1. Introduction
EQP aims at predicting the specific location, magnitude and time of future earthquake events [
1]. Through long-term observation, research and accumulation of experience by experts, it is found that there is an inherent relationship between the three elements of earthquakes (earthquake occurrence time, magnitude, and epicenter location) and characteristic indicators [
2]. Prediction of changes using historical seismic characteristic indicators is a commonly used method for EQP.
With the development of artificial intelligence, researchers have tried to apply related algorithms to EQP, and achieved good prediction results. Large earthquakes is a small probability event with a long time interval, and the number of large earthquakes observed by modern observation equipment is relatively few. Therefore, the lack of data affects the accuracy of EQP using historical seismic data [
1].
The NSA [
3], which belongs to an artificial immune algorithm, simulates the principle of self–non-self identification in the biological immune system. The algorithm mimics the process of the negative selection of immature T lymphocytes in the organism during the maturation process. First, determine the self-set; then randomly generate detectors, by deleting the detectors that recognize the self, and keep the detectors that recognize the non-self. Its advantage is that it does not require prior knowledge, and only needs a limited amount of self-data as a training set to generate a large number of non-self detectors for detecting the non-self [
3]. It is often used in binary classification problems, for it can identify self and non-self. In this study, predicting the occurrence of earthquakes of moment magnitude (MW) 5.0 and above can be regarded as a binary classification problem in essence [
4], and the NSA can be used to identify the occurrence of earthquakes (non-self) and the non-occurrence of earthquakes (self). As there is no need for non-self datasets (earthquakes of MW 5.0 and above) in the negative selection training process, the low prediction accuracy problem caused by the lack of large earthquake data in traditional machine learning methods can be solved.
In this study, the NSA of computer immunology is introduced to establish the EQP model. Using the self-non-self identification principle of negative selection, earthquakes with a predefined threshold and above magnitudes that did not occur are regarded as self, and earthquakes with a predefined threshold and above magnitudes are regarded as non-self. Since only the self data are used as the training set, the influence of the lack of large earthquake data on the training effect is reduced, and the purpose of improving the prediction accuracy of large earthquakes is achieved. Specifically, the gradient descent that encompasses DCA for data drift identification is used for the optimization of NSA. The DCA is executed in an online fashion to detect changes from the input data. A detected data drift will stimulate the optimization process. In the experimental part of this study, the MW 5.0 is used as our prediction threshold.
The main contributions of this study are described as follows:
A NSA model with the ability of adaptive learning is proposed, and it can adapt to changes in the environment and context.
DCA detects data drifts in the context of trigger-adaptation strategies, namely, the gradient descent is used to optimize the radius parameter of NSA.
The proposed DC-NSA is implemented to the historical seismic events in Sichuan and the surrounding areas.
The remainder of this study is summarized as follows:
Section 2 reviews the related works; the proposed DC-NSA framework is described in
Section 3; the experimentation part, including baselines and comparison analysis, are demonstrated in
Section 4; and
Section 5 introduces the conclusion and future works.
2. Related Works
Various machine learning methods have been implemented in EQP using historical seismic events, including statistic methods, ANN-based approaches, deep learning, and artificial immune methods [
5,
6].
Several rule-based approaches have been proposed to implement EQP tasks. For instance, Dehbozorgi and Farokhi [
7] first introduced neuro-fuzzy to predict short-term earthquake via historical seismic events. The time, location, seismic magnitude, depth, statistical, and entropy parameters, are adopted to predict whether an earthquake will occur in the following five minutes. The association rule mining is applied to predict a subsequent earthquake with reference to the historical seismic events [
8]. A spatial analysis of magnitude distribution for EQP using ANFIS based on automatic clustering is proposed to predict earthquakes of magnitudes higher than MW 5 in Indonesia [
9]. Rule-based approaches are popular due to their ease of use and flexibility.
