

Analysis of Image Preprocessing and Binarization Methods for OCR-Based Detection and Classification of Electronic Integrated Circuit Labeling

Abstract
:1. Introduction
2. Related Work
2.1. The Overview of AI-Based Solutions
- Convolutional Neural Networks (CNNs)—have shown excellent performance in OCR tasks, even with challenging texts, due to their ability to learn spatial hierarchies of patterns; however, they require substantial labeled data for training and may struggle with images containing noise or distortions;
- Recurrent Neural Networks (RNNs) and their variants (e.g., LSTM, GRU)—can model the sequential nature of text data, making them suitable for OCR tasks [8]; however, they may face difficulties in learning long-term dependencies, which could be problematic for complex, hard-to-read texts;
- Transfer Learning—fine-tuning pretrained models such as BERT [9] and GPT [10] has demonstrated promising results in OCR tasks; they leverage vast amounts of pretraining data, mitigating the need for extensive task-specific data. However, they require expertise for effective fine-tuning and might underperform on extremely noisy or low-resolution images [11];
- Adversarial Training—can improve the model’s robustness to noise and other distortions [12]; however, this method is computationally demanding and needs careful tuning to prevent overfitting;
- Multi-Modal Models—incorporate context or metadata demonstrating improved OCR performance [13]; however, they require additional data sources and may be complex to implement;
- Synthetic Data Generation—GANs and other synthetic data generation techniques can augment limited training data, which is particularly useful for OCR tasks with difficult-to-read text [14]; however, ensuring the real-world applicability of synthetic data remains a challenge.
