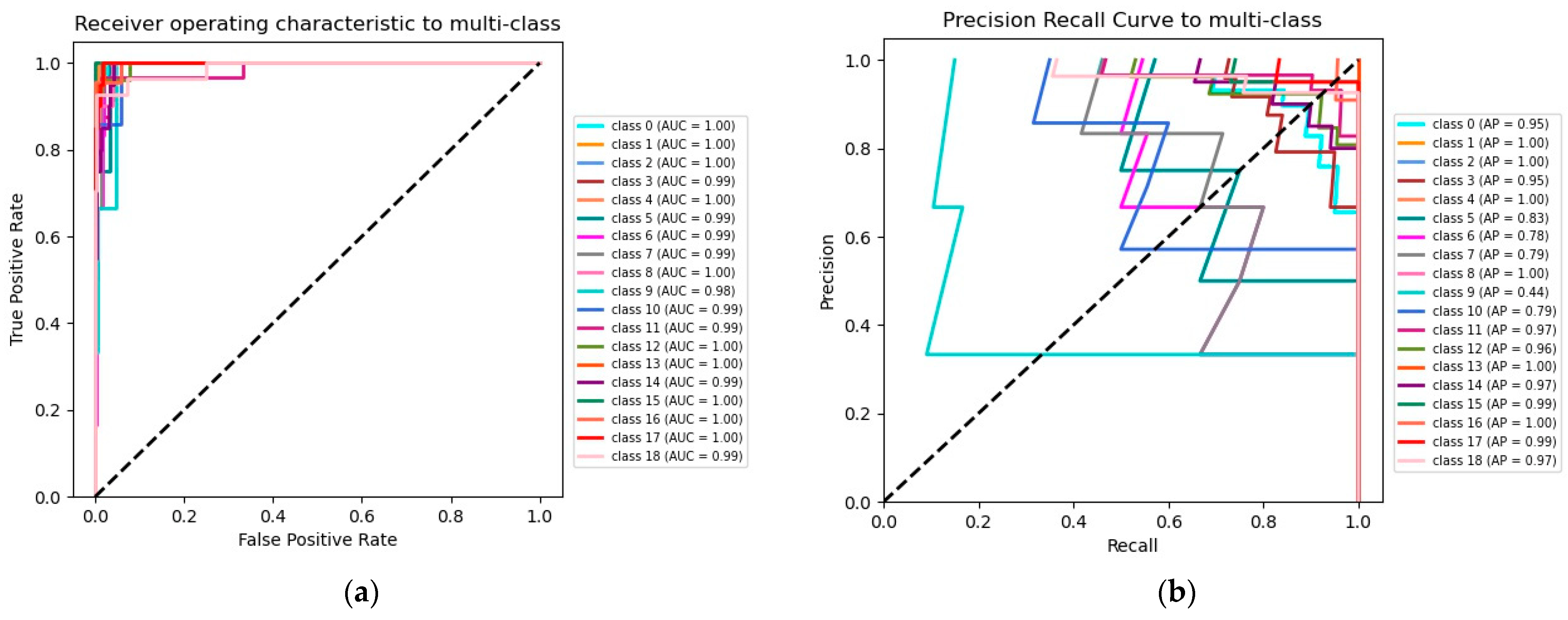
3.3. Comparison with Different Deep Learning Models
4. Conclusions
- This paper improves the ViT algorithm, the ReVI algorithm proposed in this paper outperforms both the ViT and CNN algorithms on the bamboo dataset, and ReVI still outperforms ViT despite decreasing the number of training samples. It can be concluded that the convolution and residual mechanisms compensate for the inductive bias that cannot be learned by ViT on a small-scale dataset, rendering ViT no longer limited to the number of training samples and equally applicable to classification on small-scale datasets.