Many studies, such as [
10,
11,
12], have been proposed to deal with EQP. Of these, artificial neural networks (ANNs) are the widely used approaches due to their ability to engage in self-learning and handle complex problems. However, it suffers from the lack of training data when implemented for EQPs. Shi et al. [
13] first introduced ANN in the EQP context and established the relationships between magnitude and earthquake epicentral intensity; nevertheless, the method achieves poor performance. Many research works have followed this method using various ANNs. For instance, a support vector regressor and hybrid neural network (SVR-HNN) are adopted to predict earthquakes in [
14]; this approach uses maximum relevance and minimum redundancy criteria for the relevant indicators’ extraction. The authors provide sixty seismic features for EQP and achieve encouraging prediction results. However, this work does not analyze seismic-related and non-seismic-related anomalies.
There are also many shallow machine learning works that focus on EQP. For example, in [
15], a method to discover clustering-based patterns and predict medium-large earthquakes is proposed. This approach adopts maximum likelihood to estimate the b-value of seismic data. The authors confirm that the b-value can be regarded as an earthquake precursor, and K-means achieves good performance. However, it only considers the b-value as a seismic precursor, and thus cannot truly reflect the complexity of an earthquake and affect the prediction performance. In [
16], the principal-component-analysis-based random forest (PCA-RF) was introduced to execute data dimension reduction and generate new datasets to generalize existing prediction models, and the experimental results demonstrate that the average accuracies of these approaches have been improved. Unfortunately, the differences in geological structure hinder their universality. Asim et al. [
17] adopted support vector machine (SVM) and random forest to predict earthquake activities in Cyprus, while further proving that random forest is most suitable for magnitude thresholds of MW 3.0 and MW 3.5. Notably, however, random forest produces overfitting.
Several deep learning approaches have been proposed to implement EQP tasks. For instance, DeVries et al. [
18] introduced a deep-learning method to determine a static stress-based criterion that can predict aftershock locations without presupposing the fault orientation. Moreover, it provides improved aftershock prediction location and identifies physical quantities that control seismic triggering when the earthquake cycle is active; however, it requires a large amount of training samples. Huang et al. [
19] adopted CNN for continuous EQP using historical seismic events in Taiwan, and identified its temporal pattern, which may be useful for further EQP. However, this research conducts no analysis regarding seismic indicators. Wang et al. [
20] introduced LSTM to learn the spatio-temporal relationships among earthquakes and further proved its the robustness and effectiveness. This approach can be used for EQP, even in areas without seismic sensors; however, it is computationally expensive and time-consuming.
Various artificial immune approaches have been implemented in the EQP context. For instance, in [
21], NSA is adopted to reduce the impact of inadequate earthquake data on the performance in training phase. First, eight seismic indicators proposed in [
11] served as the input of NSA. If an earthquake with a magnitude (MW ≥ 4.5) does not occur, it is regarded as “self”; otherwise, it is regarded as “non-self”. A mature detector is then generated to detect anomalous test instances. While this approach can quickly detect earthquakes, the self-detectors are difficult to define, and the deletion of matching detectors in the detector generation phase will lead to low algorithmic efficiency. In [
22], DCA is introduced for EQP. First, PCA is adopted to map these indicators to the safe signal (SS), pathogen-associated molecular pattern (PAMP) and danger signal (DS) of DCA; here, PAMP denotes the existence of anomalous indicators (indicating strong seismic activity), SS indicates that the possibility of normal is relatively high (that is, the seismic activity is weak), and DS shows that the possibility of an earthquake is high. DC then randomly samples antigens and signals to produce cumulative co-stimulatory molecules (csm), a semi-mature signal (semi), and a mature signal (mat). When the cumulative csm exceeds a given migration threshold, DC begins to migrate. If the cumulative semi exceeds the cumulative mat, the DC is semi-mature; otherwise, it is mature. Finally, the number of times each antigen is presented to be normal and anomalous is calculated, and the degree of abnormality of the antigen is evaluated by the calculating mature context antigen value (MCAV). If MCAV exceeds an anomalous threshold, the antigen is anomalous (an earthquake occurs); otherwise, it is normal (an earthquake does not occur). In [
23], a Haskell-based deterministic DCA (EQP-hDCA) was presented to predict the magnitude of earthquakes in Sichuan and surroundings with magnitudes greater than MW 4.5 in the following month. While the DCA-based EQP obtains good performance, it is affected by a serious false alarm rate, while dealing with the application, including frequent data-type switching.