2.2. Performance Evaluation of Current Industry Standard OCR Engines
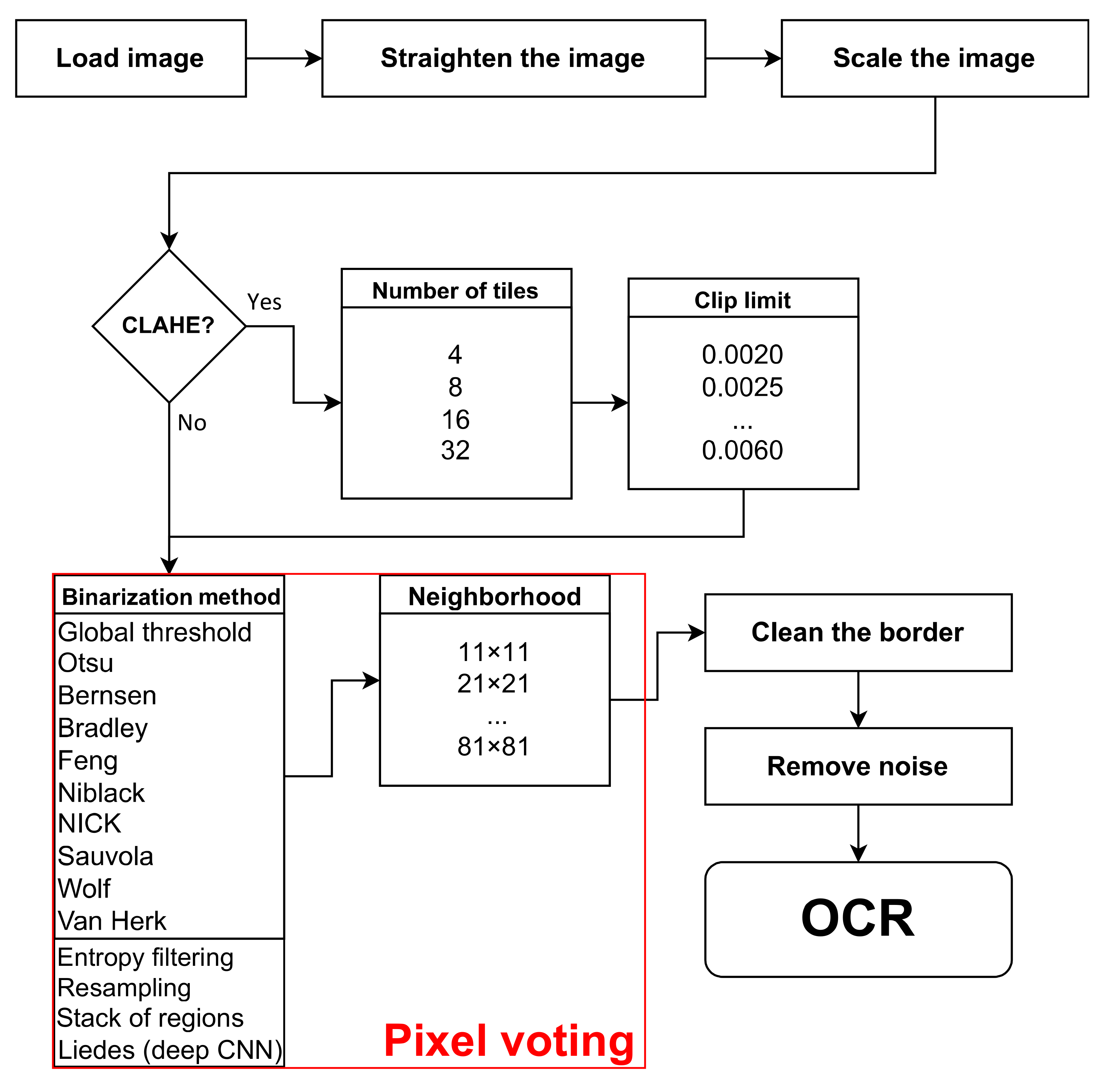
3. Image Preprocessing and Binarization Methods
3.1. Basic Image Filtering
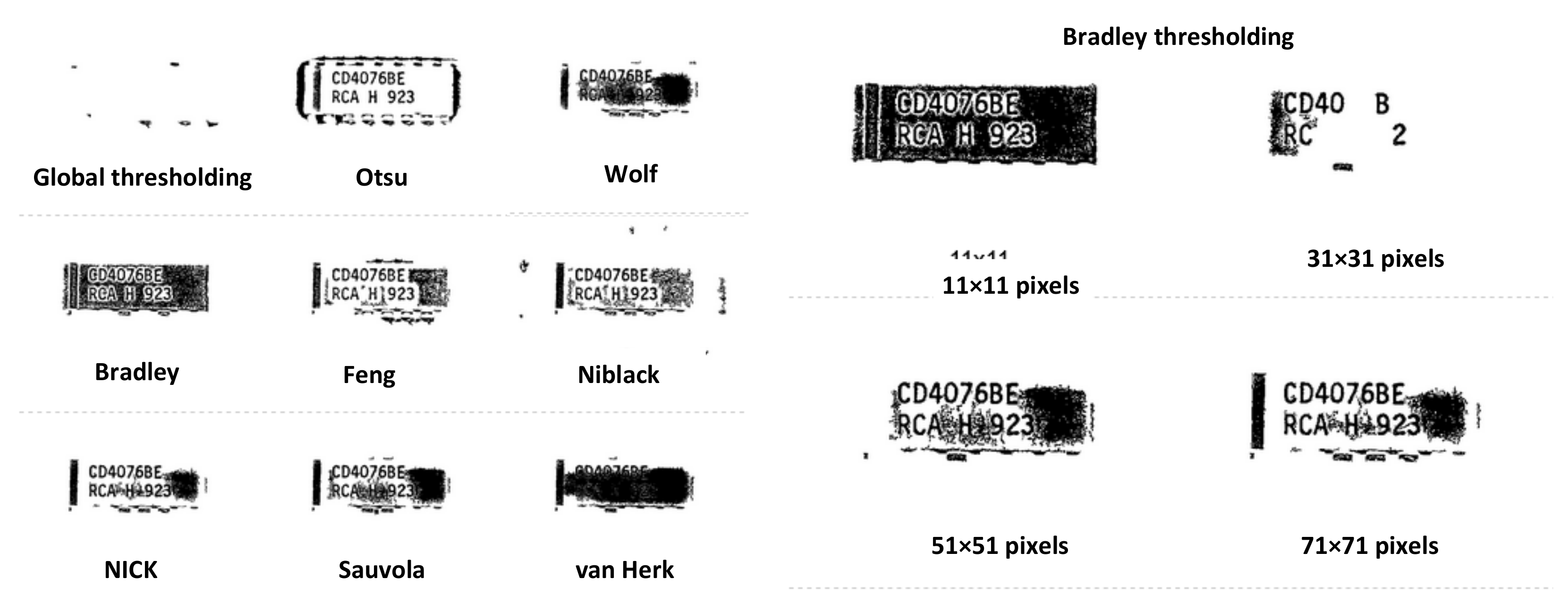
3.2. Image Binarization Methods
- Otsu binarization—determines the threshold value by maximizing the between-class variance of the foreground and background pixels [25] aswhere and are the probability functions for two clusters representing the background and foreground pixels, whereas and denote the mean intensities in these both classes;
- Bernsen thresholding—calculates the threshold value for each pixel based on the local contrast of the neighborhood as the midgrey value [26]:for pixels where the contrast of their neighborhood is above 15 (default value), where and values are determined in the local window; for low-contrast regions, the value is set to 0 or 1 depending on the midgrey value;
- Van Herk method—utilizes morphological dilation and erosion operations for an adaptive calculation of the threshold value for each pixel:
- Bradley thresholding—sets each pixel with brightness T percent lower than the average brightness of the surrounding pixels in the window to 0, and calculates the threshold value for the others as the mean of the neighborhood, weighted by a constant factor [27]:where m is the local average calculated in constant time regardless of the neighborhood size using the predetermined integral image;
- Niblack thresholding—calculates the local threshold value for each pixel based on the mean and standard deviation of the local neighborhood [28]where m is the local average, s denotes the local standard deviation, and the constant parameter ;