- Bamboo varies in species and is widely distributed around the world. Additionally, collecting bamboo samples requires much expertise and human resources. The average classification accuracy of ReVI is up to 90.21% compared to CNNs such as ResNet18, VGG16, Xception and Densenet121. The ReVI algorithm proposed in this manuscript can help bamboo experts to conduct more efficient and accurate bamboo classification and identification, which is important for the conservation of bamboo germplasm diversity.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liese, W. Research on Bamboo. Wood Sci. Technol. 1987, 21, 189–209. [Google Scholar] [CrossRef]
- Jain, S.; Kumar, R.; Jindal, U.C. Mechanical behaviour of bamboo and bamboo composite. J. Mater. Sci. 1992, 27, 4598–4604. [Google Scholar] [CrossRef]
- Sharma, B.; van der Vegte, A. Engineered Bamboo for Structural Applications. Constr. Build. Mater. 2015, 81, 66–73. [Google Scholar] [CrossRef]
- Lakkad, S.C.; Patel, J.M. Mechanical Properties of Bamboo, a Natural Composite. Fibre Sci. Technol. 1981, 14, 319–322. [Google Scholar] [CrossRef]
- Scurlock, J.M.; Dayton, D.C.; Hames, B. Bamboo: An overlooked biomass resource? Biomass Bioenergy 2000, 19, 229–244. [Google Scholar] [CrossRef] [Green Version]
- Yeasmin, L.; Ali, M.; Gantait, S.; Chakraborty, S. Bamboo: An overview on its genetic diversity and characterization. 3 Biotech 2015, 5, 1–11. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Milicevic, M.; Zubrinic, K.; Grbavac, I.; Obradovic, I. Application of deep learning architectures for accurate detection of olive tree flowering phenophase. Remote Sens. 2020, 12, 2120. [Google Scholar] [CrossRef]
- Quiroz, I.A.; Alférez, G.H. Image recognition of Legacy blueberries in a Chilean smart farm through deep learning. Comput. Electron. Agric. 2020, 168, 105044. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30, Available online: https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html (accessed on 17 January 2023).
- Lee, S.; Lee, S.; Song, B.C. Improving Vision Transformers to Learn Small-Size Dataset From Scratch. IEEE Access 2022, 10, 123212–123224. [Google Scholar] [CrossRef]
- Park, S.; Kim, B.-K.; Dong, S.-Y. Self-Supervised Rgb-Nir Fusion Video Vision Transformer Framework for Rppg Estimation. IEEE Trans. Instrum. Meas. 2022, 71, 1–10. [Google Scholar] [CrossRef]