To sum up, the selection of the EQP model is very important to the prediction performance. This study proposes a novel EQP method; we select the eight indicators used in literature [
2] as eigenvectors, and use negative selection to establish an EQP model. Moreover, DCA is used for the optimization of NSA. Since the detector generation process of the NSA only needs to use the self dataset, it can be used to reduce the problem of low prediction accuracy caused by the lack of large earthquake data in methods such as neural networks. Then, the DCA detects data drifts in input data to trigger gradient descent adaptation strategies, to improve the prediction accuracy.
3. The Proposed DC-NSA Earthquake Prediction Approach
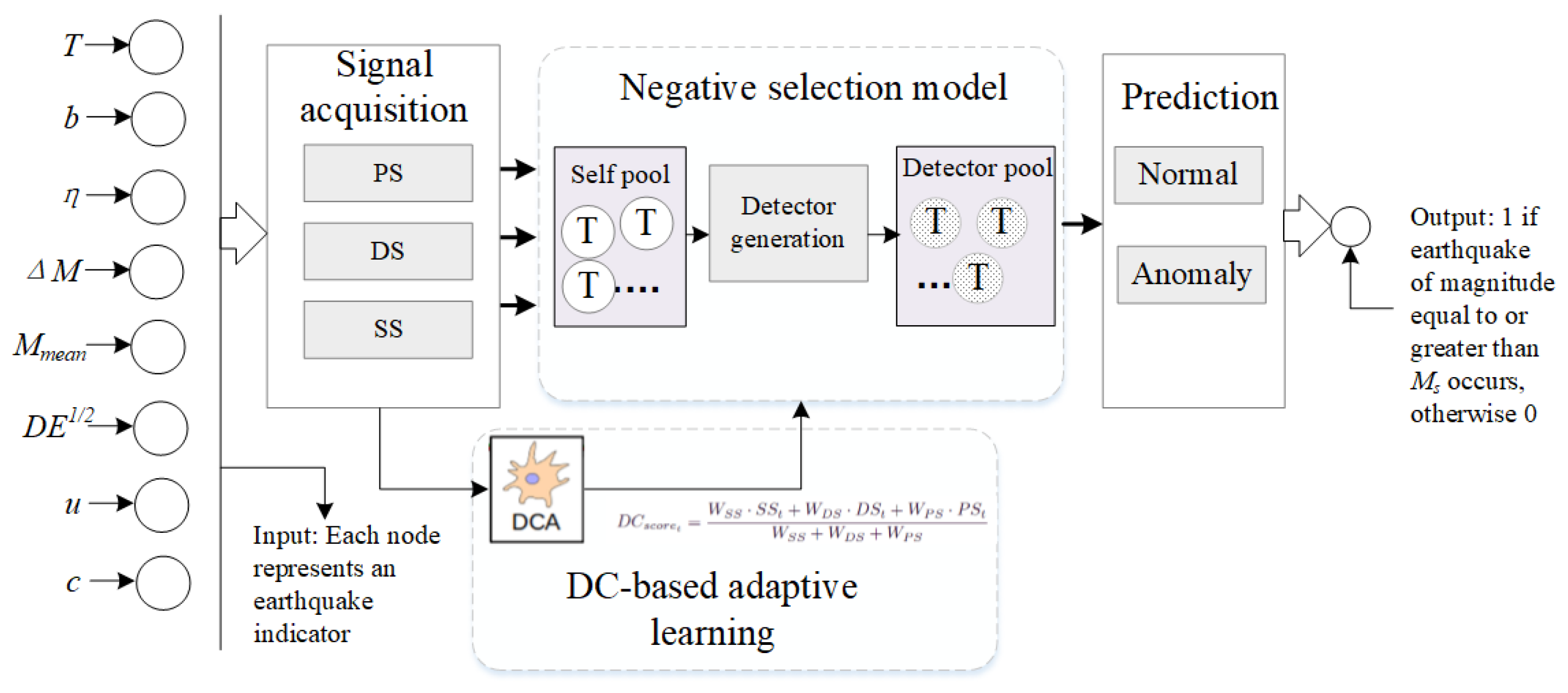
The DC-NSA architecture for EQP is described in
Figure 1, including three parts: preprocessing, NSA prediction and DC-based adaptive learning process. Firstly, the seismic event set is described as
, which is the data source of seismic indicator matrix
F, as explained in
Table 1. According to [
24],
indicates that the maximum magnitude for events occurring within the prediction horizon is larger than or equal to the threshold
, and
otherwise. The input of DC-NSA is matrix
F. Then, the corresponding DCA model executes a signal acquisition operation to sensor changes or drifts in the contextual data, and initializes the parameters of the parameters of the gradient descent. Meanwhile, the obtained signal matrix in DCA model serves as the input of NSA to execute an EQP task. Then, with the recognition of changes or drifts in contextual data, gradient descent is implemented to optimize the radius
of NSA. The output of NSA-DCA is the prediction result; 1 indicates an earthquake of magnitude equal to or greater than
occurs, and 0 otherwise.