- Sauvola method—incorporates both the mean and standard deviation of the local neighborhood to calculate the threshold value with additional use of the dynamic range of the standard deviation:where m denotes the mean local intensity, s stands for the local standard deviation, its dynamic range is , and the constant parameter ;
- Wolf method—calculates the threshold value for each pixel based on the mean and standard deviation of the local neighborhood, with an additional normalization of contrast and mean intensity:where M is the minimum gray level in the local window, , and the constant parameter ;
- Feng thresholding—a modification of Niblack’s method, incorporating a criterion of maximizing local contrast [29]:where the dynamic range of standard deviation is calculated in an additional larger window, , , assuming the positive constants: in the range of , in the range of , and in the range of [30];
- NICK thresholding—with the acronym being the first letter of its authors’ names, determines the threshold value for each pixel using the formula:where the parameter , and B denotes the local variance in the current window with its size proposed in the paper [31] equal to pixels, although it may be changed depending on the specific images.
3.3. Review of Recent Binarization Methods
4. Description of the Evaluation Dataset
5. Implementation and Results
5.1. The Choice of Filters and Binarization Methods
5.2. Application of the Pixel Voting
- Entropy filtering;
- Bradley with window size of pixels;
- Feng with window size pixels;
- Niblack with window size of pixels;
- Sauvola with window size of pixels.