- Bi, M.; Wang, M.; Li, Z.; Hong, D. Vision Transformer with Contrastive Learning for Remote Sensing Image Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 16, 738–749. [Google Scholar] [CrossRef]
- Wiedemann, G.; Remus, S.; Chawla, A.; Biemann, C. Does BERT make any sense? Interpretable word sense disambiguation with contextualized embeddings. arXiv 2019, arXiv:1909.10430. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do vision transformers see like convolutional neural networks? In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2021; Volume 34. [Google Scholar]
- Jin, X.; Zhu, X. Classifying a Limited Number of the Bamboo Species by the Transformation of Convolution Groups. In Proceedings of the 4th International Conference on Computer Science and Application Engineering, Sanya, China, 20–22 October 2020. [Google Scholar]
- Wu, Z.; Shen, C.; Van Den Hengel, A. Wider or deeper: Revisiting the resnet model for visual recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef] [Green Version]
- Coşkun, M.; Uçar, A.; Yildirim, Ö.; Demir, Y. Face recognition based on convolutional neural network. In Proceedings of the 2017 International Conference on Modern Electrical and Energy Systems (MEES), Kremenchuk, Ukraine, 15–17 November 2017. [Google Scholar]
- Almabdy, S.; Elrefaei, L. Deep convolutional neural network-based approaches for face recognition. Appl. Sci. 2019, 9, 4397. [Google Scholar] [CrossRef] [Green Version]
- Cheng, H.-D.; Jiang, X.H.; Sun, Y.; Wang, J. Color image segmentation: Advances and prospects. Pattern Recognit. 2001, 34, 2259–2281. [Google Scholar] [CrossRef]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Ripley, B. Pattern Recognition and Neural Networks; Google Scholar; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S-PLUS; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Kim, Y.; Denton, C.; Hoang, L.; Rush, A.M. Structured attention networks. arXiv 2017, arXiv:1702.00887. [Google Scholar]
- Parikh, A.P.; Täckström, O.; Das, D.; Uszkoreit, J. A decomposable attention model for natural language inference. arXiv 2016, arXiv:1606.01933. [Google Scholar]
- Paulus, R.; Xiong, C.; Socher, R. A deep reinforced model for abstractive summarization. arXiv 2017, arXiv:1705.04304. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
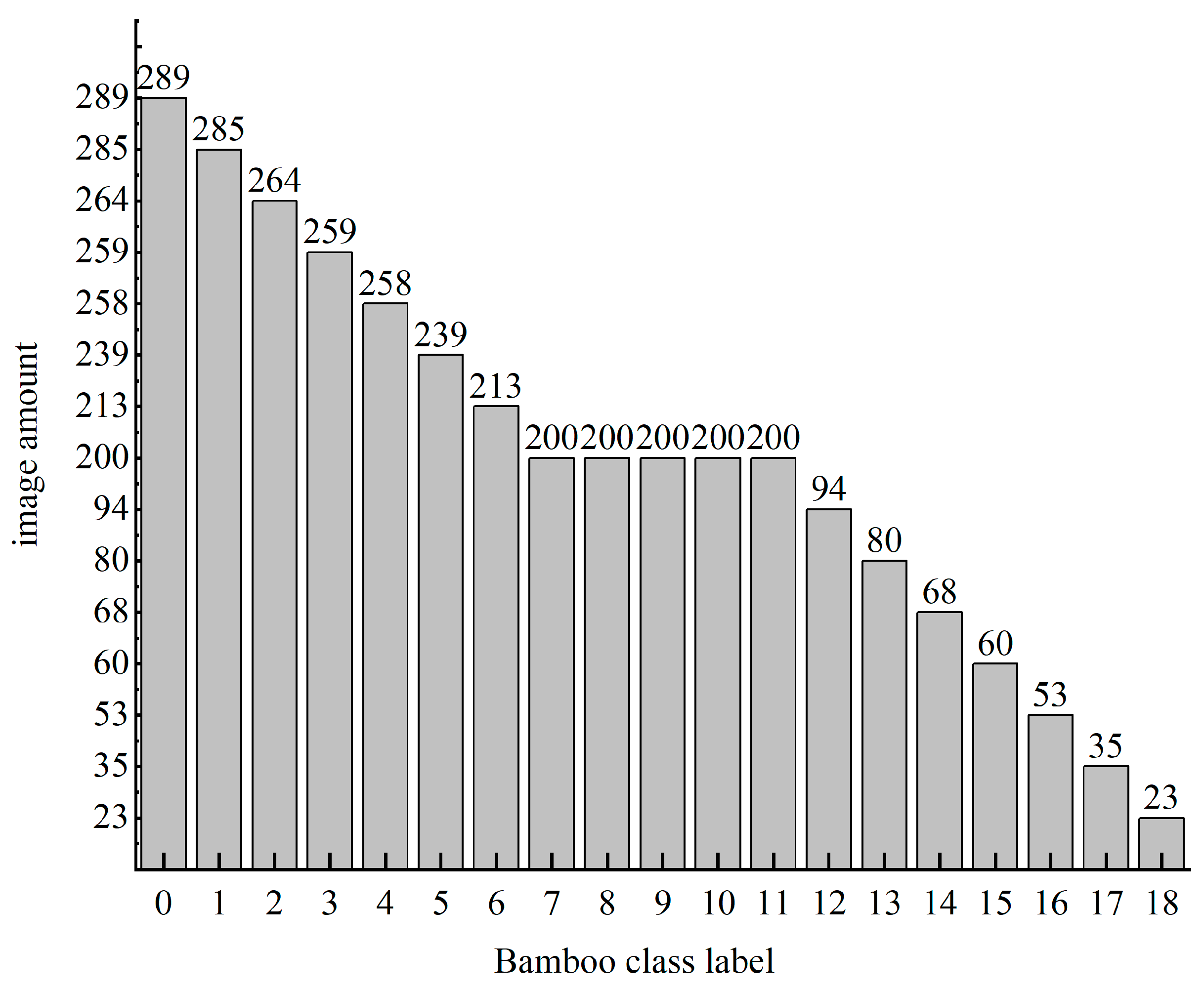{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Size | Parameter |
|---|---|---|