3.1. Seismic Indicators
The seismic indicators are calculated according to GR law, the distribution of earthquakes magnitude, and the latest EQP studies. In this study, the indicator matrix is defined as
, where
N is the number of seismic events, while
[
11]. For a seismic event
i, the indicator
is the b-value,
is the mean square deviation,
denotes the magnitude difference between the maximum magnitude and the maximum expected magnitude observed according to GR law,
is the time elapsed over the last
events with a magnitude greater than a predefined threshold (
),
is the mean time between the
N last
-characteristic events,
is the coefficient of variation of the mean time between the
N last
-characteristic events (
),
is the rate of the square root of released seismic energy, and
is the mean of the Richter magnitudes of the last
N events.
Table 1 presents the formulas used to calculate these values. Here,
denotes the cumulative frequency of earthquakes above zero,
denotes the Richter magnitude,
n is the total number of earthquake events,
denotes the observed elapsed time between characteristic events (
), and
is the total number of characteristic events. The first three indicators and the difference
are related to GR law, while
,
,
are unrelated to the assumed temporal distribution of seismic magnitude; moreover,
,
are related to the distribution of the characteristic temporal seismic magnitude.
3.2. Negative Selection Algorithm
Negative selection aims at generating tolerance to self cells, and hence, the immune system has the ability to detect unknown antigens and not to react to self-cells [
3]. The input of the NSA is self set, where each self is represented by an n-dimensional vector. The detectors (antibodies) generated by the algorithm cover the non-self space. It mainly uses an n-dimensional vector to define the detector, and uses a real value to describe the detection radius of the detector. A detector can be thought of as a hypersphere. Whether the detector detects the antigen depends on the distance between the detector and the antigen (calculated using the Euclidean distance formula) and the detector radius. If the distance is less than the self-radius, which means that the two hyperspheres intersect, which means that the detector can identify self, then the detector is eliminated; otherwise, the distance between the detector and self is taken as the radius. If the mature detectors have different radii, a large range of non-self spaces can be covered by very few discriminators; meanwhile, for less non-self spaces around the self, detectors with smaller radii can be used to cover them. The mature detector generation algorithm flow is illustrated in Algorithm 1.
| Algorithm 1 NSA |
Input: self S Output: classification matrix 1: Initialize the number of detectors , self radius , detectors set D, and maximum distance 2: while the number of detectors < do 3: Generates n-dimensional vectors d randomly 4: for each antigen s in training set S do 5: Calculate the Euclidean distance between the random detector d and the self 6: if then 7: 8: end if 9: end for 10: if then 11: 12: Add the vector to the mature detector set D 13: end if 14: end while |
3.3. Dendritic Cell Algorithm-Based NSA
In the biology immune system, dendritic cells (DCs) can identify potentially damaging foreign bodies, namely, it has strong classification abilities. Therefore, the DCA was proposed and implemented as an intrusion detection approach [
25].