5.3. Analysis of Results and Ablation Study
- Image straightening;
- Image scaling;
- Binarization;
- Morphological border cleaning;
- Morphological noise removal.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AHE | Adaptive Histogram Equalization |
| AI | Atrificial Intelligence |
| BERT | Bidirectional Encoder Representations from Transformers |
| CDF | Cumulative Distribution Function |
| CLAHE | Contrast-Limited Adaptive Histogram Equalization |
| CNN | Convolutional Neural Network |
| DIBCO | Document Image Binarization Competition |
| GAN | Generative Adversarial Network |
| GPT | Generative Pretrained Transformer |
| GRU | Gated Recurrent Unit |
| IC | Integrated Circuit |
| ITU | International Telecommunication Union |
| LSTM | Long Short-Term Memory |
| OCR | Optical Character Recognition |
| RNN | Recurrent Neural Networks |
References
- Vukovic, I.; Cisar, P.; Kuk, K.; Bandjur, M.; Popovic, B. Influence of Image Enhancement Techniques on Effectiveness of Unconstrained Face Detection and Identification. Elektron. Elektrotechnika 2021, 27, 49–58. [Google Scholar] [CrossRef]
- Yan, A.; Xiang, J.; Cao, A.; He, Z.; Cui, J.; Ni, T.; Huang, Z.; Wen, X.; Girard, P. Quadruple and Sextuple Cross-Coupled SRAM Cell Designs with Optimized Overhead for Reliable Applications. IEEE Trans. Device Mater. Reliab. 2022, 22, 282–295. [Google Scholar] [CrossRef]
- Hegghammer, T. OCR with Tesseract, Amazon Textract, and Google Document AI: A benchmarking experiment. J. Comput. Soc. Sci. 2021, 5, 861–882. [Google Scholar] [CrossRef]
- Zhao, K.; Hu, J.; Shao, H.; Hu, J. Federated multi-source domain adversarial adaptation framework for machinery fault diagnosis with data privacy. Reliab. Eng. Syst. Saf. 2023, 236, 109246. [Google Scholar] [CrossRef]
- Zhao, K.; Jia, F.; Shao, H. A novel conditional weighting transfer Wasserstein auto-encoder for rolling bearing fault diagnosis with multi-source domains. Knowl.-Based Syst. 2023, 262, 110203. [Google Scholar] [CrossRef]
- Song, F.; Liu, Y.; Jin, W.; Tan, J.; He, W. Data-Driven Feedforward Learning With Force Ripple Compensation for Wafer Stages: A Variable-Gain Robust Approach. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 1594–1608. [Google Scholar] [CrossRef]
- Maliński, K.; Okarma, K. Application of CNN-Based Method for Automatic Detection and Classification of the IC Packages. In Proceedings of the 16th International Conference on Control, Automation, Robotics and Vision (ICARCV), Shenzhen, China, 13–15 December 2020; pp. 944–950. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems, Virtual Event, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Volume 33, pp. 1877–1901. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018; Available online: OpenReview.net (accessed on 18 April 2023).
- Ng, H.W.; Nguyen, V.D.; Vonikakis, V.; Winkler, S. Deep Learning for Emotion Recognition on Small Datasets using Transfer Learning. In Proceedings of the 2015 ACM International Conference on Multimodal Interaction (ICMI), Seattle, WA, USA, 9–13 November 2015; pp. 443–449. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K., Eds.; Volume 27, pp. 672–2680. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; Pereira, F., Burges, C., Bottou, L., Weinberger, K., Eds.; Volume 25, pp. 1106–1114. [Google Scholar]
- Yujian, L.; Bo, L. A Normalized Levenshtein Distance Metric. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1091–1095. [Google Scholar] [CrossRef]
- Sporici, D.; Cușnir, E.; Boiangiu, C.A. Improving the Accuracy of Tesseract 4.0 OCR Engine Using Convolution-Based Preprocessing. Symmetry 2020, 12, 715. [Google Scholar] [CrossRef]
- Iskandarani, M.Z. Improving the OCR of Low Contrast, Small Fonts, Dark Background Forms Using Correlated Zoom and Resolution Technique (CZRT). J. Data Anal. Inf. Process. 2015, 3, 34–42. [Google Scholar] [CrossRef]