| Conv2d | 192 × 192 | 7 × 7, 64, stride 2, padding 3 |
| Maxpool | 95 × 95 | 3 × 3, stride 2 |
| Residual unit | 48 × 48 | × 1 |
| Re_embedding layer | 768 × 577 | Patch_size = 2 |
| Transformer encoder | 768 | --- |
| FC | 19 | --- |
| Highest Accuracy/% | |||||
|---|---|---|---|---|---|
| ReVI_1b | ReVI_2b | ReVI_3b | ReVI_4b | ReVI_5b | |
| Training dataset | 95.15 | 96.18 | 96.18 | 96.27 | 96.58 |
| Validation dataset | 96.65 | 95.34 | 95.81 | 95.50 | 95.65 |
| Test dataset | 87.46 | 89.30 | 90.21 | 88.07 | 89.60 |
| Model | Precision/% | Recall/% | F1-Score/% | Specificity/% | mAP/% |
|---|---|---|---|---|---|
| ReVI_3b | 91.40 | 85.67 | 79.63 | 99.35 | 91.00 |
| ViT_4b | 82.89 | 83.39 | 80.77 | 99.19 | 90.22 |
| Model | ReVI_3b | ViT_4b | ResNet18 | ResNet50 | VGG16 | DenseNet121 | Xception | ResNet18 | ResNet50 |
|---|---|---|---|---|---|---|---|---|---|
| (Pretraining) | (Pretraining) | ||||||||
| Training time | 60 m 20 s | 59 m 9 s | 40 m 34 s | 69 m 55 s | 88 m 29 s | 102 m 36 s | 74 m 10 s | 44 m 52 s | 62 m 50 s |
| accuracy/% | 90.21 | 85.63 | 84.71 | 87.16 | 84.4 | 85.93 | 82.97 | 88.07 | 94.5 |
| Precision/% | 80.15 | 81.55 | 85.44 | 82.08 | 83.52 | 81.68 | 75.19 | 80.23 | 93.9 |
| Recall/% | 80.83 | 81.26 | 75.56 | 82.73 | 75.81 | 77.38 | 76.12 | 81.02 | 87.38 |
| F1-score/% | 79.63 | 80.77 | 77.47 | 81.23 | 75.98 | 78.43 | 74.89 | 79.88 | 89.03 |
| Specificity/% | 99.35 | 99.19 | 99.14 | 99.29 | 99.12 | 99.21 | 99.04 | 99.34 | 99.69 |
| mAP/% | 90.22 | 91 | 89.94 | 88.73 | 83.99 | 88.9 | 86.86 | 85.86 | 96.36 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, Q.; Jin, X.; Song, Y.; Wang, L.; Li, S.; Rao, Y.; Zhang, X.; Gao, Q. An Improved Vision Transformer Network with a Residual Convolution Block for Bamboo Resource Image Identification. Electronics 2023, 12, 1055. https://doi.org/10.3390/electronics12041055
Zou Q, Jin X, Song Y, Wang L, Li S, Rao Y, Zhang X, Gao Q. An Improved Vision Transformer Network with a Residual Convolution Block for Bamboo Resource Image Identification. Electronics. 2023; 12(4):1055. https://doi.org/10.3390/electronics12041055
Chicago/Turabian StyleZou, Qing, Xiu Jin, Yi Song, Lianglong Wang, Shaowen Li, Yuan Rao, Xiaodan Zhang, and Qijuan Gao. 2023. "An Improved Vision Transformer Network with a Residual Convolution Block for Bamboo Resource Image Identification" Electronics 12, no. 4: 1055. https://doi.org/10.3390/electronics12041055