DCA draws on the antigen present process of DCs. DCs are able to collect and process antigens, which are molecules that stimulate immune responses, as they are in the mature state. In the immature state (iDCs), the DCs can collect diverse immune signals, including pathogen-associated molecular pattern signals (PSs), danger signals (DSs), and safety signals (SSs). The iDC changes to a semi-mature state (smDC) or mature state (mDC) according to the concentration of immune signals received. More precisely, smDC contains more SS than PS and DS, and can be declared a security context. On the contrary, mDC exposed to a large number of PS and DS will be considered a danger environment; therefore, the antigen is eliminated. Another output is the costimulatory molecule (CSM). It executes DC migration when a predefined threshold is reached. Algorithm 2 shows the structure of DCA.
The anomaly metric characterizing the signal is in accordance with the distance metric, which simply calculates the difference between SS and DS in the context parameter values of time
t and
. The Euclidean distance between all contextual parameters at time
t and
is applied for
. Given a dataset of
k contextual features
, where each feature variable
can obtain a value from its own support
, and
n contextual feature instances,
, with
,
,
and
signals are calculated as
where
is the Frobenius norm, and
is the Z-score normalized contextual feature vectors at
. After determining when the DC becomes smDC or the lifetime duration of mDC according to the concentration of its PS, DS and SS signals, check the DC, depending on
. The checking process can be described as
where
,
, and
are the weights for the
,
, and
signals, respectively.
,
, and
are the signal values at time
t computed based on Equations (
1)–(
3), respectively.
When the migration threshold
is reached, the DC no longer acknowledges the new instance to process, classifies the antigen and removes the DC from the population. Then it creates a new DC to replace it. A time window
is adopted to account for temporality relative to the DC state. Checks the fixed segment
of a DC of size
, so the resulting value can consider previous values. The
is a failure threshold, and it is finally possible to estimate whether a segment of size
at time
t indicates a change, which in this case, corresponds to a context change, and then the gradient descent should be activated. Assuming that at least one contextual feature is set by the DC as a change at time
t, the entire system has to undergo the data drift:
where
. When
, the NSA model corresponds to the current system state and must adapt to the new situation.
Table 2 shows examples of possible values for three DCA parameters as part of the experimental setup for real test scenarios discussed later.
| Algorithm 2 DCA |
Input: seismic indicators F. Output: antigen context vectors. for each antigen poll do , , and calculation by Equations ( 1)–( 3); end for for each DC do antigen adaptation; signal fusion calculation by Equation ( 4) and Table 2; if > migration threshold then antigen adaptation; end if for the DC do if SEMI > then DCContext = SEMI; else DCContext = MAT; end if end for end for for each antigen do if MCAV > then antigen = anomalous; gradient descent; else antigen = normal; end if end for
|
5. Conclusions and Future Work
This paper described an EQP method by integrating DCA and NSA. The main contribution of this paper is that it presents a novel DC-NSA approach to make a more suitable EQP model. Firstly, DC-NSA preprocesses earthquake indicators using the GR law and other earthquake magnitude distribution techniques, and obtains a seismic indicator F. Further, the corresponding DCA model executes a signal acquisition operation to sensor changes or drifts in the contextual data, and initializes the parameters of the parameters of the gradient descent. Meanwhile, the obtained signal matrix in DCA model serves as the input of NSA to execute an EQP task. Then, with the recognition of changes or drifts in contextual data, gradient descent is implemented to optimize the radius of NSA. Finally, this study used the historical seismic events in Sichuan and surroundings as our experimental data, and compared the proposed approach with DCA, NSA, PCA-RF, BPNN, RNN, PNN, EQP-hDCA, LSTM, and SVR-HNN, using the PPV, NPV, Rn, S, FAR, MCC, AUC, Avg, and R as comparison criteria. The experimental results demonstrate that our proposed DC-NSA is superior to the compared approaches.
In this study, the proposed method is derived from the function of T cell and DCs in the immune system; unlike traditional EQP methods, which lacks adaptively, the proposed approach implements the change adjustments based on the input sample. Meanwhile, the DC-NSA can handle the problem that NSA suffers from the normal patterns learned from data that have become obsolete.
However, this study only focuses on the historical seismic events, neglecting the observed data, which are also important for EQP. Therefore, we will adopt the observed data with much more instances than our experimental data. Moreover, future work will focus on enriching NSA and applying it to other earthquake-prone areas. We will further test NSA to improve the AIS detection performance through subsequent experiments.








{kind=link}
{kind=link}