- Keys, R. Cubic convolution interpolation for digital image processing. IEEE Trans. Acoust. Speech Signal Process. 1981, 29, 1153–1160. [Google Scholar] [CrossRef]
- Battiato, S.; Gallo, G.; Stanco, F. A locally adaptive zooming algorithm for digital images. Image Vis. Comput. 2002, 20, 805–812. [Google Scholar] [CrossRef]
- Mukhopadhyay, P.; Chaudhuri, B.B. A survey of Hough Transform. Pattern Recognit. 2015, 48, 993–1010. [Google Scholar] [CrossRef]
- Zuiderveld, K. Contrast Limited Adaptive Histogram Equalization. In Graphics Gems; Elsevier: Amsterdam, The Netherlands, 1994; pp. 474–485. [Google Scholar] [CrossRef]
- Sankur, B. Survey over image thresholding techniques and quantitative performance evaluation. J. Electron. Imaging 2004, 13, 146. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Bernsen, J. Dynamic thresholding of grey-level images. In Proceedings of the 8th International Conference on Pattern Recognition (ICPR), Paris, France, 27–31 October 1986; pp. 1251–1255. [Google Scholar]
- Bradley, D.; Roth, G. Adaptive Thresholding using the Integral Image. J. Graph. Tools 2007, 12, 13–21. [Google Scholar] [CrossRef]
- Niblack, W. An Introduction to Digital Image Processing; Prentice-Hall International: Hoboken, NJ, USA, 1986; p. 215. [Google Scholar]
- Feng, M.L.; Tan, Y.P. Adaptive binarization method for document image analysis. In Proceedings of the 2004 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 27–30 June 2004; Volume 1, pp. 339–342. [Google Scholar] [CrossRef]
- Nacereddine, N.; Boulmerka, A.; Mhamda, N. Video Processing and Analysis for Endoscopy-Based Internal Pipeline Inspection. In Image Processing and Communications Challenges 10; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 46–54. [Google Scholar] [CrossRef]
- Khurshid, K.; Siddiqi, I.; Faure, C.; Vincent, N. Comparison of Niblack inspired binarization methods for ancient documents. In Proceedings of the Document Recognition and Retrieval XVI, San Jose, CA, USA, 18–22 January 2009; Volume 7247, p. 7247. [Google Scholar] [CrossRef]
- Serra, J.; Soille, P. (Eds.) Mathematical Morphology and Its Applications to Image Processing; Springer: Dordrecht, The Netherlands, 1994. [Google Scholar] [CrossRef]
- Michalak, H.; Okarma, K. Improvement of Image Binarization Methods Using Image Preprocessing with Local Entropy Filtering for Alphanumerical Character Recognition Purposes. Entropy 2019, 21, 562. [Google Scholar] [CrossRef]
- Michalak, H.; Okarma, K. Adaptive Image Binarization Based on Multi-layered Stack of Regions. In Computer Analysis of Images and Patterns; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 281–293. [Google Scholar] [CrossRef]
- Michalak, H.; Okarma, K. Fast Binarization of Unevenly Illuminated Document Images Based on Background Estimation for Optical Character Recognition Purposes. J. Univers. Comput. Sci. 2019, 25, 627–646. [Google Scholar] [CrossRef]
- Pratikakis, I.; Zagoris, K.; Karagiannis, X.; Tsochatzidis, L.; Mondal, T.; Marthot-Santaniello, I. ICDAR 2019 Competition on Document Image Binarization (DIBCO 2019). In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019; pp. 1547–1556. [Google Scholar] [CrossRef]
- Lins, R.D.; Bernardino, R.B.; Smith, E.B.; Kavallieratou, E. ICDAR 2021 Competition on Time-Quality Document Image Binarization. In Document Analysis and Recognition—ICDAR 2021; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 708–722. [Google Scholar] [CrossRef]
- Ponomarenko, N.; Jin, L.; Ieremeiev, O.; Lukin, V.; Egiazarian, K.; Astola, J.; Vozel, B.; Chehdi, K.; Carli, M.; Battisti, F.; et al. Image database TID2013: Peculiarities, results and perspectives. Signal Process. Image Commun. 2015, 30, 57–77. [Google Scholar] [CrossRef]
- Hosu, V.; Lin, H.; Sziranyi, T.; Saupe, D. KonIQ-10k: An Ecologically Valid Database for Deep Learning of Blind Image Quality Assessment. IEEE Trans. Image Process. 2020, 29, 4041–4056. [Google Scholar] [CrossRef] [PubMed]
- Gu, J.; Cai, H.; Chen, H.; Ye, X.; Ren, J.S.; Dong, C. PIPAL: A Large-Scale Image Quality Assessment Dataset for Perceptual Image Restoration. In Computer Vision—ECCV 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 633–651. [Google Scholar] [CrossRef]
- Chemmanam, A.J.; N, S.; Jose, B.A. Fused features for no reference image quality assessment. Imaging Sci. J. 2022, 70, 287–299. [Google Scholar] [CrossRef]
- Tsai, P.F.; Peng, H.N.; Liao, C.H.; Yuan, S.M. Full-Reference Image Quality Assessment with Transformer and DISTS. Mathematics 2023, 11, 1599. [Google Scholar] [CrossRef]
- Yao, J.; Shen, J.; Yao, C. Image quality assessment based on the perceived structural similarity index of an image. Math. Biosci. Eng. 2023, 20, 9385–9409. [Google Scholar] [CrossRef]
- Sauvola, J.; Pietikäinen, M. Adaptive document image binarization. Pattern Recognit. 2000, 33, 225–236. [Google Scholar] [CrossRef]
- Wolf, C.; Jolion, J.M. Extraction and recognition of artificial text in multimedia documents. Form. Pattern Anal. Appl. 2004, 6, 309–326. [Google Scholar] [CrossRef]
- Van Herk, M. A fast algorithm for local minimum and maximum filters on rectangular and octagonal kernels. Pattern Recognit. Lett. 1992, 13, 517–521. [Google Scholar] [CrossRef]
- Michalak, H.; Okarma, K. Robust Combined Binarization Method of Non-Uniformly Illuminated Document Images for Alphanumerical Character Recognition. Sensors 2020, 20, 2914. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| OCR Engine | Average Levenshtein Distance |
|---|---|
| Tesseract | 27.63 |
| GOCR | 29.33 |
| CuneiForm | 38.24 |
| Kraken | 31.12 |
| A9T9 | 36.40 |
| Neighborhood Size (for Adaptive Methods) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Method | ||||||||
| Global | 25.63 | |||||||
| Otsu [25] | 29.43 | |||||||
| Bernsen [26] | 23.77 | |||||||
| Entropy filtering [33] | 20.92 | |||||||
| Stack of regions [34] | 37.01 | |||||||
| Resampling [35] | 24.95 | |||||||
| Liedes | 25.27 | |||||||
| Bradley [27] | 22.70 | 22.64 | 22.44 | 22.13 | 21.94 | 21.98 | 21.50 | 21.67 |
| Feng [29] | 26.73 | 23.85 | 24.50 | 25.00 | 24.86 | 22.27 | 23.55 | 25.16 |
| Niblack [28] | 24.30 | 24.19 | 23.65 | 23.60 | 23.42 | 23.80 | 25.43 | 25.60 |
| Sauvola [44] | 24.15 | 24.15 | 23.59 | 23.74 | 23.33 | 23.08 | 23.22 | 24.69 |
| Wolf [45] | 24.36 | 24.28 | 23.59 | 24.18 | 24.36 | 24.01 | 24.23 | 24.20 |
| NICK [31] | 24.32 | 24.59 | 24.21 | 24.29 | 24.18 | 23.82 | 23.36 | 24.19 |
| Van Herk [46] | 24.31 | 24.32 | 23.93 | 24.37 | 24.11 | 24.26 | 24.14 | 24.21 |
| Number of Algorithms | Average Levenshtein Distance |
|---|---|
| 11 | 22.74 |
| 9 | 22.03 |
| 7 | 21.13 |
| 5 | 19.32 |
| 3 | 22.07 |
| Removed Processing Step | Average Levenshtein Distance | Change |
|---|---|---|
| none—full processing pipeline | 19.32 | — |
| image straightening | 20.14 | 4.2% |
| image scaling | 24.79 | 28.3% |
| binarization | 26.98 | 39.6% |
| morphological border cleaning | 19.74 | 2.2% |
| morphological noise removal | 19.56 | 1.2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maliński, K.; Okarma, K. Analysis of Image Preprocessing and Binarization Methods for OCR-Based Detection and Classification of Electronic Integrated Circuit Labeling. Electronics 2023, 12, 2449. https://doi.org/10.3390/electronics12112449
Maliński K, Okarma K. Analysis of Image Preprocessing and Binarization Methods for OCR-Based Detection and Classification of Electronic Integrated Circuit Labeling. Electronics. 2023; 12(11):2449. https://doi.org/10.3390/electronics12112449
Chicago/Turabian StyleMaliński, Kamil, and Krzysztof Okarma. 2023. "Analysis of Image Preprocessing and Binarization Methods for OCR-Based Detection and Classification of Electronic Integrated Circuit Labeling" Electronics 12, no. 11: 2449. https://doi.org/10.3390/electronics12112449